 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evolutionary Diversity Optimisation for The Traveling Thief Problem
Apr 06, 2022
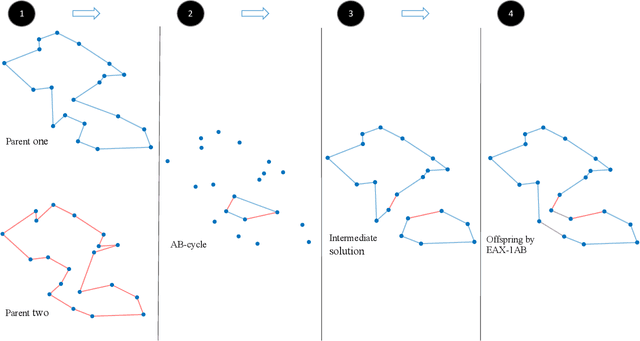

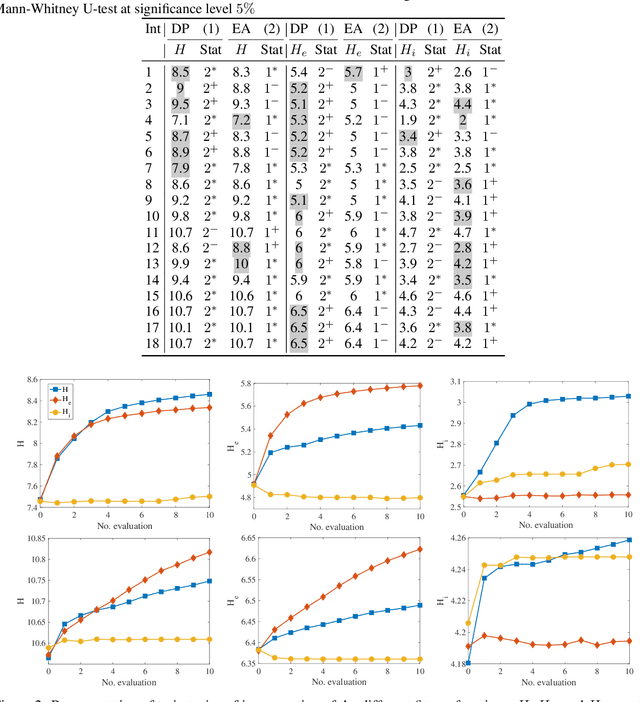
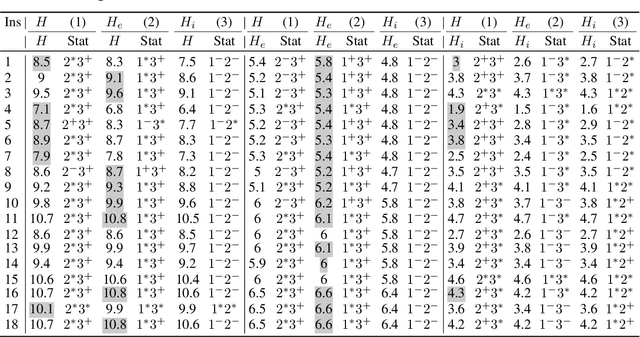
There has been a growing interest in the evolutionary computation community to compute a diverse set of high-quality solutions for a given optimisation problem. This can provide the practitioners with invaluable information about the solution space and robustness against imperfect modelling and minor problems' changes. It also enables the decision-makers to involve their interests and choose between various solutions. In this study, we investigate for the first time a prominent multi-component optimisation problem, namely the Traveling Thief Problem (TTP), in the context of evolutionary diversity optimisation. We introduce a bi-level evolutionary algorithm to maximise the structural diversity of the set of solutions. Moreover, we examine the inter-dependency among the components of the problem in terms of structural diversity and empirically determine the best method to obtain diversity. We also conduct a comprehensive experimental investigation to examine the introduced algorithm and compare the results to another recently introduced framework based on the use of Quality Diversity (QD). Our experimental results show a significant improvement of the QD approach in terms of structural diversity for most TTP benchmark instances.
X-Trans2Cap: Cross-Modal Knowledge Transfer using Transformer for 3D Dense Captioning
Mar 02, 2022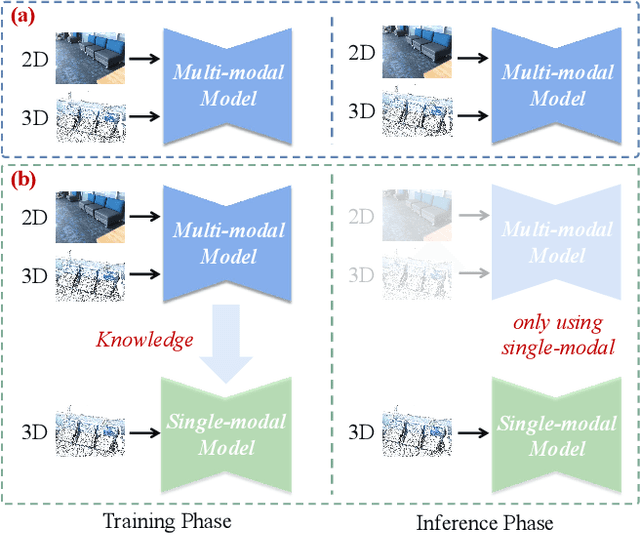
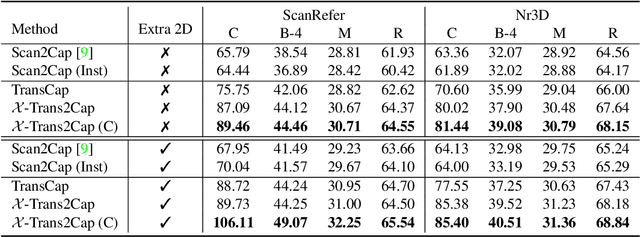
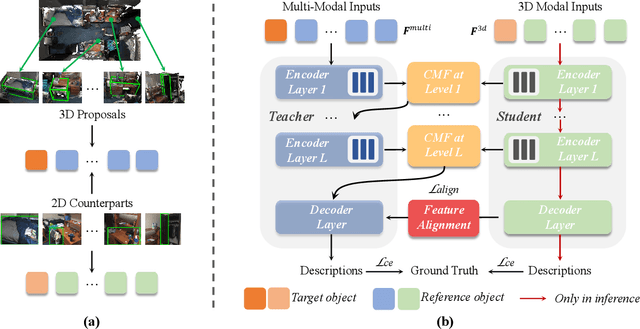

3D dense captioning aims to describe individual objects by natural language in 3D scenes, where 3D scenes are usually represented as RGB-D scans or point clouds. However, only exploiting single modal information, e.g., point cloud, previous approaches fail to produce faithful descriptions. Though aggregating 2D features into point clouds may be beneficial, it introduces an extra computational burden, especially in inference phases. In this study, we investigate a cross-modal knowledge transfer using Transformer for 3D dense captioning, X-Trans2Cap, to effectively boost the performance of single-modal 3D caption through knowledge distillation using a teacher-student framework. In practice, during the training phase, the teacher network exploits auxiliary 2D modality and guides the student network that only takes point clouds as input through the feature consistency constraints. Owing to the well-designed cross-modal feature fusion module and the feature alignment in the training phase, X-Trans2Cap acquires rich appearance information embedded in 2D images with ease. Thus, a more faithful caption can be generated only using point clouds during the inference. Qualitative and quantitative results confirm that X-Trans2Cap outperforms previous state-of-the-art by a large margin, i.e., about +21 and about +16 absolute CIDEr score on ScanRefer and Nr3D datasets, respectively.
OmniFusion: 360 Monocular Depth Estimation via Geometry-Aware Fusion
Mar 02, 2022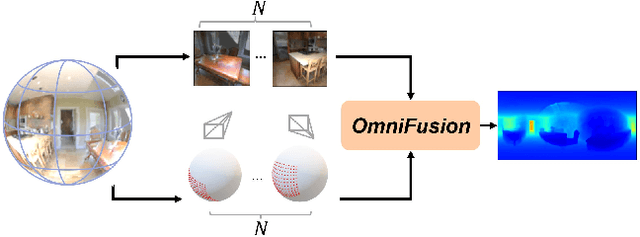
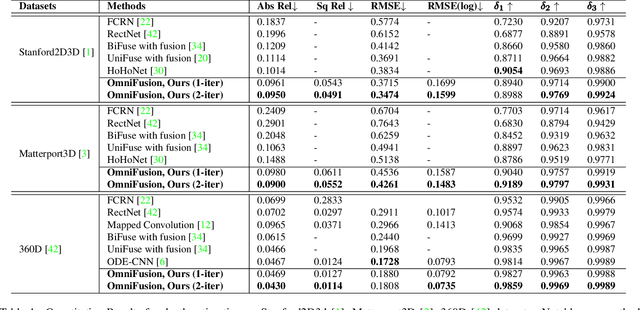
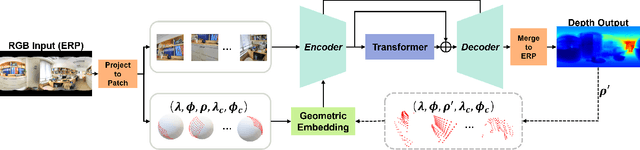

A well-known challenge in applying deep-learning methods to omnidirectional images is spherical distortion. In dense regression tasks such as depth estimation, where structural details are required, using a vanilla CNN layer on the distorted 360 image results in undesired information loss. In this paper, we propose a 360 monocular depth estimation pipeline, \textit{OmniFusion}, to tackle the spherical distortion issue. Our pipeline transforms a 360 image into less-distorted perspective patches (i.e. tangent images) to obtain patch-wise predictions via CNN, and then merge the patch-wise results for final output. To handle the discrepancy between patch-wise predictions which is a major issue affecting the merging quality, we propose a new framework with the following key components. First, we propose a geometry-aware feature fusion mechanism that combines 3D geometric features with 2D image features to compensate for the patch-wise discrepancy. Second, we employ the self-attention-based transformer architecture to conduct a global aggregation of patch-wise information, which further improves the consistency. Last, we introduce an iterative depth refinement mechanism, to further refine the estimated depth based on the more accurate geometric features. Experiments show that our method greatly mitigates the distortion issue, and achieves state-of-the-art performances on several 360 monocular depth estimation benchmark datasets.
Unseen Object Instance Segmentation with Fully Test-time RGB-D Embeddings Adaptation
Apr 21, 2022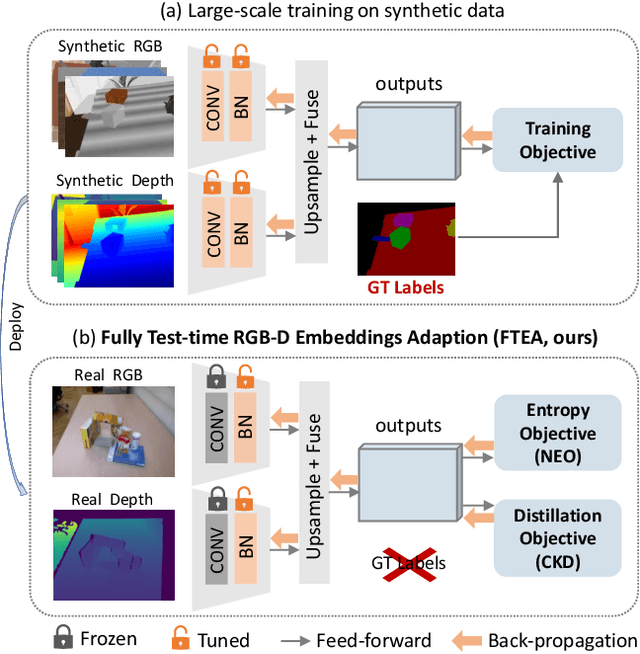
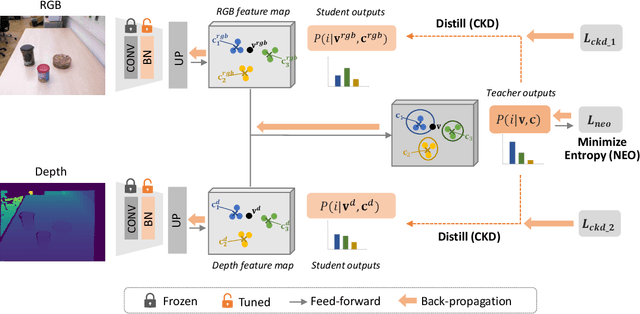
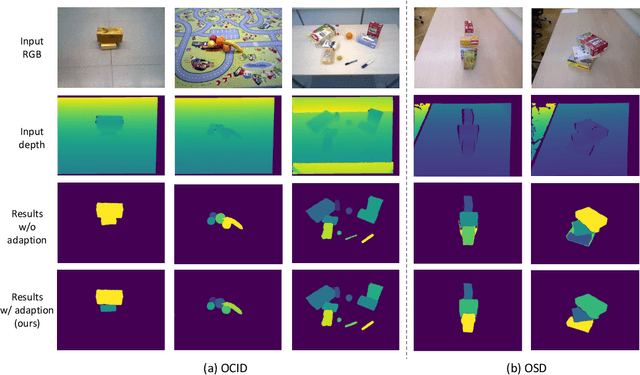
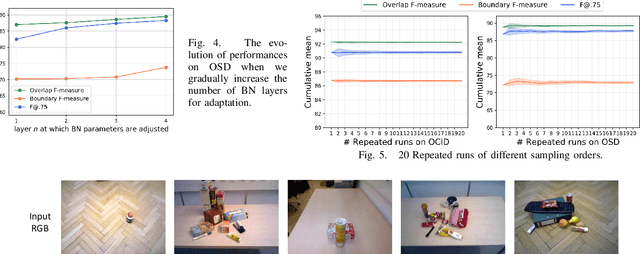
Segmenting unseen objects is a crucial ability for the robot since it may encounter new environments during the operation. Recently, a popular solution is leveraging RGB-D features of large-scale synthetic data and directly applying the model to unseen real-world scenarios. However, even though depth data have fair generalization ability, the domain shift due to the Sim2Real gap is inevitable, which presents a key challenge to the unseen object instance segmentation (UOIS) model. To tackle this problem, we re-emphasize the adaptation process across Sim2Real domains in this paper. Specifically, we propose a framework to conduct the Fully Test-time RGB-D Embeddings Adaptation (FTEA) based on parameters of the BatchNorm layer. To construct the learning objective for test-time back-propagation, we propose a novel non-parametric entropy objective that can be implemented without explicit classification layers. Moreover, we design a cross-modality knowledge distillation module to encourage the information transfer during test time. The proposed method can be efficiently conducted with test-time images, without requiring annotations or revisiting the large-scale synthetic training data. Besides significant time savings, the proposed method consistently improves segmentation results on both overlap and boundary metrics, achieving state-of-the-art performances on two real-world RGB-D image datasets. We hope our work could draw attention to the test-time adaptation and reveal a promising direction for robot perception in unseen environments.
An Unsupervised Information-Theoretic Perceptual Quality Metric
Jun 11, 2020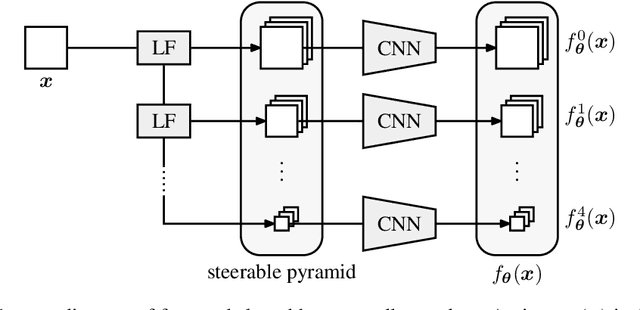
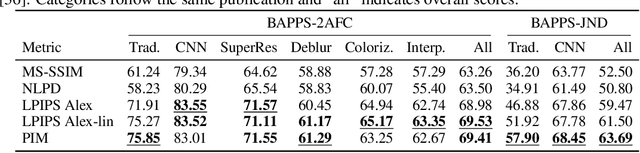
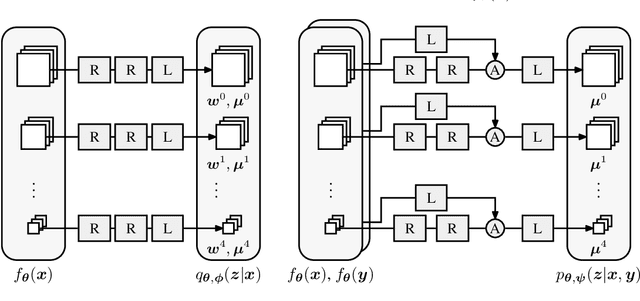
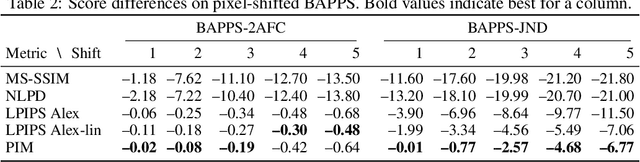
Tractable models of human perception have proved to be challenging to build. Hand-designed models such as MS-SSIM remain popular predictors of human image quality judgements due to their simplicity and speed. Recent modern deep learning approaches can perform better, but they rely on supervised data which can be costly to gather: large sets of class labels such as ImageNet, image quality ratings, or both. We combine recent advances in information-theoretic objective functions with a computational architecture informed by the physiology of the human visual system and unsupervised training on pairs of video frames, yielding our Perceptual Information Metric (PIM). We show that PIM is competitive with supervised metrics on the recent and challenging BAPPS image quality assessment dataset. We also perform qualitative experiments using the ImageNet-C dataset, and establish that our approach is robust with respect to architectural details.
Large-scale Stochastic Optimization of NDCG Surrogates for Deep Learning with Provable Convergence
Apr 06, 2022

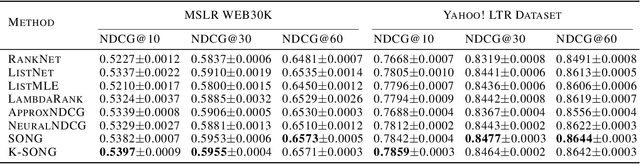

NDCG, namely Normalized Discounted Cumulative Gain, is a widely used ranking metric in information retrieval and machine learning. However, efficient and provable stochastic methods for maximizing NDCG are still lacking, especially for deep models. In this paper, we propose a principled approach to optimize NDCG and its top-$K$ variant. First, we formulate a novel compositional optimization problem for optimizing the NDCG surrogate, and a novel bilevel compositional optimization problem for optimizing the top-$K$ NDCG surrogate. Then, we develop efficient stochastic algorithms with provable convergence guarantees for the non-convex objectives. Different from existing NDCG optimization methods, the per-iteration complexity of our algorithms scales with the mini-batch size instead of the number of total items. To improve the effectiveness for deep learning, we further propose practical strategies by using initial warm-up and stop gradient operator. Experimental results on multiple datasets demonstrate that our methods outperform prior ranking approaches in terms of NDCG. To the best of our knowledge, this is the first time that stochastic algorithms are proposed to optimize NDCG with a provable convergence guarantee.
Conditional Measurement Density Estimation in Sequential Monte Carlo via Normalizing Flow
Mar 16, 2022
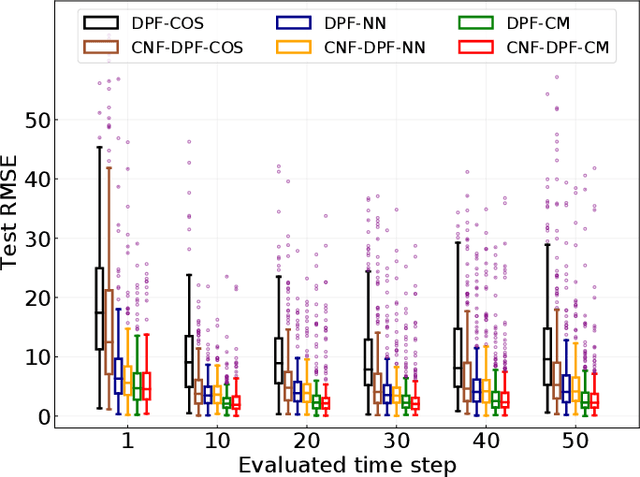
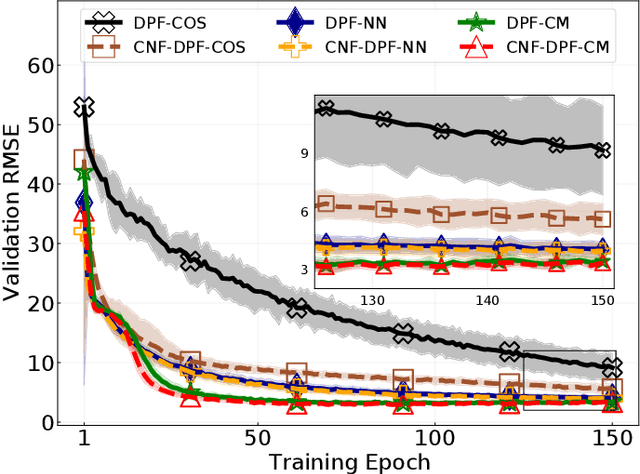
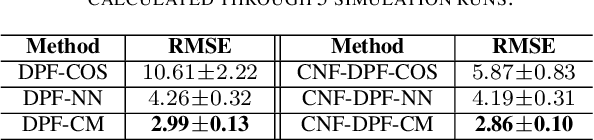
Tuning of measurement models is challenging in real-world applications of sequential Monte Carlo methods. Recent advances in differentiable particle filters have led to various efforts to learn measurement models through neural networks. But existing approaches in the differentiable particle filter framework do not admit valid probability densities in constructing measurement models, leading to incorrect quantification of the measurement uncertainty given state information. We propose to learn expressive and valid probability densities in measurement models through conditional normalizing flows, to capture the complex likelihood of measurements given states. We show that the proposed approach leads to improved estimation performance and faster training convergence in a visual tracking experiment.
Facial Expression Recognition with Swin Transformer
Mar 25, 2022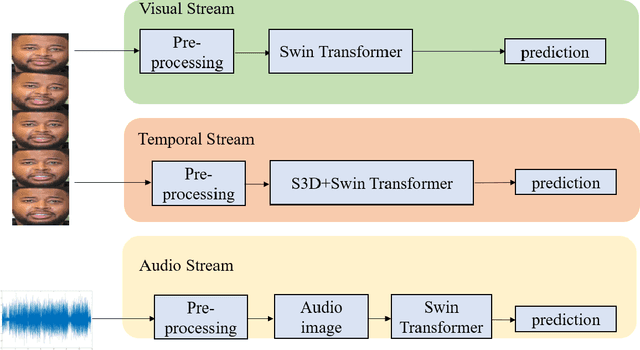
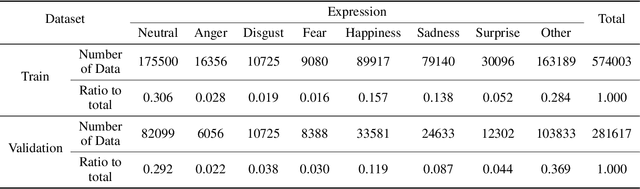

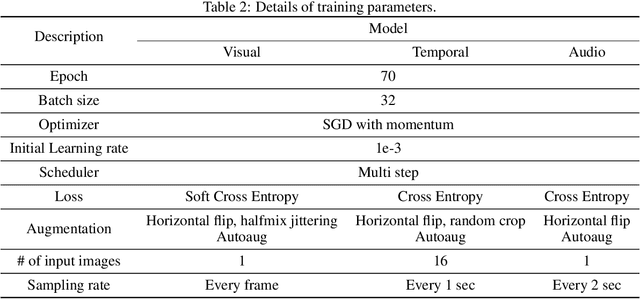
The task of recognizing human facial expressions plays a vital role in various human-related systems, including health care and medical fields. With the recent success of deep learning and the accessibility of a large amount of annotated data, facial expression recognition research has been mature enough to be utilized in real-world scenarios with audio-visual datasets. In this paper, we introduce Swin transformer-based facial expression approach for an in-the-wild audio-visual dataset of the Aff-Wild2 Expression dataset. Specifically, we employ a three-stream network (i.e., Visual stream, Temporal stream, and Audio stream) for the audio-visual videos to fuse the multi-modal information into facial expression recognition. Experimental results on the Aff-Wild2 dataset show the effectiveness of our proposed multi-modal approaches.
Cluster-based ensemble learning for wind power modeling with meteorological wind data
Apr 01, 2022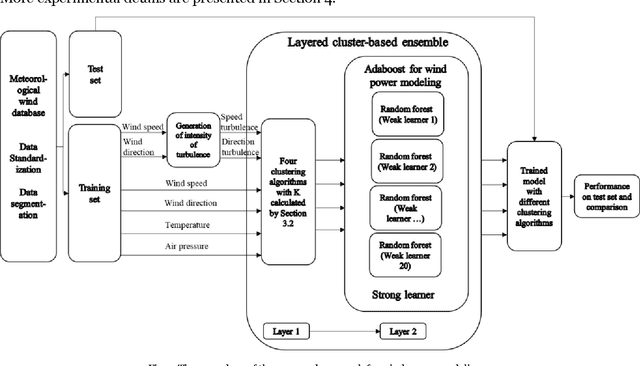
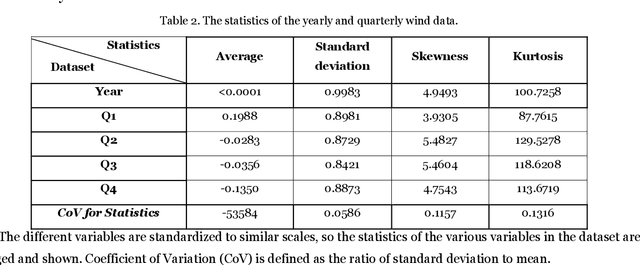
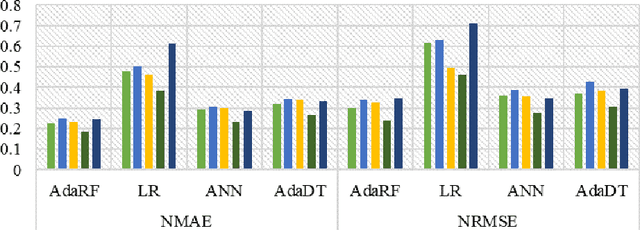
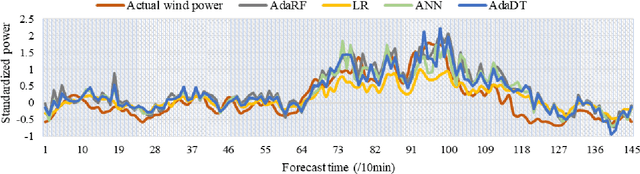
Optimal implementation and monitoring of wind energy generation hinge on reliable power modeling that is vital for understanding turbine control, farm operational optimization, and grid load balance. Based on the idea of similar wind condition leads to similar wind power; this paper constructs a modeling scheme that orderly integrates three types of ensemble learning algorithms, bagging, boosting, and stacking, and clustering approaches to achieve optimal power modeling. It also investigates applications of different clustering algorithms and methodology for determining cluster numbers in wind power modeling. The results reveal that all ensemble models with clustering exploit the intrinsic information of wind data and thus outperform models without it by approximately 15% on average. The model with the best farthest first clustering is computationally rapid and performs exceptionally well with an improvement of around 30%. The modeling is further boosted by about 5% by introducing stacking that fuses ensembles with varying clusters. The proposed modeling framework thus demonstrates promise by delivering efficient and robust modeling performance.
AccMPEG: Optimizing Video Encoding for Video Analytics
Apr 26, 2022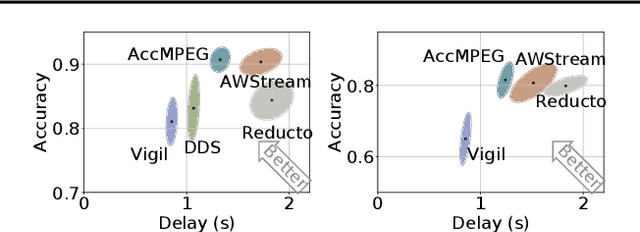
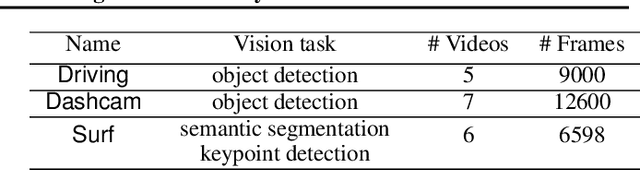
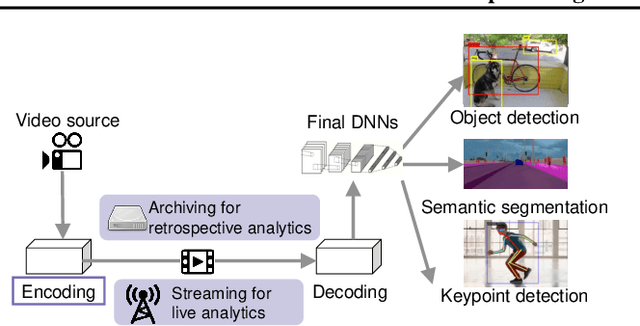

With more videos being recorded by edge sensors (cameras) and analyzed by computer-vision deep neural nets (DNNs), a new breed of video streaming systems has emerged, with the goal to compress and stream videos to remote servers in real time while preserving enough information to allow highly accurate inference by the server-side DNNs. An ideal design of the video streaming system should simultaneously meet three key requirements: (1) low latency of encoding and streaming, (2) high accuracy of server-side DNNs, and (3) low compute overheads on the camera. Unfortunately, despite many recent efforts, such video streaming system has hitherto been elusive, especially when serving advanced vision tasks such as object detection or semantic segmentation. This paper presents AccMPEG, a new video encoding and streaming system that meets all the three requirements. The key is to learn how much the encoding quality at each (16x16) macroblock can influence the server-side DNN accuracy, which we call accuracy gradient. Our insight is that these macroblock-level accuracy gradient can be inferred with sufficient precision by feeding the video frames through a cheap model. AccMPEG provides a suite of techniques that, given a new server-side DNN, can quickly create a cheap model to infer the accuracy gradient on any new frame in near realtime. Our extensive evaluation of AccMPEG on two types of edge devices (one Intel Xeon Silver 4100 CPU or NVIDIA Jetson Nano) and three vision tasks (six recent pre-trained DNNs) shows that AccMPEG (with the same camera-side compute resources) can reduce the end-to-end inference delay by 10-43% without hurting accuracy compared to the state-of-the-art baselines