 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online panoptic 3D reconstruction as a Linear Assignment Problem
Apr 01, 2022
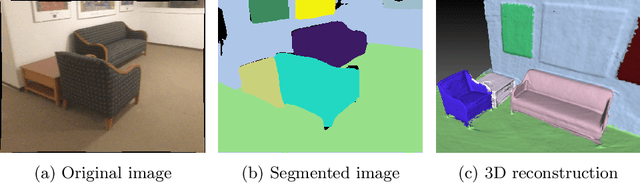
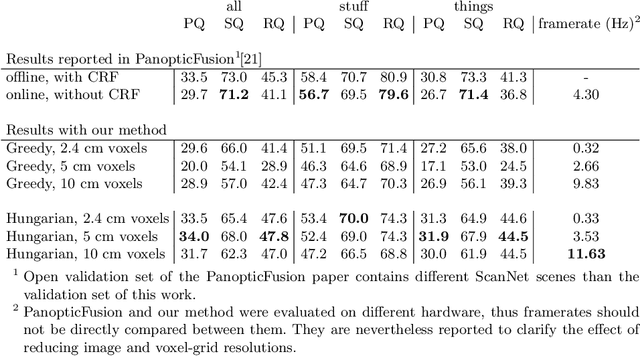

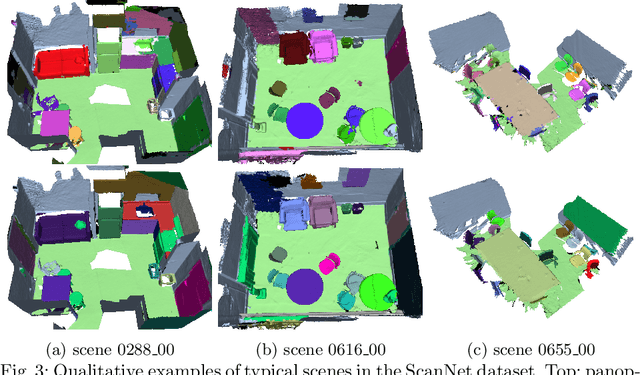
Real-time holistic scene understanding would allow machines to interpret their surrounding in a much more detailed manner than is currently possible. While panoptic image segmentation methods have brought image segmentation closer to this goal, this information has to be described relative to the 3D environment for the machine to be able to utilise it effectively. In this paper, we investigate methods for sequentially reconstructing static environments from panoptic image segmentations in 3D. We specifically target real-time operation: the algorithm must process data strictly online and be able to run at relatively fast frame rates. Additionally, the method should be scalable for environments large enough for practical applications. By applying a simple but powerful data-association algorithm, we outperform earlier similar works when operating purely online. Our method is also capable of reaching frame-rates high enough for real-time applications and is scalable to larger environments as well. Source code and further demonstrations are released to the public at: \url{https://tutvision.github.io/Online-Panoptic-3D/}
Indoor SLAM Using a Foot-mounted IMU and the local Magnetic Field
Mar 29, 2022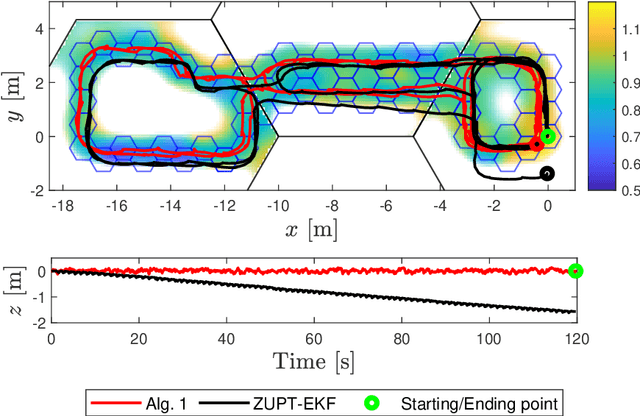
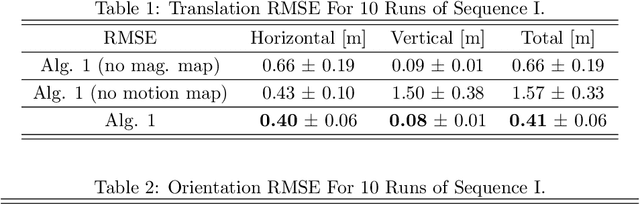

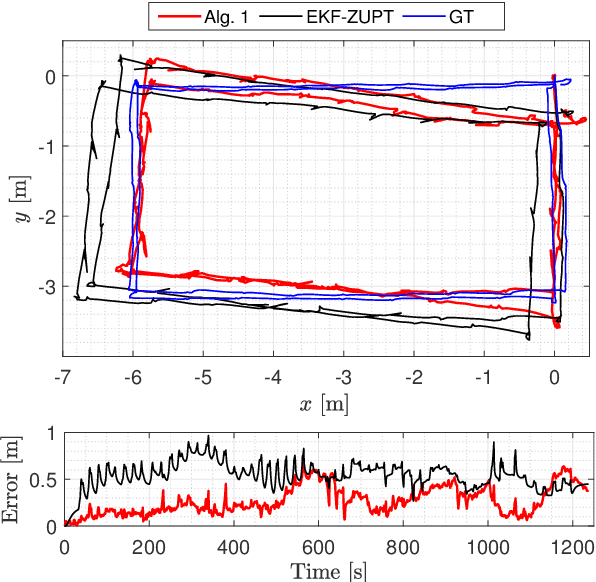
In this paper, a simultaneous localization and mapping (SLAM) algorithm for tracking the motion of a pedestrian with a foot-mounted inertial measurement unit (IMU) is proposed. The algorithm uses two maps, namely, a motion map and a magnetic field map. The motion map captures typical motion patterns of pedestrians in buildings that are constrained by e.g. corridors and doors. The magnetic map models local magnetic field anomalies in the environment using a Gaussian process (GP) model and uses them as position information. These maps are used in a Rao-Blackwellized particle filter (RBPF) to correct the pedestrian position and orientation estimates from the pedestrian dead-reckoning (PDR). The PDR is computed using an extended Kalman filter with zero-velocity updates (ZUPT-EKF). The algorithm is validated using real experimental sequences and the results show the efficacy of the algorithm in localizing pedestrians in indoor environments.
AccMPEG: Optimizing Video Encoding for Video Analytics
Apr 26, 2022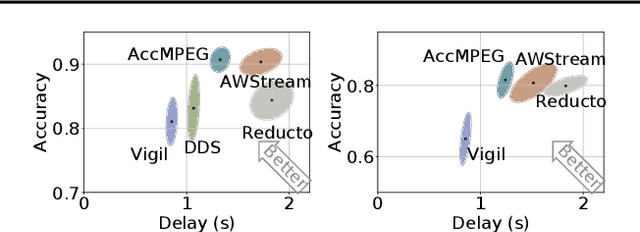
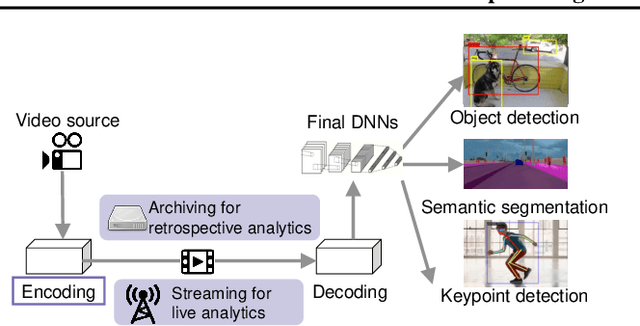

With more videos being recorded by edge sensors (cameras) and analyzed by computer-vision deep neural nets (DNNs), a new breed of video streaming systems has emerged, with the goal to compress and stream videos to remote servers in real time while preserving enough information to allow highly accurate inference by the server-side DNNs. An ideal design of the video streaming system should simultaneously meet three key requirements: (1) low latency of encoding and streaming, (2) high accuracy of server-side DNNs, and (3) low compute overheads on the camera. Unfortunately, despite many recent efforts, such video streaming system has hitherto been elusive, especially when serving advanced vision tasks such as object detection or semantic segmentation. This paper presents AccMPEG, a new video encoding and streaming system that meets all the three requirements. The key is to learn how much the encoding quality at each (16x16) macroblock can influence the server-side DNN accuracy, which we call accuracy gradient. Our insight is that these macroblock-level accuracy gradient can be inferred with sufficient precision by feeding the video frames through a cheap model. AccMPEG provides a suite of techniques that, given a new server-side DNN, can quickly create a cheap model to infer the accuracy gradient on any new frame in near realtime. Our extensive evaluation of AccMPEG on two types of edge devices (one Intel Xeon Silver 4100 CPU or NVIDIA Jetson Nano) and three vision tasks (six recent pre-trained DNNs) shows that AccMPEG (with the same camera-side compute resources) can reduce the end-to-end inference delay by 10-43% without hurting accuracy compared to the state-of-the-art baselines
VPTR: Efficient Transformers for Video Prediction
Mar 29, 2022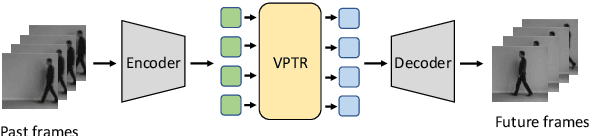
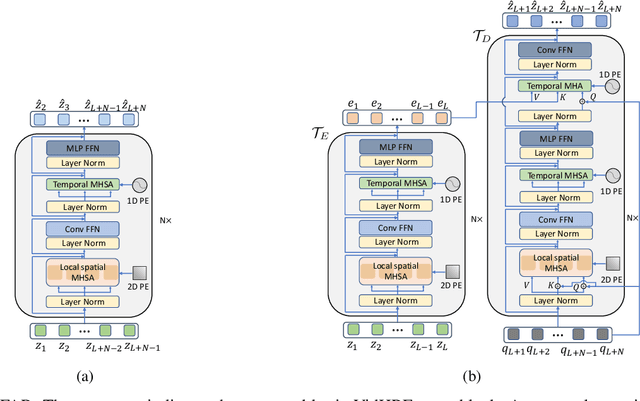
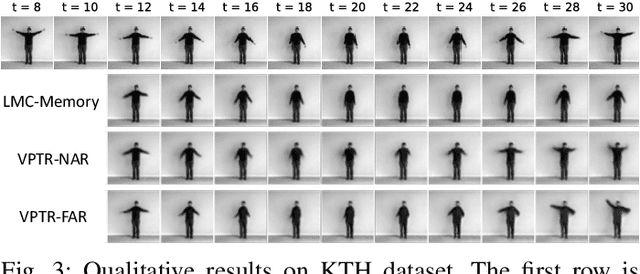
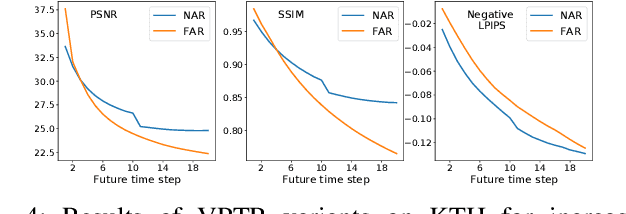
In this paper, we propose a new Transformer block for video future frames prediction based on an efficient local spatial-temporal separation attention mechanism. Based on this new Transformer block, a fully autoregressive video future frames prediction Transformer is proposed. In addition, a non-autoregressive video prediction Transformer is also proposed to increase the inference speed and reduce the accumulated inference errors of its autoregressive counterpart. In order to avoid the prediction of very similar future frames, a contrastive feature loss is applied to maximize the mutual information between predicted and ground-truth future frame features. This work is the first that makes a formal comparison of the two types of attention-based video future frames prediction models over different scenarios. The proposed models reach a performance competitive with more complex state-of-the-art models. The source code is available at \emph{https://github.com/XiYe20/VPTR}.
Privacy-Preserving Speech Representation Learning using Vector Quantization
Mar 15, 2022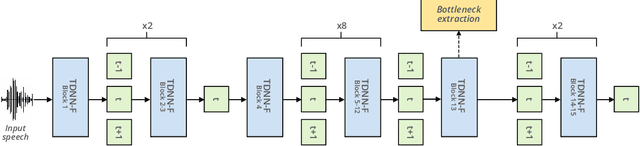
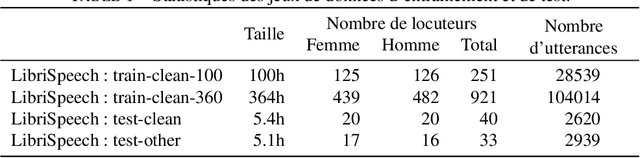

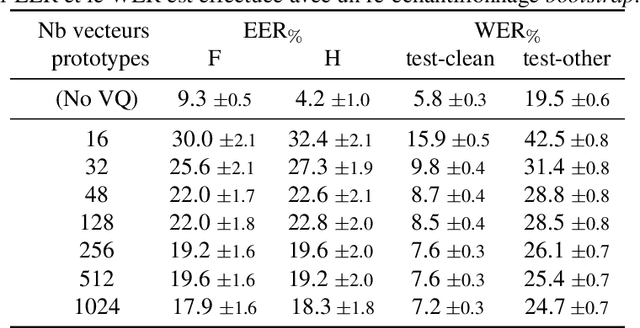
With the popularity of virtual assistants (e.g., Siri, Alexa), the use of speech recognition is now becoming more and more widespread.However, speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns.The presented experiments show that the representations extracted by the deep layers of speech recognition networks contain speaker information.This paper aims to produce an anonymous representation while preserving speech recognition performance.To this end, we propose to use vector quantization to constrain the representation space and induce the network to suppress the speaker identity.The choice of the quantization dictionary size allows to configure the trade-off between utility (speech recognition) and privacy (speaker identity concealment).
Time-Domain Speech Extraction with Spatial Information and Multi Speaker Conditioning Mechanism
Feb 07, 2021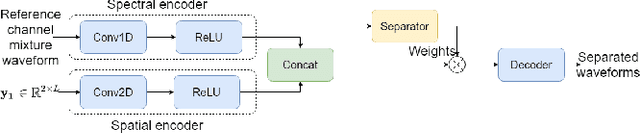
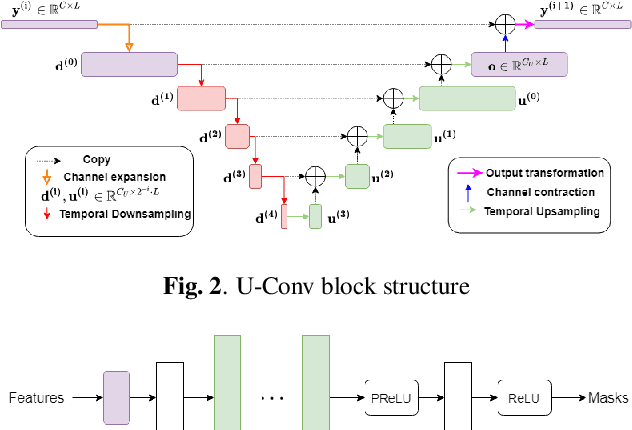
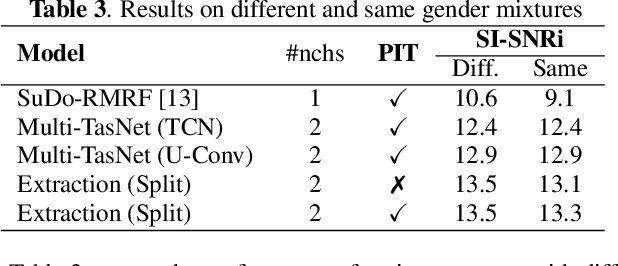

In this paper, we present a novel multi-channel speech extraction system to simultaneously extract multiple clean individual sources from a mixture in noisy and reverberant environments. The proposed method is built on an improved multi-channel time-domain speech separation network which employs speaker embeddings to identify and extract multiple targets without label permutation ambiguity. To efficiently inform the speaker information to the extraction model, we propose a new speaker conditioning mechanism by designing an additional speaker branch for receiving external speaker embeddings. Experiments on 2-channel WHAMR! data show that the proposed system improves by 9% relative the source separation performance over a strong multi-channel baseline, and it increases the speech recognition accuracy by more than 16% relative over the same baseline.
Deep Interactive Motion Prediction and Planning: Playing Games with Motion Prediction Models
Apr 05, 2022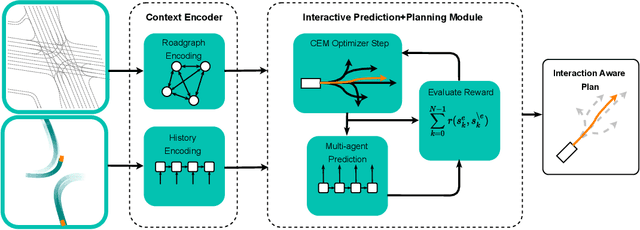
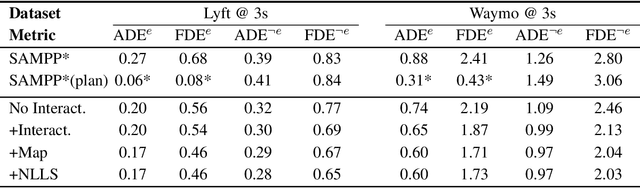

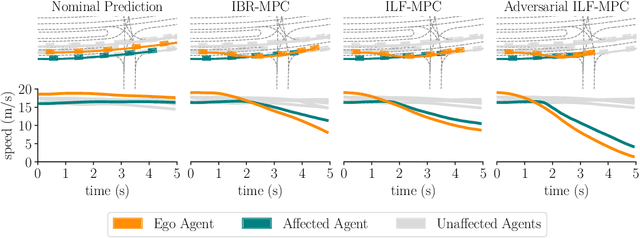
In most classical Autonomous Vehicle (AV) stacks, the prediction and planning layers are separated, limiting the planner to react to predictions that are not informed by the planned trajectory of the AV. This work presents a module that tightly couples these layers via a game-theoretic Model Predictive Controller (MPC) that uses a novel interactive multi-agent neural network policy as part of its predictive model. In our setting, the MPC planner considers all the surrounding agents by informing the multi-agent policy with the planned state sequence. Fundamental to the success of our method is the design of a novel multi-agent policy network that can steer a vehicle given the state of the surrounding agents and the map information. The policy network is trained implicitly with ground-truth observation data using backpropagation through time and a differentiable dynamics model to roll out the trajectory forward in time. Finally, we show that our multi-agent policy network learns to drive while interacting with the environment, and, when combined with the game-theoretic MPC planner, can successfully generate interactive behaviors.
Language Matters: A Weakly Supervised Pre-training Approach for Scene Text Detection and Spotting
Mar 08, 2022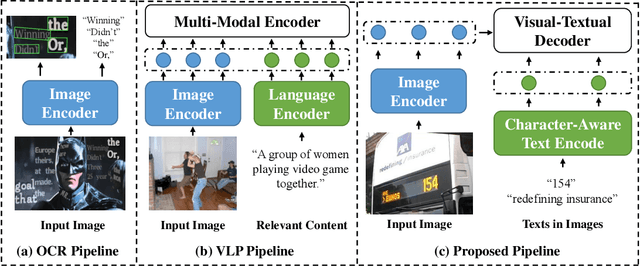
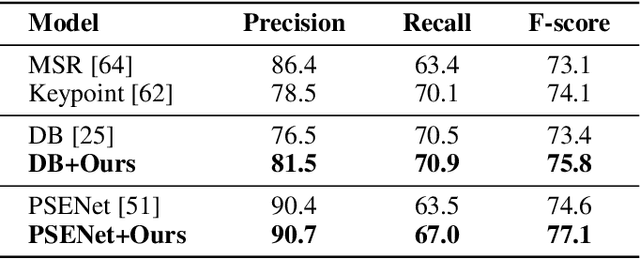
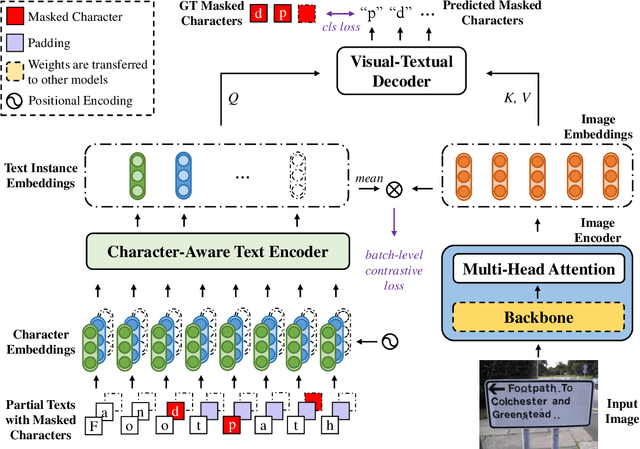

Recently, Vision-Language Pre-training (VLP) techniques have greatly benefited various vision-language tasks by jointly learning visual and textual representations, which intuitively helps in Optical Character Recognition (OCR) tasks due to the rich visual and textual information in scene text images. However, these methods cannot well cope with OCR tasks because of the difficulty in both instance-level text encoding and image-text pair acquisition (i.e. images and captured texts in them). This paper presents a weakly supervised pre-training method that can acquire effective scene text representations by jointly learning and aligning visual and textual information. Our network consists of an image encoder and a character-aware text encoder that extract visual and textual features, respectively, as well as a visual-textual decoder that models the interaction among textual and visual features for learning effective scene text representations. With the learning of textual features, the pre-trained model can attend texts in images well with character awareness. Besides, these designs enable the learning from weakly annotated texts (i.e. partial texts in images without text bounding boxes) which mitigates the data annotation constraint greatly. Experiments over the weakly annotated images in ICDAR2019-LSVT show that our pre-trained model improves F-score by +2.5% and +4.8% while transferring its weights to other text detection and spotting networks, respectively. In addition, the proposed method outperforms existing pre-training techniques consistently across multiple public datasets (e.g., +3.2% and +1.3% for Total-Text and CTW1500).
mdx: A Cloud Platform for Supporting Data Science and Cross-Disciplinary Research Collaborations
Mar 27, 2022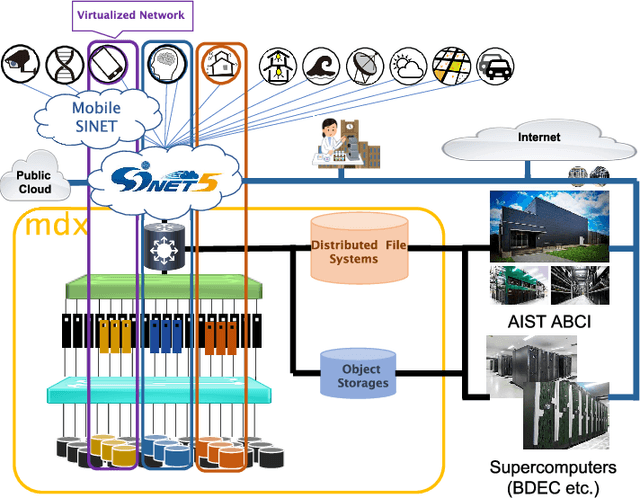
The growing amount of data and advances in data science have created a need for a new kind of cloud platform that provides users with flexibility, strong security, and the ability to couple with supercomputers and edge devices through high-performance networks. We have built such a nation-wide cloud platform, called "mdx" to meet this need. The mdx platform's virtualization service, jointly operated by 9 national universities and 2 national research institutes in Japan, launched in 2021, and more features are in development. Currently mdx is used by researchers in a wide variety of domains, including materials informatics, geo-spatial information science, life science, astronomical science, economics, social science, and computer science. This paper provides an the overview of the mdx platform, details the motivation for its development, reports its current status, and outlines its future plans.
Learning to Revise References for Faithful Summarization
Apr 13, 2022
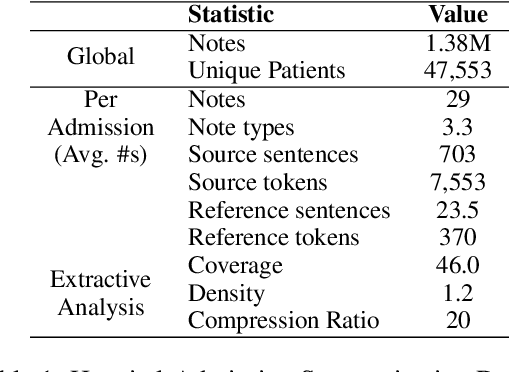
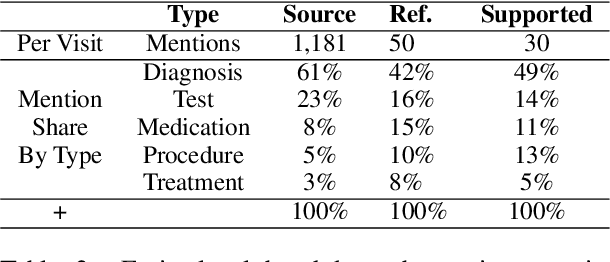

In many real-world scenarios with naturally occurring datasets, reference summaries are noisy and contain information that cannot be inferred from the source text. On large news corpora, removing low quality samples has been shown to reduce model hallucinations. Yet, this method is largely untested for smaller, noisier corpora. To improve reference quality while retaining all data, we propose a new approach: to revise--not remove--unsupported reference content. Without ground-truth supervision, we construct synthetic unsupported alternatives to supported sentences and use contrastive learning to discourage/encourage (un)faithful revisions. At inference, we vary style codes to over-generate revisions of unsupported reference sentences and select a final revision which balances faithfulness and abstraction. We extract a small corpus from a noisy source--the Electronic Health Record (EHR)--for the task of summarizing a hospital admission from multiple notes. Training models on original, filtered, and revised references, we find (1) learning from revised references reduces the hallucination rate substantially more than filtering (18.4\% vs 3.8\%), (2) learning from abstractive (vs extractive) revisions improves coherence, relevance, and faithfulness, (3) beyond redress of noisy data, the revision task has standalone value for the task: as a pre-training objective and as a post-hoc editor.