 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Modal Causal Inference with Deep Structural Equation Models
Mar 21, 2022
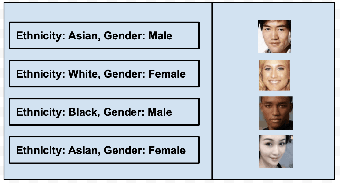
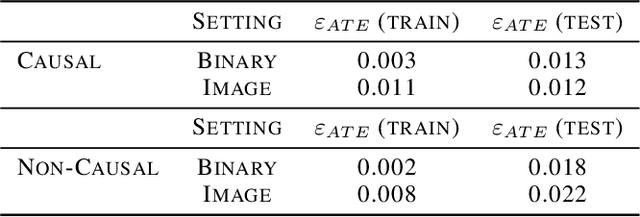
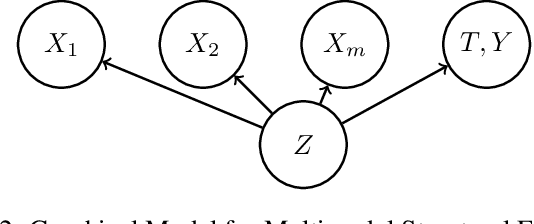

Accounting for the effects of confounders is one of the central challenges in causal inference. Unstructured multi-modal data (images, time series, text) contains valuable information about diverse types of confounders, yet it is typically left unused by most existing methods. This paper seeks to develop techniques that leverage this unstructured data within causal inference to correct for additional confounders that may otherwise not be accounted for. We formalize this task and we propose algorithms based on deep structural equations that treat multi-modal unstructured data as proxy variables. We empirically demonstrate on tasks in genomics and healthcare that unstructured data can be used to correct for diverse sources of confounding, potentially enabling the use of large amounts of data that were previously not used in causal inference.
Transferred Q-learning
Feb 09, 2022We consider $Q$-learning with knowledge transfer, using samples from a target reinforcement learning (RL) task as well as source samples from different but related RL tasks. We propose transfer learning algorithms for both batch and online $Q$-learning with offline source studies. The proposed transferred $Q$-learning algorithm contains a novel re-targeting step that enables vertical information-cascading along multiple steps in an RL task, besides the usual horizontal information-gathering as transfer learning (TL) for supervised learning. We establish the first theoretical justifications of TL in RL tasks by showing a faster rate of convergence of the $Q$ function estimation in the offline RL transfer, and a lower regret bound in the offline-to-online RL transfer under certain similarity assumptions. Empirical evidences from both synthetic and real datasets are presented to back up the proposed algorithm and our theoretical results.
UKP-SQUARE: An Online Platform for Question Answering Research
Mar 28, 2022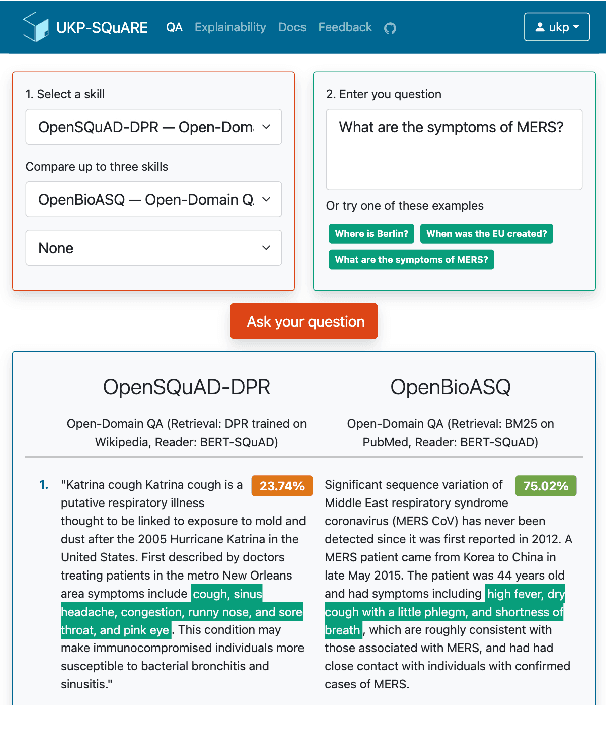

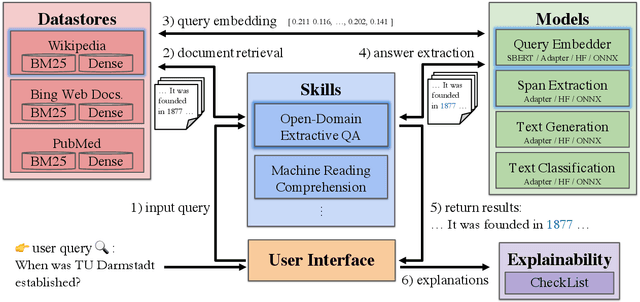
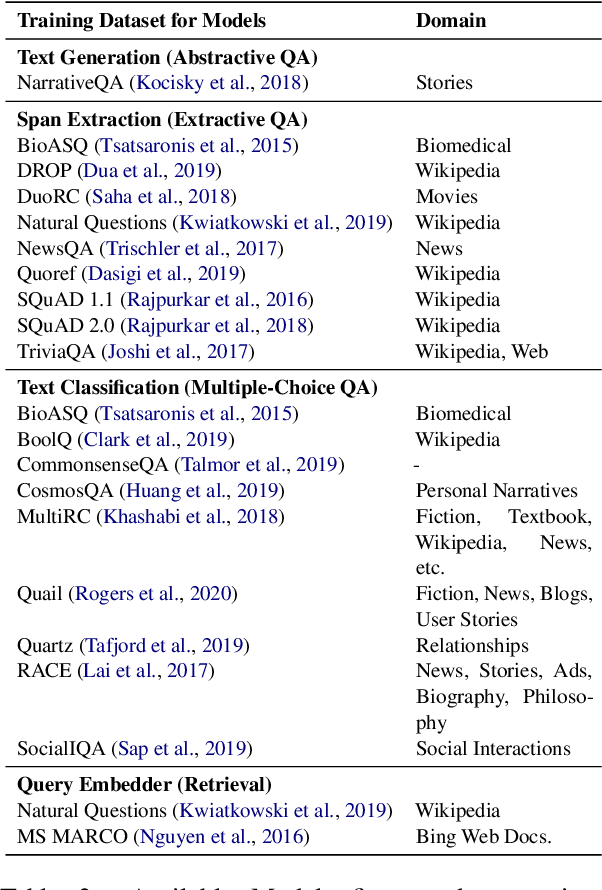
Recent advances in NLP and information retrieval have given rise to a diverse set of question answering tasks that are of different formats (e.g., extractive, abstractive), require different model architectures (e.g., generative, discriminative), and setups (e.g., with or without retrieval). Despite having a large number of powerful, specialized QA pipelines (which we refer to as Skills) that consider a single domain, model or setup, there exists no framework where users can easily explore and compare such pipelines and can extend them according to their needs. To address this issue, we present UKP-SQUARE, an extensible online QA platform for researchers which allows users to query and analyze a large collection of modern Skills via a user-friendly web interface and integrated behavioural tests. In addition, QA researchers can develop, manage, and share their custom Skills using our microservices that support a wide range of models (Transformers, Adapters, ONNX), datastores and retrieval techniques (e.g., sparse and dense). UKP-SQUARE is available on https://square.ukp-lab.de.
ArCovidVac: Analyzing Arabic Tweets About COVID-19 Vaccination
Jan 17, 2022
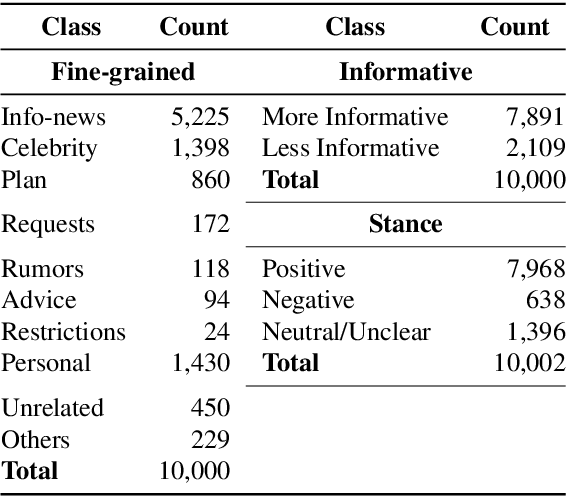


The emergence of the COVID-19 pandemic and the first global infodemic have changed our lives in many different ways. We relied on social media to get the latest information about the COVID-19 pandemic and at the same time to disseminate information. The content in social media consisted not only health related advises, plans, and informative news from policy makers, but also contains conspiracies and rumors. It became important to identify such information as soon as they are posted to make actionable decisions (e.g., debunking rumors, or taking certain measures for traveling). To address this challenge, we develop and publicly release the first largest manually annotated Arabic tweet dataset, ArCovidVac, for the COVID-19 vaccination campaign, covering many countries in the Arab region. The dataset is enriched with different layers of annotation, including, (i) Informativeness (more vs. less importance of the tweets); (ii) fine-grained tweet content types (e.g., advice, rumors, restriction, authenticate news/information); and (iii) stance towards vaccination (pro-vaccination, neutral, anti-vaccination). Further, we performed in-depth analysis of the data, exploring the popularity of different vaccines, trending hashtags, topics and presence of offensiveness in the tweets. We studied the data for individual types of tweets and temporal changes in stance towards vaccine. We benchmarked the ArCovidVac dataset using transformer architectures for informativeness, content types, and stance detection.
Aesthetic Text Logo Synthesis via Content-aware Layout Inferring
Apr 06, 2022
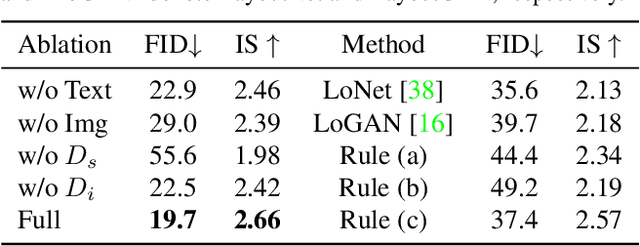
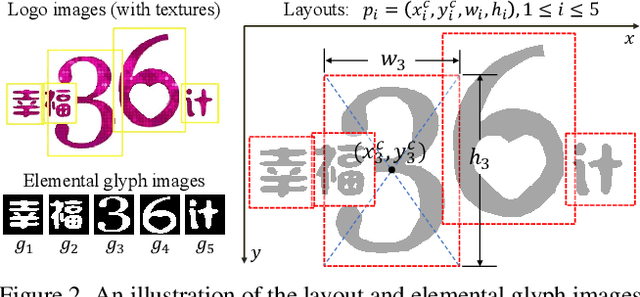
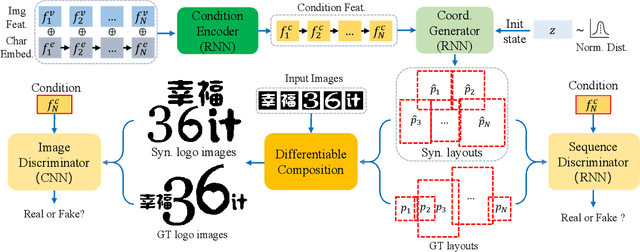
Text logo design heavily relies on the creativity and expertise of professional designers, in which arranging element layouts is one of the most important procedures. However, few attention has been paid to this task which needs to take many factors (e.g., fonts, linguistics, topics, etc.) into consideration. In this paper, we propose a content-aware layout generation network which takes glyph images and their corresponding text as input and synthesizes aesthetic layouts for them automatically. Specifically, we develop a dual-discriminator module, including a sequence discriminator and an image discriminator, to evaluate both the character placing trajectories and rendered shapes of synthesized text logos, respectively. Furthermore, we fuse the information of linguistics from texts and visual semantics from glyphs to guide layout prediction, which both play important roles in professional layout design. To train and evaluate our approach, we construct a dataset named as TextLogo3K, consisting of about 3,500 text logo images and their pixel-level annotations. Experimental studies on this dataset demonstrate the effectiveness of our approach for synthesizing visually-pleasing text logos and verify its superiority against the state of the art.
Interactive Inference under Information Constraints
Aug 18, 2020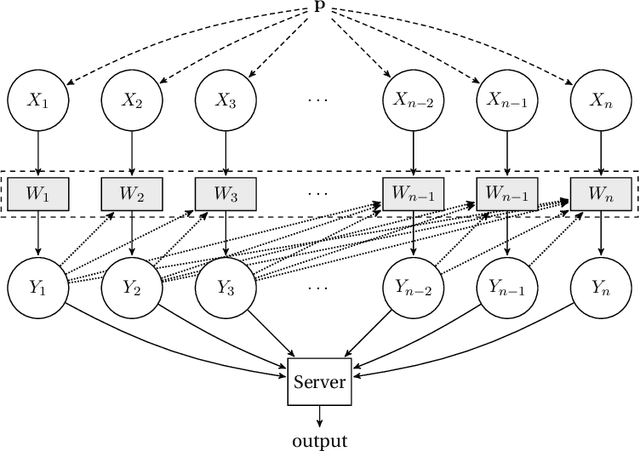
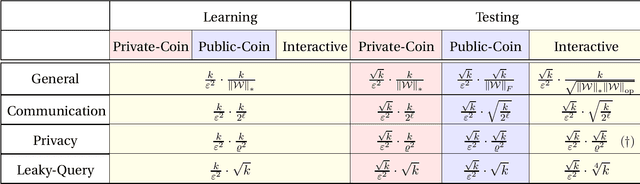
We consider distributed inference using sequentially interactive protocols. We obtain lower bounds on the minimax sample complexity of interactive protocols under local information constraints, a broad family of resource constraints which captures communication constraints, local differential privacy, and noisy binary queries as special cases. We focus on the inference tasks of learning (density estimation) and identity testing (goodness-of-fit) for discrete distributions under total variation distance, and establish general lower bounds that take into account the local constraints modeled as a channel family. Our main technical contribution is an approach to handle the correlation that builds due to interactivity and quantifies how effectively one can exploit this correlation in spite of the local constraints. Using this, we fill gaps in some prior works and characterize the optimal sample complexity of learning and testing discrete distributions under total variation distance, for both communication and local differential privacy constraints. Prior to our work, this was known only for the problem of testing under local privacy constraints (Amin, Joseph, and Mao (2020); Berrett and Butucea (2020)). Our results show that interactivity does not help for learning or testing under these two constraints. Finally, we provide the first instance of a natural family of "leaky query" local constraints under which interactive protocols strictly outperform the noninteractive ones for distribution testing.
Follow My Eye: Using Gaze to Supervise Computer-Aided Diagnosis
Apr 06, 2022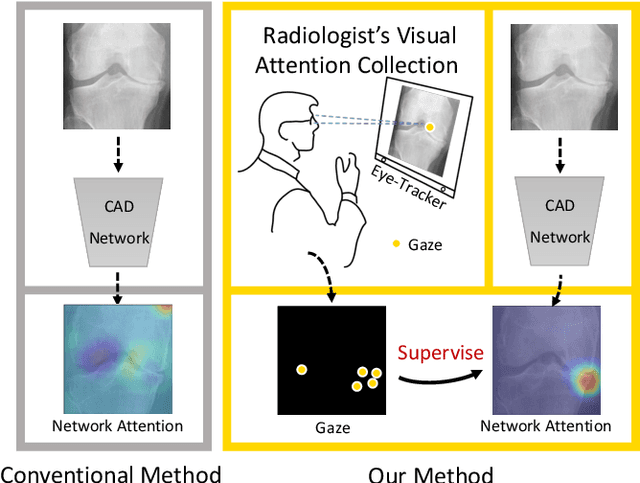
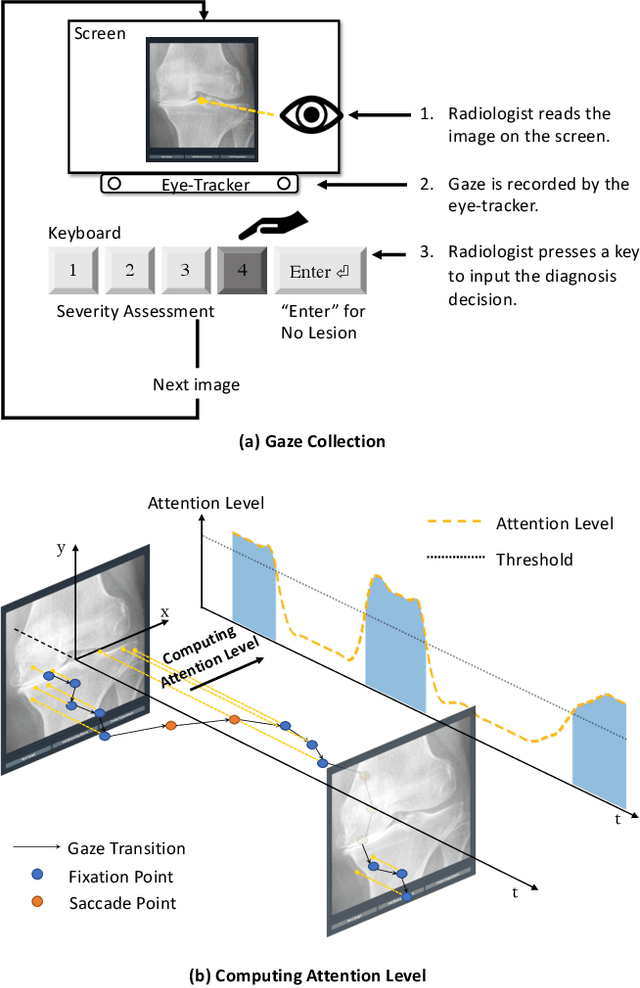
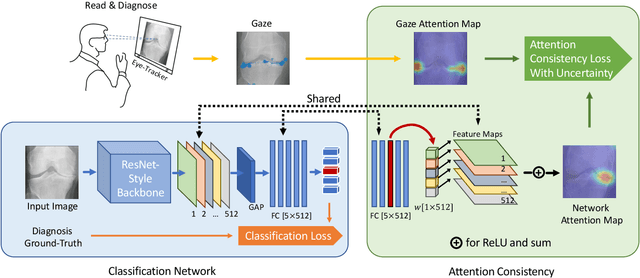
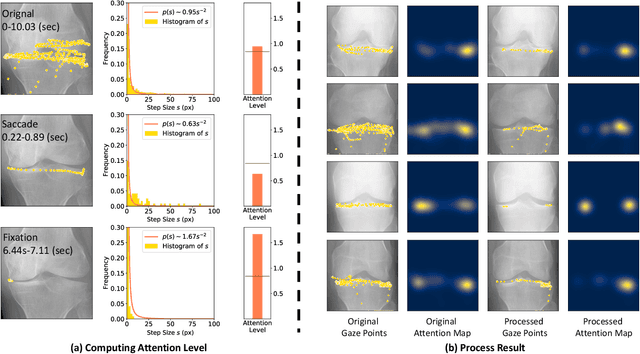
When deep neural network (DNN) was first introduced to the medical image analysis community, researchers were impressed by its performance. However, it is evident now that a large number of manually labeled data is often a must to train a properly functioning DNN. This demand for supervision data and labels is a major bottleneck in current medical image analysis, since collecting a large number of annotations from experienced experts can be time-consuming and expensive. In this paper, we demonstrate that the eye movement of radiologists reading medical images can be a new form of supervision to train the DNN-based computer-aided diagnosis (CAD) system. Particularly, we record the tracks of the radiologists' gaze when they are reading images. The gaze information is processed and then used to supervise the DNN's attention via an Attention Consistency module. To the best of our knowledge, the above pipeline is among the earliest efforts to leverage expert eye movement for deep-learning-based CAD. We have conducted extensive experiments on knee X-ray images for osteoarthritis assessment. The results show that our method can achieve considerable improvement in diagnosis performance, with the help of gaze supervision.
ConvSearch: A Open-Domain Conversational Search Behavior Dataset
Apr 06, 2022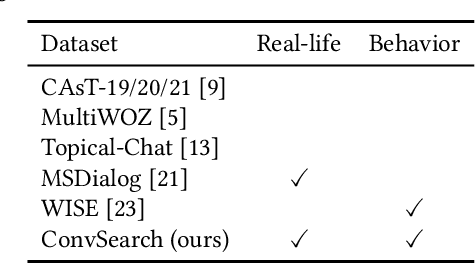
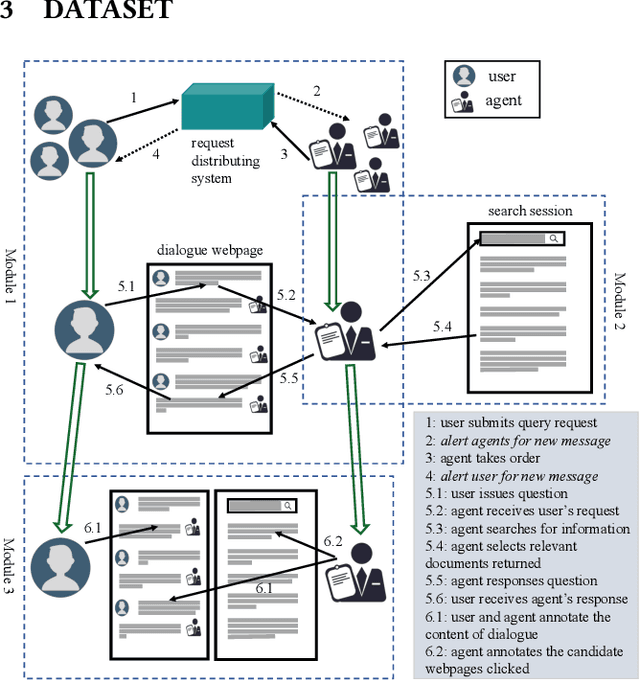
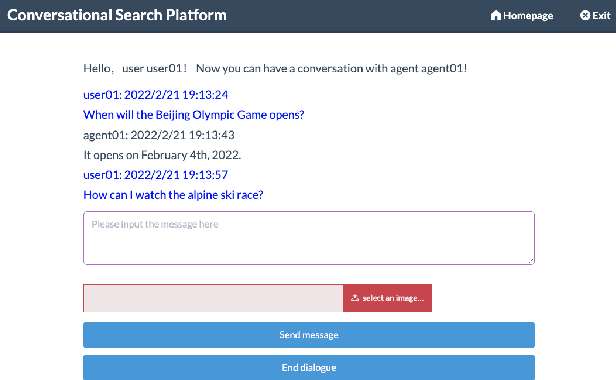
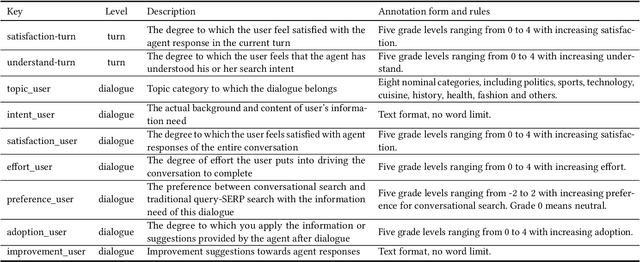
Conversational Search has been paid much attention recently with the increasing popularity of intelligent user interfaces. However, compared with the endeavour in designing effective conversational search algorithms, relatively much fewer researchers have focused on the construction of benchmark datasets. For most existing datasets, the information needs are defined by researchers and search requests are not proposed by actual users. Meanwhile, these datasets usually focus on the conversations between users and agents (systems), while largely ignores the search behaviors of agents before they return response to users. To overcome these problems, we construct a Chinese Open-Domain Conversational Search Behavior Dataset (ConvSearch) based on Wizard-of-Oz paradigm in the field study scenario. We develop a novel conversational search platform to collect dialogue contents, annotate dialogue quality and candidate search results and record agent search behaviors. 25 search agents and 51 users are recruited for the field study that lasts about 45 days. The ConvSearch dataset contains 1,131 dialogues together with annotated search results and corresponding search behaviors. We also provide the intent labels of each search behavior iteration to support intent understanding related researches. The dataset is already open to public for academic usage.
Feasibility Study of Multi-Site Split Learning for Privacy-Preserving Medical Systems under Data Imbalance Constraints in COVID-19, X-Ray, and Cholesterol Dataset
Feb 21, 2022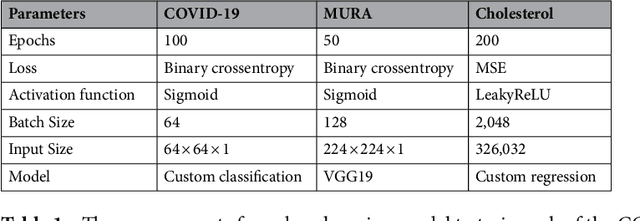

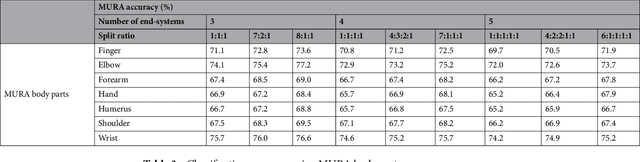

It seems as though progressively more people are in the race to upload content, data, and information online; and hospitals haven't neglected this trend either. Hospitals are now at the forefront for multi-site medical data sharing to provide groundbreaking advancements in the way health records are shared and patients are diagnosed. Sharing of medical data is essential in modern medical research. Yet, as with all data sharing technology, the challenge is to balance improved treatment with protecting patient's personal information. This paper provides a novel split learning algorithm coined the term, "multi-site split learning", which enables a secure transfer of medical data between multiple hospitals without fear of exposing personal data contained in patient records. It also explores the effects of varying the number of end-systems and the ratio of data-imbalance on the deep learning performance. A guideline for the most optimal configuration of split learning that ensures privacy of patient data whilst achieving performance is empirically given. We argue the benefits of our multi-site split learning algorithm, especially regarding the privacy preserving factor, using CT scans of COVID-19 patients, X-ray bone scans, and cholesterol level medical data.
Statistical inference of travelers' route choice preferences with system-level data
Apr 23, 2022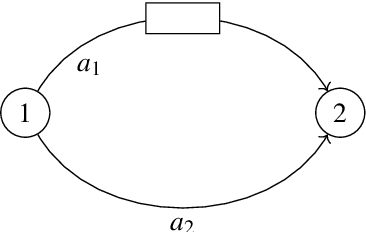
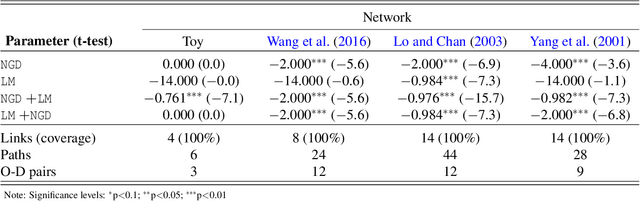
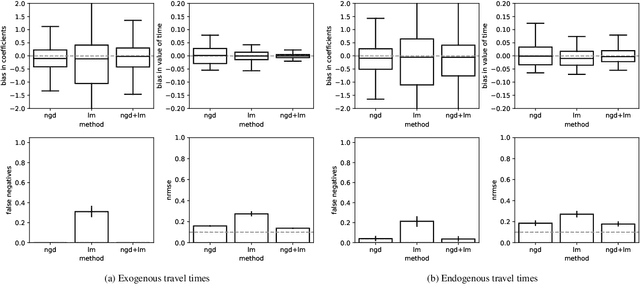
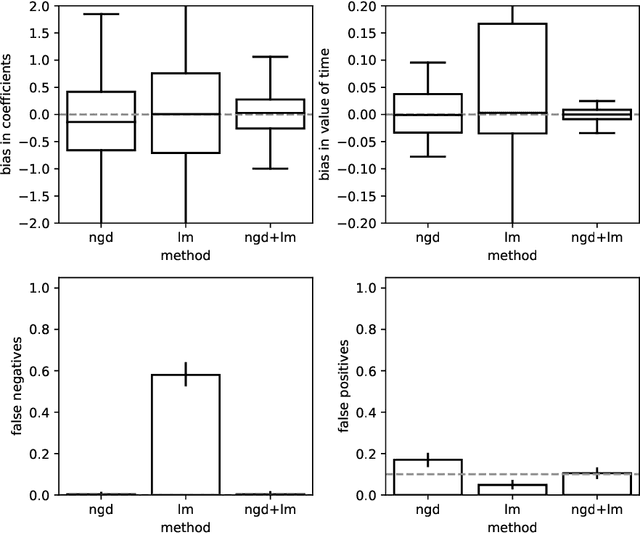
Traditional network models encapsulate travel behavior among all origin-destination pairs based on a simplified and generic utility function. Typically, the utility function consists of travel time solely and its coefficients are equated to estimates obtained from stated preference data. While this modeling strategy is reasonable, the inherent sampling bias in individual-level data may be further amplified over network flow aggregation, leading to inaccurate flow estimates. This data must be collected from surveys or travel diaries, which may be labor intensive, costly and limited to a small time period. To address these limitations, this study extends classical bi-level formulations to estimate travelers' utility functions with multiple attributes using system-level data. We formulate a methodology grounded on non-linear least squares to statistically infer travelers' utility function in the network context using traffic counts, traffic speeds, traffic incidents and sociodemographic information, among other attributes. The analysis of the mathematical properties of the optimization problem and of its pseudo-convexity motivate the use of normalized gradient descent. We also develop a hypothesis test framework to examine statistical properties of the utility function coefficients and to perform attributes selection. Experiments on synthetic data show that the coefficients are consistently recovered and that hypothesis tests are a reliable statistic to identify which attributes are determinants of travelers' route choices. Besides, a series of Monte-Carlo experiments suggest that statistical inference is robust to noise in the Origin-Destination matrix and in the traffic counts, and to various levels of sensor coverage. The methodology is also deployed at a large scale using real-world multi-source data in Fresno, CA collected before and during the COVID-19 outbreak.