 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust Disentangled Variational Speech Representation Learning for Zero-shot Voice Conversion
Mar 30, 2022
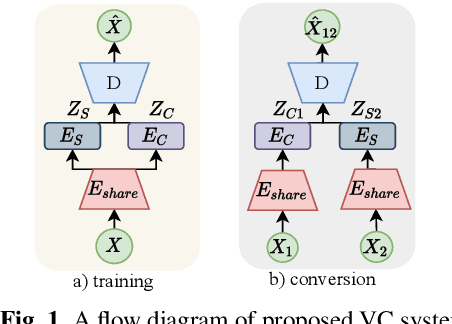
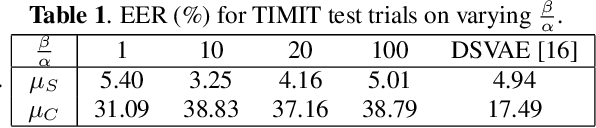
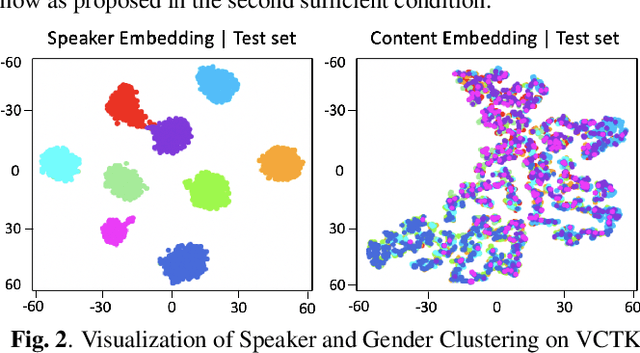
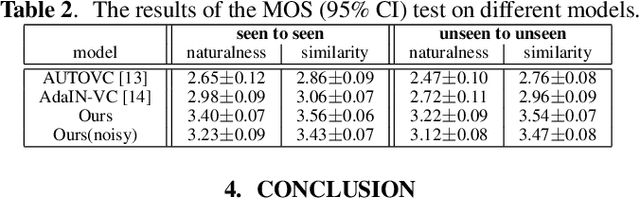
Traditional studies on voice conversion (VC) have made progress with parallel training data and known speakers. Good voice conversion quality is obtained by exploring better alignment modules or expressive mapping functions. In this study, we investigate zero-shot VC from a novel perspective of self-supervised disentangled speech representation learning. Specifically, we achieve the disentanglement by balancing the information flow between global speaker representation and time-varying content representation in a sequential variational autoencoder (VAE). A zero-shot voice conversion is performed by feeding an arbitrary speaker embedding and content embeddings to the VAE decoder. Besides that, an on-the-fly data augmentation training strategy is applied to make the learned representation noise invariant. On TIMIT and VCTK datasets, we achieve state-of-the-art performance on both objective evaluation, i.e., speaker verification (SV) on speaker embedding and content embedding, and subjective evaluation, i.e., voice naturalness and similarity, and remains to be robust even with noisy source/target utterances.
Visible-Thermal UAV Tracking: A Large-Scale Benchmark and New Baseline
Apr 08, 2022
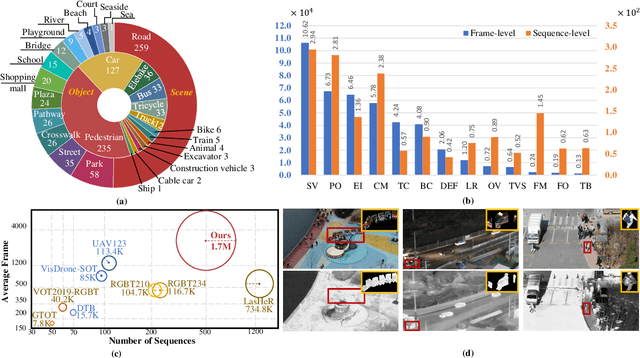
With the popularity of multi-modal sensors, visible-thermal (RGB-T) object tracking is to achieve robust performance and wider application scenarios with the guidance of objects' temperature information. However, the lack of paired training samples is the main bottleneck for unlocking the power of RGB-T tracking. Since it is laborious to collect high-quality RGB-T sequences, recent benchmarks only provide test sequences. In this paper, we construct a large-scale benchmark with high diversity for visible-thermal UAV tracking (VTUAV), including 500 sequences with 1.7 million high-resolution (1920 $\times$ 1080 pixels) frame pairs. In addition, comprehensive applications (short-term tracking, long-term tracking and segmentation mask prediction) with diverse categories and scenes are considered for exhaustive evaluation. Moreover, we provide a coarse-to-fine attribute annotation, where frame-level attributes are provided to exploit the potential of challenge-specific trackers. In addition, we design a new RGB-T baseline, named Hierarchical Multi-modal Fusion Tracker (HMFT), which fuses RGB-T data in various levels. Numerous experiments on several datasets are conducted to reveal the effectiveness of HMFT and the complement of different fusion types. The project is available at here.
Few-shot Named Entity Recognition with Self-describing Networks
Mar 23, 2022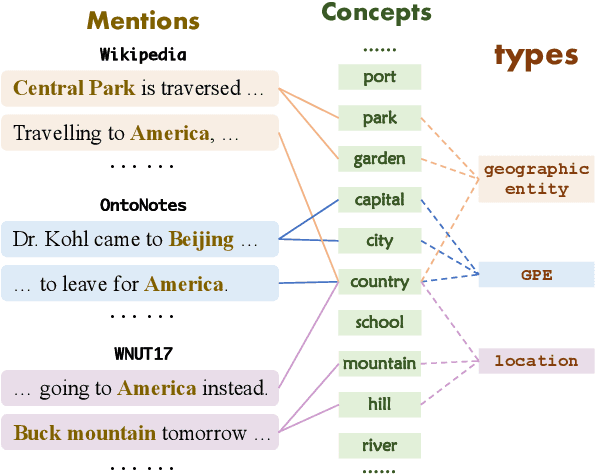
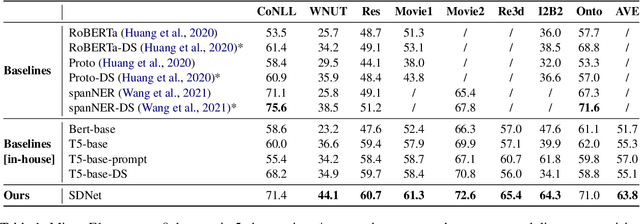
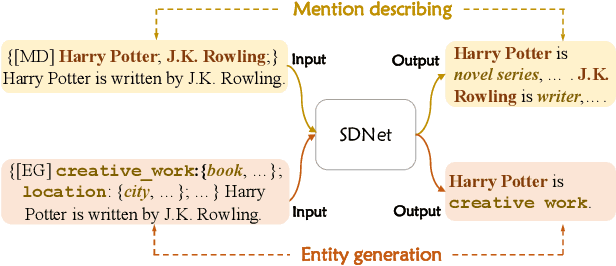
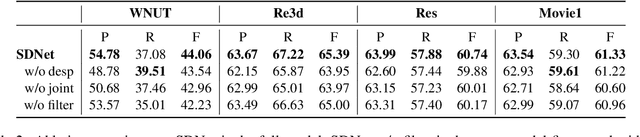
Few-shot NER needs to effectively capture information from limited instances and transfer useful knowledge from external resources. In this paper, we propose a self-describing mechanism for few-shot NER, which can effectively leverage illustrative instances and precisely transfer knowledge from external resources by describing both entity types and mentions using a universal concept set. Specifically, we design Self-describing Networks (SDNet), a Seq2Seq generation model which can universally describe mentions using concepts, automatically map novel entity types to concepts, and adaptively recognize entities on-demand. We pre-train SDNet with large-scale corpus, and conduct experiments on 8 benchmarks from different domains. Experiments show that SDNet achieves competitive performances on all benchmarks and achieves the new state-of-the-art on 6 benchmarks, which demonstrates its effectiveness and robustness.
Sparse and Dense Approaches for the Full-rank Retrieval of Responses for Dialogues
Apr 22, 2022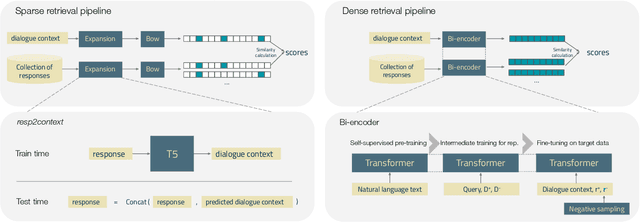
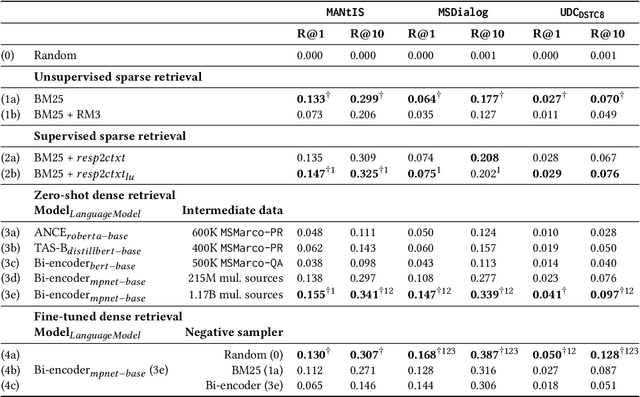
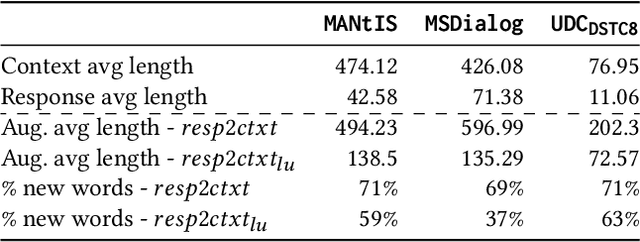
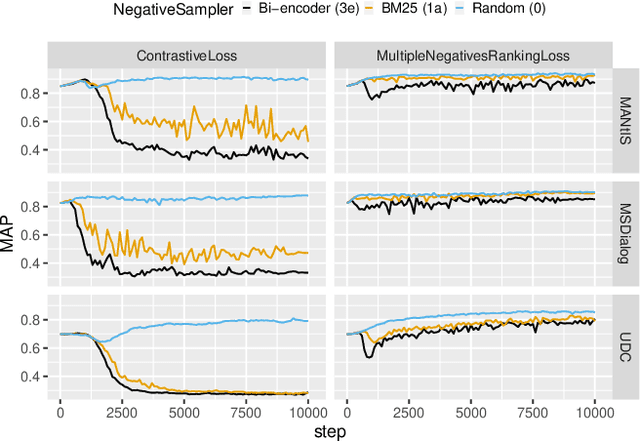
Ranking responses for a given dialogue context is a popular benchmark in which the setup is to re-rank the ground-truth response over a limited set of $n$ responses, where $n$ is typically 10. The predominance of this setup in conversation response ranking has lead to a great deal of attention to building neural re-rankers, while the first-stage retrieval step has been overlooked. Since the correct answer is always available in the candidate list of $n$ responses, this artificial evaluation setup assumes that there is a first-stage retrieval step which is always able to rank the correct response in its top-$n$ list. In this paper we focus on the more realistic task of full-rank retrieval of responses, where $n$ can be up to millions of responses. We investigate both dialogue context and response expansion techniques for sparse retrieval, as well as zero-shot and fine-tuned dense retrieval approaches. Our findings based on three different information-seeking dialogue datasets reveal that a learned response expansion technique is a solid baseline for sparse retrieval. We find the best performing method overall to be dense retrieval with intermediate training, i.e. a step after the language model pre-training where sentence representations are learned, followed by fine-tuning on the target conversational data. We also investigate the intriguing phenomena that harder negatives sampling techniques lead to worse results for the fine-tuned dense retrieval models. The code and datasets are available at https://github.com/Guzpenha/transformer_rankers/tree/full_rank_retrieval_dialogues.
A Novel Exploration of Diffusion Process based on Multi-types Galton-Watson Forests
Mar 17, 2022

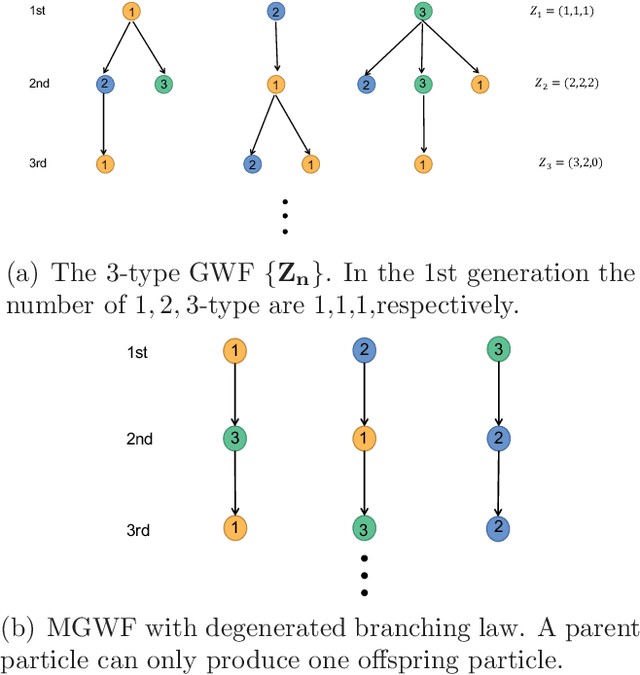
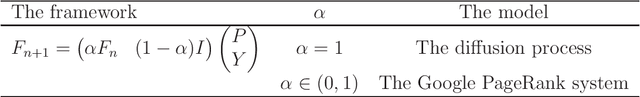
Diffusion is a commonly used technique for spreading information from point to point on a graph. The rationale behind diffusion is not clear. And the multi-types Galton-Watson forest is a random model of population growth without space or any other resource constraints. In this paper, we use the degenerated multi-types Galton-Watson forest (MGWF) to interpret the diffusion process and establish an equivalent relationship between them. With the two-phase setting of the MGWF, one can interpret the diffusion process and the Google PageRank system explicitly. It also improves the convergence behaviour of the iterative diffusion process and Google PageRank system. We validate the proposal by experiment while providing new research directions.
Writer Recognition Using Off-line Handwritten Single Block Characters
Jan 25, 2022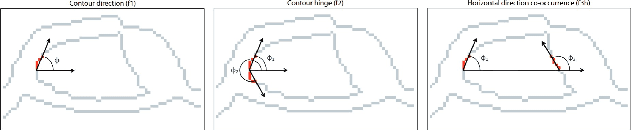

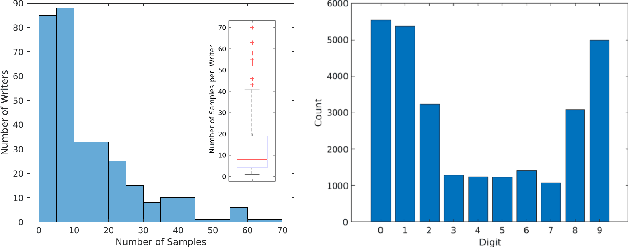
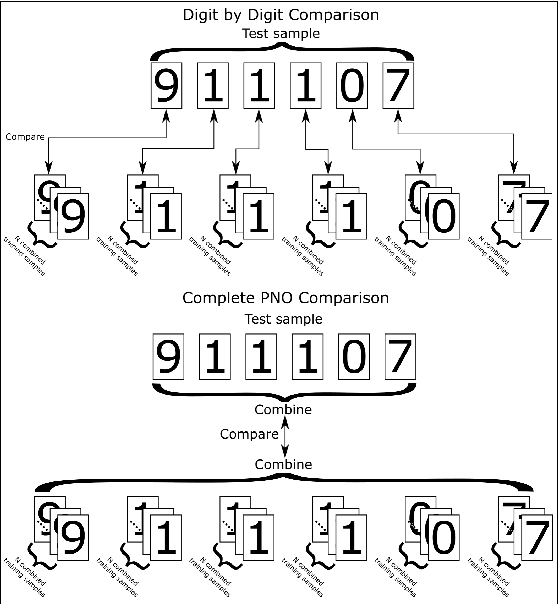
Block characters are often used when filling paper forms for a variety of purposes. We investigate if there is biometric information contained within individual digits of handwritten text. In particular, we use personal identity numbers consisting of the six digits of the date of birth, DoB. We evaluate two recognition approaches, one based on handcrafted features that compute contour directional measurements, and another based on deep features from a ResNet50 model. We use a self-captured database of 317 individuals and 4920 written DoBs in total. Results show the presence of identity-related information in a piece of handwritten information as small as six digits with the DoB. We also analyze the impact of the amount of enrolment samples, varying its number between one and ten. Results with such small amount of data are promising. With ten enrolment samples, the Top-1 accuracy with deep features is around 94%, and reaches nearly 100% by Top-10. The verification accuracy is more modest, with EER>20%with any given feature and enrolment set size, showing that there is still room for improvement.
A multi-task semi-supervised framework for Text2Graph & Graph2Text
Feb 12, 2022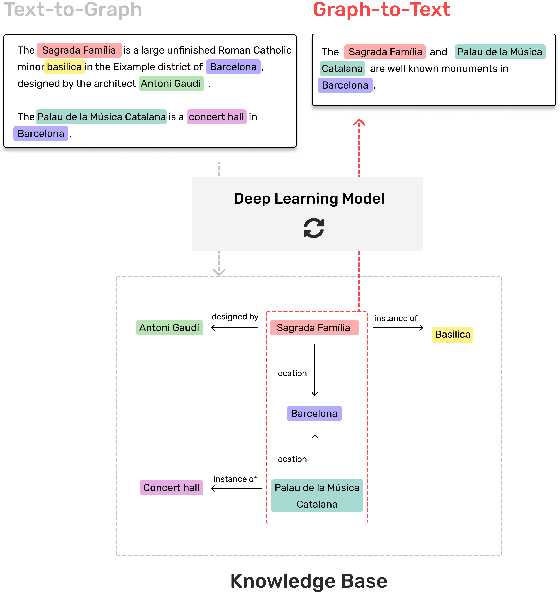

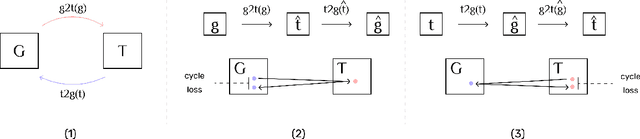
The Artificial Intelligence industry regularly develops applications that mostly rely on Knowledge Bases, a data repository about specific, or general, domains, usually represented in a graph shape. Similar to other databases, they face two main challenges: information ingestion and information retrieval. We approach these challenges by jointly learning graph extraction from text and text generation from graphs. The proposed solution, a T5 architecture, is trained in a multi-task semi-supervised environment, with our collected non-parallel data, following a cycle training regime. Experiments on WebNLG dataset show that our approach surpasses unsupervised state-of-the-art results in text-to-graph and graph-to-text. More relevantly, our framework is more consistent across seen and unseen domains than supervised models. The resulting model can be easily trained in any new domain with non-parallel data, by simply adding text and graphs about it, in our cycle framework.
Three-Stream Joint Network for Zero-Shot Sketch-Based Image Retrieval
Apr 12, 2022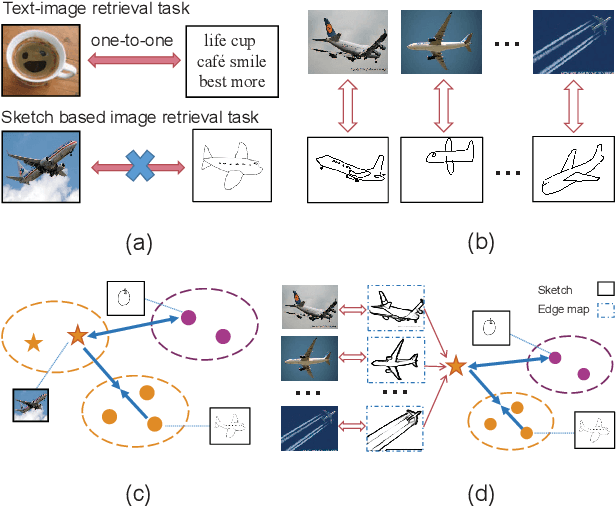
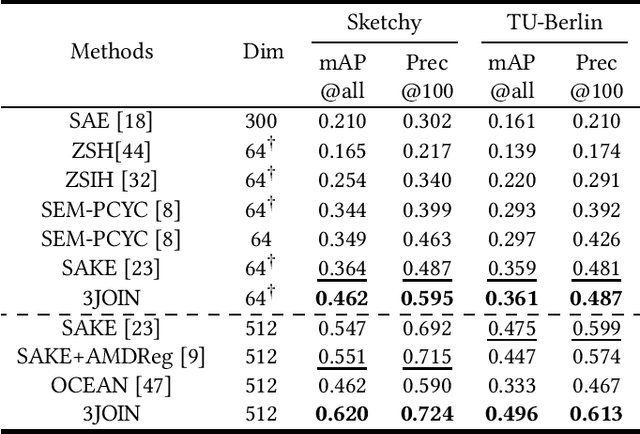
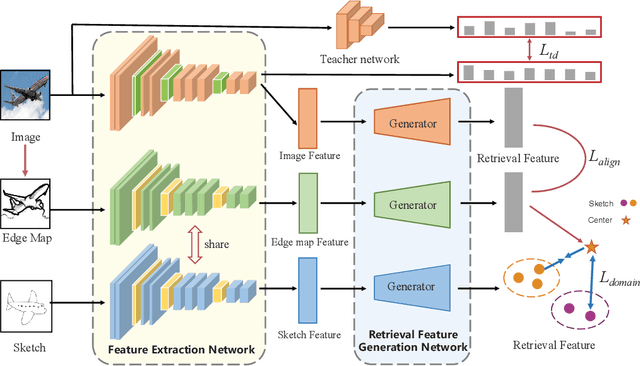
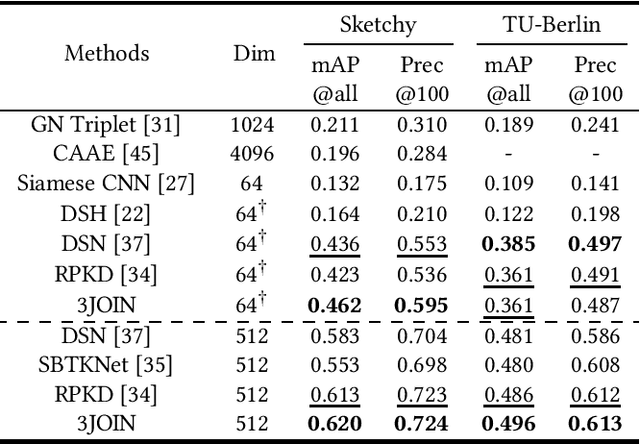
The Zero-Shot Sketch-based Image Retrieval (ZS-SBIR) is a challenging task because of the large domain gap between sketches and natural images as well as the semantic inconsistency between seen and unseen categories. Previous literature bridges seen and unseen categories by semantic embedding, which requires prior knowledge of the exact class names and additional extraction efforts. And most works reduce domain gap by mapping sketches and natural images into a common high-level space using constructed sketch-image pairs, which ignore the unpaired information between images and sketches. To address these issues, in this paper, we propose a novel Three-Stream Joint Training Network (3JOIN) for the ZS-SBIR task. To narrow the domain differences between sketches and images, we extract edge maps for natural images and treat them as a bridge between images and sketches, which have similar content to images and similar style to sketches. For exploiting a sufficient combination of sketches, natural images, and edge maps, a novel three-stream joint training network is proposed. In addition, we use a teacher network to extract the implicit semantics of the samples without the aid of other semantics and transfer the learned knowledge to unseen classes. Extensive experiments conducted on two real-world datasets demonstrate the superiority of our proposed method.
M$^2$BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation
Apr 19, 2022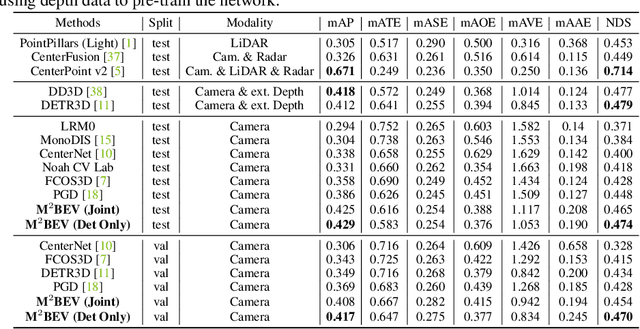
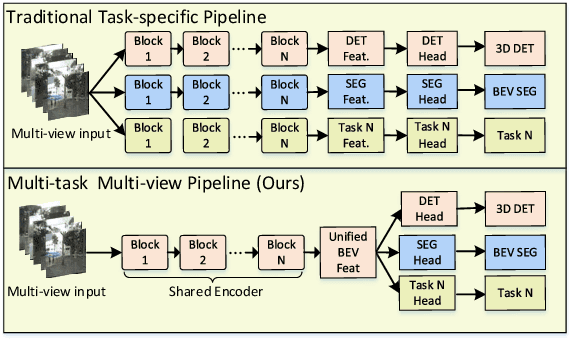
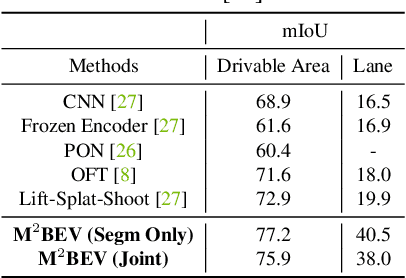
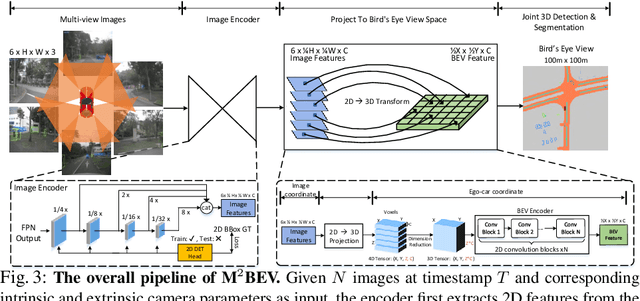
In this paper, we propose M$^2$BEV, a unified framework that jointly performs 3D object detection and map segmentation in the Birds Eye View~(BEV) space with multi-camera image inputs. Unlike the majority of previous works which separately process detection and segmentation, M$^2$BEV infers both tasks with a unified model and improves efficiency. M$^2$BEV efficiently transforms multi-view 2D image features into the 3D BEV feature in ego-car coordinates. Such BEV representation is important as it enables different tasks to share a single encoder. Our framework further contains four important designs that benefit both accuracy and efficiency: (1) An efficient BEV encoder design that reduces the spatial dimension of a voxel feature map. (2) A dynamic box assignment strategy that uses learning-to-match to assign ground-truth 3D boxes with anchors. (3) A BEV centerness re-weighting that reinforces with larger weights for more distant predictions, and (4) Large-scale 2D detection pre-training and auxiliary supervision. We show that these designs significantly benefit the ill-posed camera-based 3D perception tasks where depth information is missing. M$^2$BEV is memory efficient, allowing significantly higher resolution images as input, with faster inference speed. Experiments on nuScenes show that M$^2$BEV achieves state-of-the-art results in both 3D object detection and BEV segmentation, with the best single model achieving 42.5 mAP and 57.0 mIoU in these two tasks, respectively.
SyncNet: Using Causal Convolutions and Correlating Objective for Time Delay Estimation in Audio Signals
Mar 28, 2022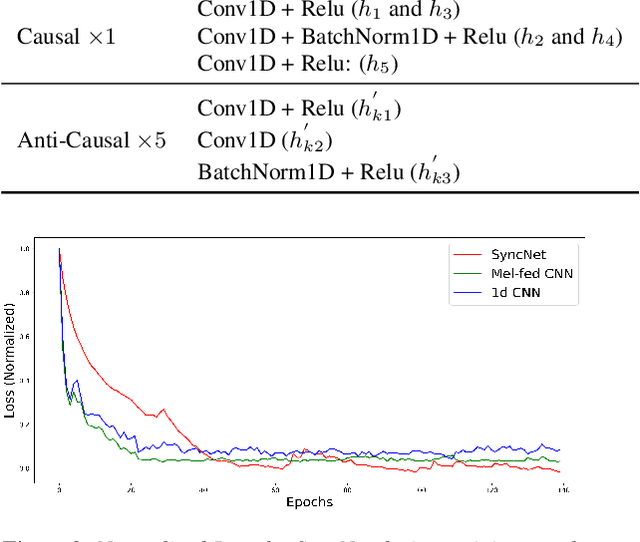
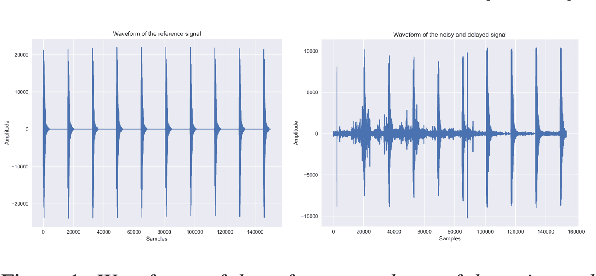
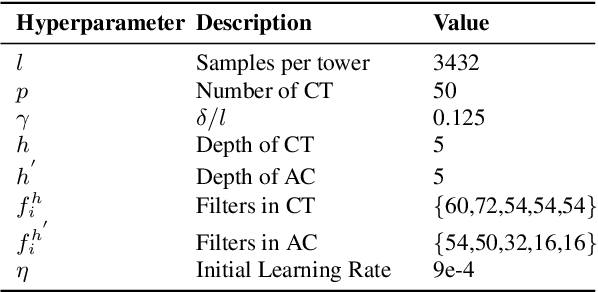
This paper addresses the task of performing robust and reliable time-delay estimation in audio-signals in noisy and reverberating environments. In contrast to the popular signal processing based methods, this paper proposes machine learning based method, i.e., a semi-causal convolutional neural network consisting of a set of causal and anti-causal layers with a novel correlation-based objective function. The causality in the network ensures non-leakage of representations from future time-intervals and the proposed loss function makes the network generate sequences with high correlation at the actual time delay. The proposed approach is also intrinsically interpretable as it does not lose time information. Even a shallow convolution network is able to capture local patterns in sequences, while also correlating them globally. SyncNet outperforms other classical approaches in estimating mutual time delays for different types of audio signals including pulse, speech and musical beats.