 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OPD: Single-view 3D Openable Part Detection
Mar 30, 2022
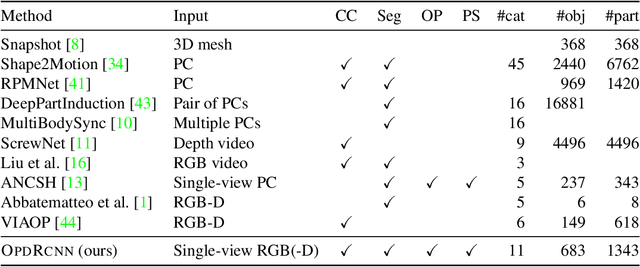

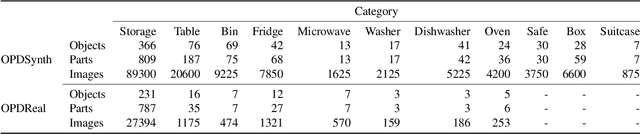
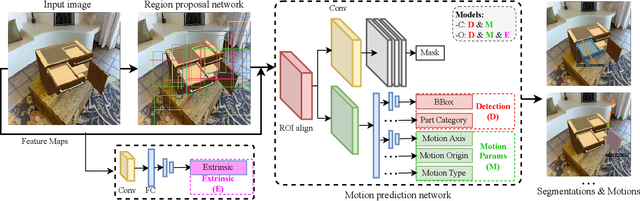
We address the task of predicting what parts of an object can open and how they move when they do so. The input is a single image of an object, and as output we detect what parts of the object can open, and the motion parameters describing the articulation of each openable part. To tackle this task, we create two datasets of 3D objects: OPDSynth based on existing synthetic objects, and OPDReal based on RGBD reconstructions of real objects. We then design OPDRCNN, a neural architecture that detects openable parts and predicts their motion parameters. Our experiments show that this is a challenging task especially when considering generalization across object categories, and the limited amount of information in a single image. Our architecture outperforms baselines and prior work especially for RGB image inputs. Short video summary at https://www.youtube.com/watch?v=P85iCaD0rfc
On-Device Next-Item Recommendation with Self-Supervised Knowledge Distillation
Apr 23, 2022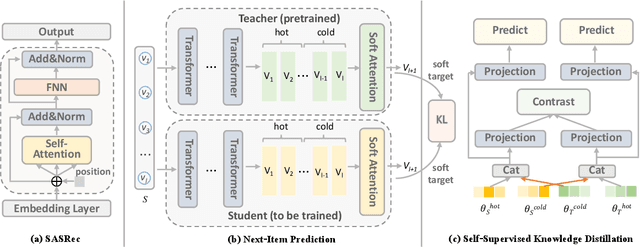
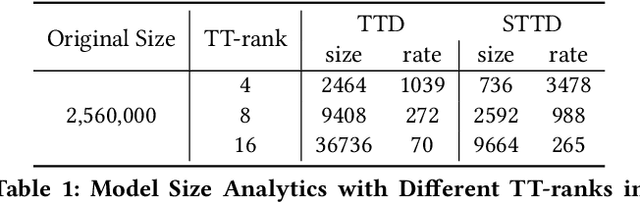
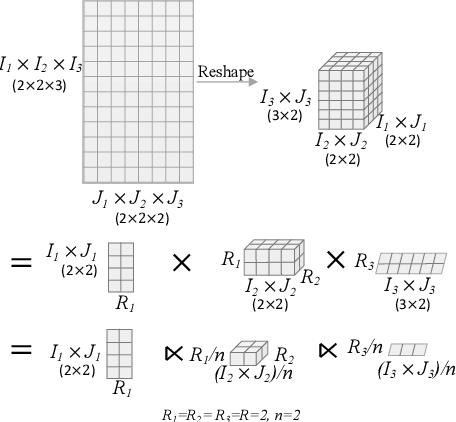

Modern recommender systems operate in a fully server-based fashion. To cater to millions of users, the frequent model maintaining and the high-speed processing for concurrent user requests are required, which comes at the cost of a huge carbon footprint. Meanwhile, users need to upload their behavior data even including the immediate environmental context to the server, raising the public concern about privacy. On-device recommender systems circumvent these two issues with cost-conscious settings and local inference. However, due to the limited memory and computing resources, on-device recommender systems are confronted with two fundamental challenges: (1) how to reduce the size of regular models to fit edge devices? (2) how to retain the original capacity? Previous research mostly adopts tensor decomposition techniques to compress the regular recommendation model with limited compression ratio so as to avoid drastic performance degradation. In this paper, we explore ultra-compact models for next-item recommendation, by loosing the constraint of dimensionality consistency in tensor decomposition. Meanwhile, to compensate for the capacity loss caused by compression, we develop a self-supervised knowledge distillation framework which enables the compressed model (student) to distill the essential information lying in the raw data, and improves the long-tail item recommendation through an embedding-recombination strategy with the original model (teacher). The extensive experiments on two benchmarks demonstrate that, with 30x model size reduction, the compressed model almost comes with no accuracy loss, and even outperforms its uncompressed counterpart in most cases.
Multi-Modal Hypergraph Diffusion Network with Dual Prior for Alzheimer Classification
Apr 04, 2022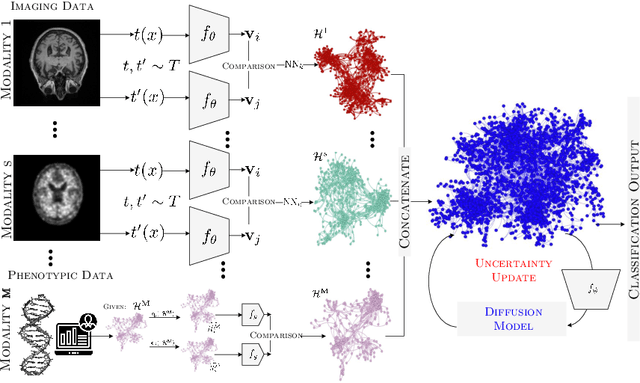
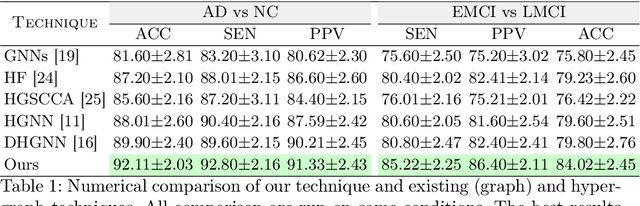
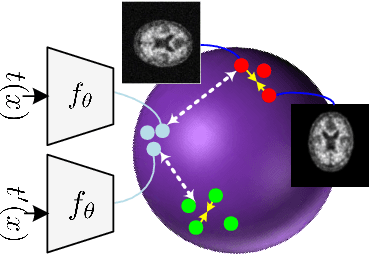
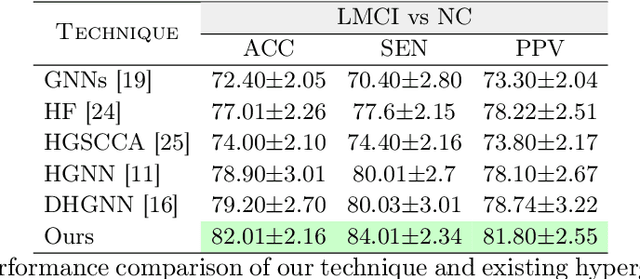
The automatic early diagnosis of prodromal stages of Alzheimer's disease is of great relevance for patient treatment to improve quality of life. We address this problem as a multi-modal classification task. Multi-modal data provides richer and complementary information. However, existing techniques only consider either lower order relations between the data and single/multi-modal imaging data. In this work, we introduce a novel semi-supervised hypergraph learning framework for Alzheimer's disease diagnosis. Our framework allows for higher-order relations among multi-modal imaging and non-imaging data whilst requiring a tiny labelled set. Firstly, we introduce a dual embedding strategy for constructing a robust hypergraph that preserves the data semantics. We achieve this by enforcing perturbation invariance at the image and graph levels using a contrastive based mechanism. Secondly, we present a dynamically adjusted hypergraph diffusion model, via a semi-explicit flow, to improve the predictive uncertainty. We demonstrate, through our experiments, that our framework is able to outperform current techniques for Alzheimer's disease diagnosis.
Multi-Agent Broad Reinforcement Learning for Intelligent Traffic Light Control
Mar 08, 2022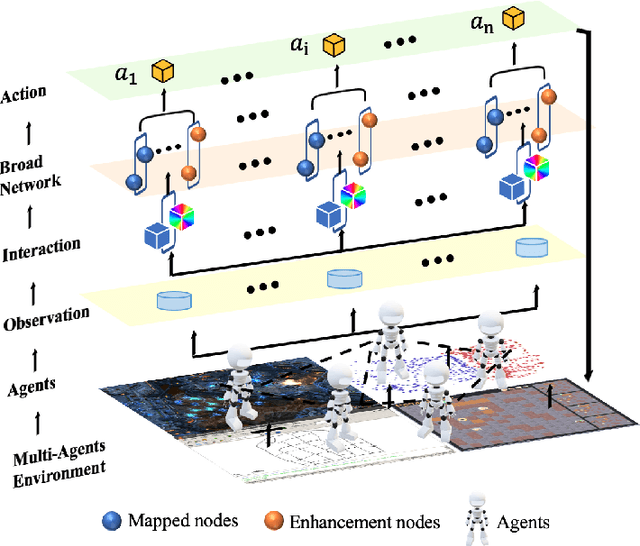
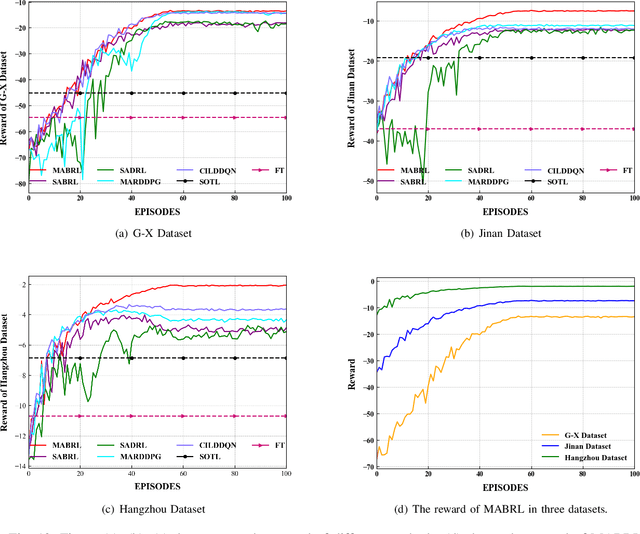
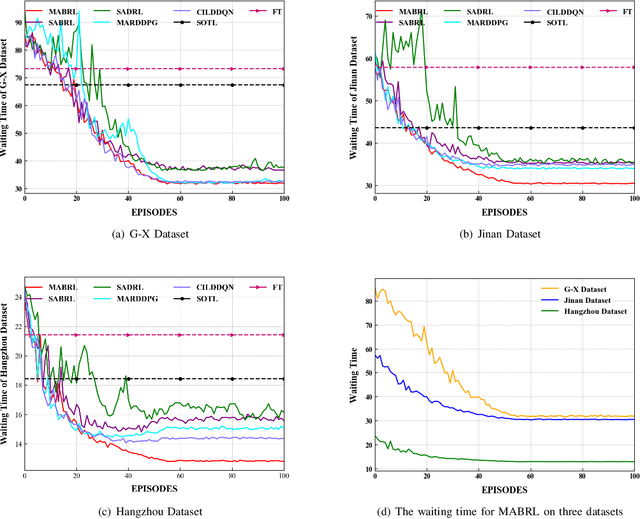
Intelligent Traffic Light Control System (ITLCS) is a typical Multi-Agent System (MAS), which comprises multiple roads and traffic lights.Constructing a model of MAS for ITLCS is the basis to alleviate traffic congestion. Existing approaches of MAS are largely based on Multi-Agent Deep Reinforcement Learning (MADRL). Although the Deep Neural Network (DNN) of MABRL is effective, the training time is long, and the parameters are difficult to trace. Recently, Broad Learning Systems (BLS) provided a selective way for learning in the deep neural networks by a flat network. Moreover, Broad Reinforcement Learning (BRL) extends BLS in Single Agent Deep Reinforcement Learning (SADRL) problem with promising results. However, BRL does not focus on the intricate structures and interaction of agents. Motivated by the feature of MADRL and the issue of BRL, we propose a Multi-Agent Broad Reinforcement Learning (MABRL) framework to explore the function of BLS in MAS. Firstly, unlike most existing MADRL approaches, which use a series of deep neural networks structures, we model each agent with broad networks. Then, we introduce a dynamic self-cycling interaction mechanism to confirm the "3W" information: When to interact, Which agents need to consider, What information to transmit. Finally, we do the experiments based on the intelligent traffic light control scenario. We compare the MABRL approach with six different approaches, and experimental results on three datasets verify the effectiveness of MABRL.
Learning the Proximity Operator in Unfolded ADMM for Phase Retrieval
Apr 04, 2022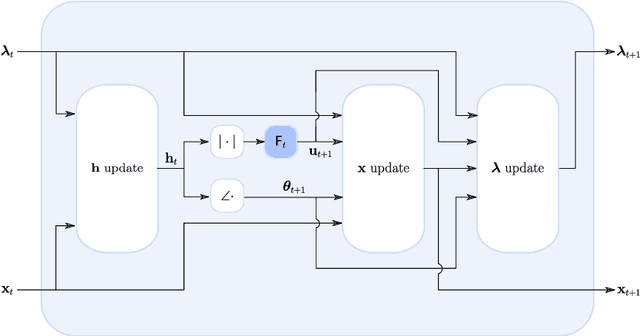
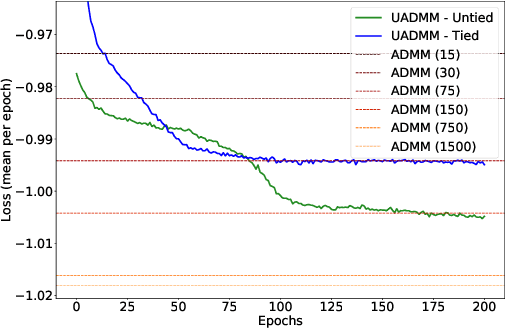
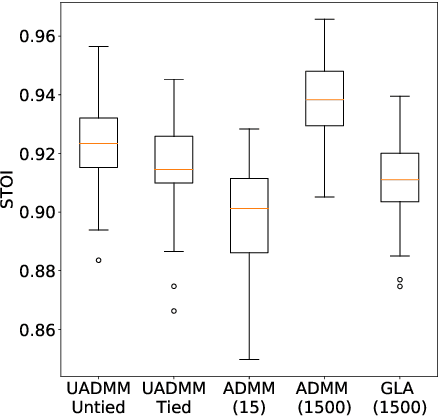
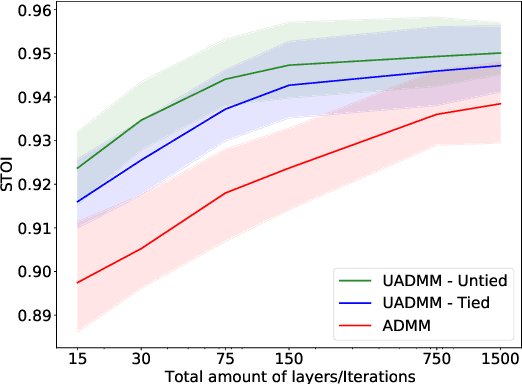
This paper considers the phase retrieval (PR) problem, which aims to reconstruct a signal from phaseless measurements such as magnitude or power spectrograms. PR is generally handled as a minimization problem involving a quadratic loss. Recent works have considered alternative discrepancy measures, such as the Bregman divergences, but it is still challenging to tailor the optimal loss for a given setting. In this paper we propose a novel strategy to automatically learn the optimal metric for PR. We unfold a recently introduced ADMM algorithm into a neural network, and we emphasize that the information about the loss used to formulate the PR problem is conveyed by the proximity operator involved in the ADMM updates. Therefore, we replace this proximity operator with trainable activation functions: learning these in a supervised setting is then equivalent to learning an optimal metric for PR. Experiments conducted with speech signals show that our approach outperforms the baseline ADMM, using a light and interpretable neural architecture.
Towards a Deeper Understanding of Skeleton-based Gait Recognition
Apr 16, 2022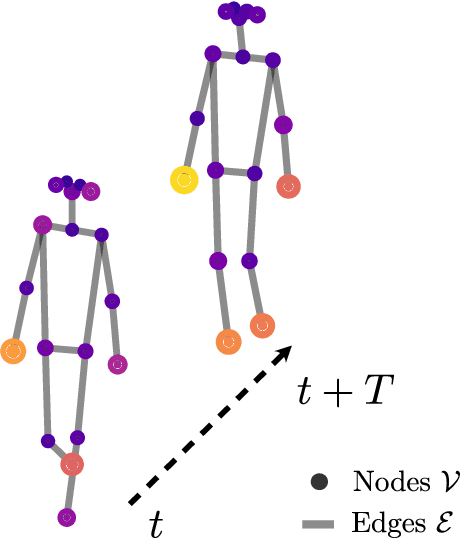
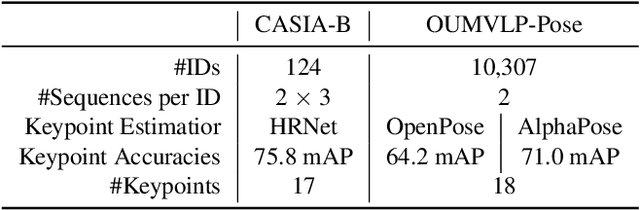
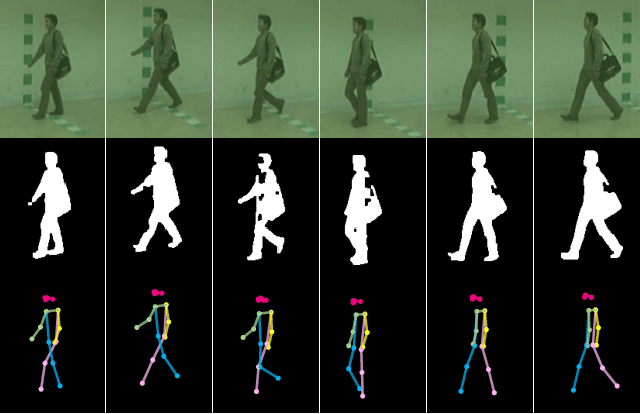
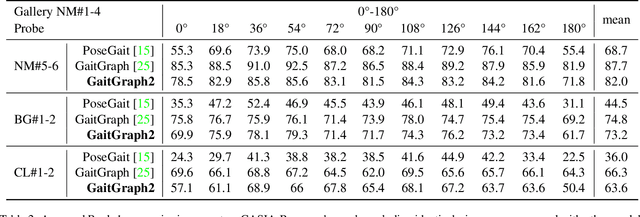
Gait recognition is a promising biometric with unique properties for identifying individuals from a long distance by their walking patterns. In recent years, most gait recognition methods used the person's silhouette to extract the gait features. However, silhouette images can lose fine-grained spatial information, suffer from (self) occlusion, and be challenging to obtain in real-world scenarios. Furthermore, these silhouettes also contain other visual clues that are not actual gait features and can be used for identification, but also to fool the system. Model-based methods do not suffer from these problems and are able to represent the temporal motion of body joints, which are actual gait features. The advances in human pose estimation started a new era for model-based gait recognition with skeleton-based gait recognition. In this work, we propose an approach based on Graph Convolutional Networks (GCNs) that combines higher-order inputs, and residual networks to an efficient architecture for gait recognition. Extensive experiments on the two popular gait datasets, CASIA-B and OUMVLP-Pose, show a massive improvement (3x) of the state-of-the-art (SotA) on the largest gait dataset OUMVLP-Pose and strong temporal modeling capabilities. Finally, we visualize our method to understand skeleton-based gait recognition better and to show that we model real gait features.
An Initialization Scheme for Meeting Separation with Spatial Mixture Models
Apr 04, 2022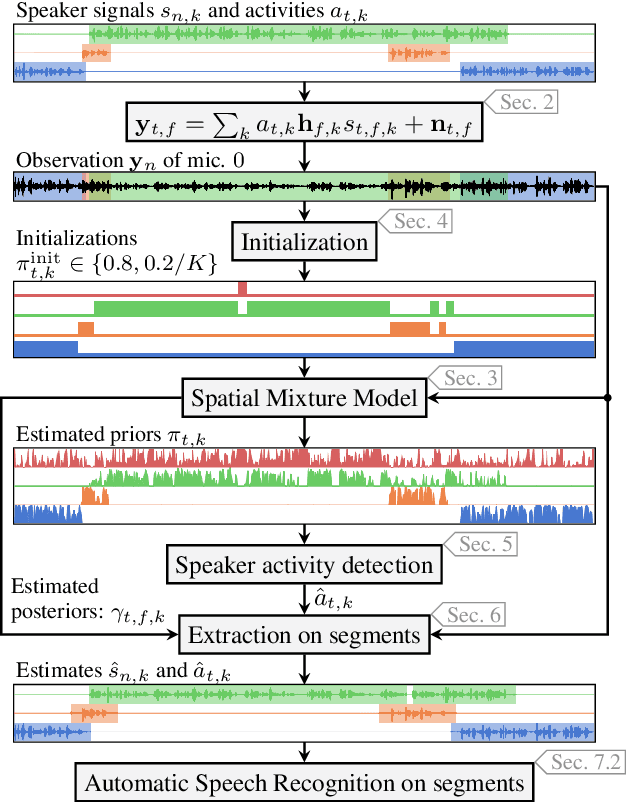
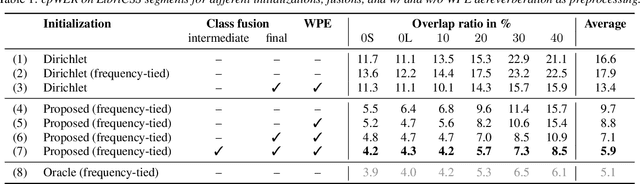
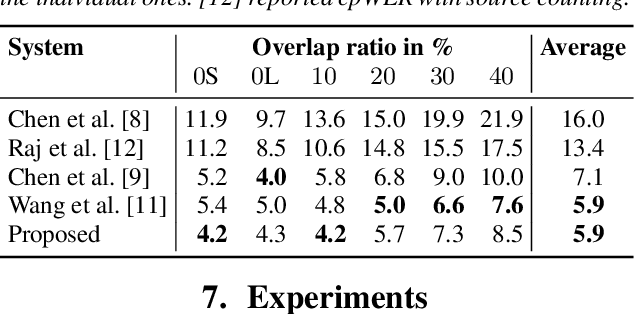
Spatial mixture model (SMM) supported acoustic beamforming has been extensively used for the separation of simultaneously active speakers. However, it has hardly been considered for the separation of meeting data, that are characterized by long recordings and only partially overlapping speech. In this contribution, we show that the fact that often only a single speaker is active can be utilized for a clever initialization of an SMM that employs time-varying class priors. In experiments on LibriCSS we show that the proposed initialization scheme achieves a significantly lower Word Error Rate (WER) on a downstream speech recognition task than a random initialization of the class probabilities by drawing from a Dirichlet distribution. With the only requirement that the number of speakers has to be known, we obtain a WER of 5.9 %, which is comparable to the best reported WER on this data set. Furthermore, the estimated speaker activity from the mixture model serves as a diarization based on spatial information.
Decision-Dependent Risk Minimization in Geometrically Decaying Dynamic Environments
Apr 08, 2022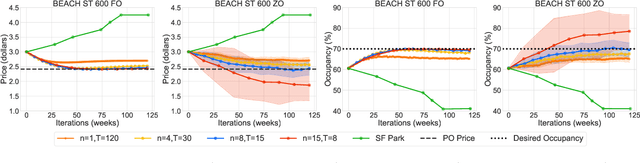

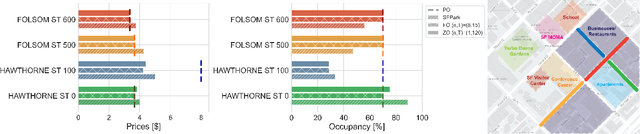
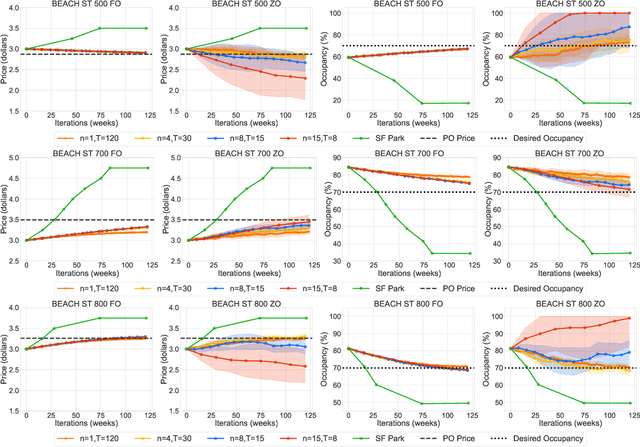
This paper studies the problem of expected loss minimization given a data distribution that is dependent on the decision-maker's action and evolves dynamically in time according to a geometric decay process. Novel algorithms for both the information setting in which the decision-maker has a first order gradient oracle and the setting in which they have simply a loss function oracle are introduced. The algorithms operate on the same underlying principle: the decision-maker repeatedly deploys a fixed decision over the length of an epoch, thereby allowing the dynamically changing environment to sufficiently mix before updating the decision. The iteration complexity in each of the settings is shown to match existing rates for first and zero order stochastic gradient methods up to logarithmic factors. The algorithms are evaluated on a "semi-synthetic" example using real world data from the SFpark dynamic pricing pilot study; it is shown that the announced prices result in an improvement for the institution's objective (target occupancy), while achieving an overall reduction in parking rates.
TEScalib: Targetless Extrinsic Self-Calibration of LiDAR and Stereo Camera for Automated Driving Vehicles with Uncertainty Analysis
Feb 28, 2022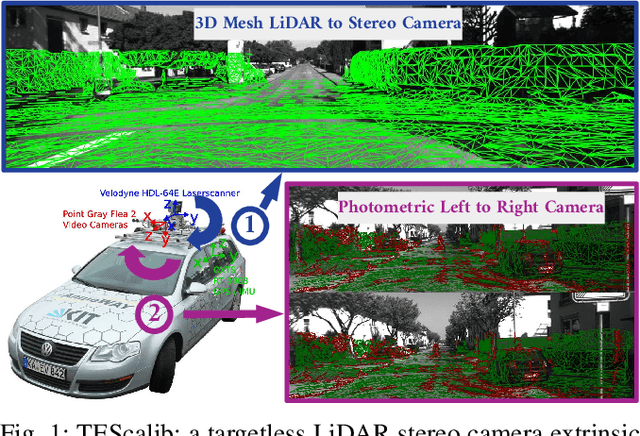
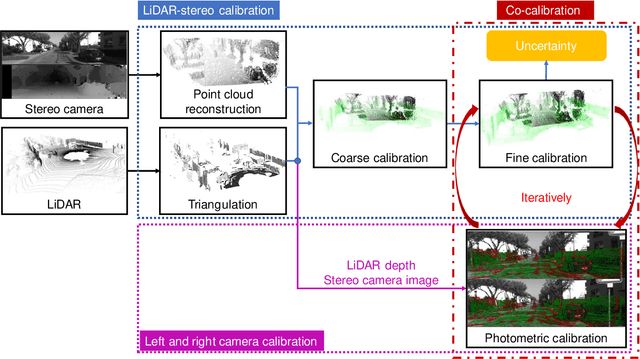
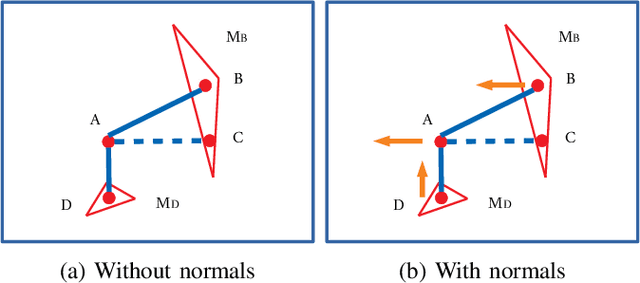
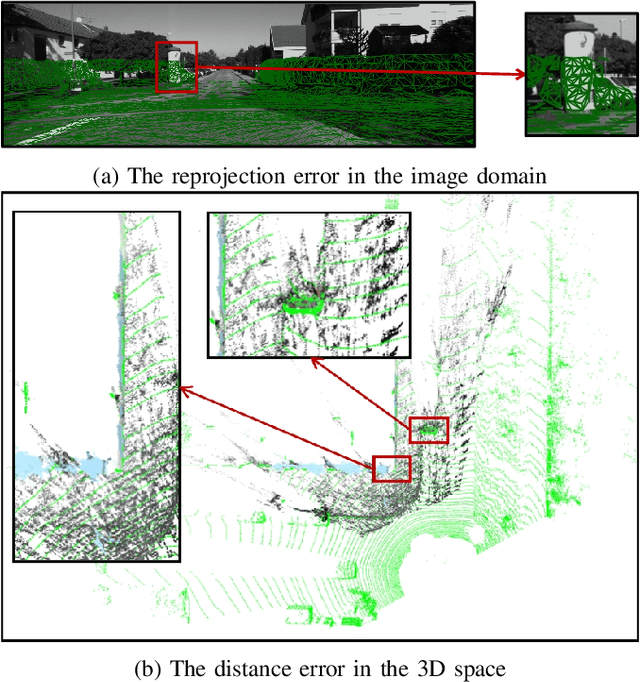
In this paper, we present TEScalib, a novel extrinsic self-calibration approach of LiDAR and stereo camera using the geometric and photometric information of surrounding environments without any calibration targets for automated driving vehicles. Since LiDAR and stereo camera are widely used for sensor data fusion on automated driving vehicles, their extrinsic calibration is highly important. However, most of the LiDAR and stereo camera calibration approaches are mainly target-based and therefore time consuming. Even the newly developed targetless approaches in last years are either inaccurate or unsuitable for driving platforms. To address those problems, we introduce TEScalib. By applying a 3D mesh reconstruction-based point cloud registration, the geometric information is used to estimate the LiDAR to stereo camera extrinsic parameters accurately and robustly. To calibrate the stereo camera, a photometric error function is builded and the LiDAR depth is involved to transform key points from one camera to another. During driving, these two parts are processed iteratively. Besides that, we also propose an uncertainty analysis for reflecting the reliability of the estimated extrinsic parameters. Our TEScalib approach evaluated on the KITTI dataset achieves very promising results.
Progressive Subsampling for Oversampled Data -- Application to Quantitative MRI
Apr 08, 2022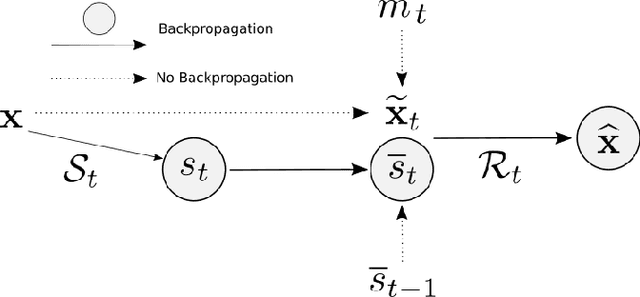
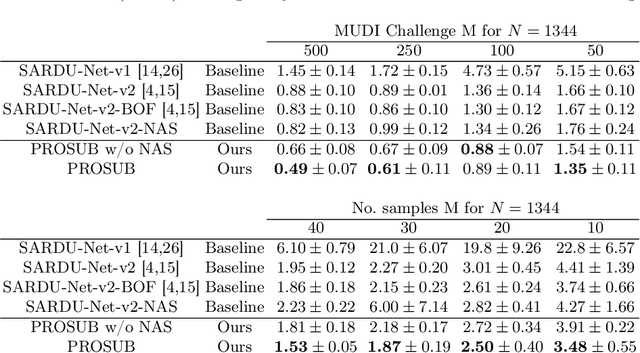
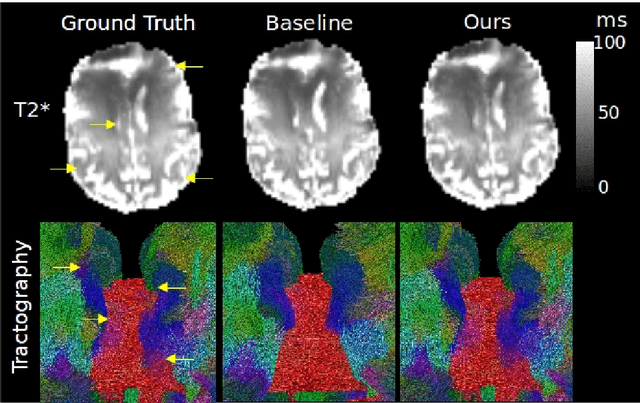
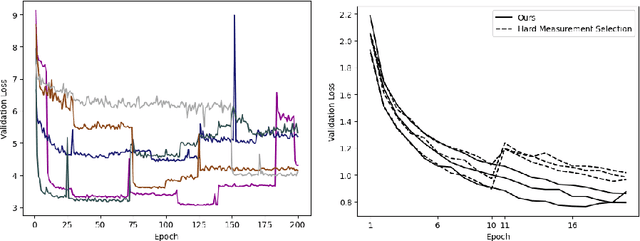
We present PROSUB: PROgressive SUBsampling, a deep learning based, automated methodology that subsamples an oversampled data set (e.g. multi-channeled 3D images) with minimal loss of information. We build upon a recent dual-network approach that won the MICCAI MUlti-DIffusion (MUDI) quantitative MRI measurement sampling-reconstruction challenge, but suffers from deep learning training instability, by subsampling with a hard decision boundary. PROSUB uses the paradigm of recursive feature elimination (RFE) and progressively subsamples measurements during deep learning training, improving optimization stability. PROSUB also integrates a neural architecture search (NAS) paradigm, allowing the network architecture hyperparameters to respond to the subsampling process. We show PROSUB outperforms the winner of the MUDI MICCAI challenge, producing large improvements >18% MSE on the MUDI challenge sub-tasks and qualitative improvements on downstream processes useful for clinical applications. We also show the benefits of incorporating NAS and analyze the effect of PROSUB's components. As our method generalizes to other problems beyond MRI measurement selection-reconstruction, our code is https://github.com/sbb-gh/PROSUB