 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automated Machine Learning for Deep Recommender Systems: A Survey
Apr 04, 2022
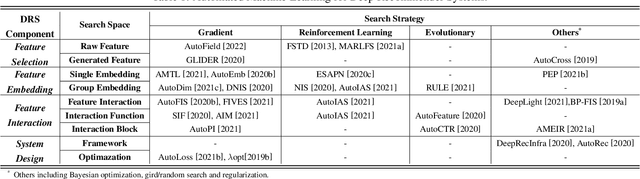
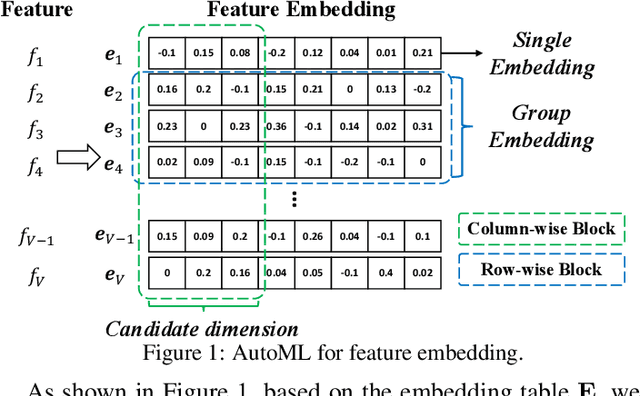
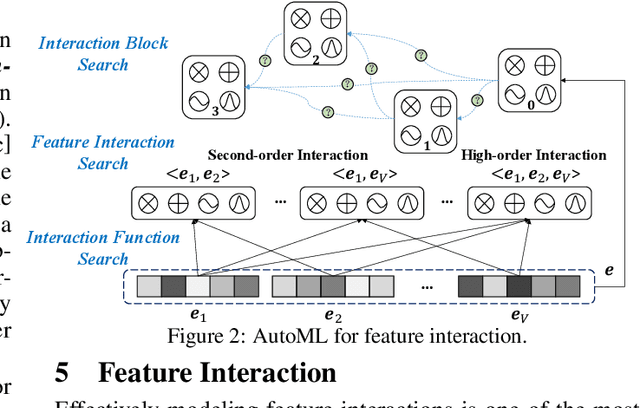
Deep recommender systems (DRS) are critical for current commercial online service providers, which address the issue of information overload by recommending items that are tailored to the user's interests and preferences. They have unprecedented feature representations effectiveness and the capacity of modeling the non-linear relationships between users and items. Despite their advancements, DRS models, like other deep learning models, employ sophisticated neural network architectures and other vital components that are typically designed and tuned by human experts. This article will give a comprehensive summary of automated machine learning (AutoML) for developing DRS models. We first provide an overview of AutoML for DRS models and the related techniques. Then we discuss the state-of-the-art AutoML approaches that automate the feature selection, feature embeddings, feature interactions, and system design in DRS. Finally, we discuss appealing research directions and summarize the survey.
Epistemic AI platform accelerates innovation by connecting biomedical knowledge
Jan 27, 2022

Epistemic AI accelerates biomedical discovery by finding hidden connections in the network of biomedical knowledge. The Epistemic AI web-based software platform embodies the concept of knowledge mapping, an interactive process that relies on a knowledge graph in combination with natural language processing (NLP), information retrieval, relevance feedback, and network analysis. Knowledge mapping reduces information overload, prevents costly mistakes, and minimizes missed opportunities in the research process. The platform combines state-of-the-art methods for information extraction with machine learning, artificial intelligence and network analysis. Starting from a single biological entity, such as a gene or disease, users may: a) construct a map of connections to that entity, b) map an entire domain of interest, and c) gain insight into large biological networks of knowledge. Knowledge maps provide clarity and organization, simplifying the day-to-day research processes.
Analogical discovery of disordered perovskite oxides by crystal structure information hidden in unsupervised material fingerprints
May 25, 2021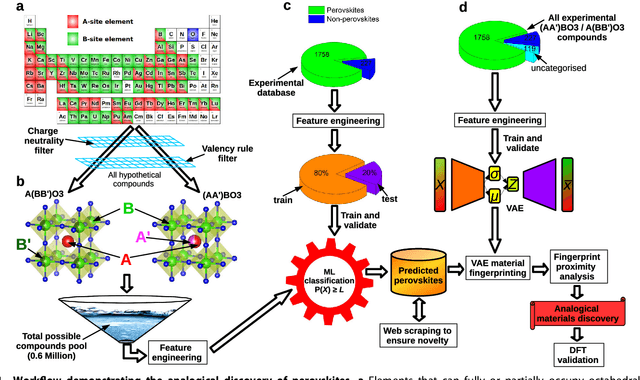

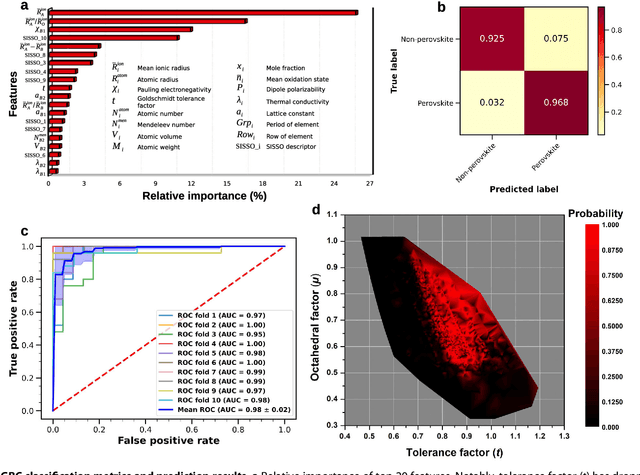
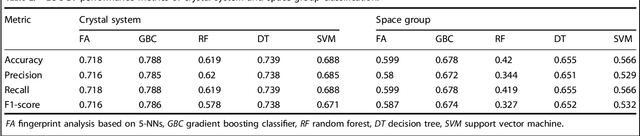
Compositional disorder induces myriad captivating phenomena in perovskites. Target-driven discovery of perovskite solid solutions has been a great challenge due to the analytical complexity introduced by disorder. Here, we demonstrate that an unsupervised deep learning strategy can find fingerprints of disordered materials that embed perovskite formability and underlying crystal structure information by learning only from the chemical composition, manifested in (A1-xA'x)BO3 and A(B1-xB'x)O3 formulae. This phenomenon can be capitalized to predict the crystal symmetry of experimental compositions, outperforming several supervised machine learning (ML) algorithms. The educated nature of material fingerprints has led to the conception of analogical materials discovery that facilitates inverse exploration of promising perovskites based on similarity investigation with known materials. The search space of unstudied perovskites is screened from ~600,000 feasible compounds using experimental data powered ML models and automated web mining tools at a 94% success rate. This concept further provides insights on possible phase transitions and computational modelling of complex compositions. The proposed quantitative analysis of materials analogies is expected to bridge the gap between the existing materials literature and the undiscovered terrain.
End-to-end multi-talker audio-visual ASR using an active speaker attention module
Apr 01, 2022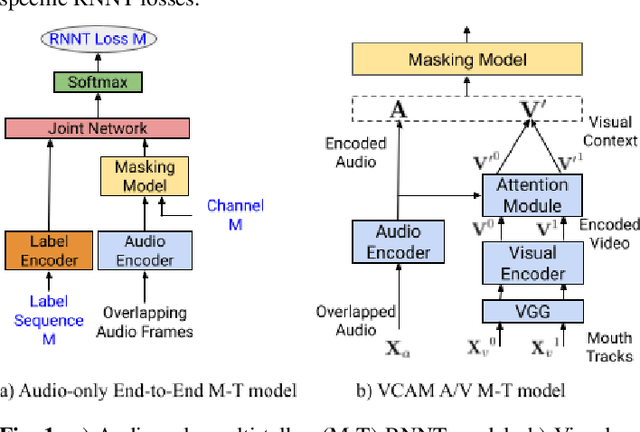
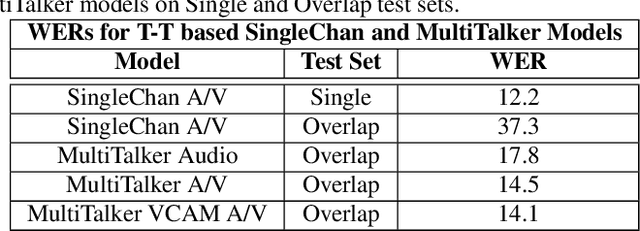
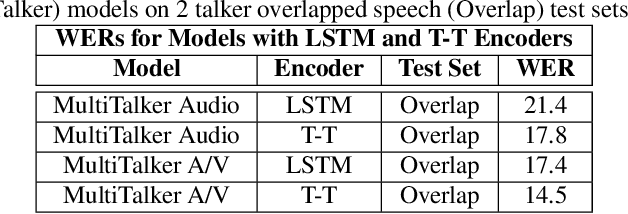
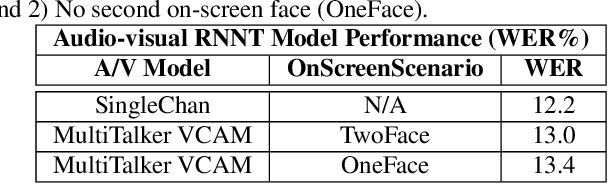
This paper presents a new approach for end-to-end audio-visual multi-talker speech recognition. The approach, referred to here as the visual context attention model (VCAM), is important because it uses the available video information to assign decoded text to one of multiple visible faces. This essentially resolves the label ambiguity issue associated with most multi-talker modeling approaches which can decode multiple label strings but cannot assign the label strings to the correct speakers. This is implemented as a transformer-transducer based end-to-end model and evaluated using a two speaker audio-visual overlapping speech dataset created from YouTube videos. It is shown in the paper that the VCAM model improves performance with respect to previously reported audio-only and audio-visual multi-talker ASR systems.
Generating Clarifying Questions for Query Refinement in Source Code Search
Jan 24, 2022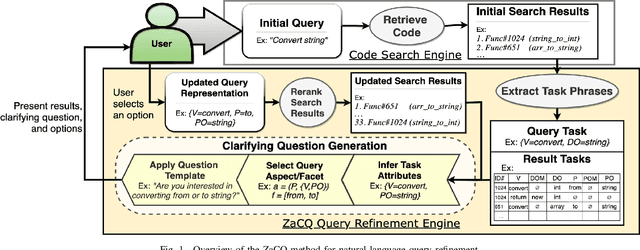
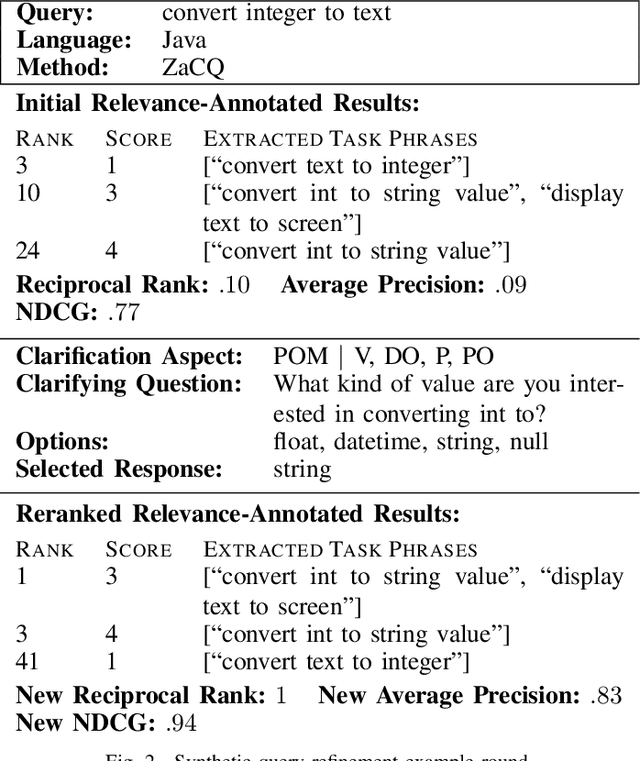
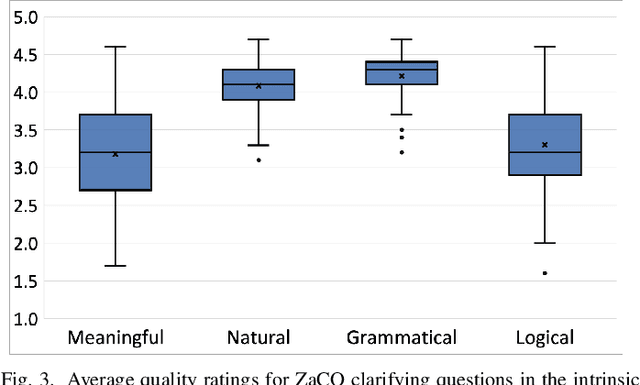
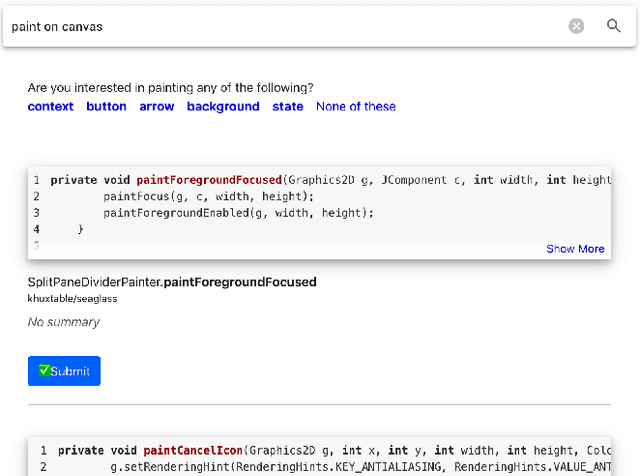
In source code search, a common information-seeking strategy involves providing a short initial query with a broad meaning, and then iteratively refining the query using terms gleaned from the results of subsequent searches. This strategy requires programmers to spend time reading search results that are irrelevant to their development needs. In contrast, when programmers seek information from other humans, they typically refine queries by asking and answering clarifying questions. Clarifying questions have been shown to benefit general-purpose search engines, but have not been examined in the context of code search. We present a method for generating natural-sounding clarifying questions using information extracted from function names and comments. Our method outperformed a keyword-based method for single-turn refinement in synthetic studies, and was associated with shorter search duration in human studies.
Clifford Circuits can be Properly PAC Learned if and only if $\textsf{RP}=\textsf{NP}$
Apr 13, 2022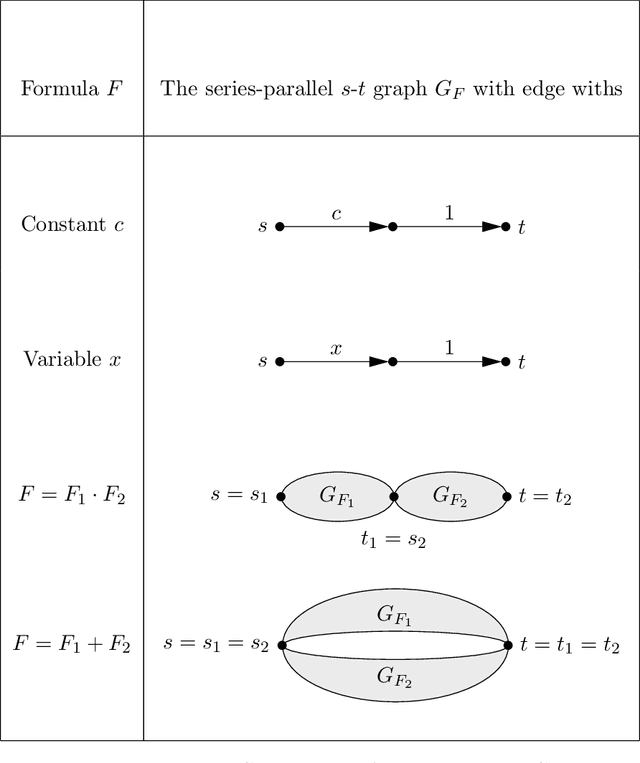
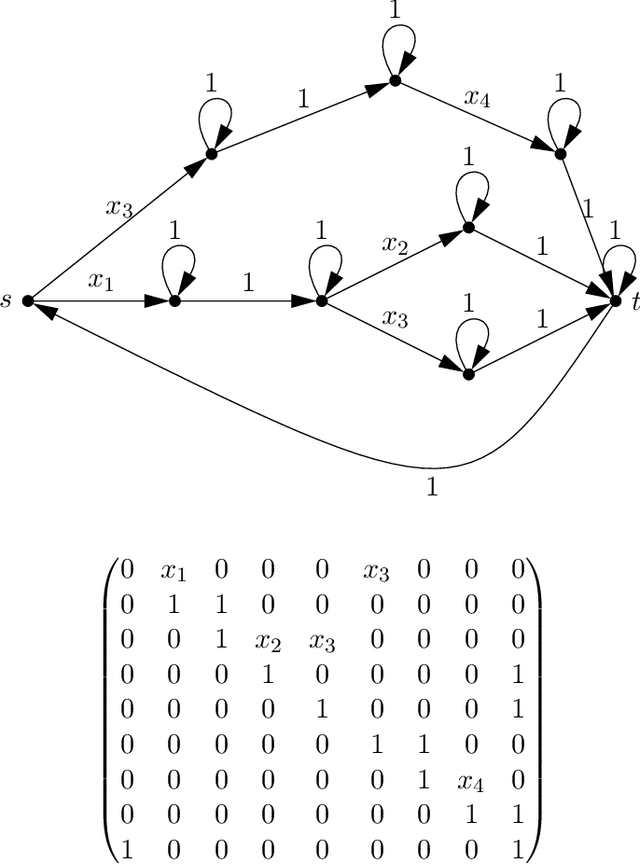
Given a dataset of input states, measurements, and probabilities, is it possible to efficiently predict the measurement probabilities associated with a quantum circuit? Recent work of Caro and Datta (2020) studied the problem of PAC learning quantum circuits in an information theoretic sense, leaving open questions of computational efficiency. In particular, one candidate class of circuits for which an efficient learner might have been possible was that of Clifford circuits, since the corresponding set of states generated by such circuits, called stabilizer states, are known to be efficiently PAC learnable (Rocchetto 2018). Here we provide a negative result, showing that proper learning of CNOT circuits is hard for classical learners unless $\textsf{RP} = \textsf{NP}$. As the classical analogue and subset of Clifford circuits, this naturally leads to a hardness result for Clifford circuits as well. Additionally, we show that if $\textsf{RP} = \textsf{NP}$ then there would exist efficient proper learning algorithms for CNOT and Clifford circuits. By similar arguments, we also find that an efficient proper quantum learner for such circuits exists if and only if $\textsf{NP} \subseteq \textsf{RQP}$.
Unbiased Directed Object Attention Graph for Object Navigation
Apr 09, 2022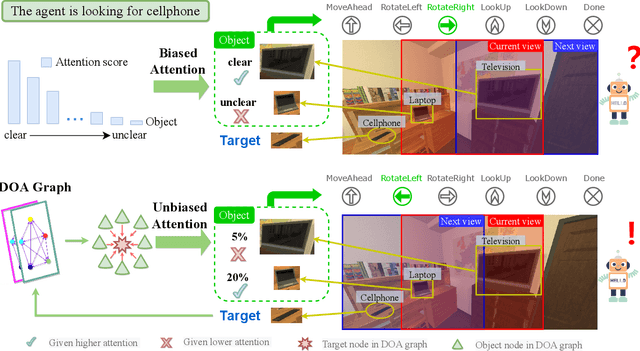
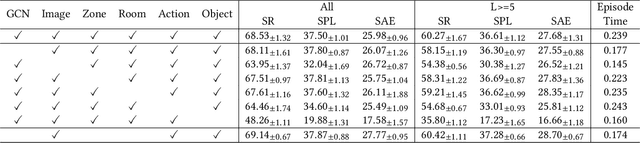
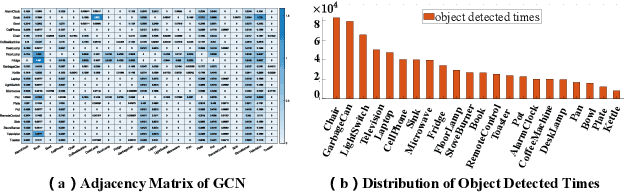
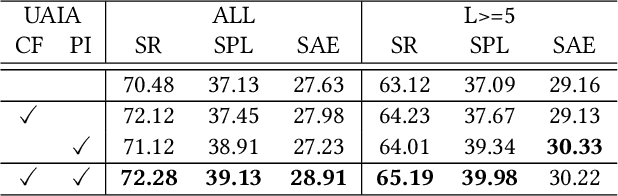
Object navigation tasks require agents to locate specific objects in unknown environments based on visual information. Previously, graph convolutions were used to implicitly explore the relationships between objects. However, due to differences in visibility among objects, it is easy to generate biases in object attention. Thus, in this paper, we propose a directed object attention (DOA) graph to guide the agent in explicitly learning the attention relationships between objects, thereby reducing the object attention bias. In particular, we use the DOA graph to perform unbiased adaptive object attention (UAOA) on the object features and unbiased adaptive image attention (UAIA) on the raw images, respectively. To distinguish features in different branches, a concise adaptive branch energy distribution (ABED) method is proposed. We assess our methods on the AI2-Thor dataset. Compared with the state-of-the-art (SOTA) method, our method reports 7.4%, 8.1% and 17.6% increase in success rate (SR), success weighted by path length (SPL) and success weighted by action efficiency (SAE), respectively.
Bits and Pieces: Understanding Information Decomposition from Part-whole Relationships and Formal Logic
Aug 21, 2020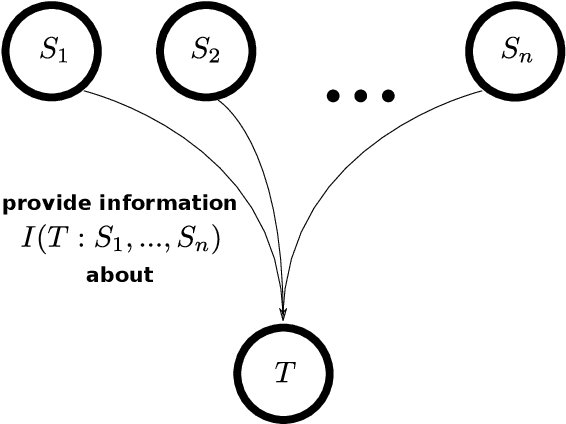
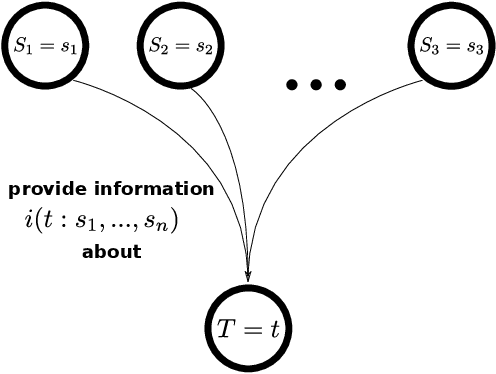

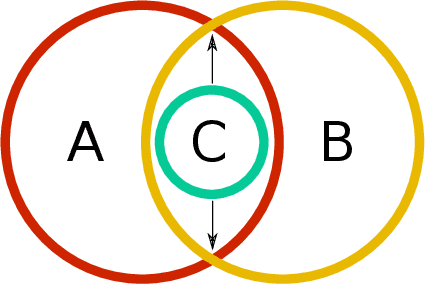
Partial information decomposition (PID) seeks to decompose the multivariate mutual information that a set of source variables contains about a target variable into basic pieces, the so called "atoms of information". Each atom describes a distinct way in which the sources may contain information about the target. In this paper we show, first, that the entire theory of partial information decomposition can be derived from considerations of elementary parthood relationships between information contributions. This way of approaching the problem has the advantage of directly characterizing the atoms of information, instead of taking an indirect approach via the concept of redundancy. Secondly, we describe several intriguing links between PID and formal logic. In particular, we show how to define a measure of PID based on the information provided by certain statements about source realizations. Furthermore, we show how the mathematical lattice structure underlying PID theory can be translated into an isomorphic structure of logical statements with a particularly simple ordering relation: logical implication. The conclusion to be drawn from these considerations is that there are three isomorphic "worlds" of partial information decomposition, i.e. three equivalent ways to mathematically describe the decomposition of the information carried by a set of sources about a target: the world of parthood relationships, the world of logical statements, and the world of antichains that was utilized by Williams and Beer in their original exposition of PID theory. We additionally show how the parthood perspective provides a systematic way to answer a type of question that has been much discussed in the PID field: whether a partial information decomposition can be uniquely determined based on concepts other than redundant information.
Mining Fine-grained Semantics via Graph Neural Networks for Evidence-based Fake News Detection
Jan 18, 2022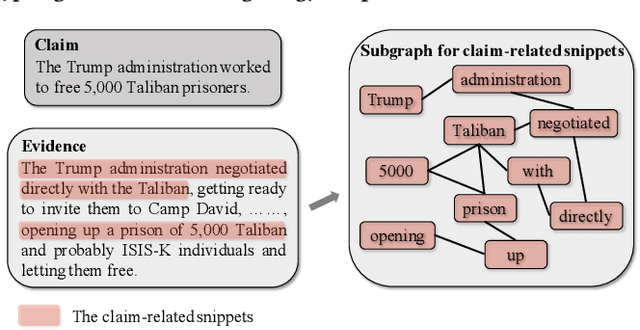
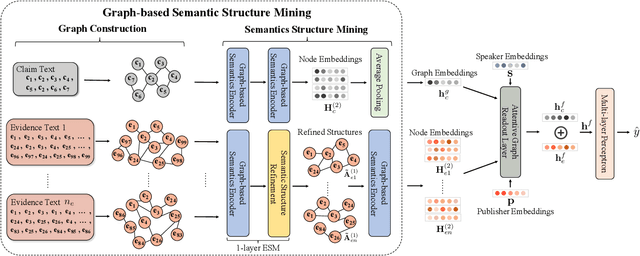
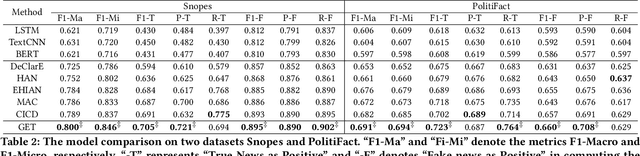
The prevalence and perniciousness of fake news has been a critical issue on the Internet, which stimulates the development of automatic fake news detection in turn. In this paper, we focus on the evidence-based fake news detection, where several evidences are utilized to probe the veracity of news (i.e., a claim). Most previous methods first employ sequential models to embed the semantic information and then capture the claim-evidence interaction based on different attention mechanisms. Despite their effectiveness, they still suffer from two main weaknesses. Firstly, due to the inherent drawbacks of sequential models, they fail to integrate the relevant information that is scattered far apart in evidences for veracity checking. Secondly, they neglect much redundant information contained in evidences that may be useless or even harmful. To solve these problems, we propose a unified Graph-based sEmantic sTructure mining framework, namely GET in short. Specifically, different from the existing work that treats claims and evidences as sequences, we model them as graph-structured data and capture the long-distance semantic dependency among dispersed relevant snippets via neighborhood propagation. After obtaining contextual semantic information, our model reduces information redundancy by performing graph structure learning. Finally, the fine-grained semantic representations are fed into the downstream claim-evidence interaction module for predictions. Comprehensive experiments have demonstrated the superiority of GET over the state-of-the-arts.
I-Tuning: Tuning Language Models with Image for Caption Generation
Feb 14, 2022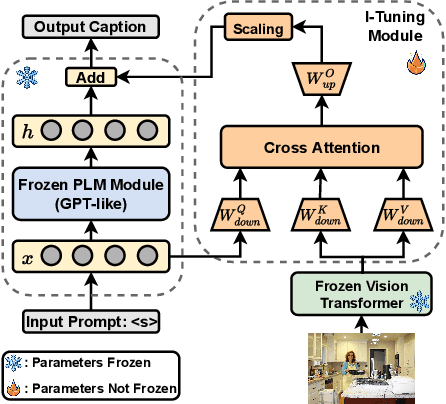
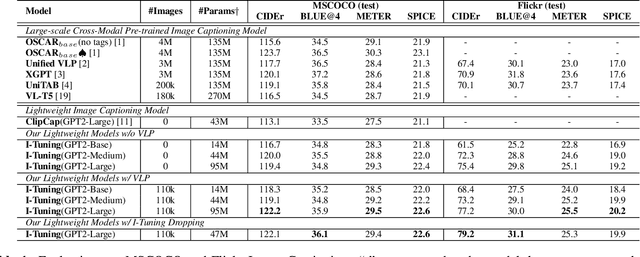
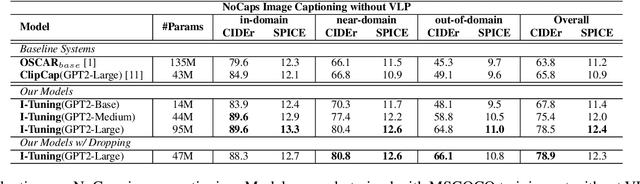

Recently, tuning the pre-trained language model (PLM) in a parameter-efficient manner becomes a popular topic in the natural language processing area. However, most of them focus on tuning the PLM with the text-only information. In this work, we propose a new perspective to tune the frozen PLM with images for caption generation. We denote our method as I-Tuning, which can automatically filter the vision information from images to adjust the output hidden states of PLM. Evaluating on the image captioning tasks (MSCOCO and Flickr30k Captioning), our method achieves comparable or even better performance than the previous models which have 2-4 times more trainable parameters and/or consume a large amount of cross-modal pre-training data.