 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unidirectional Video Denoising by Mimicking Backward Recurrent Modules with Look-ahead Forward Ones
Apr 12, 2022
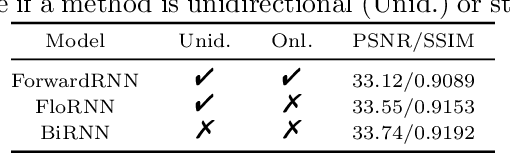
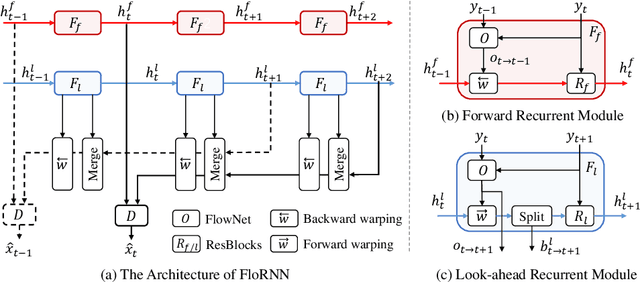

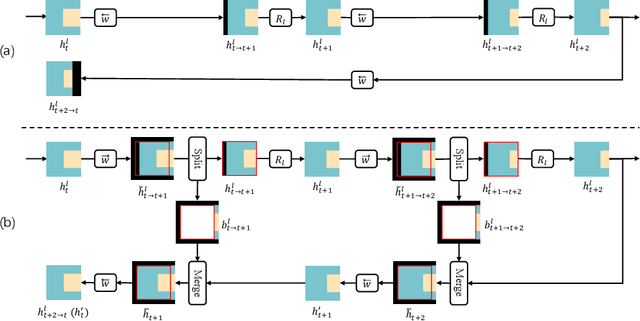
While significant progress has been made in deep video denoising, it remains very challenging for exploiting historical and future frames. Bidirectional recurrent networks (BiRNN) have exhibited appealing performance in several video restoration tasks. However, BiRNN is intrinsically offline because it uses backward recurrent modules to propagate from the last to current frames, which causes high latency and large memory consumption. To address the offline issue of BiRNN, we present a novel recurrent network consisting of forward and look-ahead recurrent modules for unidirectional video denoising. Particularly, look-ahead module is an elaborate forward module for leveraging information from near-future frames. When denoising the current frame, the hidden features by forward and look-ahead recurrent modules are combined, thereby making it feasible to exploit both historical and near-future frames. Due to the scene motion between non-neighboring frames, border pixels missing may occur when warping look-ahead feature from near-future frame to current frame, which can be largely alleviated by incorporating forward warping and border enlargement. Experiments show that our method achieves state-of-the-art performance with constant latency and memory consumption. The source code and pre-trained models will be publicly available.
Leveraging Temporal Information for 3D Detection and Domain Adaptation
Jun 30, 2020

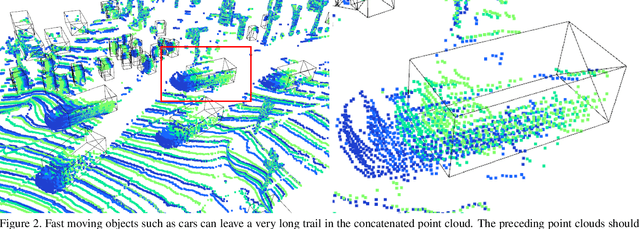
Ever since the prevalent use of the LiDARs in autonomous driving, tremendous improvements have been made to the learning on the point clouds. However, recent progress largely focuses on detecting objects in a single 360-degree sweep, without extensively exploring the temporal information. In this report, we describe a simple way to pass such information in the learning pipeline by adding timestamps to the point clouds, which shows consistent improvements across all three classes.
Information bottleneck through variational glasses
Dec 05, 2019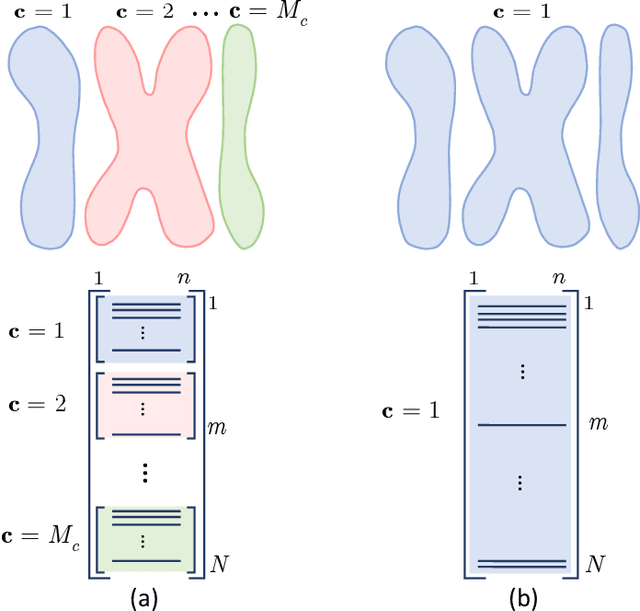
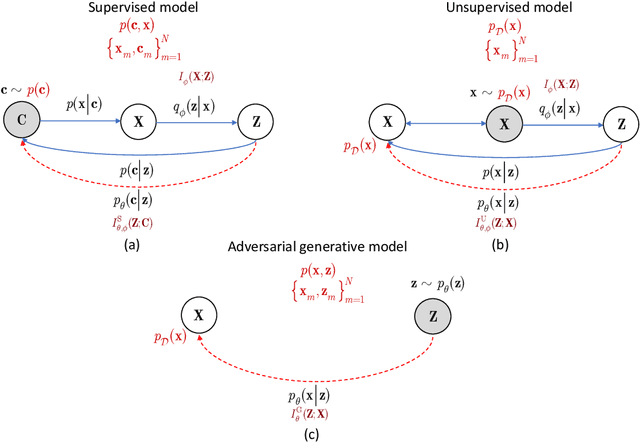
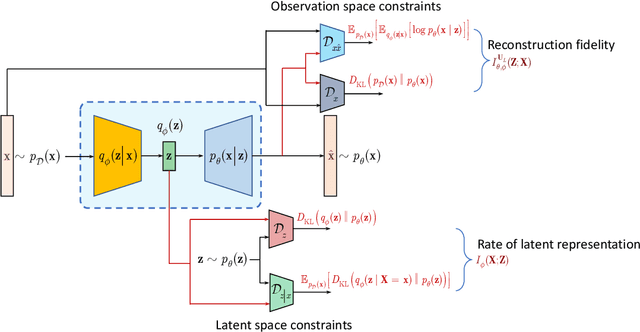
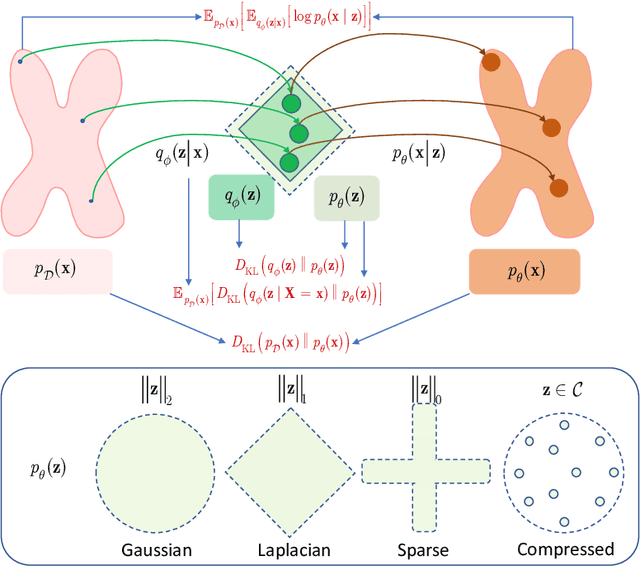
Information bottleneck (IB) principle [1] has become an important element in information-theoretic analysis of deep models. Many state-of-the-art generative models of both Variational Autoencoder (VAE) [2; 3] and Generative Adversarial Networks (GAN) [4] families use various bounds on mutual information terms to introduce certain regularization constraints [5; 6; 7; 8; 9; 10]. Accordingly, the main difference between these models consists in add regularization constraints and targeted objectives. In this work, we will consider the IB framework for three classes of models that include supervised, unsupervised and adversarial generative models. We will apply a variational decomposition leading a common structure and allowing easily establish connections between these models and analyze underlying assumptions. Based on these results, we focus our analysis on unsupervised setup and reconsider the VAE family. In particular, we present a new interpretation of VAE family based on the IB framework using a direct decomposition of mutual information terms and show some interesting connections to existing methods such as VAE [2; 3], beta-VAE [11], AAE [12], InfoVAE [5] and VAE/GAN [13]. Instead of adding regularization constraints to an evidence lower bound (ELBO) [2; 3], which itself is a lower bound, we show that many known methods can be considered as a product of variational decomposition of mutual information terms in the IB framework. The proposed decomposition might also contribute to the interpretability of generative models of both VAE and GAN families and create a new insights to a generative compression [14; 15; 16; 17]. It can also be of interest for the analysis of novelty detection based on one-class classifiers [18] with the IB based discriminators.
Sparse Tensor-based Point Cloud Attribute Compression
Apr 03, 2022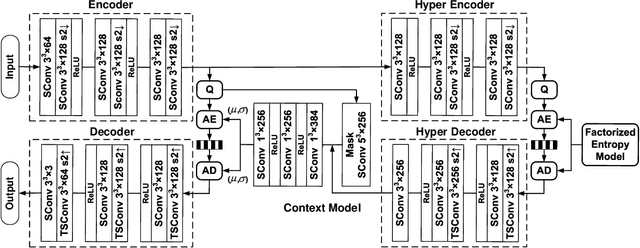


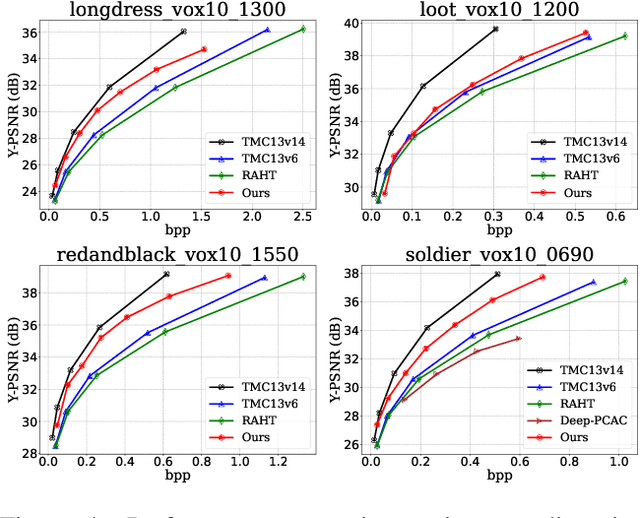
Recently, numerous learning-based compression methods have been developed with outstanding performance for the coding of the geometry information of point clouds. On the contrary, limited explorations have been devoted to point cloud attribute compression (PCAC). Thus, this study focuses on the PCAC by applying sparse convolution because of its superior efficiency for representing the geometry of unorganized points. The proposed method simply stacks sparse convolutions to construct the variational autoencoder (VAE) framework to compress the color attributes of a given point cloud. To better encode latent elements at the bottleneck, we apply the adaptive entropy model with the joint utilization of hyper prior and autoregressive neighbors to accurately estimate the bit rate. The qualitative measurement of the proposed method already rivals the latest G-PCC (or TMC13) version 14 at a similar bit rate. And, our method shows clear quantitative improvements to G-PCC version 6, and largely outperforms existing learning-based methods, which promises encouraging potentials for learnt PCAC.
GCN-FFNN: A Two-Stream Deep Model for Learning Solution to Partial Differential Equations
Apr 28, 2022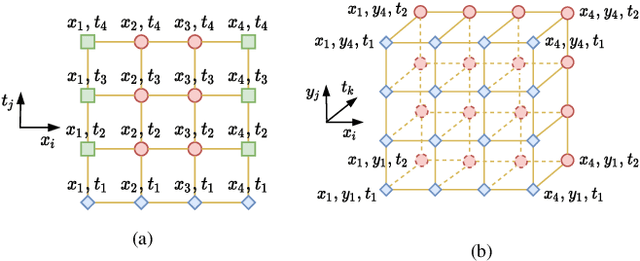
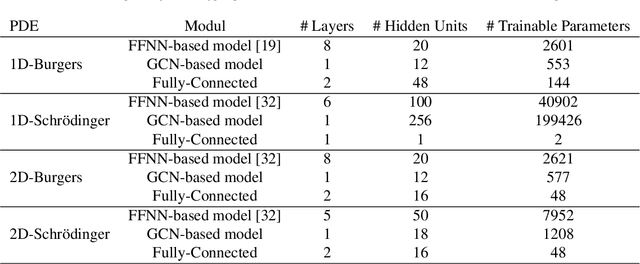
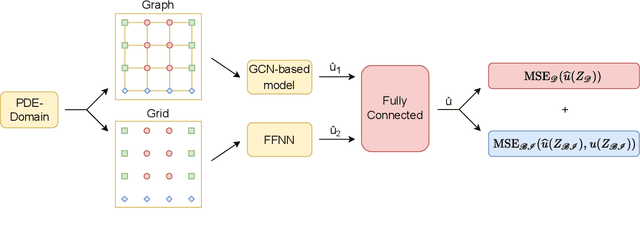
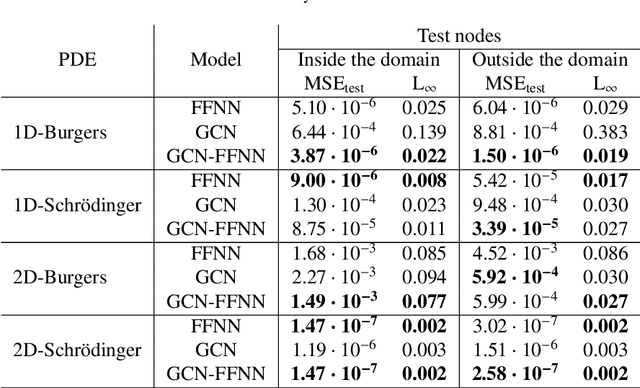
This paper introduces a novel two-stream deep model based on graph convolutional network (GCN) architecture and feed-forward neural networks (FFNN) for learning the solution of nonlinear partial differential equations (PDEs). The model aims at incorporating both graph and grid input representations using two streams corresponding to GCN and FFNN models, respectively. Each stream layer receives and processes its own input representation. As opposed to FFNN which receives a grid-like structure, the GCN stream layer operates on graph input data where the neighborhood information is incorporated through the adjacency matrix of the graph. In this way, the proposed GCN-FFNN model learns from two types of input representations, i.e. grid and graph data, obtained via the discretization of the PDE domain. The GCN-FFNN model is trained in two phases. In the first phase, the model parameters of each stream are trained separately. Both streams employ the same error function to adjust their parameters by enforcing the models to satisfy the given PDE as well as its initial and boundary conditions on grid or graph collocation (training) data. In the second phase, the learned parameters of two-stream layers are frozen and their learned representation solutions are fed to fully connected layers whose parameters are learned using the previously used error function. The learned GCN-FFNN model is tested on test data located both inside and outside the PDE domain. The obtained numerical results demonstrate the applicability and efficiency of the proposed GCN-FFNN model over individual GCN and FFNN models on 1D-Burgers, 1D-Schr\"odinger, 2D-Burgers and 2D-Schr\"odinger equations.
Semantic Line Detection Using Mirror Attention and Comparative Ranking and Matching
Mar 29, 2022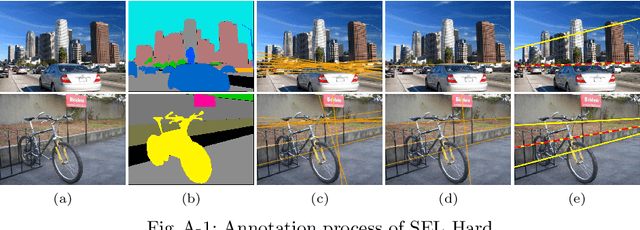



A novel algorithm to detect semantic lines is proposed in this paper. We develop three networks: detection network with mirror attention (D-Net) and comparative ranking and matching networks (R-Net and M-Net). D-Net extracts semantic lines by exploiting rich contextual information. To this end, we design the mirror attention module. Then, through pairwise comparisons of extracted semantic lines, we iteratively select the most semantic line and remove redundant ones overlapping with the selected one. For the pairwise comparisons, we develop R-Net and M-Net in the Siamese architecture. Experiments demonstrate that the proposed algorithm outperforms the conventional semantic line detector significantly. Moreover, we apply the proposed algorithm to detect two important kinds of semantic lines successfully: dominant parallel lines and reflection symmetry axes. Our codes are available at https://github.com/dongkwonjin/Semantic-Line-DRM.
Demystifying Self-Supervised Learning: An Information-Theoretical Framework
Jun 11, 2020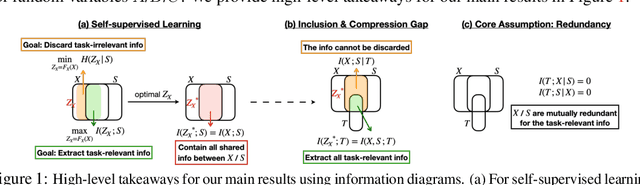
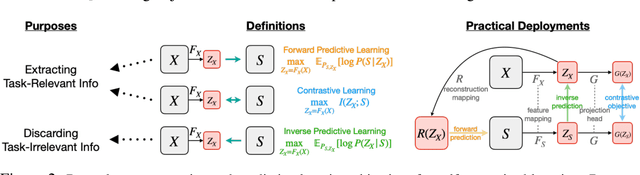
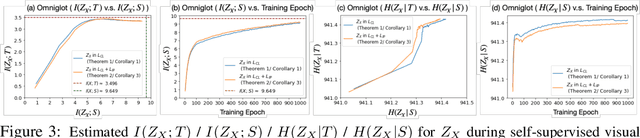

Self-supervised representation learning adopts self-defined signals as supervision and uses the learned representation for downstream tasks, such as masked language modeling (e.g., BERT) for natural language processing and contrastive visual representation learning (e.g., SimCLR) for computer vision applications. In this paper, we present a theoretical framework explaining that self-supervised learning is likely to work under the assumption that only the shared information (e.g., contextual information or content) between the input (e.g., non-masked words or original images) and self-supervised signals (e.g., masked-words or augmented images) contributes to downstream tasks. Under this assumption, we demonstrate that self-supervisedly learned representation can extract task-relevant and discard task-irrelevant information. We further connect our theoretical analysis to popular contrastive and predictive (self-supervised) learning objectives. In the experimental section, we provide controlled experiments on two popular tasks: 1) visual representation learning with various self-supervised learning objectives to empirically support our analysis; and 2) visual-textual representation learning to challenge that input and self-supervised signal lie in different modalities.
Bag of Visual Words (BoVW) with Deep Features -- Patch Classification Model for Limited Dataset of Breast Tumours
Feb 22, 2022
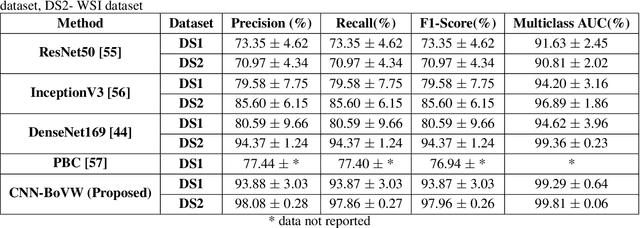
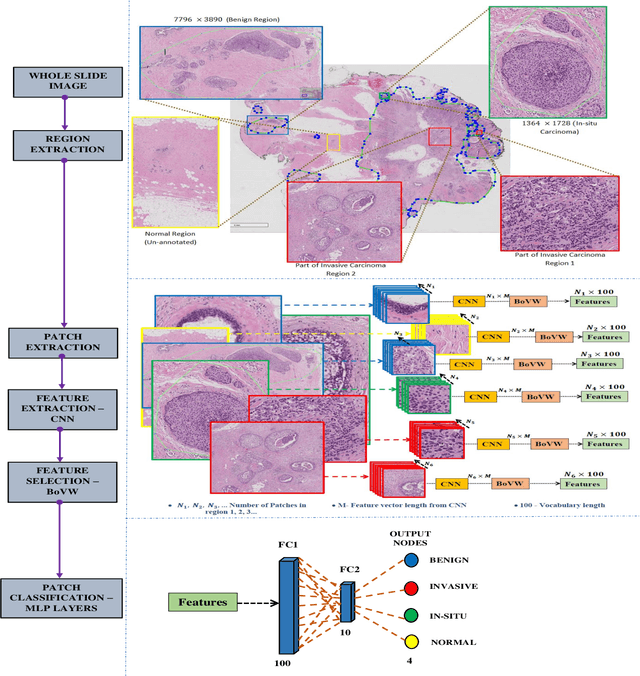
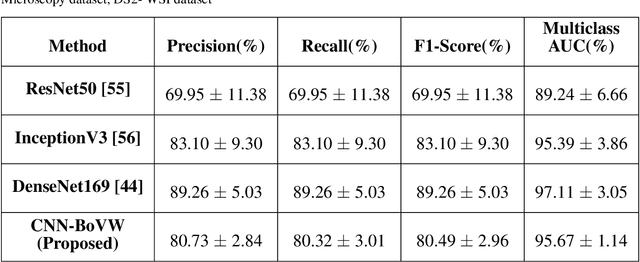
Currently, the computational complexity limits the training of high resolution gigapixel images using Convolutional Neural Networks. Therefore, such images are divided into patches or tiles. Since, these high resolution patches are encoded with discriminative information therefore; CNNs are trained on these patches to perform patch-level predictions. However, the problem with patch-level prediction is that pathologist generally annotates at image-level and not at patch level. Due to this limitation most of the patches may not contain enough class-relevant features. Through this work, we tried to incorporate patch descriptive capability within the deep framework by using Bag of Visual Words (BoVW) as a kind of regularisation to improve generalizability. Using this hypothesis, we aim to build a patch based classifier to discriminate between four classes of breast biopsy image patches (normal, benign, \textit{In situ} carcinoma, invasive carcinoma). The task is to incorporate quality deep features using CNN to describe relevant information in the images while simultaneously discarding irrelevant information using Bag of Visual Words (BoVW). The proposed method passes patches obtained from WSI and microscopy images through pre-trained CNN to extract features. BoVW is used as a feature selector to select most discriminative features among the CNN features. Finally, the selected feature sets are classified as one of the four classes. The hybrid model provides flexibility in terms of choice of pre-trained models for feature extraction. The pipeline is end-to-end since it does not require post processing of patch predictions to select discriminative patches. We compared our observations with state-of-the-art methods like ResNet50, DenseNet169, and InceptionV3 on the BACH-2018 challenge dataset. Our proposed method shows better performance than all the three methods.
Impact Intensity Estimation of a Quadruped Robot without Using a Force Sensor
Apr 03, 2022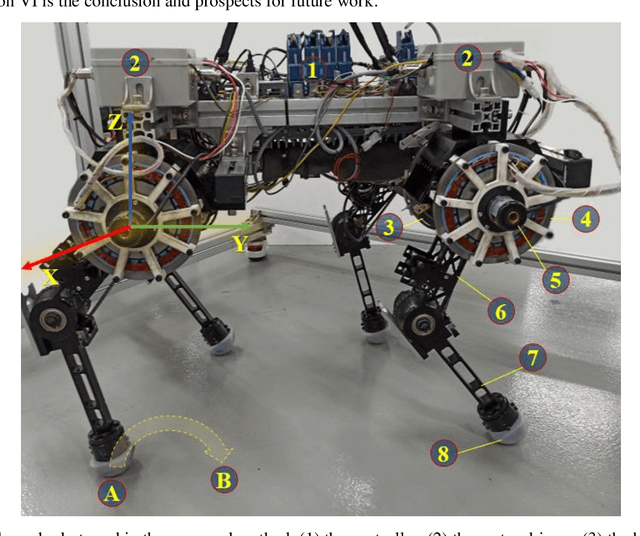
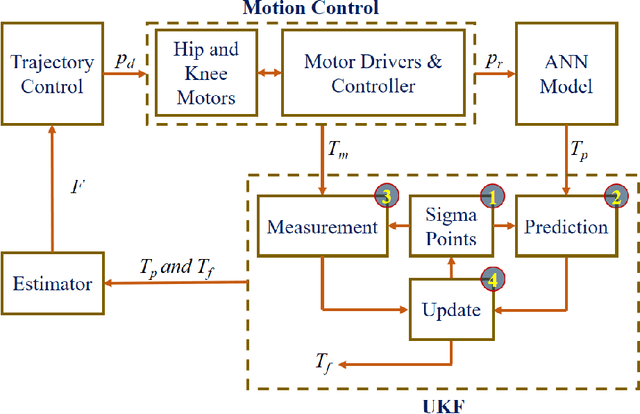
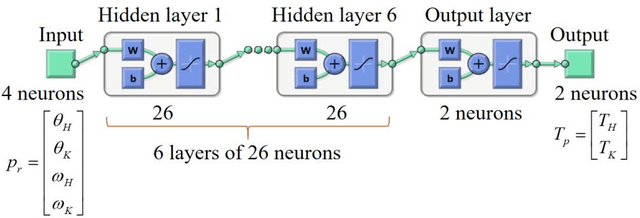
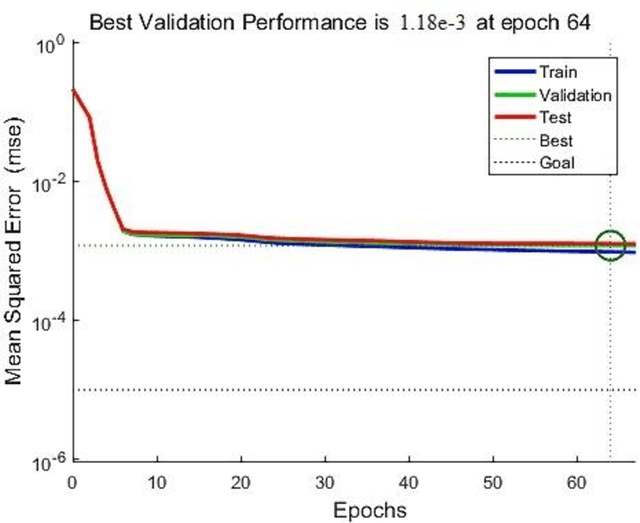
Estimating the impact intensity is one of the significant tasks of the legged robot. Accurate feedback of the impact may support the robot to plan a suitable and efficient trajectory to adapt to unknown complex terrains. Ordinarily, this task is performed by a force sensor in the robot's foot. In this letter, an impact intensity estimation without using a force sensor is proposed. An artificial neural network model is designed to predict the motor torques of the legs in an instantaneous position in the trajectory without utilizing the complex kinematic and dynamic models of motion. An unscented Kalman filter is used during the trajectory to smooth and stabilize the measurement. Based on the difference between the predicted information and the filtered value, the state and intensity of the robot foot's impact with the obstacles are estimated. The simulation and experiment on a quadruped robot are carried out to verify the effectiveness of the proposed method.
Improving English to Sinhala Neural Machine Translation using Part-of-Speech Tag
Feb 17, 2022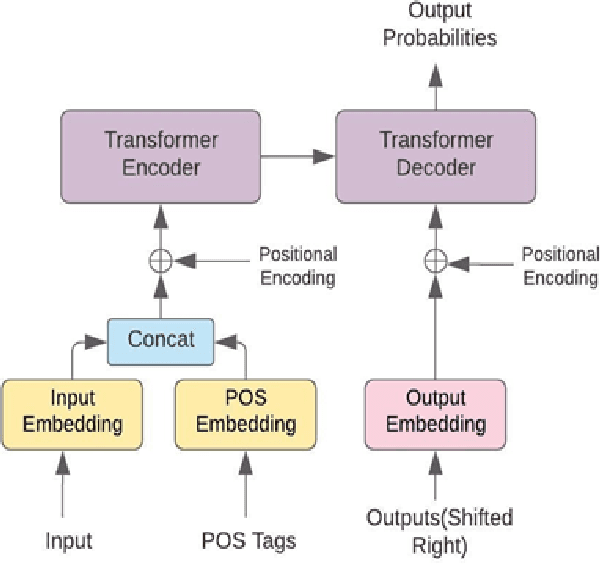
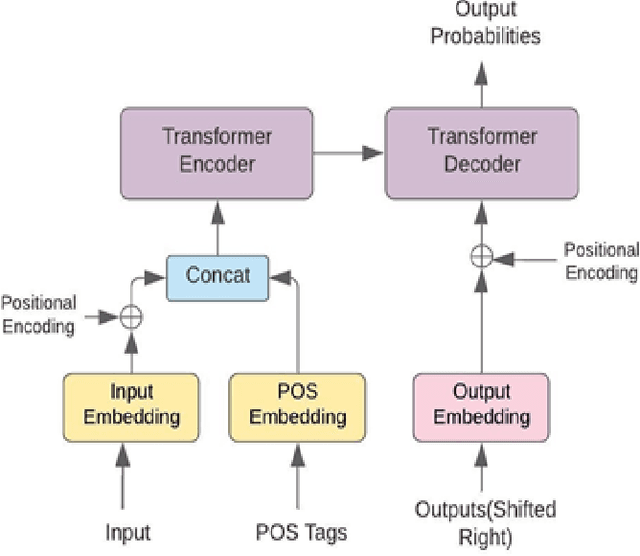
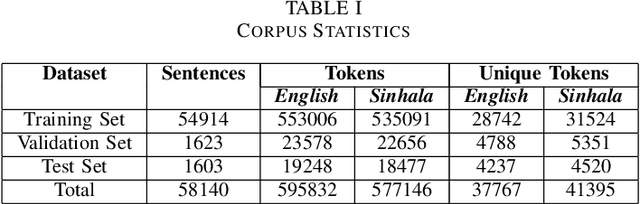
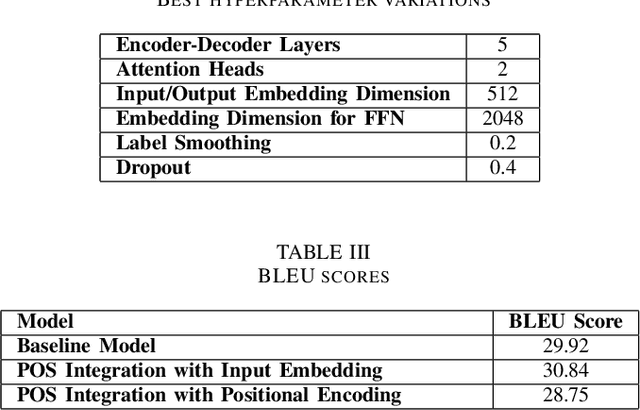
The performance of Neural Machine Translation (NMT) depends significantly on the size of the available parallel corpus. Due to this fact, low resource language pairs demonstrate low translation performance compared to high resource language pairs. The translation quality further degrades when NMT is performed for morphologically rich languages. Even though the web contains a large amount of information, most people in Sri Lanka are unable to read and understand English properly. Therefore, there is a huge requirement of translating English content to local languages to share information among locals. Sinhala language is the primary language in Sri Lanka and building an NMT system that can produce quality English to Sinhala translations is difficult due to the syntactic divergence between these two languages under low resource constraints. Thus, in this research, we explore effective methods of incorporating Part of Speech (POS) tags to the Transformer input embedding and positional encoding to further enhance the performance of the baseline English to Sinhala neural machine translation model.