 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IMLE-Net: An Interpretable Multi-level Multi-channel Model for ECG Classification
Apr 06, 2022
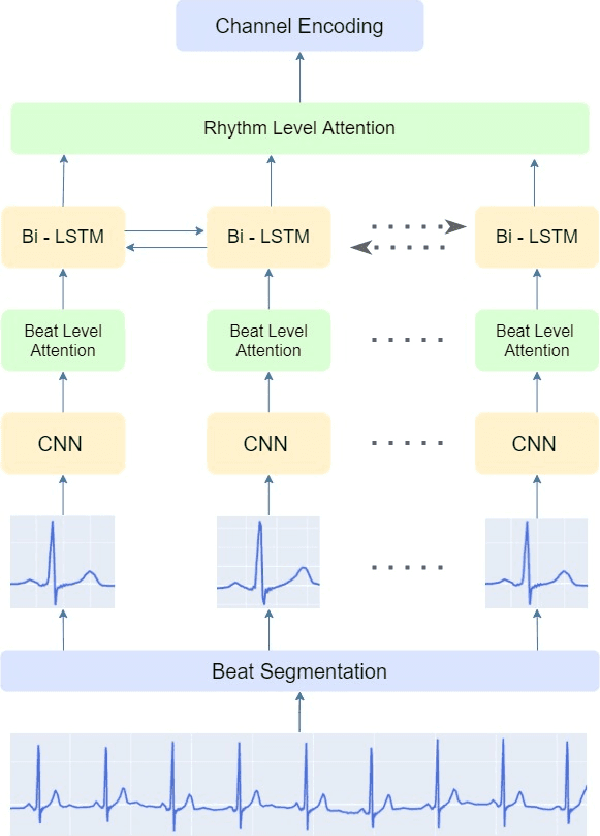
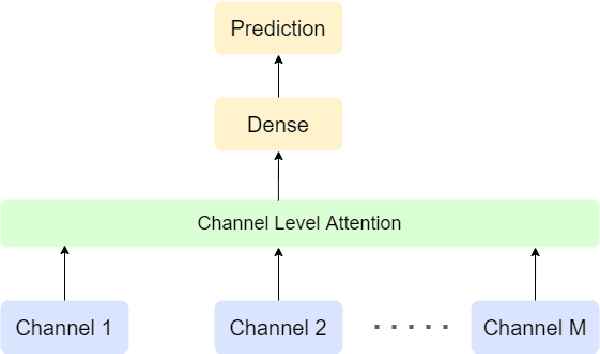
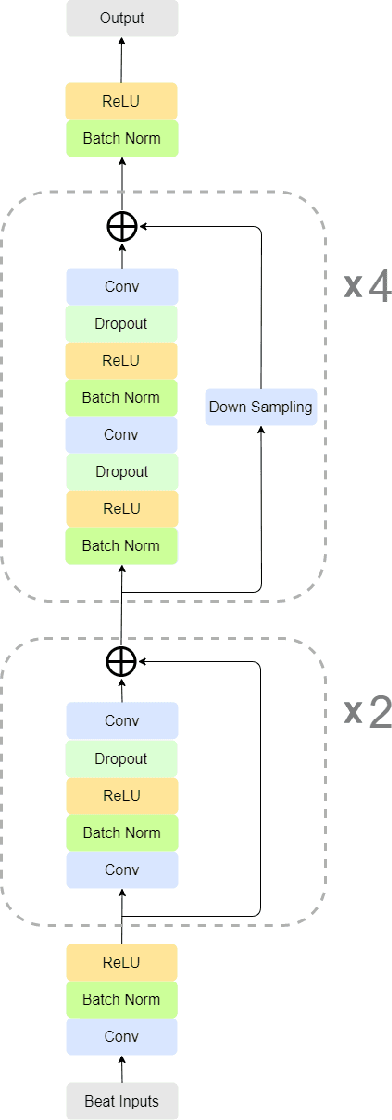

Early detection of cardiovascular diseases is crucial for effective treatment and an electrocardiogram (ECG) is pivotal for diagnosis. The accuracy of Deep Learning based methods for ECG signal classification has progressed in recent years to reach cardiologist-level performance. In clinical settings, a cardiologist makes a diagnosis based on the standard 12-channel ECG recording. Automatic analysis of ECG recordings from a multiple-channel perspective has not been given enough attention, so it is essential to analyze an ECG recording from a multiple-channel perspective. We propose a model that leverages the multiple-channel information available in the standard 12-channel ECG recordings and learns patterns at the beat, rhythm, and channel level. The experimental results show that our model achieved a macro-averaged ROC-AUC score of 0.9216, mean accuracy of 88.85\%, and a maximum F1 score of 0.8057 on the PTB-XL dataset. The attention visualization results from the interpretable model are compared against the cardiologist's guidelines to validate the correctness and usability.
From Generalisation Error to Transportation-cost Inequalities and Back
Feb 08, 2022In this work, we connect the problem of bounding the expected generalisation error with transportation-cost inequalities. Exposing the underlying pattern behind both approaches we are able to generalise them and go beyond Kullback-Leibler Divergences/Mutual Information and sub-Gaussian measures. In particular, we are able to provide a result showing the equivalence between two families of inequalities: one involving functionals and one involving measures. This result generalises the one proposed by Bobkov and G\"otze that connects transportation-cost inequalities with concentration of measure. Moreover, it allows us to recover all standard generalisation error bounds involving mutual information and to introduce new, more general bounds, that involve arbitrary divergence measures.
Email Spam Detection Using Hierarchical Attention Hybrid Deep Learning Method
Apr 15, 2022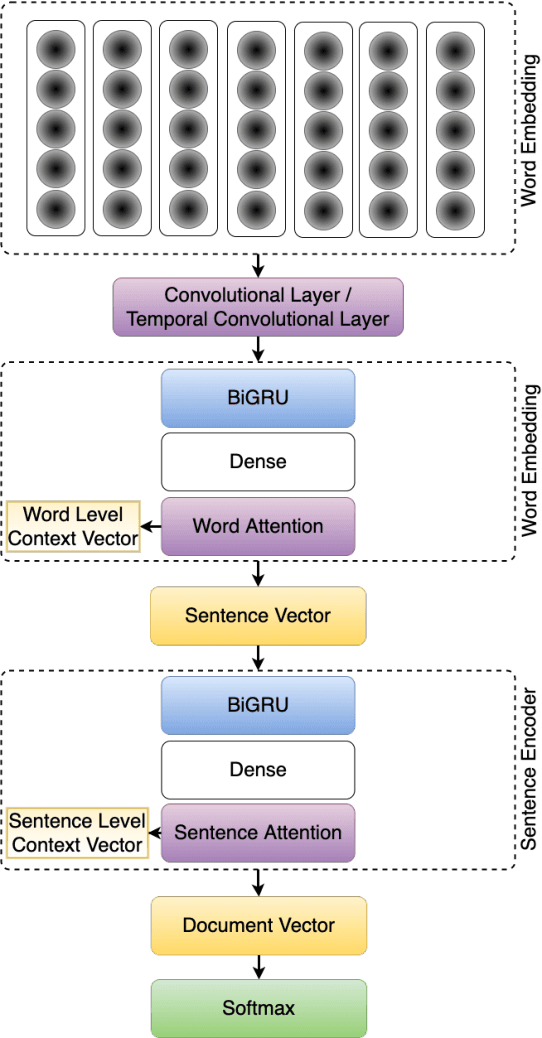
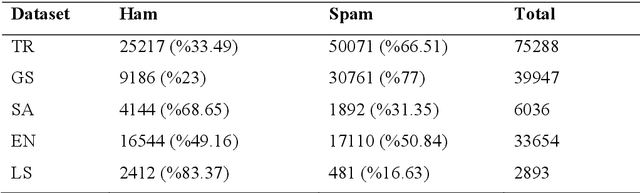
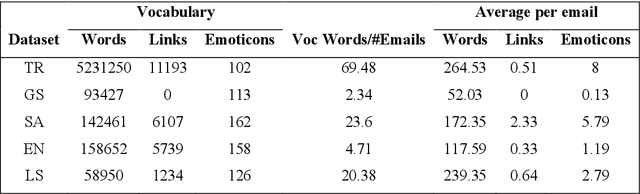
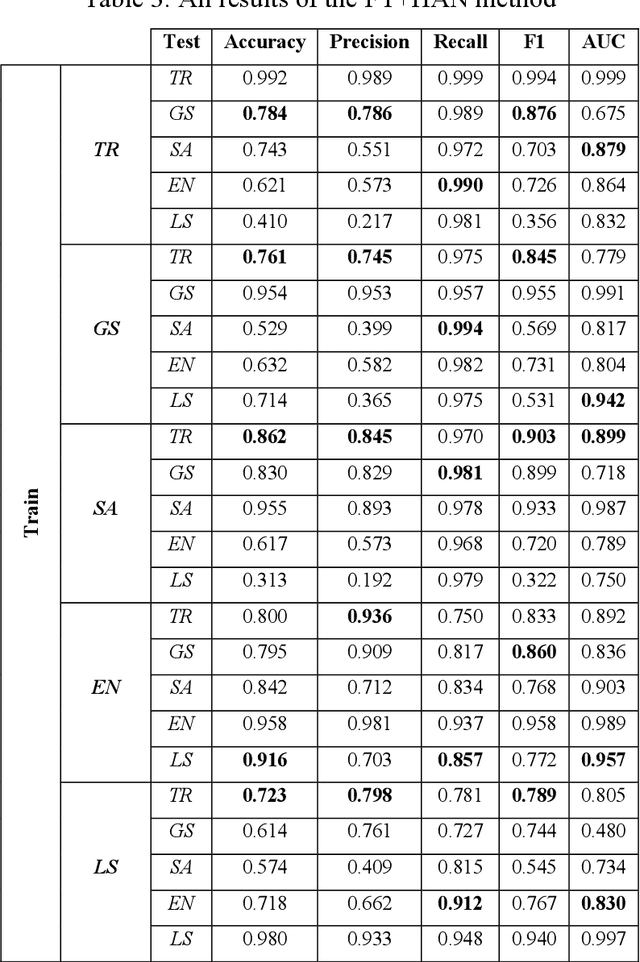
Email is one of the most widely used ways to communicate, with millions of people and businesses relying on it to communicate and share knowledge and information on a daily basis. Nevertheless, the rise in email users has occurred a dramatic increase in spam emails in recent years. Processing and managing emails properly for individuals and companies are getting increasingly difficult. This article proposes a novel technique for email spam detection that is based on a combination of convolutional neural networks, gated recurrent units, and attention mechanisms. During system training, the network is selectively focused on necessary parts of the email text. The usage of convolution layers to extract more meaningful, abstract, and generalizable features by hierarchical representation is the major contribution of this study. Additionally, this contribution incorporates cross-dataset evaluation, which enables the generation of more independent performance results from the model's training dataset. According to cross-dataset evaluation results, the proposed technique advances the results of the present attention-based techniques by utilizing temporal convolutions, which give us more flexible receptive field sizes are utilized. The suggested technique's findings are compared to those of state-of-the-art models and show that our approach outperforms them.
SUMD: Super U-shaped Matrix Decomposition Convolutional neural network for Image denoising
Apr 11, 2022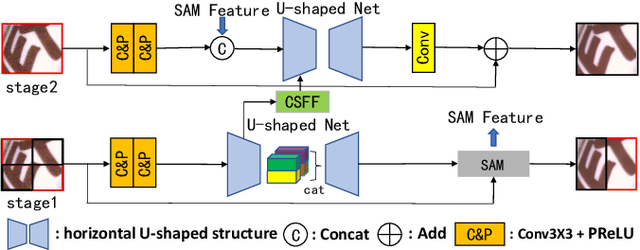
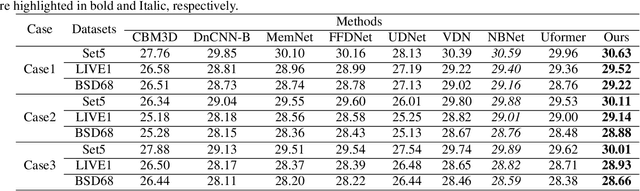
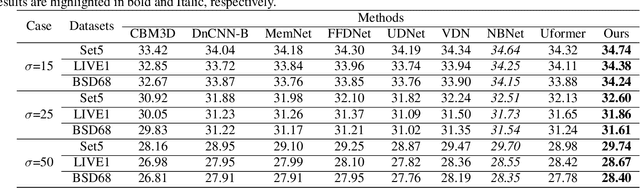
In this paper, we propose a novel and efficient CNN-based framework that leverages local and global context information for image denoising. Due to the limitations of convolution itself, the CNN-based method is generally unable to construct an effective and structured global feature representation, usually called the long-distance dependencies in the Transformer-based method. To tackle this problem, we introduce the matrix decomposition module(MD) in the network to establish the global context feature, comparable to the Transformer based method performance. Inspired by the design of multi-stage progressive restoration of U-shaped architecture, we further integrate the MD module into the multi-branches to acquire the relative global feature representation of the patch range at the current stage. Then, the stage input gradually rises to the overall scope and continuously improves the final feature. Experimental results on various image denoising datasets: SIDD, DND, and synthetic Gaussian noise datasets show that our model(SUMD) can produce comparable visual quality and accuracy results with Transformer-based methods.
User-controllable Recommendation Against Filter Bubbles
Apr 29, 2022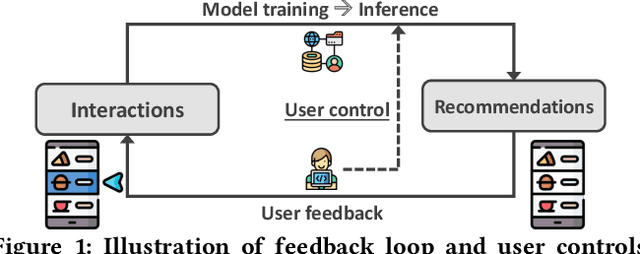
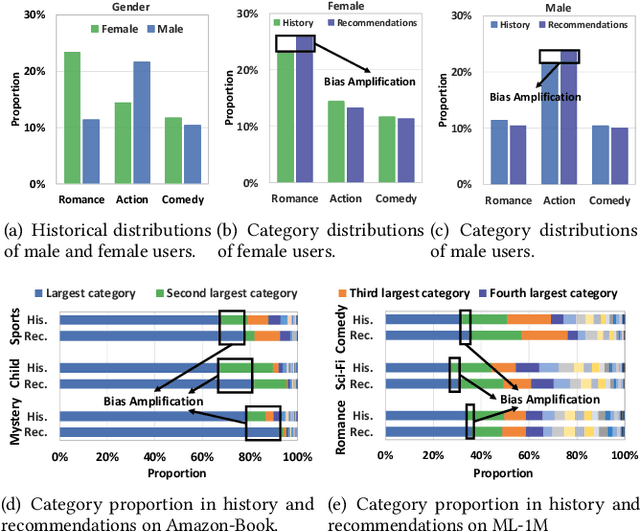
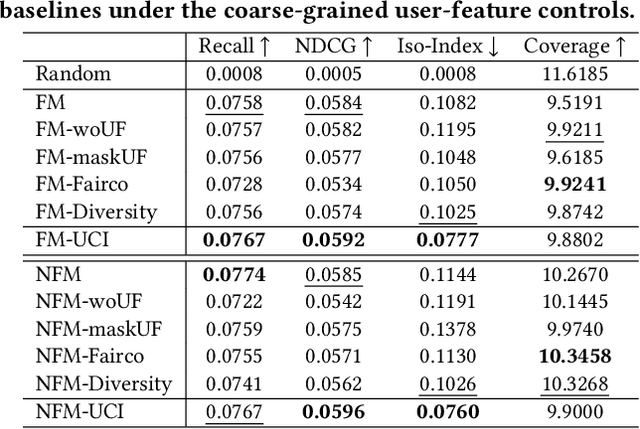
Recommender systems usually face the issue of filter bubbles: overrecommending homogeneous items based on user features and historical interactions. Filter bubbles will grow along the feedback loop and inadvertently narrow user interests. Existing work usually mitigates filter bubbles by incorporating objectives apart from accuracy such as diversity and fairness. However, they typically sacrifice accuracy, hurting model fidelity and user experience. Worse still, users have to passively accept the recommendation strategy and influence the system in an inefficient manner with high latency, e.g., keeping providing feedback (e.g., like and dislike) until the system recognizes the user intention. This work proposes a new recommender prototype called UserControllable Recommender System (UCRS), which enables users to actively control the mitigation of filter bubbles. Functionally, 1) UCRS can alert users if they are deeply stuck in filter bubbles. 2) UCRS supports four kinds of control commands for users to mitigate the bubbles at different granularities. 3) UCRS can respond to the controls and adjust the recommendations on the fly. The key to adjusting lies in blocking the effect of out-of-date user representations on recommendations, which contains historical information inconsistent with the control commands. As such, we develop a causality-enhanced User-Controllable Inference (UCI) framework, which can quickly revise the recommendations based on user controls in the inference stage and utilize counterfactual inference to mitigate the effect of out-of-date user representations. Experiments on three datasets validate that the UCI framework can effectively recommend more desired items based on user controls, showing promising performance w.r.t. both accuracy and diversity.
* Accepted by SIGIR 2022
PETR: Position Embedding Transformation for Multi-View 3D Object Detection
Mar 10, 2022
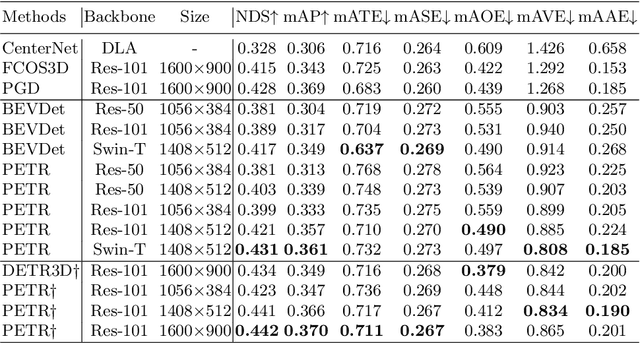
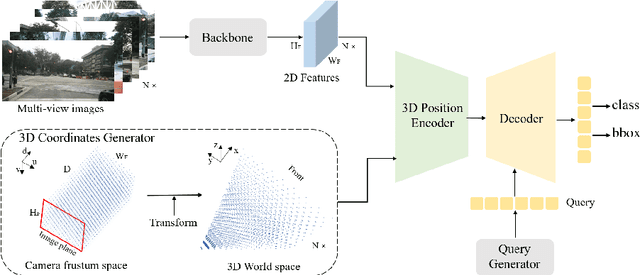
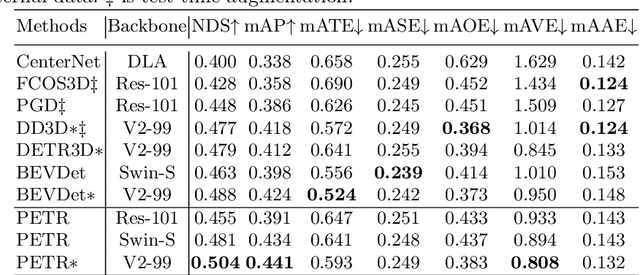
In this paper, we develop position embedding transformation (PETR) for multi-view 3D object detection. PETR encodes the position information of 3D coordinates into image features, producing the 3D position-aware features. Object query can perceive the 3D position-aware features and perform end-to-end object detection. PETR achieves state-of-the-art performance (50.4% NDS and 44.1% mAP) on standard nuScenes dataset and ranks 1st place on the benchmark. It can serve as a simple yet strong baseline for future research.
MVSTER: Epipolar Transformer for Efficient Multi-View Stereo
Apr 15, 2022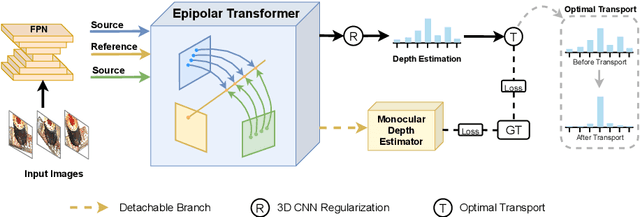
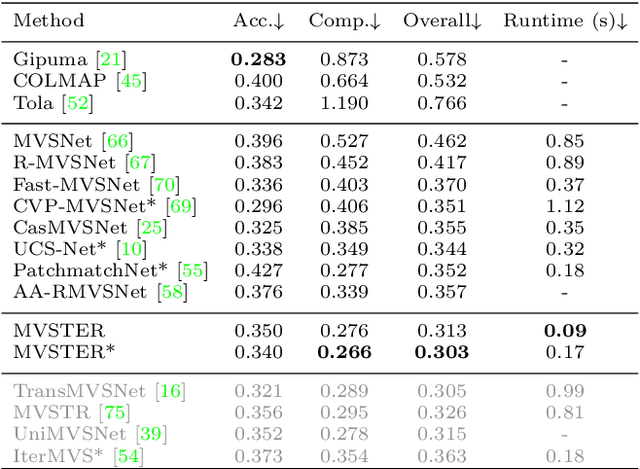

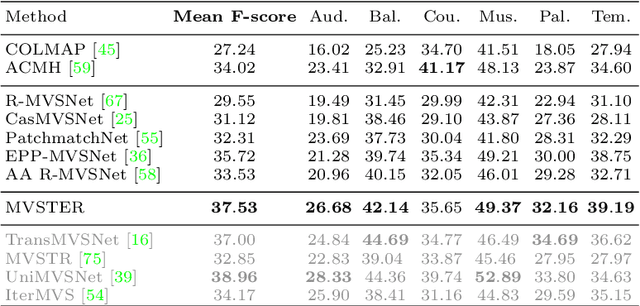
Learning-based Multi-View Stereo (MVS) methods warp source images into the reference camera frustum to form 3D volumes, which are fused as a cost volume to be regularized by subsequent networks. The fusing step plays a vital role in bridging 2D semantics and 3D spatial associations. However, previous methods utilize extra networks to learn 2D information as fusing cues, underusing 3D spatial correlations and bringing additional computation costs. Therefore, we present MVSTER, which leverages the proposed epipolar Transformer to learn both 2D semantics and 3D spatial associations efficiently. Specifically, the epipolar Transformer utilizes a detachable monocular depth estimator to enhance 2D semantics and uses cross-attention to construct data-dependent 3D associations along epipolar line. Additionally, MVSTER is built in a cascade structure, where entropy-regularized optimal transport is leveraged to propagate finer depth estimations in each stage. Extensive experiments show MVSTER achieves state-of-the-art reconstruction performance with significantly higher efficiency: Compared with MVSNet and CasMVSNet, our MVSTER achieves 34% and 14% relative improvements on the DTU benchmark, with 80% and 51% relative reductions in running time. MVSTER also ranks first on Tanks&Temples-Advanced among all published works. Code is released at https://github.com/JeffWang987.
An Unsupervised Sampling Approach for Image-Sentence Matching Using Document-Level Structural Information
Mar 21, 2021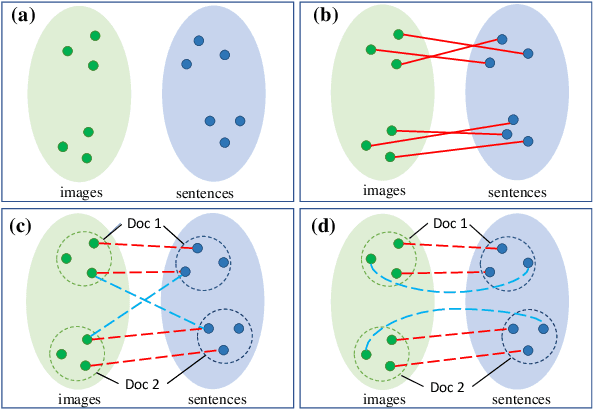

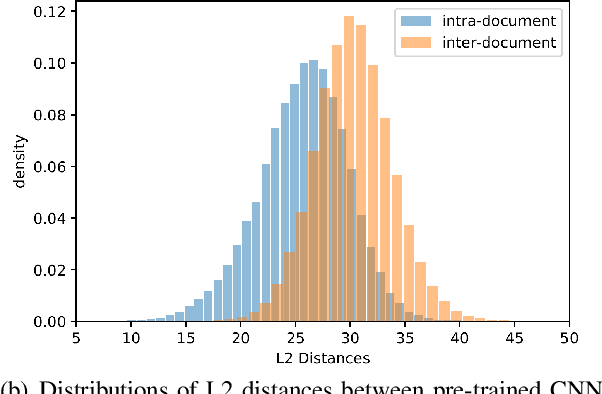
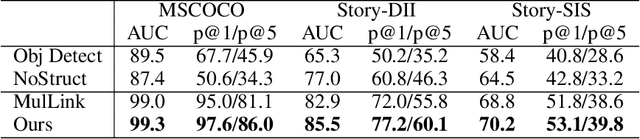
In this paper, we focus on the problem of unsupervised image-sentence matching. Existing research explores to utilize document-level structural information to sample positive and negative instances for model training. Although the approach achieves positive results, it introduces a sampling bias and fails to distinguish instances with high semantic similarity. To alleviate the bias, we propose a new sampling strategy to select additional intra-document image-sentence pairs as positive or negative samples. Furthermore, to recognize the complex pattern in intra-document samples, we propose a Transformer based model to capture fine-grained features and implicitly construct a graph for each document, where concepts in a document are introduced to bridge the representation learning of images and sentences in the context of a document. Experimental results show the effectiveness of our approach to alleviate the bias and learn well-aligned multimodal representations.
Hypergraph Convolutional Networks via Equivalency between Hypergraphs and Undirected Graphs
Apr 06, 2022
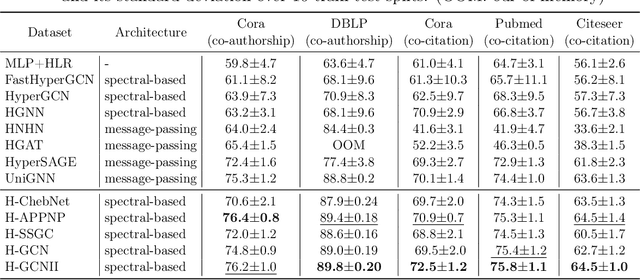

As a powerful tool for modeling complex relationships, hypergraphs are gaining popularity from the graph learning community. However, commonly used frameworks in deep hypergraph learning focus on hypergraphs with \textit{edge-independent vertex weights}(EIVWs), without considering hypergraphs with \textit{edge-dependent vertex weights} (EDVWs) that have more modeling power. To compensate for this, in this paper, we present General Hypergraph Spectral Convolution(GHSC), a general learning framework that not only can handle EDVW and EIVW hypergraphs, but more importantly, enables theoretically explicitly utilizing the existing powerful Graph Convolutional Neural Networks (GCNNs) such that largely ease the design of Hypergraph Neural Networks. In this framework, the graph Laplacian of the given undirected GCNNs is replaced with a unified hypergraph Laplacian that incorporates vertex weight information from a random walk perspective by equating our defined generalized hypergraphs with simple undirected graphs. Extensive experiments from various domains including social network analysis, visual objective classification, protein learning demonstrate that the proposed framework can achieve state-of-the-art performance.
Blockchain as an Enabler for Transfer Learning in Smart Environments
Apr 11, 2022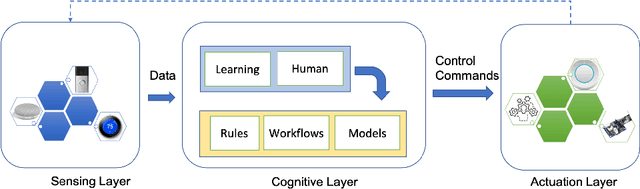
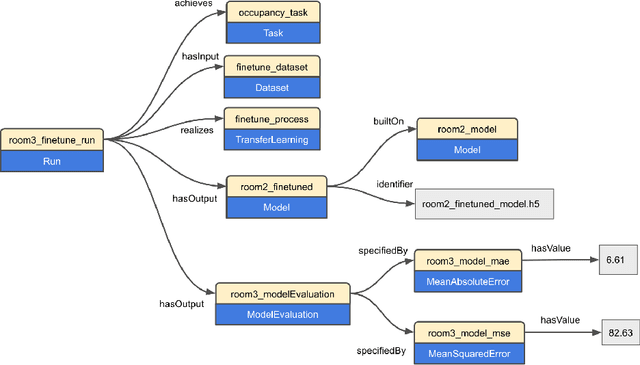
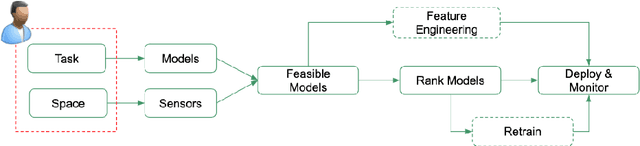
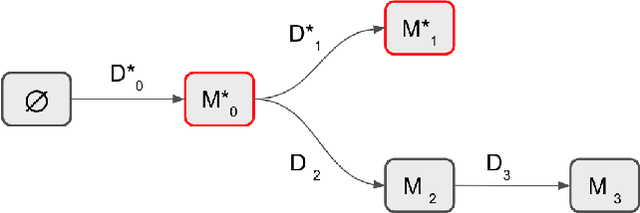
The knowledge, embodied in machine learning models for intelligent systems, is commonly associated with time-consuming and costly processes such as large-scale data collection, data labelling, network training, and fine-tuning of models. Sharing and reuse of these elaborated models between intelligent systems deployed in a different environment, which is known as transfer learning, would facilitate the adoption of services for the users and accelerates the uptake of intelligent systems in environments such as smart building and smart city applications. In this context, the communication and knowledge exchange between AI-enabled environments depend on a complicated networks of systems, system of systems, digital assets, and their chain of dependencies that hardly follows the centralized schema of traditional information systems. Rather, it requires an adaptive decentralized system architecture that is empowered by features such as data provenance, workflow transparency, and validation of process participants. In this research, we propose a decentralized and adaptive software framework based on blockchain and knowledge graph technologies that supports the knowledge exchange and interoperability between IoT-enabled environments, in a transparent and trustworthy way.