 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contextualize Me -- The Case for Context in Reinforcement Learning
Feb 09, 2022
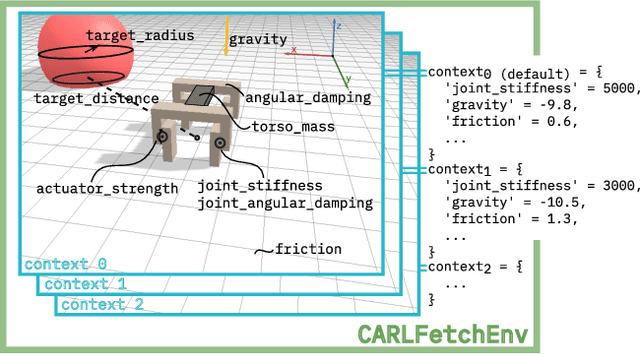
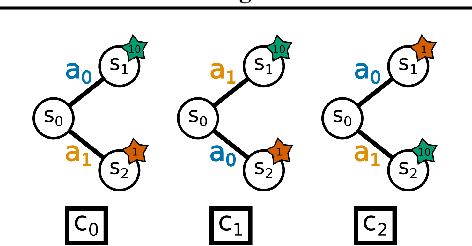
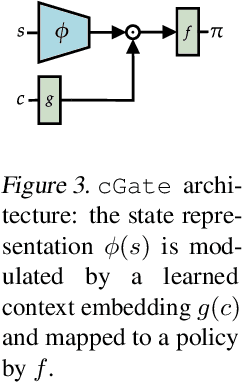
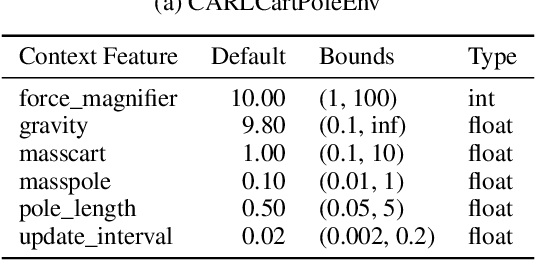
While Reinforcement Learning (RL) has made great strides towards solving increasingly complicated problems, many algorithms are still brittle to even slight changes in environments. Contextual Reinforcement Learning (cRL) provides a theoretical framework to model such changes in a principled manner, thereby enabling flexible, precise and interpretable task specification and generation. Thus, cRL is an important formalization for studying generalization in RL. In this work, we reason about solving cRL in theory and practice. We show that theoretically optimal behavior in contextual Markov Decision Processes requires explicit context information. In addition, we empirically explore context-based task generation, utilizing context information in training and propose cGate, our state-modulating policy architecture. To this end, we introduce the first benchmark library designed for generalization based on cRL extensions of popular benchmarks, CARL. In short: Context matters!
OWL (Observe, Watch, Listen): Localizing Actions in Egocentric Video via Audiovisual Temporal Context
Feb 14, 2022
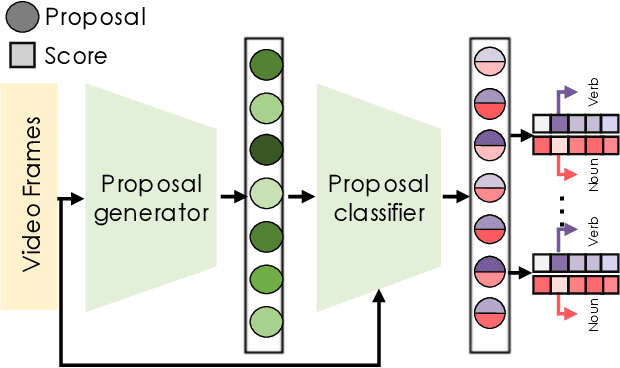

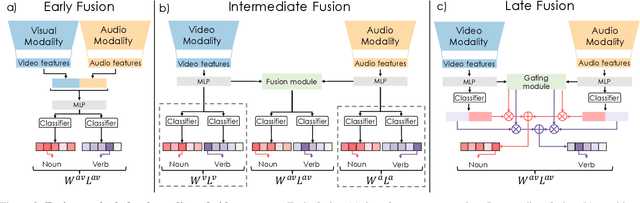
Temporal action localization (TAL) is an important task extensively explored and improved for third-person videos in recent years. Recent efforts have been made to perform fine-grained temporal localization on first-person videos. However, current TAL methods only use visual signals, neglecting the audio modality that exists in most videos and that shows meaningful action information in egocentric videos. In this work, we take a deep look into the effectiveness of audio in detecting actions in egocentric videos and introduce a simple-yet-effective approach via Observing, Watching, and Listening (OWL) to leverage audio-visual information and context for egocentric TAL. For doing that, we: 1) compare and study different strategies for where and how to fuse the two modalities; 2) propose a transformer-based model to incorporate temporal audio-visual context. Our experiments show that our approach achieves state-of-the-art performance on EPIC-KITCHENS-100.
Cluster-based ensemble learning for wind power modeling with meteorological wind data
Apr 01, 2022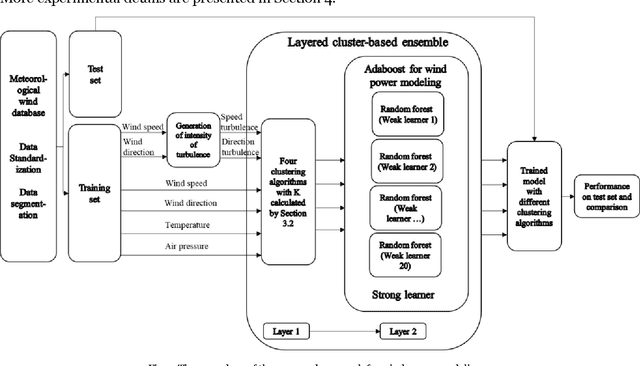
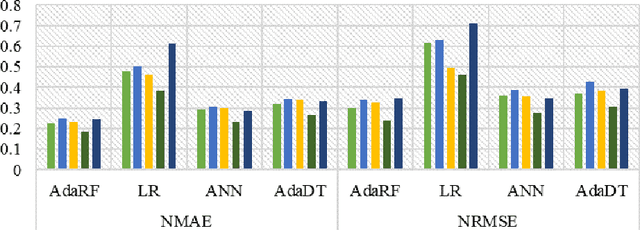
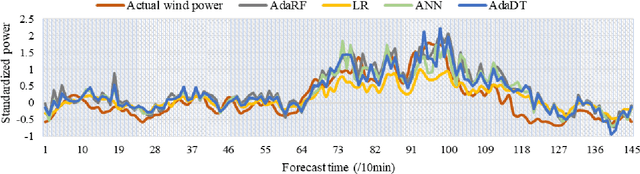
Optimal implementation and monitoring of wind energy generation hinge on reliable power modeling that is vital for understanding turbine control, farm operational optimization, and grid load balance. Based on the idea of similar wind condition leads to similar wind power; this paper constructs a modeling scheme that orderly integrates three types of ensemble learning algorithms, bagging, boosting, and stacking, and clustering approaches to achieve optimal power modeling. It also investigates applications of different clustering algorithms and methodology for determining cluster numbers in wind power modeling. The results reveal that all ensemble models with clustering exploit the intrinsic information of wind data and thus outperform models without it by approximately 15% on average. The model with the best farthest first clustering is computationally rapid and performs exceptionally well with an improvement of around 30%. The modeling is further boosted by about 5% by introducing stacking that fuses ensembles with varying clusters. The proposed modeling framework thus demonstrates promise by delivering efficient and robust modeling performance.
Semantic Feature Extraction for Generalized Zero-shot Learning
Dec 29, 2021

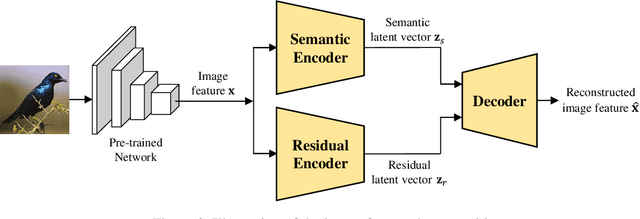
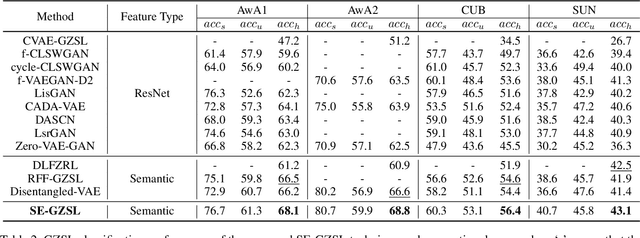
Generalized zero-shot learning (GZSL) is a technique to train a deep learning model to identify unseen classes using the attribute. In this paper, we put forth a new GZSL technique that improves the GZSL classification performance greatly. Key idea of the proposed approach, henceforth referred to as semantic feature extraction-based GZSL (SE-GZSL), is to use the semantic feature containing only attribute-related information in learning the relationship between the image and the attribute. In doing so, we can remove the interference, if any, caused by the attribute-irrelevant information contained in the image feature. To train a network extracting the semantic feature, we present two novel loss functions, 1) mutual information-based loss to capture all the attribute-related information in the image feature and 2) similarity-based loss to remove unwanted attribute-irrelevant information. From extensive experiments using various datasets, we show that the proposed SE-GZSL technique outperforms conventional GZSL approaches by a large margin.
DOM-LM: Learning Generalizable Representations for HTML Documents
Jan 25, 2022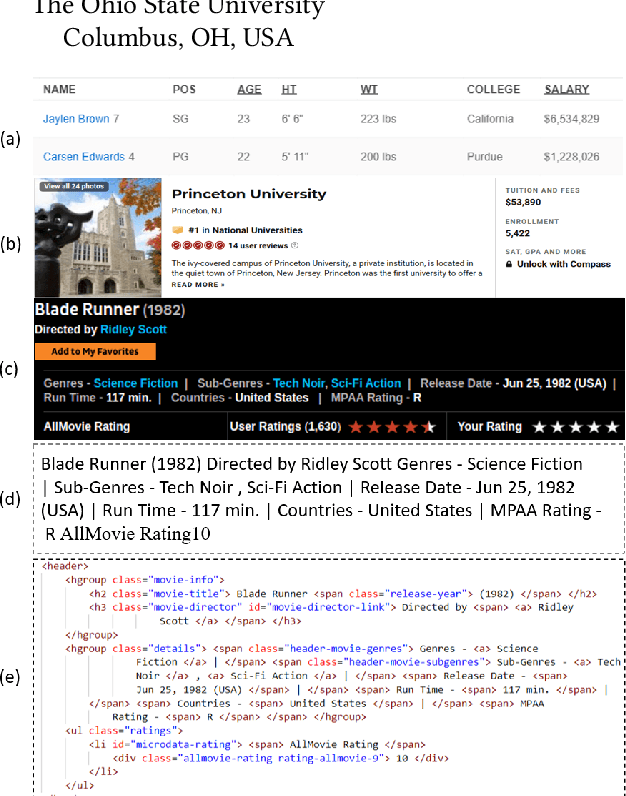

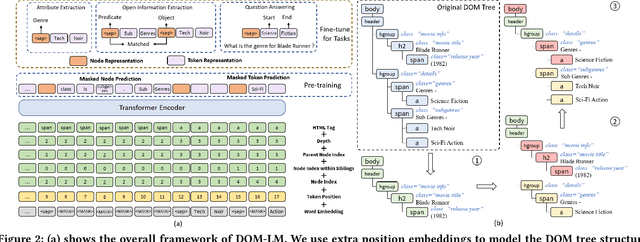
HTML documents are an important medium for disseminating information on the Web for human consumption. An HTML document presents information in multiple text formats including unstructured text, structured key-value pairs, and tables. Effective representation of these documents is essential for machine understanding to enable a wide range of applications, such as Question Answering, Web Search, and Personalization. Existing work has either represented these documents using visual features extracted by rendering them in a browser, which is typically computationally expensive, or has simply treated them as plain text documents, thereby failing to capture useful information presented in their HTML structure. We argue that the text and HTML structure together convey important semantics of the content and therefore warrant a special treatment for their representation learning. In this paper, we introduce a novel representation learning approach for web pages, dubbed DOM-LM, which addresses the limitations of existing approaches by encoding both text and DOM tree structure with a transformer-based encoder and learning generalizable representations for HTML documents via self-supervised pre-training. We evaluate DOM-LM on a variety of webpage understanding tasks, including Attribute Extraction, Open Information Extraction, and Question Answering. Our extensive experiments show that DOM-LM consistently outperforms all baselines designed for these tasks. In particular, DOM-LM demonstrates better generalization performance both in few-shot and zero-shot settings, making it attractive for making it suitable for real-world application settings with limited labeled data.
Building a 3-Player Mahjong AI using Deep Reinforcement Learning
Feb 25, 2022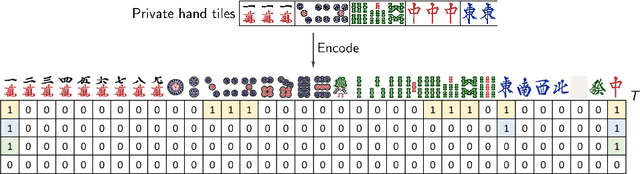
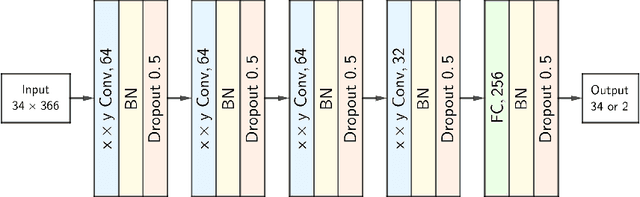
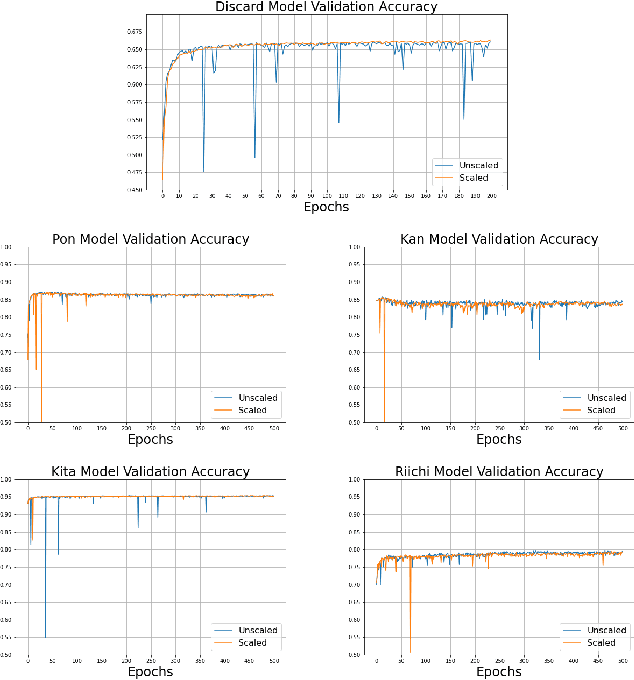
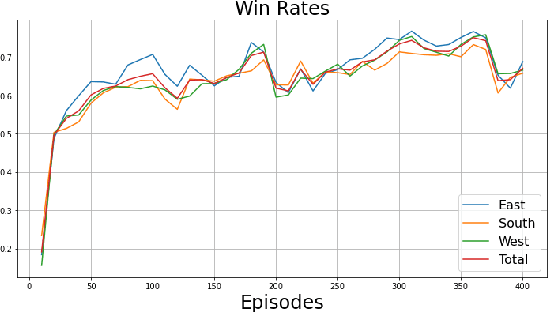
Mahjong is a popular multi-player imperfect-information game developed in China in the late 19th-century, with some very challenging features for AI research. Sanma, being a 3-player variant of the Japanese Riichi Mahjong, possesses unique characteristics including fewer tiles and, consequently, a more aggressive playing style. It is thus challenging and of great research interest in its own right, but has not yet been explored. In this paper, we present Meowjong, an AI for Sanma using deep reinforcement learning. We define an informative and compact 2-dimensional data structure for encoding the observable information in a Sanma game. We pre-train 5 convolutional neural networks (CNNs) for Sanma's 5 actions -- discard, Pon, Kan, Kita and Riichi, and enhance the major action's model, namely the discard model, via self-play reinforcement learning using the Monte Carlo policy gradient method. Meowjong's models achieve test accuracies comparable with AIs for 4-player Mahjong through supervised learning, and gain a significant further enhancement from reinforcement learning. Being the first ever AI in Sanma, we claim that Meowjong stands as a state-of-the-art in this game.
AccMPEG: Optimizing Video Encoding for Video Analytics
Apr 26, 2022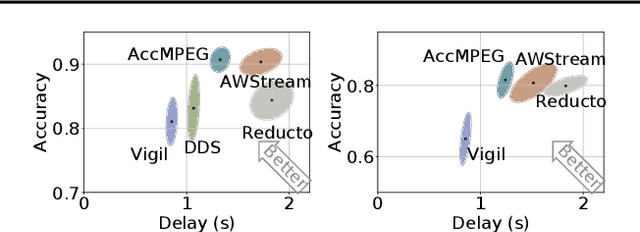
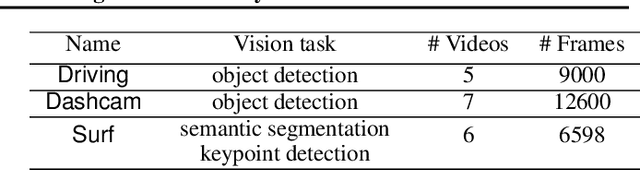
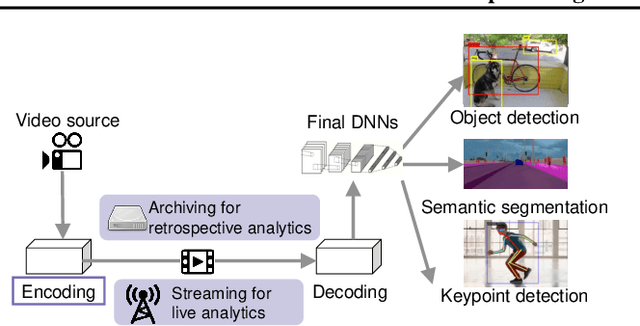

With more videos being recorded by edge sensors (cameras) and analyzed by computer-vision deep neural nets (DNNs), a new breed of video streaming systems has emerged, with the goal to compress and stream videos to remote servers in real time while preserving enough information to allow highly accurate inference by the server-side DNNs. An ideal design of the video streaming system should simultaneously meet three key requirements: (1) low latency of encoding and streaming, (2) high accuracy of server-side DNNs, and (3) low compute overheads on the camera. Unfortunately, despite many recent efforts, such video streaming system has hitherto been elusive, especially when serving advanced vision tasks such as object detection or semantic segmentation. This paper presents AccMPEG, a new video encoding and streaming system that meets all the three requirements. The key is to learn how much the encoding quality at each (16x16) macroblock can influence the server-side DNN accuracy, which we call accuracy gradient. Our insight is that these macroblock-level accuracy gradient can be inferred with sufficient precision by feeding the video frames through a cheap model. AccMPEG provides a suite of techniques that, given a new server-side DNN, can quickly create a cheap model to infer the accuracy gradient on any new frame in near realtime. Our extensive evaluation of AccMPEG on two types of edge devices (one Intel Xeon Silver 4100 CPU or NVIDIA Jetson Nano) and three vision tasks (six recent pre-trained DNNs) shows that AccMPEG (with the same camera-side compute resources) can reduce the end-to-end inference delay by 10-43% without hurting accuracy compared to the state-of-the-art baselines
Residual-guided Personalized Speech Synthesis based on Face Image
Apr 01, 2022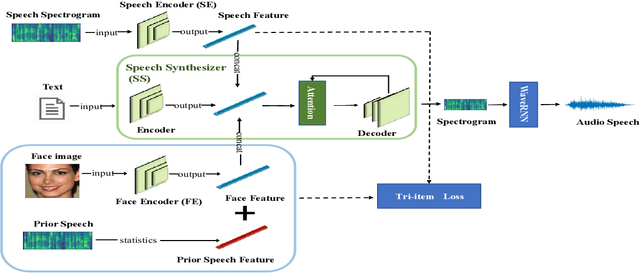
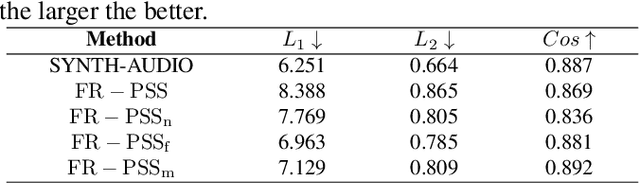
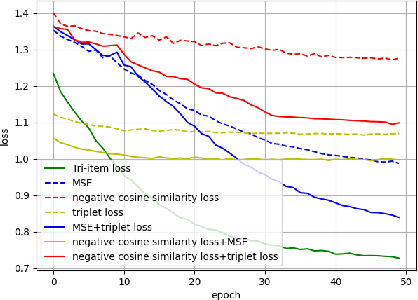

Previous works derive personalized speech features by training the model on a large dataset composed of his/her audio sounds. It was reported that face information has a strong link with the speech sound. Thus in this work, we innovatively extract personalized speech features from human faces to synthesize personalized speech using neural vocoder. A Face-based Residual Personalized Speech Synthesis Model (FR-PSS) containing a speech encoder, a speech synthesizer and a face encoder is designed for PSS. In this model, by designing two speech priors, a residual-guided strategy is introduced to guide the face feature to approach the true speech feature in the training. Moreover, considering the error of feature's absolute values and their directional bias, we formulate a novel tri-item loss function for face encoder. Experimental results show that the speech synthesized by our model is comparable to the personalized speech synthesized by training a large amount of audio data in previous works.
Understanding Graph Convolutional Networks for Text Classification
Mar 30, 2022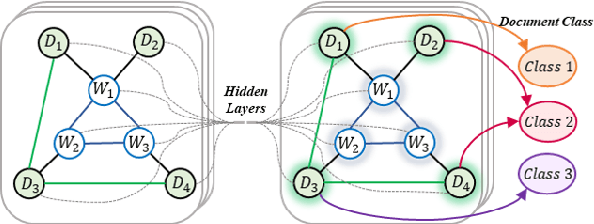
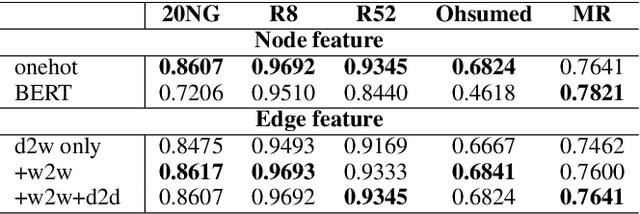
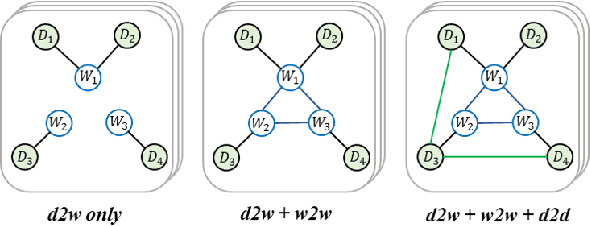
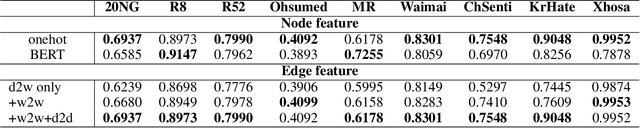
Graph Convolutional Networks (GCN) have been effective at tasks that have rich relational structure and can preserve global structure information of a dataset in graph embeddings. Recently, many researchers focused on examining whether GCNs could handle different Natural Language Processing tasks, especially text classification. While applying GCNs to text classification is well-studied, its graph construction techniques, such as node/edge selection and their feature representation, and the optimal GCN learning mechanism in text classification is rather neglected. In this paper, we conduct a comprehensive analysis of the role of node and edge embeddings in a graph and its GCN learning techniques in text classification. Our analysis is the first of its kind and provides useful insights into the importance of each graph node/edge construction mechanism when applied at the GCN training/testing in different text classification benchmarks, as well as under its semi-supervised environment.
Behaviorally Grounded Model-Based and Model Free Cost Reduction in a Simulated Multi-Echelon Supply Chain
Feb 25, 2022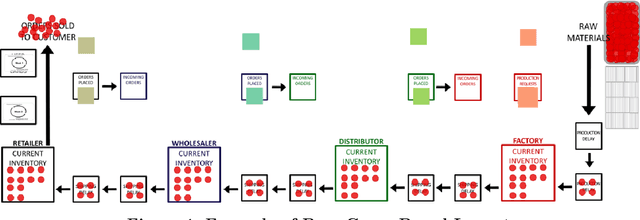
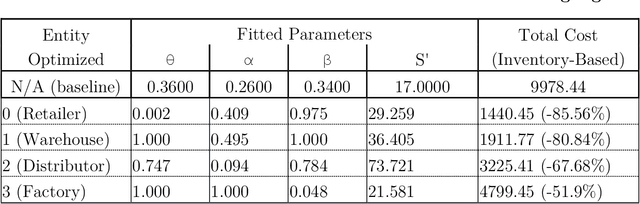
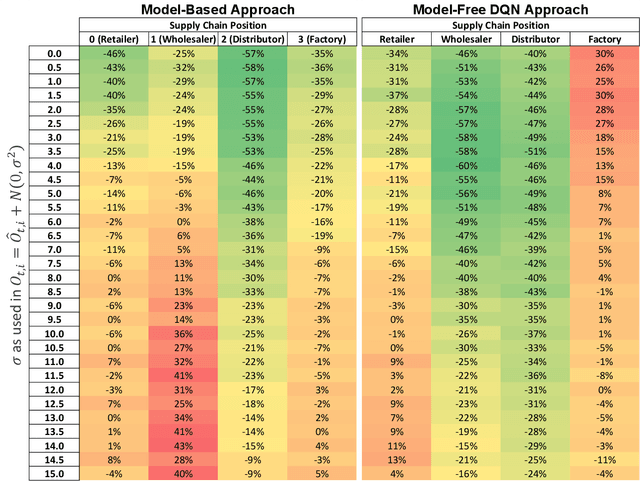
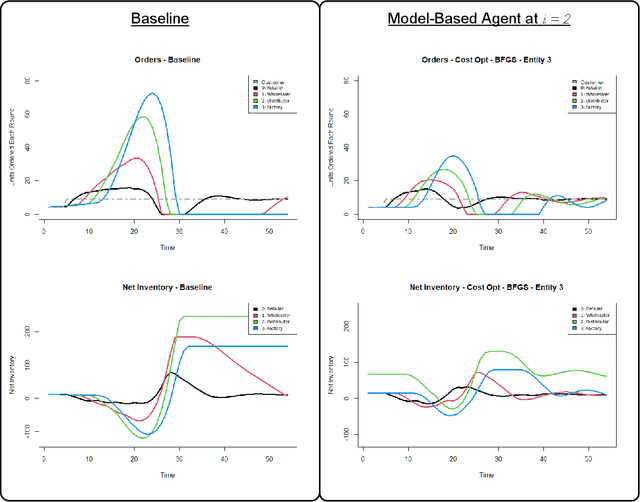
Amplification and phase shift in ordering signals, commonly referred to as bullwhip, are responsible for both excessive strain on real world inventory management systems, stock outs, and unnecessary capital reservation though safety stock building. Bullwhip is a classic, yet persisting, problem with reverberating consequences in inventory management. Research on bullwhip has consistently emphasized behavioral influences for this phenomenon and leveraged behavioral ordering models to suggest interventions. However more recent model-free approaches have also seen success. In this work, the author develops algorithmic approaches towards mitigating bullwhip using both behaviorally grounded model-based approaches alongside a model-free dual deep Q-network reinforcement learning approach. In addition to exploring the utility of this specific model-free architecture to multi-echelon supply chains with imperfect information sharing and information delays, the author directly compares the performance of these model-based and model-free approaches. In doing so, this work highlights both the insights gained from exploring model-based approaches in the context of prior behavioral operations management literature and emphasizes the complementary nature of model-based and model-free approaches in approaching behaviorally grounded supply chain management problems.