 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integrating Frequency Translational Invariance in TDNNs and Frequency Positional Information in 2D ResNets to Enhance Speaker Verification
Apr 06, 2021
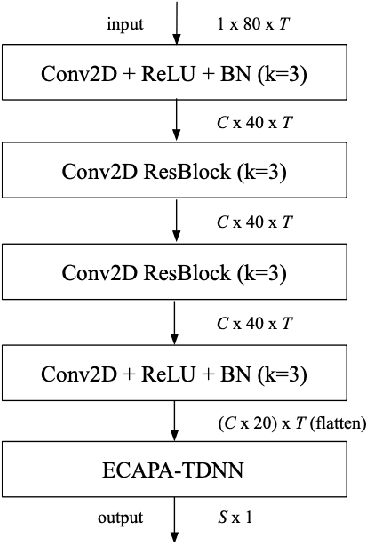
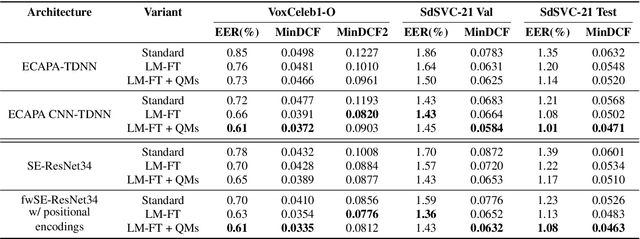
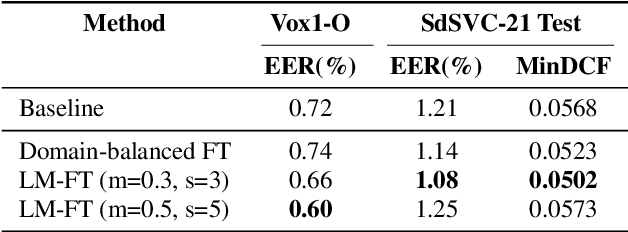

This paper describes the IDLab submission for the text-independent task of the Short-duration Speaker Verification Challenge 2021 (SdSVC-21). This speaker verification competition focuses on short duration test recordings and cross-lingual trials, along with the constraint of limited availability of in-domain DeepMine Farsi training data. Currently, both Time Delay Neural Networks (TDNNs) and ResNets achieve state-of-the-art results in speaker verification. These architectures are structurally very different and the construction of hybrid networks looks a promising way forward. We introduce a 2D convolutional stem in a strong ECAPA-TDNN baseline to transfer some of the strong characteristics of a ResNet based model to this hybrid CNN-TDNN architecture. Similarly, we incorporate absolute frequency positional encodings in an SE-ResNet34 architecture. These learnable feature map biases along the frequency axis offer this architecture a straightforward way to exploit frequency positional information. We also propose a frequency-wise variant of Squeeze-Excitation (SE) which better preserves frequency-specific information when rescaling the feature maps. Both modified architectures significantly outperform their corresponding baseline on the SdSVC-21 evaluation data and the original VoxCeleb1 test set. A four system fusion containing the two improved architectures achieved a third place in the final SdSVC-21 Task 2 ranking.
Abstract Flow for Temporal Semantic Segmentation on the Permutohedral Lattice
Mar 29, 2022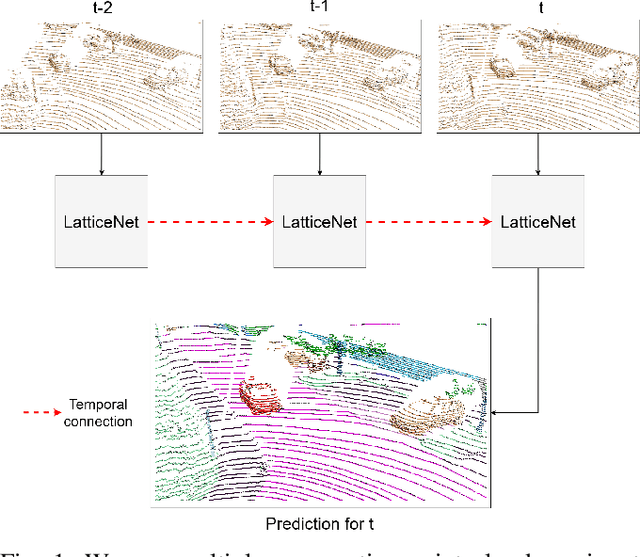
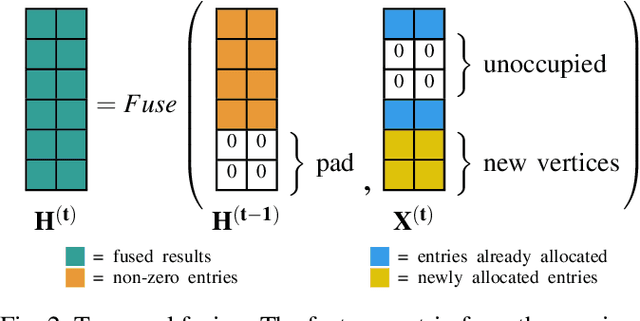
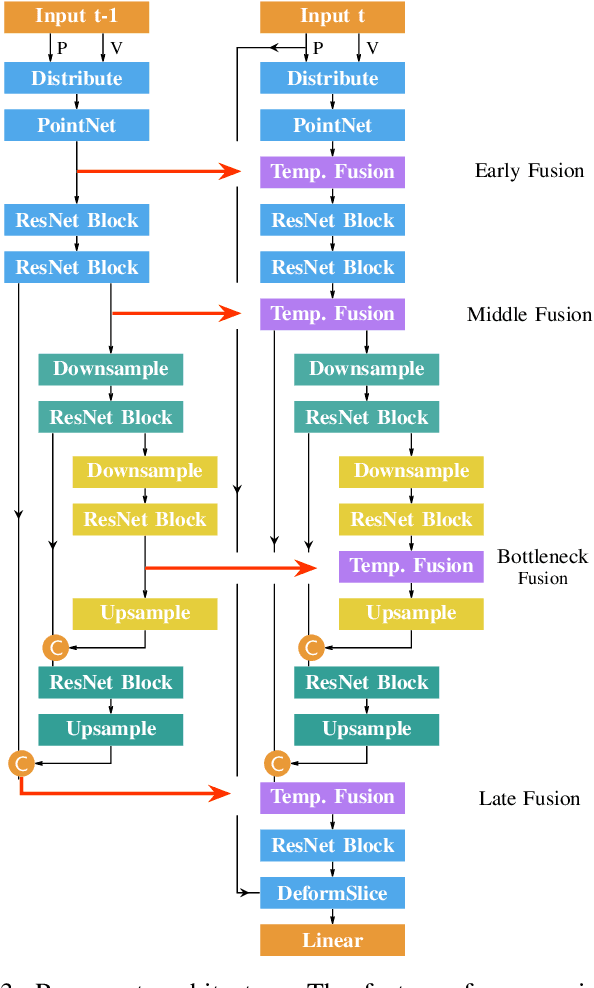
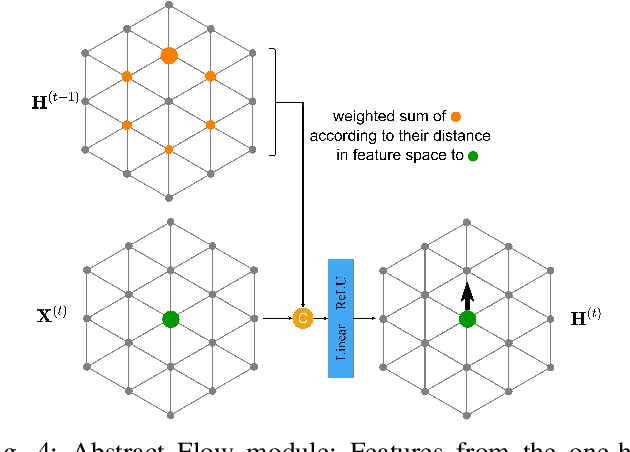
Semantic segmentation is a core ability required by autonomous agents, as being able to distinguish which parts of the scene belong to which object class is crucial for navigation and interaction with the environment. Approaches which use only one time-step of data cannot distinguish between moving objects nor can they benefit from temporal integration. In this work, we extend a backbone LatticeNet to process temporal point cloud data. Additionally, we take inspiration from optical flow methods and propose a new module called Abstract Flow which allows the network to match parts of the scene with similar abstract features and gather the information temporally. We obtain state-of-the-art results on the SemanticKITTI dataset that contains LiDAR scans from real urban environments. We share the PyTorch implementation of TemporalLatticeNet at https://github.com/AIS-Bonn/temporal_latticenet .
Embedding Information onto a Dynamical System
May 22, 2021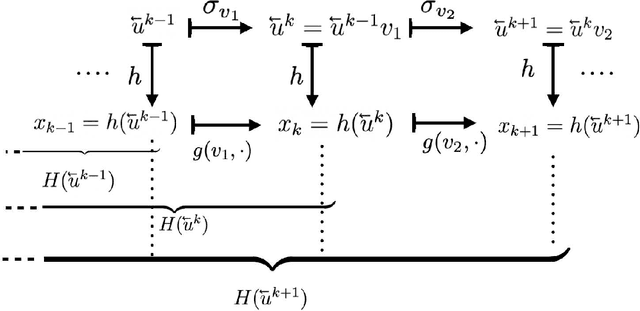
The celebrated Takens' embedding theorem concerns embedding an attractor of a dynamical system in a Euclidean space of appropriate dimension through a generic delay-observation map. The embedding also establishes a topological conjugacy. In this paper, we show how an arbitrary sequence can be mapped into another space as an attractive solution of a nonautonomous dynamical system. Such mapping also entails a topological conjugacy and an embedding between the sequence and the attractive solution spaces. This result is not a generalization of Takens embedding theorem but helps us understand what exactly is required by discrete-time state space models widely used in applications to embed an external stimulus onto its solution space. Our results settle another basic problem concerning the perturbation of an autonomous dynamical system. We describe what exactly happens to the dynamics when exogenous noise perturbs continuously a local irreducible attracting set (such as a stable fixed point) of a discrete-time autonomous dynamical system.
A Review on Methods and Applications in Multimodal Deep Learning
Feb 18, 2022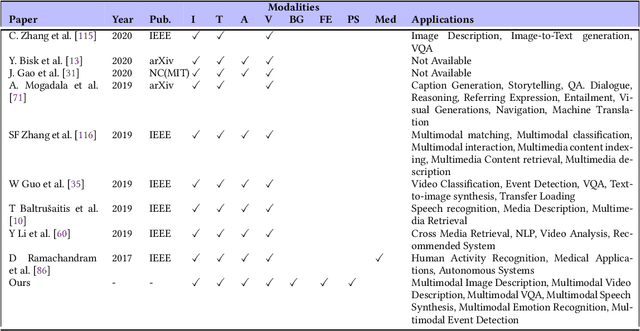
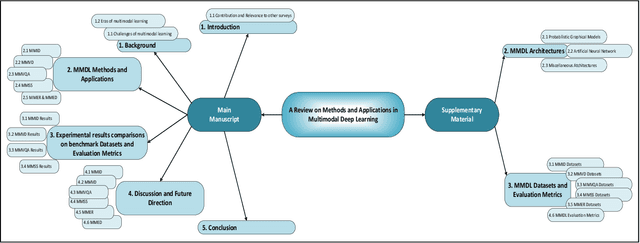
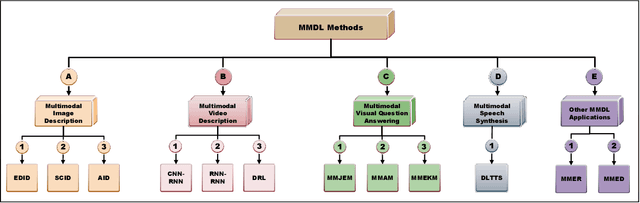
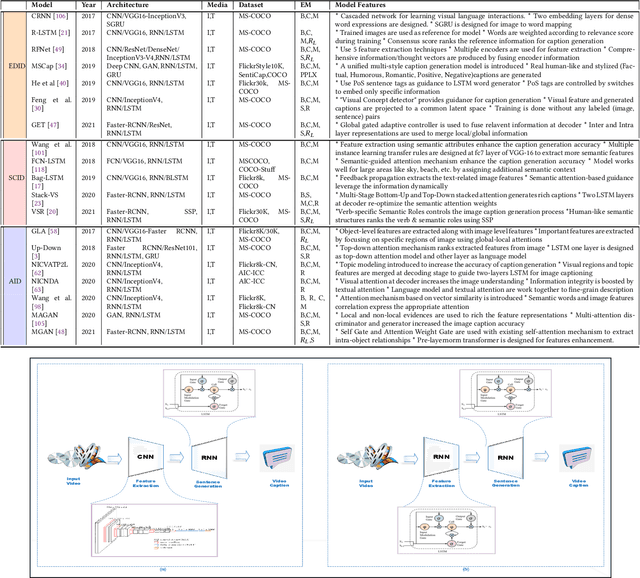
Deep Learning has implemented a wide range of applications and has become increasingly popular in recent years. The goal of multimodal deep learning (MMDL) is to create models that can process and link information using various modalities. Despite the extensive development made for unimodal learning, it still cannot cover all the aspects of human learning. Multimodal learning helps to understand and analyze better when various senses are engaged in the processing of information. This paper focuses on multiple types of modalities, i.e., image, video, text, audio, body gestures, facial expressions, and physiological signals. Detailed analysis of the baseline approaches and an in-depth study of recent advancements during the last five years (2017 to 2021) in multimodal deep learning applications has been provided. A fine-grained taxonomy of various multimodal deep learning methods is proposed, elaborating on different applications in more depth. Lastly, main issues are highlighted separately for each domain, along with their possible future research directions.
* 29 pages. arXiv admin note: substantial text overlap with arXiv:2105.11087
Masked Transformer for Neighhourhood-aware Click-Through Rate Prediction
Jan 25, 2022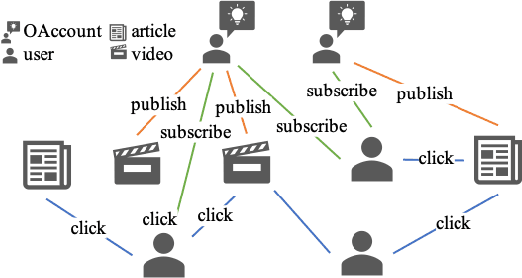
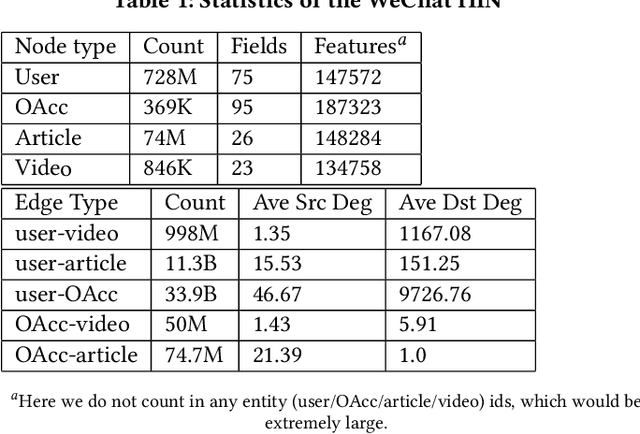
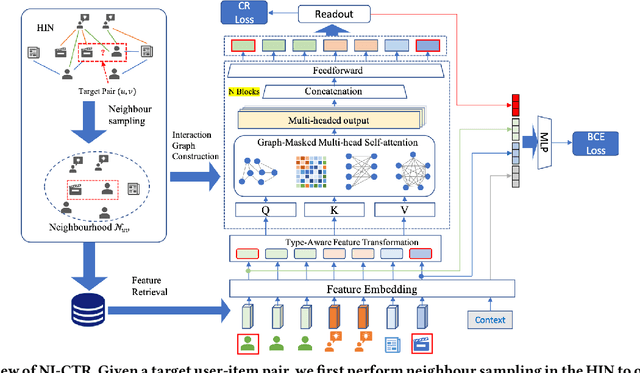
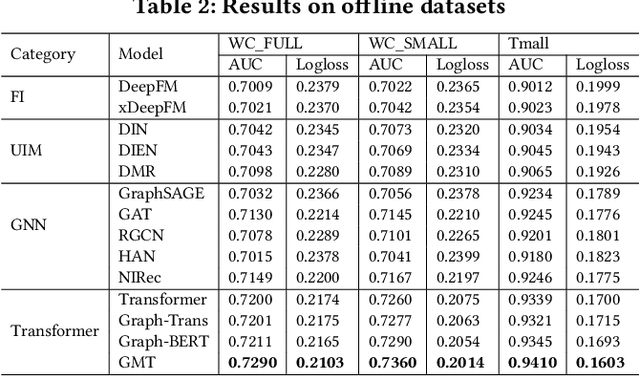
Click-Through Rate (CTR) prediction, is an essential component of online advertising. The mainstream techniques mostly focus on feature interaction or user interest modeling, which rely on users' directly interacted items. The performance of these methods are usally impeded by inactive behaviours and system's exposure, incurring that the features extracted do not contain enough information to represent all potential interests. For this sake, we propose Neighbor-Interaction based CTR prediction, which put this task into a Heterogeneous Information Network (HIN) setting, then involves local neighborhood of the target user-item pair in the HIN to predict their linkage. In order to enhance the representation of the local neighbourhood, we consider four types of topological interaction among the nodes, and propose a novel Graph-masked Transformer architecture to effectively incorporates both feature and topological information. We conduct comprehensive experiments on two real world datasets and the experimental results show that our proposed method outperforms state-of-the-art CTR models significantly.
Do Transformers Encode a Foundational Ontology? Probing Abstract Classes in Natural Language
Jan 25, 2022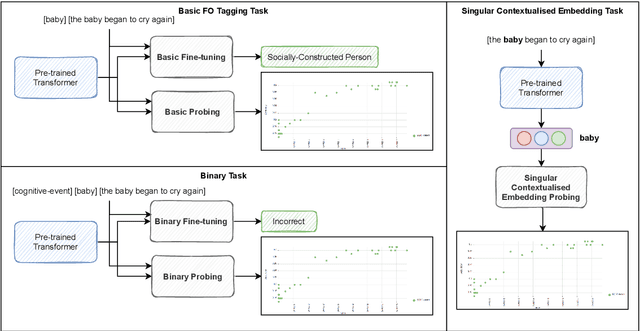
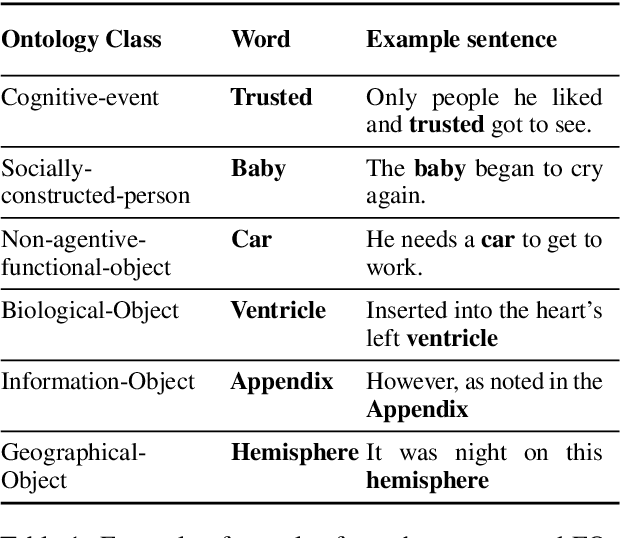

With the methodological support of probing (or diagnostic classification), recent studies have demonstrated that Transformers encode syntactic and semantic information to some extent. Following this line of research, this paper aims at taking semantic probing to an abstraction extreme with the goal of answering the following research question: can contemporary Transformer-based models reflect an underlying Foundational Ontology? To this end, we present a systematic Foundational Ontology (FO) probing methodology to investigate whether Transformers-based models encode abstract semantic information. Following different pre-training and fine-tuning regimes, we present an extensive evaluation of a diverse set of large-scale language models over three distinct and complementary FO tagging experiments. Specifically, we present and discuss the following conclusions: (1) The probing results indicate that Transformer-based models incidentally encode information related to Foundational Ontologies during the pre-training pro-cess; (2) Robust FO taggers (accuracy of 90 percent)can be efficiently built leveraging on this knowledge.
Translational Lung Imaging Analysis Through Disentangled Representations
Mar 03, 2022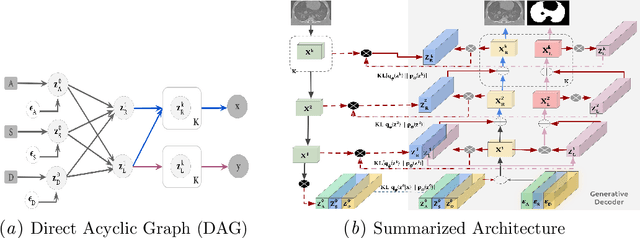
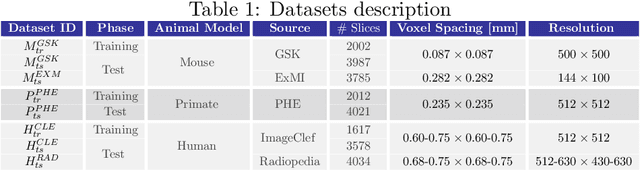
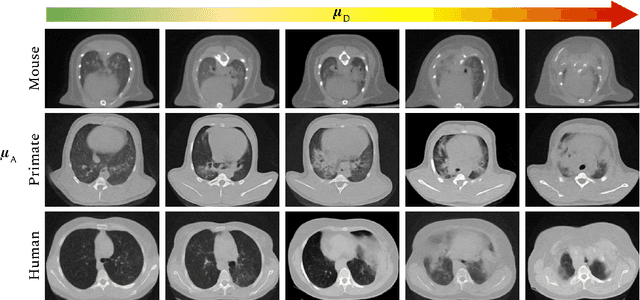

The development of new treatments often requires clinical trials with translational animal models using (pre)-clinical imaging to characterize inter-species pathological processes. Deep Learning (DL) models are commonly used to automate retrieving relevant information from the images. Nevertheless, they typically suffer from low generability and explainability as a product of their entangled design, resulting in a specific DL model per animal model. Consequently, it is not possible to take advantage of the high capacity of DL to discover statistical relationships from inter-species images. To alleviate this problem, in this work, we present a model capable of extracting disentangled information from images of different animal models and the mechanisms that generate the images. Our method is located at the intersection between deep generative models, disentanglement and causal representation learning. It is optimized from images of pathological lung infected by Tuberculosis and is able: a) from an input slice, infer its position in a volume, the animal model to which it belongs, the damage present and even more, generate a mask covering the whole lung (similar overlap measures to the nnU-Net), b) generate realistic lung images by setting the above variables and c) generate counterfactual images, namely, healthy versions of a damaged input slice.
Tag-Based Attention Guided Bottom-Up Approach for Video Instance Segmentation
Apr 22, 2022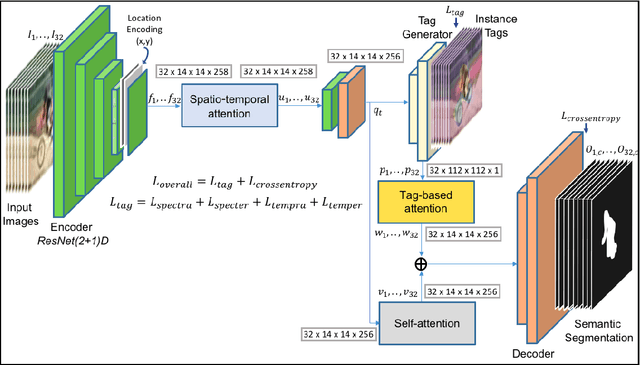
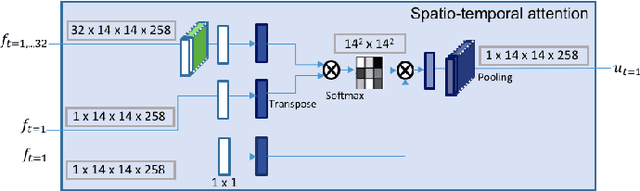
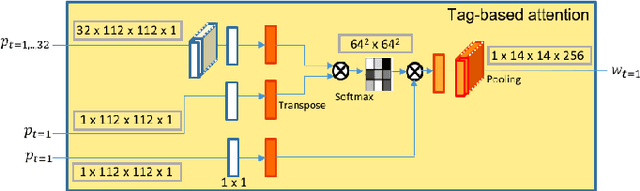
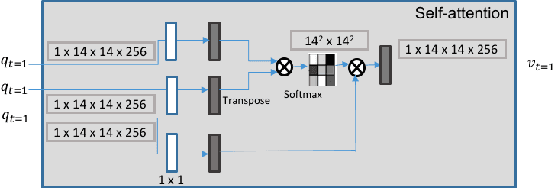
Video Instance Segmentation is a fundamental computer vision task that deals with segmenting and tracking object instances across a video sequence. Most existing methods typically accomplish this task by employing a multi-stage top-down approach that usually involves separate networks to detect and segment objects in each frame, followed by associating these detections in consecutive frames using a learned tracking head. In this work, however, we introduce a simple end-to-end trainable bottom-up approach to achieve instance mask predictions at the pixel-level granularity, instead of the typical region-proposals-based approach. Unlike contemporary frame-based models, our network pipeline processes an input video clip as a single 3D volume to incorporate temporal information. The central idea of our formulation is to solve the video instance segmentation task as a tag assignment problem, such that generating distinct tag values essentially separates individual object instances across the video sequence (here each tag could be any arbitrary value between 0 and 1). To this end, we propose a novel spatio-temporal tagging loss that allows for sufficient separation of different objects as well as necessary identification of different instances of the same object. Furthermore, we present a tag-based attention module that improves instance tags, while concurrently learning instance propagation within a video. Evaluations demonstrate that our method provides competitive results on YouTube-VIS and DAVIS-19 datasets, and has minimum run-time compared to other state-of-the-art performance methods.
Sparse Tensor-based Point Cloud Attribute Compression
Apr 03, 2022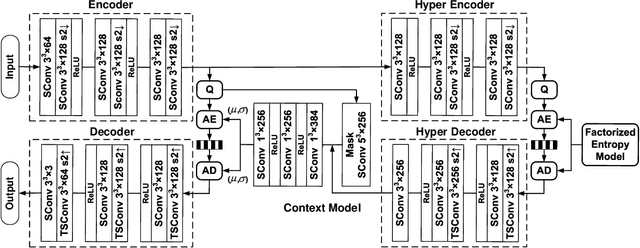


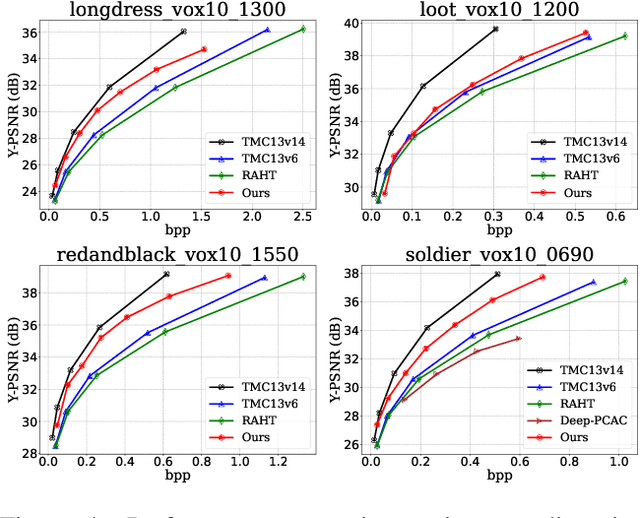
Recently, numerous learning-based compression methods have been developed with outstanding performance for the coding of the geometry information of point clouds. On the contrary, limited explorations have been devoted to point cloud attribute compression (PCAC). Thus, this study focuses on the PCAC by applying sparse convolution because of its superior efficiency for representing the geometry of unorganized points. The proposed method simply stacks sparse convolutions to construct the variational autoencoder (VAE) framework to compress the color attributes of a given point cloud. To better encode latent elements at the bottleneck, we apply the adaptive entropy model with the joint utilization of hyper prior and autoregressive neighbors to accurately estimate the bit rate. The qualitative measurement of the proposed method already rivals the latest G-PCC (or TMC13) version 14 at a similar bit rate. And, our method shows clear quantitative improvements to G-PCC version 6, and largely outperforms existing learning-based methods, which promises encouraging potentials for learnt PCAC.
Automatic Text Summarization Methods: A Comprehensive Review
Mar 03, 2022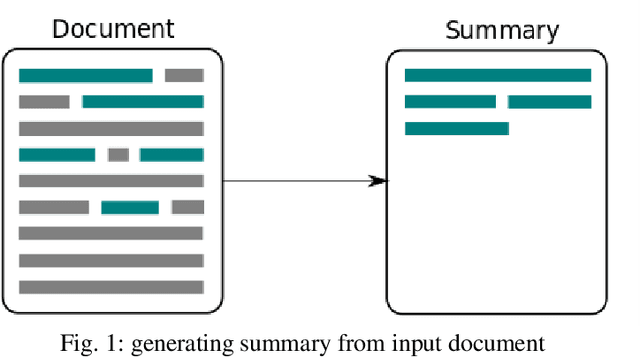
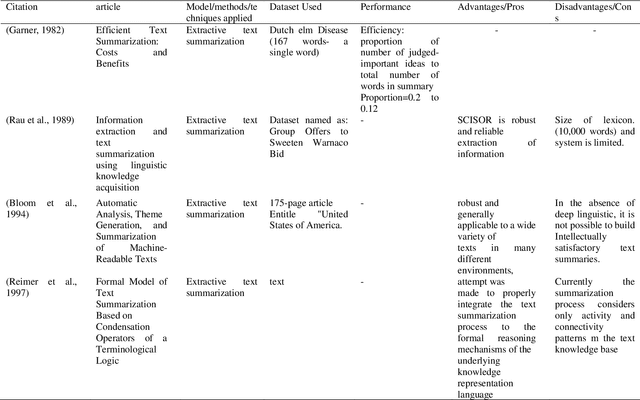
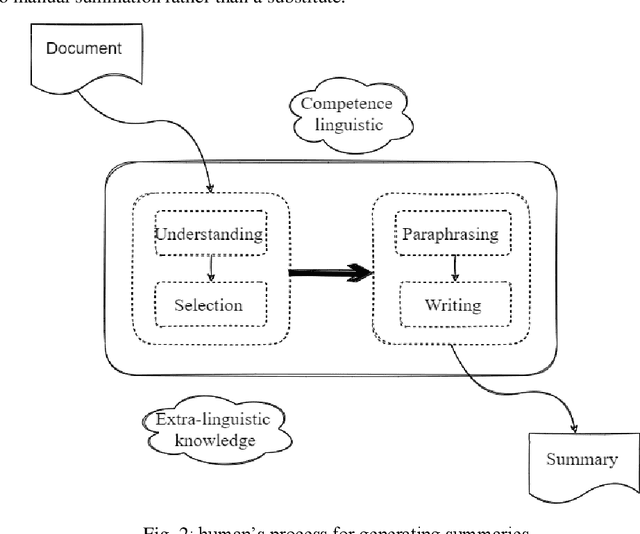
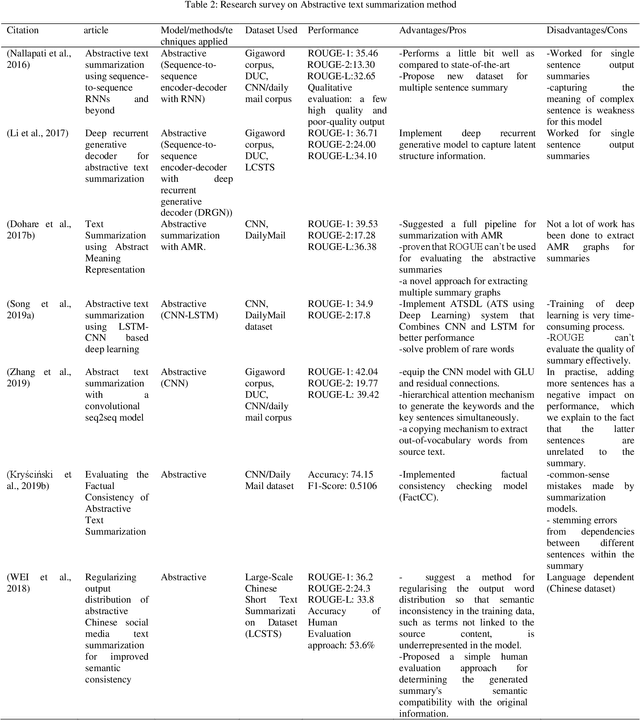
One of the most pressing issues that have arisen due to the rapid growth of the Internet is known as information overloading. Simplifying the relevant information in the form of a summary will assist many people because the material on any topic is plentiful on the Internet. Manually summarising massive amounts of text is quite challenging for humans. So, it has increased the need for more complex and powerful summarizers. Researchers have been trying to improve approaches for creating summaries since the 1950s, such that the machine-generated summary matches the human-created summary. This study provides a detailed state-of-the-art analysis of text summarization concepts such as summarization approaches, techniques used, standard datasets, evaluation metrics and future scopes for research. The most commonly accepted approaches are extractive and abstractive, studied in detail in this work. Evaluating the summary and increasing the development of reusable resources and infrastructure aids in comparing and replicating findings, adding competition to improve the outcomes. Different evaluation methods of generated summaries are also discussed in this study. Finally, at the end of this study, several challenges and research opportunities related to text summarization research are mentioned that may be useful for potential researchers working in this area.