 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization
Jan 23, 2022

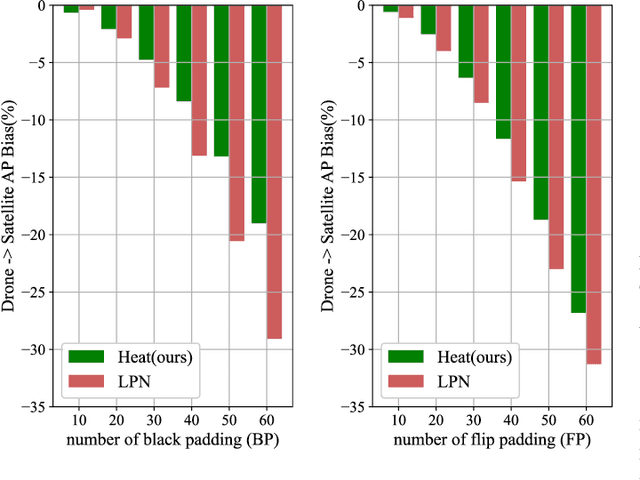
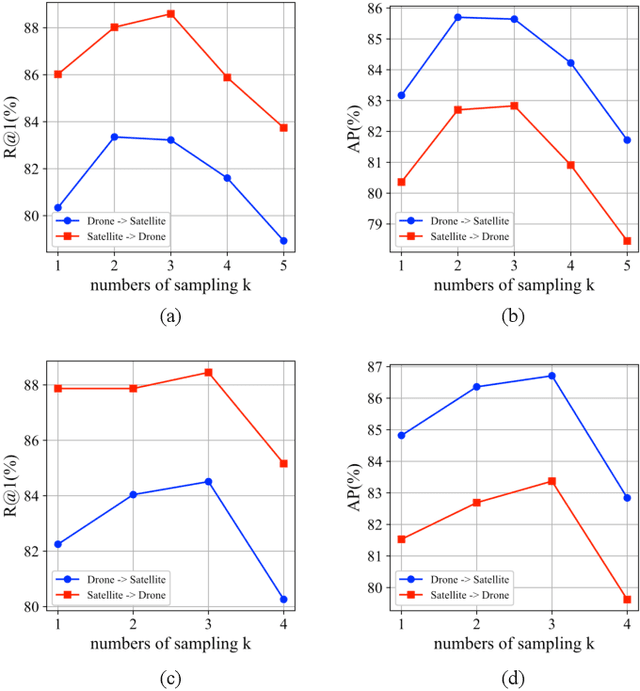
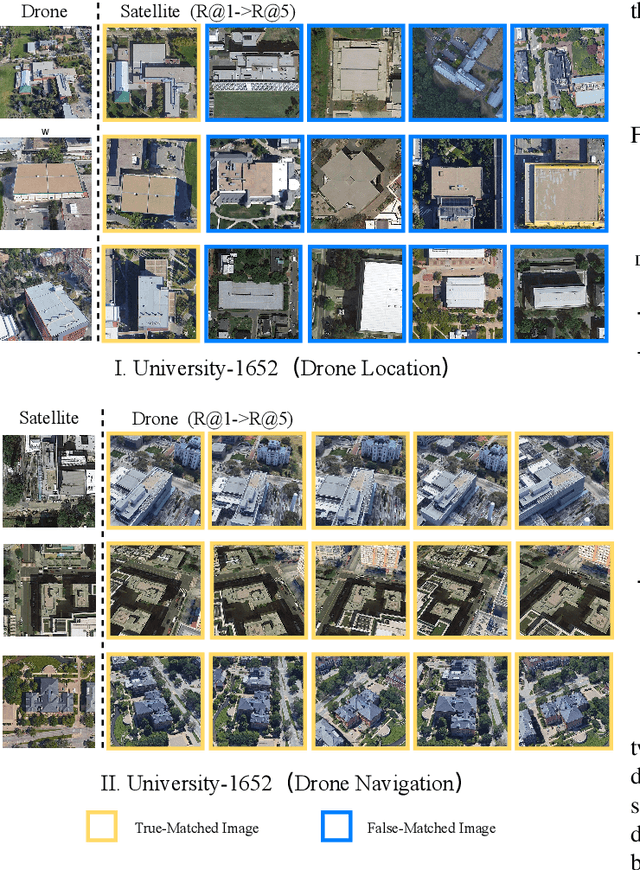
Cross-view geo-localization is a task of matching the same geographic image from different views, e.g., unmanned aerial vehicle (UAV) and satellite. The most difficult challenges are the position shift and the uncertainty of distance and scale. Existing methods are mainly aimed at digging for more comprehensive fine-grained information. However, it underestimates the importance of extracting robust feature representation and the impact of feature alignment. The CNN-based methods have achieved great success in cross-view geo-localization. However it still has some limitations, e.g., it can only extract part of the information in the neighborhood and some scale reduction operations will make some fine-grained information lost. In particular, we introduce a simple and efficient transformer-based structure called Feature Segmentation and Region Alignment (FSRA) to enhance the model's ability to understand contextual information as well as to understand the distribution of instances. Without using additional supervisory information, FSRA divides regions based on the heat distribution of the transformer's feature map, and then aligns multiple specific regions in different views one on one. Finally, FSRA integrates each region into a set of feature representations. The difference is that FSRA does not divide regions manually, but automatically based on the heat distribution of the feature map. So that specific instances can still be divided and aligned when there are significant shifts and scale changes in the image. In addition, a multiple sampling strategy is proposed to overcome the disparity in the number of satellite images and that of images from other sources. Experiments show that the proposed method has superior performance and achieves the state-of-the-art in both tasks of drone view target localization and drone navigation. Code will be released at https://github.com/Dmmm1997/FSRA
Demystifying Deep Learning in Predictive Spatio-Temporal Analytics: An Information-Theoretic Framework
Sep 17, 2020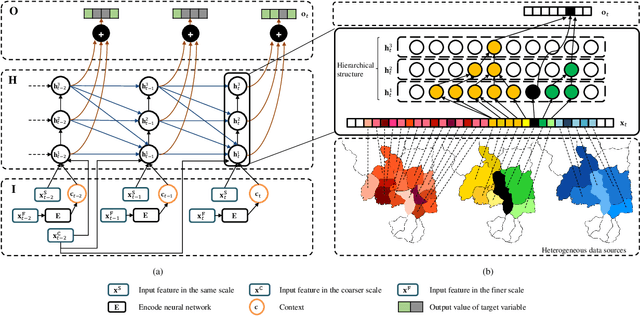
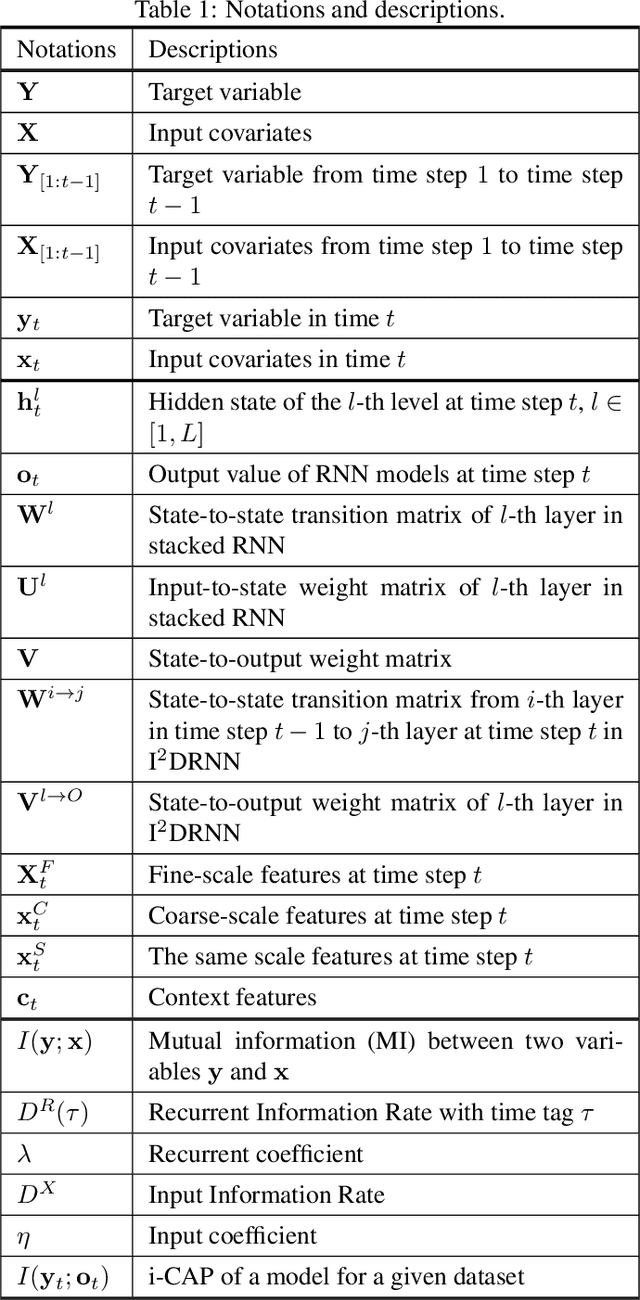
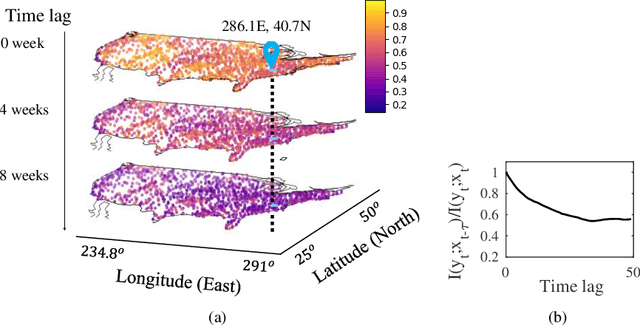
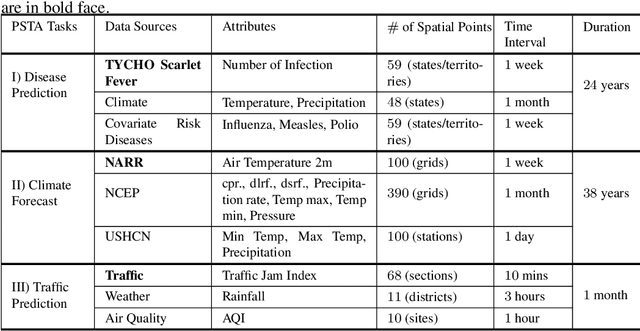
Deep learning has achieved incredible success over the past years, especially in various challenging predictive spatio-temporal analytics (PSTA) tasks, such as disease prediction, climate forecast, and traffic prediction, where intrinsic dependency relationships among data exist and generally manifest at multiple spatio-temporal scales. However, given a specific PSTA task and the corresponding dataset, how to appropriately determine the desired configuration of a deep learning model, theoretically analyze the model's learning behavior, and quantitatively characterize the model's learning capacity remains a mystery. In order to demystify the power of deep learning for PSTA, in this paper, we provide a comprehensive framework for deep learning model design and information-theoretic analysis. First, we develop and demonstrate a novel interactively- and integratively-connected deep recurrent neural network (I$^2$DRNN) model. I$^2$DRNN consists of three modules: an Input module that integrates data from heterogeneous sources; a Hidden module that captures the information at different scales while allowing the information to flow interactively between layers; and an Output module that models the integrative effects of information from various hidden layers to generate the output predictions. Second, to theoretically prove that our designed model can learn multi-scale spatio-temporal dependency in PSTA tasks, we provide an information-theoretic analysis to examine the information-based learning capacity (i-CAP) of the proposed model. Third, to validate the I$^2$DRNN model and confirm its i-CAP, we systematically conduct a series of experiments involving both synthetic datasets and real-world PSTA tasks. The experimental results show that the I$^2$DRNN model outperforms both classical and state-of-the-art models, and is able to capture meaningful multi-scale spatio-temporal dependency.
KCD: Knowledge Walks and Textual Cues Enhanced Political Perspective Detection in News Media
Apr 08, 2022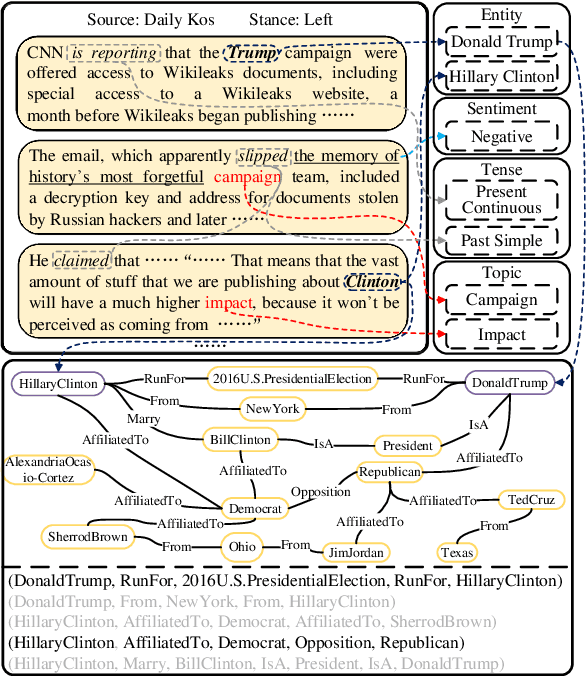
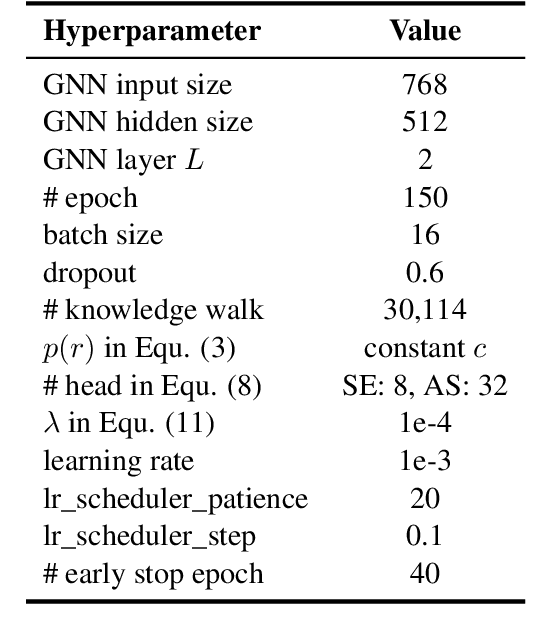
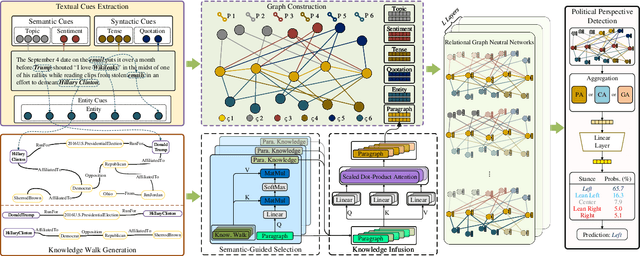
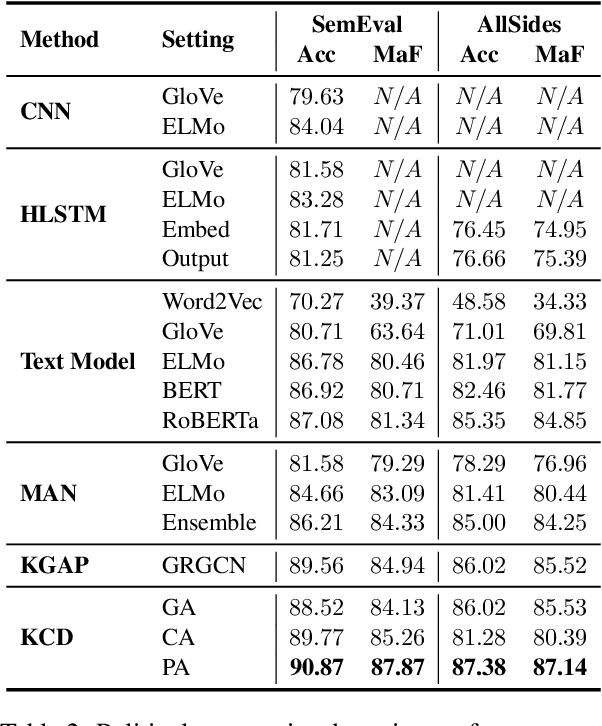
Political perspective detection has become an increasingly important task that can help combat echo chambers and political polarization. Previous approaches generally focus on leveraging textual content to identify stances, while they fail to reason with background knowledge or leverage the rich semantic and syntactic textual labels in news articles. In light of these limitations, we propose KCD, a political perspective detection approach to enable multi-hop knowledge reasoning and incorporate textual cues as paragraph-level labels. Specifically, we firstly generate random walks on external knowledge graphs and infuse them with news text representations. We then construct a heterogeneous information network to jointly model news content as well as semantic, syntactic and entity cues in news articles. Finally, we adopt relational graph neural networks for graph-level representation learning and conduct political perspective detection. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods on two benchmark datasets. We further examine the effect of knowledge walks and textual cues and how they contribute to our approach's data efficiency.
A Review on Methods and Applications in Multimodal Deep Learning
Feb 18, 2022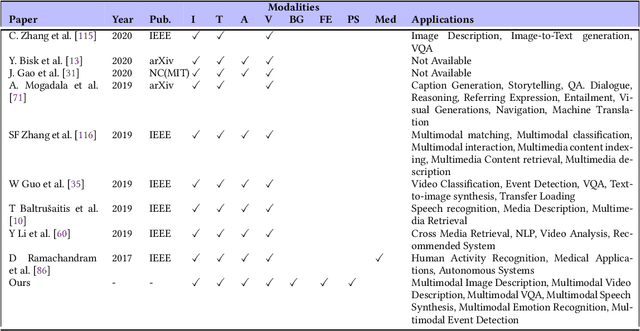
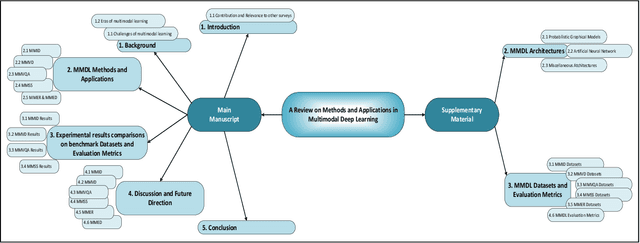
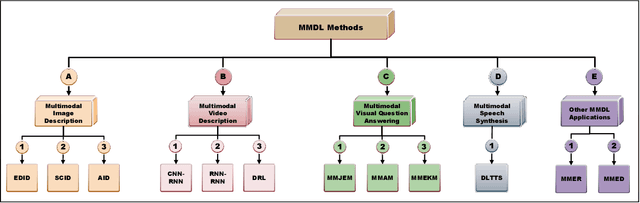
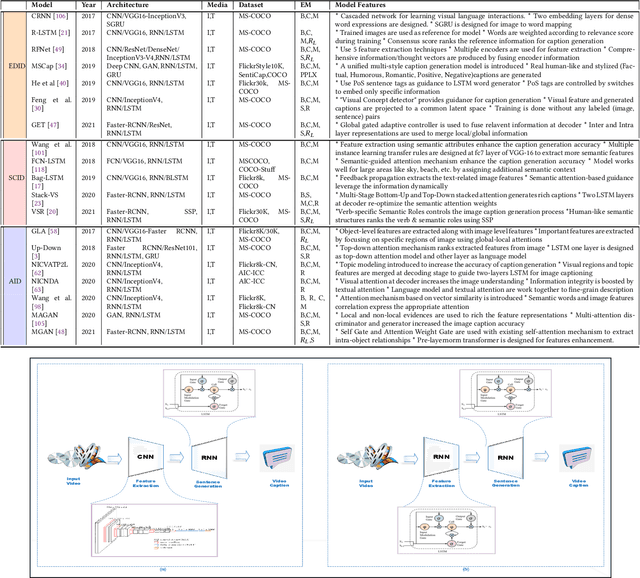
Deep Learning has implemented a wide range of applications and has become increasingly popular in recent years. The goal of multimodal deep learning (MMDL) is to create models that can process and link information using various modalities. Despite the extensive development made for unimodal learning, it still cannot cover all the aspects of human learning. Multimodal learning helps to understand and analyze better when various senses are engaged in the processing of information. This paper focuses on multiple types of modalities, i.e., image, video, text, audio, body gestures, facial expressions, and physiological signals. Detailed analysis of the baseline approaches and an in-depth study of recent advancements during the last five years (2017 to 2021) in multimodal deep learning applications has been provided. A fine-grained taxonomy of various multimodal deep learning methods is proposed, elaborating on different applications in more depth. Lastly, main issues are highlighted separately for each domain, along with their possible future research directions.
* 29 pages. arXiv admin note: substantial text overlap with arXiv:2105.11087
Multi-view and Multi-modal Event Detection Utilizing Transformer-based Multi-sensor fusion
Feb 18, 2022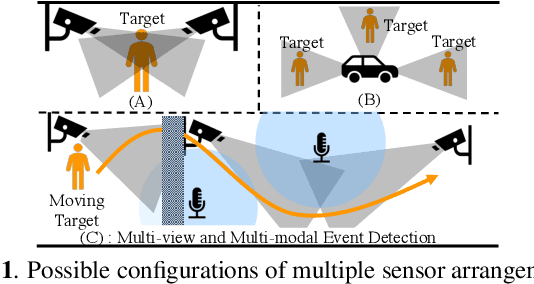
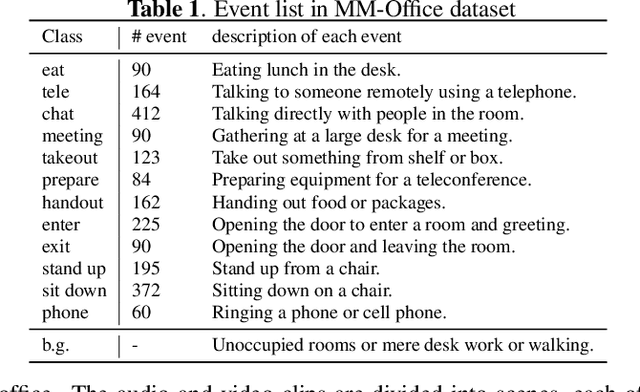
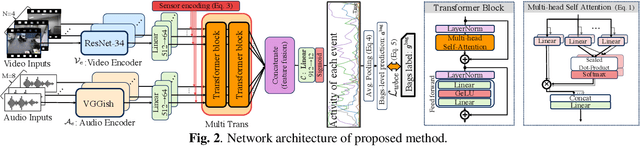
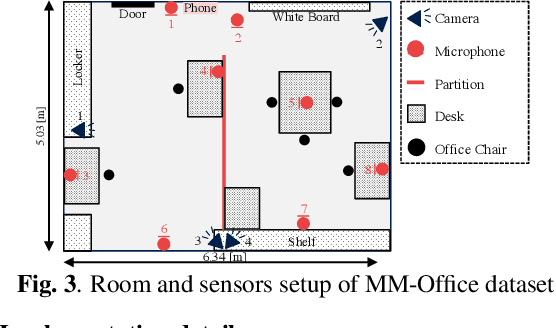
We tackle a challenging task: multi-view and multi-modal event detection that detects events in a wide-range real environment by utilizing data from distributed cameras and microphones and their weak labels. In this task, distributed sensors are utilized complementarily to capture events that are difficult to capture with a single sensor, such as a series of actions of people moving in an intricate room, or communication between people located far apart in a room. For sensors to cooperate effectively in such a situation, the system should be able to exchange information among sensors and combines information that is useful for identifying events in a complementary manner. For such a mechanism, we propose a Transformer-based multi-sensor fusion (MultiTrans) which combines multi-sensor data on the basis of the relationships between features of different viewpoints and modalities. In the experiments using a dataset newly collected for this task, our proposed method using MultiTrans improved the event detection performance and outperformed comparatives.
Generative Forensics: Procedural Generation and Information Games
Apr 03, 2020


Procedural generation is used across game design to achieve a wide variety of ends, and has led to the creation of several game subgenres by injecting variance, surprise or unpredictability into otherwise static designs. Information games are a type of mystery game in which the player is tasked with gathering knowledge and developing an understanding of an event or system. Their reliance on player knowledge leaves them vulnerable to spoilers and hard to replay. In this paper we introduce the notion of generative forensics games, a subgenre of information games that challenge the player to understand the output of a generative system. We introduce information games, show how generative forensics develops the idea, report on two prototype games we created, and evaluate our work on generative forensics so far from a player and a designer perspective.
Exploiting Multiple EEG Data Domains with Adversarial Learning
Apr 16, 2022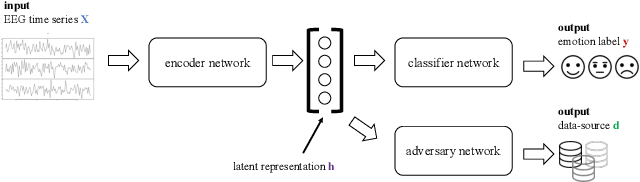
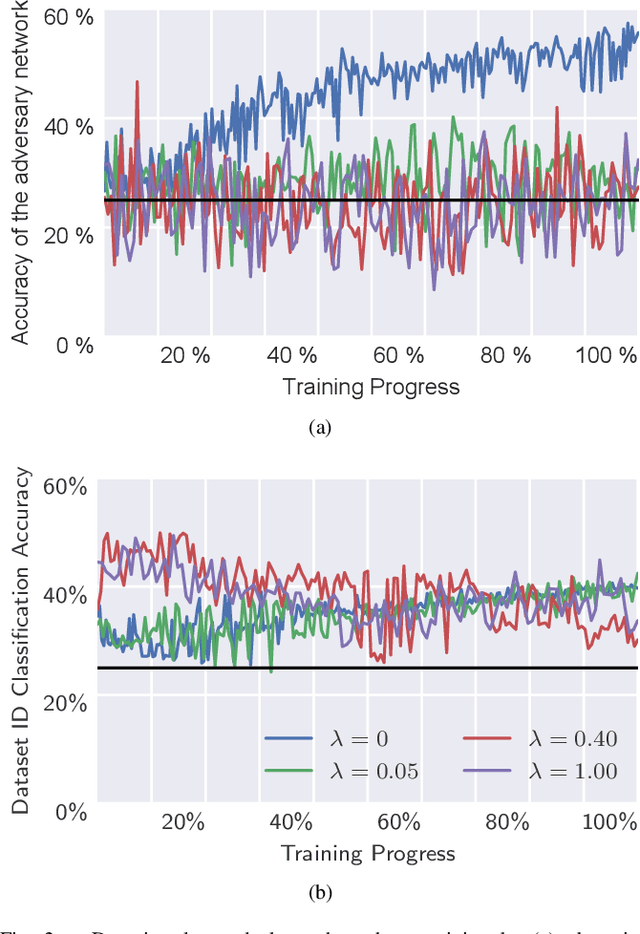
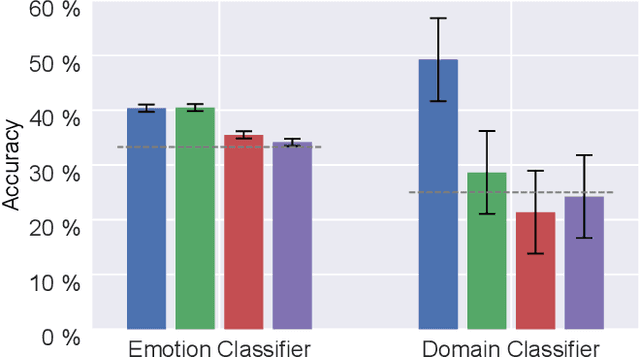
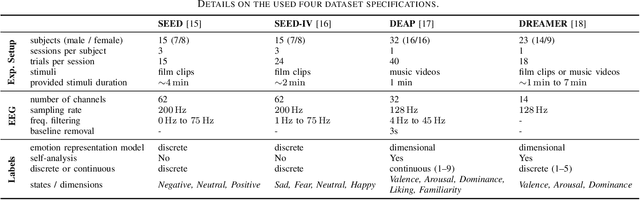
Electroencephalography (EEG) is shown to be a valuable data source for evaluating subjects' mental states. However, the interpretation of multi-modal EEG signals is challenging, as they suffer from poor signal-to-noise-ratio, are highly subject-dependent, and are bound to the equipment and experimental setup used, (i.e. domain). This leads to machine learning models often suffer from poor generalization ability, where they perform significantly worse on real-world data than on the exploited training data. Recent research heavily focuses on cross-subject and cross-session transfer learning frameworks to reduce domain calibration efforts for EEG signals. We argue that multi-source learning via learning domain-invariant representations from multiple data-sources is a viable alternative, as the available data from different EEG data-source domains (e.g., subjects, sessions, experimental setups) grow massively. We propose an adversarial inference approach to learn data-source invariant representations in this context, enabling multi-source learning for EEG-based brain-computer interfaces. We unify EEG recordings from different source domains (i.e., emotion recognition datasets SEED, SEED-IV, DEAP, DREAMER), and demonstrate the feasibility of our invariant representation learning approach in suppressing data-source-relevant information leakage by 35% while still achieving stable EEG-based emotion classification performance.
Adaptive Cross-Attention-Driven Spatial-Spectral Graph Convolutional Network for Hyperspectral Image Classification
Apr 12, 2022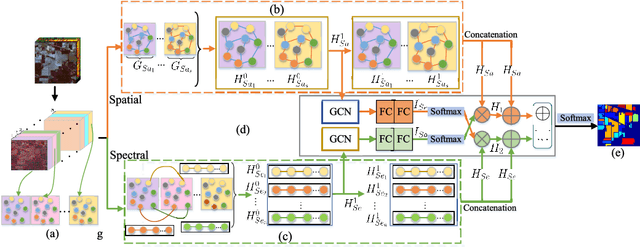
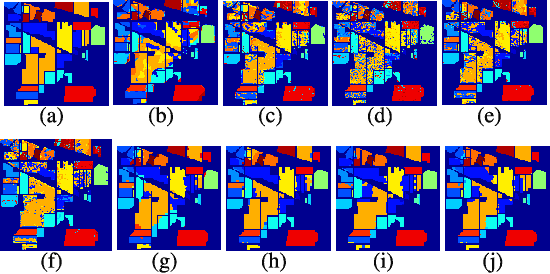
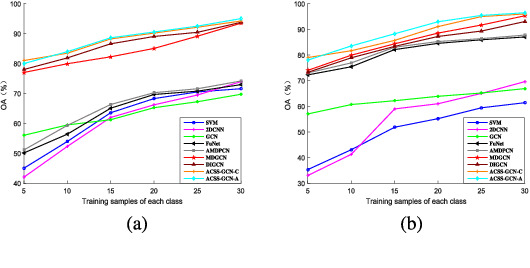
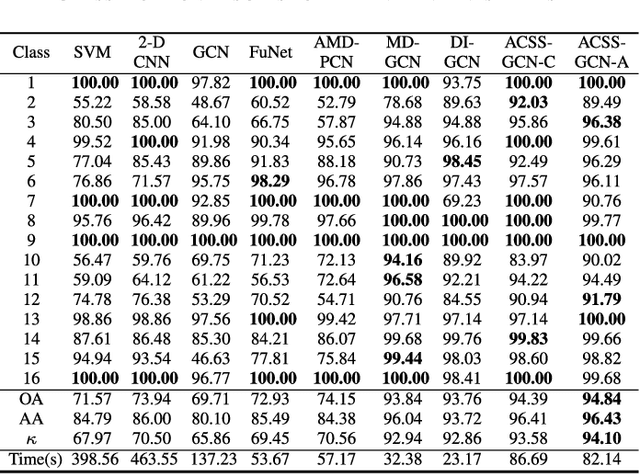
Recently, graph convolutional networks (GCNs) have been developed to explore spatial relationship between pixels, achieving better classification performance of hyperspectral images (HSIs). However, these methods fail to sufficiently leverage the relationship between spectral bands in HSI data. As such, we propose an adaptive cross-attention-driven spatial-spectral graph convolutional network (ACSS-GCN), which is composed of a spatial GCN (Sa-GCN) subnetwork, a spectral GCN (Se-GCN) subnetwork, and a graph cross-attention fusion module (GCAFM). Specifically, Sa-GCN and Se-GCN are proposed to extract the spatial and spectral features by modeling correlations between spatial pixels and between spectral bands, respectively. Then, by integrating attention mechanism into information aggregation of graph, the GCAFM, including three parts, i.e., spatial graph attention block, spectral graph attention block, and fusion block, is designed to fuse the spatial and spectral features and suppress noise interference in Sa-GCN and Se-GCN. Moreover, the idea of the adaptive graph is introduced to explore an optimal graph through back propagation during the training process. Experiments on two HSI data sets show that the proposed method achieves better performance than other classification methods.
A Decomposition-Based Hybrid Ensemble CNN Framework for Improving Cross-Subject EEG Decoding Performance
Mar 14, 2022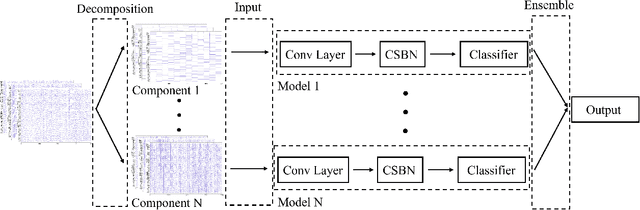
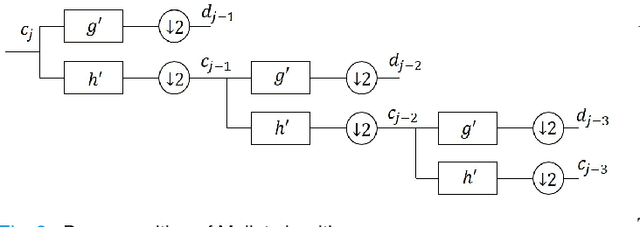
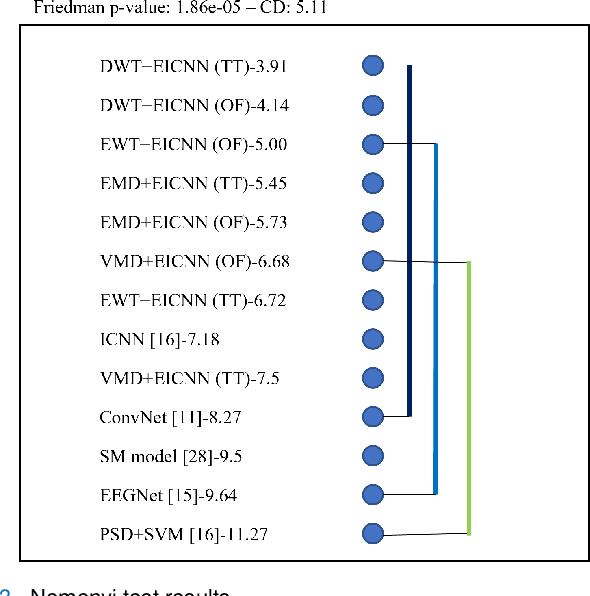
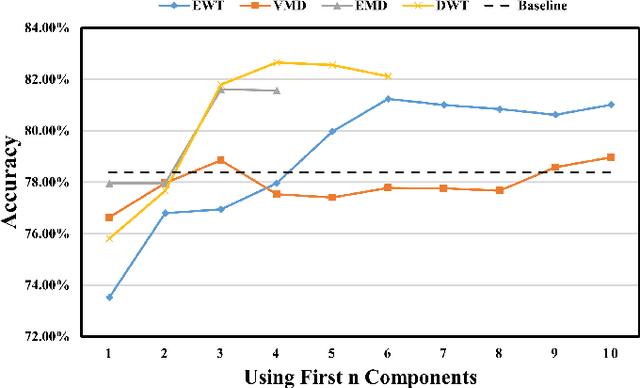
Electroencephalogram (EEG) signals are complex, non-linear, and non-stationary in nature. However, previous studies that applied decomposition to minimize the complexity mainly exploited the hand-engineering features, limiting the information learned in EEG decoding. Therefore, extracting additional primary features from different disassembled components to improve the EEG-based recognition performance remains challenging. On the other hand, attempts have been made to use a single model to learn the hand-engineering features. Less work has been done to improve the generalization ability through ensemble learning. In this work, we propose a novel decomposition-based hybrid ensemble convolutional neural network (CNN) framework to enhance the capability of decoding EEG signals. CNNs, in particular, automatically learn the primary features from raw disassembled components but not handcraft features. The first option is to fuse the obtained score before the Softmax layer and execute back-propagation on the entire ensemble network, whereas the other is to fuse the probability output of the Softmax layer. Moreover, a component-specific batch normalization (CSBN) layer is employed to reduce subject variability. Against the challenging cross-subject driver fatigue-related situation awareness (SA) recognition task, eight models are proposed under the framework, which all showed superior performance than the strong baselines. The performance of different decomposition methods and ensemble modes were further compared. Results indicated that discrete wavelet transform (DWT)-based ensemble CNN achieves the best 82.11% among the proposed models. Our framework can be simply extended to any CNN architecture and applied in any EEG-related sectors, opening the possibility of extracting more preliminary information from complex EEG data.
Deep Polarimetric HDR Reconstruction
Mar 27, 2022
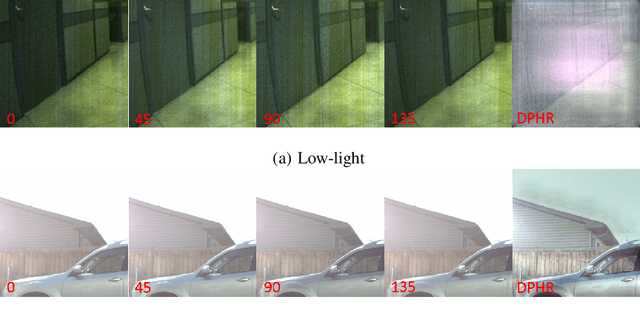
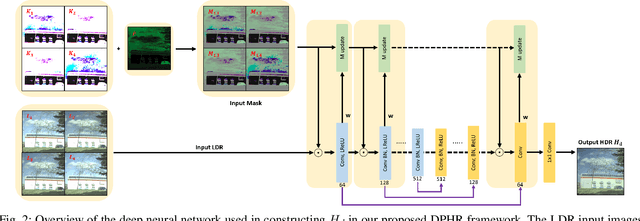
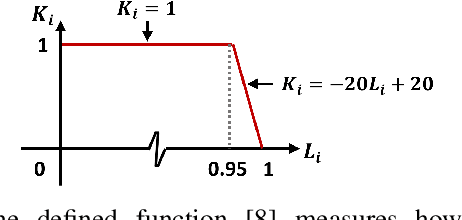
This paper proposes a novel learning based high-dynamic-range (HDR) reconstruction method using a polarization camera. We utilize a previous observation that polarization filters with different orientations can attenuate natural light differently, and we treat the multiple images acquired by the polarization camera as a set acquired under different exposure times, to introduce the development of solutions for the HDR reconstruction problem. We propose a deep HDR reconstruction framework with a feature masking mechanism that uses polarimetric cues available from the polarization camera, called Deep Polarimetric HDR Reconstruction (DPHR). The proposed DPHR obtains polarimetric information to propagate valid features through the network more effectively to regress the missing pixels. We demonstrate through both qualitative and quantitative evaluations that the proposed DPHR performs favorably than state-of-the-art HDR reconstruction algorithms.