 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SimMC: Simple Masked Contrastive Learning of Skeleton Representations for Unsupervised Person Re-Identification
Apr 21, 2022
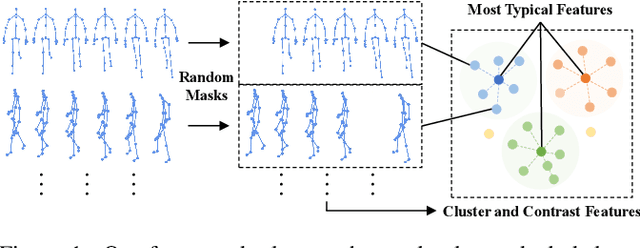
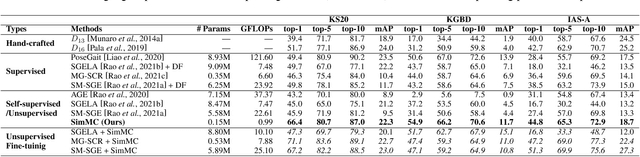
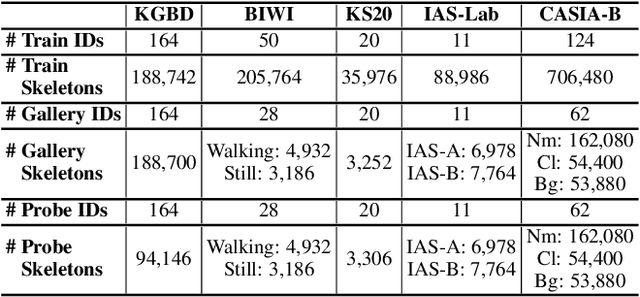
Recent advances in skeleton-based person re-identification (re-ID) obtain impressive performance via either hand-crafted skeleton descriptors or skeleton representation learning with deep learning paradigms. However, they typically require skeletal pre-modeling and label information for training, which leads to limited applicability of these methods. In this paper, we focus on unsupervised skeleton-based person re-ID, and present a generic Simple Masked Contrastive learning (SimMC) framework to learn effective representations from unlabeled 3D skeletons for person re-ID. Specifically, to fully exploit skeleton features within each skeleton sequence, we first devise a masked prototype contrastive learning (MPC) scheme to cluster the most typical skeleton features (skeleton prototypes) from different subsequences randomly masked from raw sequences, and contrast the inherent similarity between skeleton features and different prototypes to learn discriminative skeleton representations without using any label. Then, considering that different subsequences within the same sequence usually enjoy strong correlations due to the nature of motion continuity, we propose the masked intra-sequence contrastive learning (MIC) to capture intra-sequence pattern consistency between subsequences, so as to encourage learning more effective skeleton representations for person re-ID. Extensive experiments validate that the proposed SimMC outperforms most state-of-the-art skeleton-based methods. We further show its scalability and efficiency in enhancing the performance of existing models. Our codes are available at https://github.com/Kali-Hac/SimMC.
A Performance-Consistent and Computation-Efficient CNN System for High-Quality Automated Brain Tumor Segmentation
May 02, 2022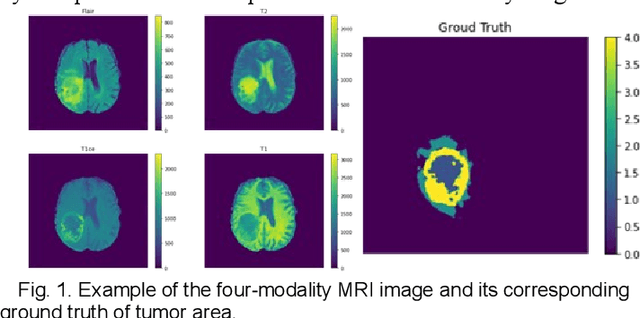
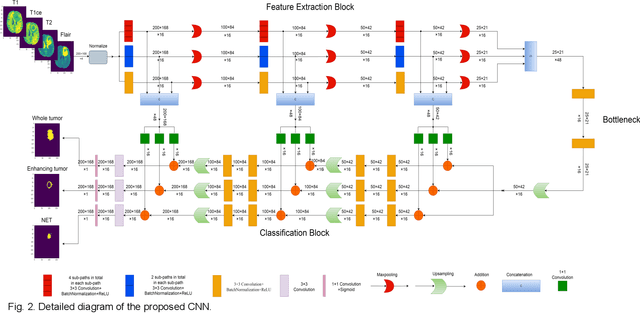
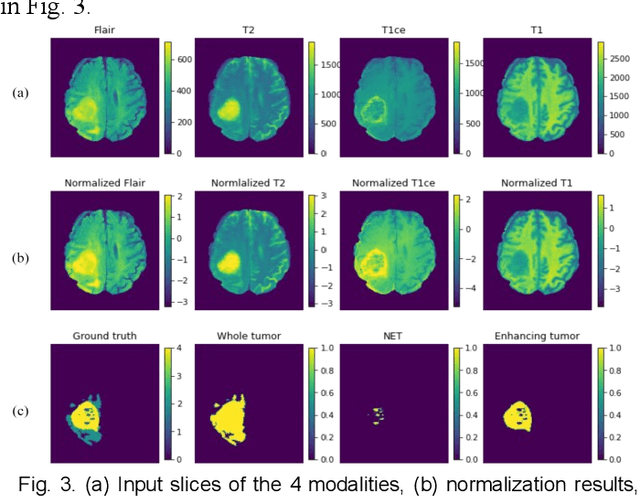
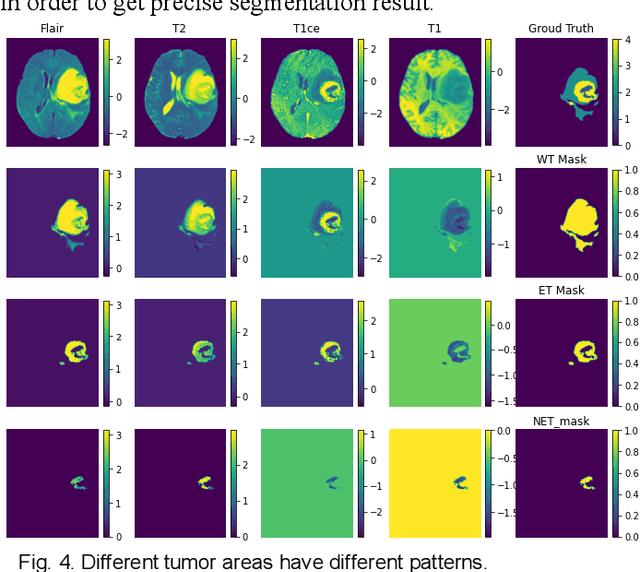
The research on developing CNN-based fully-automated Brain-Tumor-Segmentation systems has been progressed rapidly. For the systems to be applicable in practice, a good The research on developing CNN-based fully-automated Brain-Tumor-Segmentation systems has been progressed rapidly. For the systems to be applicable in practice, a good processing quality and reliability are the must. Moreover, for wide applications of such systems, a minimization of computation complexity is desirable, which can also result in a minimization of randomness in computation and, consequently, a better performance consistency. To this end, the CNN in the proposed system has a unique structure with 2 distinguished characters. Firstly, the three paths of its feature extraction block are designed to extract, from the multi-modality input, comprehensive feature information of mono-modality, paired-modality and cross-modality data, respectively. Also, it has a particular three-branch classification block to identify the pixels of 4 classes. Each branch is trained separately so that the parameters are updated specifically with the corresponding ground truth data of a target tumor areas. The convolution layers of the system are custom-designed with specific purposes, resulting in a very simple config of 61,843 parameters in total. The proposed system is tested extensively with BraTS2018 and BraTS2019 datasets. The mean Dice scores, obtained from the ten experiments on BraTS2018 validation samples, are 0.787+0.003, 0.886+0.002, 0.801+0.007, for enhancing tumor, whole tumor and tumor core, respectively, and 0.751+0.007, 0.885+0.002, 0.776+0.004 on BraTS2019. The test results demonstrate that the proposed system is able to perform high-quality segmentation in a consistent manner. Furthermore, its extremely low computation complexity will facilitate its implementation/application in various environments.
Leverage Your Local and Global Representations: A New Self-Supervised Learning Strategy
Apr 13, 2022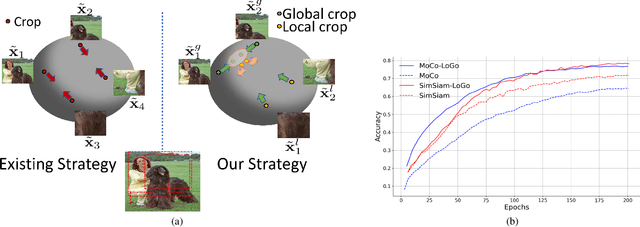
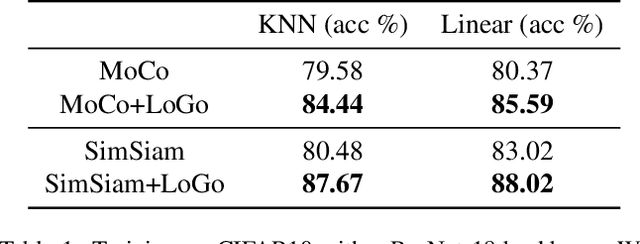
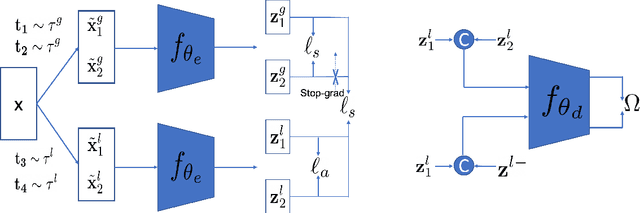
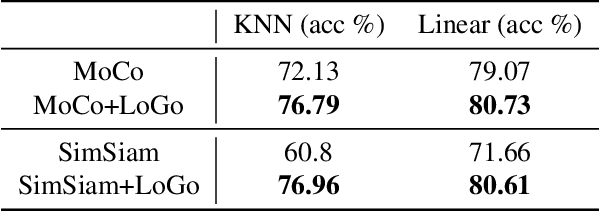
Self-supervised learning (SSL) methods aim to learn view-invariant representations by maximizing the similarity between the features extracted from different crops of the same image regardless of cropping size and content. In essence, this strategy ignores the fact that two crops may truly contain different image information, e.g., background and small objects, and thus tends to restrain the diversity of the learned representations. In this work, we address this issue by introducing a new self-supervised learning strategy, LoGo, that explicitly reasons about Local and Global crops. To achieve view invariance, LoGo encourages similarity between global crops from the same image, as well as between a global and a local crop. However, to correctly encode the fact that the content of smaller crops may differ entirely, LoGo promotes two local crops to have dissimilar representations, while being close to global crops. Our LoGo strategy can easily be applied to existing SSL methods. Our extensive experiments on a variety of datasets and using different self-supervised learning frameworks validate its superiority over existing approaches. Noticeably, we achieve better results than supervised models on transfer learning when using only 1/10 of the data.
Federated Learning with Position-Aware Neurons
Apr 02, 2022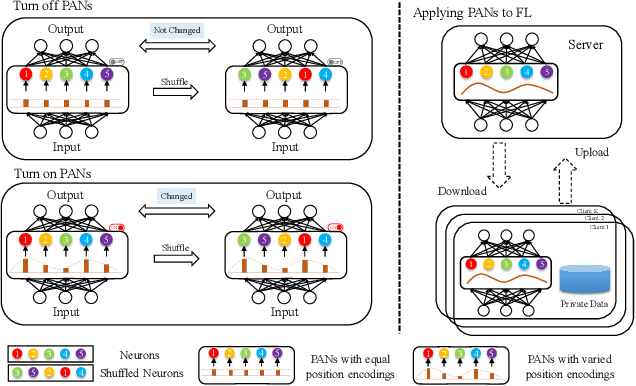

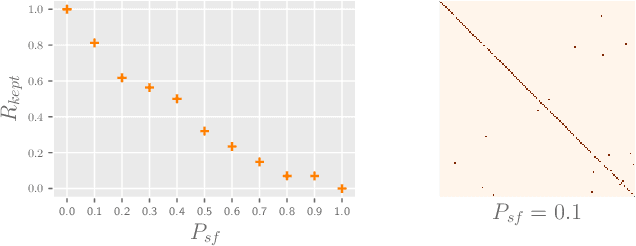
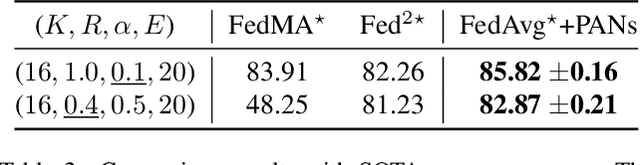
Federated Learning (FL) fuses collaborative models from local nodes without centralizing users' data. The permutation invariance property of neural networks and the non-i.i.d. data across clients make the locally updated parameters imprecisely aligned, disabling the coordinate-based parameter averaging. Traditional neurons do not explicitly consider position information. Hence, we propose Position-Aware Neurons (PANs) as an alternative, fusing position-related values (i.e., position encodings) into neuron outputs. PANs couple themselves to their positions and minimize the possibility of dislocation, even updating on heterogeneous data. We turn on/off PANs to disable/enable the permutation invariance property of neural networks. PANs are tightly coupled with positions when applied to FL, making parameters across clients pre-aligned and facilitating coordinate-based parameter averaging. PANs are algorithm-agnostic and could universally improve existing FL algorithms. Furthermore, "FL with PANs" is simple to implement and computationally friendly.
Low-rank features based double transformation matrices learning for image classification
Feb 17, 2022Linear regression is a supervised method that has been widely used in classification tasks. In order to apply linear regression to classification tasks, a technique for relaxing regression targets was proposed. However, methods based on this technique ignore the pressure on a single transformation matrix due to the complex information contained in the data. A single transformation matrix in this case is too strict to provide a flexible projection, thus it is necessary to adopt relaxation on transformation matrix. This paper proposes a double transformation matrices learning method based on latent low-rank feature extraction. The core idea is to use double transformation matrices for relaxation, and jointly projecting the learned principal and salient features from two directions into the label space, which can share the pressure of a single transformation matrix. Firstly, the low-rank features are learned by the latent low rank representation (LatLRR) method which processes the original data from two directions. In this process, sparse noise is also separated, which alleviates its interference on projection learning to some extent. Then, two transformation matrices are introduced to process the two features separately, and the information useful for the classification is extracted. Finally, the two transformation matrices can be easily obtained by alternate optimization methods. Through such processing, even when a large amount of redundant information is contained in samples, our method can also obtain projection results that are easy to classify. Experiments on multiple data sets demonstrate the effectiveness of our approach for classification, especially for complex scenarios.
Recurrent neural networks that generalize from examples and optimize by dreaming
Apr 17, 2022
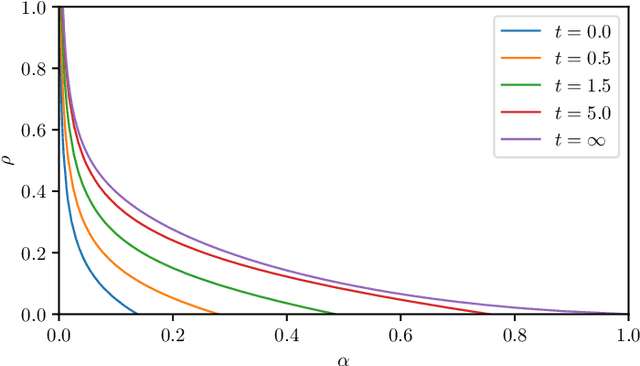
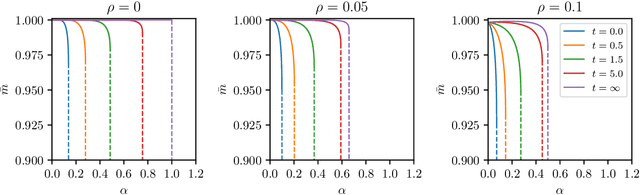
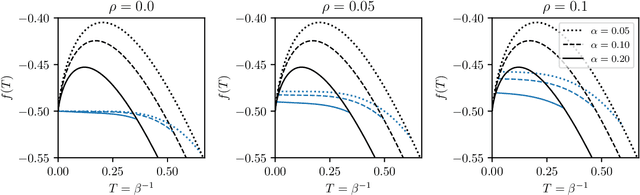
The gap between the huge volumes of data needed to train artificial neural networks and the relatively small amount of data needed by their biological counterparts is a central puzzle in machine learning. Here, inspired by biological information-processing, we introduce a generalized Hopfield network where pairwise couplings between neurons are built according to Hebb's prescription for on-line learning and allow also for (suitably stylized) off-line sleeping mechanisms. Moreover, in order to retain a learning framework, here the patterns are not assumed to be available, instead, we let the network experience solely a dataset made of a sample of noisy examples for each pattern. We analyze the model by statistical-mechanics tools and we obtain a quantitative picture of its capabilities as functions of its control parameters: the resulting network is an associative memory for pattern recognition that learns from examples on-line, generalizes and optimizes its storage capacity by off-line sleeping. Remarkably, the sleeping mechanisms always significantly reduce (up to $\approx 90\%$) the dataset size required to correctly generalize, further, there are memory loads that are prohibitive to Hebbian networks without sleeping (no matter the size and quality of the provided examples), but that are easily handled by the present "rested" neural networks.
Downlink Channel Covariance Matrix Reconstruction for FDD Massive MIMO Systems with Limited Feedback
Apr 02, 2022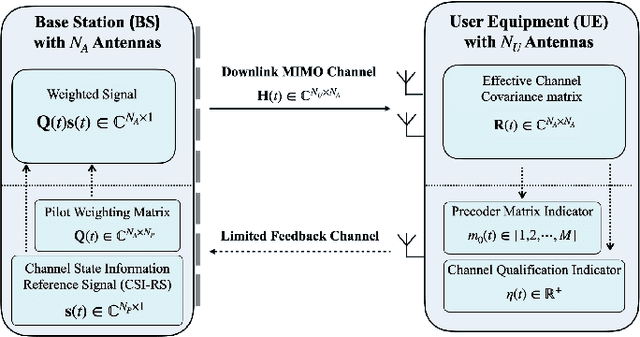
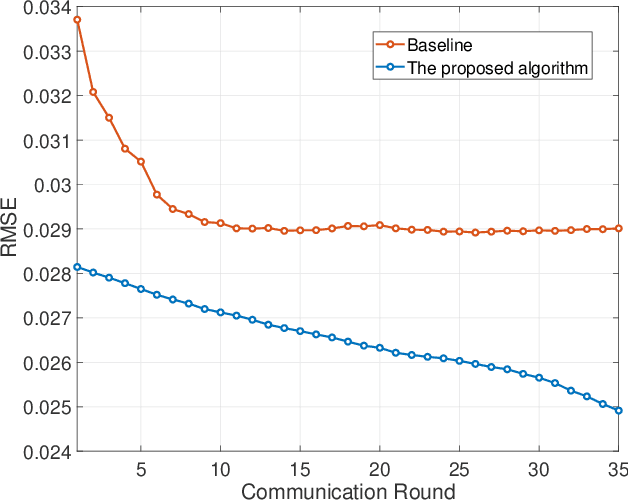
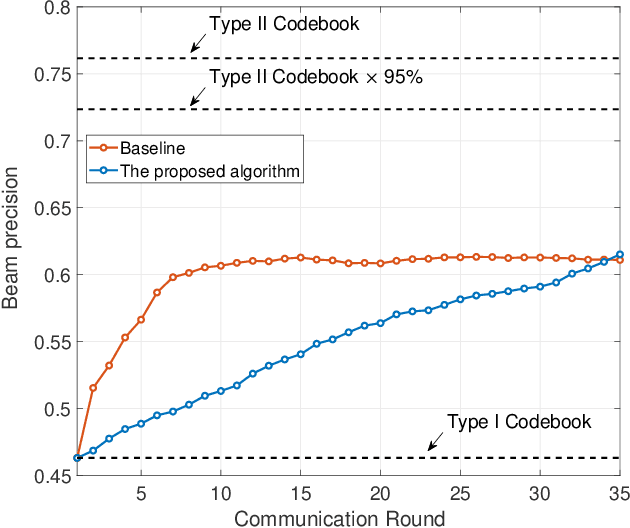
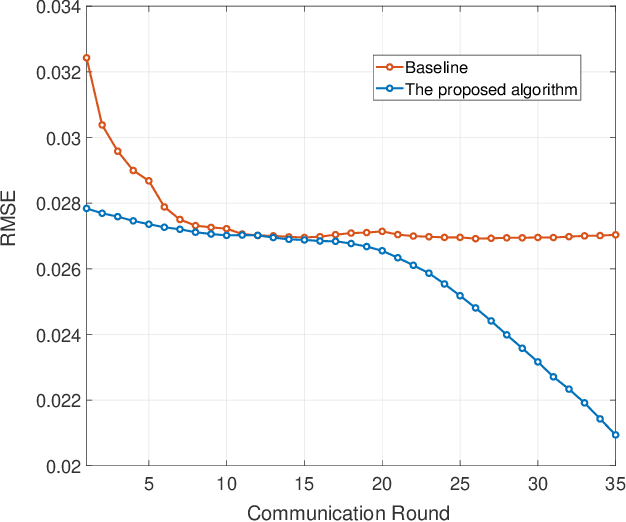
The downlink channel covariance matrix (CCM) acquisition is the key step for the practical performance of massive multiple-input and multiple-output (MIMO) systems, including beamforming, channel tracking, and user scheduling. However, this task is challenging in the popular frequency division duplex massive MIMO systems with Type I codebook due to the limited channel information feedback. In this paper, we propose a novel formulation that leverages the structure of the codebook and feedback values for an accurate estimation of the downlink CCM. Then, we design a cutting plane algorithm to consecutively shrink the feasible set containing the downlink CCM, enabled by the careful design of pilot weighting matrices. Theoretical analysis shows that as the number of communication rounds increases, the proposed cutting plane algorithm can recover the ground-truth CCM. Numerical results are presented to demonstrate the superior performance of the proposed algorithm over the existing benchmark in CCM reconstruction.
No-Reference Quality Assessment for 360-degree Images by Analysis of Multi-frequency Information and Local-global Naturalness
Feb 22, 2021
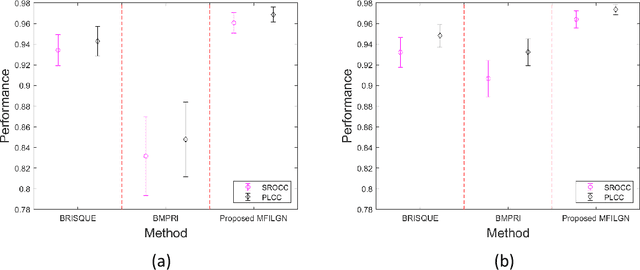
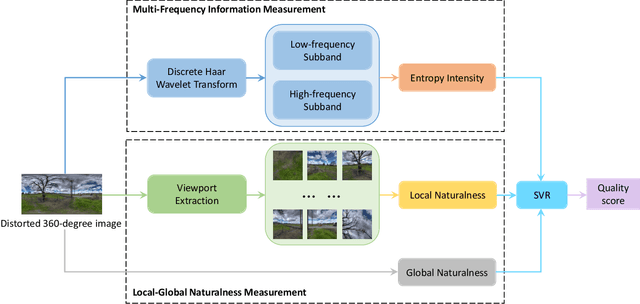

360-degree/omnidirectional images (OIs) have achieved remarkable attentions due to the increasing applications of virtual reality (VR). Compared to conventional 2D images, OIs can provide more immersive experience to consumers, benefitting from the higher resolution and plentiful field of views (FoVs). Moreover, observing OIs is usually in the head mounted display (HMD) without references. Therefore, an efficient blind quality assessment method, which is specifically designed for 360-degree images, is urgently desired. In this paper, motivated by the characteristics of the human visual system (HVS) and the viewing process of VR visual contents, we propose a novel and effective no-reference omnidirectional image quality assessment (NR OIQA) algorithm by Multi-Frequency Information and Local-Global Naturalness (MFILGN). Specifically, inspired by the frequency-dependent property of visual cortex, we first decompose the projected equirectangular projection (ERP) maps into wavelet subbands. Then, the entropy intensities of low and high frequency subbands are exploited to measure the multi-frequency information of OIs. Besides, except for considering the global naturalness of ERP maps, owing to the browsed FoVs, we extract the natural scene statistics features from each viewport image as the measure of local naturalness. With the proposed multi-frequency information measurement and local-global naturalness measurement, we utilize support vector regression as the final image quality regressor to train the quality evaluation model from visual quality-related features to human ratings. To our knowledge, the proposed model is the first no-reference quality assessment method for 360-degreee images that combines multi-frequency information and image naturalness. Experimental results on two publicly available OIQA databases demonstrate that our proposed MFILGN outperforms state-of-the-art approaches.
OPD: Single-view 3D Openable Part Detection
Mar 30, 2022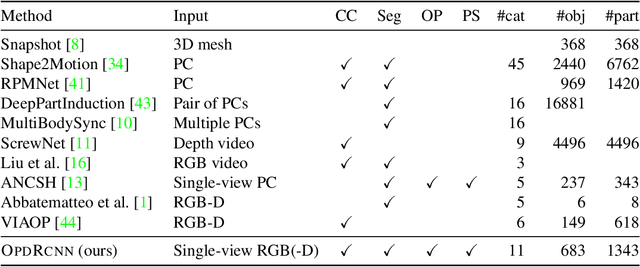

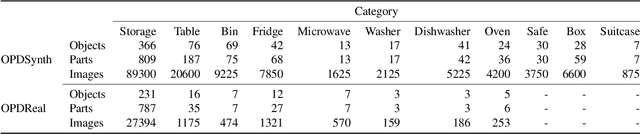
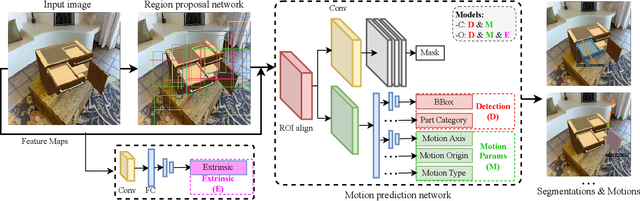
We address the task of predicting what parts of an object can open and how they move when they do so. The input is a single image of an object, and as output we detect what parts of the object can open, and the motion parameters describing the articulation of each openable part. To tackle this task, we create two datasets of 3D objects: OPDSynth based on existing synthetic objects, and OPDReal based on RGBD reconstructions of real objects. We then design OPDRCNN, a neural architecture that detects openable parts and predicts their motion parameters. Our experiments show that this is a challenging task especially when considering generalization across object categories, and the limited amount of information in a single image. Our architecture outperforms baselines and prior work especially for RGB image inputs. Short video summary at https://www.youtube.com/watch?v=P85iCaD0rfc
Realistic Evaluation of Transductive Few-Shot Learning
Apr 24, 2022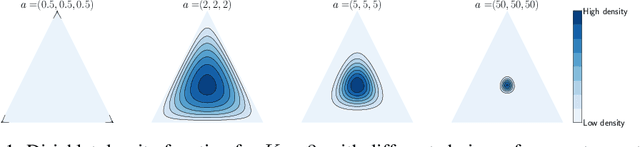
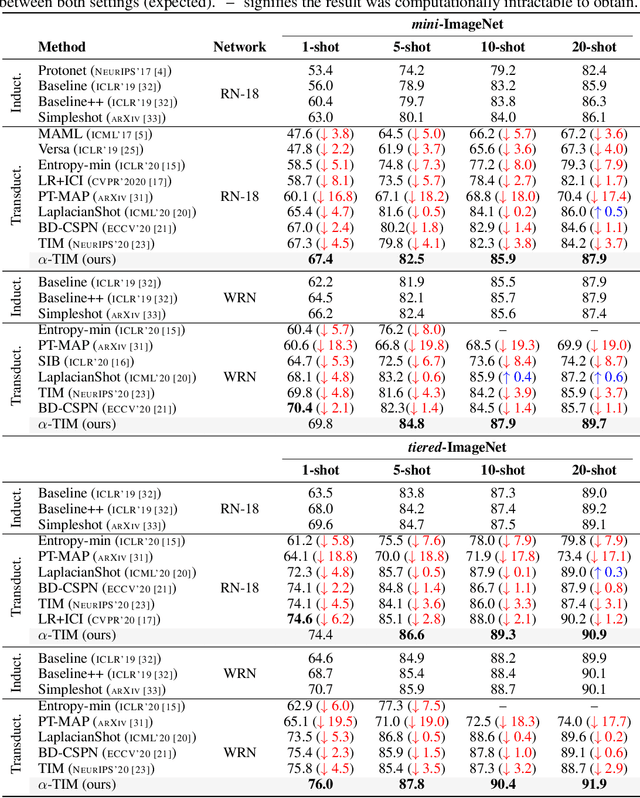
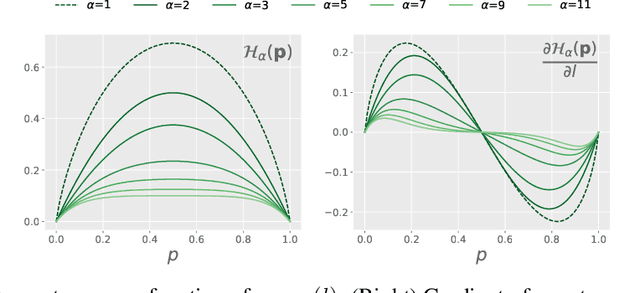
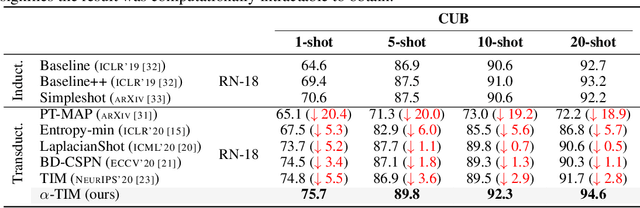
Transductive inference is widely used in few-shot learning, as it leverages the statistics of the unlabeled query set of a few-shot task, typically yielding substantially better performances than its inductive counterpart. The current few-shot benchmarks use perfectly class-balanced tasks at inference. We argue that such an artificial regularity is unrealistic, as it assumes that the marginal label probability of the testing samples is known and fixed to the uniform distribution. In fact, in realistic scenarios, the unlabeled query sets come with arbitrary and unknown label marginals. We introduce and study the effect of arbitrary class distributions within the query sets of few-shot tasks at inference, removing the class-balance artefact. Specifically, we model the marginal probabilities of the classes as Dirichlet-distributed random variables, which yields a principled and realistic sampling within the simplex. This leverages the current few-shot benchmarks, building testing tasks with arbitrary class distributions. We evaluate experimentally state-of-the-art transductive methods over 3 widely used data sets, and observe, surprisingly, substantial performance drops, even below inductive methods in some cases. Furthermore, we propose a generalization of the mutual-information loss, based on $\alpha$-divergences, which can handle effectively class-distribution variations. Empirically, we show that our transductive $\alpha$-divergence optimization outperforms state-of-the-art methods across several data sets, models and few-shot settings. Our code is publicly available at https://github.com/oveilleux/Realistic_Transductive_Few_Shot.