 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data-Free Quantization with Accurate Activation Clipping and Adaptive Batch Normalization
Apr 08, 2022
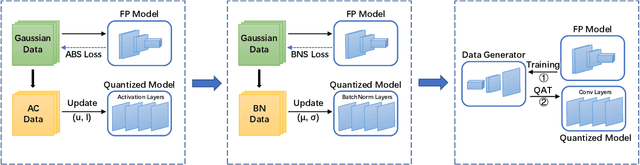
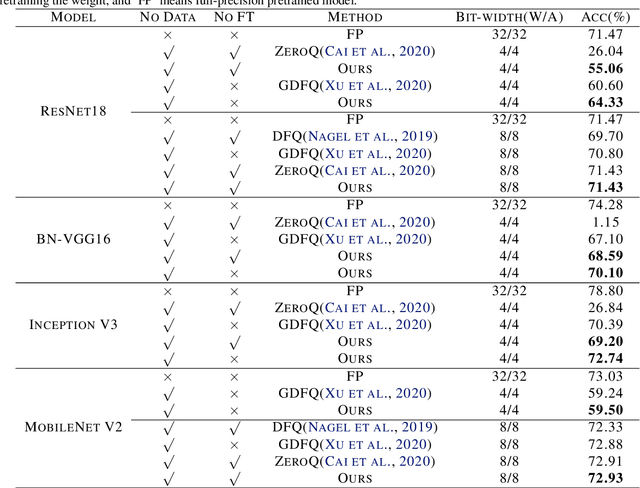
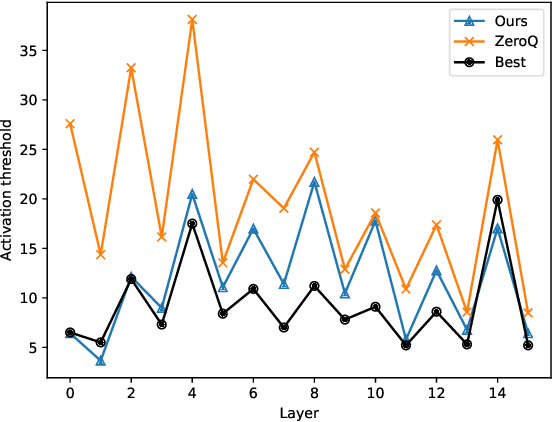
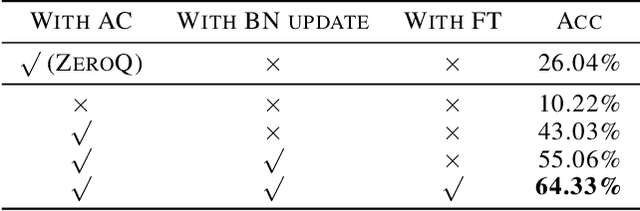
Data-free quantization is a task that compresses the neural network to low bit-width without access to original training data. Most existing data-free quantization methods cause severe performance degradation due to inaccurate activation clipping range and quantization error, especially for low bit-width. In this paper, we present a simple yet effective data-free quantization method with accurate activation clipping and adaptive batch normalization. Accurate activation clipping (AAC) improves the model accuracy by exploiting accurate activation information from the full-precision model. Adaptive batch normalization firstly proposes to address the quantization error from distribution changes by updating the batch normalization layer adaptively. Extensive experiments demonstrate that the proposed data-free quantization method can yield surprisingly performance, achieving 64.33% top-1 accuracy of ResNet18 on ImageNet dataset, with 3.7% absolute improvement outperforming the existing state-of-the-art methods.
Millimeter-Wave Sensing for Avoidance of High-Risk Ground Conditions for Mobile Robots
Mar 30, 2022
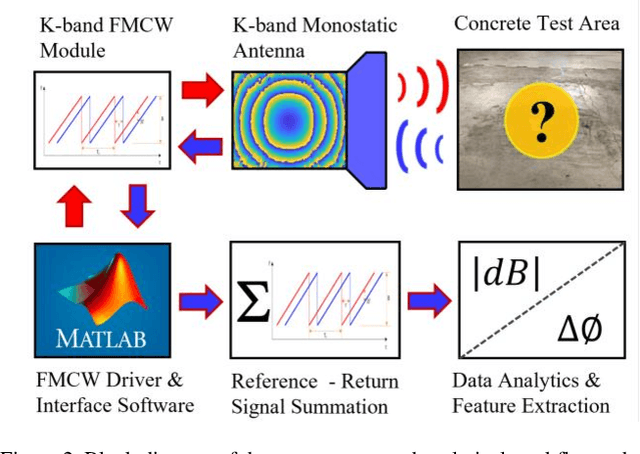
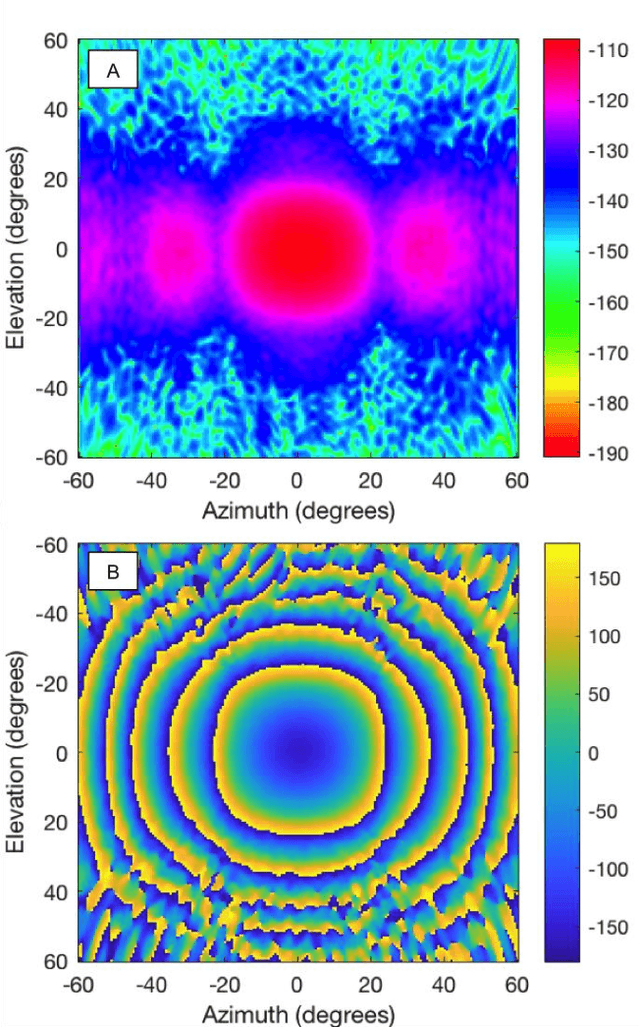
Mobile robot autonomy has made significant advances in recent years, with navigation algorithms well developed and used commercially in certain well-defined environments, such as warehouses. The common link in usage scenarios is that the environments in which the robots are utilized have a high degree of certainty. Operating environments are often designed to be robot friendly, for example augmented reality markers are strategically placed and the ground is typically smooth, level, and clear of debris. For robots to be useful in a wider range of environments, especially environments that are not sanitized for their use, robots must be able to handle uncertainty. This requires a robot to incorporate new sensors and sources of information, and to be able to use this information to make decisions regarding navigation and the overall mission. When using autonomous mobile robots in unstructured and poorly defined environments, such as a natural disaster site or in a rural environment, ground condition is of critical importance and is a common cause of failure. Examples include loss of traction due to high levels of ground water, hidden cavities, or material boundary failures. To evaluate a non-contact sensing method to mitigate these risks, Frequency Modulated Continuous Wave (FMCW) radar is integrated with an Unmanned Ground Vehicle (UGV), representing a novel application of FMCW to detect new measurands for Robotic Autonomous Systems (RAS) navigation, informing on terrain integrity and adding to the state-of-the-art in sensing for optimized autonomous path planning. In this paper, the FMCW is first evaluated in a desktop setting to determine its performance in anticipated ground conditions. The FMCW is then fixed to a UGV and the sensor system is tested and validated in a representative environment containing regions with significant levels of ground water saturation.
Distributed Auto-Learning GNN for Multi-Cell Cluster-Free NOMA Communications
Apr 28, 2022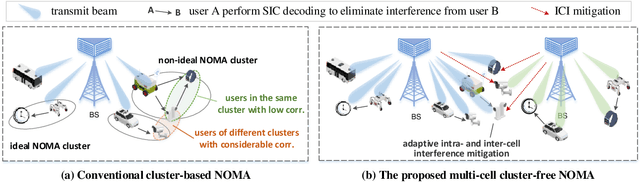
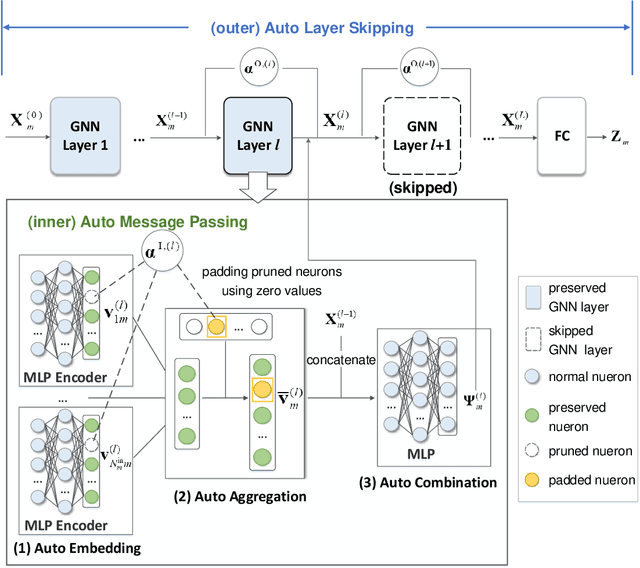
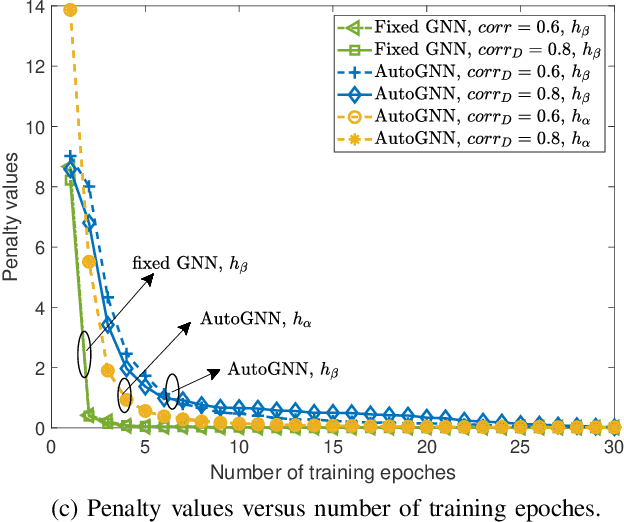
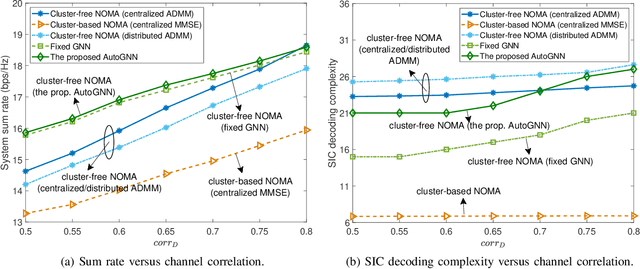
A multi-cell cluster-free NOMA framework is proposed, where both intra-cell and inter-cell interference are jointly mitigated via flexible cluster-free successive interference cancellation (SIC) and coordinated beamforming design, respectively. The joint design problem is formulated to maximize the system sum rate while satisfying the SIC decoding requirements and users' data rate constraints. To address this highly complex and coupling non-convex mixed integer nonlinear programming (MINLP), a novel distributed auto-learning graph neural network (AutoGNN) architecture is proposed to alleviate the overwhelming information exchange burdens among base stations (BSs). The proposed AutoGNN can train the GNN model weights whilst automatically learning the optimal GNN architecture, namely the GNN network depth and message embedding sizes, to achieve communication-efficient distributed scheduling. Based on the proposed architecture, a bi-level AutoGNN learning algorithm is further developed to efficiently approximate the hypergradient in model training. It is theoretically proved that the proposed bi-level AutoGNN learning algorithm can converge to a stationary point. Numerical results reveal that: 1) the proposed cluster-free NOMA framework outperforms the conventional cluster-based NOMA framework in the multi-cell scenario; and 2) the proposed AutoGNN architecture significantly reduces the computation and communication overheads compared to the conventional convex optimization-based methods and the conventional GNN with a fixed architecture.
Public awareness and attitudes towards search engine optimization
Apr 21, 2022

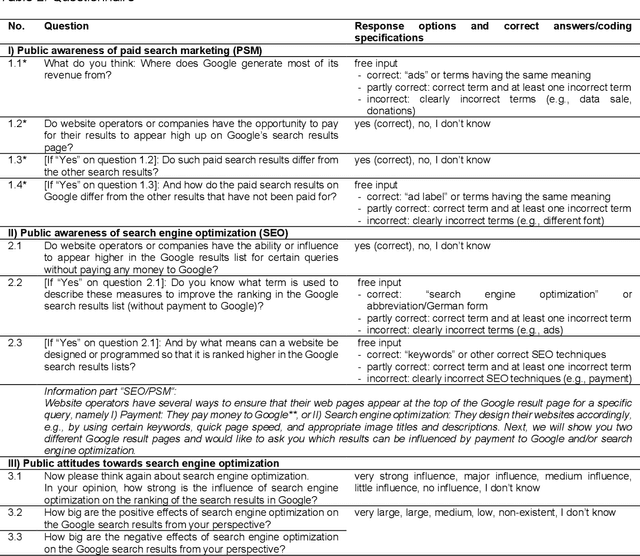
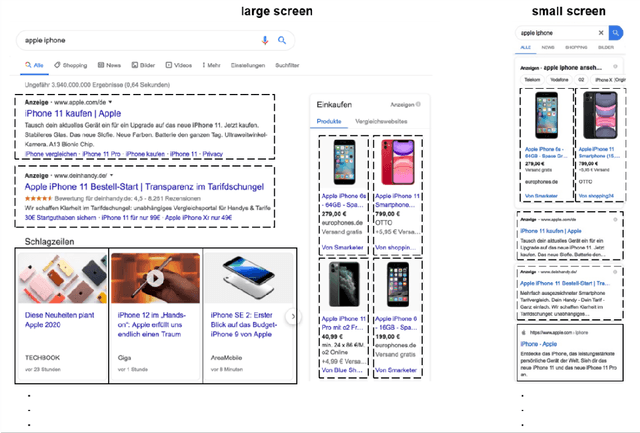
This research focuses on what users know about search engine optimization (SEO) and how well they can identify results that have potentially been influenced by SEO. We conducted an online survey with a sample representative of the German online population (N = 2,012). We found that 43% of users assume a better ranking can be achieved without paying money to Google. This is in stark contrast to the possibility of influence through paid advertisements, which 79% of internet users are aware of. However, only 29.2% know how ads differ from organic results. The term "search engine optimization" is known to 8.9% of users but 14.5% can correctly name at least one SEO tactic. Success in labelling results that can be influenced through SEO varies by search engine result page (SERP) complexity and devices: participants achieved higher success rates on SERPs with simple structures than on the more complex SERPs. SEO results were identified better on the small screen than on the large screen. 59.2% assumed that SEO has a (very) strong impact on rankings. SEO is more often perceived as positive (75.2%) than negative (68.4%). The insights from this study have implications for search engine providers, regulators, and information literacy.
* 20 pages, 9 tables, 5 figures
Cross-modal Image Retrieval with Deep Mutual Information Maximization
Mar 10, 2021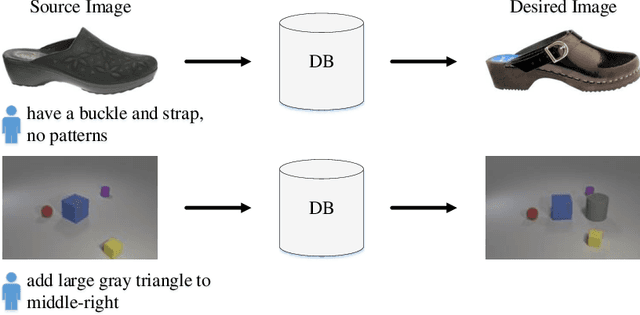
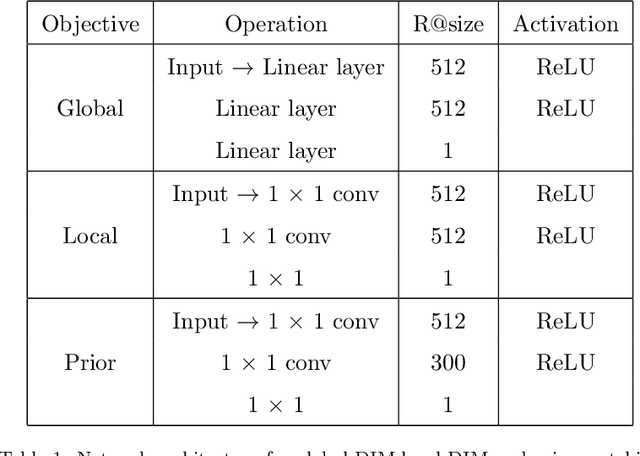
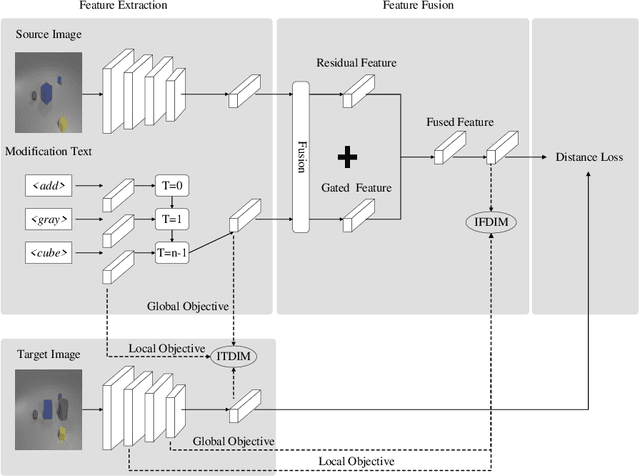
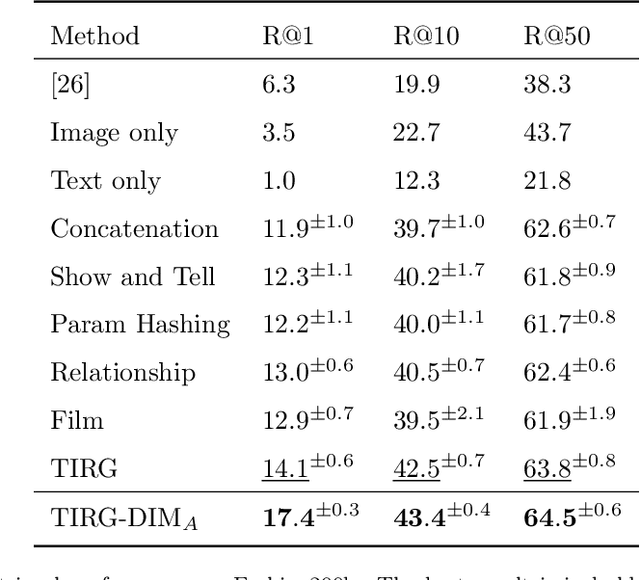
In this paper, we study the cross-modal image retrieval, where the inputs contain a source image plus some text that describes certain modifications to this image and the desired image. Prior work usually uses a three-stage strategy to tackle this task: 1) extract the features of the inputs; 2) fuse the feature of the source image and its modified text to obtain fusion feature; 3) learn a similarity metric between the desired image and the source image + modified text by using deep metric learning. Since classical image/text encoders can learn the useful representation and common pair-based loss functions of distance metric learning are enough for cross-modal retrieval, people usually improve retrieval accuracy by designing new fusion networks. However, these methods do not successfully handle the modality gap caused by the inconsistent distribution and representation of the features of different modalities, which greatly influences the feature fusion and similarity learning. To alleviate this problem, we adopt the contrastive self-supervised learning method Deep InforMax (DIM) to our approach to bridge this gap by enhancing the dependence between the text, the image, and their fusion. Specifically, our method narrows the modality gap between the text modality and the image modality by maximizing mutual information between their not exactly semantically identical representation. Moreover, we seek an effective common subspace for the semantically same fusion feature and desired image's feature by utilizing Deep InforMax between the low-level layer of the image encoder and the high-level layer of the fusion network. Extensive experiments on three large-scale benchmark datasets show that we have bridged the modality gap between different modalities and achieve state-of-the-art retrieval performance.
A Semi-Synthetic Dataset Generation Framework for Causal Inference in Recommender Systems
Feb 23, 2022
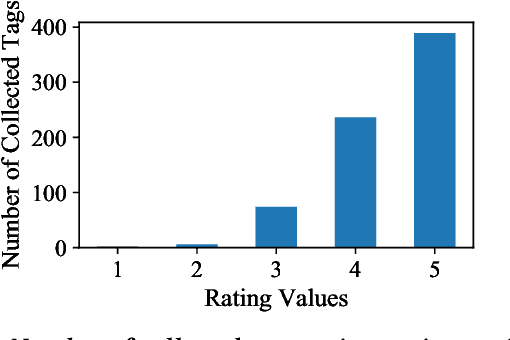
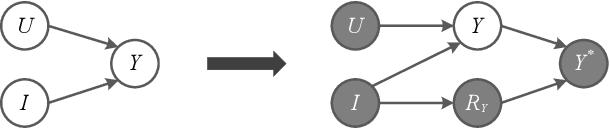
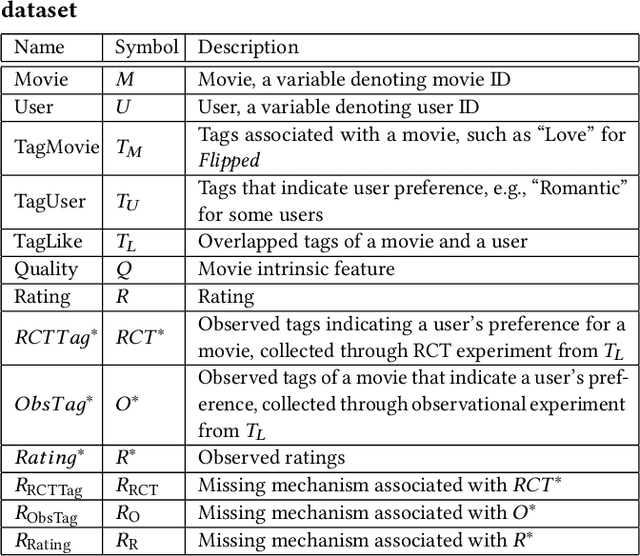
Accurate recommendation and reliable explanation are two key issues for modern recommender systems. However, most recommendation benchmarks only concern the prediction of user-item ratings while omitting the underlying causes behind the ratings. For example, the widely-used Yahoo!R3 dataset contains little information on the causes of the user-movie ratings. A solution could be to conduct surveys and require the users to provide such information. In practice, the user surveys can hardly avoid compliance issues and sparse user responses, which greatly hinders the exploration of causality-based recommendation. To better support the studies of causal inference and further explanations in recommender systems, we propose a novel semi-synthetic data generation framework for recommender systems where causal graphical models with missingness are employed to describe the causal mechanism of practical recommendation scenarios. To illustrate the use of our framework, we construct a semi-synthetic dataset with Causal Tags And Ratings (CTAR), based on the movies as well as their descriptive tags and rating information collected from a famous movie rating website. Using the collected data and the causal graph, the user-item-ratings and their corresponding user-item-tags are automatically generated, which provides the reasons (selected tags) why the user rates the items. Descriptive statistics and baseline results regarding the CTAR dataset are also reported. The proposed data generation framework is not limited to recommendation, and the released APIs can be used to generate customized datasets for other research tasks.
partitura: A Python Package for Handling Symbolic Musical Data
Jan 31, 2022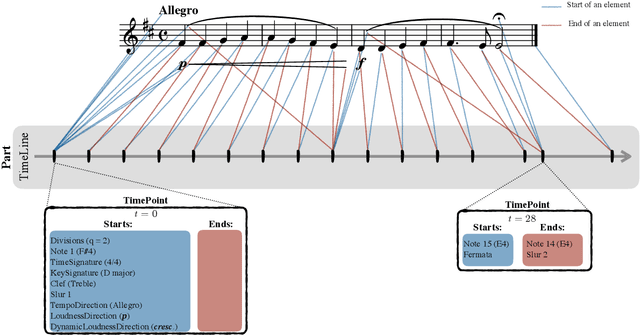
This demo paper introduces partitura, a Python package for handling symbolic musical information. The principal aim of this package is to handle richly structured musical information as conveyed by modern staff music notation. It provides a much wider range of possibilities to deal with music than the more reductive (but very common) piano roll-oriented approach inspired by the MIDI standard. The package is an open source project and is available on GitHub.
Probing for the Usage of Grammatical Number
Apr 21, 2022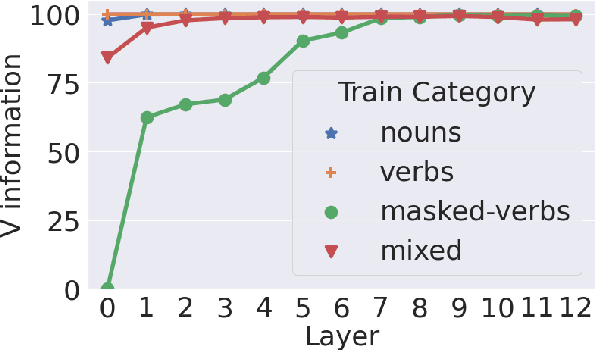
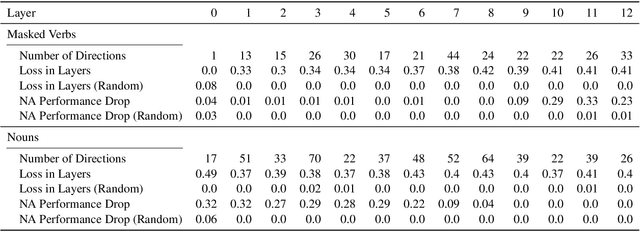
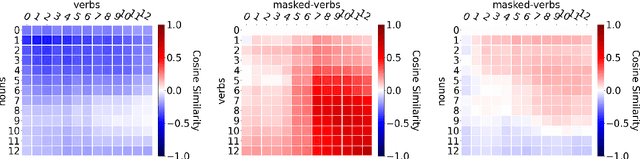
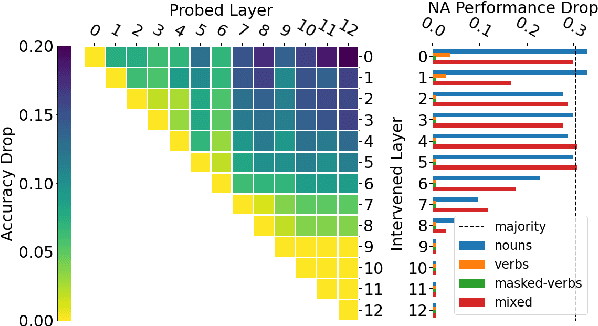
A central quest of probing is to uncover how pre-trained models encode a linguistic property within their representations. An encoding, however, might be spurious-i.e., the model might not rely on it when making predictions. In this paper, we try to find encodings that the model actually uses, introducing a usage-based probing setup. We first choose a behavioral task which cannot be solved without using the linguistic property. Then, we attempt to remove the property by intervening on the model's representations. We contend that, if an encoding is used by the model, its removal should harm the performance on the chosen behavioral task. As a case study, we focus on how BERT encodes grammatical number, and on how it uses this encoding to solve the number agreement task. Experimentally, we find that BERT relies on a linear encoding of grammatical number to produce the correct behavioral output. We also find that BERT uses a separate encoding of grammatical number for nouns and verbs. Finally, we identify in which layers information about grammatical number is transferred from a noun to its head verb.
ONBRA: Rigorous Estimation of the Temporal Betweenness Centrality in Temporal Networks
Mar 01, 2022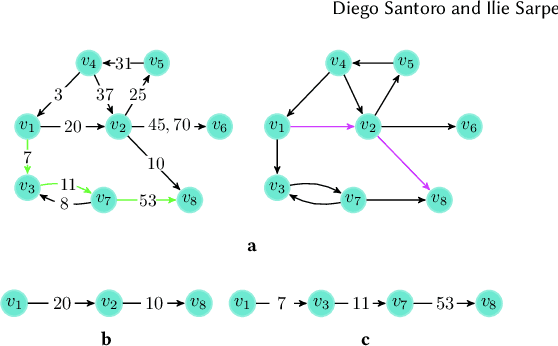
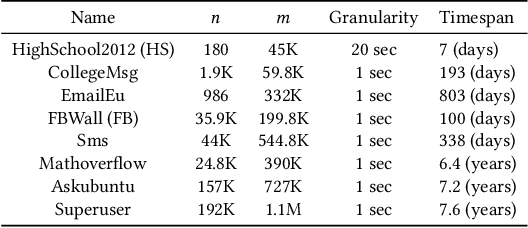
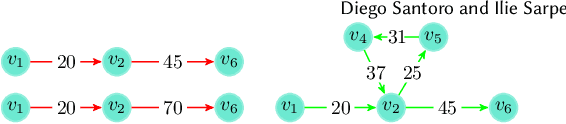

In network analysis, the betweenness centrality of a node informally captures the fraction of shortest paths visiting that node. The computation of the betweenness centrality measure is a fundamental task in the analysis of modern networks, enabling the identification of the most central nodes in such networks. Additionally to being massive, modern networks also contain information about the time at which their events occur. Such networks are often called temporal networks. The temporal information makes the study of the betweenness centrality in temporal networks (i.e., temporal betweenness centrality) much more challenging than in static networks (i.e., networks without temporal information). Moreover, the exact computation of the temporal betweenness centrality is often impractical on even moderately-sized networks, given its extremely high computational cost. A natural approach to reduce such computational cost is to obtain high-quality estimates of the exact values of the temporal betweenness centrality. In this work we present ONBRA, the first sampling-based approximation algorithm for estimating the temporal betweenness centrality values of the nodes in a temporal network, providing rigorous probabilistic guarantees on the quality of its output. ONBRA is able to compute the estimates of the temporal betweenness centrality values under two different optimality criteria for the shortest paths of the temporal network. In addition, ONBRA outputs high-quality estimates with sharp theoretical guarantees leveraging on the \emph{empirical Bernstein bound}, an advanced concentration inequality. Finally, our experimental evaluation shows that ONBRA significantly reduces the computational resources required by the exact computation of the temporal betweenness centrality on several real world networks, while reporting high-quality estimates with rigorous guarantees.
Temporal Attention for Language Models
Feb 04, 2022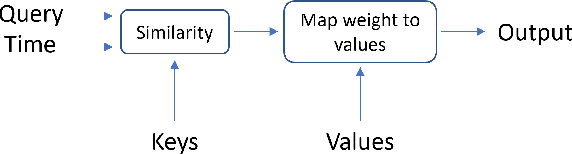

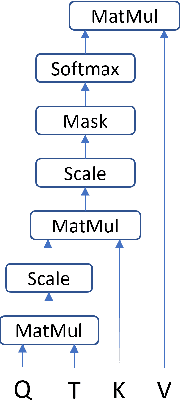
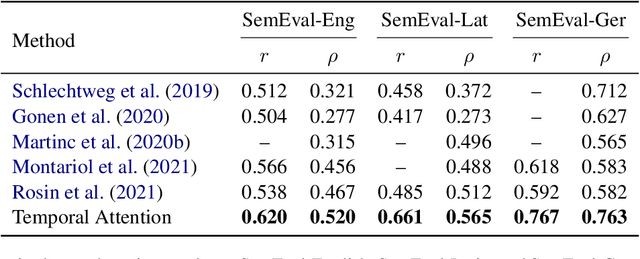
Pretrained language models based on the transformer architecture have shown great success in NLP. Textual training data often comes from the web and is thus tagged with time-specific information, but most language models ignore this information. They are trained on the textual data alone, limiting their ability to generalize temporally. In this work, we extend the key component of the transformer architecture, i.e., the self-attention mechanism, and propose temporal attention - a time-aware self-attention mechanism. Temporal attention can be applied to any transformer model and requires the input texts to be accompanied with their relevant time points. It allows the transformer to capture this temporal information and create time-specific contextualized word representations. We leverage these representations for the task of semantic change detection; we apply our proposed mechanism to BERT and experiment on three datasets in different languages (English, German, and Latin) that also vary in time, size, and genre. Our proposed model achieves state-of-the-art results on all the datasets.