 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Target Filter and Detector for Speaker Diarization
Mar 30, 2022
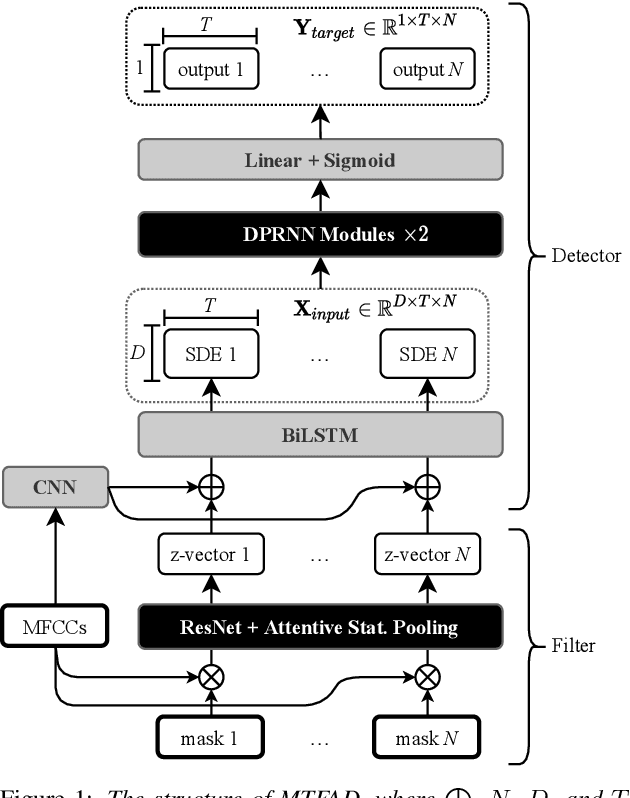
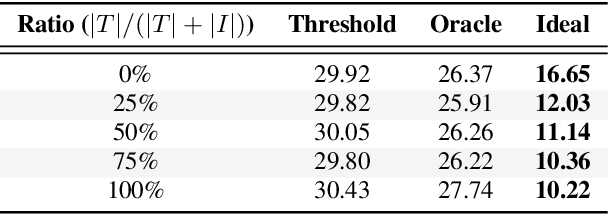
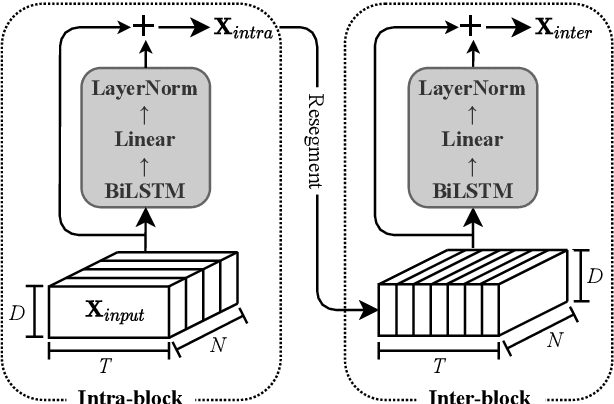
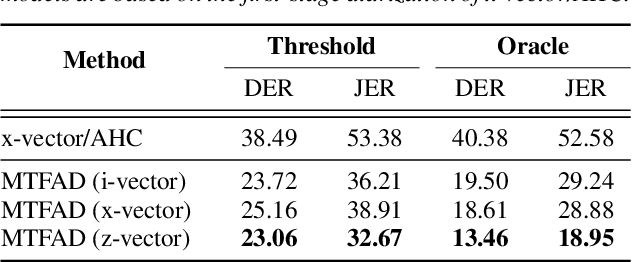
A good representation of a target speaker usually helps to extract important information about the speaker and detect the corresponding temporal regions in a multi-speaker conversation. In this paper, we propose a neural architecture that simultaneously extracts speaker embeddings consistent with the speaker diarization objective and detects the presence of each speaker frame by frame, regardless of the number of speakers in the conversation. To this end, a residual network (ResNet) and a dual-path recurrent neural network (DPRNN) are integrated into a unified structure. When tested on the 2-speaker CALLHOME corpus, our proposed model outperforms most methods published so far. Evaluated in a more challenging case of concurrent speakers ranging from two to seven, our system also achieves relative diarization error rate reductions of 26.35% and 6.4% over two typical baselines, namely the traditional x-vector clustering system and the attention-based system.
AccMPEG: Optimizing Video Encoding for Video Analytics
Apr 26, 2022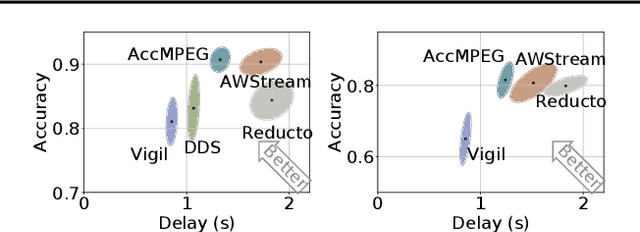
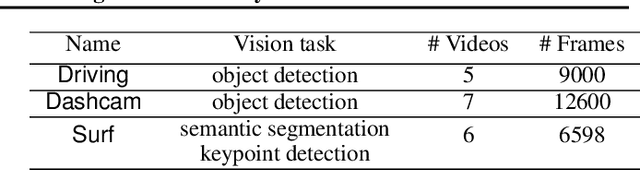
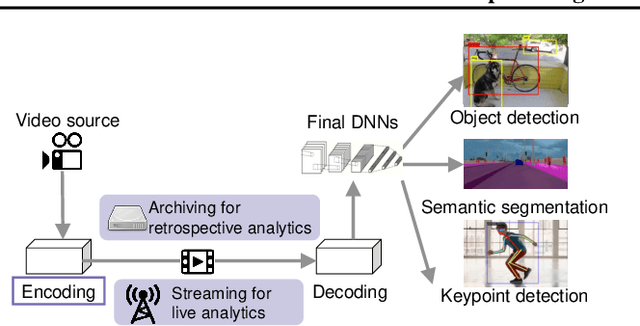

With more videos being recorded by edge sensors (cameras) and analyzed by computer-vision deep neural nets (DNNs), a new breed of video streaming systems has emerged, with the goal to compress and stream videos to remote servers in real time while preserving enough information to allow highly accurate inference by the server-side DNNs. An ideal design of the video streaming system should simultaneously meet three key requirements: (1) low latency of encoding and streaming, (2) high accuracy of server-side DNNs, and (3) low compute overheads on the camera. Unfortunately, despite many recent efforts, such video streaming system has hitherto been elusive, especially when serving advanced vision tasks such as object detection or semantic segmentation. This paper presents AccMPEG, a new video encoding and streaming system that meets all the three requirements. The key is to learn how much the encoding quality at each (16x16) macroblock can influence the server-side DNN accuracy, which we call accuracy gradient. Our insight is that these macroblock-level accuracy gradient can be inferred with sufficient precision by feeding the video frames through a cheap model. AccMPEG provides a suite of techniques that, given a new server-side DNN, can quickly create a cheap model to infer the accuracy gradient on any new frame in near realtime. Our extensive evaluation of AccMPEG on two types of edge devices (one Intel Xeon Silver 4100 CPU or NVIDIA Jetson Nano) and three vision tasks (six recent pre-trained DNNs) shows that AccMPEG (with the same camera-side compute resources) can reduce the end-to-end inference delay by 10-43% without hurting accuracy compared to the state-of-the-art baselines
Kernel Proposal Network for Arbitrary Shape Text Detection
Mar 12, 2022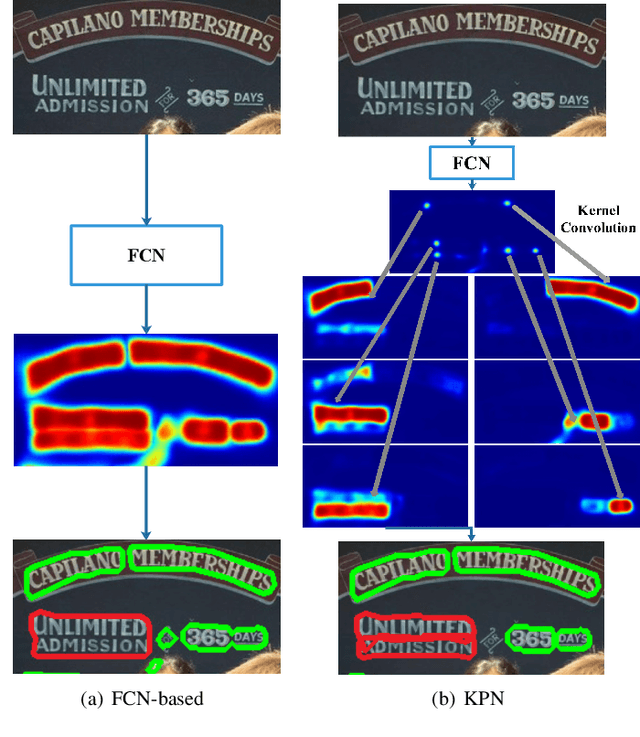


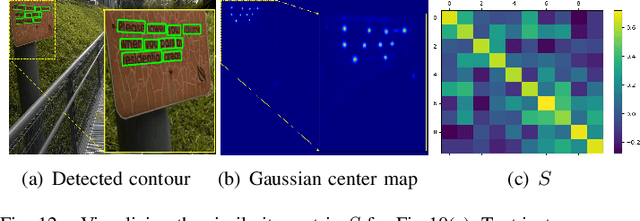
Segmentation-based methods have achieved great success for arbitrary shape text detection. However, separating neighboring text instances is still one of the most challenging problems due to the complexity of texts in scene images. In this paper, we propose an innovative Kernel Proposal Network (dubbed KPN) for arbitrary shape text detection. The proposed KPN can separate neighboring text instances by classifying different texts into instance-independent feature maps, meanwhile avoiding the complex aggregation process existing in segmentation-based arbitrary shape text detection methods. To be concrete, our KPN will predict a Gaussian center map for each text image, which will be used to extract a series of candidate kernel proposals (i.e., dynamic convolution kernel) from the embedding feature maps according to their corresponding keypoint positions. To enforce the independence between kernel proposals, we propose a novel orthogonal learning loss (OLL) via orthogonal constraints. Specifically, our kernel proposals contain important self-information learned by network and location information by position embedding. Finally, kernel proposals will individually convolve all embedding feature maps for generating individual embedded maps of text instances. In this way, our KPN can effectively separate neighboring text instances and improve the robustness against unclear boundaries. To our knowledge, our work is the first to introduce the dynamic convolution kernel strategy to efficiently and effectively tackle the adhesion problem of neighboring text instances in text detection. Experimental results on challenging datasets verify the impressive performance and efficiency of our method. The code and model are available at https://github.com/GXYM/KPN.
The Sound of Bounding-Boxes
Mar 30, 2022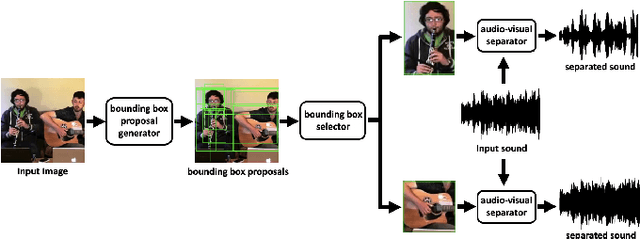
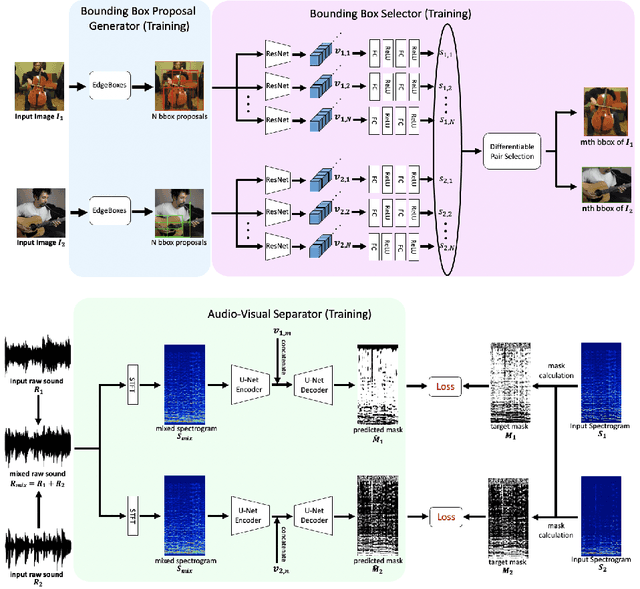
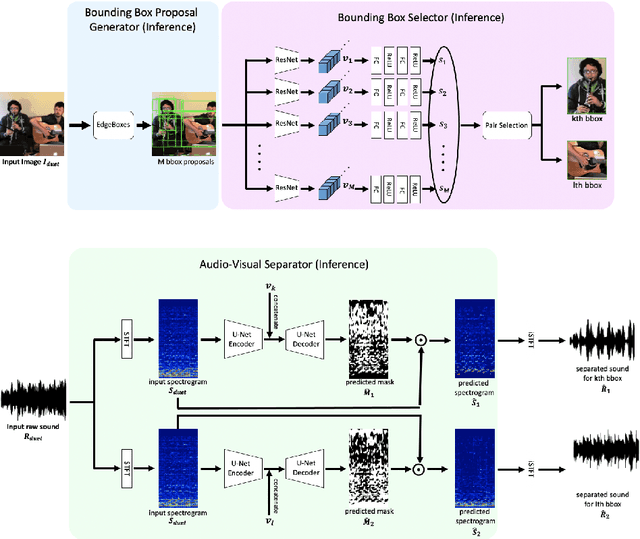

In the task of audio-visual sound source separation, which leverages visual information for sound source separation, identifying objects in an image is a crucial step prior to separating the sound source. However, existing methods that assign sound on detected bounding boxes suffer from a problem that their approach heavily relies on pre-trained object detectors. Specifically, when using these existing methods, it is required to predetermine all the possible categories of objects that can produce sound and use an object detector applicable to all such categories. To tackle this problem, we propose a fully unsupervised method that learns to detect objects in an image and separate sound source simultaneously. As our method does not rely on any pre-trained detector, our method is applicable to arbitrary categories without any additional annotation. Furthermore, although being fully unsupervised, we found that our method performs comparably in separation accuracy.
Semantically Video Coding: Instill Static-Dynamic Clues into Structured Bitstream for AI Tasks
Jan 25, 2022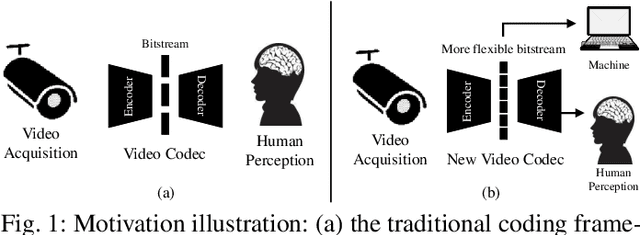
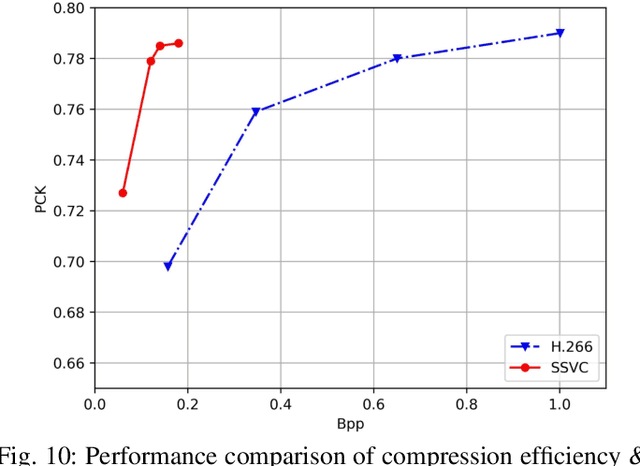
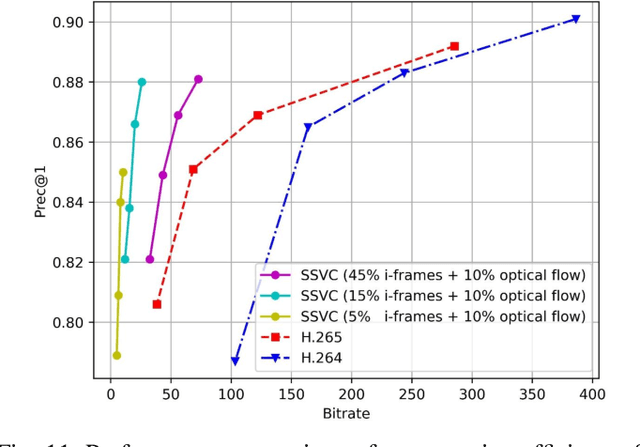
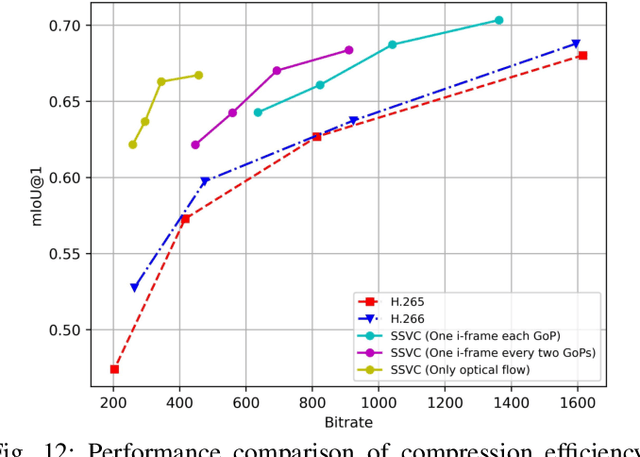
Traditional media coding schemes typically encode image/video into a semantic-unknown binary stream, which fails to directly support downstream intelligent tasks at the bitstream level. Semantically Structured Image Coding (SSIC) framework makes the first attempt to enable decoding-free or partial-decoding image intelligent task analysis via a Semantically Structured Bitstream (SSB). However, the SSIC only considers image coding and its generated SSB only contains the static object information. In this paper, we extend the idea of semantically structured coding from video coding perspective and propose an advanced Semantically Structured Video Coding (SSVC) framework to support heterogeneous intelligent applications. Video signals contain more rich dynamic motion information and exist more redundancy due to the similarity between adjacent frames. Thus, we present a reformulation of semantically structured bitstream (SSB) in SSVC which contains both static object characteristics and dynamic motion clues. Specifically, we introduce optical flow to encode continuous motion information and reduce cross-frame redundancy via a predictive coding architecture, then the optical flow and residual information are reorganized into SSB, which enables the proposed SSVC could better adaptively support video-based downstream intelligent applications. Extensive experiments demonstrate that the proposed SSVC framework could directly support multiple intelligent tasks just depending on a partially decoded bitstream. This avoids the full bitstream decompression and thus significantly saves bitrate/bandwidth consumption for intelligent analytics. We verify this point on the tasks of image object detection, pose estimation, video action recognition, video object segmentation, etc.
Deep Page-Level Interest Network in Reinforcement Learning for Ads Allocation
Apr 01, 2022
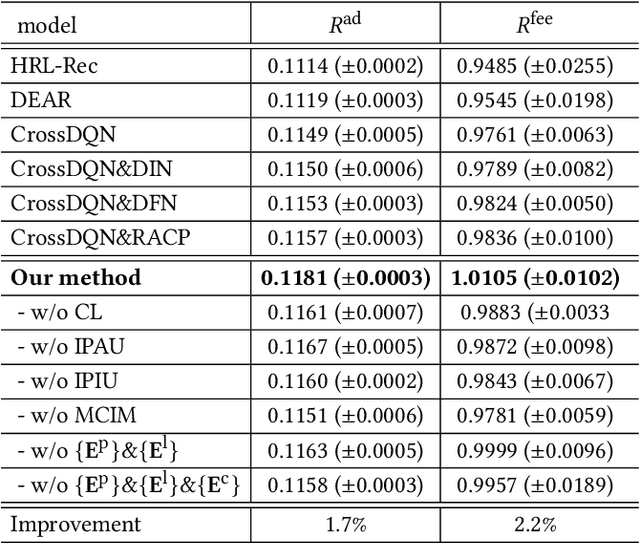
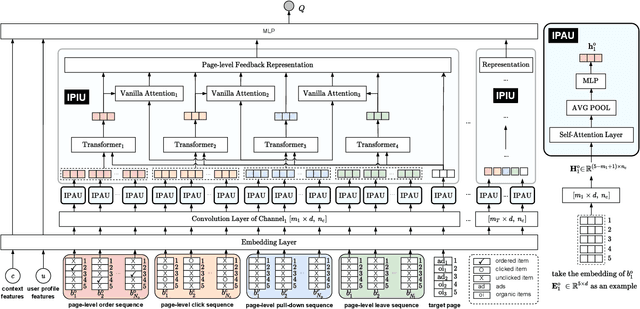
A mixed list of ads and organic items is usually displayed in feed and how to allocate the limited slots to maximize the overall revenue is a key problem. Meanwhile, modeling user preference with historical behavior is essential in recommendation and advertising (e.g., CTR prediction and ads allocation). Most previous works for user behavior modeling only model user's historical point-level positive feedback (i.e., click), which neglect the page-level information of feedback and other types of feedback. To this end, we propose Deep Page-level Interest Network (DPIN) to model the page-level user preference and exploit multiple types of feedback. Specifically, we introduce four different types of page-level feedback as input, and capture user preference for item arrangement under different receptive fields through the multi-channel interaction module. Through extensive offline and online experiments on Meituan food delivery platform, we demonstrate that DPIN can effectively model the page-level user preference and increase the revenue for the platform.
An Unsupervised Information-Theoretic Perceptual Quality Metric
Jun 11, 2020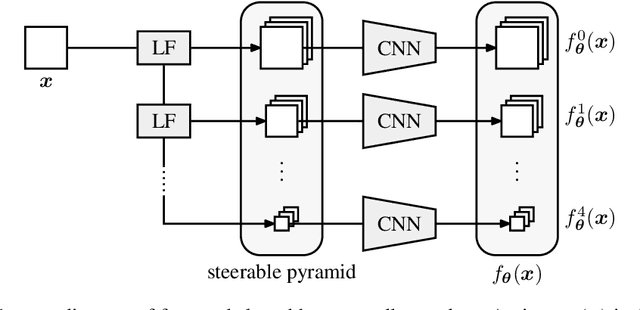
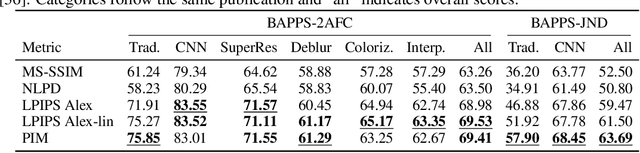
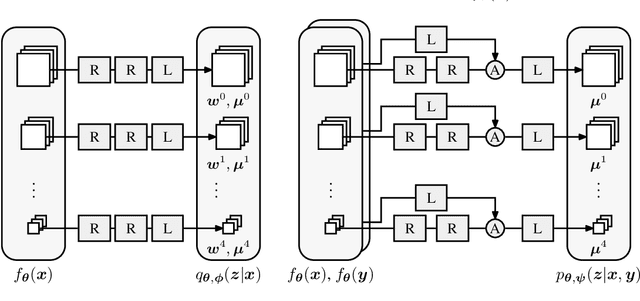
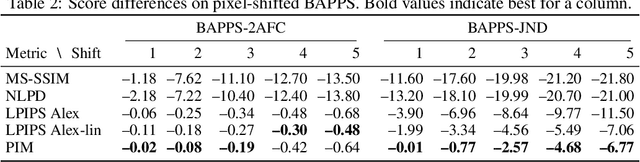
Tractable models of human perception have proved to be challenging to build. Hand-designed models such as MS-SSIM remain popular predictors of human image quality judgements due to their simplicity and speed. Recent modern deep learning approaches can perform better, but they rely on supervised data which can be costly to gather: large sets of class labels such as ImageNet, image quality ratings, or both. We combine recent advances in information-theoretic objective functions with a computational architecture informed by the physiology of the human visual system and unsupervised training on pairs of video frames, yielding our Perceptual Information Metric (PIM). We show that PIM is competitive with supervised metrics on the recent and challenging BAPPS image quality assessment dataset. We also perform qualitative experiments using the ImageNet-C dataset, and establish that our approach is robust with respect to architectural details.
Two heads are better than one: Enhancing medical representations by pre-training over structured and unstructured electronic health records
Jan 25, 2022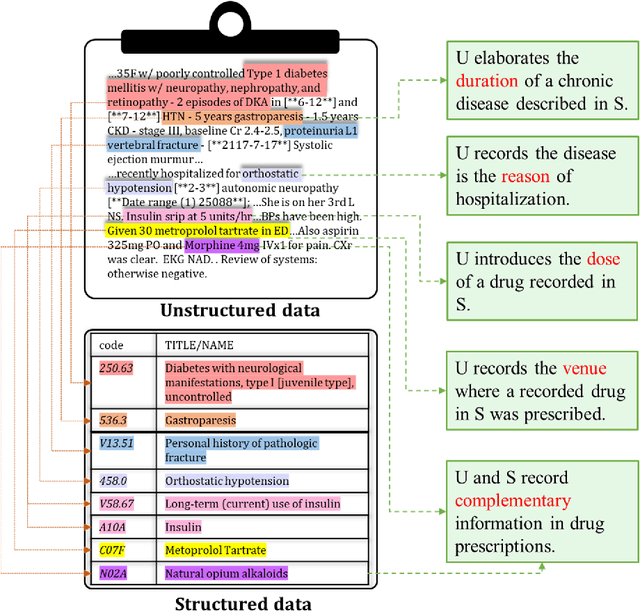
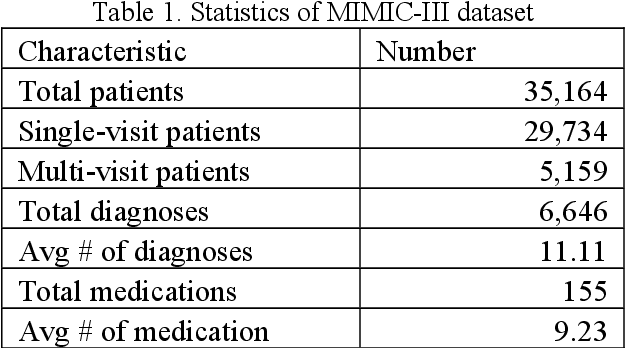
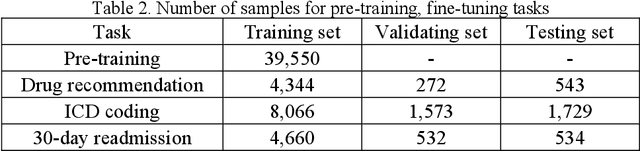
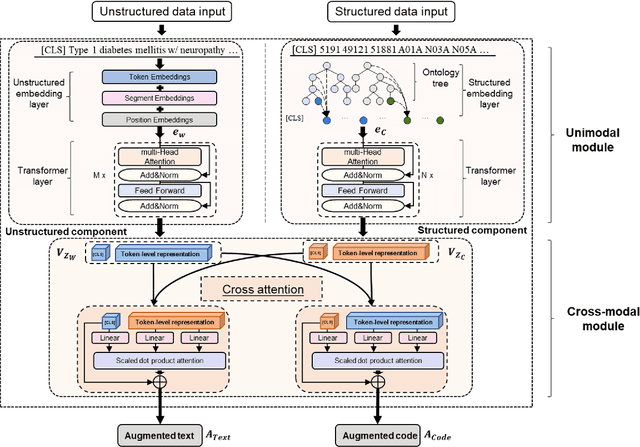
The massive context of electronic health records (EHRs) has created enormous potentials for improving healthcare, among which structured (coded) data and unstructured (text) data are two important textual modalities. They do not exist in isolation and can complement each other in most real-life clinical scenarios. Most existing researches in medical informatics, however, either only focus on a particular modality or straightforwardly concatenate the information from different modalities, which ignore the interaction and information sharing between them. To address these issues, we proposed a unified deep learning-based medical pre-trained language model, named UMM-PLM, to automatically learn representative features from multimodal EHRs that consist of both structured data and unstructured data. Specifically, we first developed parallel unimodal information representation modules to capture the unimodal-specific characteristic, where unimodal representations were learned from each data source separately. A cross-modal module was further introduced to model the interactions between different modalities. We pre-trained the model on a large EHRs dataset containing both structured data and unstructured data and verified the effectiveness of the model on three downstream clinical tasks, i.e., medication recommendation, 30-day readmission and ICD coding through extensive experiments. The results demonstrate the power of UMM-PLM compared with benchmark methods and state-of-the-art baselines. Analyses show that UMM-PLM can effectively concern with multimodal textual information and has the potential to provide more comprehensive interpretations for clinical decision making.
Unsupervised Anomaly Detection in 3D Brain MRI using Deep Learning with Multi-Task Brain Age Prediction
Jan 31, 2022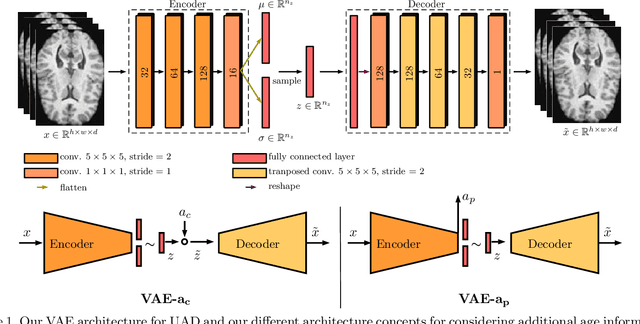

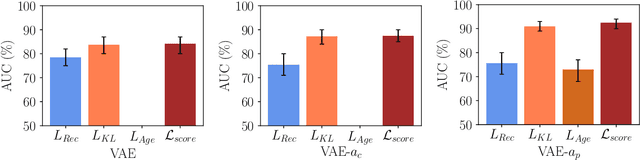
Lesion detection in brain Magnetic Resonance Images (MRIs) remains a challenging task. MRIs are typically read and interpreted by domain experts, which is a tedious and time-consuming process. Recently, unsupervised anomaly detection (UAD) in brain MRI with deep learning has shown promising results to provide a quick, initial assessment. So far, these methods only rely on the visual appearance of healthy brain anatomy for anomaly detection. Another biomarker for abnormal brain development is the deviation between the brain age and the chronological age, which is unexplored in combination with UAD. We propose deep learning for UAD in 3D brain MRI considering additional age information. We analyze the value of age information during training, as an additional anomaly score, and systematically study several architecture concepts. Based on our analysis, we propose a novel deep learning approach for UAD with multi-task age prediction. We use clinical T1-weighted MRIs of 1735 healthy subjects and the publicly available BraTs 2019 data set for our study. Our novel approach significantly improves UAD performance with an AUC of 92.60% compared to an AUC-score of 84.37% using previous approaches without age information.
No-Reference Quality Assessment for 360-degree Images by Analysis of Multi-frequency Information and Local-global Naturalness
Feb 22, 2021
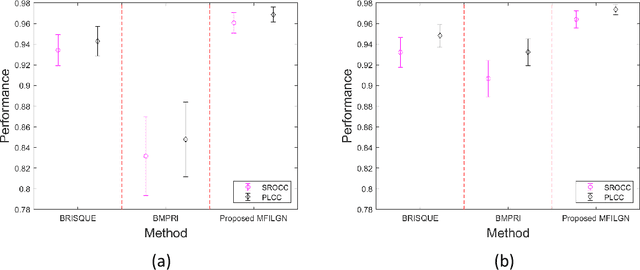
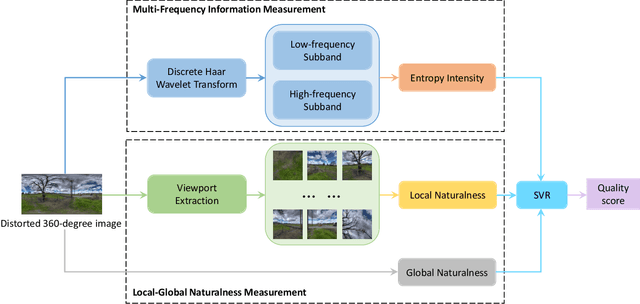

360-degree/omnidirectional images (OIs) have achieved remarkable attentions due to the increasing applications of virtual reality (VR). Compared to conventional 2D images, OIs can provide more immersive experience to consumers, benefitting from the higher resolution and plentiful field of views (FoVs). Moreover, observing OIs is usually in the head mounted display (HMD) without references. Therefore, an efficient blind quality assessment method, which is specifically designed for 360-degree images, is urgently desired. In this paper, motivated by the characteristics of the human visual system (HVS) and the viewing process of VR visual contents, we propose a novel and effective no-reference omnidirectional image quality assessment (NR OIQA) algorithm by Multi-Frequency Information and Local-Global Naturalness (MFILGN). Specifically, inspired by the frequency-dependent property of visual cortex, we first decompose the projected equirectangular projection (ERP) maps into wavelet subbands. Then, the entropy intensities of low and high frequency subbands are exploited to measure the multi-frequency information of OIs. Besides, except for considering the global naturalness of ERP maps, owing to the browsed FoVs, we extract the natural scene statistics features from each viewport image as the measure of local naturalness. With the proposed multi-frequency information measurement and local-global naturalness measurement, we utilize support vector regression as the final image quality regressor to train the quality evaluation model from visual quality-related features to human ratings. To our knowledge, the proposed model is the first no-reference quality assessment method for 360-degreee images that combines multi-frequency information and image naturalness. Experimental results on two publicly available OIQA databases demonstrate that our proposed MFILGN outperforms state-of-the-art approaches.