 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decision-Dependent Risk Minimization in Geometrically Decaying Dynamic Environments
Apr 08, 2022
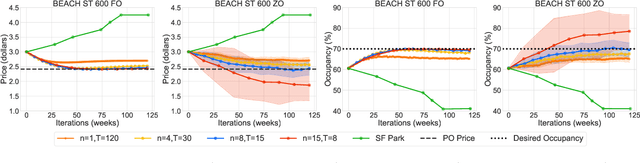

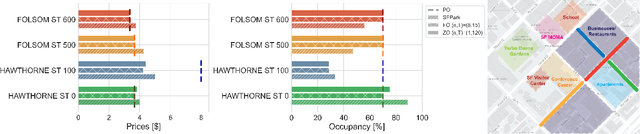
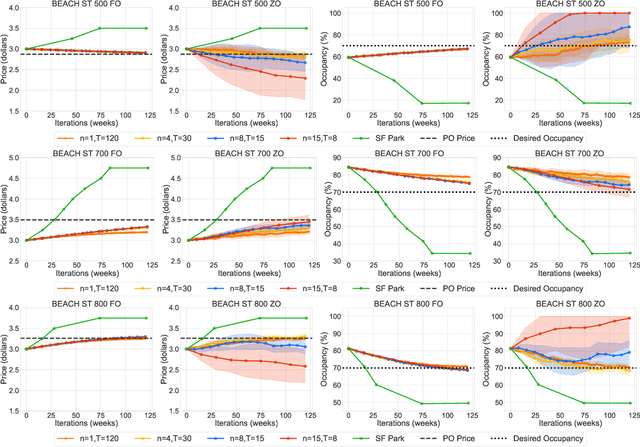
This paper studies the problem of expected loss minimization given a data distribution that is dependent on the decision-maker's action and evolves dynamically in time according to a geometric decay process. Novel algorithms for both the information setting in which the decision-maker has a first order gradient oracle and the setting in which they have simply a loss function oracle are introduced. The algorithms operate on the same underlying principle: the decision-maker repeatedly deploys a fixed decision over the length of an epoch, thereby allowing the dynamically changing environment to sufficiently mix before updating the decision. The iteration complexity in each of the settings is shown to match existing rates for first and zero order stochastic gradient methods up to logarithmic factors. The algorithms are evaluated on a "semi-synthetic" example using real world data from the SFpark dynamic pricing pilot study; it is shown that the announced prices result in an improvement for the institution's objective (target occupancy), while achieving an overall reduction in parking rates.
Progressive Subsampling for Oversampled Data -- Application to Quantitative MRI
Apr 08, 2022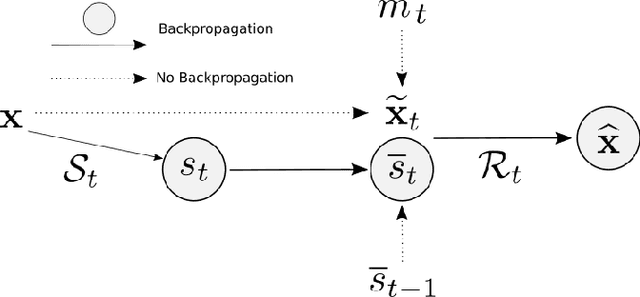
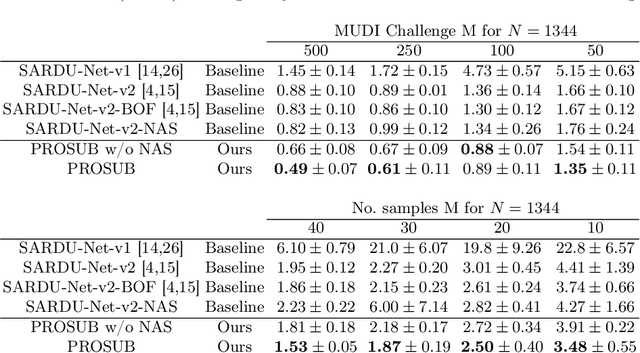
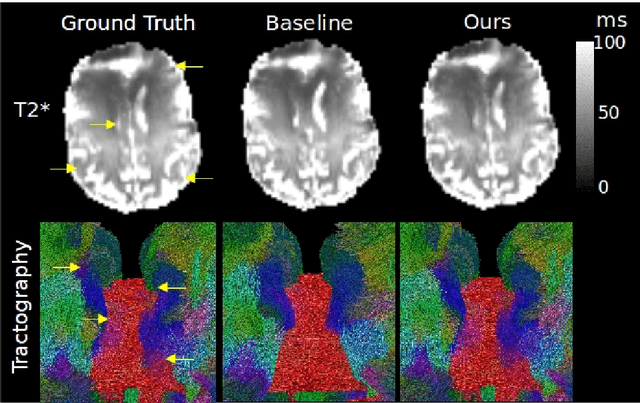
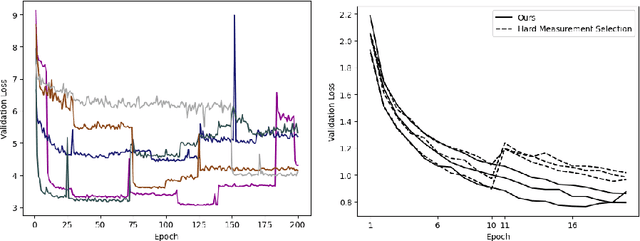
We present PROSUB: PROgressive SUBsampling, a deep learning based, automated methodology that subsamples an oversampled data set (e.g. multi-channeled 3D images) with minimal loss of information. We build upon a recent dual-network approach that won the MICCAI MUlti-DIffusion (MUDI) quantitative MRI measurement sampling-reconstruction challenge, but suffers from deep learning training instability, by subsampling with a hard decision boundary. PROSUB uses the paradigm of recursive feature elimination (RFE) and progressively subsamples measurements during deep learning training, improving optimization stability. PROSUB also integrates a neural architecture search (NAS) paradigm, allowing the network architecture hyperparameters to respond to the subsampling process. We show PROSUB outperforms the winner of the MUDI MICCAI challenge, producing large improvements >18% MSE on the MUDI challenge sub-tasks and qualitative improvements on downstream processes useful for clinical applications. We also show the benefits of incorporating NAS and analyze the effect of PROSUB's components. As our method generalizes to other problems beyond MRI measurement selection-reconstruction, our code is https://github.com/sbb-gh/PROSUB
Low-rank features based double transformation matrices learning for image classification
Feb 17, 2022Linear regression is a supervised method that has been widely used in classification tasks. In order to apply linear regression to classification tasks, a technique for relaxing regression targets was proposed. However, methods based on this technique ignore the pressure on a single transformation matrix due to the complex information contained in the data. A single transformation matrix in this case is too strict to provide a flexible projection, thus it is necessary to adopt relaxation on transformation matrix. This paper proposes a double transformation matrices learning method based on latent low-rank feature extraction. The core idea is to use double transformation matrices for relaxation, and jointly projecting the learned principal and salient features from two directions into the label space, which can share the pressure of a single transformation matrix. Firstly, the low-rank features are learned by the latent low rank representation (LatLRR) method which processes the original data from two directions. In this process, sparse noise is also separated, which alleviates its interference on projection learning to some extent. Then, two transformation matrices are introduced to process the two features separately, and the information useful for the classification is extracted. Finally, the two transformation matrices can be easily obtained by alternate optimization methods. Through such processing, even when a large amount of redundant information is contained in samples, our method can also obtain projection results that are easy to classify. Experiments on multiple data sets demonstrate the effectiveness of our approach for classification, especially for complex scenarios.
MAT: Mask-Aware Transformer for Large Hole Image Inpainting
Mar 30, 2022



Recent studies have shown the importance of modeling long-range interactions in the inpainting problem. To achieve this goal, existing approaches exploit either standalone attention techniques or transformers, but usually under a low resolution in consideration of computational cost. In this paper, we present a novel transformer-based model for large hole inpainting, which unifies the merits of transformers and convolutions to efficiently process high-resolution images. We carefully design each component of our framework to guarantee the high fidelity and diversity of recovered images. Specifically, we customize an inpainting-oriented transformer block, where the attention module aggregates non-local information only from partial valid tokens, indicated by a dynamic mask. Extensive experiments demonstrate the state-of-the-art performance of the new model on multiple benchmark datasets. Code is released at https://github.com/fenglinglwb/MAT.
Connect, Not Collapse: Explaining Contrastive Learning for Unsupervised Domain Adaptation
Apr 01, 2022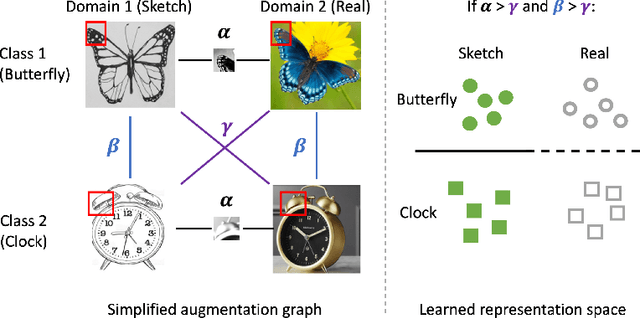
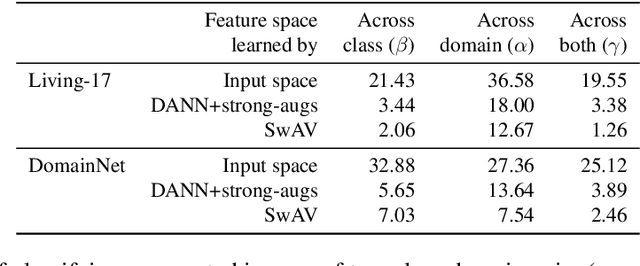
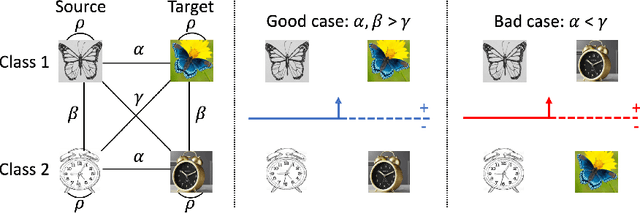

We consider unsupervised domain adaptation (UDA), where labeled data from a source domain (e.g., photographs) and unlabeled data from a target domain (e.g., sketches) are used to learn a classifier for the target domain. Conventional UDA methods (e.g., domain adversarial training) learn domain-invariant features to improve generalization to the target domain. In this paper, we show that contrastive pre-training, which learns features on unlabeled source and target data and then fine-tunes on labeled source data, is competitive with strong UDA methods. However, we find that contrastive pre-training does not learn domain-invariant features, diverging from conventional UDA intuitions. We show theoretically that contrastive pre-training can learn features that vary subtantially across domains but still generalize to the target domain, by disentangling domain and class information. Our results suggest that domain invariance is not necessary for UDA. We empirically validate our theory on benchmark vision datasets.
Attentive Temporal Pooling for Conformer-based Streaming Language Identification in Long-form Speech
Mar 21, 2022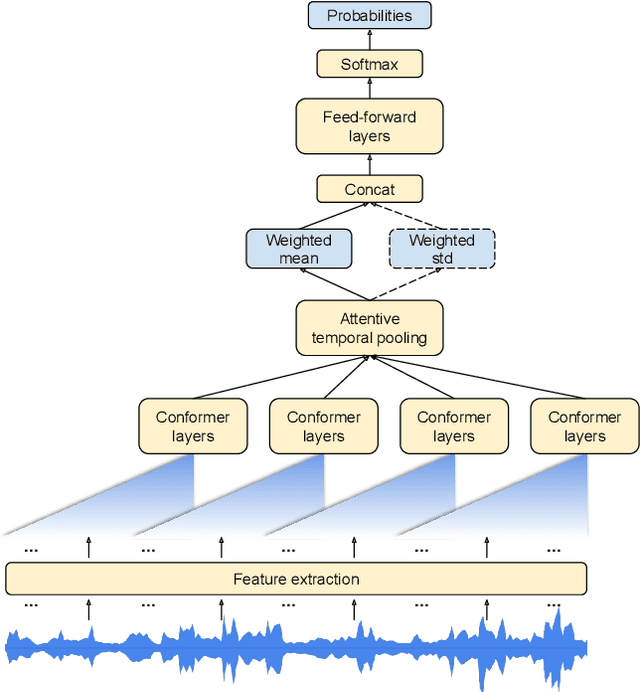
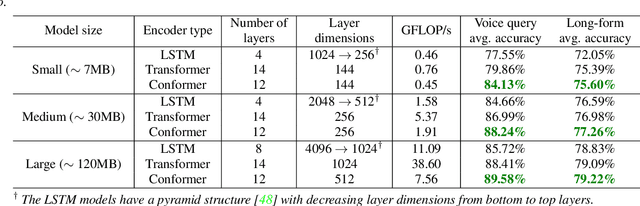
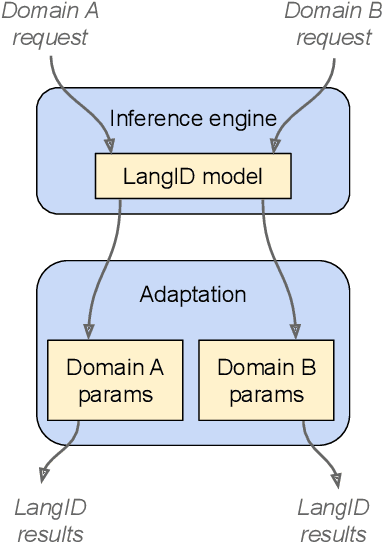
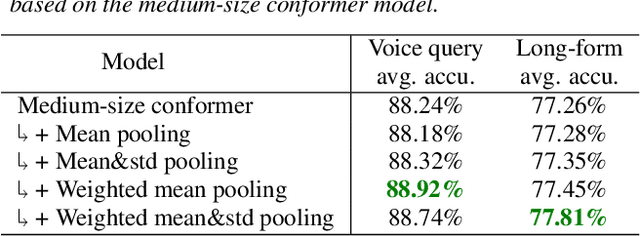
In this paper, we introduce a novel language identification system based on conformer layers. We propose an attentive temporal pooling mechanism to allow the model to carry information in long-form audio via a recurrent form, such that the inference can be performed in a streaming fashion. Additionally, a simple domain adaptation mechanism is introduced to allow adapting an existing language identification model to a new domain where the prior language distribution is different. We perform a comparative study of different model topologies under different constraints of model size, and find that conformer-base models outperform LSTM and transformer based models. Our experiments also show that attentive temporal pooling and domain adaptation significantly improve the model accuracy.
RadioTransformer: A Cascaded Global-Focal Transformer for Visual Attention-guided Disease Classification
Feb 23, 2022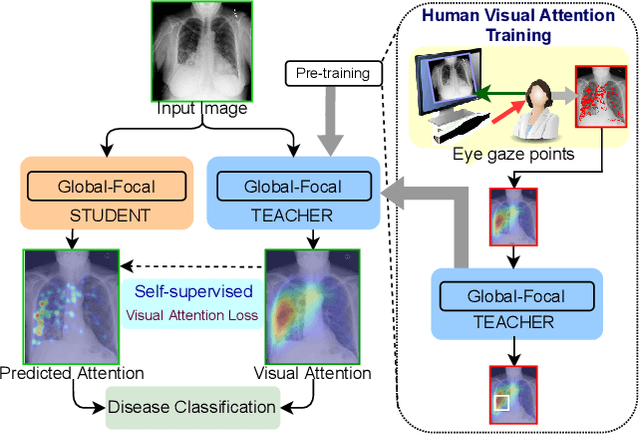

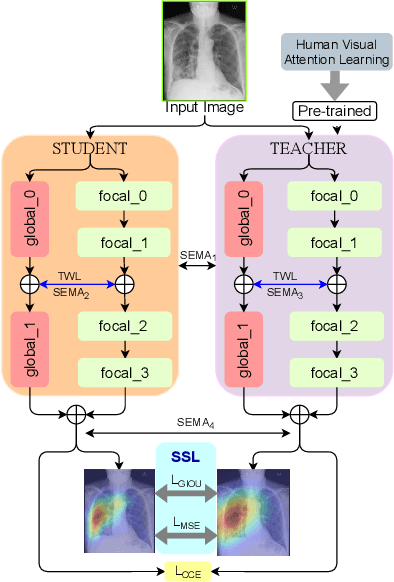
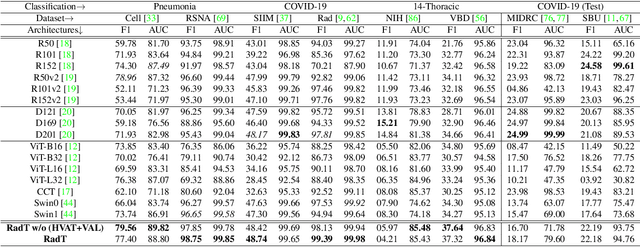
In this work, we present RadioTransformer, a novel visual attention-driven transformer framework, that leverages radiologists' gaze patterns and models their visuo-cognitive behavior for disease diagnosis on chest radiographs. Domain experts, such as radiologists, rely on visual information for medical image interpretation. On the other hand, deep neural networks have demonstrated significant promise in similar tasks even where visual interpretation is challenging. Eye-gaze tracking has been used to capture the viewing behavior of domain experts, lending insights into the complexity of visual search. However, deep learning frameworks, even those that rely on attention mechanisms, do not leverage this rich domain information. RadioTransformer fills this critical gap by learning from radiologists' visual search patterns, encoded as 'human visual attention regions' in a cascaded global-focal transformer framework. The overall 'global' image characteristics and the more detailed 'local' features are captured by the proposed global and focal modules, respectively. We experimentally validate the efficacy of our student-teacher approach for 8 datasets involving different disease classification tasks where eye-gaze data is not available during the inference phase.
Fine-tuning Image Transformers using Learnable Memory
Mar 30, 2022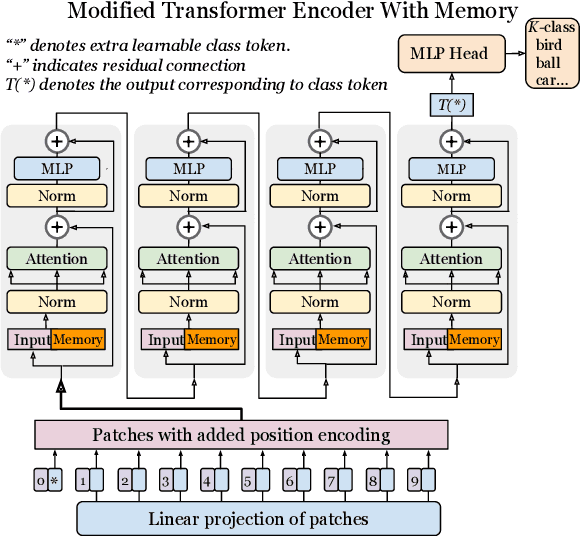
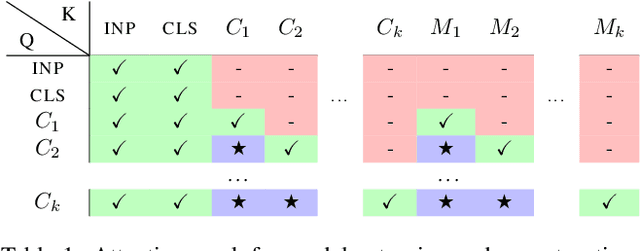
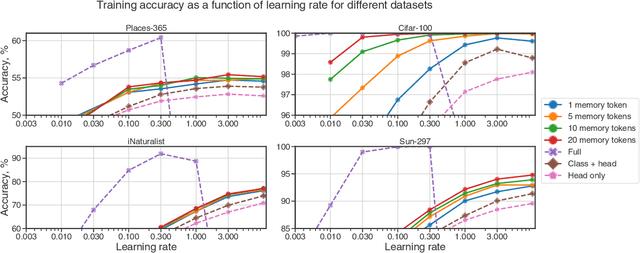
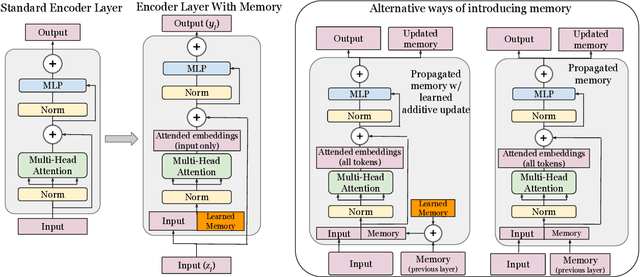
In this paper we propose augmenting Vision Transformer models with learnable memory tokens. Our approach allows the model to adapt to new tasks, using few parameters, while optionally preserving its capabilities on previously learned tasks. At each layer we introduce a set of learnable embedding vectors that provide contextual information useful for specific datasets. We call these "memory tokens". We show that augmenting a model with just a handful of such tokens per layer significantly improves accuracy when compared to conventional head-only fine-tuning, and performs only slightly below the significantly more expensive full fine-tuning. We then propose an attention-masking approach that enables extension to new downstream tasks, with a computation reuse. In this setup in addition to being parameters efficient, models can execute both old and new tasks as a part of single inference at a small incremental cost.
KCD: Knowledge Walks and Textual Cues Enhanced Political Perspective Detection in News Media
Apr 08, 2022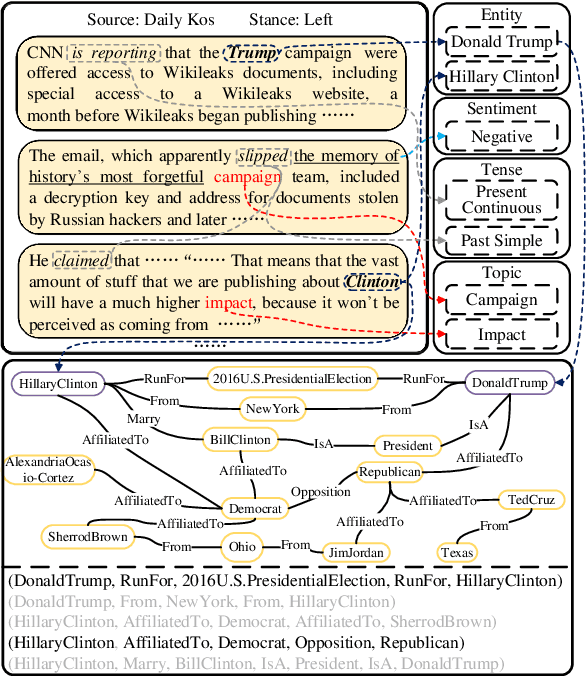
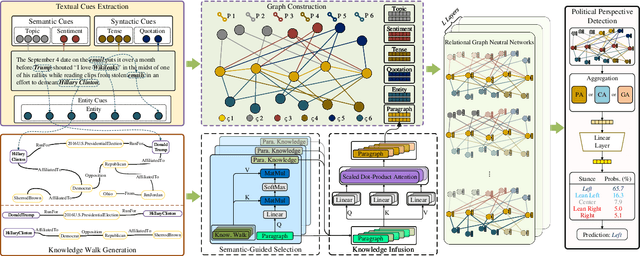
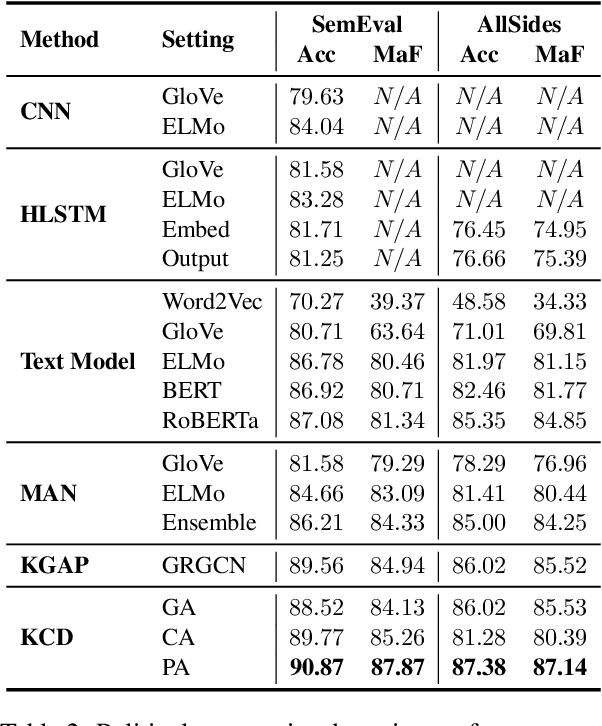
Political perspective detection has become an increasingly important task that can help combat echo chambers and political polarization. Previous approaches generally focus on leveraging textual content to identify stances, while they fail to reason with background knowledge or leverage the rich semantic and syntactic textual labels in news articles. In light of these limitations, we propose KCD, a political perspective detection approach to enable multi-hop knowledge reasoning and incorporate textual cues as paragraph-level labels. Specifically, we firstly generate random walks on external knowledge graphs and infuse them with news text representations. We then construct a heterogeneous information network to jointly model news content as well as semantic, syntactic and entity cues in news articles. Finally, we adopt relational graph neural networks for graph-level representation learning and conduct political perspective detection. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods on two benchmark datasets. We further examine the effect of knowledge walks and textual cues and how they contribute to our approach's data efficiency.
Fisher Information Field: an Efficient and Differentiable Map for Perception-aware Planning
Aug 07, 2020



Considering visual localization accuracy at the planning time gives preference to robot motion that can be better localized and thus has the potential of improving vision-based navigation, especially in visually degraded environments. To integrate the knowledge about localization accuracy in motion planning algorithms, a central task is to quantify the amount of information that an image taken at a 6 degree-of-freedom pose brings for localization, which is often represented by the Fisher information. However, computing the Fisher information from a set of sparse landmarks (i.e., a point cloud), which is the most common map for visual localization, is inefficient. This approach scales linearly with the number of landmarks in the environment and does not allow the reuse of the computed Fisher information. To overcome these drawbacks, we propose the first dedicated map representation for evaluating the Fisher information of 6 degree-of-freedom visual localization for perception-aware motion planning. By formulating the Fisher information and sensor visibility carefully, we are able to separate the rotational invariant component from the Fisher information and store it in a voxel grid, namely the Fisher information field. This step only needs to be performed once for a known environment. The Fisher information for arbitrary poses can then be computed from the field in constant time, eliminating the need of costly iterating all the 3D landmarks at the planning time. Experimental results show that the proposed Fisher information field can be applied to different motion planning algorithms and is at least one order-of-magnitude faster than using the point cloud directly. Moreover,the proposed map representation is differentiable, resulting in better performance than the point cloud when used in trajectory optimization algorithms.