 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mixture Components Inference for Sparse Regression: Introduction and Application for Estimation of Neuronal Signal from fMRI BOLD
Mar 14, 2022
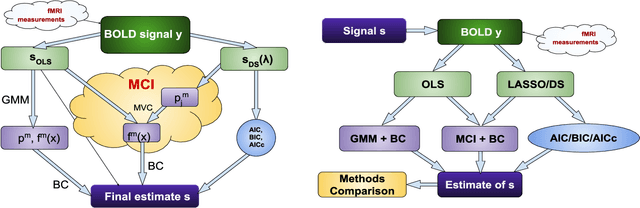
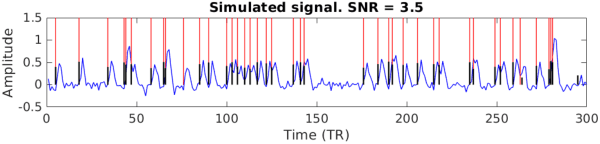
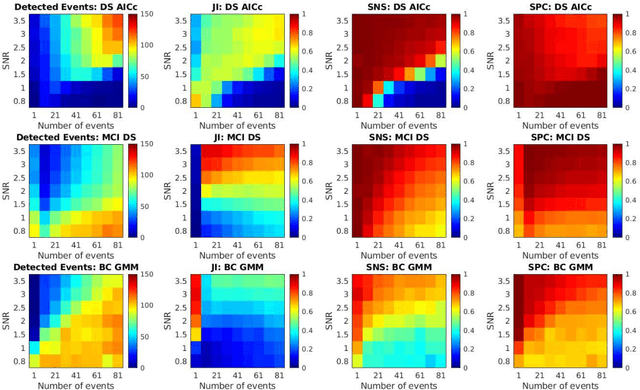
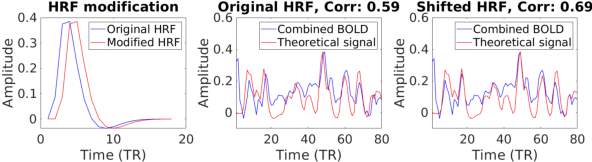
Sparse linear regression methods including the well-known LASSO and the Dantzig selector have become ubiquitous in the engineering practice, including in medical imaging. Among other tasks, they have been successfully applied for the estimation of neuronal activity from functional magnetic resonance data without prior knowledge of the stimulus or activation timing, utilizing an approximate knowledge of the hemodynamic response to local neuronal activity. These methods work by generating a parametric family of solutions with different sparsity, among which an ultimate choice is made using an information criteria. We propose a novel approach, that instead of selecting a single option from the family of regularized solutions, utilizes the whole family of such sparse regression solutions. Namely, their ensemble provides a first approximation of probability of activation at each time-point, and together with the conditional neuronal activity distributions estimated with the theory of mixtures with varying concentrations, they serve as the inputs to a Bayes classifier eventually deciding on the verity of activation at each time-point. We show in extensive numerical simulations that this new method performs favourably in comparison with standard approaches in a range of realistic scenarios. This is mainly due to the avoidance of overfitting and underfitting that commonly plague the solutions based on sparse regression combined with model selection methods, including the corrected Akaike Information Criterion. This advantage is finally documented in selected fMRI task datasets.
RAPQ: Rescuing Accuracy for Power-of-Two Low-bit Post-training Quantization
Apr 26, 2022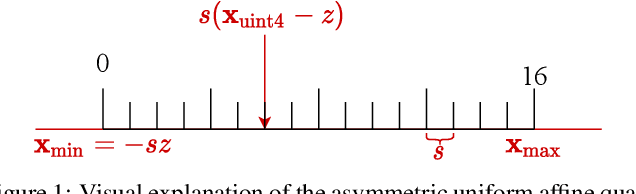
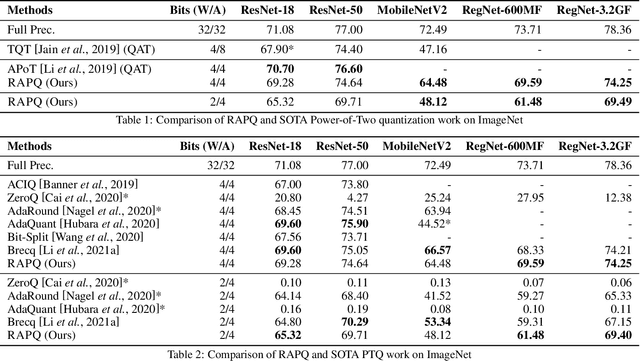

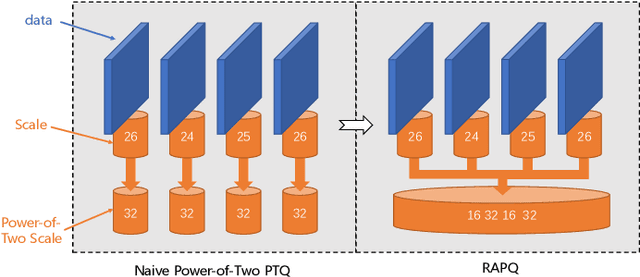
We introduce a Power-of-Two post-training quantization( PTQ) method for deep neural network that meets hardware requirements and does not call for long-time retraining. PTQ requires a small set of calibration data and is easier for deployment, but results in lower accuracy than Quantization-Aware Training( QAT). Power-of-Two quantization can convert the multiplication introduced by quantization and dequantization to bit-shift that is adopted by many efficient accelerators. However, the Power-of-Two scale has fewer candidate values, which leads to more rounding or clipping errors. We propose a novel Power-of-Two PTQ framework, dubbed RAPQ, which dynamically adjusts the Power-of-Two scales of the whole network instead of statically determining them layer by layer. It can theoretically trade off the rounding error and clipping error of the whole network. Meanwhile, the reconstruction method in RAPQ is based on the BN information of every unit. Extensive experiments on ImageNet prove the excellent performance of our proposed method. Without bells and whistles, RAPQ can reach accuracy of 65% and 48% on ResNet-18 and MobileNetV2 respectively with weight INT2 activation INT4. We are the first to propose PTQ for the more constrained but hardware-friendly Power-of-Two quantization and prove that it can achieve nearly the same accuracy as SOTA PTQ method. The code will be released.
Remote State Estimation of Multiple Systems over Semi-Markov Wireless Fading Channels
Mar 31, 2022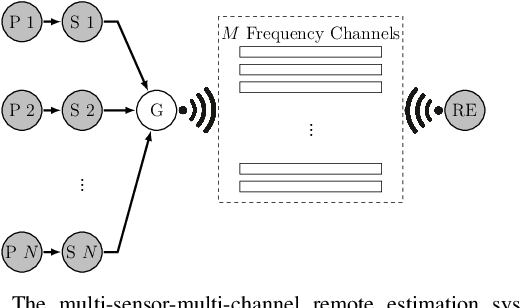
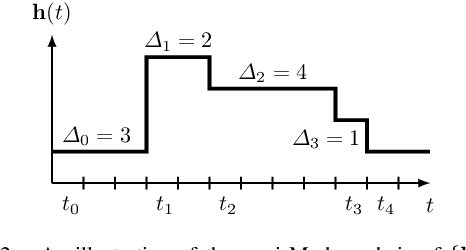
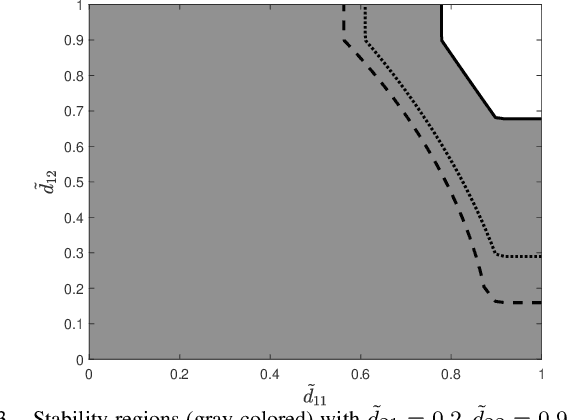
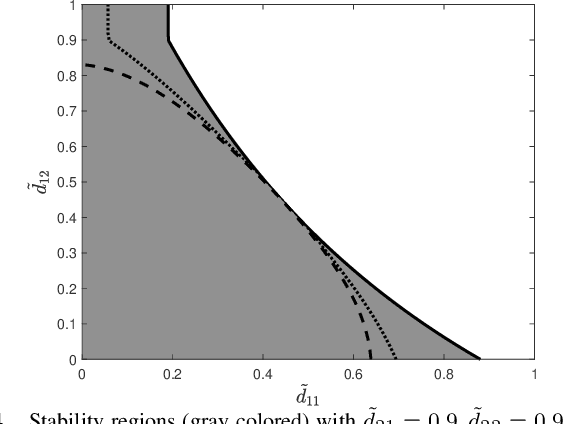
This work studies remote state estimation of multiple linear time-invariant systems over shared wireless time-varying communication channels. We model the channel states by a semi-Markov process which captures both the random holding period of each channel state and the state transitions. The model is sufficiently general to be used in both fast and slow fading scenarios. We derive necessary and sufficient stability conditions of the multi-sensor-multi-channel system in terms of the system parameters. We further investigate how the delay of the channel state information availability and the holding period of channel states affect the stability. In particular, we show that, from a system stability perspective, fast fading channels may be preferable to slow fading ones.
Sketched RT3D: How to reconstruct billions of photons per second
Mar 02, 2022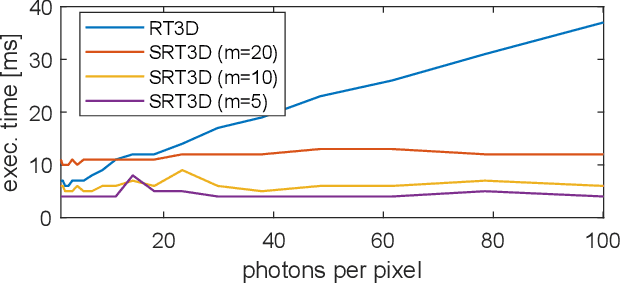
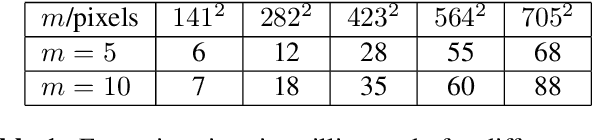
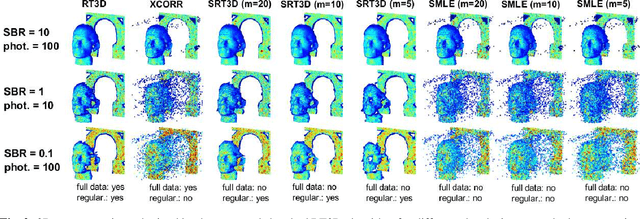

Single-photon light detection and ranging (lidar) captures depth and intensity information of a 3D scene. Reconstructing a scene from observed photons is a challenging task due to spurious detections associated with background illumination sources. To tackle this problem, there is a plethora of 3D reconstruction algorithms which exploit spatial regularity of natural scenes to provide stable reconstructions. However, most existing algorithms have computational and memory complexity proportional to the number of recorded photons. This complexity hinders their real-time deployment on modern lidar arrays which acquire billions of photons per second. Leveraging a recent lidar sketching framework, we show that it is possible to modify existing reconstruction algorithms such that they only require a small sketch of the photon information. In particular, we propose a sketched version of a recent state-of-the-art algorithm which uses point cloud denoisers to provide spatially regularized reconstructions. A series of experiments performed on real lidar datasets demonstrates a significant reduction of execution time and memory requirements, while achieving the same reconstruction performance than in the full data case.
A Variational Information Bottleneck Approach to Multi-Omics Data Integration
Feb 10, 2021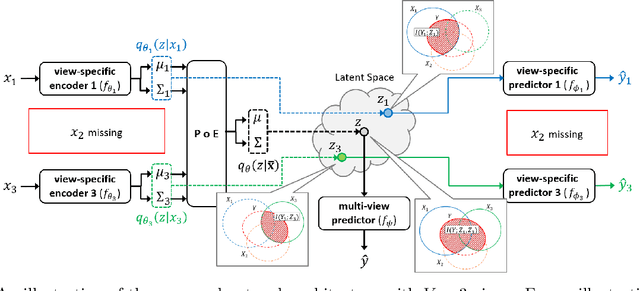

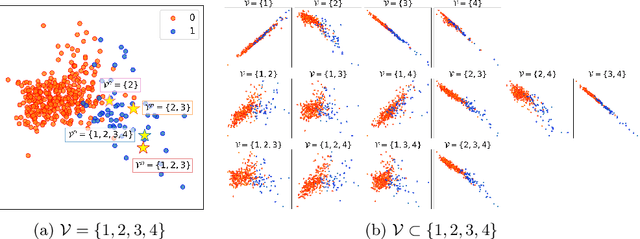
Integration of data from multiple omics techniques is becoming increasingly important in biomedical research. Due to non-uniformity and technical limitations in omics platforms, such integrative analyses on multiple omics, which we refer to as views, involve learning from incomplete observations with various view-missing patterns. This is challenging because i) complex interactions within and across observed views need to be properly addressed for optimal predictive power and ii) observations with various view-missing patterns need to be flexibly integrated. To address such challenges, we propose a deep variational information bottleneck (IB) approach for incomplete multi-view observations. Our method applies the IB framework on marginal and joint representations of the observed views to focus on intra-view and inter-view interactions that are relevant for the target. Most importantly, by modeling the joint representations as a product of marginal representations, we can efficiently learn from observed views with various view-missing patterns. Experiments on real-world datasets show that our method consistently achieves gain from data integration and outperforms state-of-the-art benchmarks.
A Learnable Variational Model for Joint Multimodal MRI Reconstruction and Synthesis
Apr 08, 2022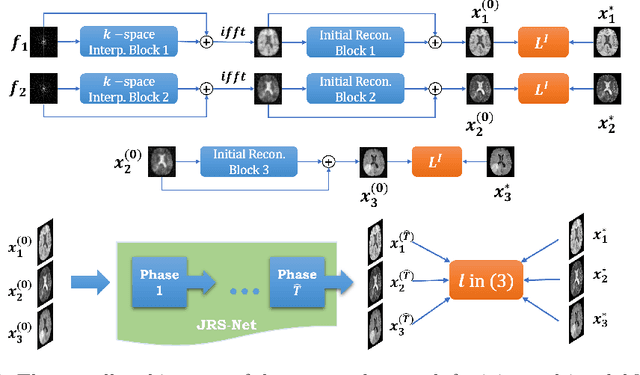
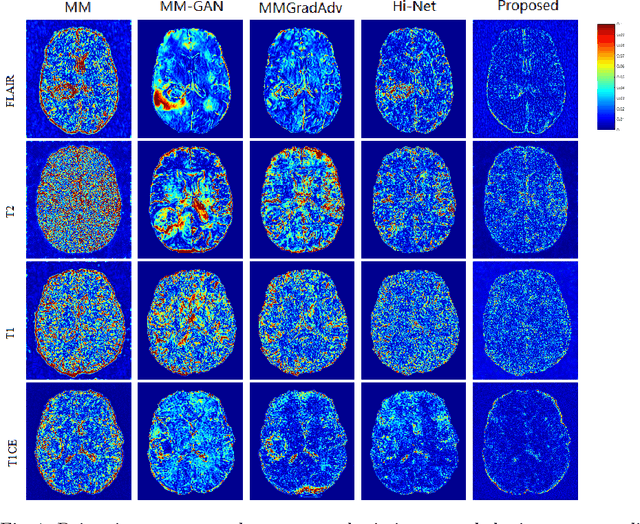

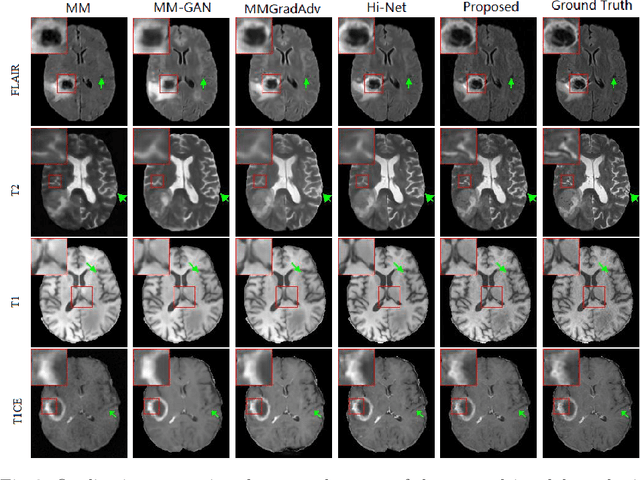
Generating multi-contrasts/modal MRI of the same anatomy enriches diagnostic information but is limited in practice due to excessive data acquisition time. In this paper, we propose a novel deep-learning model for joint reconstruction and synthesis of multi-modal MRI using incomplete k-space data of several source modalities as inputs. The output of our model includes reconstructed images of the source modalities and high-quality image synthesized in the target modality. Our proposed model is formulated as a variational problem that leverages several learnable modality-specific feature extractors and a multimodal synthesis module. We propose a learnable optimization algorithm to solve this model, which induces a multi-phase network whose parameters can be trained using multi-modal MRI data. Moreover, a bilevel-optimization framework is employed for robust parameter training. We demonstrate the effectiveness of our approach using extensive numerical experiments.
Equivariant Graph Attention Networks for Molecular Property Prediction
Feb 20, 2022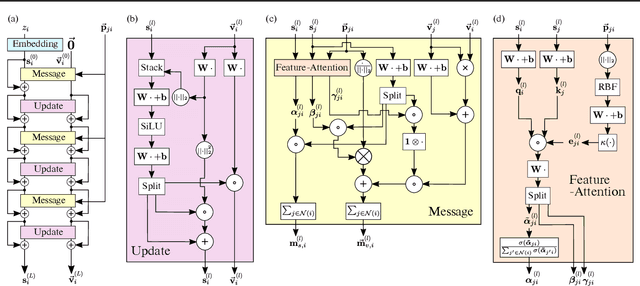
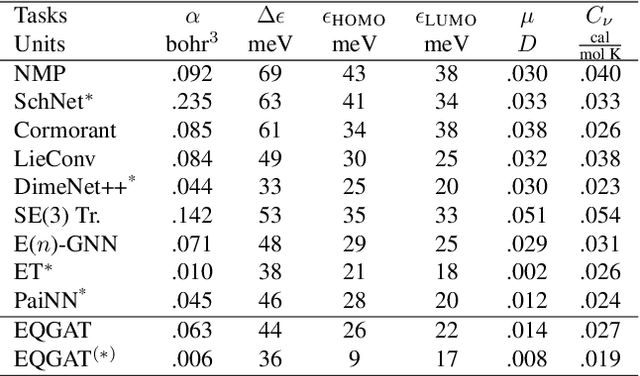
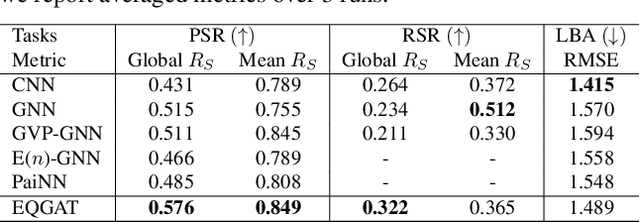
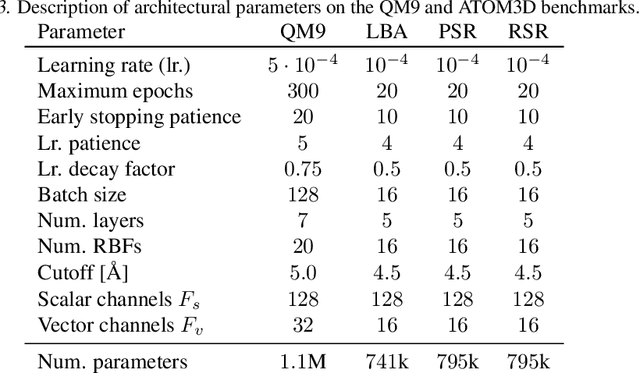
Learning and reasoning about 3D molecular structures with varying size is an emerging and important challenge in machine learning and especially in drug discovery. Equivariant Graph Neural Networks (GNNs) can simultaneously leverage the geometric and relational detail of the problem domain and are known to learn expressive representations through the propagation of information between nodes leveraging higher-order representations to faithfully express the geometry of the data, such as directionality in their intermediate layers. In this work, we propose an equivariant GNN that operates with Cartesian coordinates to incorporate directionality and we implement a novel attention mechanism, acting as a content and spatial dependent filter when propagating information between nodes. We demonstrate the efficacy of our architecture on predicting quantum mechanical properties of small molecules and its benefit on problems that concern macromolecular structures such as protein complexes.
UniDU: Towards A Unified Generative Dialogue Understanding Framework
Apr 10, 2022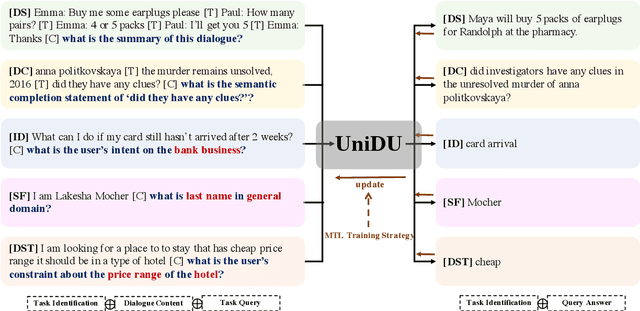
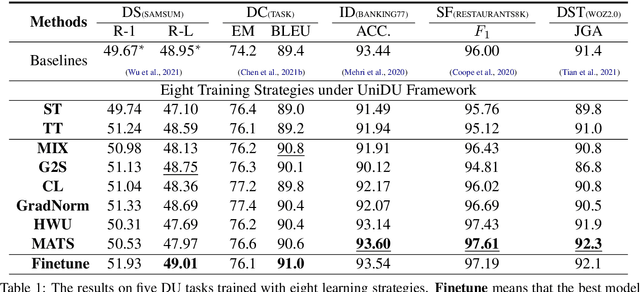

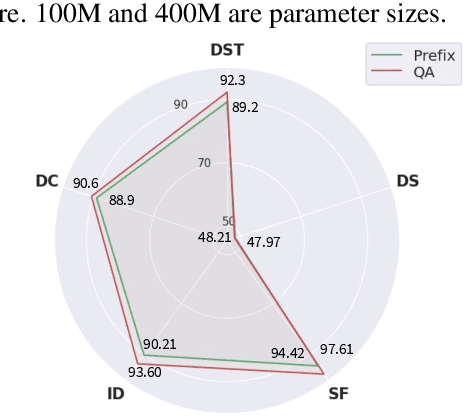
With the development of pre-trained language models, remarkable success has been witnessed in dialogue understanding (DU) direction. However, the current DU approaches just employ an individual model for each DU task, independently, without considering the shared knowledge across different DU tasks. In this paper, we investigate a unified generative dialogue understanding framework, namely UniDU, to achieve information exchange among DU tasks. Specifically, we reformulate the DU tasks into unified generative paradigm. In addition, to consider different training data for each task, we further introduce model-agnostic training strategy to optimize unified model in a balanced manner. We conduct the experiments on ten dialogue understanding datasets, which span five fundamental tasks: dialogue summary, dialogue completion, slot filling, intent detection and dialogue state tracking. The proposed UniDU framework outperforms task-specific well-designed methods on all 5 tasks. We further conduct comprehensive analysis experiments to study the effect factors. The experimental results also show that the proposed method obtains promising performance on unseen dialogue domain.
ClothFormer:Taming Video Virtual Try-on in All Module
Apr 26, 2022
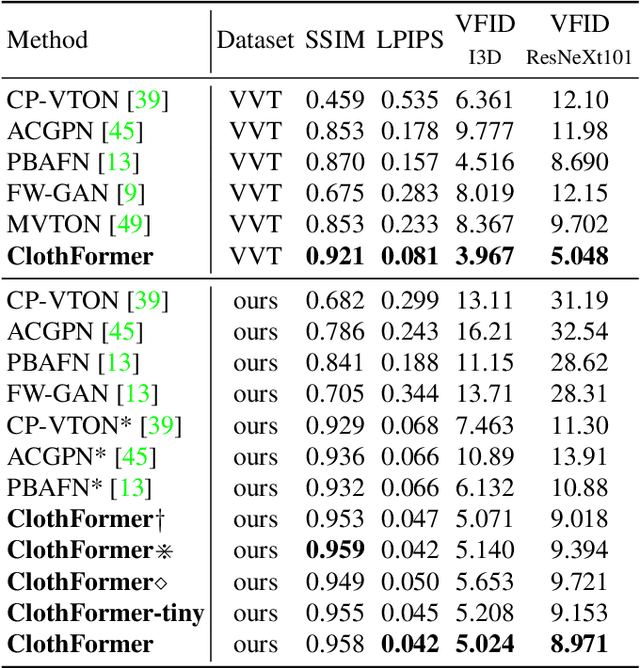
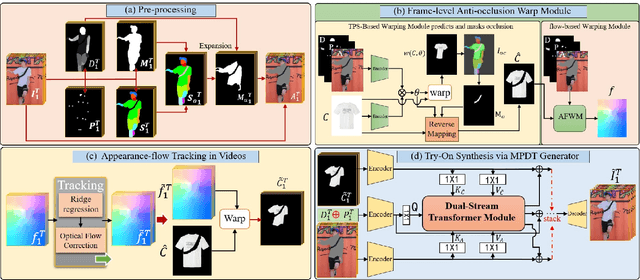
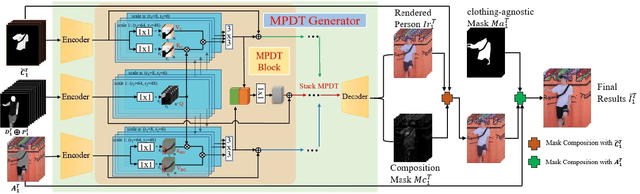
The task of video virtual try-on aims to fit the target clothes to a person in the video with spatio-temporal consistency. Despite tremendous progress of image virtual try-on, they lead to inconsistency between frames when applied to videos. Limited work also explored the task of video-based virtual try-on but failed to produce visually pleasing and temporally coherent results. Moreover, there are two other key challenges: 1) how to generate accurate warping when occlusions appear in the clothing region; 2) how to generate clothes and non-target body parts (e.g. arms, neck) in harmony with the complicated background; To address them, we propose a novel video virtual try-on framework, ClothFormer, which successfully synthesizes realistic, harmonious, and spatio-temporal consistent results in complicated environment. In particular, ClothFormer involves three major modules. First, a two-stage anti-occlusion warping module that predicts an accurate dense flow mapping between the body regions and the clothing regions. Second, an appearance-flow tracking module utilizes ridge regression and optical flow correction to smooth the dense flow sequence and generate a temporally smooth warped clothing sequence. Third, a dual-stream transformer extracts and fuses clothing textures, person features, and environment information to generate realistic try-on videos. Through rigorous experiments, we demonstrate that our method highly surpasses the baselines in terms of synthesized video quality both qualitatively and quantitatively.
In-N-Out: Pre-Training and Self-Training using Auxiliary Information for Out-of-Distribution Robustness
Dec 08, 2020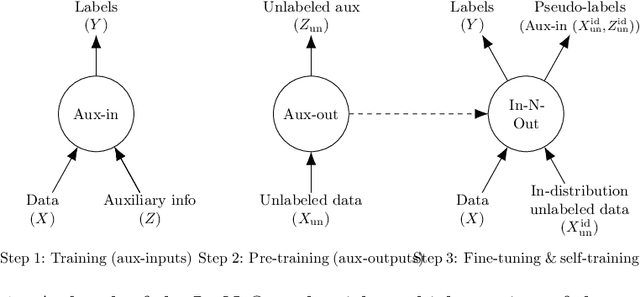
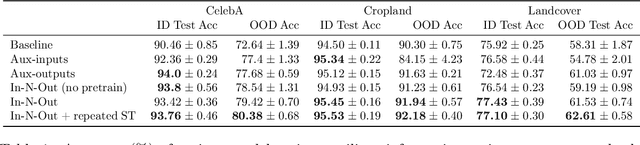

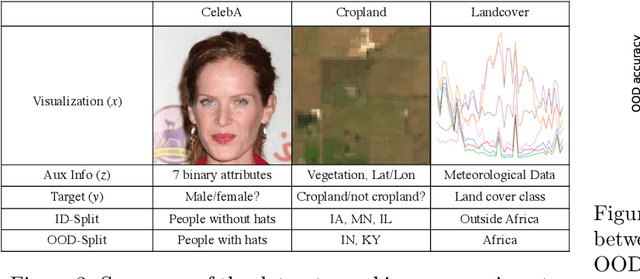
Consider a prediction setting where a few inputs (e.g., satellite images) are expensively annotated with the prediction targets (e.g., crop types), and many inputs are cheaply annotated with auxiliary information (e.g., climate information). How should we best leverage this auxiliary information for the prediction task? Empirically across three image and time-series datasets, and theoretically in a multi-task linear regression setting, we show that (i) using auxiliary information as input features improves in-distribution error but can hurt out-of-distribution (OOD) error; while (ii) using auxiliary information as outputs of auxiliary tasks to pre-train a model improves OOD error. To get the best of both worlds, we introduce In-N-Out, which first trains a model with auxiliary inputs and uses it to pseudolabel all the in-distribution inputs, then pre-trains a model on OOD auxiliary outputs and fine-tunes this model with the pseudolabels (self-training). We show both theoretically and empirically that In-N-Out outperforms auxiliary inputs or outputs alone on both in-distribution and OOD error.