 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automatic Detection of Expressed Emotion from Five-Minute Speech Samples: Challenges and Opportunities
Mar 30, 2022
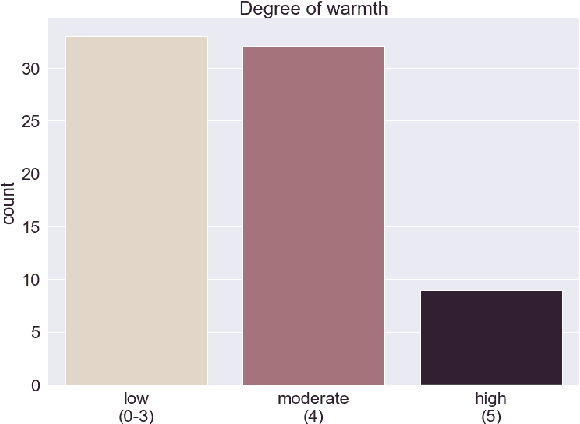
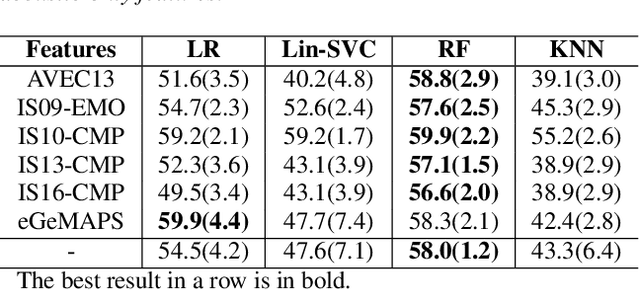
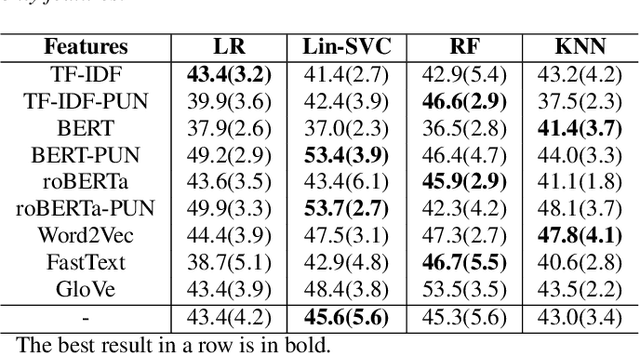
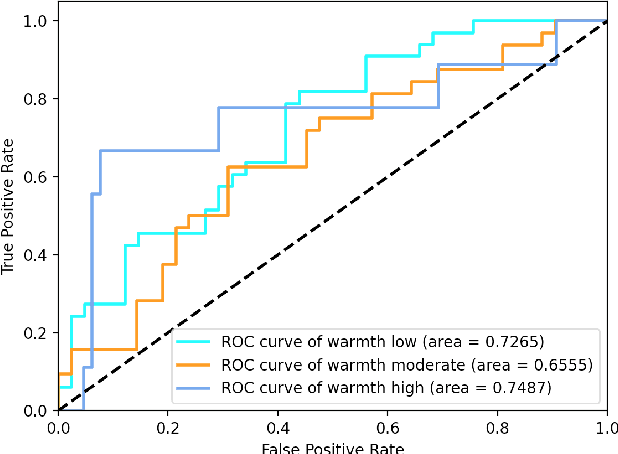
We present a novel feasibility study on the automatic recognition of Expressed Emotion (EE), a family environment concept based on caregivers speaking freely about their relative/family member. We describe an automated approach for determining the \textit{degree of warmth}, a key component of EE, from acoustic and text features acquired from a sample of 37 recorded interviews. These recordings, collected over 20 years ago, are derived from a nationally representative birth cohort of 2,232 British twin children and were manually coded for EE. We outline the core steps of extracting usable information from recordings with highly variable audio quality and assess the efficacy of four machine learning approaches trained with different combinations of acoustic and text features. Despite the challenges of working with this legacy data, we demonstrated that the degree of warmth can be predicted with an $F_{1}$-score of \textbf{61.5\%}. In this paper, we summarise our learning and provide recommendations for future work using real-world speech samples.
Lensless coherent diffraction imaging based on spatial light modulator with unknown modulation curve
Apr 08, 2022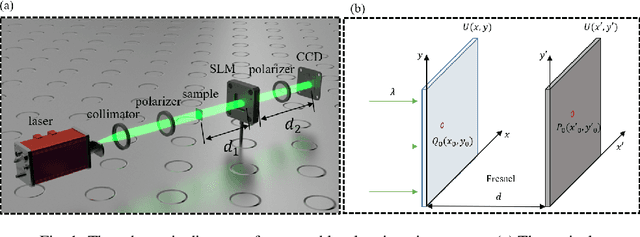


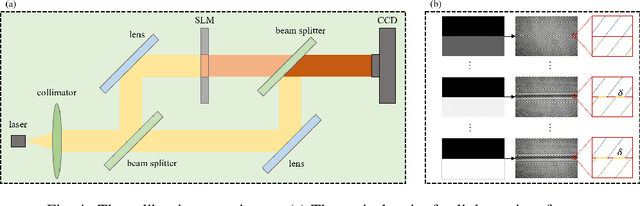
Lensless imaging is a popular research field for the advantages of small size, wide field-of-view and low aberration in recent years. However, some traditional lensless imaging methods suffer from slow convergence, mechanical errors and conjugate solution interference, which limit its further application and development. In this work, we proposed a lensless imaging method based on spatial light modulator (SLM) with unknown modulation curve. In our imaging system, we use SLM to modulate the wavefront of object, and introduce the ptychographic scanning algorithm that is able to recover the complex amplitude information even the SLM modulation curve is inaccurate or unknown. In addition, we also design a split-beam interference experiment to calibrate the modulation curve of SLM, and using the calibrated modulation function as the initial value of the expended ptychography iterative engine (ePIE) algorithm can improve the convergence speed. We further analyze the effect of modulation function, algorithm parameters and the characteristics of the coherent light source on the quality of reconstructed image. The simulated and real experiments show that the proposed method is superior to traditional mechanical scanning methods in terms of recovering speed and accuracy, with the recovering resolution up to 14 um.
CAT-Det: Contrastively Augmented Transformer for Multi-modal 3D Object Detection
Apr 04, 2022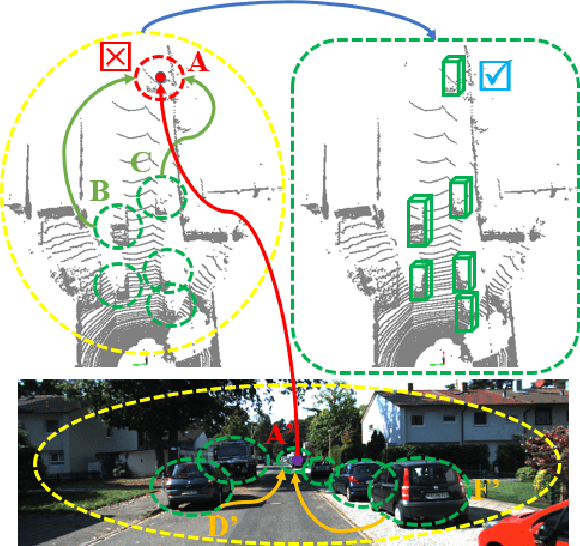
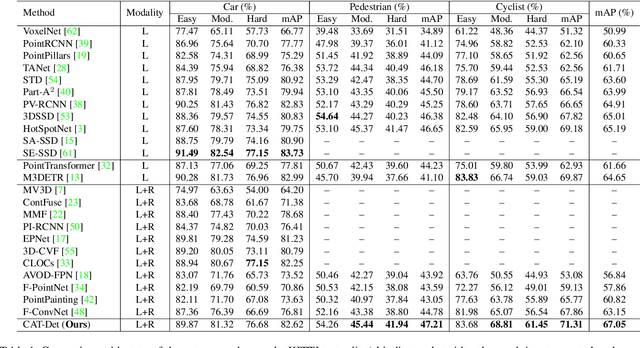
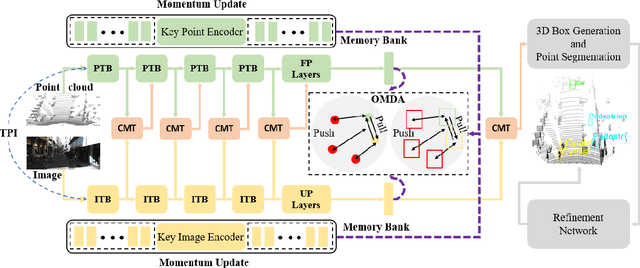
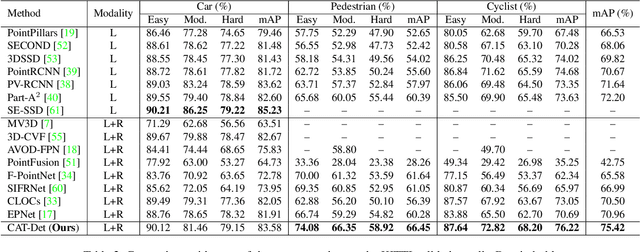
In autonomous driving, LiDAR point-clouds and RGB images are two major data modalities with complementary cues for 3D object detection. However, it is quite difficult to sufficiently use them, due to large inter-modal discrepancies. To address this issue, we propose a novel framework, namely Contrastively Augmented Transformer for multi-modal 3D object Detection (CAT-Det). Specifically, CAT-Det adopts a two-stream structure consisting of a Pointformer (PT) branch, an Imageformer (IT) branch along with a Cross-Modal Transformer (CMT) module. PT, IT and CMT jointly encode intra-modal and inter-modal long-range contexts for representing an object, thus fully exploring multi-modal information for detection. Furthermore, we propose an effective One-way Multi-modal Data Augmentation (OMDA) approach via hierarchical contrastive learning at both the point and object levels, significantly improving the accuracy only by augmenting point-clouds, which is free from complex generation of paired samples of the two modalities. Extensive experiments on the KITTI benchmark show that CAT-Det achieves a new state-of-the-art, highlighting its effectiveness.
Leveraging Temporal Information for 3D Detection and Domain Adaptation
Jun 30, 2020
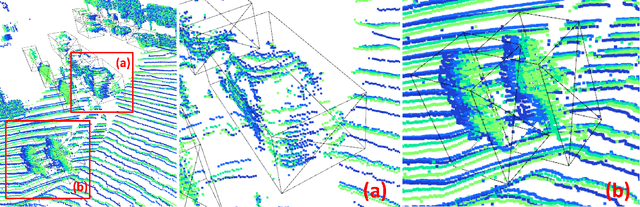

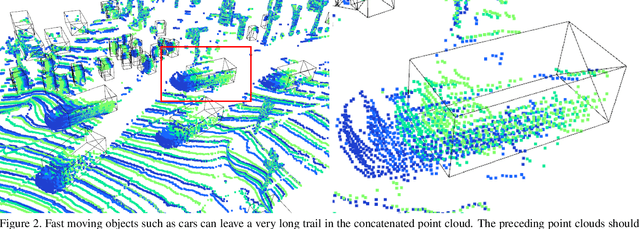
Ever since the prevalent use of the LiDARs in autonomous driving, tremendous improvements have been made to the learning on the point clouds. However, recent progress largely focuses on detecting objects in a single 360-degree sweep, without extensively exploring the temporal information. In this report, we describe a simple way to pass such information in the learning pipeline by adding timestamps to the point clouds, which shows consistent improvements across all three classes.
UTIL: An Ultra-wideband Time-difference-of-arrival Indoor Localization Dataset
Mar 28, 2022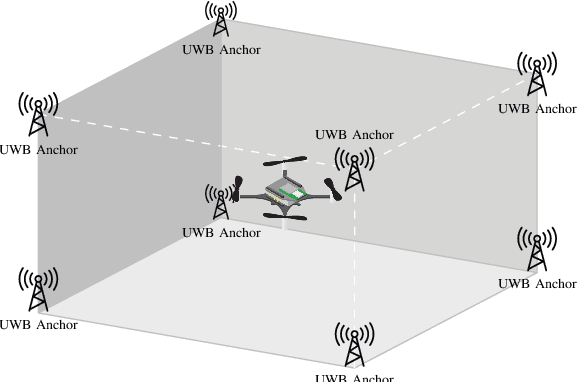
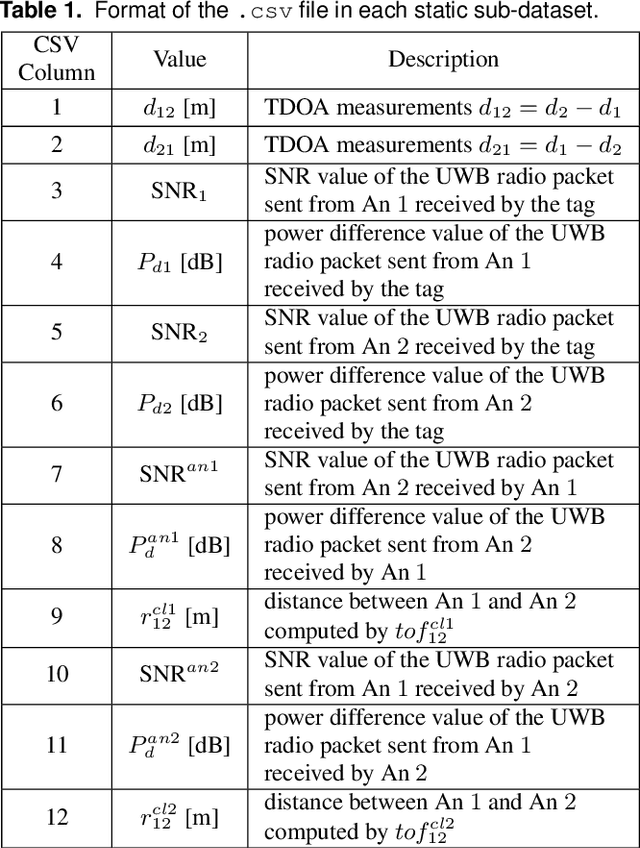
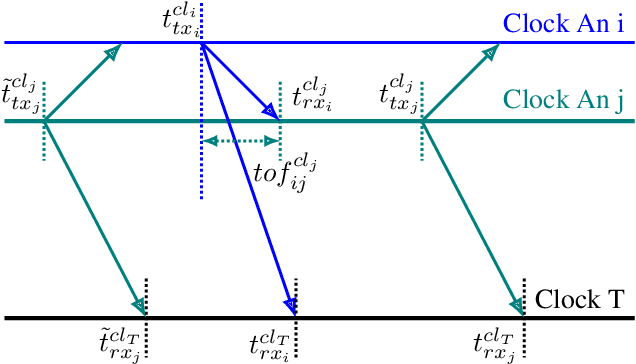
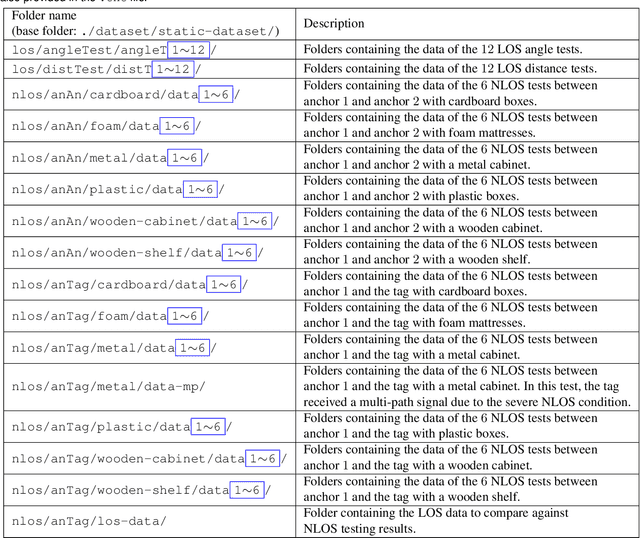
This paper presents an ultra-wideband (UWB) time-difference-of-arrival (TDOA) dataset collected from a quadrotor for research purposes. The dataset consists of low-level signal information from static experiments and UWB TDOA measurements and additional onboard sensor data from flight experiments on a quadrotor. The data collection process is discussed in detail, including the equipment used, measurement collection procedure, and the calibration of the quadrotor platform. All the data is made available as plain text files and we provide both Matlab and Python scripts to parse and analyze the data. We provide a thorough description of the data format and some pointers on the potential usage of each sub-dataset. The dataset is available for download at https://utiasdsl.github.io/util-uwb-dataset/. We hope this dataset will help researchers develop and compare reliable estimation methods for the emerging UWB TDOA-based indoor localization technology.
PEGG-Net: Background Agnostic Pixel-Wise Efficient Grasp Generation Under Closed-Loop Conditions
Mar 30, 2022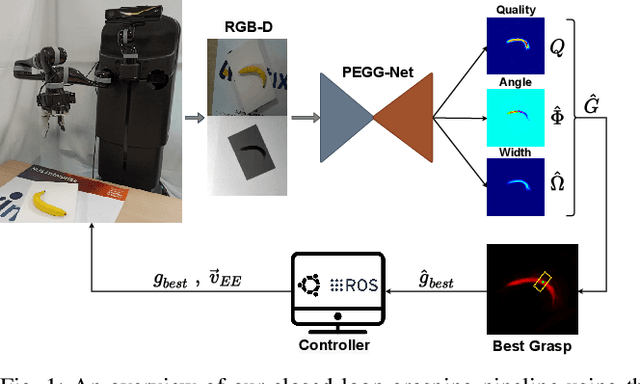
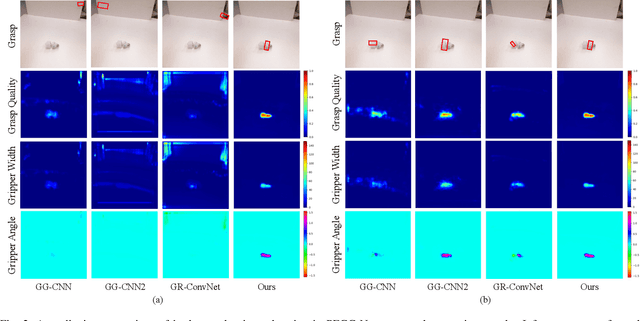
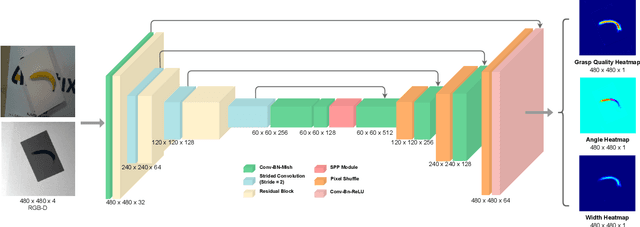

Performing closed-loop grasping at close proximity to an object requires a large field of view. However, such images will inevitably bring large amounts of unnecessary background information, especially when the camera is far away from the target object at the initial stage, resulting in performance degradation of the grasping network. To address this problem, we design a novel PEGG-Net, a real-time, pixel-wise, robotic grasp generation network. The proposed lightweight network is inherently able to learn to remove background noise that can reduce grasping accuracy. Our proposed PEGG-Net achieves improved state-of-the-art performance on both Cornell dataset (98.9%) and Jacquard dataset (93.8%). In the real-world tests, PEGG-Net can support closed-loop grasping at up to 50Hz using an image size of 480x480 in dynamic environments. The trained model also generalizes to previously unseen objects with complex geometrical shapes, household objects and workshop tools and achieved an overall grasp success rate of 91.2% in our real-world grasping experiments.
Vision Transformers for Single Image Dehazing
Apr 08, 2022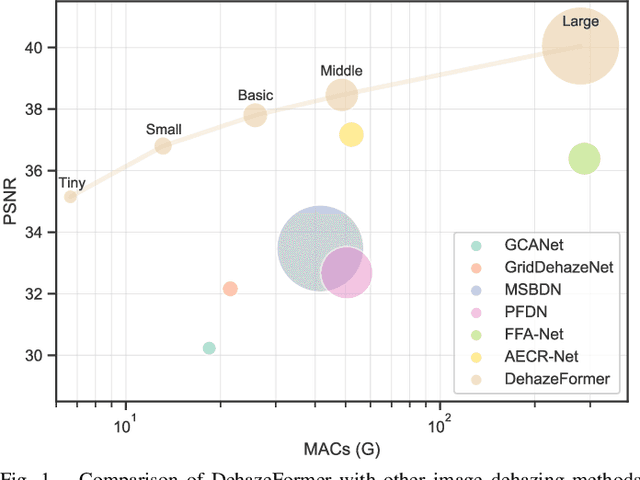


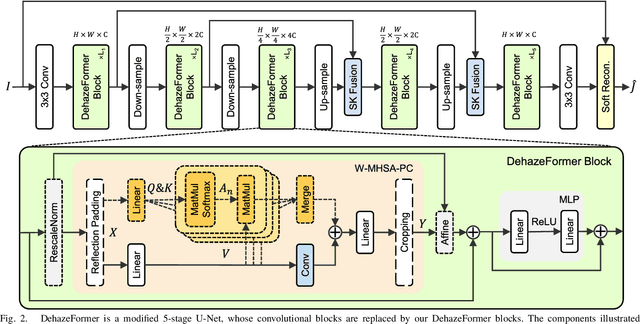
Image dehazing is a representative low-level vision task that estimates latent haze-free images from hazy images. In recent years, convolutional neural network-based methods have dominated image dehazing. However, vision Transformers, which has recently made a breakthrough in high-level vision tasks, has not brought new dimensions to image dehazing. We start with the popular Swin Transformer and find that several of its key designs are unsuitable for image dehazing. To this end, we propose DehazeFormer, which consists of various improvements, such as the modified normalization layer, activation function, and spatial information aggregation scheme. We train multiple variants of DehazeFormer on various datasets to demonstrate its effectiveness. Specifically, on the most frequently used SOTS indoor set, our small model outperforms FFA-Net with only 25% #Param and 5% computational cost. To the best of our knowledge, our large model is the first method with the PSNR over 40 dB on the SOTS indoor set, dramatically outperforming the previous state-of-the-art methods. We also collect a large-scale realistic remote sensing dehazing dataset for evaluating the method's capability to remove highly non-homogeneous haze.
CasGCN: Predicting future cascade growth based on information diffusion graph
Sep 10, 2020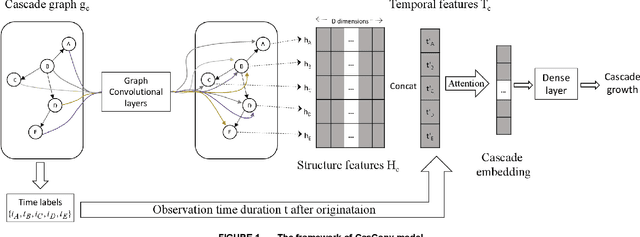
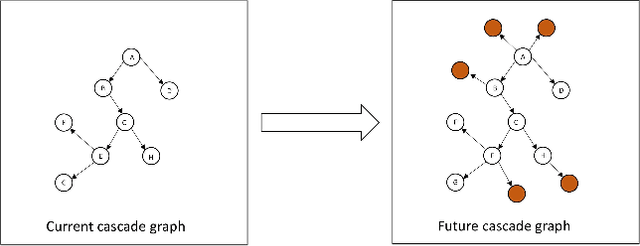
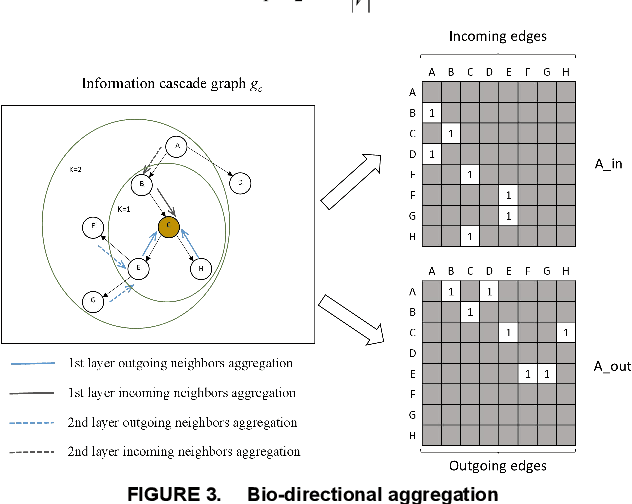
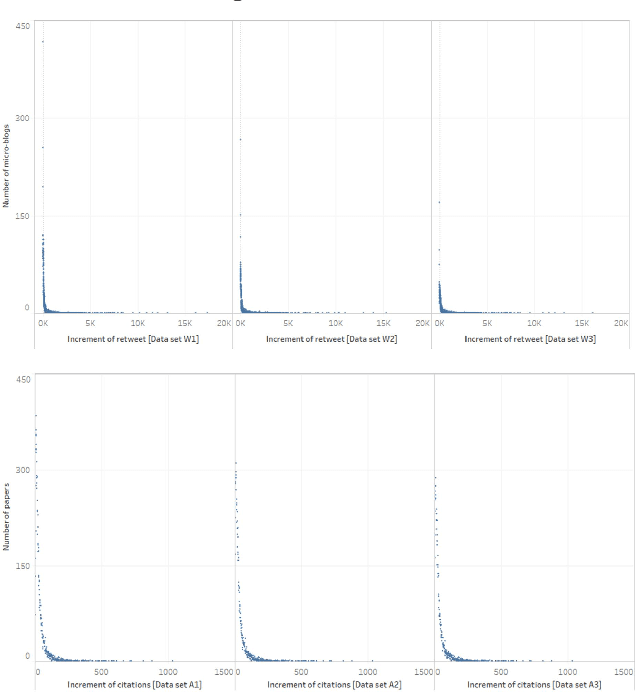
Sudden bursts of information cascades can lead to unexpected consequences such as extreme opinions, changes in fashion trends, and uncontrollable spread of rumors. It has become an important problem on how to effectively predict a cascade' size in the future, especially for large-scale cascades on social media platforms such as Twitter and Weibo. However, existing methods are insufficient in dealing with this challenging prediction problem. Conventional methods heavily rely on either hand crafted features or unrealistic assumptions. End-to-end deep learning models, such as recurrent neural networks, are not suitable to work with graphical inputs directly and cannot handle structural information that is embedded in the cascade graphs. In this paper, we propose a novel deep learning architecture for cascade growth prediction, called CasGCN, which employs the graph convolutional network to extract structural features from a graphical input, followed by the application of the attention mechanism on both the extracted features and the temporal information before conducting cascade size prediction. We conduct experiments on two real-world cascade growth prediction scenarios (i.e., retweet popularity on Sina Weibo and academic paper citations on DBLP), with the experimental results showing that CasGCN enjoys a superior performance over several baseline methods, particularly when the cascades are of large scale.
Generative Forensics: Procedural Generation and Information Games
Apr 03, 2020


Procedural generation is used across game design to achieve a wide variety of ends, and has led to the creation of several game subgenres by injecting variance, surprise or unpredictability into otherwise static designs. Information games are a type of mystery game in which the player is tasked with gathering knowledge and developing an understanding of an event or system. Their reliance on player knowledge leaves them vulnerable to spoilers and hard to replay. In this paper we introduce the notion of generative forensics games, a subgenre of information games that challenge the player to understand the output of a generative system. We introduce information games, show how generative forensics develops the idea, report on two prototype games we created, and evaluate our work on generative forensics so far from a player and a designer perspective.
AdvEst: Adversarial Perturbation Estimation to Classify and Detect Adversarial Attacks against Speaker Identification
Apr 08, 2022
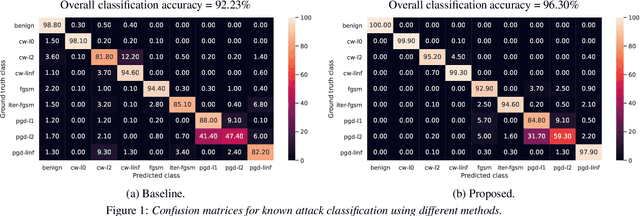

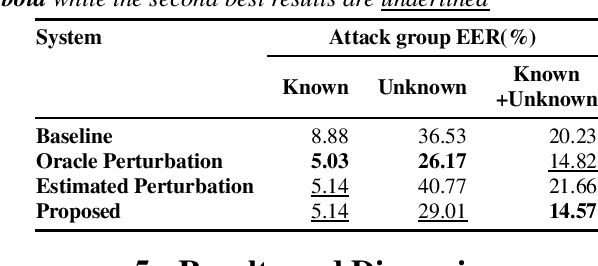
Adversarial attacks pose a severe security threat to the state-of-the-art speaker identification systems, thereby making it vital to propose countermeasures against them. Building on our previous work that used representation learning to classify and detect adversarial attacks, we propose an improvement to it using AdvEst, a method to estimate adversarial perturbation. First, we prove our claim that training the representation learning network using adversarial perturbations as opposed to adversarial examples (consisting of the combination of clean signal and adversarial perturbation) is beneficial because it eliminates nuisance information. At inference time, we use a time-domain denoiser to estimate the adversarial perturbations from adversarial examples. Using our improved representation learning approach to obtain attack embeddings (signatures), we evaluate their performance for three applications: known attack classification, attack verification, and unknown attack detection. We show that common attacks in the literature (Fast Gradient Sign Method (FGSM), Projected Gradient Descent (PGD), Carlini-Wagner (CW) with different Lp threat models) can be classified with an accuracy of ~96%. We also detect unknown attacks with an equal error rate (EER) of ~9%, which is absolute improvement of ~12% from our previous work.