 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Human-AI Partnerships in Child Welfare: Understanding Worker Practices, Challenges, and Desires for Algorithmic Decision Support
Apr 05, 2022
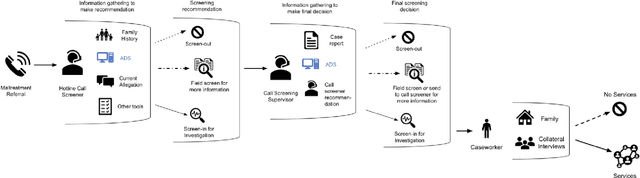
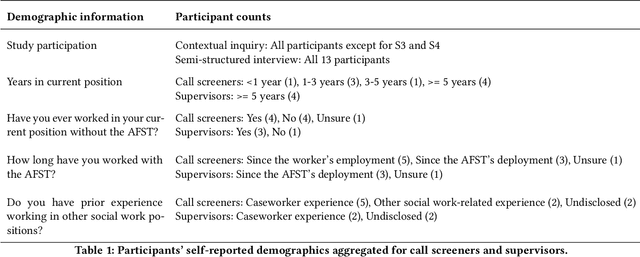
AI-based decision support tools (ADS) are increasingly used to augment human decision-making in high-stakes, social contexts. As public sector agencies begin to adopt ADS, it is critical that we understand workers' experiences with these systems in practice. In this paper, we present findings from a series of interviews and contextual inquiries at a child welfare agency, to understand how they currently make AI-assisted child maltreatment screening decisions. Overall, we observe how workers' reliance upon the ADS is guided by (1) their knowledge of rich, contextual information beyond what the AI model captures, (2) their beliefs about the ADS's capabilities and limitations relative to their own, (3) organizational pressures and incentives around the use of the ADS, and (4) awareness of misalignments between algorithmic predictions and their own decision-making objectives. Drawing upon these findings, we discuss design implications towards supporting more effective human-AI decision-making.
Multi-organ Segmentation Network with Adversarial Performance Validator
Apr 16, 2022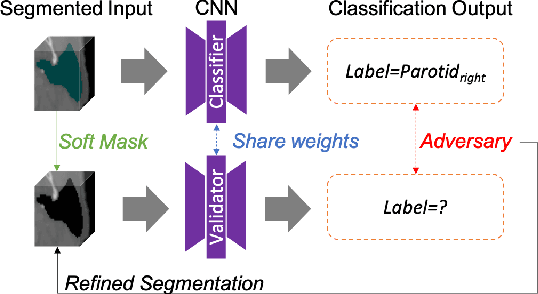
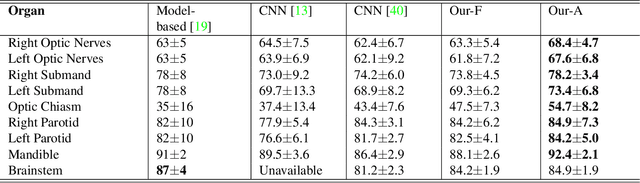
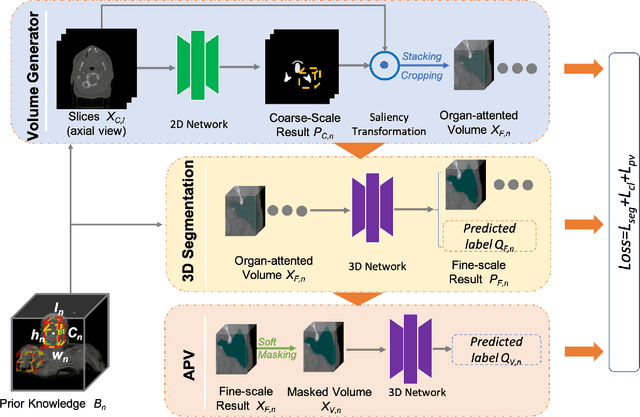
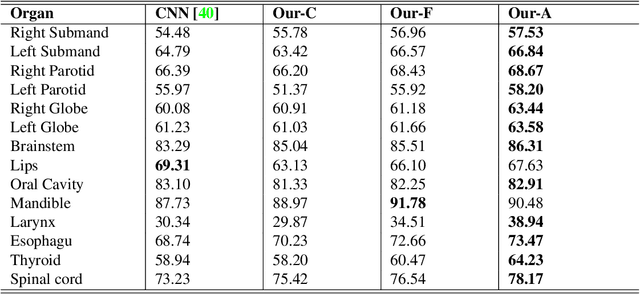
CT organ segmentation on computed tomography (CT) images becomes a significant brick for modern medical image analysis, supporting clinic workflows in multiple domains. Previous segmentation methods include 2D convolution neural networks (CNN) based approaches, fed by CT image slices that lack the structural knowledge in axial view, and 3D CNN-based methods with the expensive computation cost in multi-organ segmentation applications. This paper introduces an adversarial performance validation network into a 2D-to-3D segmentation framework. The classifier and performance validator competition contribute to accurate segmentation results via back-propagation. The proposed network organically converts the 2D-coarse result to 3D high-quality segmentation masks in a coarse-to-fine manner, allowing joint optimization to improve segmentation accuracy. Besides, the structural information of one specific organ is depicted by a statistics-meaningful prior bounding box, which is transformed into a global feature leveraging the learning process in 3D fine segmentation. The experiments on the NIH pancreas segmentation dataset demonstrate the proposed network achieves state-of-the-art accuracy on small organ segmentation and outperforms the previous best. High accuracy is also reported on multi-organ segmentation in a dataset collected by ourselves.
Resolving the Disparate Impact of Uncertainty: Affirmative Action vs. Affirmative Information
Feb 19, 2021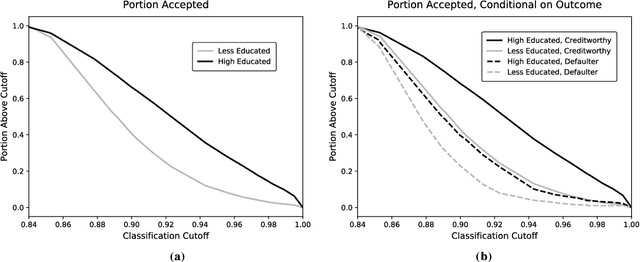
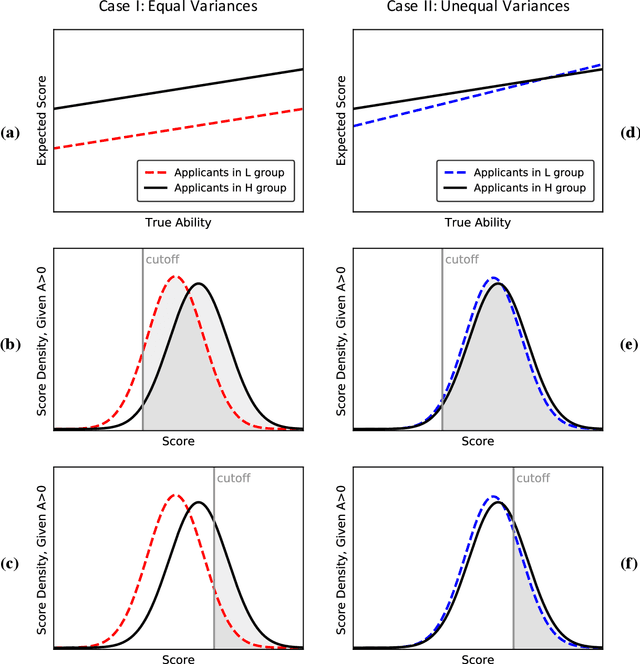
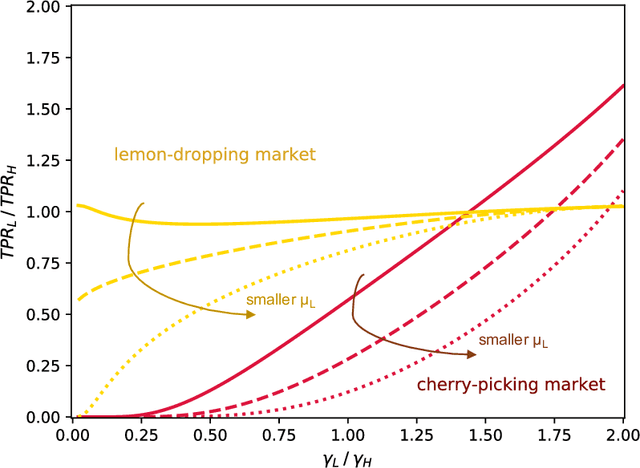
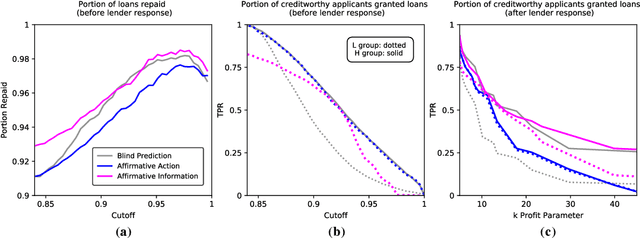
Algorithmic risk assessments hold the promise of greatly advancing accurate decision-making, but in practice, multiple real-world examples have been shown to distribute errors disproportionately across demographic groups. In this paper, we characterize why error disparities arise in the first place. We show that predictive uncertainty often leads classifiers to systematically disadvantage groups with lower-mean outcomes, assigning them smaller true and false positive rates than their higher-mean counterparts. This can occur even when prediction is group-blind. We prove that to avoid these error imbalances, individuals in lower-mean groups must either be over-represented among positive classifications or be assigned more accurate predictions than those in higher-mean groups. We focus on the latter condition as a solution to bridge error rate divides and show that data acquisition for low-mean groups can increase access to opportunity. We call the strategy "affirmative information" and compare it to traditional affirmative action in the classification task of identifying creditworthy borrowers.
Probing Pre-Trained Language Models for Cross-Cultural Differences in Values
Mar 25, 2022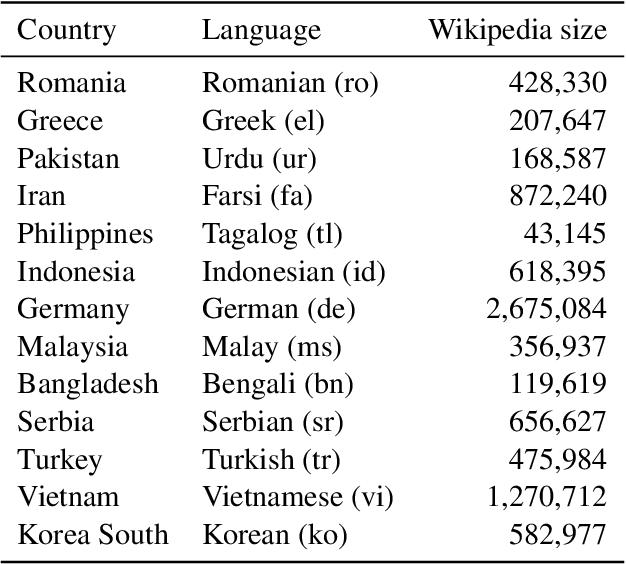
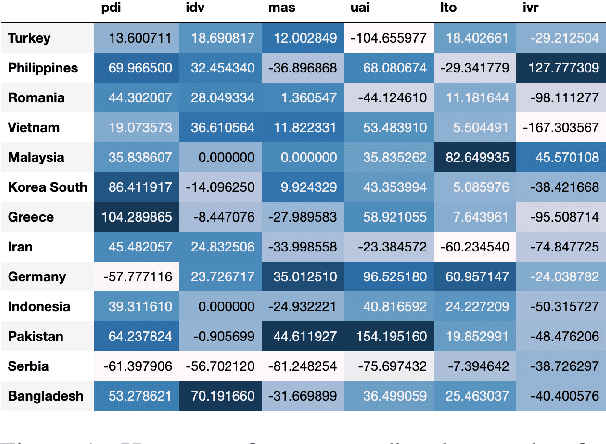
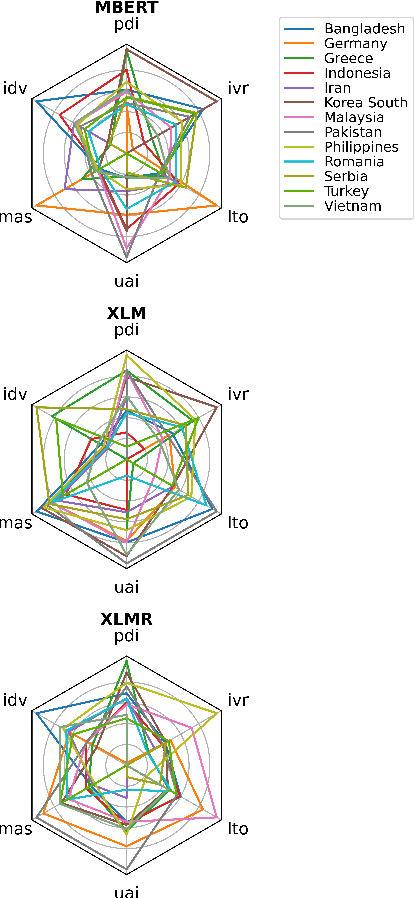
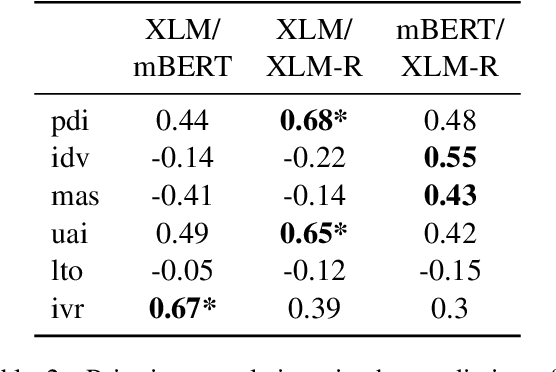
Language embeds information about social, cultural, and political values people hold. Prior work has explored social and potentially harmful biases encoded in Pre-Trained Language models (PTLMs). However, there has been no systematic study investigating how values embedded in these models vary across cultures. In this paper, we introduce probes to study which values across cultures are embedded in these models, and whether they align with existing theories and cross-cultural value surveys. We find that PTLMs capture differences in values across cultures, but those only weakly align with established value surveys. We discuss implications of using mis-aligned models in cross-cultural settings, as well as ways of aligning PTLMs with value surveys.
Bridging Cross-Lingual Gaps During Leveraging the Multilingual Sequence-to-Sequence Pretraining for Text Generation
Apr 16, 2022
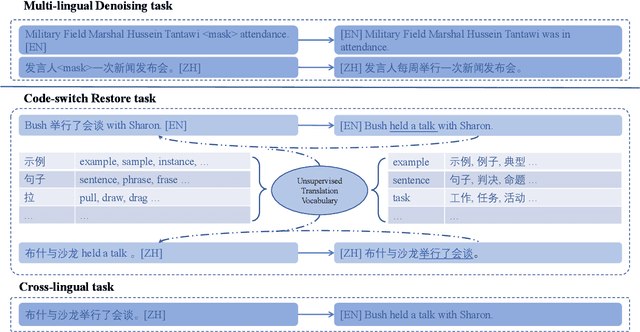
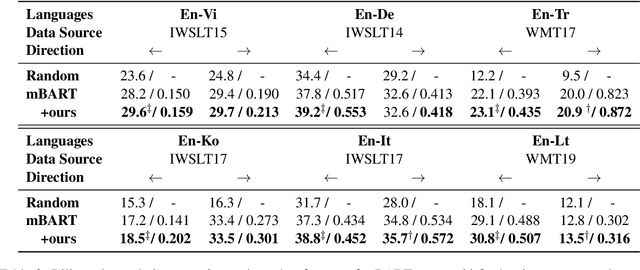
For multilingual sequence-to-sequence pretrained language models (multilingual Seq2Seq PLMs), e.g. mBART, the self-supervised pretraining task is trained on a wide range of monolingual languages, e.g. 25 languages from commoncrawl, while the downstream cross-lingual tasks generally progress on a bilingual language subset, e.g. English-German, making there exists the cross-lingual data discrepancy, namely \textit{domain discrepancy}, and cross-lingual learning objective discrepancy, namely \textit{task discrepancy}, between the pretrain and finetune stages. To bridge the above cross-lingual domain and task gaps, we extend the vanilla pretrain-finetune pipeline with extra code-switching restore task. Specifically, the first stage employs the self-supervised code-switching restore task as a pretext task, allowing the multilingual Seq2Seq PLM to acquire some in-domain alignment information. And for the second stage, we continuously fine-tune the model on labeled data normally. Experiments on a variety of cross-lingual NLG tasks, including 12 bilingual translation tasks, 36 zero-shot translation tasks, and cross-lingual summarization tasks show our model outperforms the strong baseline mBART consistently. Comprehensive analyses indicate our approach could narrow the cross-lingual sentence representation distance and improve low-frequency word translation with trivial computational cost.
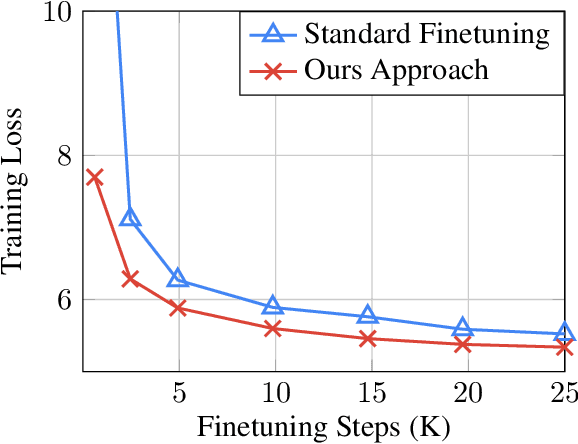
Leveraging Equivariant Features for Absolute Pose Regression
Apr 05, 2022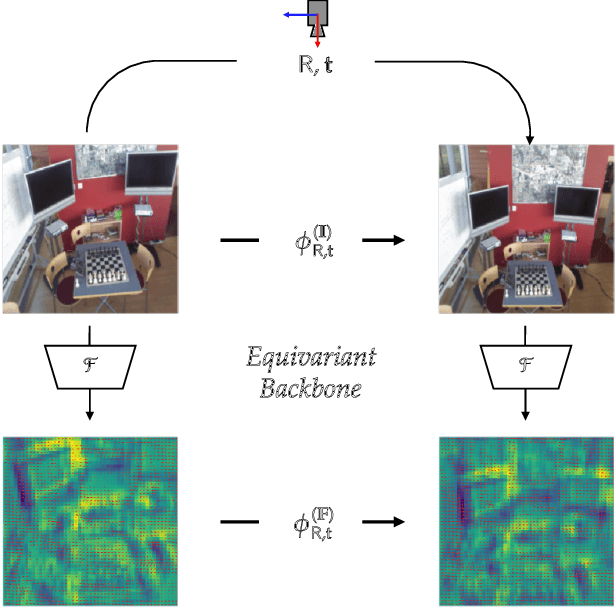
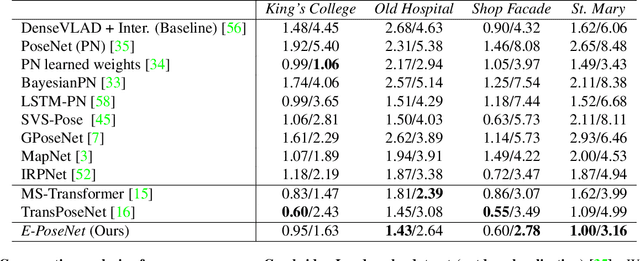
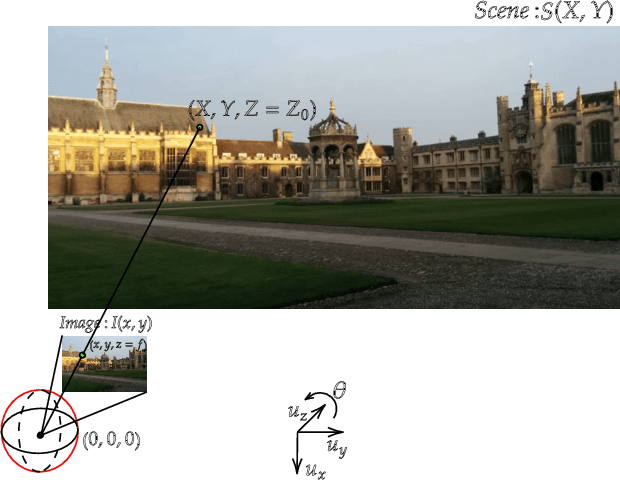
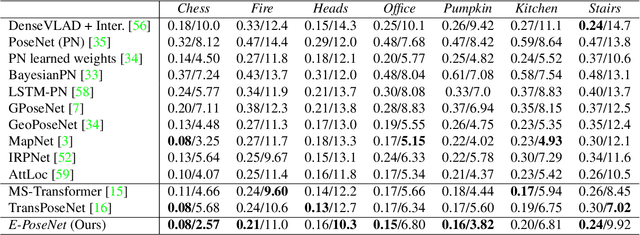
While end-to-end approaches have achieved state-of-the-art performance in many perception tasks, they are not yet able to compete with 3D geometry-based methods in pose estimation. Moreover, absolute pose regression has been shown to be more related to image retrieval. As a result, we hypothesize that the statistical features learned by classical Convolutional Neural Networks do not carry enough geometric information to reliably solve this inherently geometric task. In this paper, we demonstrate how a translation and rotation equivariant Convolutional Neural Network directly induces representations of camera motions into the feature space. We then show that this geometric property allows for implicitly augmenting the training data under a whole group of image plane-preserving transformations. Therefore, we argue that directly learning equivariant features is preferable than learning data-intensive intermediate representations. Comprehensive experimental validation demonstrates that our lightweight model outperforms existing ones on standard datasets.
Do Syntax Trees Help Pre-trained Transformers Extract Information?
Aug 20, 2020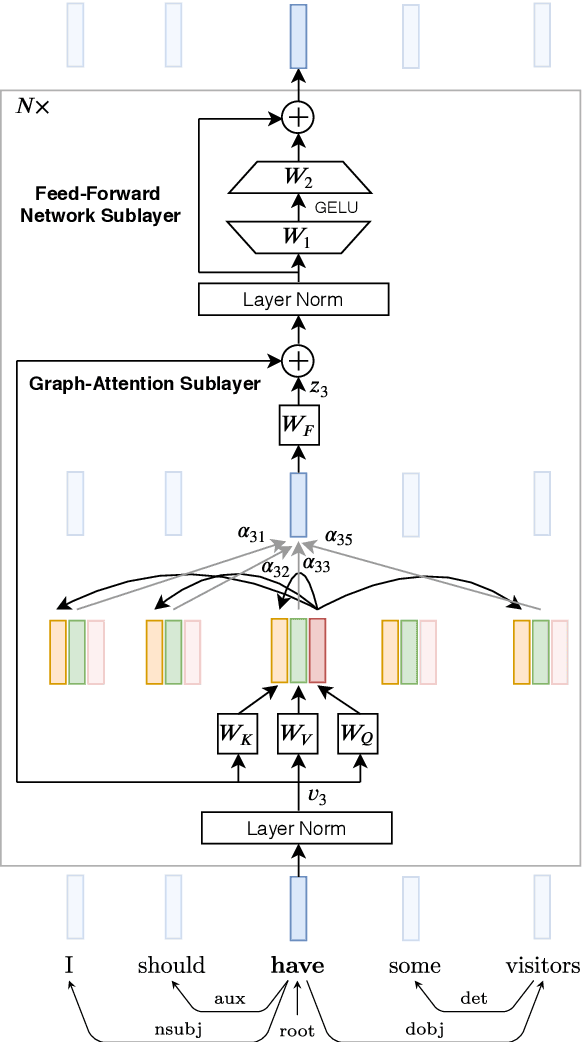
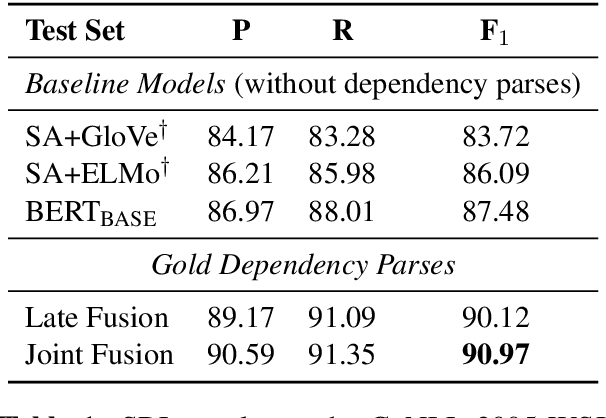
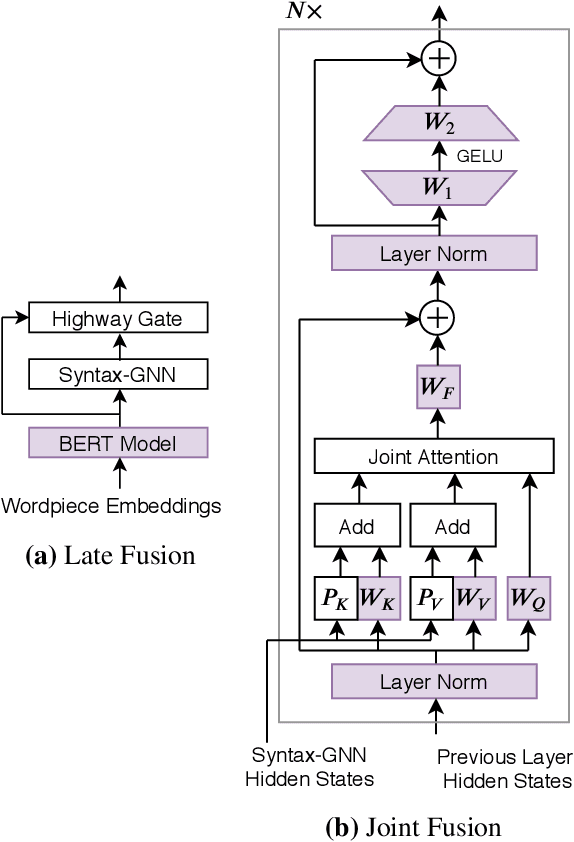
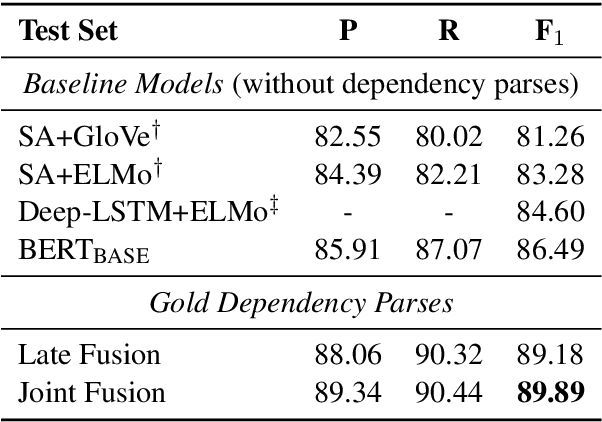
Much recent work suggests that incorporating syntax information from dependency trees can improve task-specific transformer models. However, the effect of incorporating dependency tree information into pre-trained transformer models (e.g., BERT) remains unclear, especially given recent studies highlighting how these models implicitly encode syntax. In this work, we systematically study the utility of incorporating dependency trees into pre-trained transformers on three representative information extraction tasks: semantic role labeling (SRL), named entity recognition, and relation extraction. We propose and investigate two distinct strategies for incorporating dependency structure: a late fusion approach, which applies a graph neural network on the output of a transformer, and a joint fusion approach, which infuses syntax structure into the transformer attention layers. These strategies are representative of prior work, but we introduce essential design decisions that are necessary for strong performance. Our empirical analysis demonstrates that these syntax-infused transformers obtain state-of-the-art results on SRL and relation extraction tasks. However, our analysis also reveals a critical shortcoming of these models: we find that their performance gains are highly contingent on the availability of human-annotated dependency parses, which raises important questions regarding the viability of syntax-augmented transformers in real-world applications.
A Hierarchical N-Gram Framework for Zero-Shot Link Prediction
Apr 16, 2022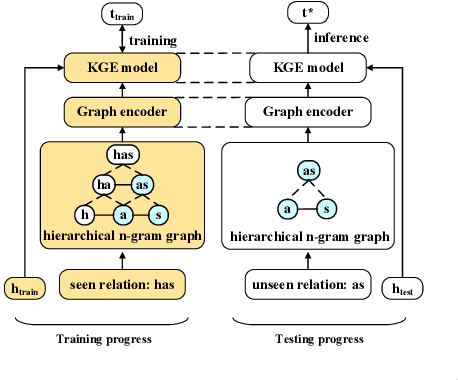
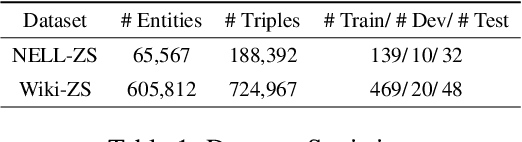
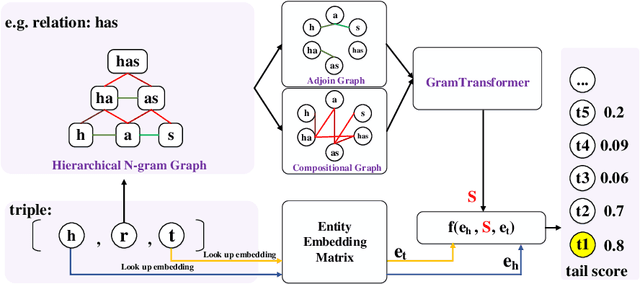
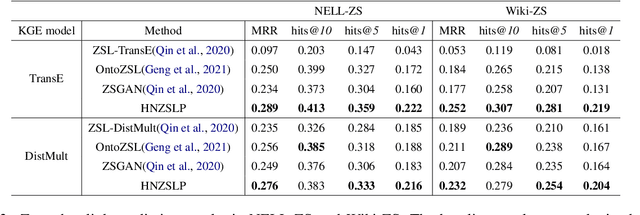
Due to the incompleteness of knowledge graphs (KGs), zero-shot link prediction (ZSLP) which aims to predict unobserved relations in KGs has attracted recent interest from researchers. A common solution is to use textual features of relations (e.g., surface name or textual descriptions) as auxiliary information to bridge the gap between seen and unseen relations. Current approaches learn an embedding for each word token in the text. These methods lack robustness as they suffer from the out-of-vocabulary (OOV) problem. Meanwhile, models built on character n-grams have the capability of generating expressive representations for OOV words. Thus, in this paper, we propose a Hierarchical N-Gram framework for Zero-Shot Link Prediction (HNZSLP), which considers the dependencies among character n-grams of the relation surface name for ZSLP. Our approach works by first constructing a hierarchical n-gram graph on the surface name to model the organizational structure of n-grams that leads to the surface name. A GramTransformer, based on the Transformer is then presented to model the hierarchical n-gram graph to construct the relation embedding for ZSLP. Experimental results show the proposed HNZSLP achieved state-of-the-art performance on two ZSLP datasets.
Typical Decoding for Natural Language Generation
Feb 10, 2022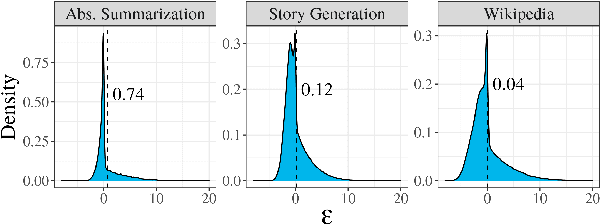
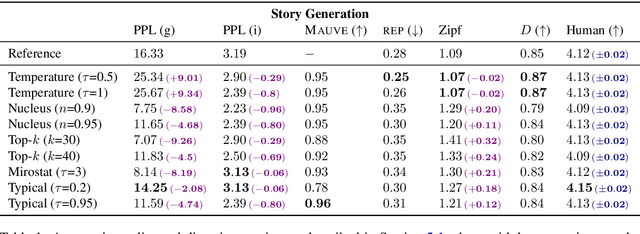
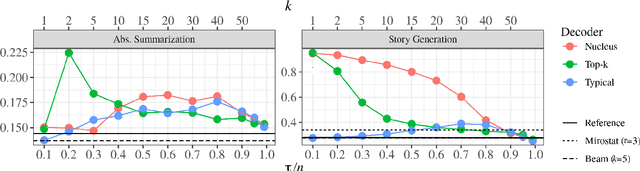
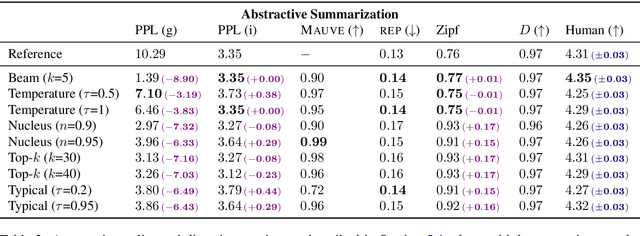
Despite achieving incredibly low perplexities on myriad natural language corpora, today's language models still often underperform when used to generate text. This dichotomy has puzzled the language generation community for the last few years. In this work, we posit that the abstraction of natural language as a communication channel (\`a la Shannon, 1948) can provide new insights into the behaviors of probabilistic language generators, e.g., why high-probability texts can be dull or repetitive. Humans use language as a means of communicating information, and do so in an efficient yet error-minimizing manner, choosing each word in a string with this (perhaps subconscious) goal in mind. We propose that generation from probabilistic models should mimic this behavior. Rather than always choosing words from the high-probability region of the distribution--which have a low Shannon information content--we sample from the set of words with an information content close to its expected value, i.e., close to the conditional entropy of our model. This decision criterion can be realized through a simple and efficient implementation, which we call typical sampling. Automatic and human evaluations show that, in comparison to nucleus and top-k sampling, typical sampling offers competitive performance in terms of quality while consistently reducing the number of degenerate repetitions.
Measuring and Sampling: A Metric-guided Subgraph Learning Framework for Graph Neural Network
Dec 30, 2021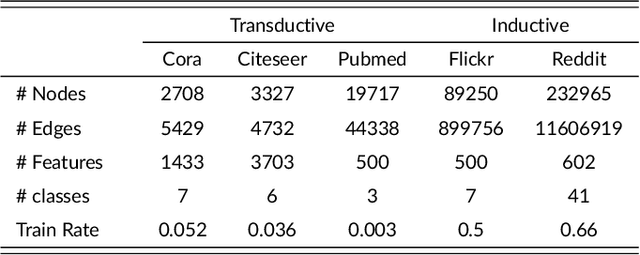
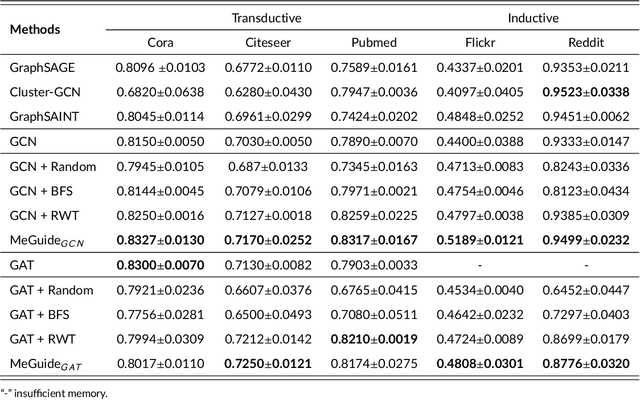
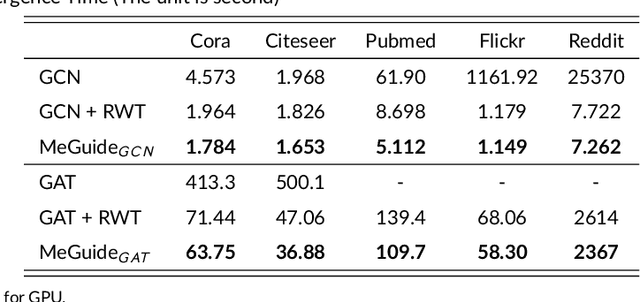
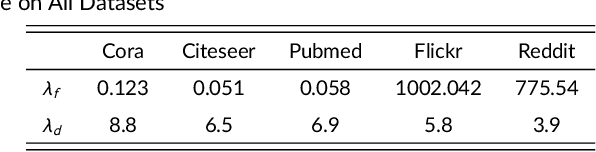
Graph neural network (GNN) has shown convincing performance in learning powerful node representations that preserve both node attributes and graph structural information. However, many GNNs encounter problems in effectiveness and efficiency when they are designed with a deeper network structure or handle large-sized graphs. Several sampling algorithms have been proposed for improving and accelerating the training of GNNs, yet they ignore understanding the source of GNN performance gain. The measurement of information within graph data can help the sampling algorithms to keep high-value information while removing redundant information and even noise. In this paper, we propose a Metric-Guided (MeGuide) subgraph learning framework for GNNs. MeGuide employs two novel metrics: Feature Smoothness and Connection Failure Distance to guide the subgraph sampling and mini-batch based training. Feature Smoothness is designed for analyzing the feature of nodes in order to retain the most valuable information, while Connection Failure Distance can measure the structural information to control the size of subgraphs. We demonstrate the effectiveness and efficiency of MeGuide in training various GNNs on multiple datasets.