 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SimMC: Simple Masked Contrastive Learning of Skeleton Representations for Unsupervised Person Re-Identification
Apr 28, 2022
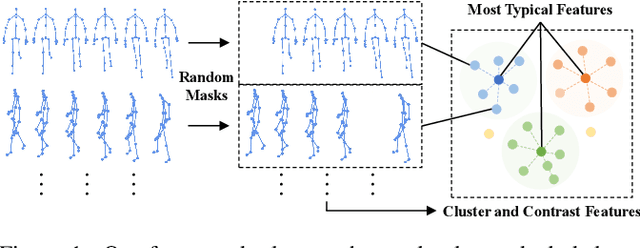
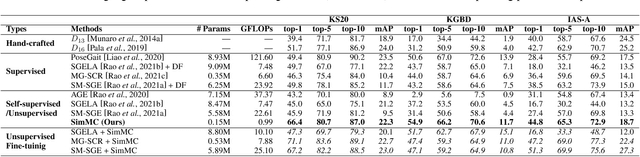
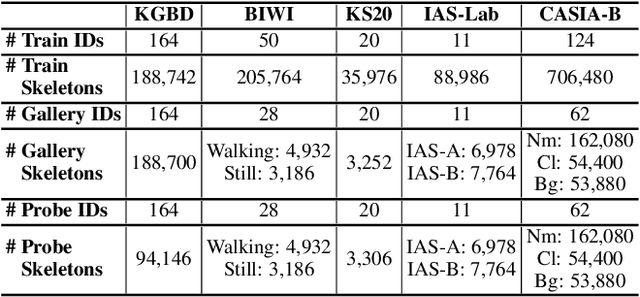
Recent advances in skeleton-based person re-identification (re-ID) obtain impressive performance via either hand-crafted skeleton descriptors or skeleton representation learning with deep learning paradigms. However, they typically require skeletal pre-modeling and label information for training, which leads to limited applicability of these methods. In this paper, we focus on unsupervised skeleton-based person re-ID, and present a generic Simple Masked Contrastive learning (SimMC) framework to learn effective representations from unlabeled 3D skeletons for person re-ID. Specifically, to fully exploit skeleton features within each skeleton sequence, we first devise a masked prototype contrastive learning (MPC) scheme to cluster the most typical skeleton features (skeleton prototypes) from different subsequences randomly masked from raw sequences, and contrast the inherent similarity between skeleton features and different prototypes to learn discriminative skeleton representations without using any label. Then, considering that different subsequences within the same sequence usually enjoy strong correlations due to the nature of motion continuity, we propose the masked intra-sequence contrastive learning (MIC) to capture intra-sequence pattern consistency between subsequences, so as to encourage learning more effective skeleton representations for person re-ID. Extensive experiments validate that the proposed SimMC outperforms most state-of-the-art skeleton-based methods. We further show its scalability and efficiency in enhancing the performance of existing models. Our codes are available at https://github.com/Kali-Hac/SimMC.
Privacy-Preserving Personalized Fitness Recommender System (P3FitRec): A Multi-level Deep Learning Approach
Mar 23, 2022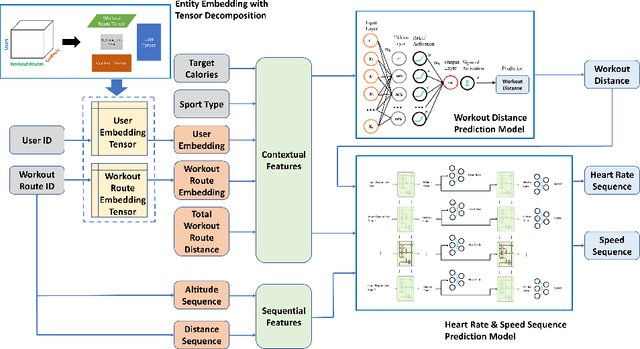
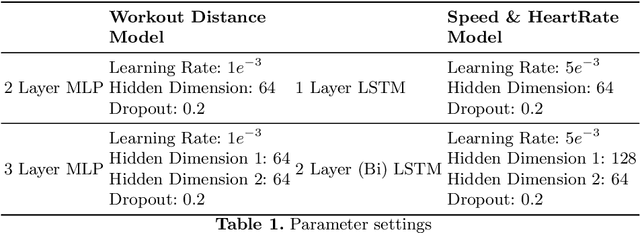
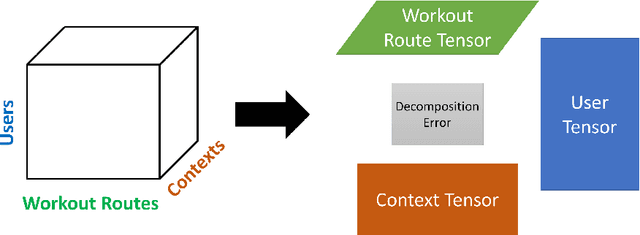
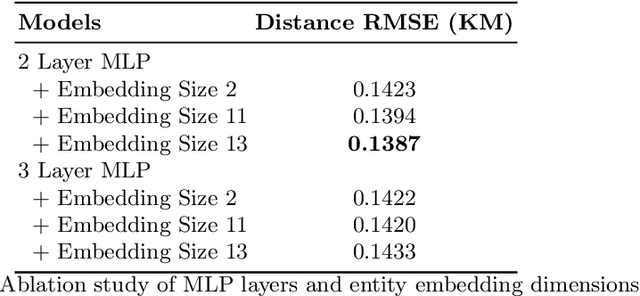
Recommender systems have been successfully used in many domains with the help of machine learning algorithms. However, such applications tend to use multi-dimensional user data, which has raised widespread concerns about the breach of users privacy. Meanwhile, wearable technologies have enabled users to collect fitness-related data through embedded sensors to monitor their conditions or achieve personalized fitness goals. In this paper, we propose a novel privacy-aware personalized fitness recommender system. We introduce a multi-level deep learning framework that learns important features from a large-scale real fitness dataset that is collected from wearable IoT devices to derive intelligent fitness recommendations. Unlike most existing approaches, our approach achieves personalization by inferring the fitness characteristics of users from sensory data and thus minimizing the need for explicitly collecting user identity or biometric information, such as name, age, height, weight. In particular, our proposed models and algorithms predict (a) personalized exercise distance recommendations to help users to achieve target calories, (b) personalized speed sequence recommendations to adjust exercise speed given the nature of the exercise and the chosen route, and (c) personalized heart rate sequence to guide the user of the potential health status for future exercises. Our experimental evaluation on a real-world Fitbit dataset demonstrated high accuracy in predicting exercise distance, speed sequence, and heart rate sequence compared to similar studies. Furthermore, our approach is novel compared to existing studies as it does not require collecting and using users sensitive information, and thus it preserves the users privacy.
A Graph-based approach to derive the geodesic distance on Statistical manifolds: Application to Multimedia Information Retrieval
Jun 26, 2021

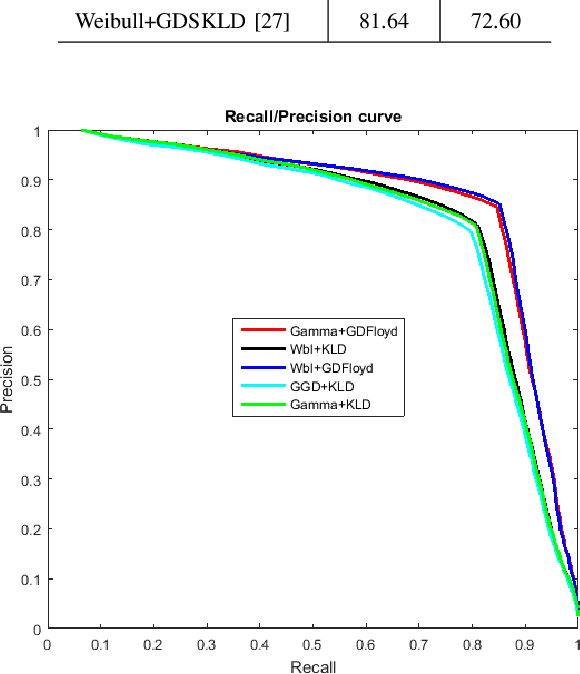
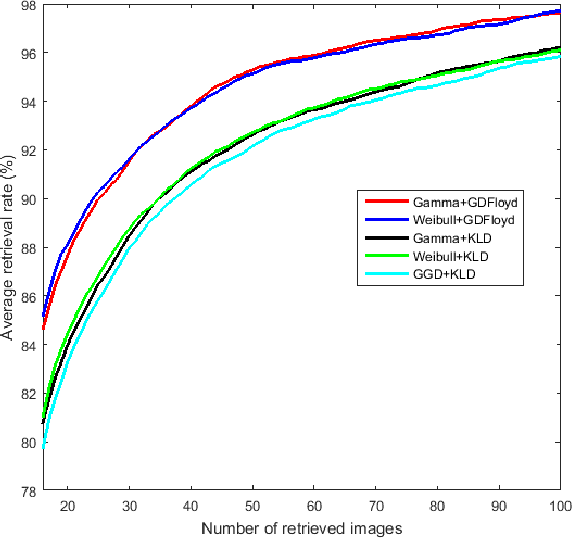
In this paper, we leverage the properties of non-Euclidean Geometry to define the Geodesic distance (GD) on the space of statistical manifolds. The Geodesic distance is a real and intuitive similarity measure that is a good alternative to the purely statistical and extensively used Kullback-Leibler divergence (KLD). Despite the effectiveness of the GD, a closed-form does not exist for many manifolds, since the geodesic equations are hard to solve. This explains that the major studies have been content to use numerical approximations. Nevertheless, most of those do not take account of the manifold properties, which leads to a loss of information and thus to low performances. We propose an approximation of the Geodesic distance through a graph-based method. This latter permits to well represent the structure of the statistical manifold, and respects its geometrical properties. Our main aim is to compare the graph-based approximation to the state of the art approximations. Thus, the proposed approach is evaluated for two statistical manifolds, namely the Weibull manifold and the Gamma manifold, considering the Content-Based Texture Retrieval application on different databases.
Effectively Using Long and Short Sessions for Multi-Session-based Recommendations
May 09, 2022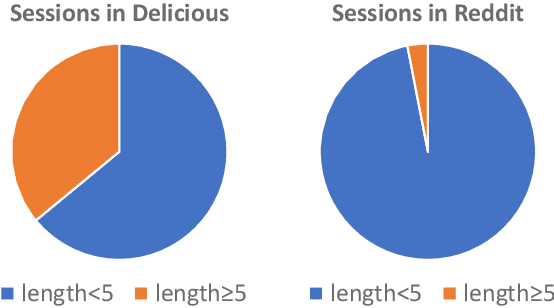
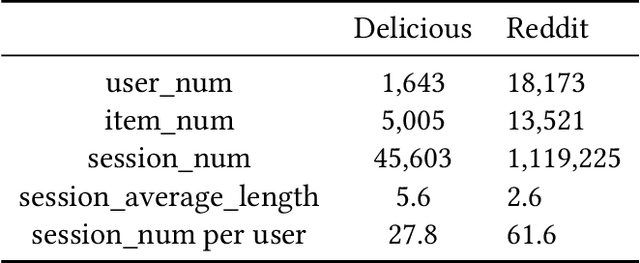
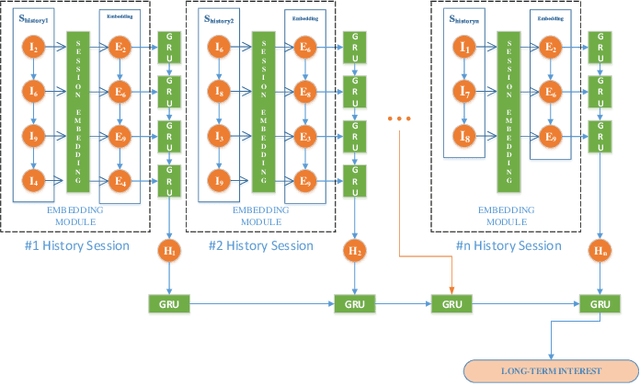
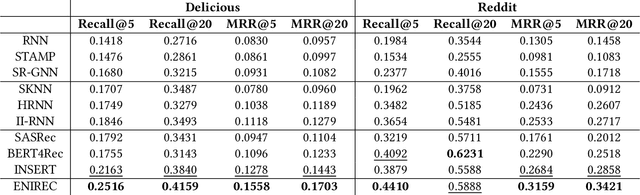
It is not accurate to make recommendations only based one single current session. Therefore, multi-session-based recommendation(MSBR) is a solution for the problem. Compared with the previous MSBR models, we have made three improvements in this paper. First, the previous work choose to use all the history sessions of the user and/or of his similar users. When the user's current interest changes greatly from the past, most of these sessions can only have negative impacts. Therefore, we select a large number of randomly chosen sessions from the dataset as candidate sessions to avoid over depending on history data. Then we only choose to use the most similar sessions to get the most useful information while reduce the noise caused by dissimilar sessions. Second, in real-world datasets, short sessions account for a large proportion. The RNN often used in previous work is not suitable to process short sessions, because RNN only focuses on the sequential relationship, which we find is not the only relationship between items in short sessions. So, we designed a more suitable method named GAFE based on attention to process short sessions. Third, Although there are few long sessions, they can not be ignored. Not like previous models, which simply process long sessions in the same way as short sessions, we propose LSIS, which can split the interest of long sessions, to make better use of long sessions. Finally, to help recommendations, we also have considered users' long-term interests captured by a multi-layer GRU. Considering the four points above, we built the model ENIREC. Experiments on two real-world datasets show that the comprehensive performance of ENIREC is better than other existing models.
Exploring the Impact of Negative Samples of Contrastive Learning: A Case Study of Sentence Embedding
Mar 16, 2022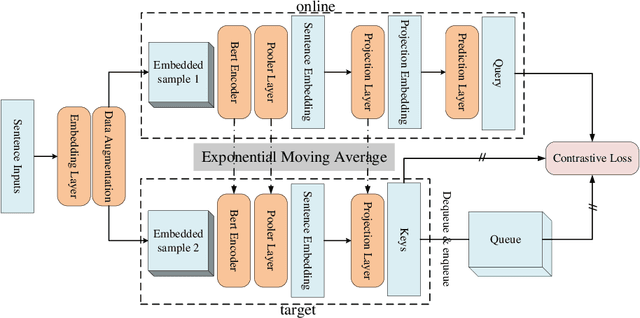
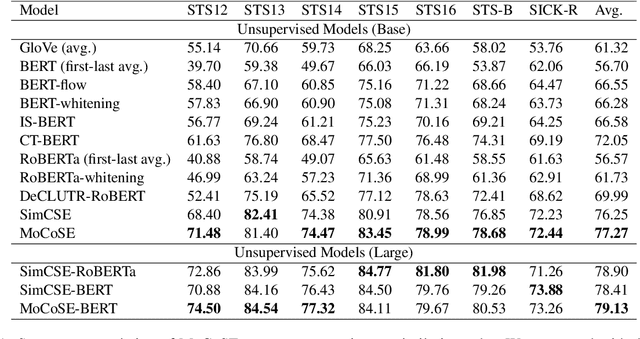
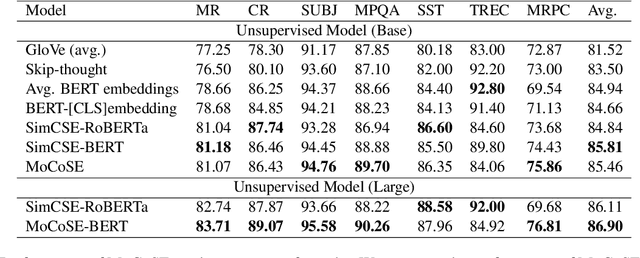
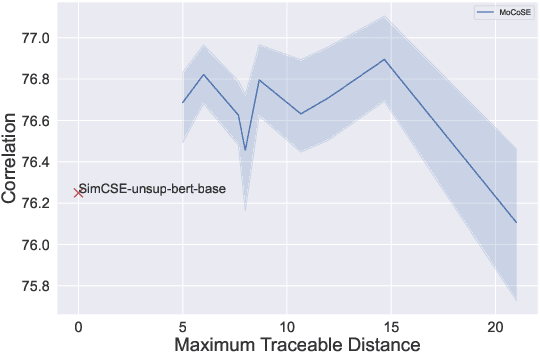
Contrastive learning is emerging as a powerful technique for extracting knowledge from unlabeled data. This technique requires a balanced mixture of two ingredients: positive (similar) and negative (dissimilar) samples. This is typically achieved by maintaining a queue of negative samples during training. Prior works in the area typically uses a fixed-length negative sample queue, but how the negative sample size affects the model performance remains unclear. The opaque impact of the number of negative samples on performance when employing contrastive learning aroused our in-depth exploration. This paper presents a momentum contrastive learning model with negative sample queue for sentence embedding, namely MoCoSE. We add the prediction layer to the online branch to make the model asymmetric and together with EMA update mechanism of the target branch to prevent the model from collapsing. We define a maximum traceable distance metric, through which we learn to what extent the text contrastive learning benefits from the historical information of negative samples. Our experiments find that the best results are obtained when the maximum traceable distance is at a certain range, demonstrating that there is an optimal range of historical information for a negative sample queue. We evaluate the proposed unsupervised MoCoSE on the semantic text similarity (STS) task and obtain an average Spearman's correlation of $77.27\%$. Source code is available at https://github.com/xbdxwyh/mocose.
TASTEset -- Recipe Dataset and Food Entities Recognition Benchmark
Apr 16, 2022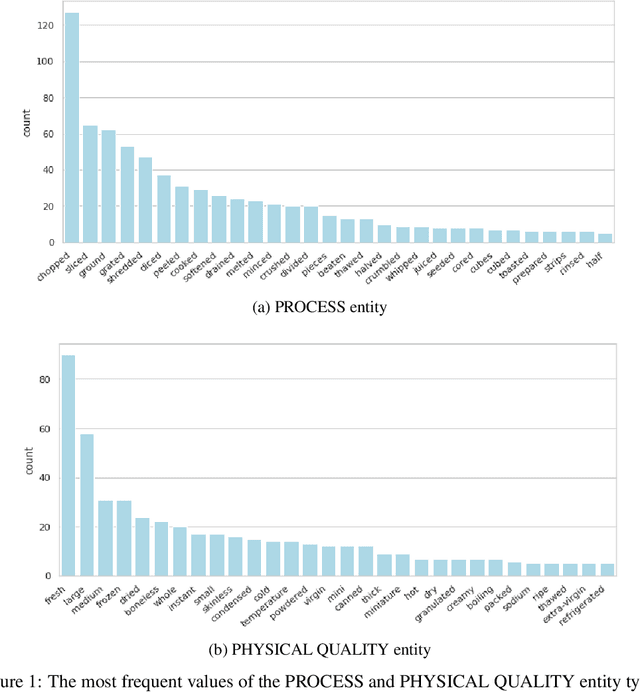
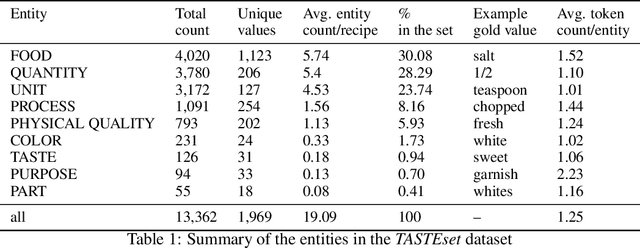
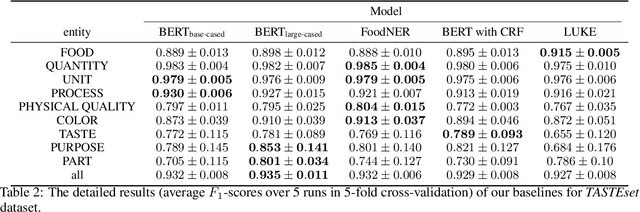
Food Computing is currently a fast-growing field of research. Natural language processing (NLP) is also increasingly essential in this field, especially for recognising food entities. However, there are still only a few well-defined tasks that serve as benchmarks for solutions in this area. We introduce a new dataset -- called \textit{TASTEset} -- to bridge this gap. In this dataset, Named Entity Recognition (NER) models are expected to find or infer various types of entities helpful in processing recipes, e.g.~food products, quantities and their units, names of cooking processes, physical quality of ingredients, their purpose, taste. The dataset consists of 700 recipes with more than 13,000 entities to extract. We provide a few state-of-the-art baselines of named entity recognition models, which show that our dataset poses a solid challenge to existing models. The best model achieved, on average, 0.95 $F_1$ score, depending on the entity type -- from 0.781 to 0.982. We share the dataset and the task to encourage progress on more in-depth and complex information extraction from recipes.
Epistemic AI platform accelerates innovation by connecting biomedical knowledge
Jan 30, 2022

Epistemic AI accelerates biomedical discovery by finding hidden connections in the network of biomedical knowledge. The Epistemic AI web-based software platform embodies the concept of knowledge mapping, an interactive process that relies on a knowledge graph in combination with natural language processing (NLP), information retrieval, relevance feedback, and network analysis. Knowledge mapping reduces information overload, prevents costly mistakes, and minimizes missed opportunities in the research process. The platform combines state-of-the-art methods for information extraction with machine learning, artificial intelligence and network analysis. Starting from a single biological entity, such as a gene or disease, users may: a) construct a map of connections to that entity, b) map an entire domain of interest, and c) gain insight into large biological networks of knowledge. Knowledge maps provide clarity and organization, simplifying the day-to-day research processes.
Traffic Context Aware Data Augmentation for Rare Object Detection in Autonomous Driving
May 01, 2022
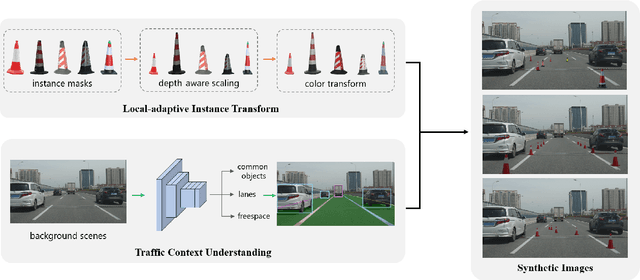


Detection of rare objects (e.g., traffic cones, traffic barrels and traffic warning triangles) is an important perception task to improve the safety of autonomous driving. Training of such models typically requires a large number of annotated data which is expensive and time consuming to obtain. To address the above problem, an emerging approach is to apply data augmentation to automatically generate cost-free training samples. In this work, we propose a systematic study on simple Copy-Paste data augmentation for rare object detection in autonomous driving. Specifically, local adaptive instance-level image transformation is introduced to generate realistic rare object masks from source domain to the target domain. Moreover, traffic scene context is utilized to guide the placement of masks of rare objects. To this end, our data augmentation generates training data with high quality and realistic characteristics by leveraging both local and global consistency. In addition, we build a new dataset named NM10k consisting 10k training images, 4k validation images and the corresponding labels with a diverse range of scenarios in autonomous driving. Experiments on NM10k show that our method achieves promising results on rare object detection. We also present a thorough study to illustrate the effectiveness of our local-adaptive and global constraints based Copy-Paste data augmentation for rare object detection. The data, development kit and more information of NM10k dataset are available online at: \url{https://nullmax-vision.github.io}.
Improving Robustness to Model Inversion Attacks via Mutual Information Regularization
Sep 11, 2020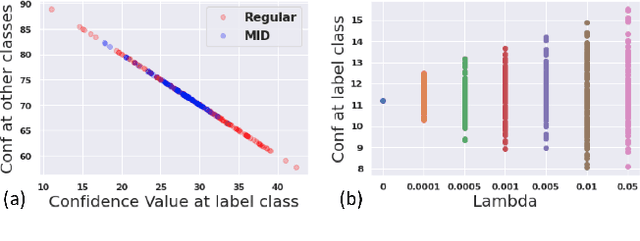


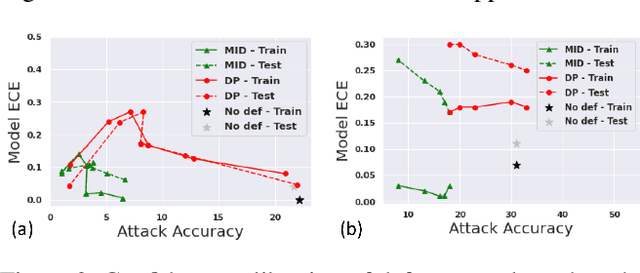
This paper studies defense mechanisms against model inversion (MI) attacks -- a type of privacy attacks aimed at inferring information about the training data distribution given the access to a target machine learning model. Existing defense mechanisms rely on model-specific heuristics or noise injection. While being able to mitigate attacks, existing methods significantly hinder model performance. There remains a question of how to design a defense mechanism that is applicable to a variety of models and achieves better utility-privacy tradeoff. In this paper, we propose the Mutual Information Regularization based Defense (MID) against MI attacks. The key idea is to limit the information about the model input contained in the prediction, thereby limiting the ability of an adversary to infer the private training attributes from the model prediction. Our defense principle is model-agnostic and we present tractable approximations to the regularizer for linear regression, decision trees, and neural networks, which have been successfully attacked by prior work if not attached with any defenses. We present a formal study of MI attacks by devising a rigorous game-based definition and quantifying the associated information leakage. Our theoretical analysis sheds light on the inefficacy of DP in defending against MI attacks, which has been empirically observed in several prior works. Our experiments demonstrate that MID leads to state-of-the-art performance for a variety of MI attacks, target models and datasets.
2D LiDAR and Camera Fusion Using Motion Cues for Indoor Layout Estimation
Apr 24, 2022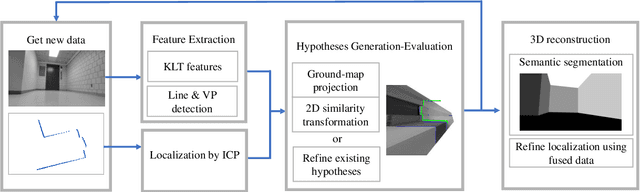


This paper presents a novel indoor layout estimation system based on the fusion of 2D LiDAR and intensity camera data. A ground robot explores an indoor space with a single floor and vertical walls, and collects a sequence of intensity images and 2D LiDAR datasets. The LiDAR provides accurate depth information, while the camera captures high-resolution data for semantic interpretation. The alignment of sensor outputs and image segmentation are computed jointly by aligning LiDAR points, as samples of the room contour, to ground-wall boundaries in the images. The alignment problem is decoupled into a top-down view projection and a 2D similarity transformation estimation, which can be solved according to the vertical vanishing point and motion of two sensors. The recursive random sample consensus algorithm is implemented to generate, evaluate and optimize multiple hypotheses with the sequential measurements. The system allows jointly analyzing the geometric interpretation from different sensors without offline calibration. The ambiguity in images for ground-wall boundary extraction is removed with the assistance of LiDAR observations, which improves the accuracy of semantic segmentation. The localization and mapping is refined using the fused data, which enables the system to work reliably in scenes with low texture or low geometric features.