 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ECAPA-TDNN for Multi-speaker Text-to-speech Synthesis
Mar 26, 2022
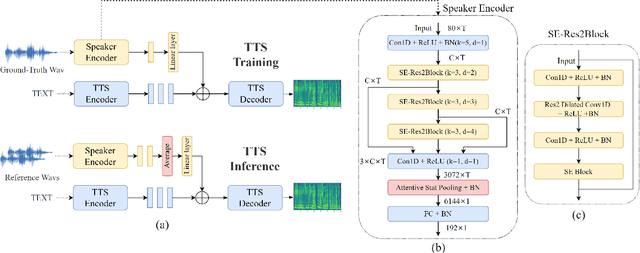
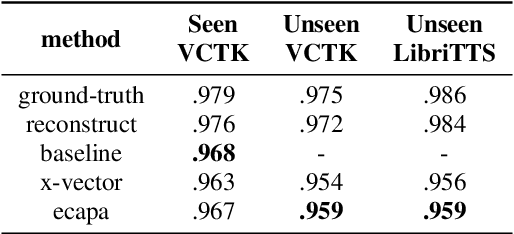
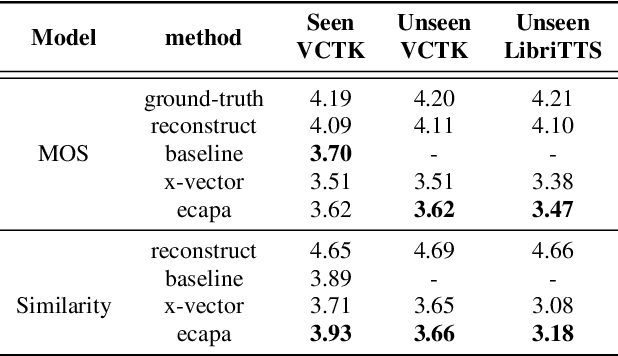
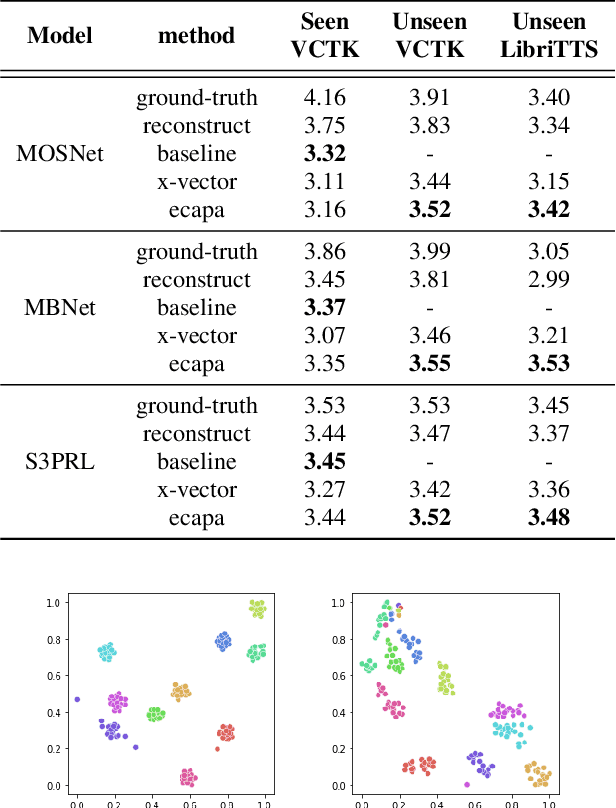
In recent years, neural network based methods for multi-speaker text-to-speech synthesis (TTS) have made significant progress. However, the current speaker encoder models used in these methods still cannot capture enough speaker information. In this paper, we focus on accurate speaker encoder modeling and propose an end-to-end method that can generate high-quality speech and better similarity for both seen and unseen speakers. The proposed architecture consists of three separately trained components: a speaker encoder based on the state-of-the-art ECAPA-TDNN model which is derived from speaker verification task, a FastSpeech2 based synthesizer, and a HiFi-GAN vocoder. The comparison among different speaker encoder models shows our proposed method can achieve better naturalness and similarity. To efficiently evaluate our synthesized speech, we are the first to adopt deep learning based automatic MOS evaluation methods to assess our results, and these methods show great potential in automatic speech quality assessment.
Multimodal Quasi-AutoRegression: Forecasting the visual popularity of new fashion products
Apr 08, 2022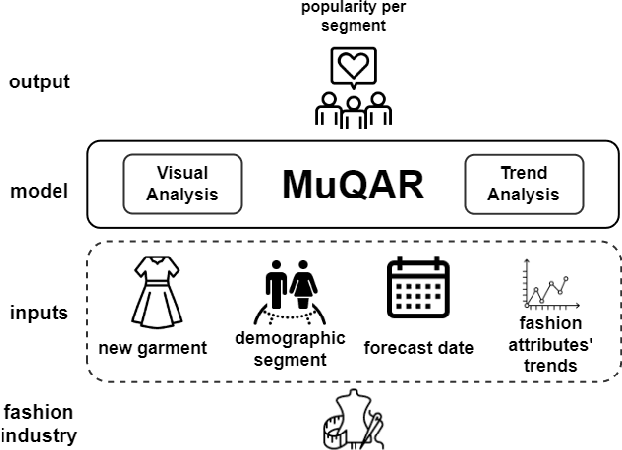
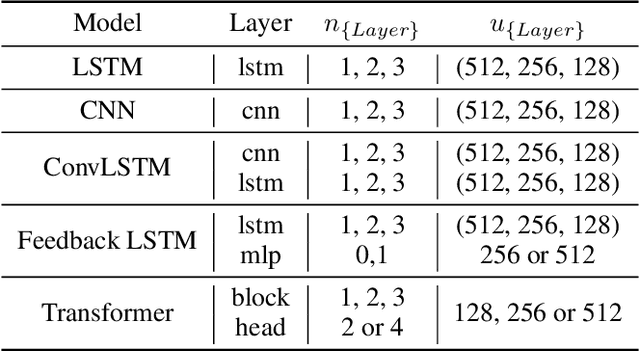
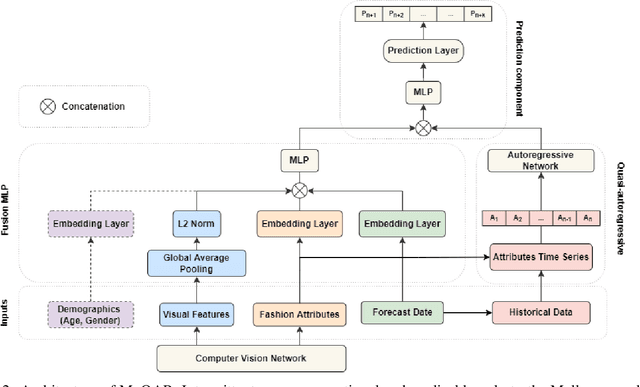
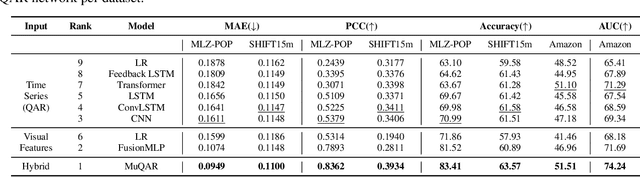
Estimating the preferences of consumers is of utmost importance for the fashion industry as appropriately leveraging this information can be beneficial in terms of profit. Trend detection in fashion is a challenging task due to the fast pace of change in the fashion industry. Moreover, forecasting the visual popularity of new garment designs is even more demanding due to lack of historical data. To this end, we propose MuQAR, a Multimodal Quasi-AutoRegressive deep learning architecture that combines two modules: (1) a multi-modal multi-layer perceptron processing categorical and visual features extracted by computer vision networks and (2) a quasi-autoregressive neural network modelling the time series of the product's attributes, which are used as a proxy of temporal popularity patterns mitigating the lack of historical data. We perform an extensive ablation analysis on two large scale image fashion datasets, Mallzee-popularity and SHIFT15m to assess the adequacy of MuQAR and also use the Amazon Reviews: Home and Kitchen dataset to assess generalisability to other domains. A comparative study on the VISUELLE dataset, shows that MuQAR is capable of competing and surpassing the domain's current state of the art by 2.88% in terms of WAPE and 3.04% in terms of MAE.
Differentially Private Federated Learning with Local Regularization and Sparsification
Mar 21, 2022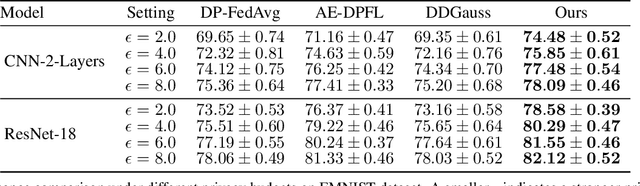
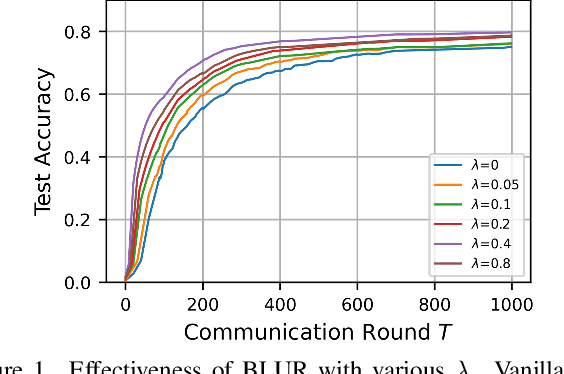
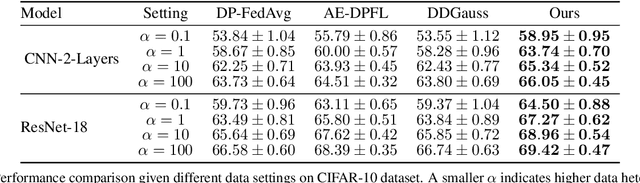
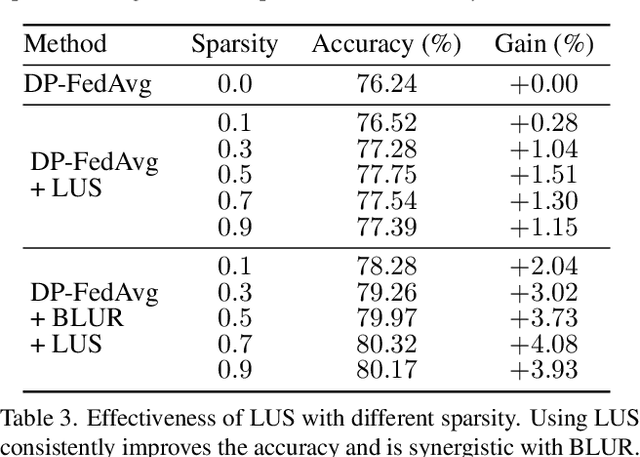
User-level differential privacy (DP) provides certifiable privacy guarantees to the information that is specific to any user's data in federated learning. Existing methods that ensure user-level DP come at the cost of severe accuracy decrease. In this paper, we study the cause of model performance degradation in federated learning under user-level DP guarantee. We find the key to solving this issue is to naturally restrict the norm of local updates before executing operations that guarantee DP. To this end, we propose two techniques, Bounded Local Update Regularization and Local Update Sparsification, to increase model quality without sacrificing privacy. We provide theoretical analysis on the convergence of our framework and give rigorous privacy guarantees. Extensive experiments show that our framework significantly improves the privacy-utility trade-off over the state-of-the-arts for federated learning with user-level DP guarantee.
Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment
Mar 31, 2022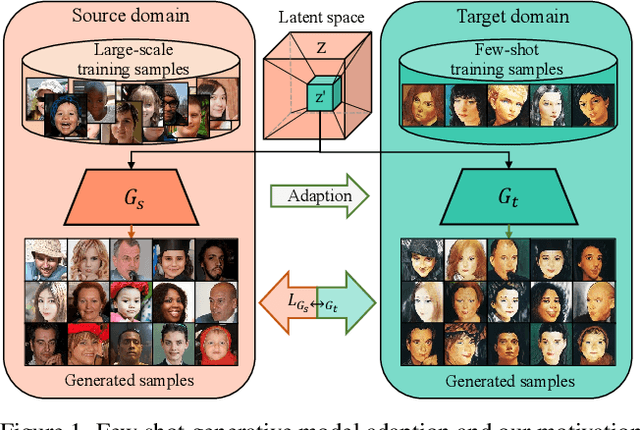
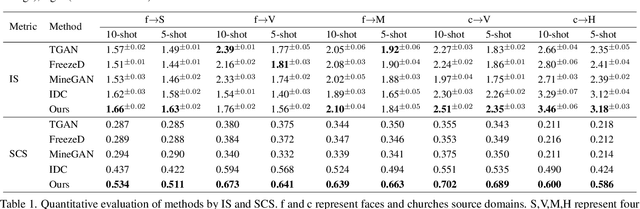
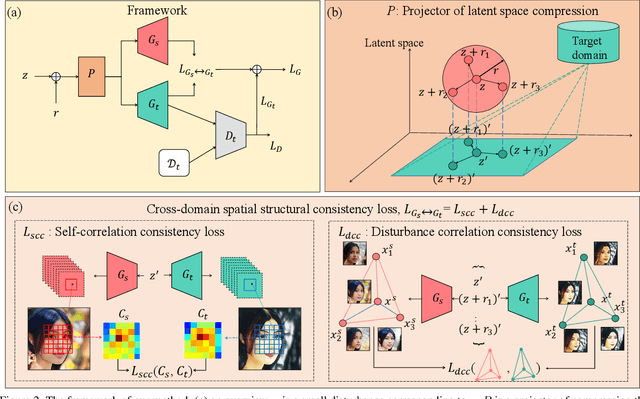

Training a generative adversarial network (GAN) with limited data has been a challenging task. A feasible solution is to start with a GAN well-trained on a large scale source domain and adapt it to the target domain with a few samples, termed as few shot generative model adaption. However, existing methods are prone to model overfitting and collapse in extremely few shot setting (less than 10). To solve this problem, we propose a relaxed spatial structural alignment method to calibrate the target generative models during the adaption. We design a cross-domain spatial structural consistency loss comprising the self-correlation and disturbance correlation consistency loss. It helps align the spatial structural information between the synthesis image pairs of the source and target domains. To relax the cross-domain alignment, we compress the original latent space of generative models to a subspace. Image pairs generated from the subspace are pulled closer. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.
AstBERT: Enabling Language Model for Code Understanding with Abstract Syntax Tree
Jan 20, 2022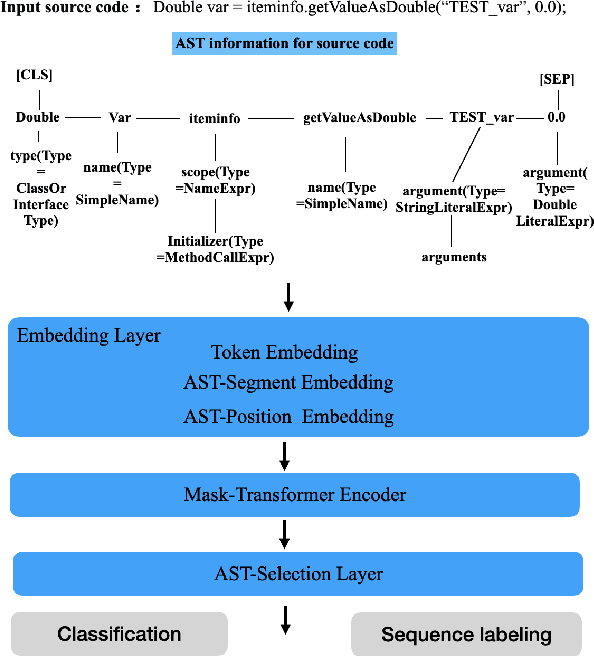


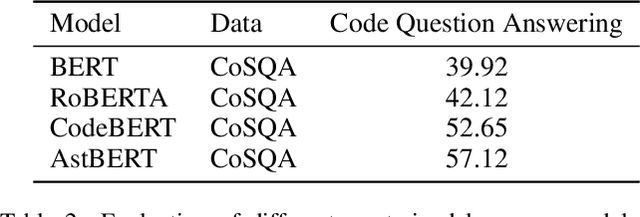
Using a pre-trained language model (i.e. BERT) to apprehend source codes has attracted increasing attention in the natural language processing community. However, there are several challenges when it comes to applying these language models to solve programming language (PL) related problems directly, the significant one of which is the lack of domain knowledge issue that substantially deteriorates the model's performance. To this end, we propose the AstBERT model, a pre-trained language model aiming to better understand the PL using the abstract syntax tree (AST). Specifically, we collect a colossal amount of source codes (both java and python) from GitHub and incorporate the contextual code knowledge into our model through the help of code parsers, in which AST information of the source codes can be interpreted and integrated. We verify the performance of the proposed model on code information extraction and code search tasks, respectively. Experiment results show that our AstBERT model achieves state-of-the-art performance on both downstream tasks (with 96.4% for code information extraction task, and 57.12% for code search task).
ESGBERT: Language Model to Help with Classification Tasks Related to Companies Environmental, Social, and Governance Practices
Mar 31, 2022
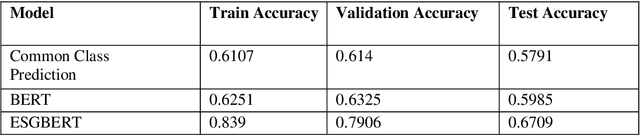
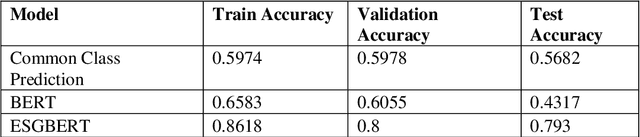
Environmental, Social, and Governance (ESG) are non-financial factors that are garnering attention from investors as they increasingly look to apply these as part of their analysis to identify material risks and growth opportunities. Some of this attention is also driven by clients who, now more aware than ever, are demanding for their money to be managed and invested responsibly. As the interest in ESG grows, so does the need for investors to have access to consumable ESG information. Since most of it is in text form in reports, disclosures, press releases, and 10-Q filings, we see a need for sophisticated NLP techniques for classification tasks for ESG text. We hypothesize that an ESG domain-specific pre-trained model will help with such and study building of the same in this paper. We explored doing this by fine-tuning BERTs pre-trained weights using ESG specific text and then further fine-tuning the model for a classification task. We were able to achieve accuracy better than the original BERT and baseline models in environment-specific classification tasks.
ChildPredictor: A Child Face Prediction Framework with Disentangled Learning
Apr 21, 2022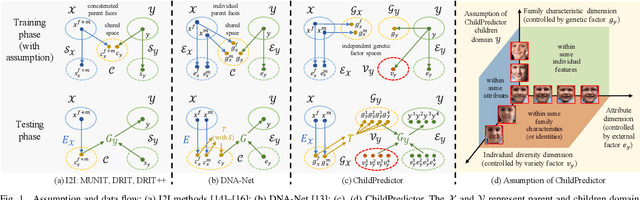

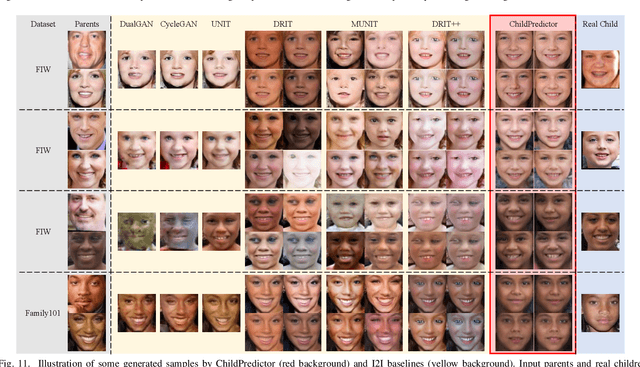

The appearances of children are inherited from their parents, which makes it feasible to predict them. Predicting realistic children's faces may help settle many social problems, such as age-invariant face recognition, kinship verification, and missing child identification. It can be regarded as an image-to-image translation task. Existing approaches usually assume domain information in the image-to-image translation can be interpreted by "style", i.e., the separation of image content and style. However, such separation is improper for the child face prediction, because the facial contours between children and parents are not the same. To address this issue, we propose a new disentangled learning strategy for children's face prediction. We assume that children's faces are determined by genetic factors (compact family features, e.g., face contour), external factors (facial attributes irrelevant to prediction, such as moustaches and glasses), and variety factors (individual properties for each child). On this basis, we formulate predictions as a mapping from parents' genetic factors to children's genetic factors, and disentangle them from external and variety factors. In order to obtain accurate genetic factors and perform the mapping, we propose a ChildPredictor framework. It transfers human faces to genetic factors by encoders and back by generators. Then, it learns the relationship between the genetic factors of parents and children through a mapping function. To ensure the generated faces are realistic, we collect a large Family Face Database to train ChildPredictor and evaluate it on the FF-Database validation set. Experimental results demonstrate that ChildPredictor is superior to other well-known image-to-image translation methods in predicting realistic and diverse child faces. Implementation codes can be found at https://github.com/zhaoyuzhi/ChildPredictor.
Is Surprisal in Issue Trackers Actionable?
Apr 15, 2022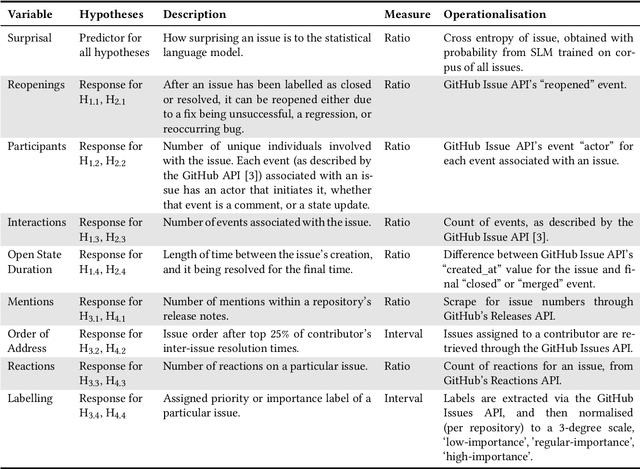
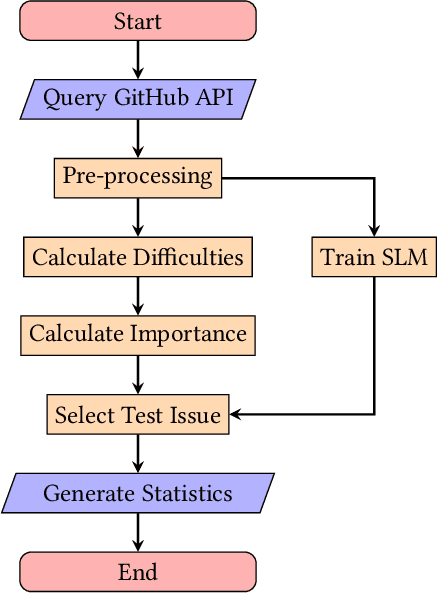
Background. From information theory, surprisal is a measurement of how unexpected an event is. Statistical language models provide a probabilistic approximation of natural languages, and because surprisal is constructed with the probability of an event occuring, it is therefore possible to determine the surprisal associated with English sentences. The issues and pull requests of software repository issue trackers give insight into the development process and likely contain the surprising events of this process. Objective. Prior works have identified that unusual events in software repositories are of interest to developers, and use simple code metrics-based methods for detecting them. In this study we will propose a new method for unusual event detection in software repositories using surprisal. With the ability to find surprising issues and pull requests, we intend to further analyse them to determine if they actually hold importance in a repository, or if they pose a significant challenge to address. If it is possible to find bad surprises early, or before they cause additional troubles, it is plausible that effort, cost and time will be saved as a result. Method. After extracting the issues and pull requests from 5000 of the most popular software repositories on GitHub, we will train a language model to represent these issues. We will measure their perceived importance in the repository, measure their resolution difficulty using several analogues, measure the surprisal of each, and finally generate inferential statistics to describe any correlations.
Audio-visual multi-channel speech separation, dereverberation and recognition
Apr 08, 2022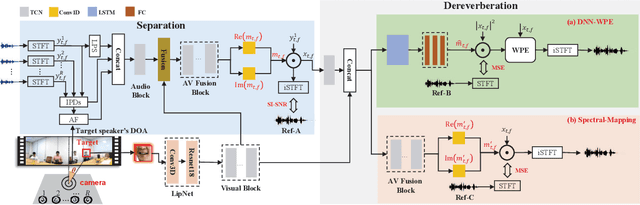

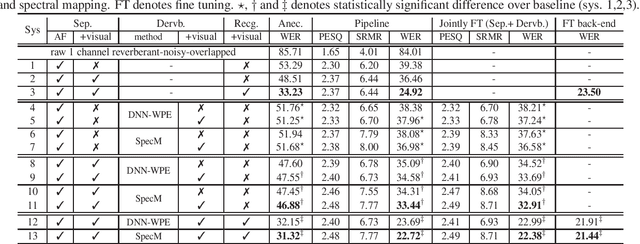
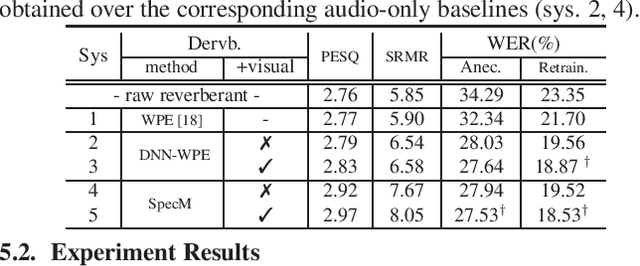
Despite the rapid advance of automatic speech recognition (ASR) technologies, accurate recognition of cocktail party speech characterised by the interference from overlapping speakers, background noise and room reverberation remains a highly challenging task to date. Motivated by the invariance of visual modality to acoustic signal corruption, audio-visual speech enhancement techniques have been developed, although predominantly targeting overlapping speech separation and recognition tasks. In this paper, an audio-visual multi-channel speech separation, dereverberation and recognition approach featuring a full incorporation of visual information into all three stages of the system is proposed. The advantage of the additional visual modality over using audio only is demonstrated on two neural dereverberation approaches based on DNN-WPE and spectral mapping respectively. The learning cost function mismatch between the separation and dereverberation models and their integration with the back-end recognition system is minimised using fine-tuning on the MSE and LF-MMI criteria. Experiments conducted on the LRS2 dataset suggest that the proposed audio-visual multi-channel speech separation, dereverberation and recognition system outperforms the baseline audio-visual multi-channel speech separation and recognition system containing no dereverberation module by a statistically significant word error rate (WER) reduction of 2.06% absolute (8.77% relative).
Target Confusion in End-to-end Speaker Extraction: Analysis and Approaches
Apr 04, 2022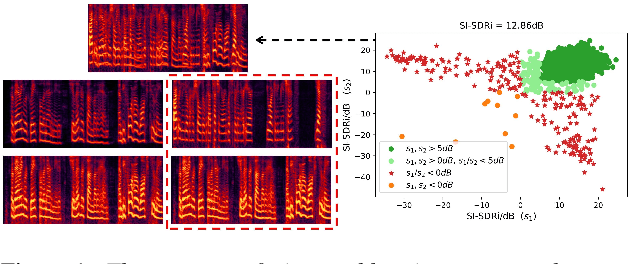
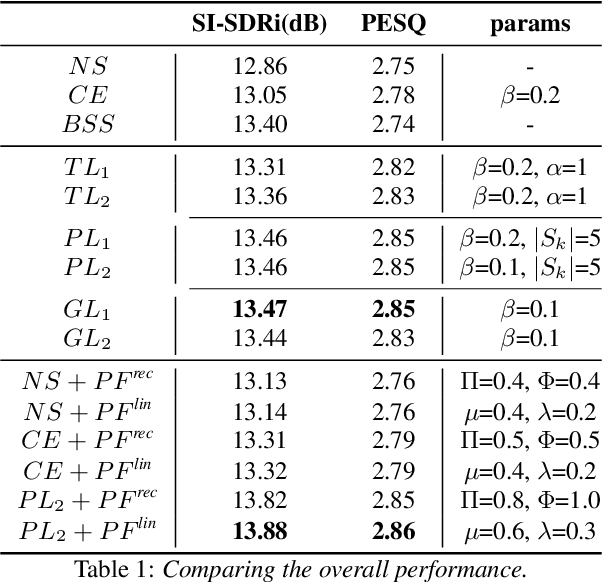

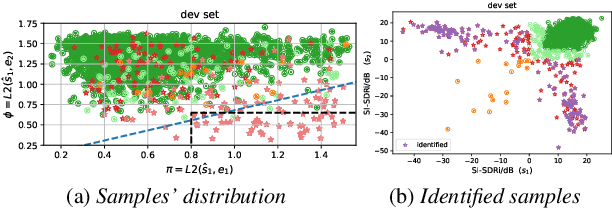
Recently, end-to-end speaker extraction has attracted increasing attention and shown promising results. However, its performance is often inferior to that of a blind source separation (BSS) counterpart with a similar network architecture, due to the auxiliary speaker encoder may sometimes generate ambiguous speaker embeddings. Such ambiguous guidance information may confuse the separation network and hence lead to wrong extraction results, which deteriorates the overall performance. We refer to this as the target confusion problem. In this paper, we conduct an analysis of such an issue and solve it in two stages. In the training phase, we propose to integrate metric learning methods to improve the distinguishability of embeddings produced by the speaker encoder. While for inference, a novel post-filtering strategy is designed to revise the wrong results. Specifically, we first identify these confusion samples by measuring the similarities between output estimates and enrollment utterances, after which the true target sources are recovered by a subtraction operation. Experiments show that performance improvement of more than 1dB SI-SDRi can be brought, which validates the effectiveness of our methods and emphasizes the impact of the target confusion problem.