 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Prototype-based Domain Generalization Framework for Subject-Independent Brain-Computer Interfaces
Apr 15, 2022
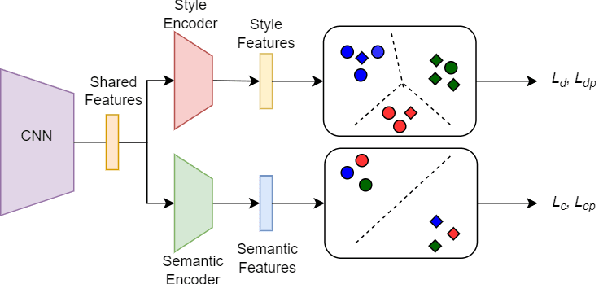
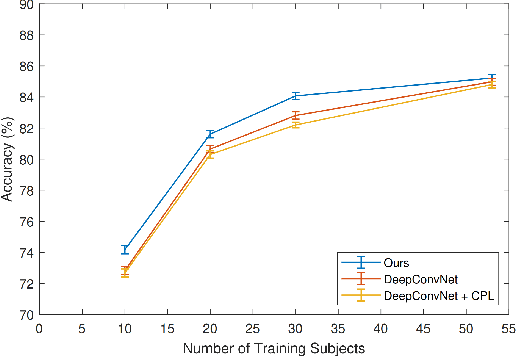
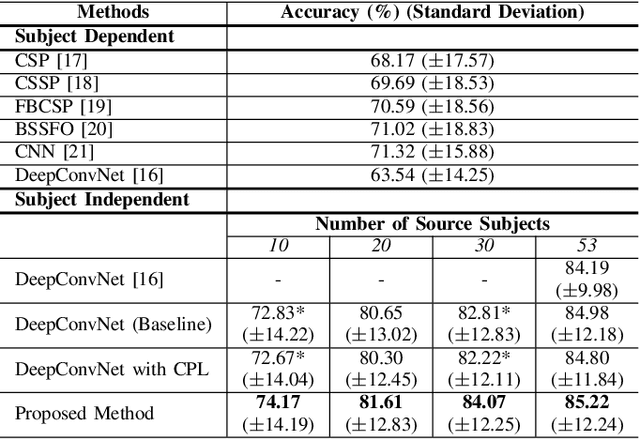
Brain-computer interface (BCI) is challenging to use in practice due to the inter/intra-subject variability of electroencephalography (EEG). The BCI system, in general, necessitates a calibration technique to obtain subject/session-specific data in order to tune the model each time the system is utilized. This issue is acknowledged as a key hindrance to BCI, and a new strategy based on domain generalization has recently evolved to address it. In light of this, we've concentrated on developing an EEG classification framework that can be applied directly to data from unknown domains (i.e. subjects), using only data acquired from separate subjects previously. For this purpose, in this paper, we proposed a framework that employs the open-set recognition technique as an auxiliary task to learn subject-specific style features from the source dataset while helping the shared feature extractor with mapping the features of the unseen target dataset as a new unseen domain. Our aim is to impose cross-instance style in-variance in the same domain and reduce the open space risk on the potential unseen subject in order to improve the generalization ability of the shared feature extractor. Our experiments showed that using the domain information as an auxiliary network increases the generalization performance.
Using Full-text Content of Academic Articles to Build a Methodology Taxonomy of Information Science in China
Jan 20, 2021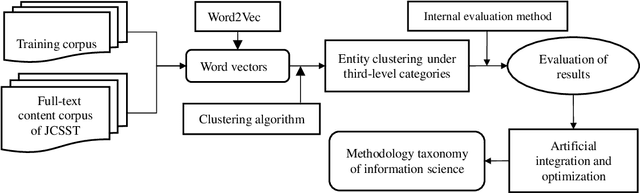
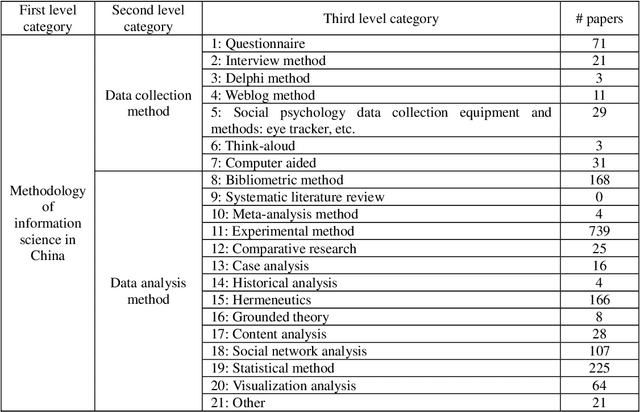
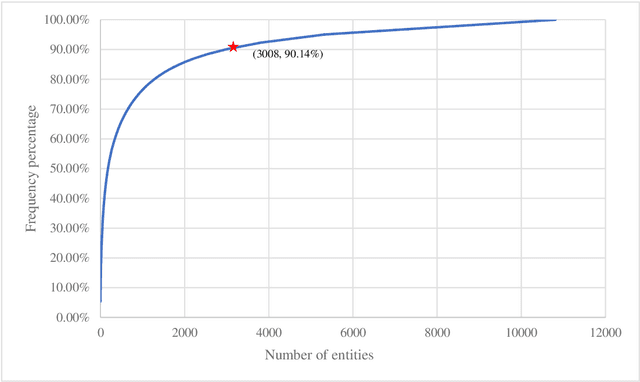

Research on the construction of traditional information science methodology taxonomy is mostly conducted manually. From the limited corpus, researchers have attempted to summarize some of the research methodology entities into several abstract levels (generally three levels); however, they have been unable to provide a more granular hierarchy. Moreover, updating the methodology taxonomy is traditionally a slow process. In this study, we collected full-text academic papers related to information science. First, we constructed a basic methodology taxonomy with three levels by manual annotation. Then, the word vectors of the research methodology entities were trained using the full-text data. Accordingly, the research methodology entities were clustered and the basic methodology taxonomy was expanded using the clustering results to obtain a methodology taxonomy with more levels. This study provides new concepts for constructing a methodology taxonomy of information science. The proposed methodology taxonomy is semi-automated; it is more detailed than conventional schemes and the speed of taxonomy renewal has been enhanced.
Demystifying Deep Learning in Predictive Spatio-Temporal Analytics: An Information-Theoretic Framework
Sep 14, 2020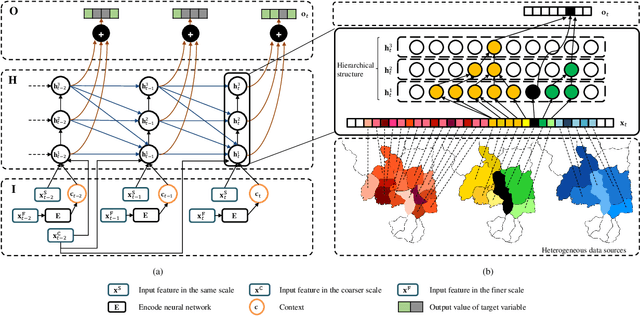
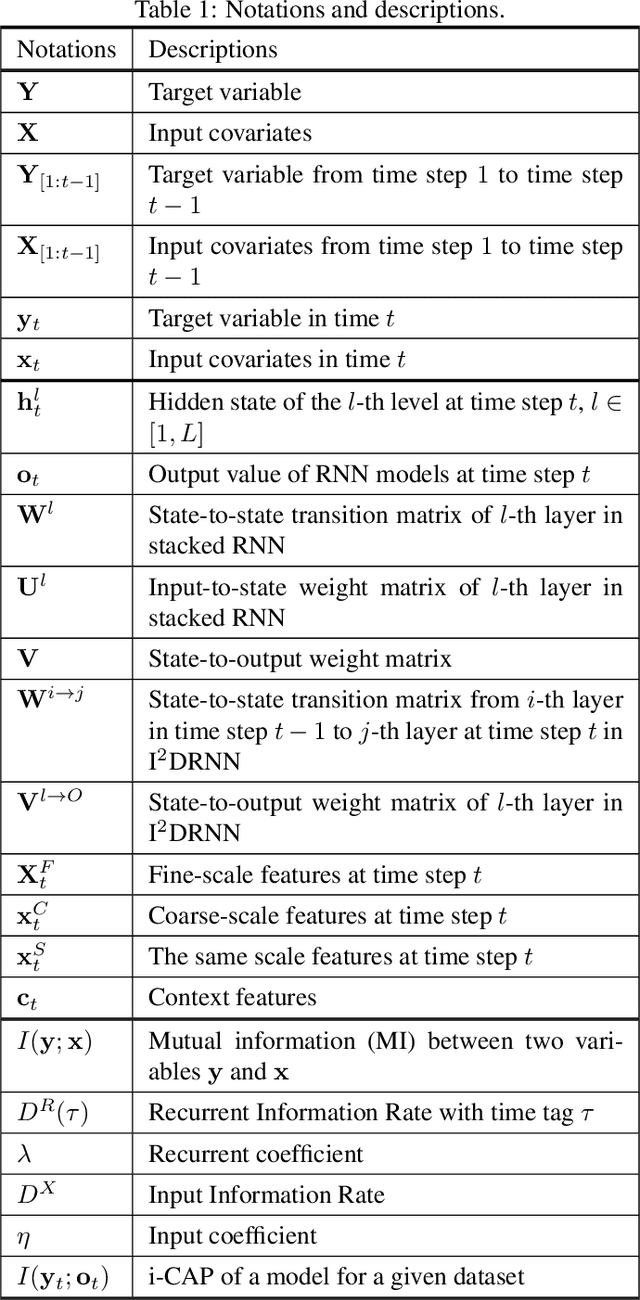
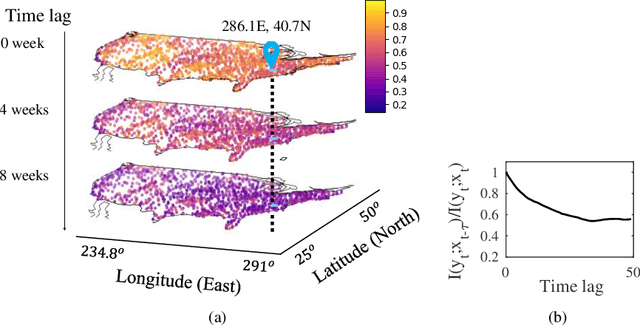
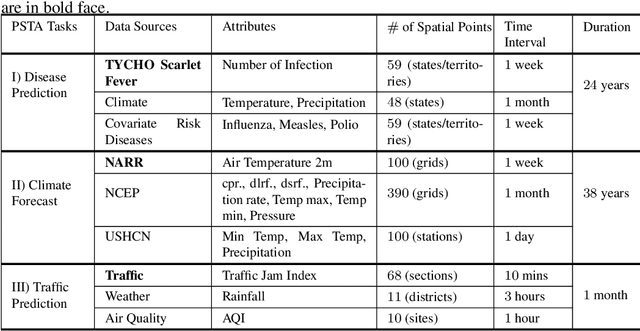
Deep learning has achieved incredible success over the past years, especially in various challenging predictive spatio-temporal analytics (PSTA) tasks, such as disease prediction, climate forecast, and traffic prediction, where intrinsic dependency relationships among data exist and generally manifest at multiple spatio-temporal scales. However, given a specific PSTA task and the corresponding dataset, how to appropriately determine the desired configuration of a deep learning model, theoretically analyze the model's learning behavior, and quantitatively characterize the model's learning capacity remains a mystery. In order to demystify the power of deep learning for PSTA, in this paper, we provide a comprehensive framework for deep learning model design and information-theoretic analysis. First, we develop and demonstrate a novel interactively- and integratively-connected deep recurrent neural network (I$^2$DRNN) model. I$^2$DRNN consists of three modules: an Input module that integrates data from heterogeneous sources; a Hidden module that captures the information at different scales while allowing the information to flow interactively between layers; and an Output module that models the integrative effects of information from various hidden layers to generate the output predictions. Second, to theoretically prove that our designed model can learn multi-scale spatio-temporal dependency in PSTA tasks, we provide an information-theoretic analysis to examine the information-based learning capacity (i-CAP) of the proposed model. Third, to validate the I$^2$DRNN model and confirm its i-CAP, we systematically conduct a series of experiments involving both synthetic datasets and real-world PSTA tasks. The experimental results show that the I$^2$DRNN model outperforms both classical and state-of-the-art models, and is able to capture meaningful multi-scale spatio-temporal dependency.
OWL (Observe, Watch, Listen): Localizing Actions in Egocentric Video via Audiovisual Temporal Context
Feb 14, 2022
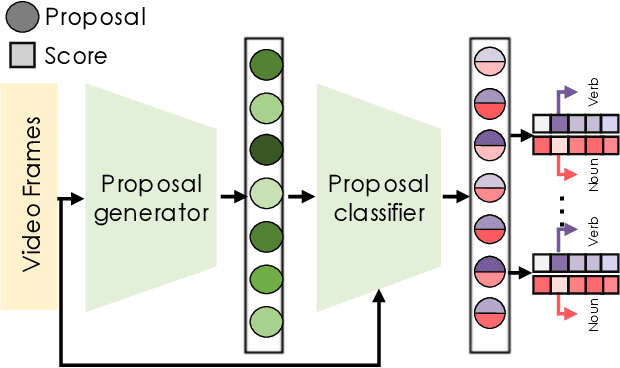

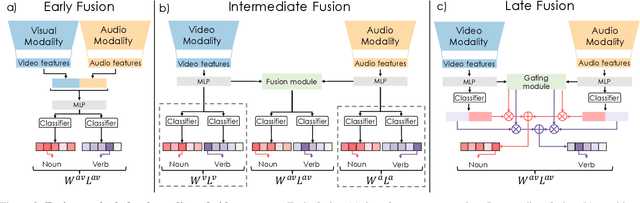
Temporal action localization (TAL) is an important task extensively explored and improved for third-person videos in recent years. Recent efforts have been made to perform fine-grained temporal localization on first-person videos. However, current TAL methods only use visual signals, neglecting the audio modality that exists in most videos and that shows meaningful action information in egocentric videos. In this work, we take a deep look into the effectiveness of audio in detecting actions in egocentric videos and introduce a simple-yet-effective approach via Observing, Watching, and Listening (OWL) to leverage audio-visual information and context for egocentric TAL. For doing that, we: 1) compare and study different strategies for where and how to fuse the two modalities; 2) propose a transformer-based model to incorporate temporal audio-visual context. Our experiments show that our approach achieves state-of-the-art performance on EPIC-KITCHENS-100.
Deep Joint Source-Channel Coding for CSI Feedback: An End-to-End Approach
Apr 07, 2022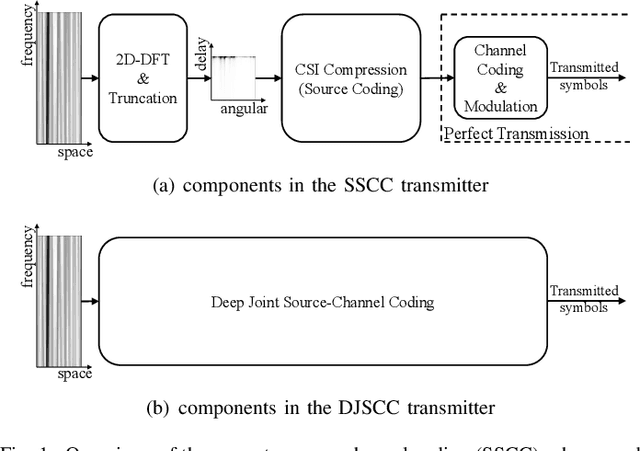
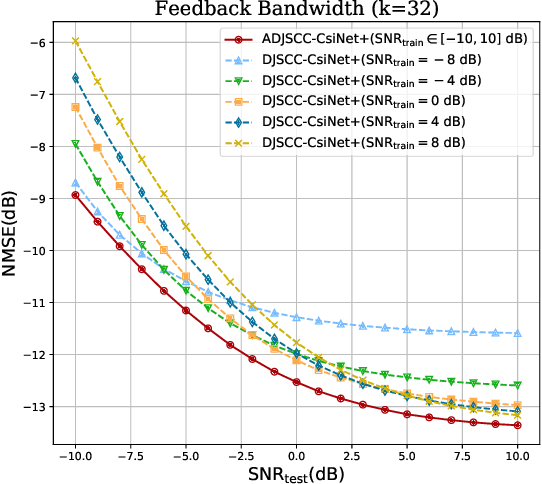
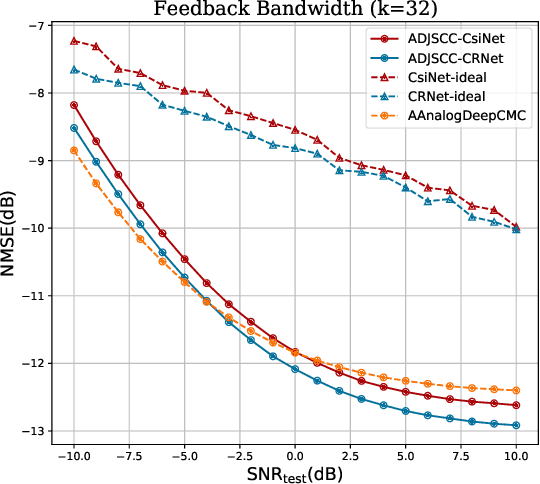
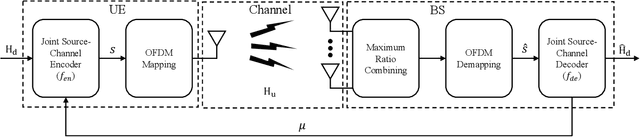
The increased throughput brought by MIMO technology relies on the knowledge of channel state information (CSI) acquired in the base station (BS). To make the CSI feedback overhead affordable for the evolution of MIMO technology (e.g., massive MIMO and ultra-massive MIMO), deep learning (DL) is introduced to deal with the CSI compression task. Based on the separation principle in existing communication systems, DL based CSI compression is used as source coding. However, this separate source-channel coding (SSCC) scheme is inferior to the joint source-channel coding (JSCC) scheme in the finite blocklength regime. In this paper, we propose a deep joint source-channel coding (DJSCC) based framework for the CSI feedback task. In particular, the proposed method can simultaneously learn from the CSI source and the wireless channel. Instead of truncating CSI via Fourier transform in the delay domain in existing methods, we apply non-linear transform networks to compress the CSI. Furthermore, we adopt an SNR adaption mechanism to deal with the wireless channel variations. The extensive experiments demonstrate the validity, adaptability, and generality of the proposed framework.
Semantic Segmentation for Point Cloud Scenes via Dilated Graph Feature Aggregation and Pyramid Decoders
Apr 11, 2022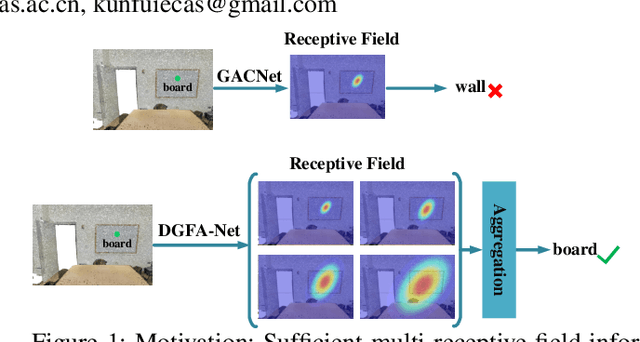
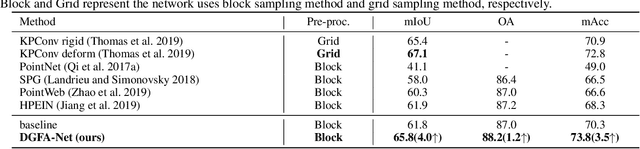
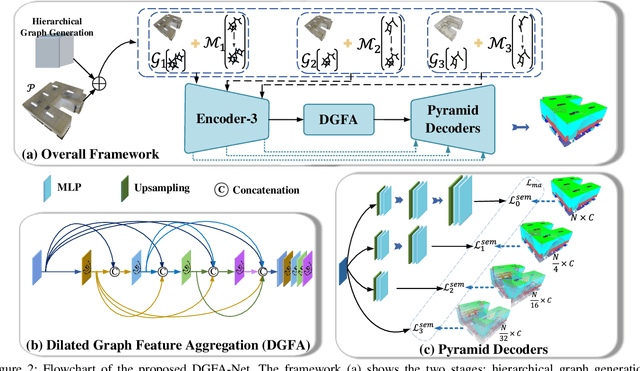

Semantic segmentation of point clouds generates comprehensive understanding of scenes through densely predicting the category for each point. Due to the unicity of receptive field, semantic segmentation of point clouds remains challenging for the expression of multi-receptive field features, which brings about the misclassification of instances with similar spatial structures. In this paper, we propose a graph convolutional network DGFA-Net rooted in dilated graph feature aggregation (DGFA), guided by multi-basis aggregation loss (MALoss) calculated through Pyramid Decoders. To configure multi-receptive field features, DGFA which takes the proposed dilated graph convolution (DGConv) as its basic building block, is designed to aggregate multi-scale feature representation by capturing dilated graphs with various receptive regions. By simultaneously considering penalizing the receptive field information with point sets of different resolutions as calculation bases, we introduce Pyramid Decoders driven by MALoss for the diversity of receptive field bases. Combining these two aspects, DGFA-Net significantly improves the segmentation performance of instances with similar spatial structures. Experiments on S3DIS, ShapeNetPart and Toronto-3D show that DGFA-Net outperforms the baseline approach, achieving a new state-of-the-art segmentation performance.
Ultrasound Shear Wave Elasticity Imaging with Spatio-Temporal Deep Learning
Apr 11, 2022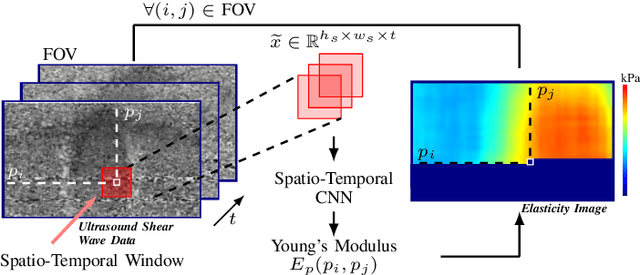
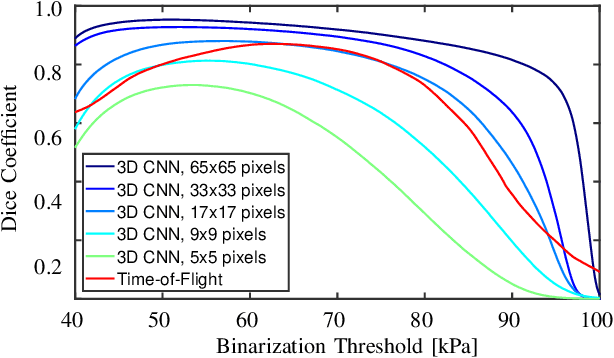
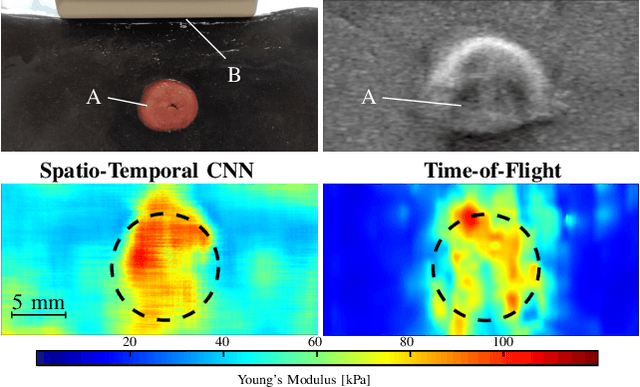

Ultrasound shear wave elasticity imaging is a valuable tool for quantifying the elastic properties of tissue. Typically, the shear wave velocity is derived and mapped to an elasticity value, which neglects information such as the shape of the propagating shear wave or push sequence characteristics. We present 3D spatio-temporal CNNs for fast local elasticity estimation from ultrasound data. This approach is based on retrieving elastic properties from shear wave propagation within small local regions. A large training data set is acquired with a robot from homogeneous gelatin phantoms ranging from 17.42 kPa to 126.05 kPa with various push locations. The results show that our approach can estimate elastic properties on a pixelwise basis with a mean absolute error of 5.01+-4.37 kPa. Furthermore, we estimate local elasticity independent of the push location and can even perform accurate estimates inside the push region. For phantoms with embedded inclusions, we report a 53.93% lower MAE (7.50 kPa) and on the background of 85.24% (1.64 kPa) compared to a conventional shear wave method. Overall, our method offers fast local estimations of elastic properties with small spatio-temporal window sizes.
WaBERT: A Low-resource End-to-end Model for Spoken Language Understanding and Speech-to-BERT Alignment
Apr 22, 2022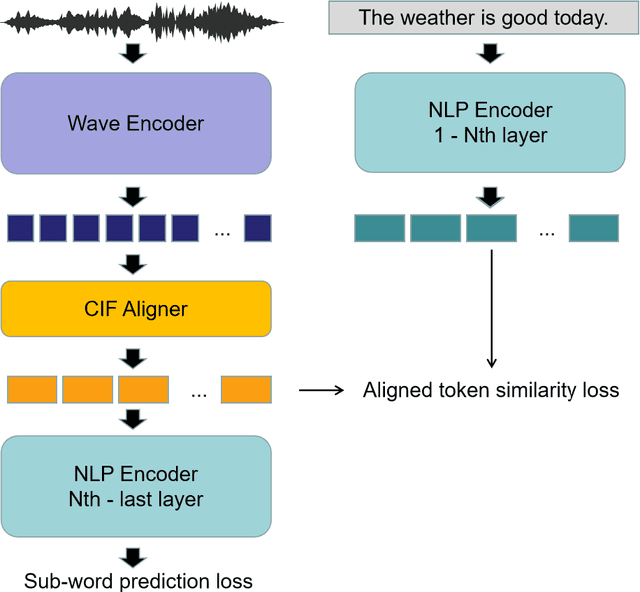


Historically lower-level tasks such as automatic speech recognition (ASR) and speaker identification are the main focus in the speech field. Interest has been growing in higher-level spoken language understanding (SLU) tasks recently, like sentiment analysis (SA). However, improving performances on SLU tasks remains a big challenge. Basically, there are two main methods for SLU tasks: (1) Two-stage method, which uses a speech model to transfer speech to text, then uses a language model to get the results of downstream tasks; (2) One-stage method, which just fine-tunes a pre-trained speech model to fit in the downstream tasks. The first method loses emotional cues such as intonation, and causes recognition errors during ASR process, and the second one lacks necessary language knowledge. In this paper, we propose the Wave BERT (WaBERT), a novel end-to-end model combining the speech model and the language model for SLU tasks. WaBERT is based on the pre-trained speech and language model, hence training from scratch is not needed. We also set most parameters of WaBERT frozen during training. By introducing WaBERT, audio-specific information and language knowledge are integrated in the short-time and low-resource training process to improve results on the dev dataset of SLUE SA tasks by 1.15% of recall score and 0.82% of F1 score. Additionally, we modify the serial Continuous Integrate-and-Fire (CIF) mechanism to achieve the monotonic alignment between the speech and text modalities.
X-Trans2Cap: Cross-Modal Knowledge Transfer using Transformer for 3D Dense Captioning
Mar 02, 2022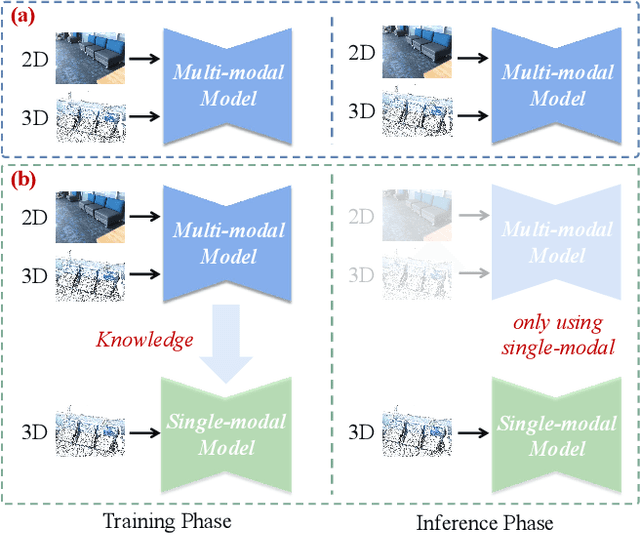
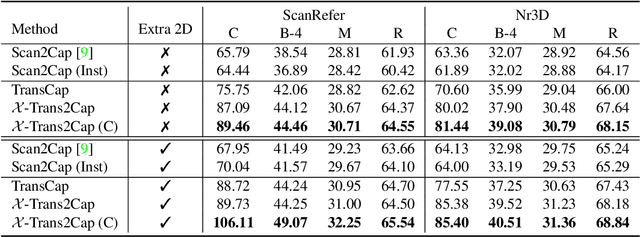
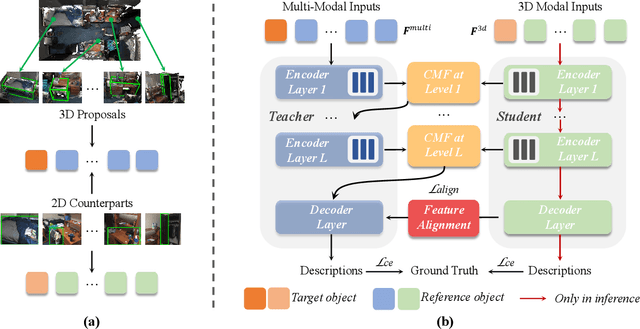

3D dense captioning aims to describe individual objects by natural language in 3D scenes, where 3D scenes are usually represented as RGB-D scans or point clouds. However, only exploiting single modal information, e.g., point cloud, previous approaches fail to produce faithful descriptions. Though aggregating 2D features into point clouds may be beneficial, it introduces an extra computational burden, especially in inference phases. In this study, we investigate a cross-modal knowledge transfer using Transformer for 3D dense captioning, X-Trans2Cap, to effectively boost the performance of single-modal 3D caption through knowledge distillation using a teacher-student framework. In practice, during the training phase, the teacher network exploits auxiliary 2D modality and guides the student network that only takes point clouds as input through the feature consistency constraints. Owing to the well-designed cross-modal feature fusion module and the feature alignment in the training phase, X-Trans2Cap acquires rich appearance information embedded in 2D images with ease. Thus, a more faithful caption can be generated only using point clouds during the inference. Qualitative and quantitative results confirm that X-Trans2Cap outperforms previous state-of-the-art by a large margin, i.e., about +21 and about +16 absolute CIDEr score on ScanRefer and Nr3D datasets, respectively.
OmniFusion: 360 Monocular Depth Estimation via Geometry-Aware Fusion
Mar 02, 2022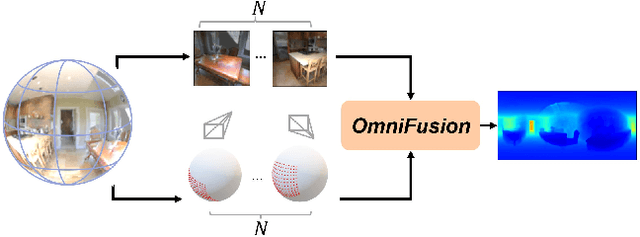
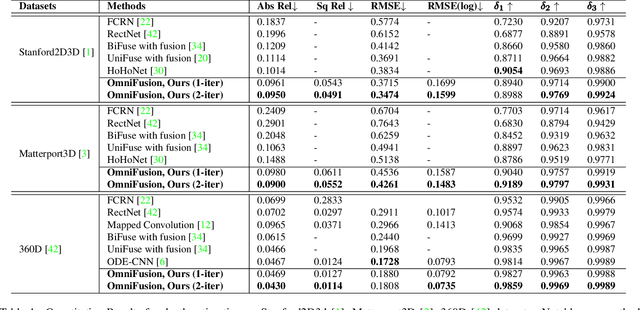
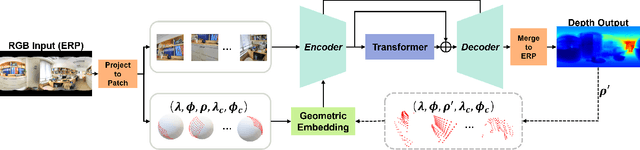

A well-known challenge in applying deep-learning methods to omnidirectional images is spherical distortion. In dense regression tasks such as depth estimation, where structural details are required, using a vanilla CNN layer on the distorted 360 image results in undesired information loss. In this paper, we propose a 360 monocular depth estimation pipeline, \textit{OmniFusion}, to tackle the spherical distortion issue. Our pipeline transforms a 360 image into less-distorted perspective patches (i.e. tangent images) to obtain patch-wise predictions via CNN, and then merge the patch-wise results for final output. To handle the discrepancy between patch-wise predictions which is a major issue affecting the merging quality, we propose a new framework with the following key components. First, we propose a geometry-aware feature fusion mechanism that combines 3D geometric features with 2D image features to compensate for the patch-wise discrepancy. Second, we employ the self-attention-based transformer architecture to conduct a global aggregation of patch-wise information, which further improves the consistency. Last, we introduce an iterative depth refinement mechanism, to further refine the estimated depth based on the more accurate geometric features. Experiments show that our method greatly mitigates the distortion issue, and achieves state-of-the-art performances on several 360 monocular depth estimation benchmark datasets.