 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Novel Channel Identification Architecture for mmWave Systems Based on Eigen Features
Apr 11, 2022
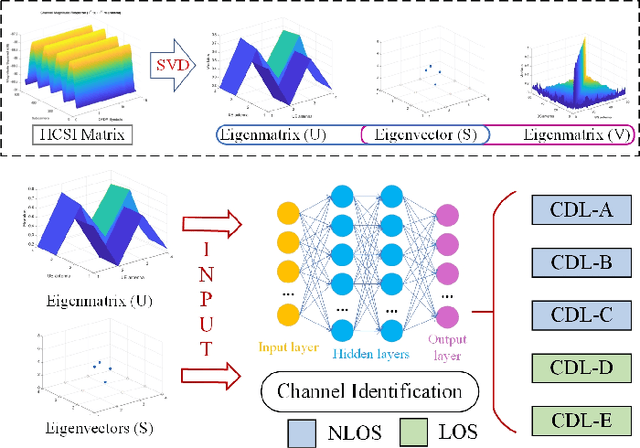
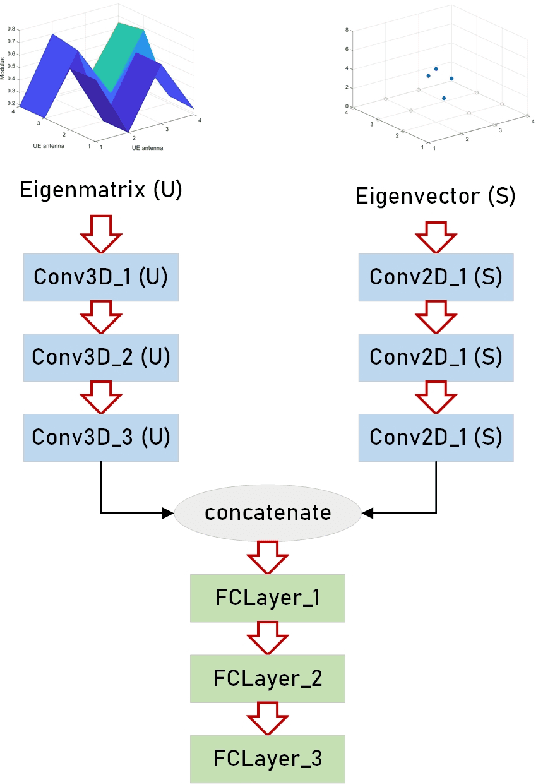
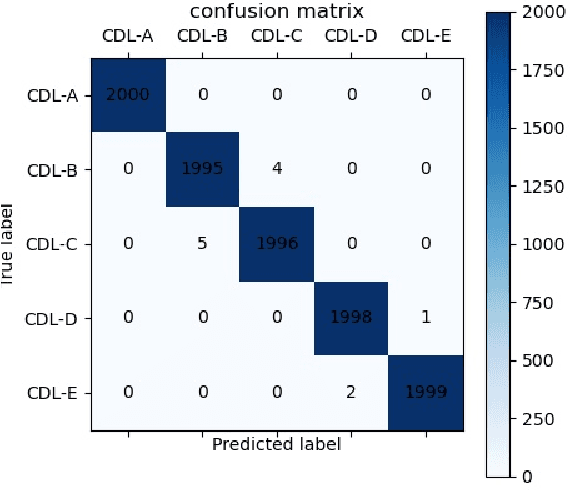
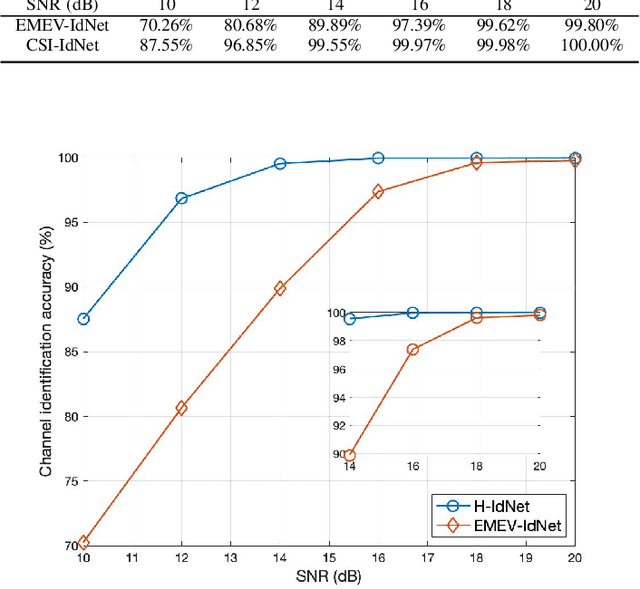
Millimeter wave (mmWave) communication technique has been developed rapidly because of many advantages of high speed, large bandwidth, and ultra-low delay. However, mmWave communications systems suffer from fast fading and frequent blocking. Hence, the ideal communication environment for mmWave is line of sight (LOS) channel. To improve the efficiency and capacity of mmWave system, and to better build the Internet of Everything (IoE) service network, this paper focuses on the channel identification technique in line-of- sight (LOS) and non-LOS (NLOS) environments. Considering the limited computing ability of user equipments (UEs), this paper proposes a novel channel identification architecture based on eigen features, i.e. eigenmatrix and eigenvector (EMEV) of channel state information (CSI). Furthermore, this paper explores clustered delay line (CDL) channel identification with mmWave, which is defined by the 3rd generation partnership project (3GPP). Ther experimental results show that the EMEV based scheme can achieve identification accuracy of 99.88% assuming perfect CSI. In the robustness test, the maximum noise can be tolerated is SNR= 16 dB, with the threshold acc \geq 95%. What is more, the novel architecture based on EMEV feature will reduce the comprehensive overhead by about 90%.
Prototype-based Domain Generalization Framework for Subject-Independent Brain-Computer Interfaces
Apr 15, 2022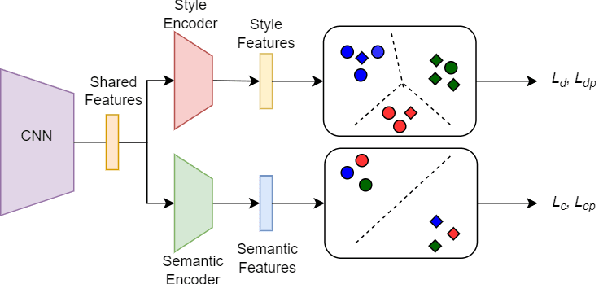
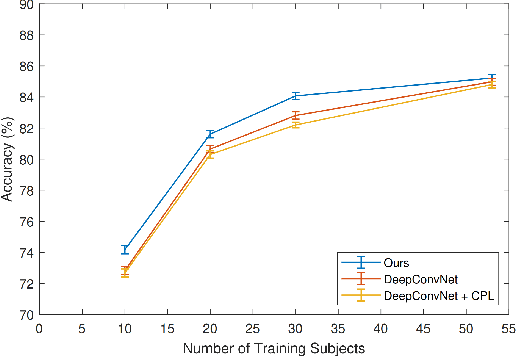
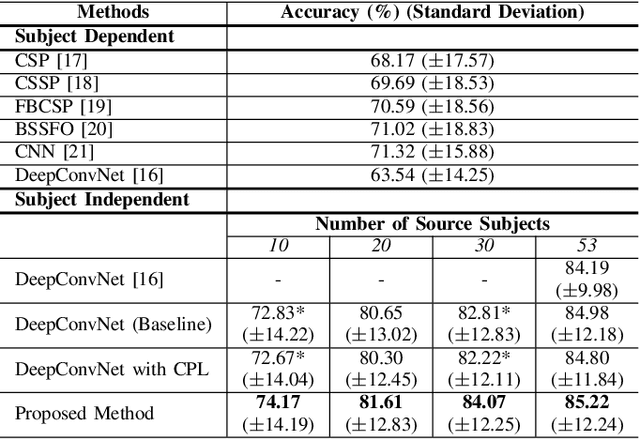
Brain-computer interface (BCI) is challenging to use in practice due to the inter/intra-subject variability of electroencephalography (EEG). The BCI system, in general, necessitates a calibration technique to obtain subject/session-specific data in order to tune the model each time the system is utilized. This issue is acknowledged as a key hindrance to BCI, and a new strategy based on domain generalization has recently evolved to address it. In light of this, we've concentrated on developing an EEG classification framework that can be applied directly to data from unknown domains (i.e. subjects), using only data acquired from separate subjects previously. For this purpose, in this paper, we proposed a framework that employs the open-set recognition technique as an auxiliary task to learn subject-specific style features from the source dataset while helping the shared feature extractor with mapping the features of the unseen target dataset as a new unseen domain. Our aim is to impose cross-instance style in-variance in the same domain and reduce the open space risk on the potential unseen subject in order to improve the generalization ability of the shared feature extractor. Our experiments showed that using the domain information as an auxiliary network increases the generalization performance.
Wind speed forecast using random forest learning method
Mar 23, 2022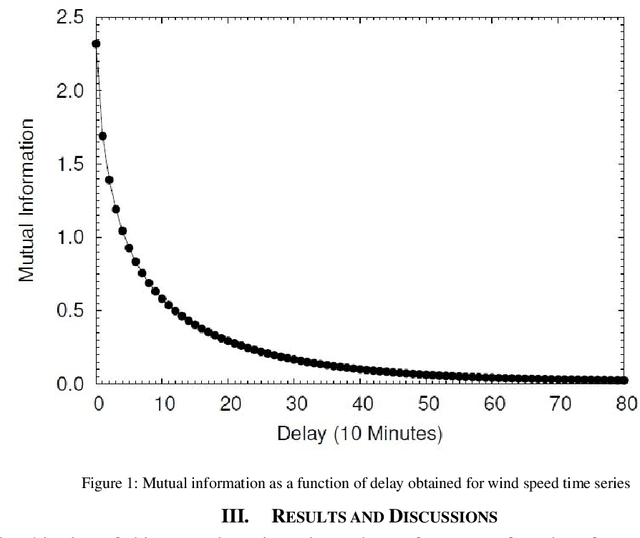
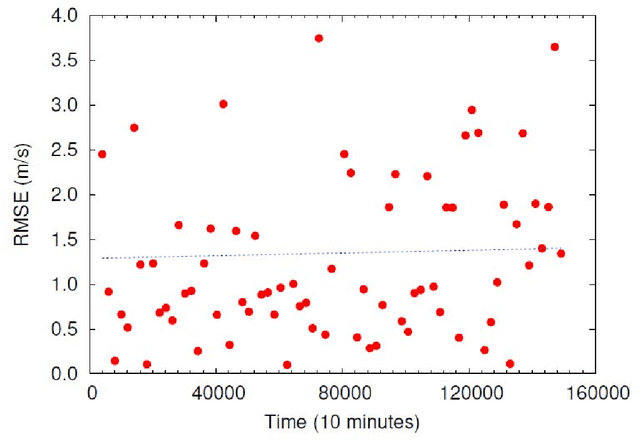
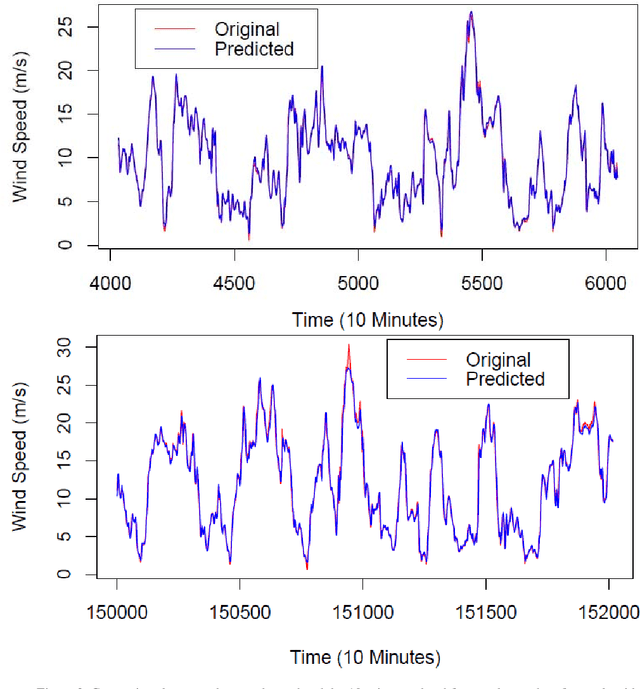
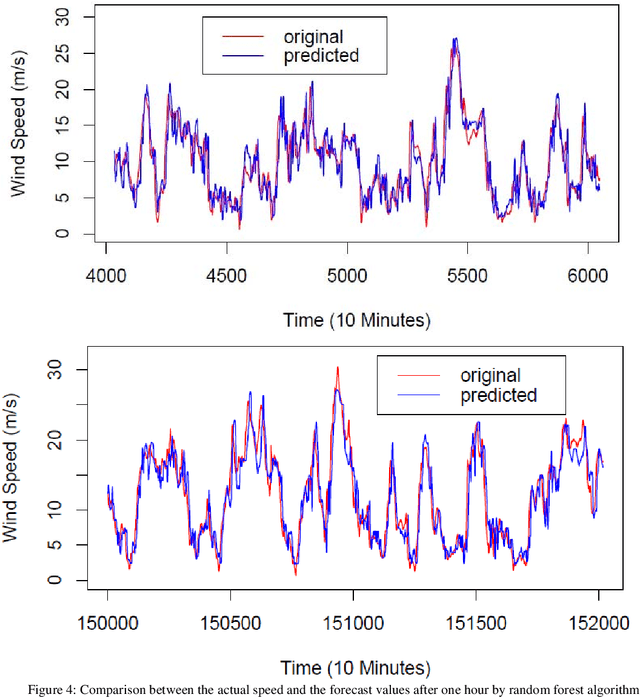
Wind speed forecasting models and their application to wind farm operations are attaining remarkable attention in the literature because of its benefits as a clean energy source. In this paper, we suggested the time series machine learning approach called random forest regression for predicting wind speed variations. The computed values of mutual information and auto-correlation shows that wind speed values depend on the past data up to 12 hours. The random forest model was trained using ensemble from two weeks data with previous 12 hours values as input for every value. The computed root mean square error shows that model trained with two weeks data can be employed to make reliable short-term predictions up to three years ahead.
WaBERT: A Low-resource End-to-end Model for Spoken Language Understanding and Speech-to-BERT Alignment
Apr 22, 2022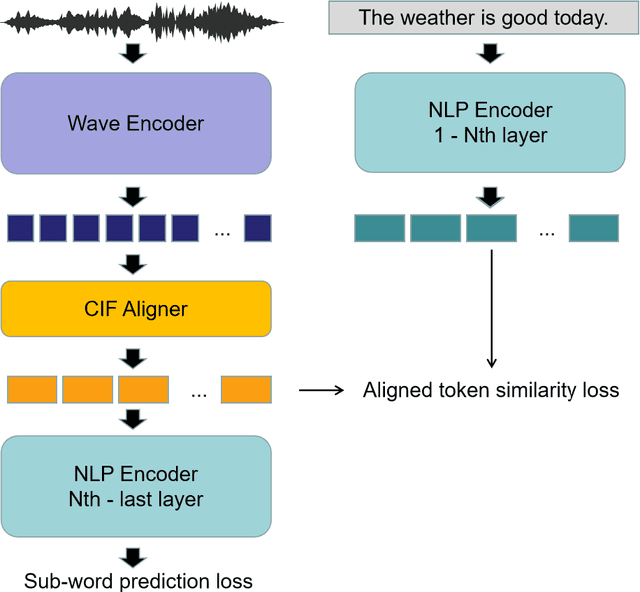


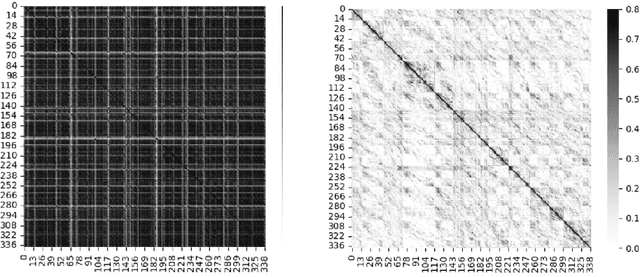
Historically lower-level tasks such as automatic speech recognition (ASR) and speaker identification are the main focus in the speech field. Interest has been growing in higher-level spoken language understanding (SLU) tasks recently, like sentiment analysis (SA). However, improving performances on SLU tasks remains a big challenge. Basically, there are two main methods for SLU tasks: (1) Two-stage method, which uses a speech model to transfer speech to text, then uses a language model to get the results of downstream tasks; (2) One-stage method, which just fine-tunes a pre-trained speech model to fit in the downstream tasks. The first method loses emotional cues such as intonation, and causes recognition errors during ASR process, and the second one lacks necessary language knowledge. In this paper, we propose the Wave BERT (WaBERT), a novel end-to-end model combining the speech model and the language model for SLU tasks. WaBERT is based on the pre-trained speech and language model, hence training from scratch is not needed. We also set most parameters of WaBERT frozen during training. By introducing WaBERT, audio-specific information and language knowledge are integrated in the short-time and low-resource training process to improve results on the dev dataset of SLUE SA tasks by 1.15% of recall score and 0.82% of F1 score. Additionally, we modify the serial Continuous Integrate-and-Fire (CIF) mechanism to achieve the monotonic alignment between the speech and text modalities.
Robust Generalization via $α$-Mutual Information
Jan 14, 2020
The aim of this work is to provide bounds connecting two probability measures of the same event using R\'enyi $\alpha$-Divergences and Sibson's $\alpha$-Mutual Information, a generalization of respectively the Kullback-Leibler Divergence and Shannon's Mutual Information. A particular case of interest can be found when the two probability measures considered are a joint distribution and the corresponding product of marginals (representing the statistically independent scenario). In this case, a bound using Sibson's $\alpha-$Mutual Information is retrieved, extending a result involving Maximal Leakage to general alphabets. These results have broad applications, from bounding the generalization error of learning algorithms to the more general framework of adaptive data analysis, provided that the divergences and/or information measures used are amenable to such an analysis ({\it i.e.,} are robust to post-processing and compose adaptively). The generalization error bounds are derived with respect to high-probability events but a corresponding bound on expected generalization error is also retrieved.
Language-Independent Speaker Anonymization Approach using Self-Supervised Pre-Trained Models
Mar 26, 2022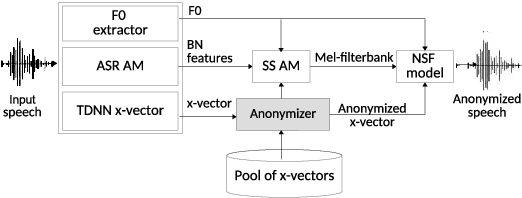
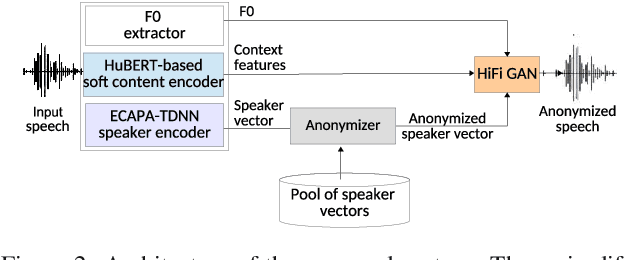

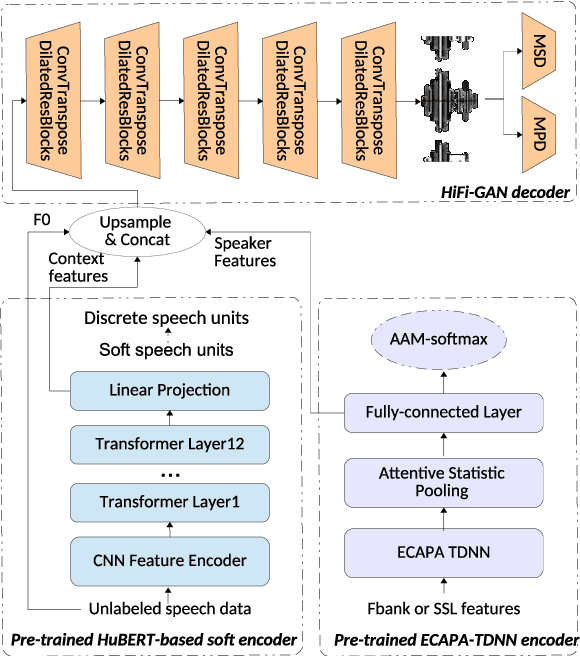
Speaker anonymization aims to protect the privacy of speakers while preserving spoken linguistic information from speech. Current mainstream neural network speaker anonymization systems are complicated, containing an F0 extractor, speaker encoder, automatic speech recognition acoustic model (ASR AM), speech synthesis acoustic model and speech waveform generation model. Moreover, as an ASR AM is language-dependent, trained on English data, it is hard to adapt it into another language. In this paper, we propose a simpler self-supervised learning (SSL)-based method for language-independent speaker anonymization without any explicit language-dependent model, which can be easily used for other languages. Extensive experiments were conducted on the VoicePrivacy Challenge 2020 datasets in English and AISHELL-3 datasets in Mandarin to demonstrate the effectiveness of our proposed SSL-based language-independent speaker anonymization method.
Semantic Segmentation for Point Cloud Scenes via Dilated Graph Feature Aggregation and Pyramid Decoders
Apr 11, 2022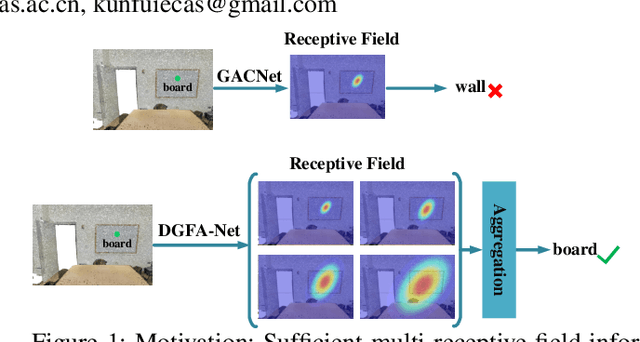
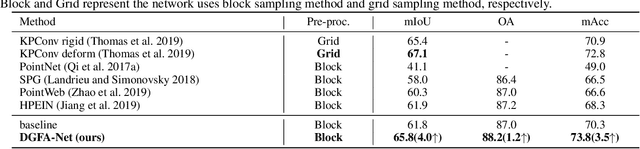
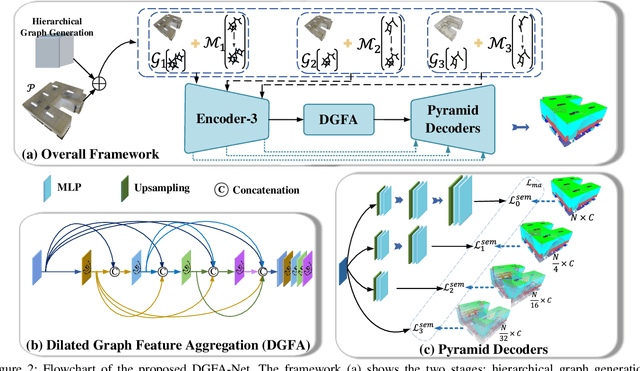

Semantic segmentation of point clouds generates comprehensive understanding of scenes through densely predicting the category for each point. Due to the unicity of receptive field, semantic segmentation of point clouds remains challenging for the expression of multi-receptive field features, which brings about the misclassification of instances with similar spatial structures. In this paper, we propose a graph convolutional network DGFA-Net rooted in dilated graph feature aggregation (DGFA), guided by multi-basis aggregation loss (MALoss) calculated through Pyramid Decoders. To configure multi-receptive field features, DGFA which takes the proposed dilated graph convolution (DGConv) as its basic building block, is designed to aggregate multi-scale feature representation by capturing dilated graphs with various receptive regions. By simultaneously considering penalizing the receptive field information with point sets of different resolutions as calculation bases, we introduce Pyramid Decoders driven by MALoss for the diversity of receptive field bases. Combining these two aspects, DGFA-Net significantly improves the segmentation performance of instances with similar spatial structures. Experiments on S3DIS, ShapeNetPart and Toronto-3D show that DGFA-Net outperforms the baseline approach, achieving a new state-of-the-art segmentation performance.
Ultrasound Shear Wave Elasticity Imaging with Spatio-Temporal Deep Learning
Apr 11, 2022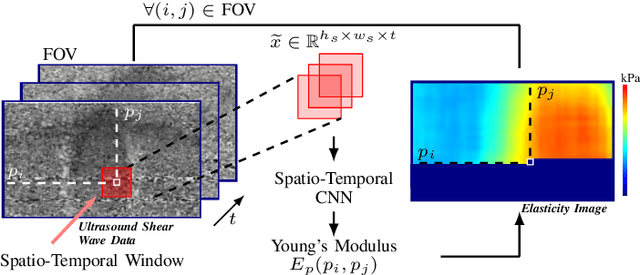
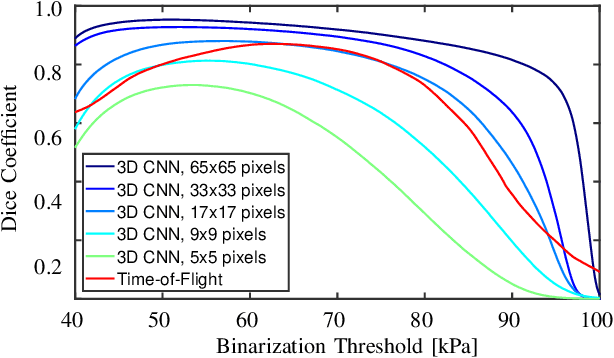
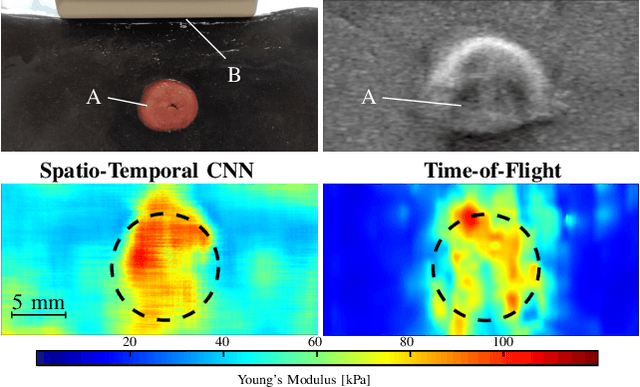

Ultrasound shear wave elasticity imaging is a valuable tool for quantifying the elastic properties of tissue. Typically, the shear wave velocity is derived and mapped to an elasticity value, which neglects information such as the shape of the propagating shear wave or push sequence characteristics. We present 3D spatio-temporal CNNs for fast local elasticity estimation from ultrasound data. This approach is based on retrieving elastic properties from shear wave propagation within small local regions. A large training data set is acquired with a robot from homogeneous gelatin phantoms ranging from 17.42 kPa to 126.05 kPa with various push locations. The results show that our approach can estimate elastic properties on a pixelwise basis with a mean absolute error of 5.01+-4.37 kPa. Furthermore, we estimate local elasticity independent of the push location and can even perform accurate estimates inside the push region. For phantoms with embedded inclusions, we report a 53.93% lower MAE (7.50 kPa) and on the background of 85.24% (1.64 kPa) compared to a conventional shear wave method. Overall, our method offers fast local estimations of elastic properties with small spatio-temporal window sizes.
Bag of Visual Words (BoVW) with Deep Features -- Patch Classification Model for Limited Dataset of Breast Tumours
Feb 22, 2022
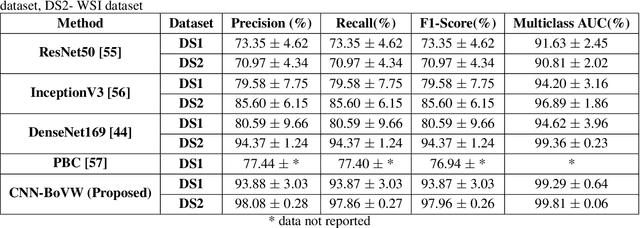
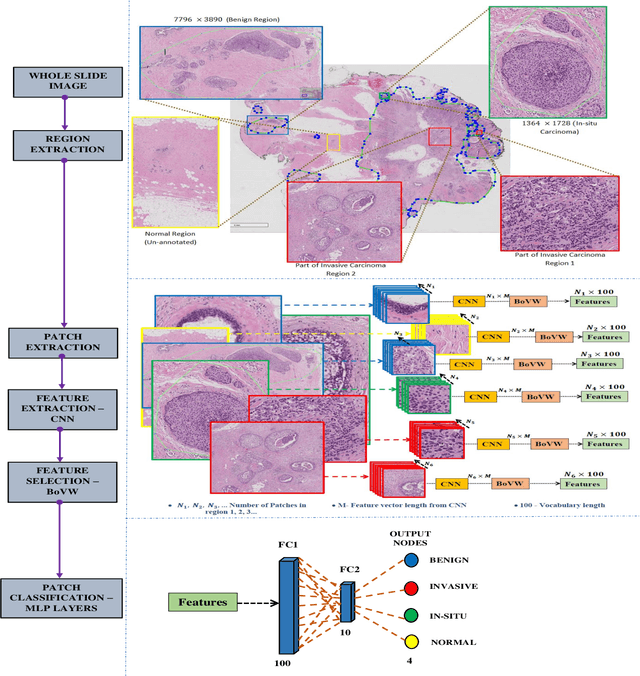
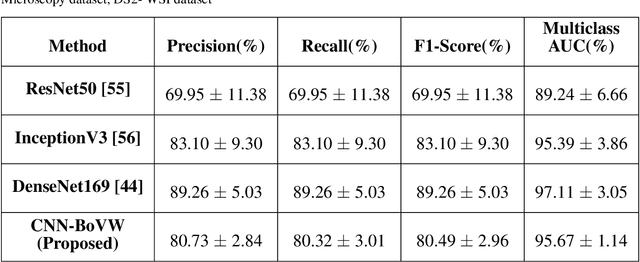
Currently, the computational complexity limits the training of high resolution gigapixel images using Convolutional Neural Networks. Therefore, such images are divided into patches or tiles. Since, these high resolution patches are encoded with discriminative information therefore; CNNs are trained on these patches to perform patch-level predictions. However, the problem with patch-level prediction is that pathologist generally annotates at image-level and not at patch level. Due to this limitation most of the patches may not contain enough class-relevant features. Through this work, we tried to incorporate patch descriptive capability within the deep framework by using Bag of Visual Words (BoVW) as a kind of regularisation to improve generalizability. Using this hypothesis, we aim to build a patch based classifier to discriminate between four classes of breast biopsy image patches (normal, benign, \textit{In situ} carcinoma, invasive carcinoma). The task is to incorporate quality deep features using CNN to describe relevant information in the images while simultaneously discarding irrelevant information using Bag of Visual Words (BoVW). The proposed method passes patches obtained from WSI and microscopy images through pre-trained CNN to extract features. BoVW is used as a feature selector to select most discriminative features among the CNN features. Finally, the selected feature sets are classified as one of the four classes. The hybrid model provides flexibility in terms of choice of pre-trained models for feature extraction. The pipeline is end-to-end since it does not require post processing of patch predictions to select discriminative patches. We compared our observations with state-of-the-art methods like ResNet50, DenseNet169, and InceptionV3 on the BACH-2018 challenge dataset. Our proposed method shows better performance than all the three methods.
Multiple-environment Self-adaptive Network for Aerial-view Geo-localization
Apr 18, 2022
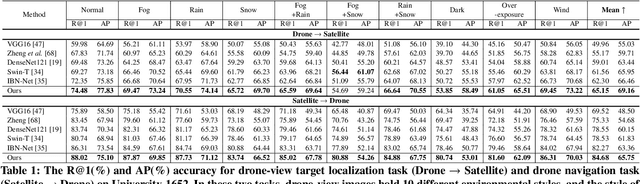
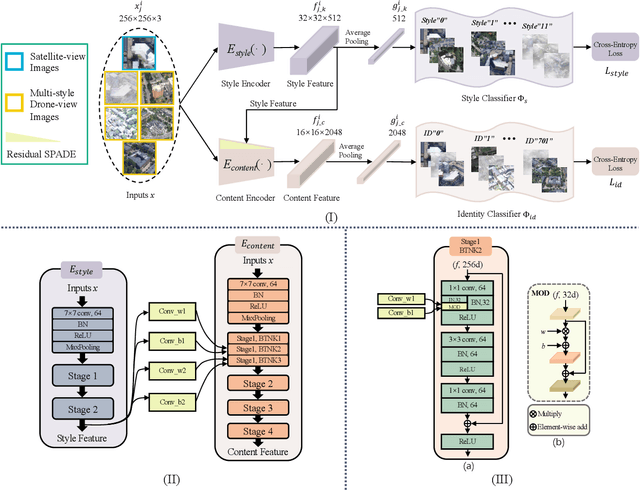

Aerial-view geo-localization tends to determine an unknown position through matching the drone-view image with the geo-tagged satellite-view image. This task is mostly regarded as an image retrieval problem. The key underpinning this task is to design a series of deep neural networks to learn discriminative image descriptors. However, existing methods meet large performance drops under realistic weather, such as rain and fog, since they do not take the domain shift between the training data and multiple test environments into consideration. To minor this domain gap, we propose a Multiple-environment Self-adaptive Network (MuSe-Net) to dynamically adjust the domain shift caused by environmental changing. In particular, MuSe-Net employs a two-branch neural network containing one multiple-environment style extraction network and one self-adaptive feature extraction network. As the name implies, the multiple-environment style extraction network is to extract the environment-related style information, while the self-adaptive feature extraction network utilizes an adaptive modulation module to dynamically minimize the environment-related style gap. Extensive experiments on two widely-used benchmarks, i.e., University-1652 and CVUSA, demonstrate that the proposed MuSe-Net achieves a competitive result for geo-localization in multiple environments. Furthermore, we observe that the proposed method also shows great potential to the unseen extreme weather, such as mixing the fog, rain and snow.