 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Phone Mask Training for Phonetic-Reduction-Robust E2E Uyghur Speech Recognition
Apr 02, 2022
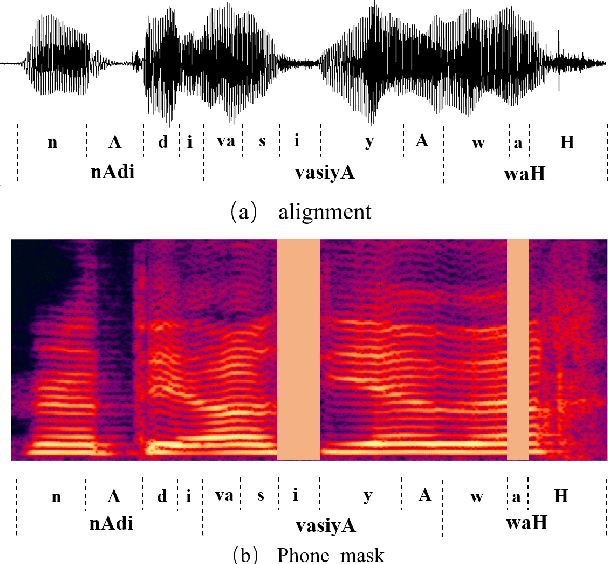

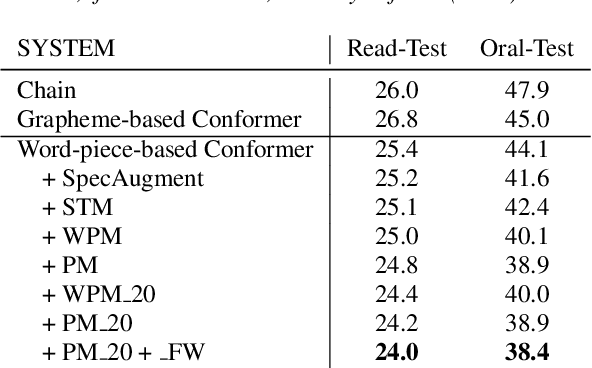
In Uyghur speech, consonant and vowel reduction are often encountered, especially in spontaneous speech with high speech rate, which will cause a degradation of speech recognition performance. To solve this problem, we propose an effective phone mask training method for Conformer-based Uyghur end-to-end (E2E) speech recognition. The idea is to randomly mask off a certain percentage features of phones during model training, which simulates the above verbal phenomena and facilitates E2E model to learn more contextual information. According to experiments, the above issues can be greatly alleviated. In addition, deep investigations are carried out into different units in masking, which shows the effectiveness of our proposed masking unit. We also further study the masking method and optimize filling strategy of phone mask. Finally, compared with Conformer-based E2E baseline without mask training, our model demonstrates about 5.51% relative Word Error Rate (WER) reduction on reading speech and 12.92% on spontaneous speech, respectively. The above approach has also been verified on test-set of open-source data THUYG-20, which shows 20% relative improvements.
* Accepted by INTERSPEECH 2021
UKP-SQUARE: An Online Platform for Question Answering Research
Mar 28, 2022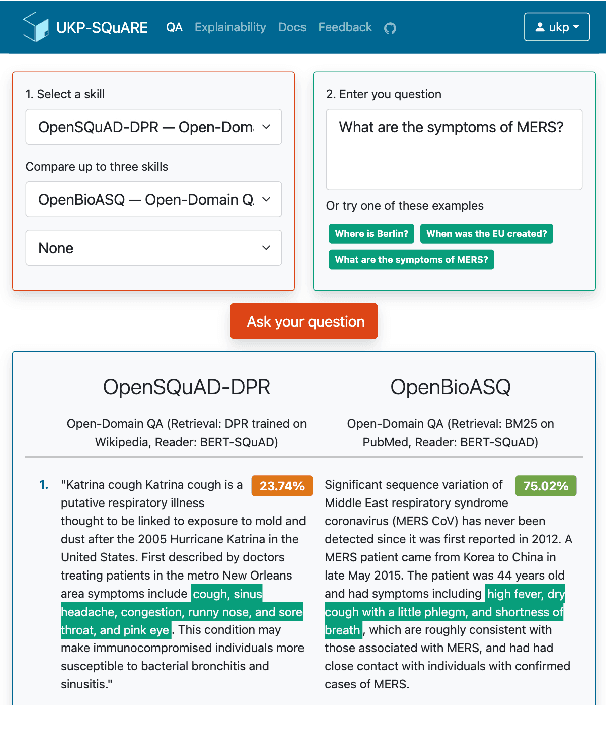

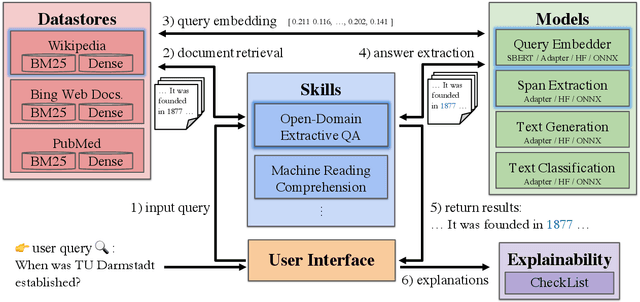
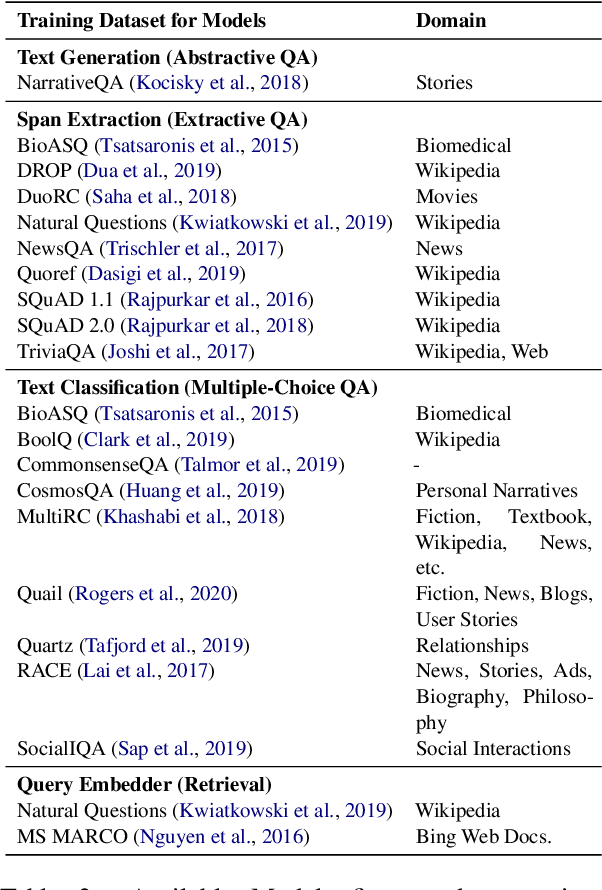
Recent advances in NLP and information retrieval have given rise to a diverse set of question answering tasks that are of different formats (e.g., extractive, abstractive), require different model architectures (e.g., generative, discriminative), and setups (e.g., with or without retrieval). Despite having a large number of powerful, specialized QA pipelines (which we refer to as Skills) that consider a single domain, model or setup, there exists no framework where users can easily explore and compare such pipelines and can extend them according to their needs. To address this issue, we present UKP-SQUARE, an extensible online QA platform for researchers which allows users to query and analyze a large collection of modern Skills via a user-friendly web interface and integrated behavioural tests. In addition, QA researchers can develop, manage, and share their custom Skills using our microservices that support a wide range of models (Transformers, Adapters, ONNX), datastores and retrieval techniques (e.g., sparse and dense). UKP-SQUARE is available on https://square.ukp-lab.de.
Enhancing Causal Estimation through Unlabeled Offline Data
Feb 16, 2022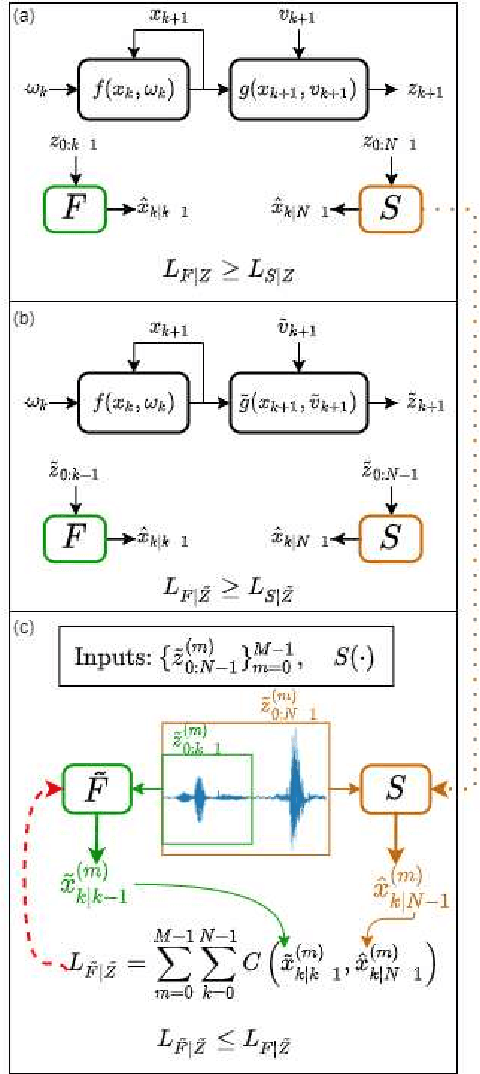
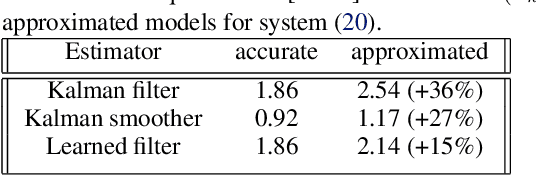
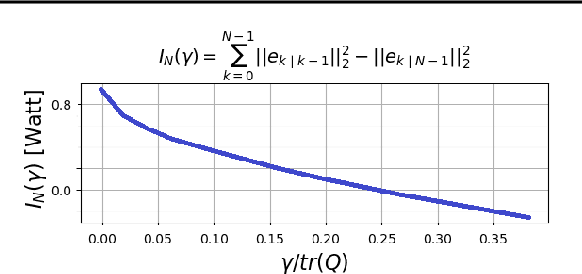
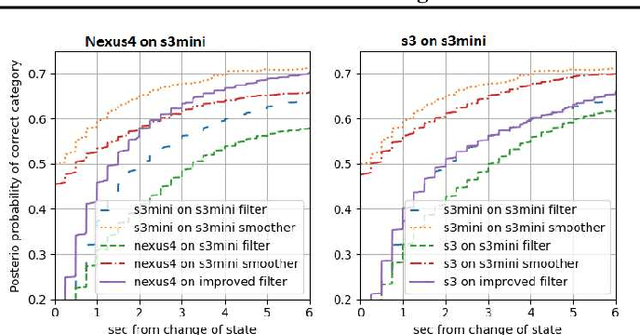
Consider a situation where a new patient arrives in the Intensive Care Unit (ICU) and is monitored by multiple sensors. We wish to assess relevant unmeasured physiological variables (e.g., cardiac contractility and output and vascular resistance) that have a strong effect on the patients diagnosis and treatment. We do not have any information about this specific patient, but, extensive offline information is available about previous patients, that may only be partially related to the present patient (a case of dataset shift). This information constitutes our prior knowledge, and is both partial and approximate. The basic question is how to best use this prior knowledge, combined with online patient data, to assist in diagnosing the current patient most effectively. Our proposed approach consists of three stages: (i) Use the abundant offline data in order to create both a non-causal and a causal estimator for the relevant unmeasured physiological variables. (ii) Based on the non-causal estimator constructed, and a set of measurements from a new group of patients, we construct a causal filter that provides higher accuracy in the prediction of the hidden physiological variables for this new set of patients. (iii) For any new patient arriving in the ICU, we use the constructed filter in order to predict relevant internal variables. Overall, this strategy allows us to make use of the abundantly available offline data in order to enhance causal estimation for newly arriving patients. We demonstrate the effectiveness of this methodology on a (non-medical) real-world task, in situations where the offline data is only partially related to the new observations. We provide a mathematical analysis of the merits of the approach in a linear setting of Kalman filtering and smoothing, demonstrating its utility.
Simultaneous Alignment and Surface Regression Using Hybrid 2D-3D Networks for 3D Coherent Layer Segmentation of Retina OCT Images
Mar 04, 2022

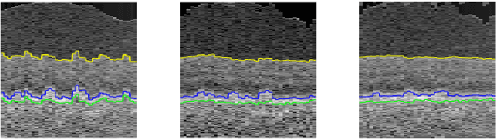
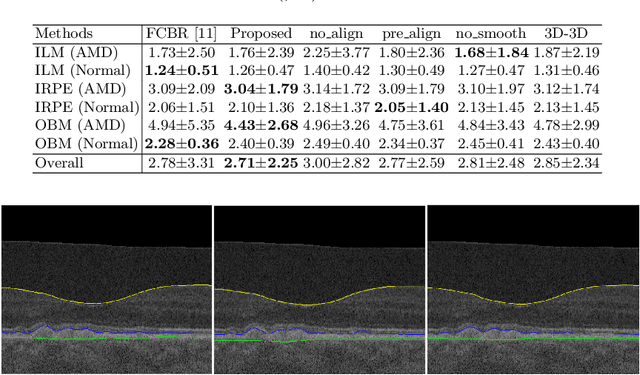
Automated surface segmentation of retinal layer is important and challenging in analyzing optical coherence tomography (OCT). Recently, many deep learning based methods have been developed for this task and yield remarkable performance. However, due to large spatial gap and potential mismatch between the B-scans of OCT data, all of them are based on 2D segmentation of individual B-scans, which may loss the continuity information across the B-scans. In addition, 3D surface of the retina layers can provide more diagnostic information, which is crucial in quantitative image analysis. In this study, a novel framework based on hybrid 2D-3D convolutional neural networks (CNNs) is proposed to obtain continuous 3D retinal layer surfaces from OCT. The 2D features of individual B-scans are extracted by an encoder consisting of 2D convolutions. These 2D features are then used to produce the alignment displacement field and layer segmentation by two 3D decoders, which are coupled via a spatial transformer module. The entire framework is trained end-to-end. To the best of our knowledge, this is the first study that attempts 3D retinal layer segmentation in volumetric OCT images based on CNNs. Experiments on a publicly available dataset show that our framework achieves superior results to state-of-the-art 2D methods in terms of both layer segmentation accuracy and cross-B-scan 3D continuity, thus offering more clinical values than previous works.
Inductive Link Prediction for Nodes Having Only Attribute Information
Jul 16, 2020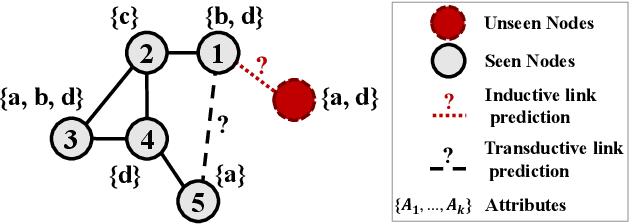
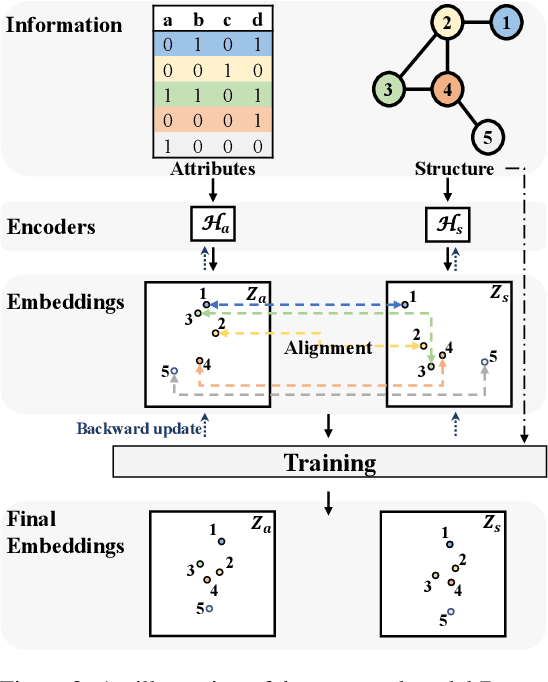
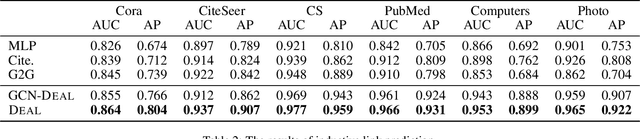
Predicting the link between two nodes is a fundamental problem for graph data analytics. In attributed graphs, both the structure and attribute information can be utilized for link prediction. Most existing studies focus on transductive link prediction where both nodes are already in the graph. However, many real-world applications require inductive prediction for new nodes having only attribute information. It is more challenging since the new nodes do not have structure information and cannot be seen during the model training. To solve this problem, we propose a model called DEAL, which consists of three components: two node embedding encoders and one alignment mechanism. The two encoders aim to output the attribute-oriented node embedding and the structure-oriented node embedding, and the alignment mechanism aligns the two types of embeddings to build the connections between the attributes and links. Our model DEAL is versatile in the sense that it works for both inductive and transductive link prediction. Extensive experiments on several benchmark datasets show that our proposed model significantly outperforms existing inductive link prediction methods, and also outperforms the state-of-the-art methods on transductive link prediction.
Multi-Level Interaction Reranking with User Behavior History
Apr 20, 2022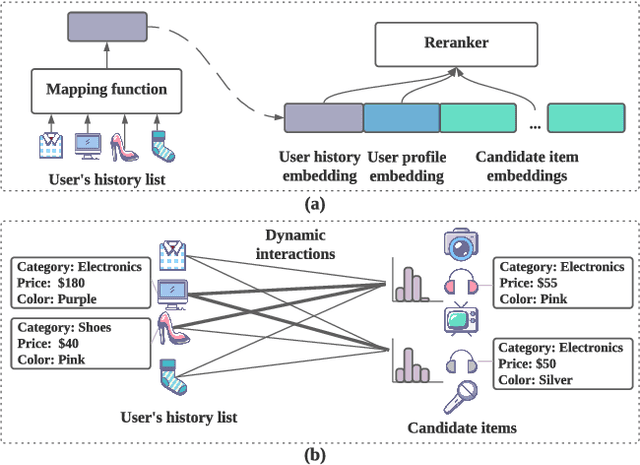
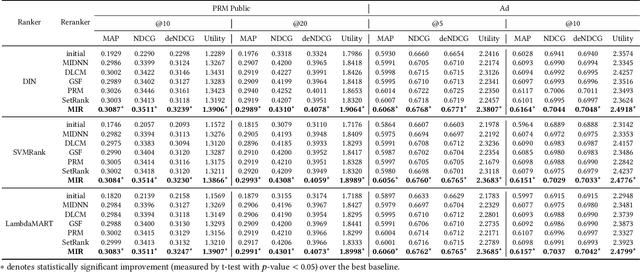
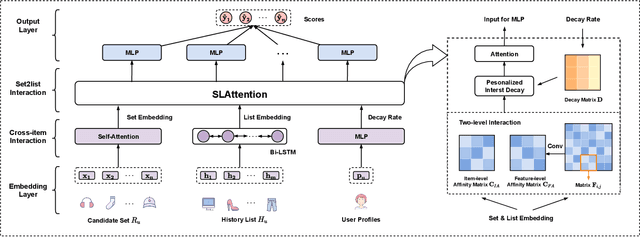
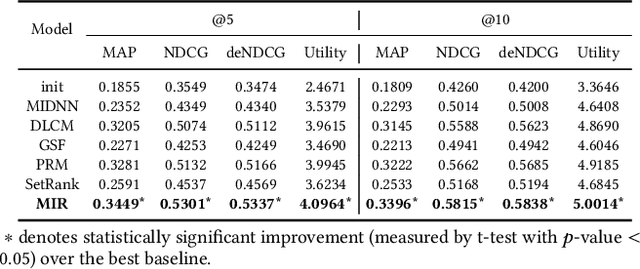
As the final stage of the multi-stage recommender system (MRS), reranking directly affects users' experience and satisfaction, thus playing a critical role in MRS. Despite the improvement achieved in the existing work, three issues are yet to be solved. First, users' historical behaviors contain rich preference information, such as users' long and short-term interests, but are not fully exploited in reranking. Previous work typically treats items in history equally important, neglecting the dynamic interaction between the history and candidate items. Second, existing reranking models focus on learning interactions at the item level while ignoring the fine-grained feature-level interactions. Lastly, estimating the reranking score on the ordered initial list before reranking may lead to the early scoring problem, thereby yielding suboptimal reranking performance. To address the above issues, we propose a framework named Multi-level Interaction Reranking (MIR). MIR combines low-level cross-item interaction and high-level set-to-list interaction, where we view the candidate items to be reranked as a set and the users' behavior history in chronological order as a list. We design a novel SLAttention structure for modeling the set-to-list interactions with personalized long-short term interests. Moreover, feature-level interactions are incorporated to capture the fine-grained influence among items. We design MIR in such a way that any permutation of the input items would not change the output ranking, and we theoretically prove it. Extensive experiments on three public and proprietary datasets show that MIR significantly outperforms the state-of-the-art models using various ranking and utility metrics.
Aesthetic Text Logo Synthesis via Content-aware Layout Inferring
Apr 06, 2022
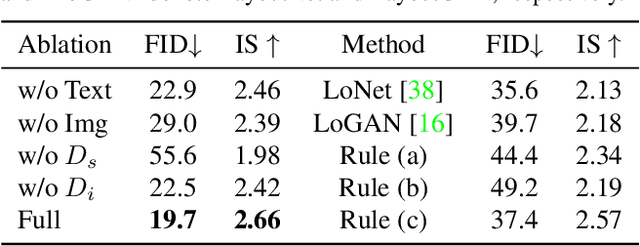
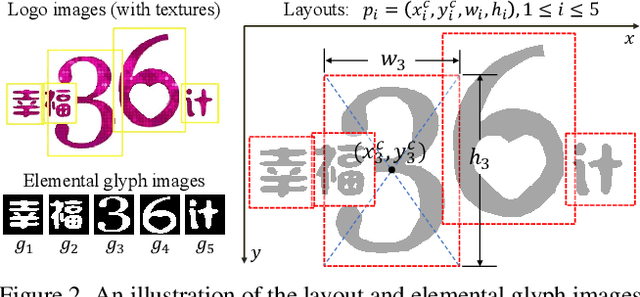
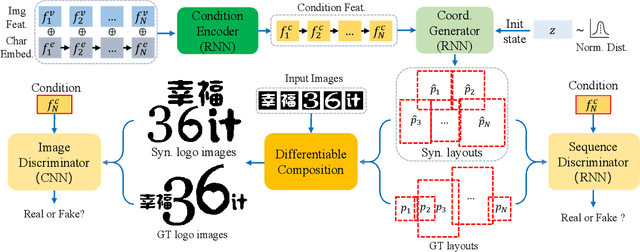
Text logo design heavily relies on the creativity and expertise of professional designers, in which arranging element layouts is one of the most important procedures. However, few attention has been paid to this task which needs to take many factors (e.g., fonts, linguistics, topics, etc.) into consideration. In this paper, we propose a content-aware layout generation network which takes glyph images and their corresponding text as input and synthesizes aesthetic layouts for them automatically. Specifically, we develop a dual-discriminator module, including a sequence discriminator and an image discriminator, to evaluate both the character placing trajectories and rendered shapes of synthesized text logos, respectively. Furthermore, we fuse the information of linguistics from texts and visual semantics from glyphs to guide layout prediction, which both play important roles in professional layout design. To train and evaluate our approach, we construct a dataset named as TextLogo3K, consisting of about 3,500 text logo images and their pixel-level annotations. Experimental studies on this dataset demonstrate the effectiveness of our approach for synthesizing visually-pleasing text logos and verify its superiority against the state of the art.
LP-BERT: Multi-task Pre-training Knowledge Graph BERT for Link Prediction
Jan 13, 2022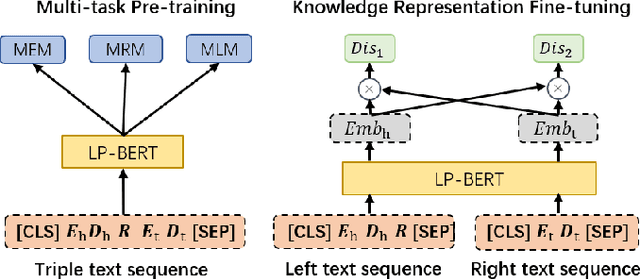
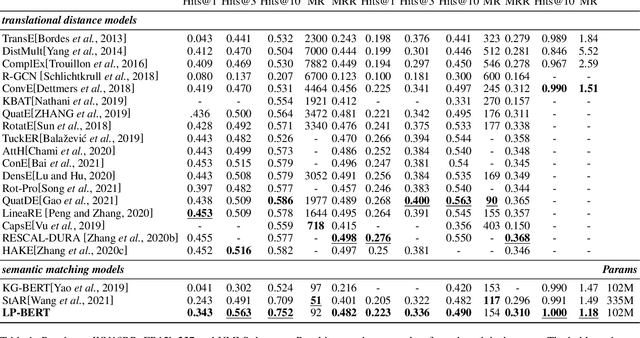
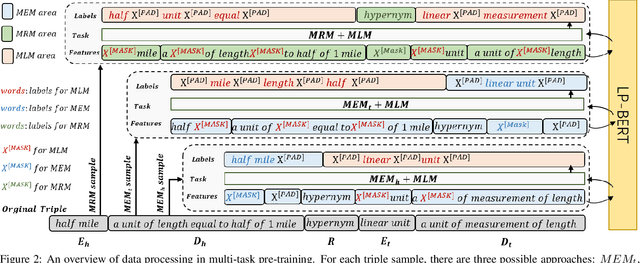
Link prediction plays an significant role in knowledge graph, which is an important resource for many artificial intelligence tasks, but it is often limited by incompleteness. In this paper, we propose knowledge graph BERT for link prediction, named LP-BERT, which contains two training stages: multi-task pre-training and knowledge graph fine-tuning. The pre-training strategy not only uses Mask Language Model (MLM) to learn the knowledge of context corpus, but also introduces Mask Entity Model (MEM) and Mask Relation Model (MRM), which can learn the relationship information from triples by predicting semantic based entity and relation elements. Structured triple relation information can be transformed into unstructured semantic information, which can be integrated into the pre-training model together with context corpus information. In the fine-tuning phase, inspired by contrastive learning, we carry out a triple-style negative sampling in sample batch, which greatly increased the proportion of negative sampling while keeping the training time almost unchanged. Furthermore, we propose a data augmentation method based on the inverse relationship of triples to further increase the sample diversity. We achieve state-of-the-art results on WN18RR and UMLS datasets, especially the Hits@10 indicator improved by 5\% from the previous state-of-the-art result on WN18RR dataset.
Follow My Eye: Using Gaze to Supervise Computer-Aided Diagnosis
Apr 06, 2022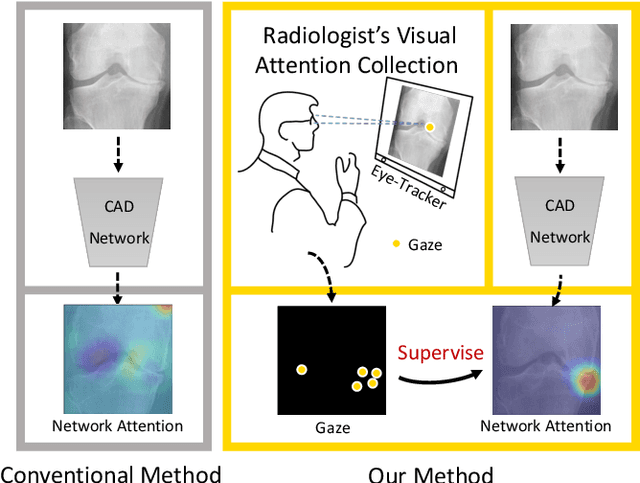
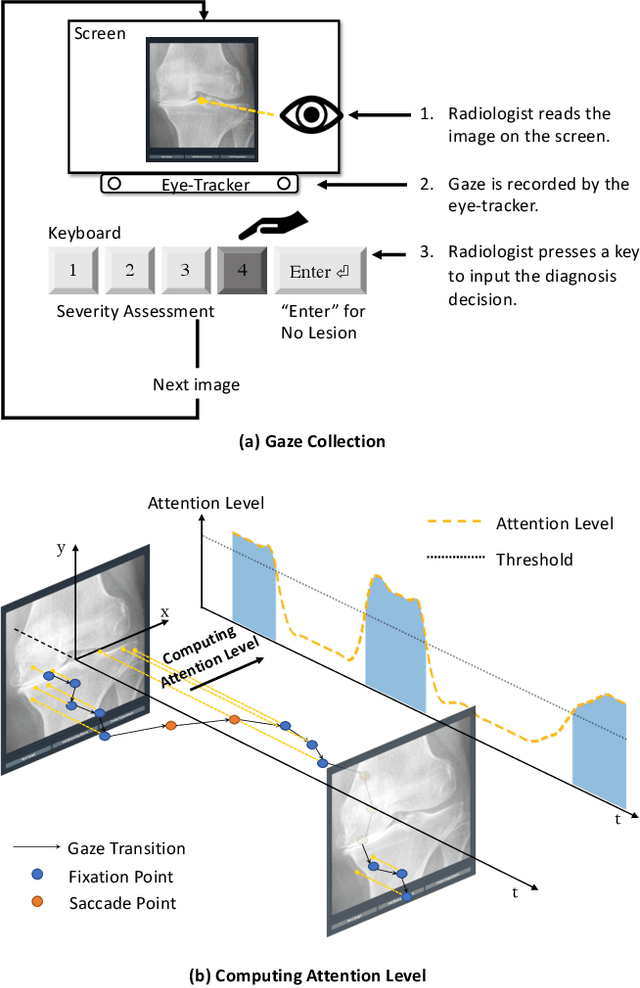
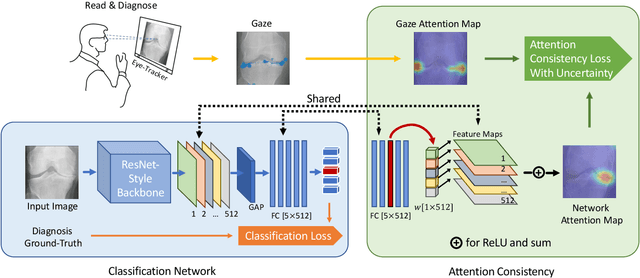
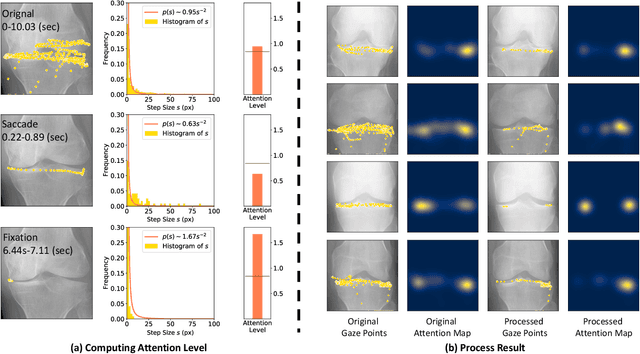
When deep neural network (DNN) was first introduced to the medical image analysis community, researchers were impressed by its performance. However, it is evident now that a large number of manually labeled data is often a must to train a properly functioning DNN. This demand for supervision data and labels is a major bottleneck in current medical image analysis, since collecting a large number of annotations from experienced experts can be time-consuming and expensive. In this paper, we demonstrate that the eye movement of radiologists reading medical images can be a new form of supervision to train the DNN-based computer-aided diagnosis (CAD) system. Particularly, we record the tracks of the radiologists' gaze when they are reading images. The gaze information is processed and then used to supervise the DNN's attention via an Attention Consistency module. To the best of our knowledge, the above pipeline is among the earliest efforts to leverage expert eye movement for deep-learning-based CAD. We have conducted extensive experiments on knee X-ray images for osteoarthritis assessment. The results show that our method can achieve considerable improvement in diagnosis performance, with the help of gaze supervision.
ConvSearch: A Open-Domain Conversational Search Behavior Dataset
Apr 06, 2022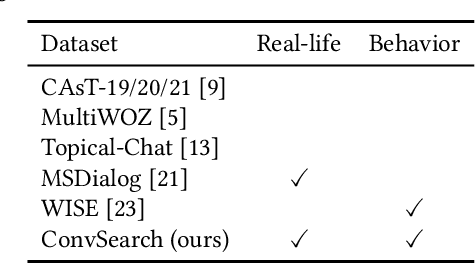
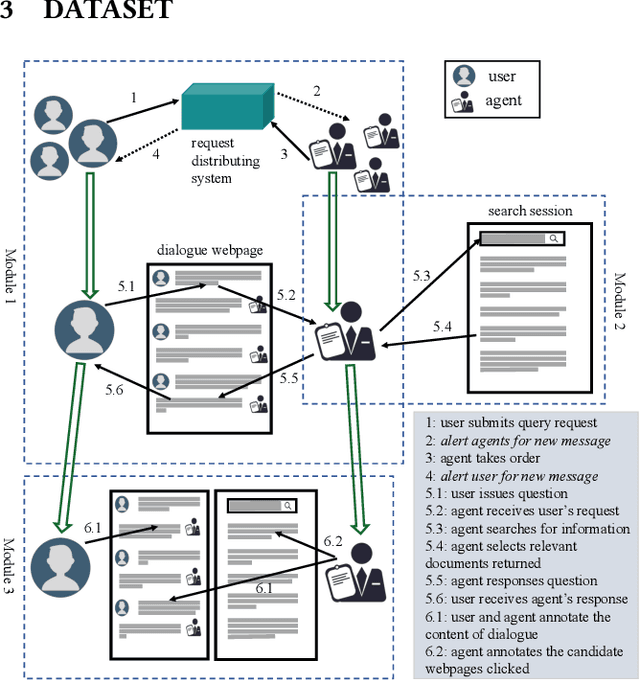
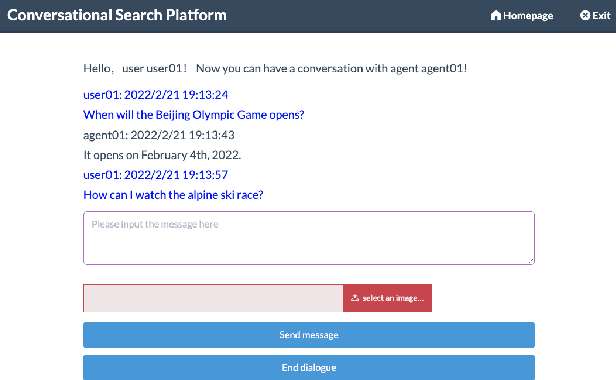
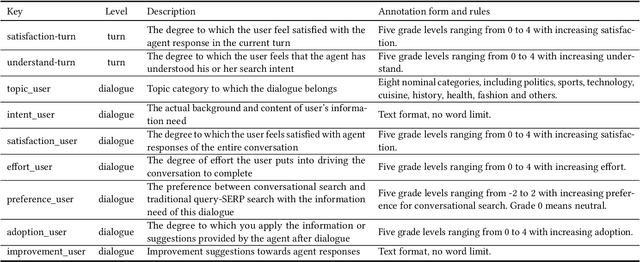
Conversational Search has been paid much attention recently with the increasing popularity of intelligent user interfaces. However, compared with the endeavour in designing effective conversational search algorithms, relatively much fewer researchers have focused on the construction of benchmark datasets. For most existing datasets, the information needs are defined by researchers and search requests are not proposed by actual users. Meanwhile, these datasets usually focus on the conversations between users and agents (systems), while largely ignores the search behaviors of agents before they return response to users. To overcome these problems, we construct a Chinese Open-Domain Conversational Search Behavior Dataset (ConvSearch) based on Wizard-of-Oz paradigm in the field study scenario. We develop a novel conversational search platform to collect dialogue contents, annotate dialogue quality and candidate search results and record agent search behaviors. 25 search agents and 51 users are recruited for the field study that lasts about 45 days. The ConvSearch dataset contains 1,131 dialogues together with annotated search results and corresponding search behaviors. We also provide the intent labels of each search behavior iteration to support intent understanding related researches. The dataset is already open to public for academic usage.