 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-view and Multi-modal Event Detection Utilizing Transformer-based Multi-sensor fusion
Feb 18, 2022
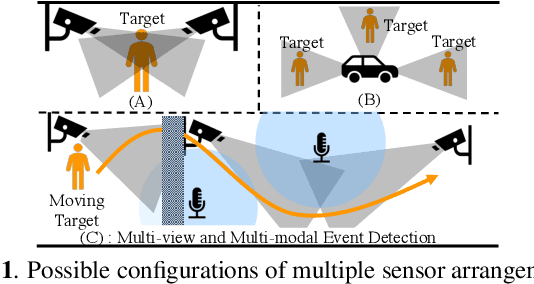
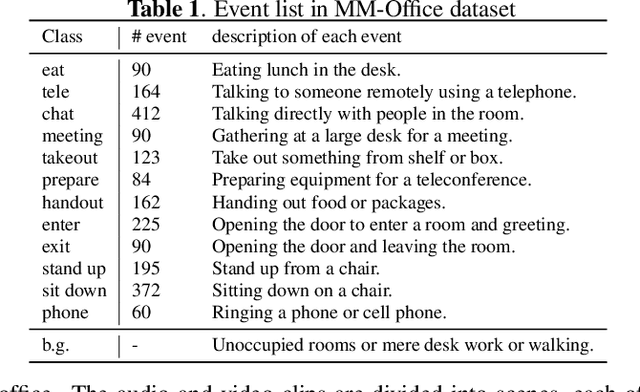
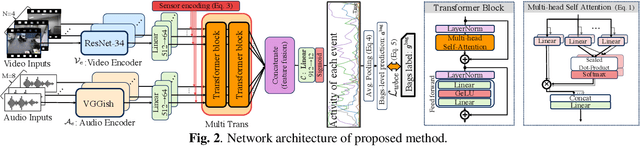
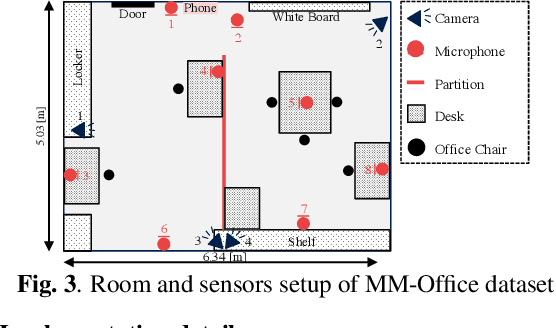
We tackle a challenging task: multi-view and multi-modal event detection that detects events in a wide-range real environment by utilizing data from distributed cameras and microphones and their weak labels. In this task, distributed sensors are utilized complementarily to capture events that are difficult to capture with a single sensor, such as a series of actions of people moving in an intricate room, or communication between people located far apart in a room. For sensors to cooperate effectively in such a situation, the system should be able to exchange information among sensors and combines information that is useful for identifying events in a complementary manner. For such a mechanism, we propose a Transformer-based multi-sensor fusion (MultiTrans) which combines multi-sensor data on the basis of the relationships between features of different viewpoints and modalities. In the experiments using a dataset newly collected for this task, our proposed method using MultiTrans improved the event detection performance and outperformed comparatives.
Temporal Alignment for History Representation in Reinforcement Learning
Apr 07, 2022



Environments in Reinforcement Learning are usually only partially observable. To address this problem, a possible solution is to provide the agent with information about the past. However, providing complete observations of numerous steps can be excessive. Inspired by human memory, we propose to represent history with only important changes in the environment and, in our approach, to obtain automatically this representation using self-supervision. Our method (TempAl) aligns temporally-close frames, revealing a general, slowly varying state of the environment. This procedure is based on contrastive loss, which pulls embeddings of nearby observations to each other while pushing away other samples from the batch. It can be interpreted as a metric that captures the temporal relations of observations. We propose to combine both common instantaneous and our history representation and we evaluate TempAl on all available Atari games from the Arcade Learning Environment. TempAl surpasses the instantaneous-only baseline in 35 environments out of 49. The source code of the method and of all the experiments is available at https://github.com/htdt/tempal.
Enriching Unsupervised User Embedding via Medical Concepts
Mar 29, 2022
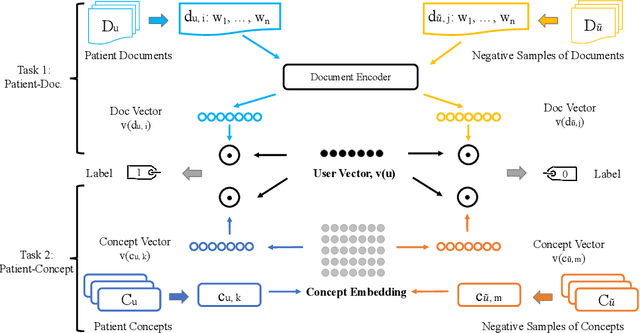
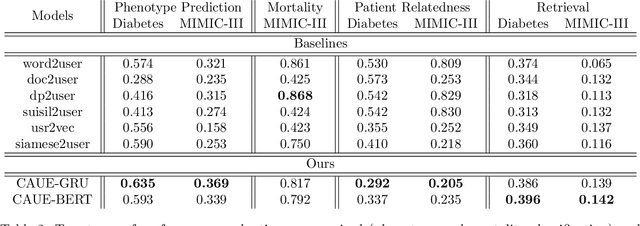
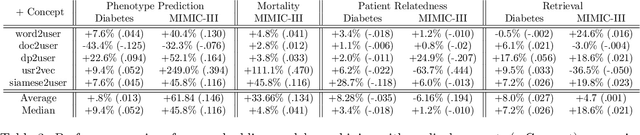
Clinical notes in Electronic Health Records (EHR) present rich documented information of patients to inference phenotype for disease diagnosis and study patient characteristics for cohort selection. Unsupervised user embedding aims to encode patients into fixed-length vectors without human supervisions. Medical concepts extracted from the clinical notes contain rich connections between patients and their clinical categories. However, existing unsupervised approaches of user embeddings from clinical notes do not explicitly incorporate medical concepts. In this study, we propose a concept-aware unsupervised user embedding that jointly leverages text documents and medical concepts from two clinical corpora, MIMIC-III and Diabetes. We evaluate user embeddings on both extrinsic and intrinsic tasks, including phenotype classification, in-hospital mortality prediction, patient retrieval, and patient relatedness. Experiments on the two clinical corpora show our approach exceeds unsupervised baselines, and incorporating medical concepts can significantly improve the baseline performance.
Masked Transformer for Neighhourhood-aware Click-Through Rate Prediction
Jan 25, 2022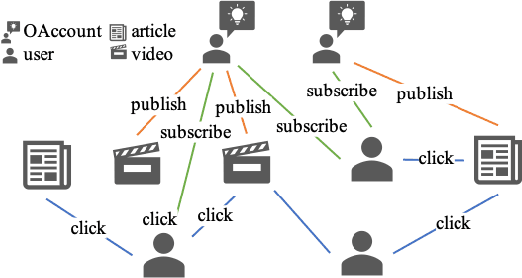
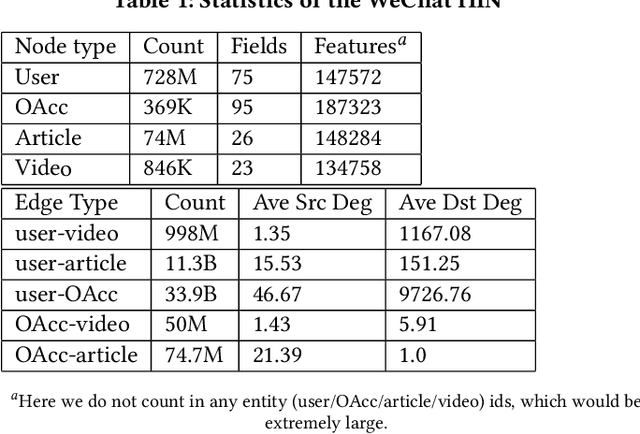
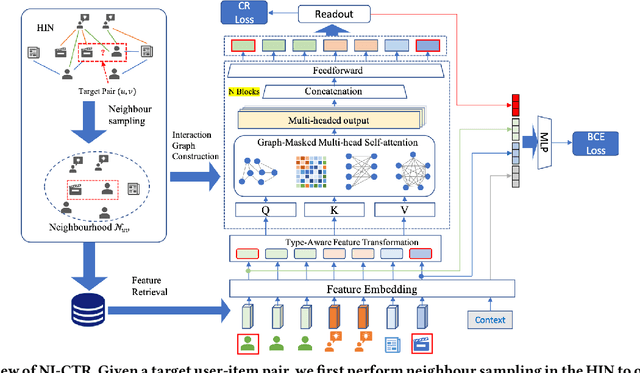
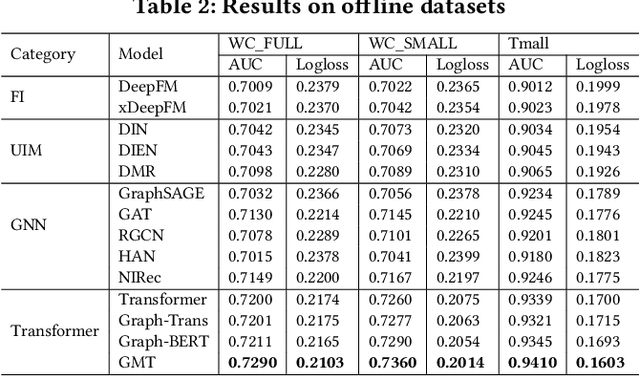
Click-Through Rate (CTR) prediction, is an essential component of online advertising. The mainstream techniques mostly focus on feature interaction or user interest modeling, which rely on users' directly interacted items. The performance of these methods are usally impeded by inactive behaviours and system's exposure, incurring that the features extracted do not contain enough information to represent all potential interests. For this sake, we propose Neighbor-Interaction based CTR prediction, which put this task into a Heterogeneous Information Network (HIN) setting, then involves local neighborhood of the target user-item pair in the HIN to predict their linkage. In order to enhance the representation of the local neighbourhood, we consider four types of topological interaction among the nodes, and propose a novel Graph-masked Transformer architecture to effectively incorporates both feature and topological information. We conduct comprehensive experiments on two real world datasets and the experimental results show that our proposed method outperforms state-of-the-art CTR models significantly.
Do Transformers Encode a Foundational Ontology? Probing Abstract Classes in Natural Language
Jan 25, 2022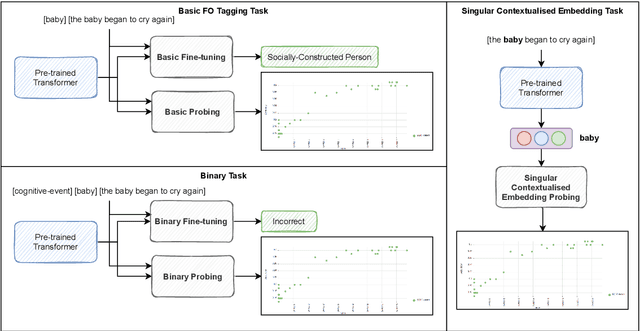
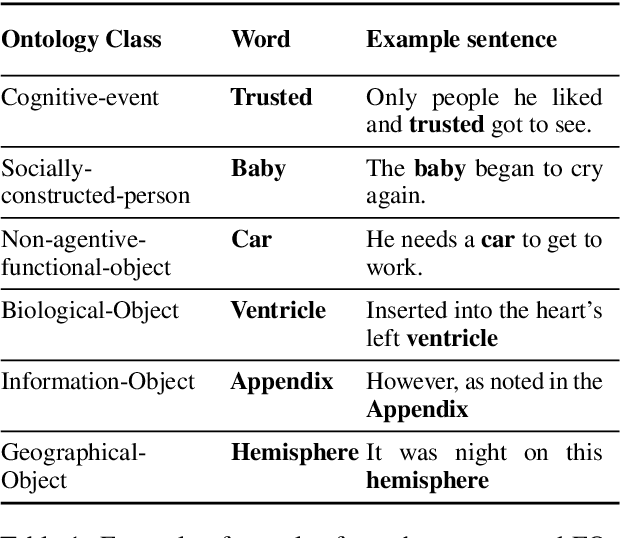
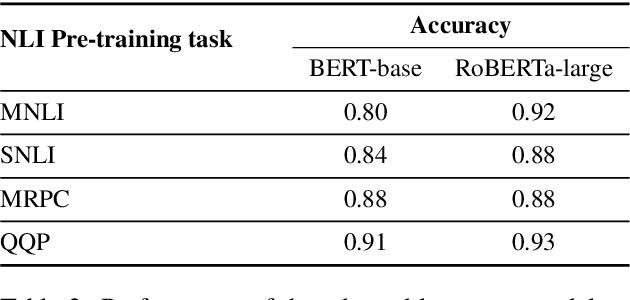

With the methodological support of probing (or diagnostic classification), recent studies have demonstrated that Transformers encode syntactic and semantic information to some extent. Following this line of research, this paper aims at taking semantic probing to an abstraction extreme with the goal of answering the following research question: can contemporary Transformer-based models reflect an underlying Foundational Ontology? To this end, we present a systematic Foundational Ontology (FO) probing methodology to investigate whether Transformers-based models encode abstract semantic information. Following different pre-training and fine-tuning regimes, we present an extensive evaluation of a diverse set of large-scale language models over three distinct and complementary FO tagging experiments. Specifically, we present and discuss the following conclusions: (1) The probing results indicate that Transformer-based models incidentally encode information related to Foundational Ontologies during the pre-training pro-cess; (2) Robust FO taggers (accuracy of 90 percent)can be efficiently built leveraging on this knowledge.
ProbNVS: Fast Novel View Synthesis with Learned Probability-Guided Sampling
Apr 07, 2022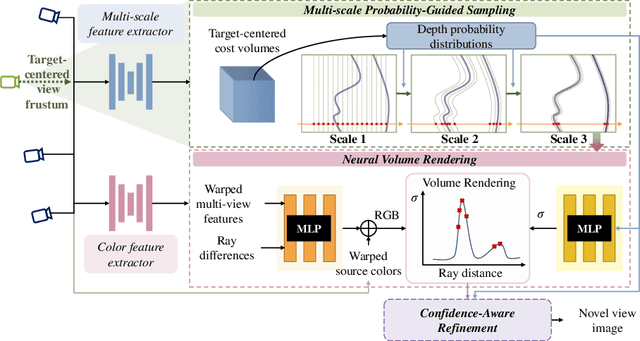
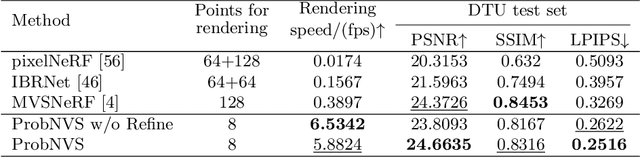
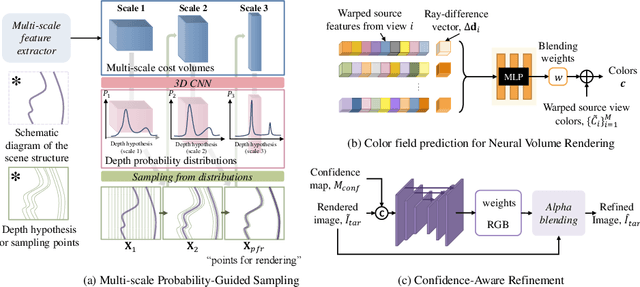
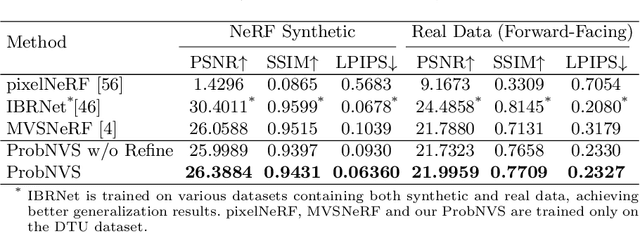
Existing state-of-the-art novel view synthesis methods rely on either fairly accurate 3D geometry estimation or sampling of the entire space for neural volumetric rendering, which limit the overall efficiency. In order to improve the rendering efficiency by reducing sampling points without sacrificing rendering quality, we propose to build a novel view synthesis framework based on learned MVS priors that enables general, fast and photo-realistic view synthesis simultaneously. Specifically, fewer but important points are sampled under the guidance of depth probability distributions extracted from the learned MVS architecture. Based on the learned probability-guided sampling, a neural volume rendering module is elaborately devised to fully aggregate source view information as well as the learned scene structures to synthesize photorealistic target view images. Finally, the rendering results in uncertain, occluded and unreferenced regions can be further improved by incorporating a confidence-aware refinement module. Experiments show that our method achieves 15 to 40 times faster rendering compared to state-of-the-art baselines, with strong generalization capacity and comparable high-quality novel view synthesis performance.
Sign and Basis Invariant Networks for Spectral Graph Representation Learning
Apr 11, 2022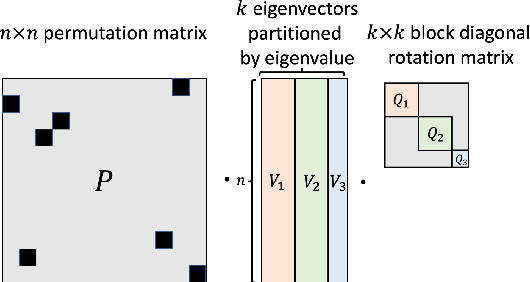
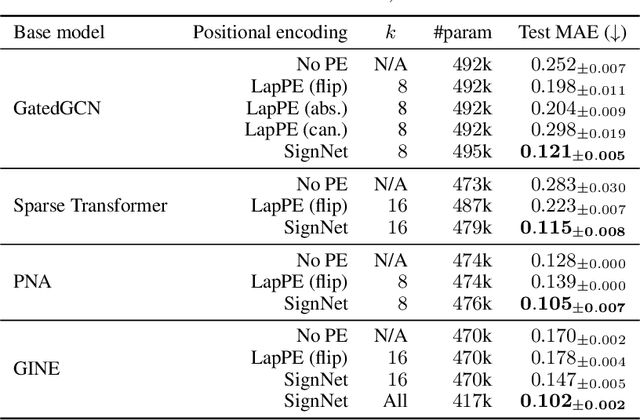

Many machine learning tasks involve processing eigenvectors derived from data. Especially valuable are Laplacian eigenvectors, which capture useful structural information about graphs and other geometric objects. However, ambiguities arise when computing eigenvectors: for each eigenvector $v$, the sign flipped $-v$ is also an eigenvector. More generally, higher dimensional eigenspaces contain infinitely many choices of basis eigenvectors. These ambiguities make it a challenge to process eigenvectors and eigenspaces in a consistent way. In this work we introduce SignNet and BasisNet -- new neural architectures that are invariant to all requisite symmetries and hence process collections of eigenspaces in a principled manner. Our networks are universal, i.e., they can approximate any continuous function of eigenvectors with the proper invariances. They are also theoretically strong for graph representation learning -- they can approximate any spectral graph convolution, can compute spectral invariants that go beyond message passing neural networks, and can provably simulate previously proposed graph positional encodings. Experiments show the strength of our networks for molecular graph regression, learning expressive graph representations, and learning implicit neural representations on triangle meshes. Our code is available at https://github.com/cptq/SignNet-BasisNet .
Preventing Over-Smoothing for Hypergraph Neural Networks
Mar 31, 2022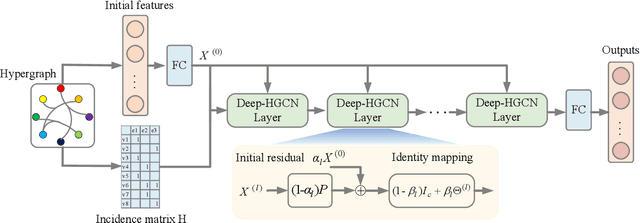
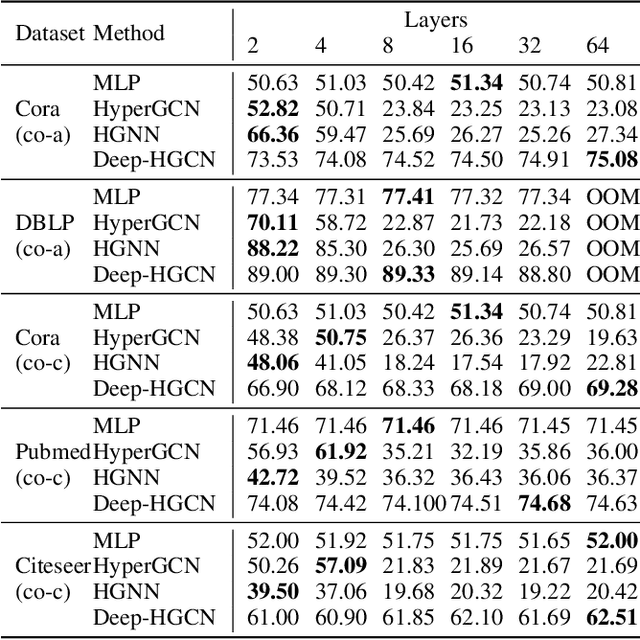
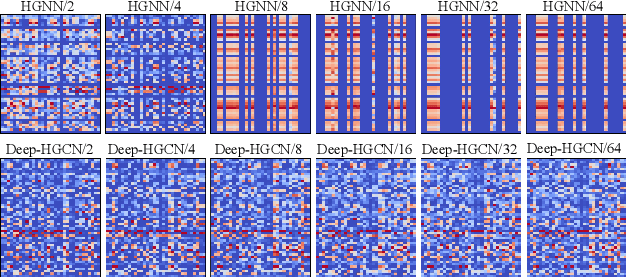
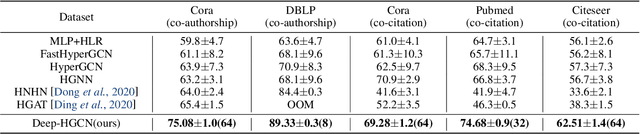
In recent years, hypergraph learning has attracted great attention due to its capacity in representing complex and high-order relationships. However, current neural network approaches designed for hypergraphs are mostly shallow, thus limiting their ability to extract information from high-order neighbors. In this paper, we show both theoretically and empirically, that the performance of hypergraph neural networks does not improve as the number of layers increases, which is known as the over-smoothing problem. To tackle this issue, we develop a new deep hypergraph convolutional network called Deep-HGCN, which can maintain the heterogeneity of node representation in deep layers. Specifically, we prove that a $k$-layer Deep-HGCN simulates a polynomial filter of order $k$ with arbitrary coefficients, which can relieve the problem of over-smoothing. Experimental results on various datasets demonstrate the superior performance of the proposed model comparing to the state-of-the-art hypergraph learning approaches.
An Unsupervised Information-Theoretic Perceptual Quality Metric
Jun 11, 2020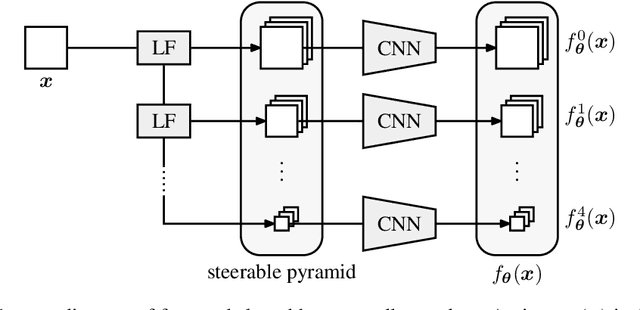
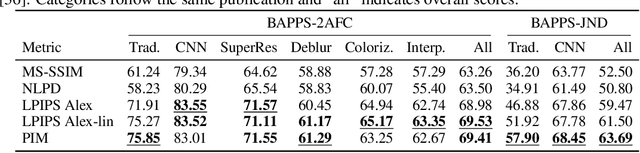
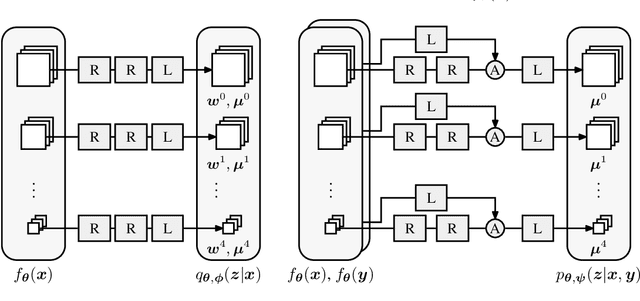
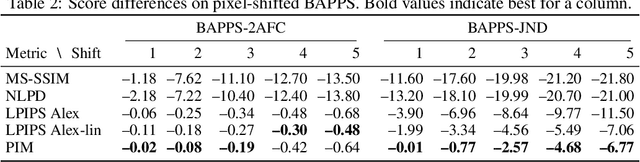
Tractable models of human perception have proved to be challenging to build. Hand-designed models such as MS-SSIM remain popular predictors of human image quality judgements due to their simplicity and speed. Recent modern deep learning approaches can perform better, but they rely on supervised data which can be costly to gather: large sets of class labels such as ImageNet, image quality ratings, or both. We combine recent advances in information-theoretic objective functions with a computational architecture informed by the physiology of the human visual system and unsupervised training on pairs of video frames, yielding our Perceptual Information Metric (PIM). We show that PIM is competitive with supervised metrics on the recent and challenging BAPPS image quality assessment dataset. We also perform qualitative experiments using the ImageNet-C dataset, and establish that our approach is robust with respect to architectural details.
ReINTEL Challenge 2020: A Multimodal Ensemble Model for Detecting Unreliable Information on Vietnamese SNS
Dec 18, 2020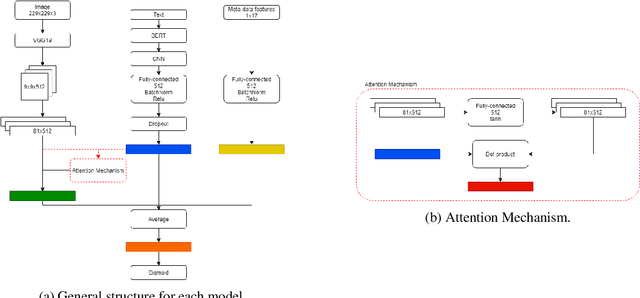
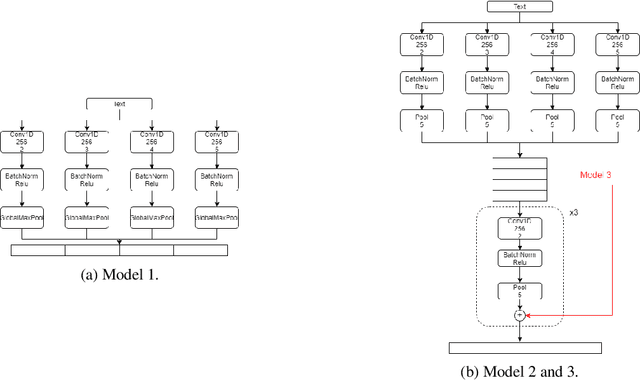

In this paper, we present our methods for unrealiable information identification task at VLSP 2020 ReINTEL Challenge. The task is to classify a piece of information into reliable or unreliable category. We propose a novel multimodal ensemble model which combines two multimodal models to solve the task. In each multimodal model, we combined feature representations acquired from three different data types: texts, images, and metadata. Multimodal features are derived from three neural networks and fused for classification. Experimental results showed that our proposed multimodal ensemble model improved against single models in term of ROC AUC score. We obtained 0.9445 AUC score on the private test of the challenge.