 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Interactive Motion Prediction and Planning: Playing Games with Motion Prediction Models
Apr 05, 2022
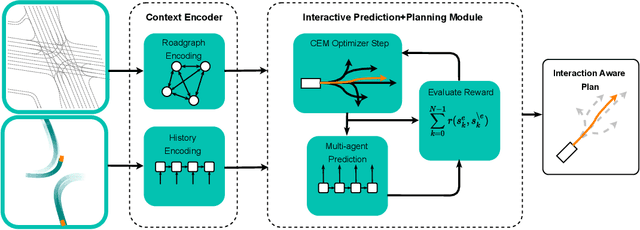
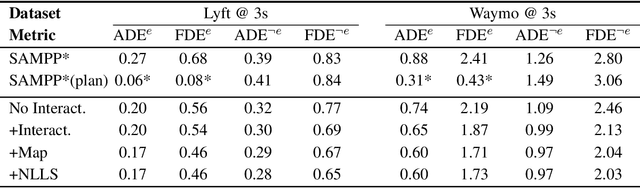

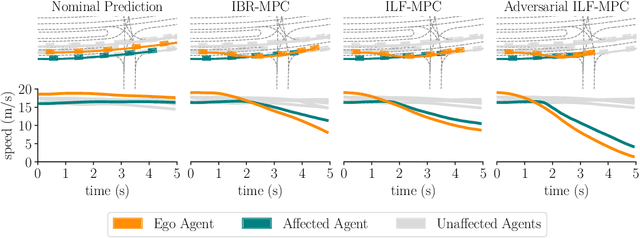
In most classical Autonomous Vehicle (AV) stacks, the prediction and planning layers are separated, limiting the planner to react to predictions that are not informed by the planned trajectory of the AV. This work presents a module that tightly couples these layers via a game-theoretic Model Predictive Controller (MPC) that uses a novel interactive multi-agent neural network policy as part of its predictive model. In our setting, the MPC planner considers all the surrounding agents by informing the multi-agent policy with the planned state sequence. Fundamental to the success of our method is the design of a novel multi-agent policy network that can steer a vehicle given the state of the surrounding agents and the map information. The policy network is trained implicitly with ground-truth observation data using backpropagation through time and a differentiable dynamics model to roll out the trajectory forward in time. Finally, we show that our multi-agent policy network learns to drive while interacting with the environment, and, when combined with the game-theoretic MPC planner, can successfully generate interactive behaviors.
Quantification of Occlusion Handling Capability of a 3D Human Pose Estimation Framework
Mar 08, 2022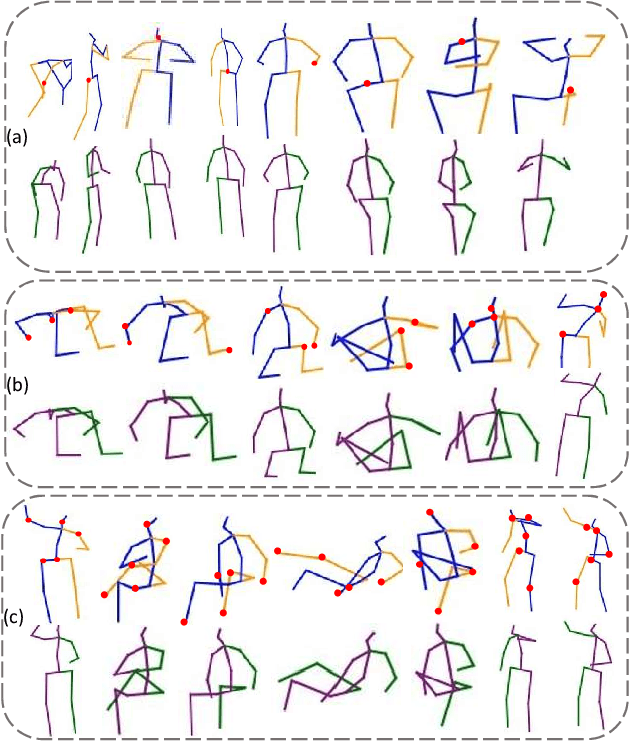
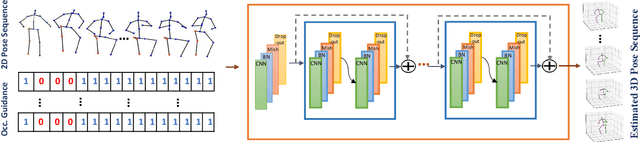
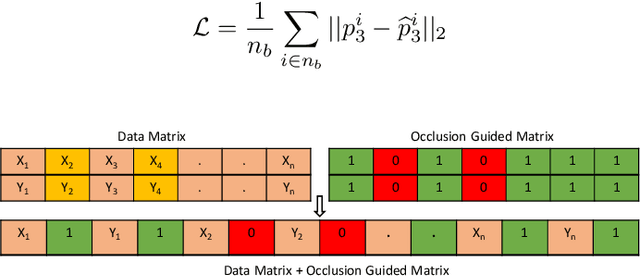
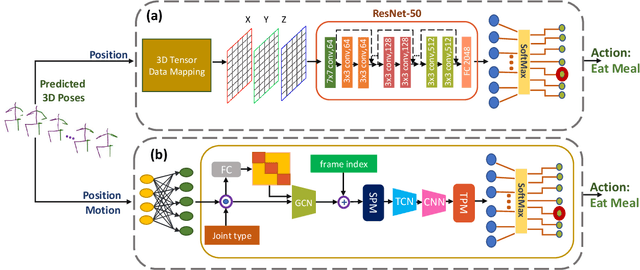
3D human pose estimation using monocular images is an important yet challenging task. Existing 3D pose detection methods exhibit excellent performance under normal conditions however their performance may degrade due to occlusion. Recently some occlusion aware methods have also been proposed, however, the occlusion handling capability of these networks has not yet been thoroughly investigated. In the current work, we propose an occlusion-guided 3D human pose estimation framework and quantify its occlusion handling capability by using different protocols. The proposed method estimates more accurate 3D human poses using 2D skeletons with missing joints as input. Missing joints are handled by introducing occlusion guidance that provides extra information about the absence or presence of a joint. Temporal information has also been exploited to better estimate the missing joints. A large number of experiments are performed for the quantification of occlusion handling capability of the proposed method on three publicly available datasets in various settings including random missing joints, fixed body parts missing, and complete frames missing, using mean per joint position error criterion. In addition to that, the quality of the predicted 3D poses is also evaluated using action classification performance as a criterion. 3D poses estimated by the proposed method achieved significantly improved action recognition performance in the presence of missing joints. Our experiments demonstrate the effectiveness of the proposed framework for handling the missing joints as well as quantification of the occlusion handling capability of the deep neural networks.
VPTR: Efficient Transformers for Video Prediction
Mar 29, 2022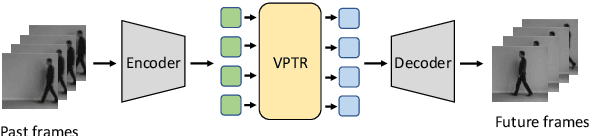
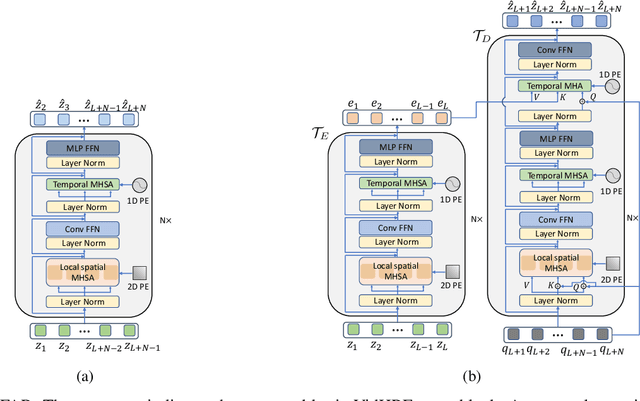
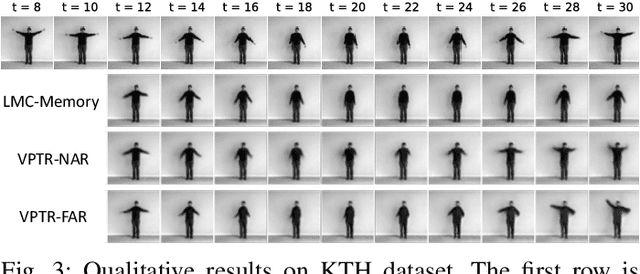
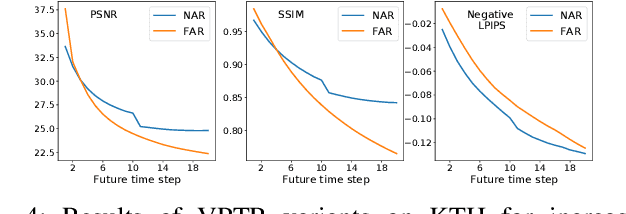
In this paper, we propose a new Transformer block for video future frames prediction based on an efficient local spatial-temporal separation attention mechanism. Based on this new Transformer block, a fully autoregressive video future frames prediction Transformer is proposed. In addition, a non-autoregressive video prediction Transformer is also proposed to increase the inference speed and reduce the accumulated inference errors of its autoregressive counterpart. In order to avoid the prediction of very similar future frames, a contrastive feature loss is applied to maximize the mutual information between predicted and ground-truth future frame features. This work is the first that makes a formal comparison of the two types of attention-based video future frames prediction models over different scenarios. The proposed models reach a performance competitive with more complex state-of-the-art models. The source code is available at \emph{https://github.com/XiYe20/VPTR}.
FenceNet: Fine-grained Footwork Recognition in Fencing
Apr 20, 2022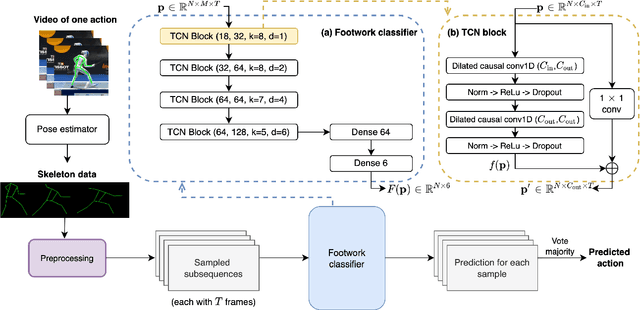
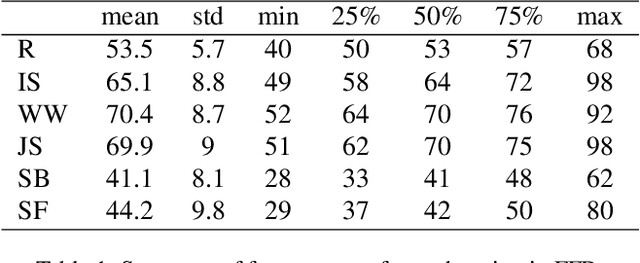

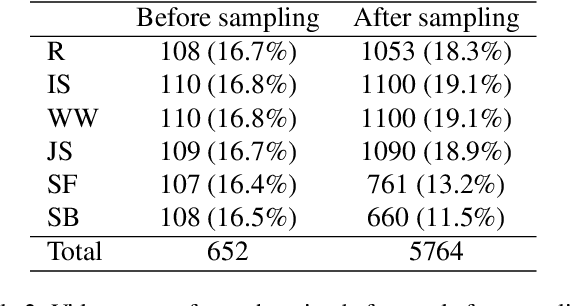
Current data analysis for the Canadian Olympic fencing team is primarily done manually by coaches and analysts. Due to the highly repetitive, yet dynamic and subtle movements in fencing, manual data analysis can be inefficient and inaccurate. We propose FenceNet as a novel architecture to automate the classification of fine-grained footwork techniques in fencing. FenceNet takes 2D pose data as input and classifies actions using a skeleton-based action recognition approach that incorporates temporal convolutional networks to capture temporal information. We train and evaluate FenceNet on the Fencing Footwork Dataset (FFD), which contains 10 fencers performing 6 different footwork actions for 10-11 repetitions each (652 total videos). FenceNet achieves 85.4% accuracy under 10-fold cross-validation, where each fencer is left out as the test set. This accuracy is within 1% of the current state-of-the-art method, JLJA (86.3%), which selects and fuses features engineered from skeleton data, depth videos, and inertial measurement units. BiFenceNet, a variant of FenceNet that captures the "bidirectionality" of human movement through two separate networks, achieves 87.6% accuracy, outperforming JLJA. Since neither FenceNet nor BiFenceNet requires data from wearable sensors, unlike JLJA, they could be directly applied to most fencing videos, using 2D pose data as input extracted from off-the-shelf 2D human pose estimators. In comparison to JLJA, our methods are also simpler as they do not require manual feature engineering, selection, or fusion.
DRSpeech: Degradation-Robust Text-to-Speech Synthesis with Frame-Level and Utterance-Level Acoustic Representation Learning
Mar 29, 2022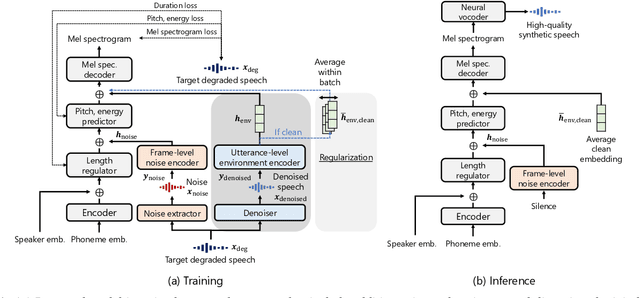

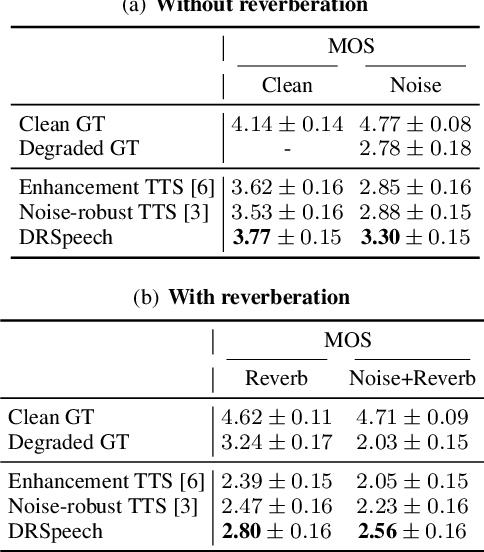

Most text-to-speech (TTS) methods use high-quality speech corpora recorded in a well-designed environment, incurring a high cost for data collection. To solve this problem, existing noise-robust TTS methods are intended to use noisy speech corpora as training data. However, they only address either time-invariant or time-variant noises. We propose a degradation-robust TTS method, which can be trained on speech corpora that contain both additive noises and environmental distortions. It jointly represents the time-variant additive noises with a frame-level encoder and the time-invariant environmental distortions with an utterance-level encoder. We also propose a regularization method to attain clean environmental embedding that is disentangled from the utterance-dependent information such as linguistic contents and speaker characteristics. Evaluation results show that our method achieved significantly higher-quality synthetic speech than previous methods in the condition including both additive noise and reverberation.
mdx: A Cloud Platform for Supporting Data Science and Cross-Disciplinary Research Collaborations
Mar 27, 2022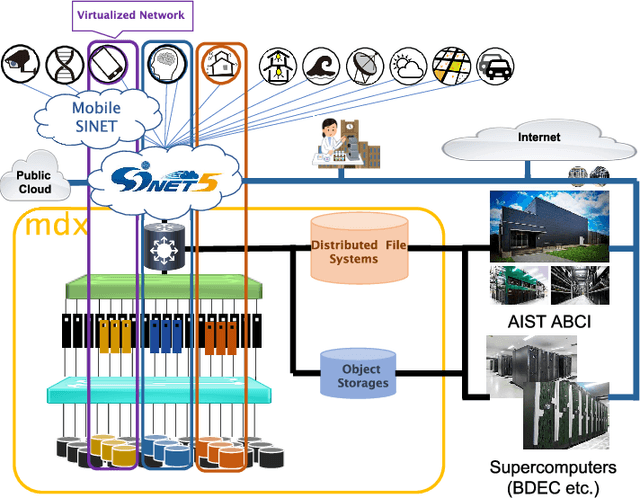
The growing amount of data and advances in data science have created a need for a new kind of cloud platform that provides users with flexibility, strong security, and the ability to couple with supercomputers and edge devices through high-performance networks. We have built such a nation-wide cloud platform, called "mdx" to meet this need. The mdx platform's virtualization service, jointly operated by 9 national universities and 2 national research institutes in Japan, launched in 2021, and more features are in development. Currently mdx is used by researchers in a wide variety of domains, including materials informatics, geo-spatial information science, life science, astronomical science, economics, social science, and computer science. This paper provides an the overview of the mdx platform, details the motivation for its development, reports its current status, and outlines its future plans.
Privacy-Preserving Speech Representation Learning using Vector Quantization
Mar 15, 2022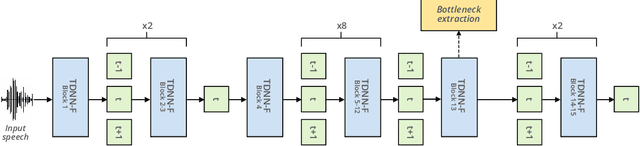
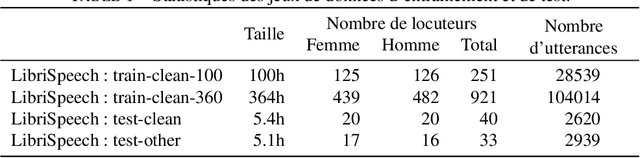

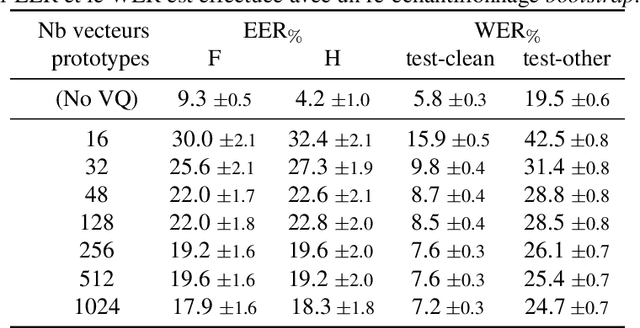
With the popularity of virtual assistants (e.g., Siri, Alexa), the use of speech recognition is now becoming more and more widespread.However, speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns.The presented experiments show that the representations extracted by the deep layers of speech recognition networks contain speaker information.This paper aims to produce an anonymous representation while preserving speech recognition performance.To this end, we propose to use vector quantization to constrain the representation space and induce the network to suppress the speaker identity.The choice of the quantization dictionary size allows to configure the trade-off between utility (speech recognition) and privacy (speaker identity concealment).
Gaze-based Object Detection in the Wild
Mar 29, 2022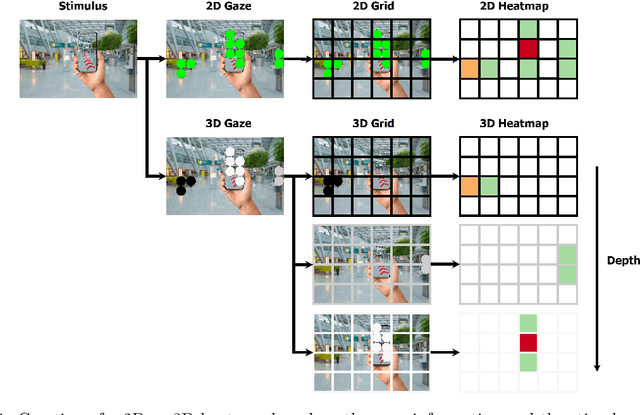
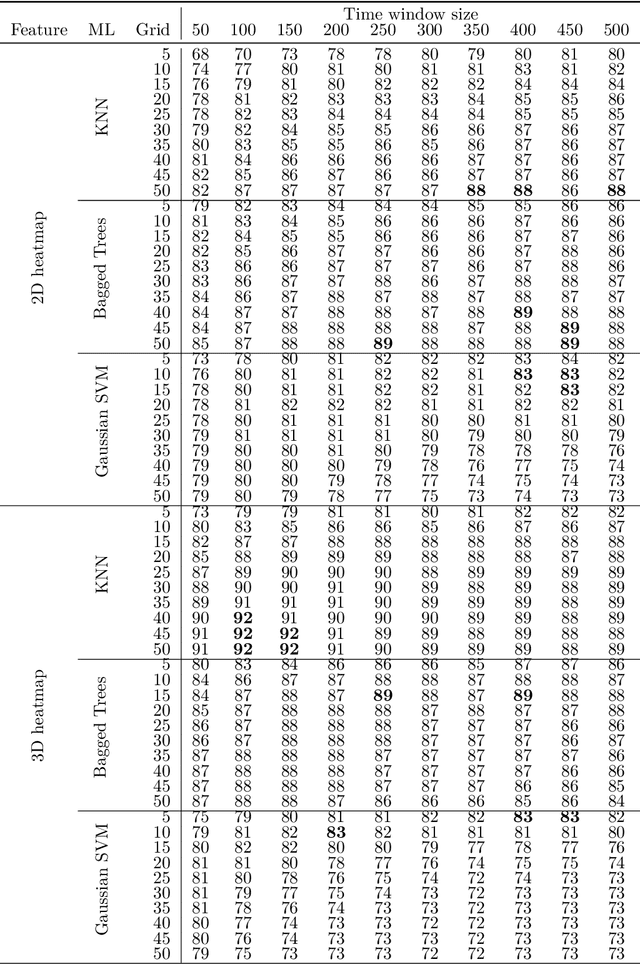
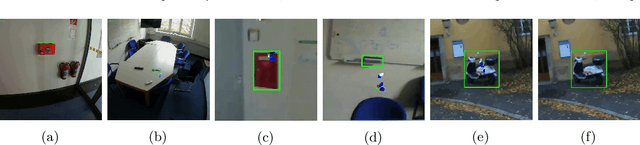
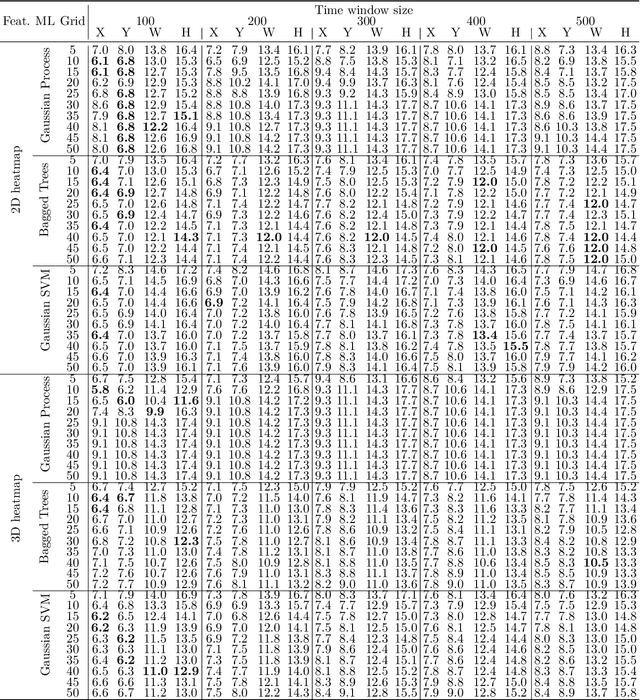
In human-robot collaboration, one challenging task is to teach a robot new yet unknown objects. Thereby, gaze can contain valuable information. We investigate if it is possible to detect objects (object or no object) from gaze data and determine their bounding box parameters. For this purpose, we explore different sizes of temporal windows, which serve as a basis for the computation of heatmaps, i.e., the spatial distribution of the gaze data. Additionally, we analyze different grid sizes of these heatmaps, and various machine learning techniques are applied. To generate the data, we conducted a small study with five subjects who could move freely and thus, turn towards arbitrary objects. This way, we chose a scenario for our data collection that is as realistic as possible. Since the subjects move while facing objects, the heatmaps also contain gaze data trajectories, complicating the detection and parameter regression.
Normalizing Flow-based Day-Ahead Wind Power Scenario Generation for Profitable and Reliable Delivery Commitments by Wind Farm Operators
Apr 05, 2022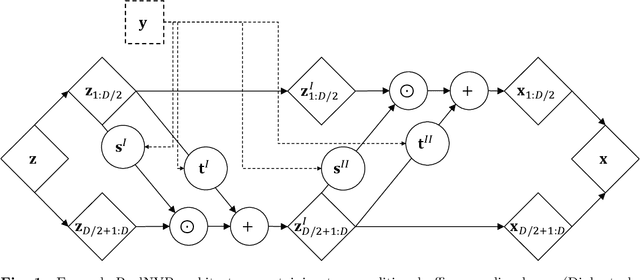
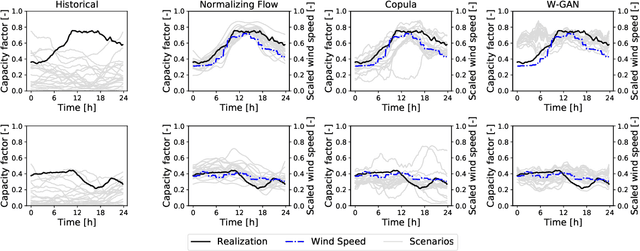
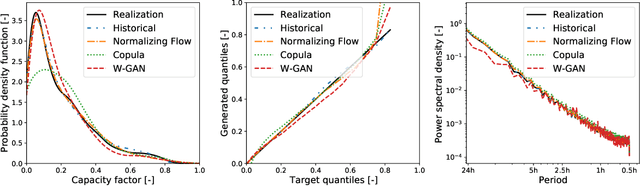
We present a specialized scenario generation method that utilizes forecast information to generate scenarios for the particular usage in day-ahead scheduling problems. In particular, we use normalizing flows to generate wind power generation scenarios by sampling from a conditional distribution that uses day-ahead wind speed forecasts to tailor the scenarios to the specific day. We apply the generated scenarios in a simple stochastic day-ahead bidding problem of a wind electricity producer and run a statistical analysis focusing on whether the scenarios yield profitable and reliable decisions. Compared to conditional scenarios generated from Gaussian copulas and Wasserstein-generative adversarial networks, the normalizing flow scenarios identify the daily trends more accurately and with a lower spread while maintaining a diverse variety. In the stochastic day-ahead bidding problem, the conditional scenarios from all methods lead to significantly more profitable and reliable results compared to an unconditional selection of historical scenarios. The obtained profits using the normalizing flow scenarios are consistently closest to the perfect foresight solution, in particular, for small sets of only five scenarios.
Multi-View Transformer for 3D Visual Grounding
Apr 05, 2022
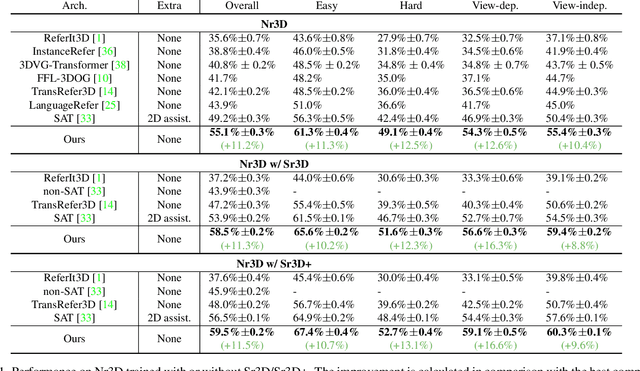
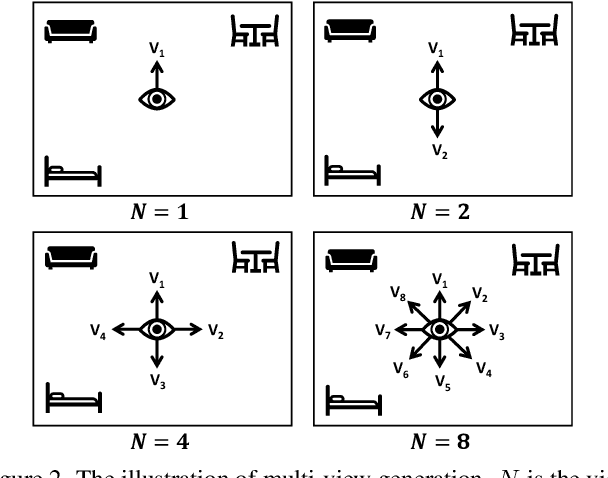
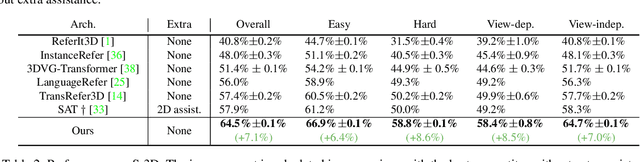
The 3D visual grounding task aims to ground a natural language description to the targeted object in a 3D scene, which is usually represented in 3D point clouds. Previous works studied visual grounding under specific views. The vision-language correspondence learned by this way can easily fail once the view changes. In this paper, we propose a Multi-View Transformer (MVT) for 3D visual grounding. We project the 3D scene to a multi-view space, in which the position information of the 3D scene under different views are modeled simultaneously and aggregated together. The multi-view space enables the network to learn a more robust multi-modal representation for 3D visual grounding and eliminates the dependence on specific views. Extensive experiments show that our approach significantly outperforms all state-of-the-art methods. Specifically, on Nr3D and Sr3D datasets, our method outperforms the best competitor by 11.2% and 7.1% and even surpasses recent work with extra 2D assistance by 5.9% and 6.6%. Our code is available at https://github.com/sega-hsj/MVT-3DVG.