 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cylin-Painting: Seamless 360° Panoramic Image Outpainting and Beyond with Cylinder-Style Convolutions
Apr 18, 2022
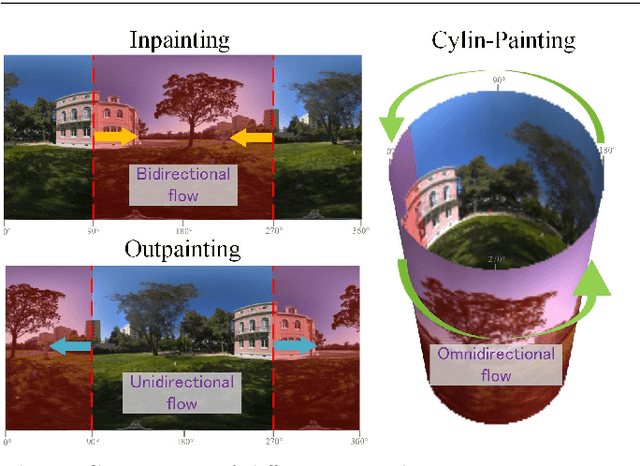
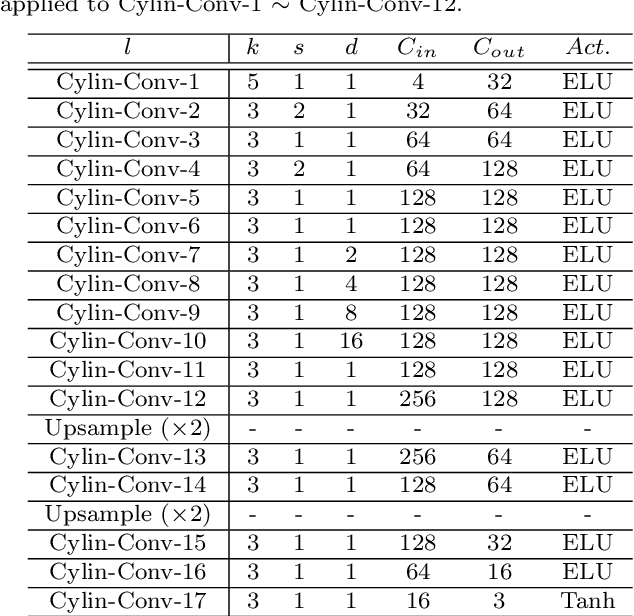
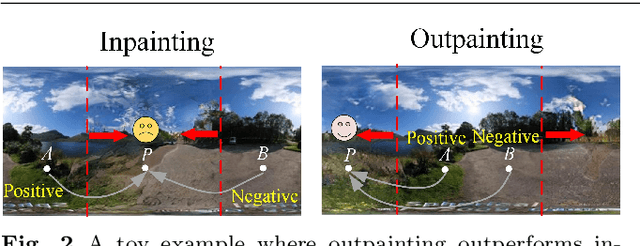
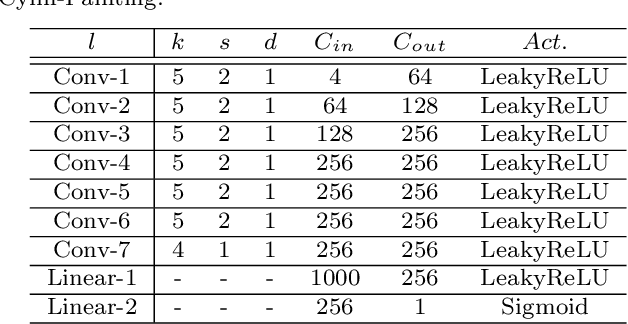
Image outpainting gains increasing attention since it can generate the complete scene from a partial view, providing a valuable solution to construct 360{\deg} panoramic images. As image outpainting suffers from the intrinsic issue of unidirectional completion flow, previous methods convert the original problem into inpainting, which allows a bidirectional flow. However, we find that inpainting has its own limitations and is inferior to outpainting in certain situations. The question of how they may be combined for the best of both has as yet remained under-explored. In this paper, we provide a deep analysis of the differences between inpainting and outpainting, which essentially depends on how the source pixels contribute to the unknown regions under different spatial arrangements. Motivated by this analysis, we present a Cylin-Painting framework that involves meaningful collaborations between inpainting and outpainting and efficiently fuses the different arrangements, with a view to leveraging their complementary benefits on a consistent and seamless cylinder. Nevertheless, directly applying the cylinder-style convolution often generates visually unpleasing results as it could discard important positional information. To address this issue, we further present a learnable positional embedding strategy and incorporate the missing component of positional encoding into the cylinder convolution, which significantly improves the panoramic results. Note that while developed for image outpainting, the proposed solution can be effectively extended to other panoramic vision tasks, such as object detection, depth estimation, and image super resolution.
Scalable and Real-time Multi-Camera Vehicle Detection, Re-Identification, and Tracking
Apr 15, 2022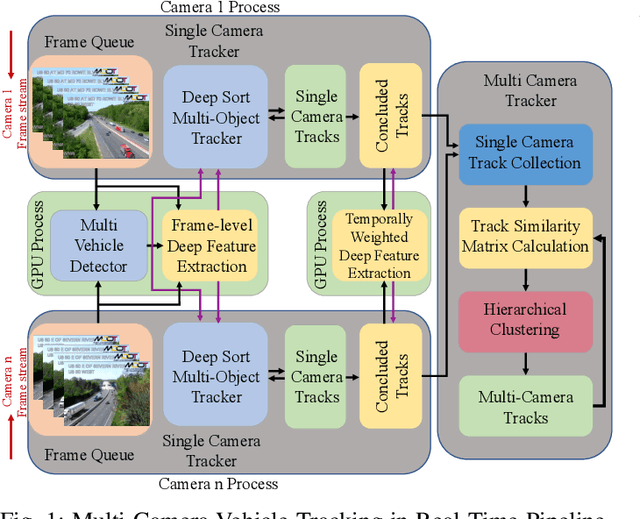

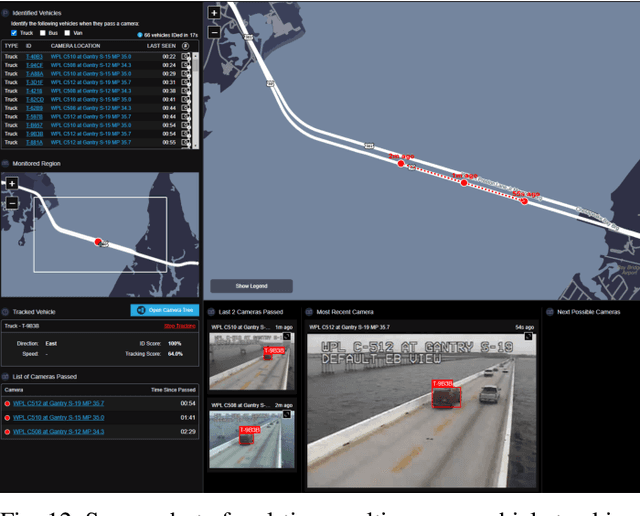
Multi-camera vehicle tracking is one of the most complicated tasks in Computer Vision as it involves distinct tasks including Vehicle Detection, Tracking, and Re-identification. Despite the challenges, multi-camera vehicle tracking has immense potential in transportation applications including speed, volume, origin-destination (O-D), and routing data generation. Several recent works have addressed the multi-camera tracking problem. However, most of the effort has gone towards improving accuracy on high-quality benchmark datasets while disregarding lower camera resolutions, compression artifacts and the overwhelming amount of computational power and time needed to carry out this task on its edge and thus making it prohibitive for large-scale and real-time deployment. Therefore, in this work we shed light on practical issues that should be addressed for the design of a multi-camera tracking system to provide actionable and timely insights. Moreover, we propose a real-time city-scale multi-camera vehicle tracking system that compares favorably to computationally intensive alternatives and handles real-world, low-resolution CCTV instead of idealized and curated video streams. To show its effectiveness, in addition to integration into the Regional Integrated Transportation Information System (RITIS), we participated in the 2021 NVIDIA AI City multi-camera tracking challenge and our method is ranked among the top five performers on the public leaderboard.
Auto-MLM: Improved Contrastive Learning for Self-supervised Multi-lingual Knowledge Retrieval
Mar 30, 2022

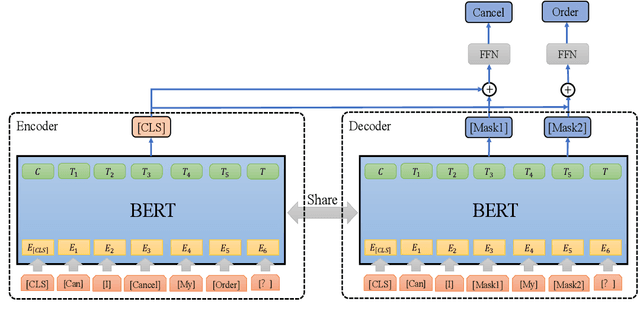
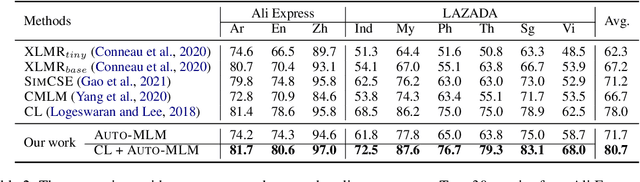
Contrastive learning (CL) has become a ubiquitous approach for several natural language processing (NLP) downstream tasks, especially for question answering (QA). However, the major challenge, how to efficiently train the knowledge retrieval model in an unsupervised manner, is still unresolved. Recently the commonly used methods are composed of CL and masked language model (MLM). Unexpectedly, MLM ignores the sentence-level training, and CL also neglects extraction of the internal info from the query. To optimize the CL hardly obtain internal information from the original query, we introduce a joint training method by combining CL and Auto-MLM for self-supervised multi-lingual knowledge retrieval. First, we acquire the fixed dimensional sentence vector. Then, mask some words among the original sentences with random strategy. Finally, we generate a new token representation for predicting the masked tokens. Experimental results show that our proposed approach consistently outperforms all the previous SOTA methods on both AliExpress $\&$ LAZADA service corpus and openly available corpora in 8 languages.
VSA: Learning Varied-Size Window Attention in Vision Transformers
Apr 18, 2022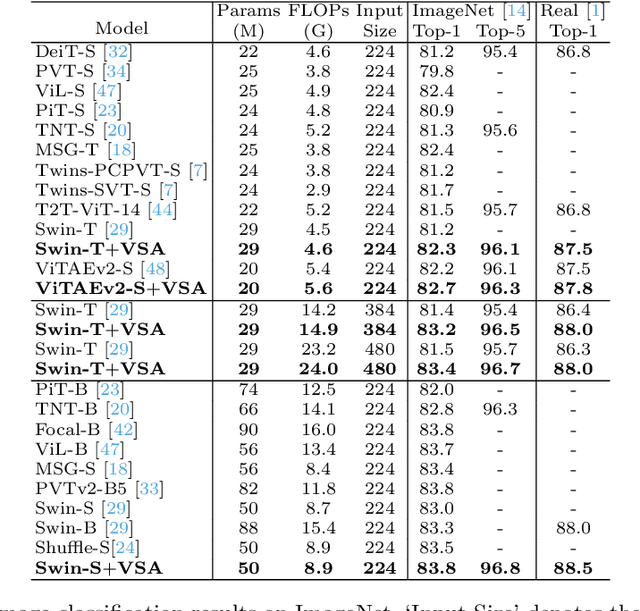
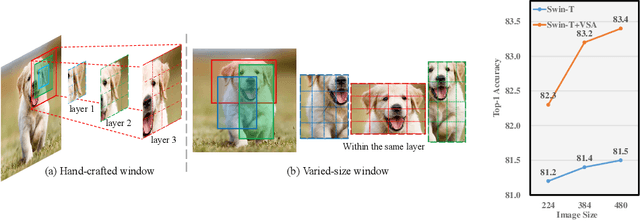
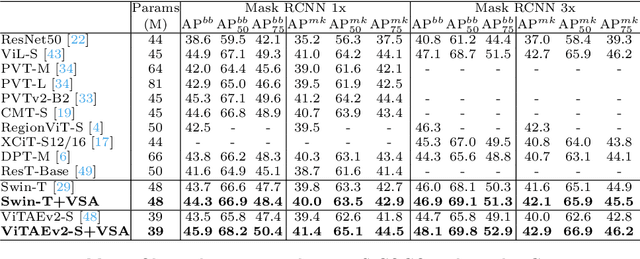
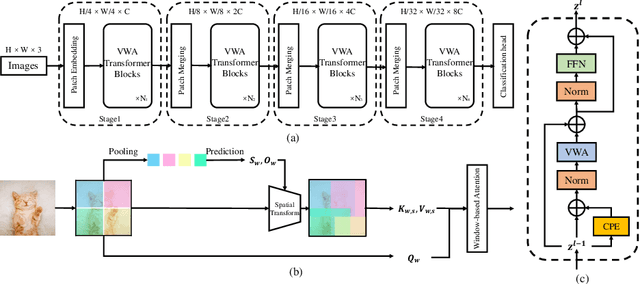
Attention within windows has been widely explored in vision transformers to balance the performance, computation complexity, and memory footprint. However, current models adopt a hand-crafted fixed-size window design, which restricts their capacity of modeling long-term dependencies and adapting to objects of different sizes. To address this drawback, we propose \textbf{V}aried-\textbf{S}ize Window \textbf{A}ttention (VSA) to learn adaptive window configurations from data. Specifically, based on the tokens within each default window, VSA employs a window regression module to predict the size and location of the target window, i.e., the attention area where the key and value tokens are sampled. By adopting VSA independently for each attention head, it can model long-term dependencies, capture rich context from diverse windows, and promote information exchange among overlapped windows. VSA is an easy-to-implement module that can replace the window attention in state-of-the-art representative models with minor modifications and negligible extra computational cost while improving their performance by a large margin, e.g., 1.1\% for Swin-T on ImageNet classification. In addition, the performance gain increases when using larger images for training and test. Experimental results on more downstream tasks, including object detection, instance segmentation, and semantic segmentation, further demonstrate the superiority of VSA over the vanilla window attention in dealing with objects of different sizes. The code will be released https://github.com/ViTAE-Transformer/ViTAE-VSA.
Extended vehicle energy dataset (eVED): an enhanced large-scale dataset for deep learning on vehicle trip energy consumption
Mar 16, 2022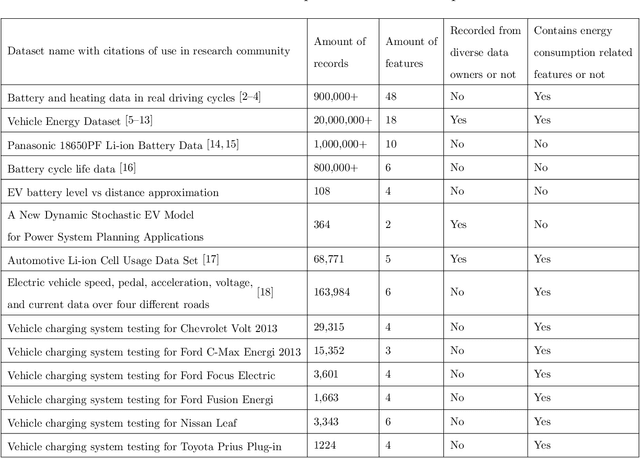
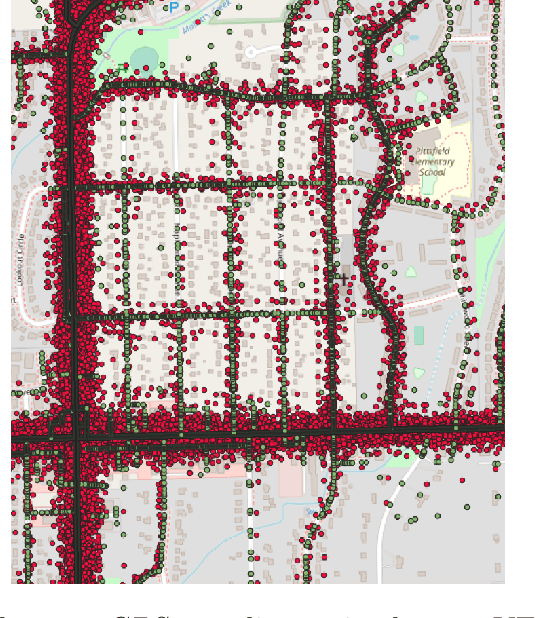

This work presents an extended version of the Vehicle Energy Dataset (VED), which is a openly released large-scale dataset for vehicle energy consumption analysis. Compared with its original version, the extended VED (eVED) dataset is enhanced with accurate vehicle trip GPS coordinates, serving as a basis to associate the VED trip records with external information, e.g., road speed limit and intersections, from accessible map services to accumulate attributes that is essential in analyzing vehicle energy consumption. In particularly, we calibrate all the GPS trace records in the original VED data, upon which we associated the VED data with attributes extracted from the Geographic Information System (QGIS), the Overpass API, the Open Street Map API, and Google Maps API. The associated attributes include 12,609,170 records of road elevation, 12,203,044 of speed limit, 12,281,719 of speed limit with direction (in case the road is bi-directional), 584,551 of intersections, 429,638 of bus stop, 312,196 of crossings, 195,856 of traffic signals, 29,397 of stop signs, 5,848 of turning loops, 4,053 of railway crossings (level crossing), 3,554 of turning circles, and 2,938 of motorway junctions. With the accurate GPS coordinates and enriched features of the vehicle trip record, the obtained eVED dataset can provide a precise and abundant medium to feed a learning engine, especially a deep learning engine that is more demanding on data sufficiency and richness. Moreover, our software work for data calibration and enrichment can be reused to generate further vehicle trip datasets for specific user cases, contributing to deep insights into vehicle behaviors and traffic dynamics analyses. We anticipate that the eVED dataset and our data enrichment software can serve the academic and industrial automotive section as apparatus in developing future technologies.
Bankruptcy Prediction via Mixing Intra-Risk and Spillover-Risk
Feb 12, 2022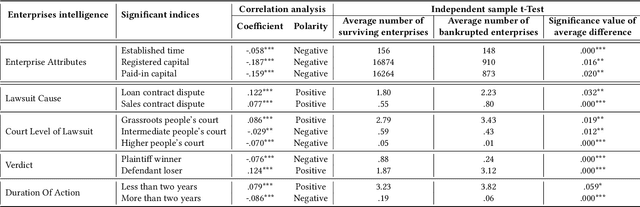
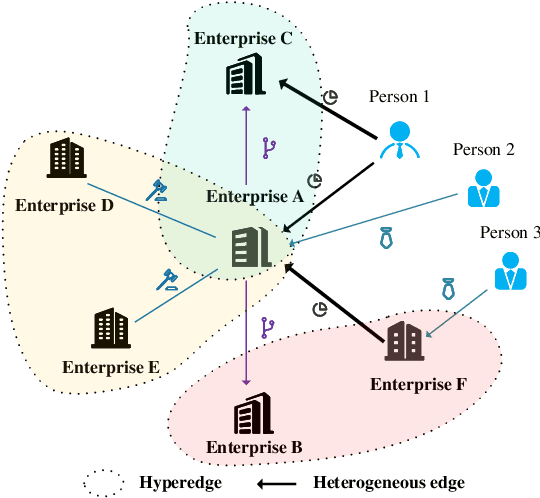
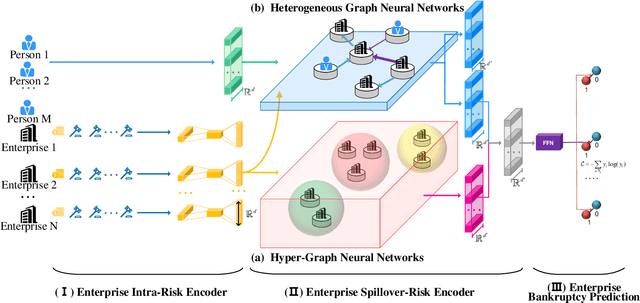
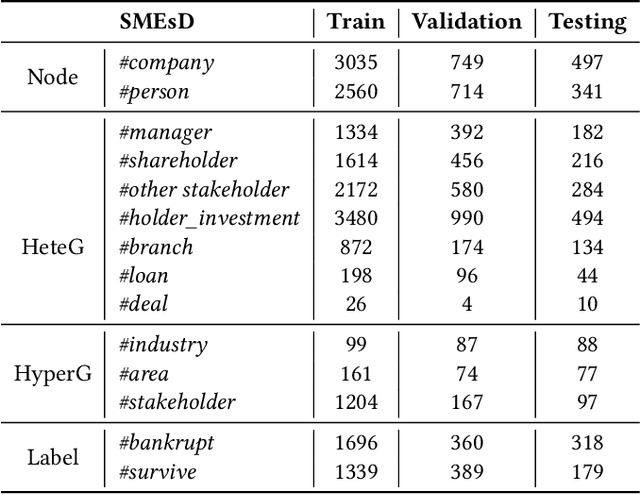
Bankruptcy risk prediction for Small and Medium-sized Enterprises (SMEs) is a crucial step for financial institutions to make the loan decision and identify region economics's early warning. However, previous studies in both finance and AI research fields only consider either the intra-risk or the spillover-risk, ignoring their interactions and their combinatorial effect for simplicity. This paper for the first time considers both risks simultaneously and their joint effect in bankruptcy prediction. Specifically, we first propose an enterprise intra-risk encoder with LSTM based on enterprise risk statistical significance indicators from its basic business information and litigation information for its intra-risk learning. Afterward, we propose an enterprise spillover-risk encoder based on enterprise relational information from the enterprise knowledge graph for its spillover-risk embedding. In particular, the spillover-risk encoder is equipped with both the newly proposed Hyper-Graph Neural Networks (Hyper-GNNs) and Heterogeneous Graph Neural Networks (Heter-GNNs), which is able to model spillover risk from two different aspects, i.e. common risk factors based on hyperedges and direct diffusion risk from the neighbors, respectively. With the two kinds of encoders, a unified framework is designed to simultaneously capture intra-risk and spillover-risk for bankruptcy prediction. To evaluate our model, we collect multi-sources SMEs real-world data and build a novel benchmark dataset SMEsD. We provide open access to the dataset, which is expected to promote the financial risk analysis research further. Experiments on SMEsD against nine SOTA baselines demonstrate the effectiveness of the proposed model for bankruptcy prediction.
Evaluating a Generative Adversarial Framework for Information Retrieval
Oct 01, 2020
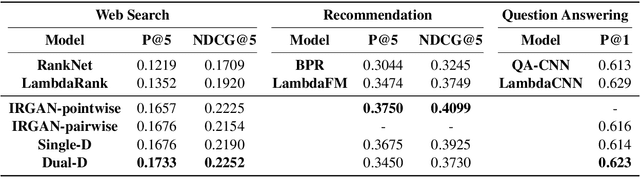
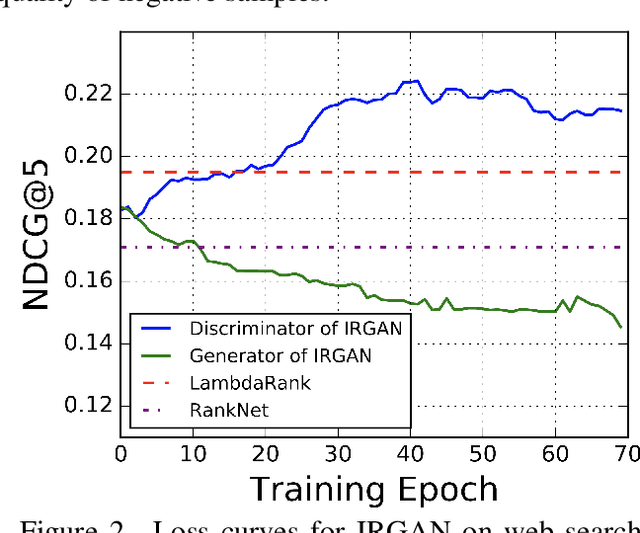

Recent advances in Generative Adversarial Networks (GANs) have resulted in its widespread applications to multiple domains. A recent model, IRGAN, applies this framework to Information Retrieval (IR) and has gained significant attention over the last few years. In this focused work, we critically analyze multiple components of IRGAN, while providing experimental and theoretical evidence of some of its shortcomings. Specifically, we identify issues with the constant baseline term in the policy gradients optimization and show that the generator harms IRGAN's performance. Motivated by our findings, we propose two models influenced by self-contrastive estimation and co-training which outperform IRGAN on two out of the three tasks considered.
Automated Data Augmentations for Graph Classification
Mar 19, 2022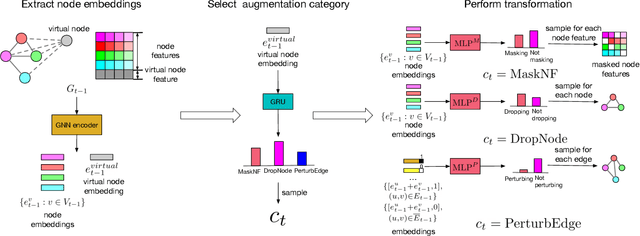
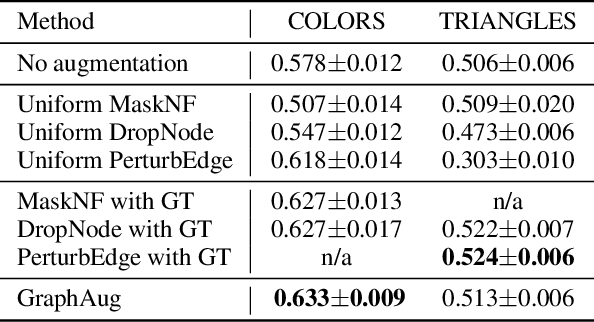
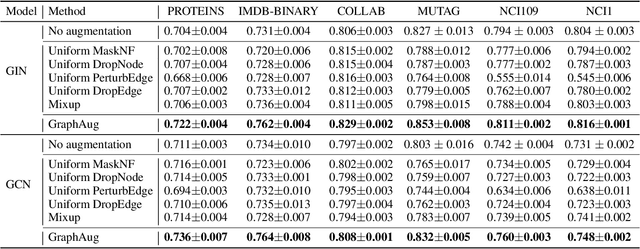
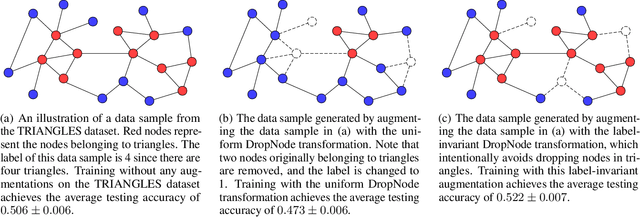
Data augmentations are effective in improving the invariance of learning machines. We argue that the corechallenge of data augmentations lies in designing data transformations that preserve labels. This is relativelystraightforward for images, but much more challenging for graphs. In this work, we propose GraphAug, a novelautomated data augmentation method aiming at computing label-invariant augmentations for graph classification.Instead of using uniform transformations as in existing studies, GraphAug uses an automated augmentationmodel to avoid compromising critical label-related information of the graph, thereby producing label-invariantaugmentations at most times. To ensure label-invariance, we develop a training method based on reinforcementlearning to maximize an estimated label-invariance probability. Comprehensive experiments show that GraphAugoutperforms previous graph augmentation methods on various graph classification tasks.
Intelligent Sight and Sound: A Chronic Cancer Pain Dataset
Apr 07, 2022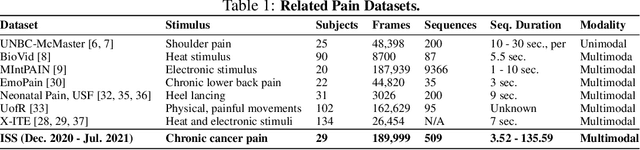
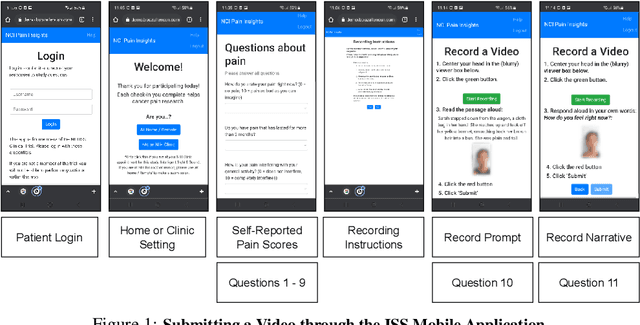
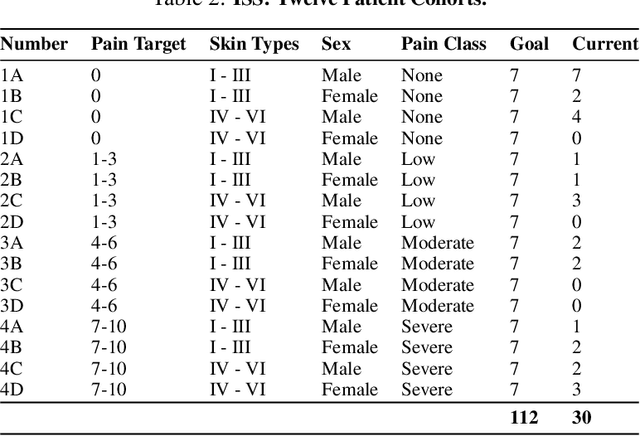

Cancer patients experience high rates of chronic pain throughout the treatment process. Assessing pain for this patient population is a vital component of psychological and functional well-being, as it can cause a rapid deterioration of quality of life. Existing work in facial pain detection often have deficiencies in labeling or methodology that prevent them from being clinically relevant. This paper introduces the first chronic cancer pain dataset, collected as part of the Intelligent Sight and Sound (ISS) clinical trial, guided by clinicians to help ensure that model findings yield clinically relevant results. The data collected to date consists of 29 patients, 509 smartphone videos, 189,999 frames, and self-reported affective and activity pain scores adopted from the Brief Pain Inventory (BPI). Using static images and multi-modal data to predict self-reported pain levels, early models show significant gaps between current methods available to predict pain today, with room for improvement. Due to the especially sensitive nature of the inherent Personally Identifiable Information (PII) of facial images, the dataset will be released under the guidance and control of the National Institutes of Health (NIH).
Calculate the Optimum Threshold for Double Energy Detection Technique in Cognitive Radio Networks (CRNs)
Apr 15, 2022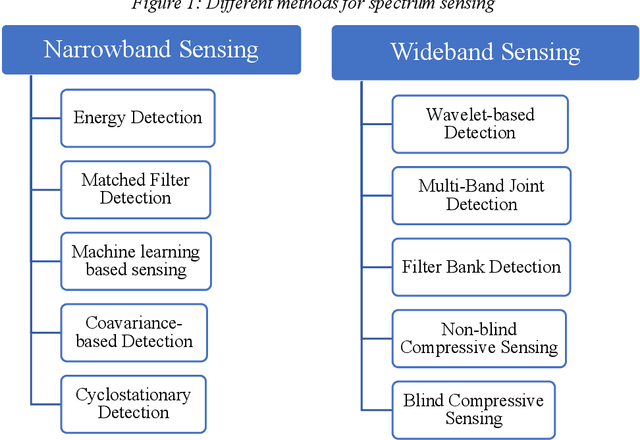
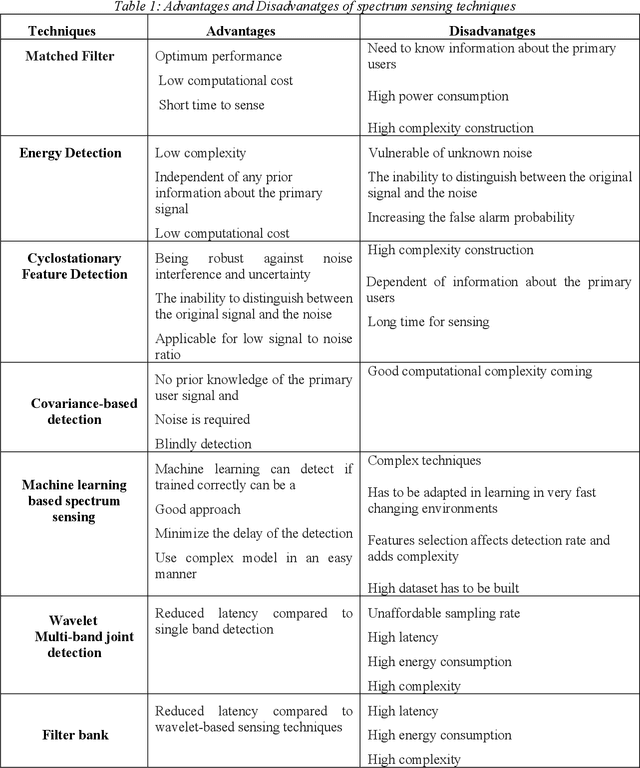

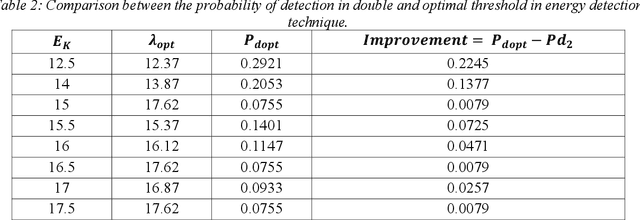
One of the most important technical challenges when designing a Cognitive Radio Networks (CRNs) is spectrum sensing, which has the responsibility of recognizing the presence or absence of the primary users in the frequency bands. A common technique used for spectrum sensing is double energy detection since it can operate without any prior information regarding the characteristics of the primary user signals. A double threshold energy detection algorithm is based on the use of two thresholds, to check the energy of the received signals and decided whether the spectrum is occupied or not. Furthermore, thresholds play a key role in the energy detection algorithm, by considering the stochastic features of noise in this model, as a result calculating the optimal threshold is a crucial task. In this paper, the Bi-Section algorithm was used to detect the optimum energy level in the fuzzy region which is an area between the low and high energy threshold. For this purpose, the decision threshold was determined by the use of the Bisection function for cognitive users. Numerical simulations show that the proposed method achieves better detection performance than the conventional double-threshold energy-sensing schemes. Moreover, the presented technique has advantages such as increasing the probability of detection of primary users and decreasing the probability of Collison between primary and secondary users.