 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Performance-Consistent and Computation-Efficient CNN System for High-Quality Automated Brain Tumor Segmentation
May 02, 2022
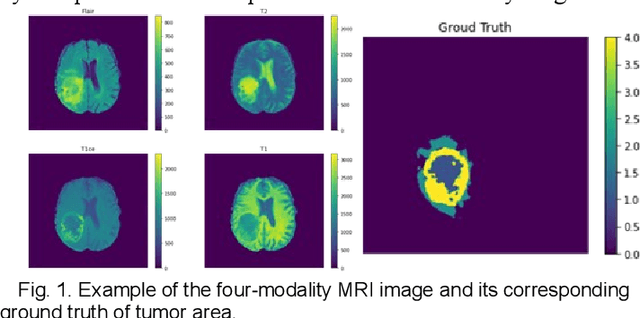
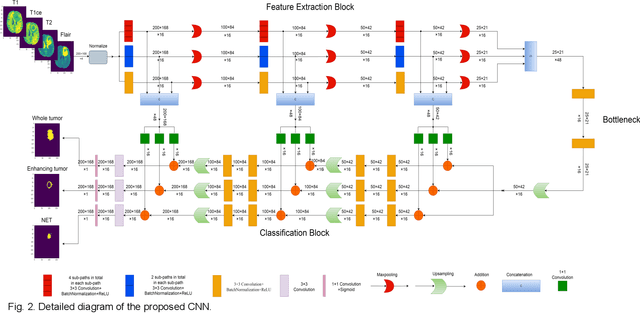
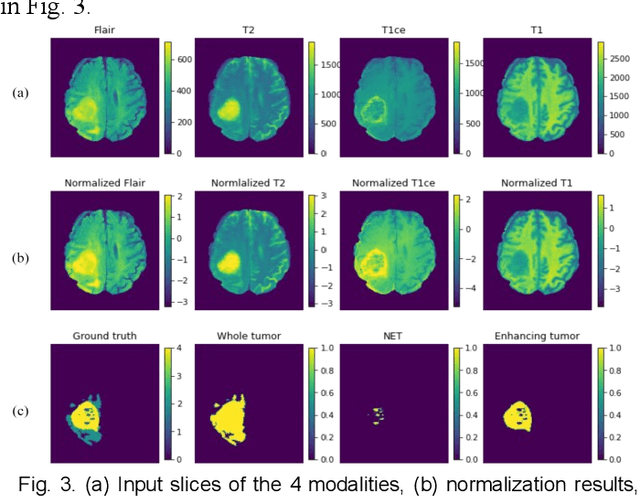
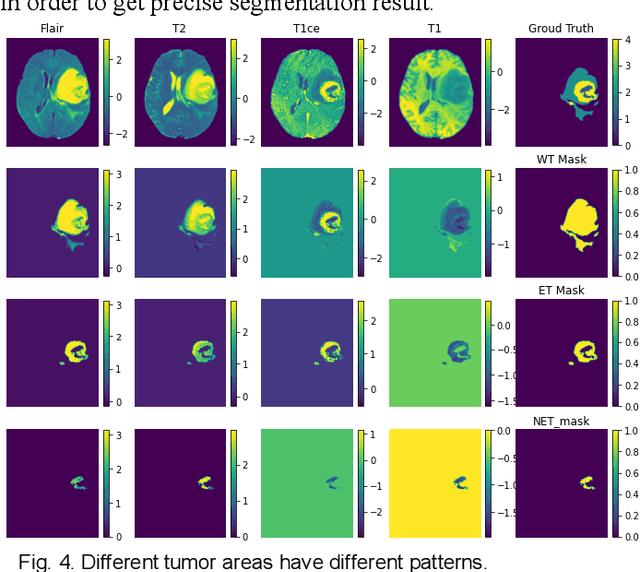
The research on developing CNN-based fully-automated Brain-Tumor-Segmentation systems has been progressed rapidly. For the systems to be applicable in practice, a good The research on developing CNN-based fully-automated Brain-Tumor-Segmentation systems has been progressed rapidly. For the systems to be applicable in practice, a good processing quality and reliability are the must. Moreover, for wide applications of such systems, a minimization of computation complexity is desirable, which can also result in a minimization of randomness in computation and, consequently, a better performance consistency. To this end, the CNN in the proposed system has a unique structure with 2 distinguished characters. Firstly, the three paths of its feature extraction block are designed to extract, from the multi-modality input, comprehensive feature information of mono-modality, paired-modality and cross-modality data, respectively. Also, it has a particular three-branch classification block to identify the pixels of 4 classes. Each branch is trained separately so that the parameters are updated specifically with the corresponding ground truth data of a target tumor areas. The convolution layers of the system are custom-designed with specific purposes, resulting in a very simple config of 61,843 parameters in total. The proposed system is tested extensively with BraTS2018 and BraTS2019 datasets. The mean Dice scores, obtained from the ten experiments on BraTS2018 validation samples, are 0.787+0.003, 0.886+0.002, 0.801+0.007, for enhancing tumor, whole tumor and tumor core, respectively, and 0.751+0.007, 0.885+0.002, 0.776+0.004 on BraTS2019. The test results demonstrate that the proposed system is able to perform high-quality segmentation in a consistent manner. Furthermore, its extremely low computation complexity will facilitate its implementation/application in various environments.
A Collection of Deep Learning-based Feature-Free Approaches for Characterizing Single-Objective Continuous Fitness Landscapes
Apr 13, 2022
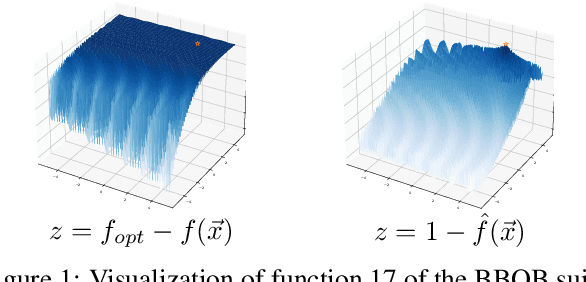
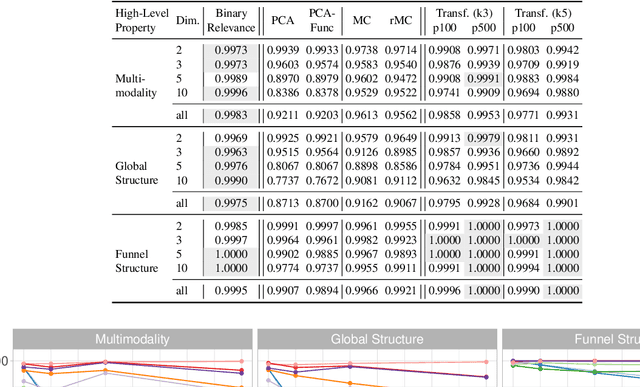
Exploratory Landscape Analysis is a powerful technique for numerically characterizing landscapes of single-objective continuous optimization problems. Landscape insights are crucial both for problem understanding as well as for assessing benchmark set diversity and composition. Despite the irrefutable usefulness of these features, they suffer from their own ailments and downsides. Hence, in this work we provide a collection of different approaches to characterize optimization landscapes. Similar to conventional landscape features, we require a small initial sample. However, instead of computing features based on that sample, we develop alternative representations of the original sample. These range from point clouds to 2D images and, therefore, are entirely feature-free. We demonstrate and validate our devised methods on the BBOB testbed and predict, with the help of Deep Learning, the high-level, expert-based landscape properties such as the degree of multimodality and the existence of funnel structures. The quality of our approaches is on par with methods relying on the traditional landscape features. Thereby, we provide an exciting new perspective on every research area which utilizes problem information such as problem understanding and algorithm design as well as automated algorithm configuration and selection.
Visual Attention Methods in Deep Learning: An In-Depth Survey
Apr 21, 2022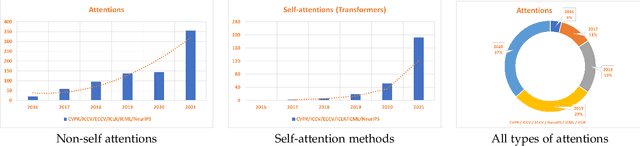
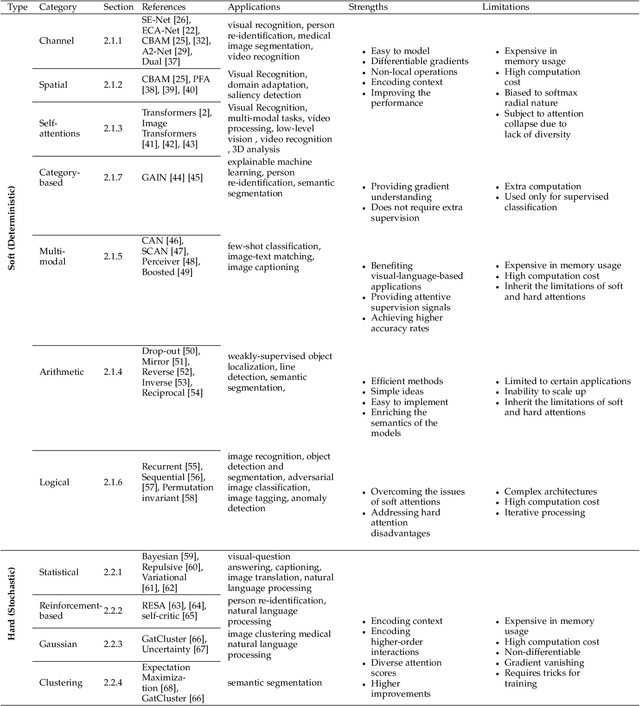
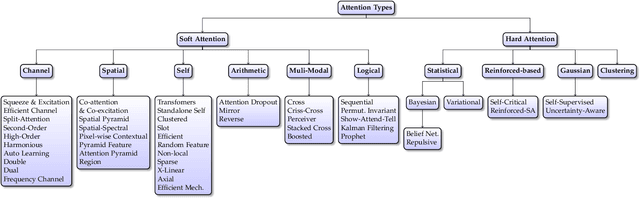
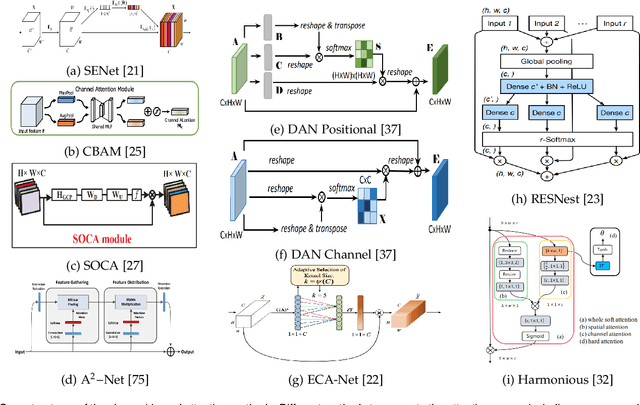
Inspired by the human cognitive system, attention is a mechanism that imitates the human cognitive awareness about specific information, amplifying critical details to focus more on the essential aspects of data. Deep learning has employed attention to boost performance for many applications. Interestingly, the same attention design can suit processing different data modalities and can easily be incorporated into large networks. Furthermore, multiple complementary attention mechanisms can be incorporated in one network. Hence, attention techniques have become extremely attractive. However, the literature lacks a comprehensive survey specific to attention techniques to guide researchers in employing attention in their deep models. Note that, besides being demanding in terms of training data and computational resources, transformers only cover a single category in self-attention out of the many categories available. We fill this gap and provide an in-depth survey of 50 attention techniques categorizing them by their most prominent features. We initiate our discussion by introducing the fundamental concepts behind the success of attention mechanism. Next, we furnish some essentials such as the strengths and limitations of each attention category, describe their fundamental building blocks, basic formulations with primary usage, and applications specifically for computer vision. We also discuss the challenges and open questions related to attention mechanism in general. Finally, we recommend possible future research directions for deep attention.
Fisher Information Field: an Efficient and Differentiable Map for Perception-aware Planning
Aug 07, 2020



Considering visual localization accuracy at the planning time gives preference to robot motion that can be better localized and thus has the potential of improving vision-based navigation, especially in visually degraded environments. To integrate the knowledge about localization accuracy in motion planning algorithms, a central task is to quantify the amount of information that an image taken at a 6 degree-of-freedom pose brings for localization, which is often represented by the Fisher information. However, computing the Fisher information from a set of sparse landmarks (i.e., a point cloud), which is the most common map for visual localization, is inefficient. This approach scales linearly with the number of landmarks in the environment and does not allow the reuse of the computed Fisher information. To overcome these drawbacks, we propose the first dedicated map representation for evaluating the Fisher information of 6 degree-of-freedom visual localization for perception-aware motion planning. By formulating the Fisher information and sensor visibility carefully, we are able to separate the rotational invariant component from the Fisher information and store it in a voxel grid, namely the Fisher information field. This step only needs to be performed once for a known environment. The Fisher information for arbitrary poses can then be computed from the field in constant time, eliminating the need of costly iterating all the 3D landmarks at the planning time. Experimental results show that the proposed Fisher information field can be applied to different motion planning algorithms and is at least one order-of-magnitude faster than using the point cloud directly. Moreover,the proposed map representation is differentiable, resulting in better performance than the point cloud when used in trajectory optimization algorithms.
Multi-Task Learning for Visual Scene Understanding
Mar 28, 2022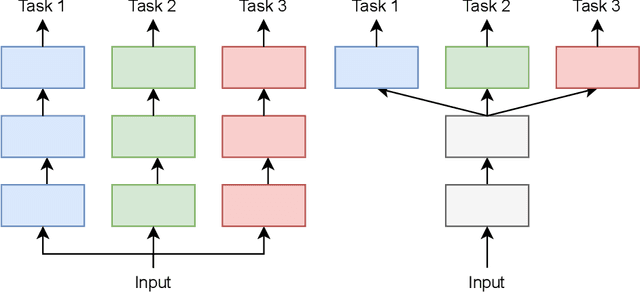


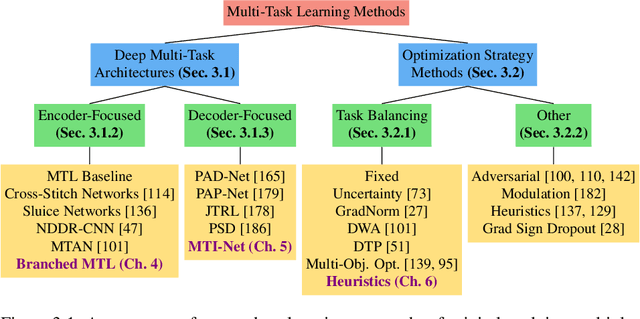
Despite the recent progress in deep learning, most approaches still go for a silo-like solution, focusing on learning each task in isolation: training a separate neural network for each individual task. Many real-world problems, however, call for a multi-modal approach and, therefore, for multi-tasking models. Multi-task learning (MTL) aims to leverage useful information across tasks to improve the generalization capability of a model. This thesis is concerned with multi-task learning in the context of computer vision. First, we review existing approaches for MTL. Next, we propose several methods that tackle important aspects of multi-task learning. The proposed methods are evaluated on various benchmarks. The results show several advances in the state-of-the-art of multi-task learning. Finally, we discuss several possibilities for future work.
Self-Supervised Learning to Guide Scientifically Relevant Categorization of Martian Terrain Images
Apr 21, 2022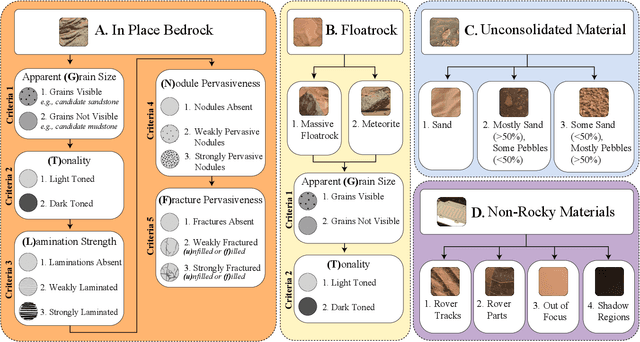

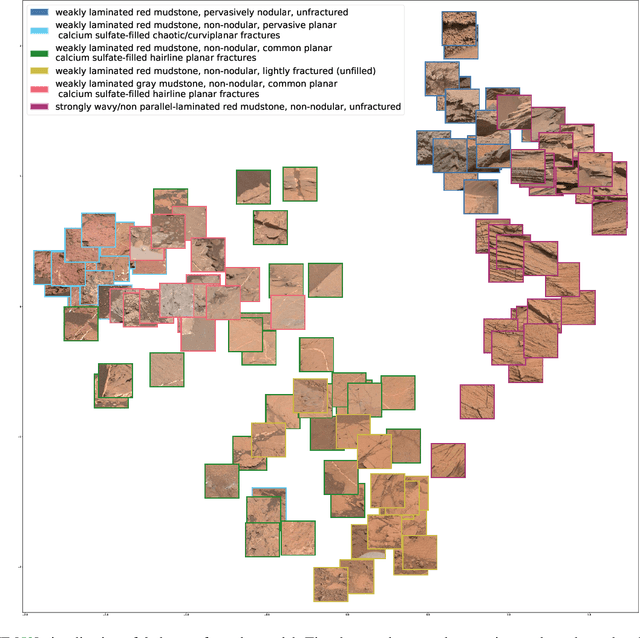

Automatic terrain recognition in Mars rover images is an important problem not just for navigation, but for scientists interested in studying rock types, and by extension, conditions of the ancient Martian paleoclimate and habitability. Existing approaches to label Martian terrain either involve the use of non-expert annotators producing taxonomies of limited granularity (e.g. soil, sand, bedrock, float rock, etc.), or rely on generic class discovery approaches that tend to produce perceptual classes such as rover parts and landscape, which are irrelevant to geologic analysis. Expert-labeled datasets containing granular geological/geomorphological terrain categories are rare or inaccessible to public, and sometimes require the extraction of relevant categorical information from complex annotations. In order to facilitate the creation of a dataset with detailed terrain categories, we present a self-supervised method that can cluster sedimentary textures in images captured from the Mast camera onboard the Curiosity rover (Mars Science Laboratory). We then present a qualitative analysis of these clusters and describe their geologic significance via the creation of a set of granular terrain categories. The precision and geologic validation of these automatically discovered clusters suggest that our methods are promising for the rapid classification of important geologic features and will therefore facilitate our long-term goal of producing a large, granular, and publicly available dataset for Mars terrain recognition.
What is wrong with you?: Leveraging User Sentiment for Automatic Dialog Evaluation
Mar 25, 2022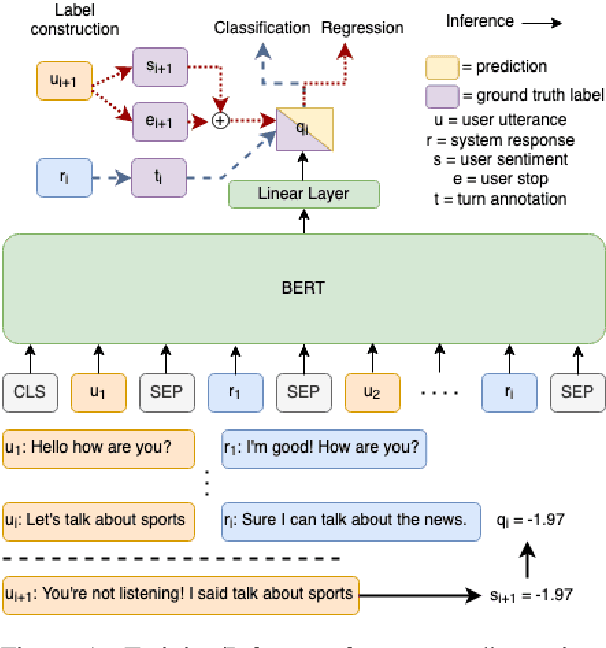

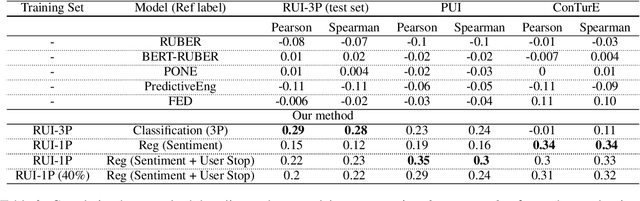
Accurate automatic evaluation metrics for open-domain dialogs are in high demand. Existing model-based metrics for system response evaluation are trained on human annotated data, which is cumbersome to collect. In this work, we propose to use information that can be automatically extracted from the next user utterance, such as its sentiment or whether the user explicitly ends the conversation, as a proxy to measure the quality of the previous system response. This allows us to train on a massive set of dialogs with weak supervision, without requiring manual system turn quality annotations. Experiments show that our model is comparable to models trained on human annotated data. Furthermore, our model generalizes across both spoken and written open-domain dialog corpora collected from real and paid users.
Predicting score distribution to improve non-intrusive speech quality estimation
Apr 13, 2022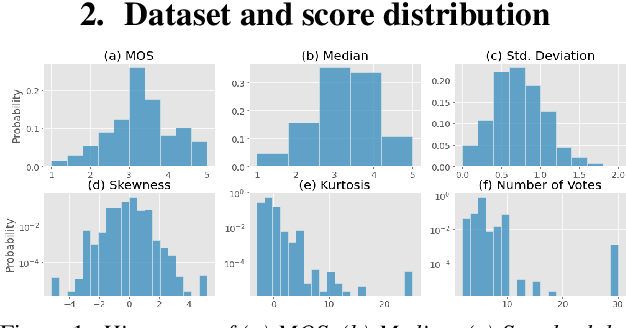
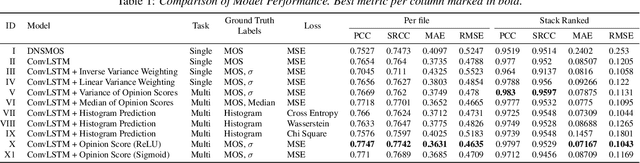
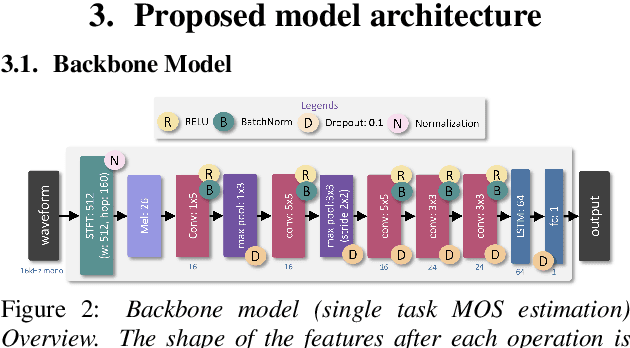
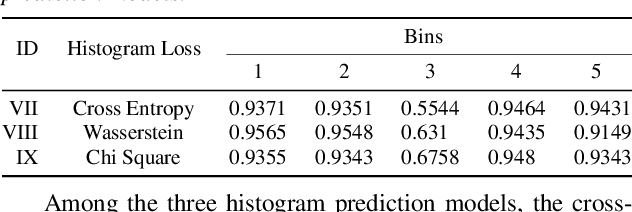
Deep noise suppressors (DNS) have become an attractive solution to remove background noise, reverberation, and distortions from speech and are widely used in telephony/voice applications. They are also occasionally prone to introducing artifacts and lowering the perceptual quality of the speech. Subjective listening tests that use multiple human judges to derive a mean opinion score (MOS) are a popular way to measure these models' performance. Deep neural network based non-intrusive MOS estimation models have recently emerged as a popular cost-efficient alternative to these tests. These models are trained with only the MOS labels, often discarding the secondary statistics of the opinion scores. In this paper, we investigate several ways to integrate the distribution of opinion scores (e.g. variance, histogram information) to improve the MOS estimation performance. Our model is trained on a corpus of 419K denoised samples by 320 different DNS models and model variations and evaluated on 18K test samples from DNSMOS. We show that with very minor modification of a single task MOS estimation pipeline, these freely available labels can provide up to a 0.016 RMSE and 1% SRCC improvement.
The dangers in algorithms learning humans' values and irrationalities
Mar 01, 2022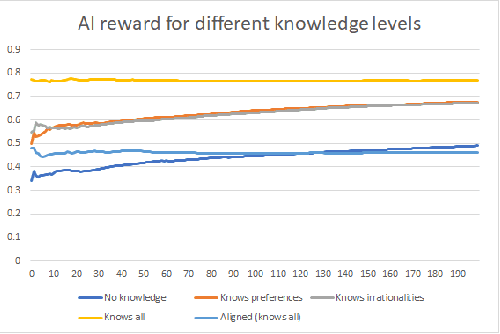
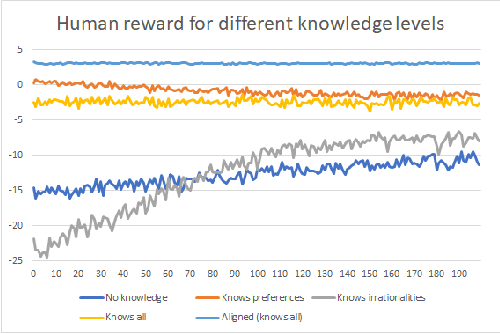
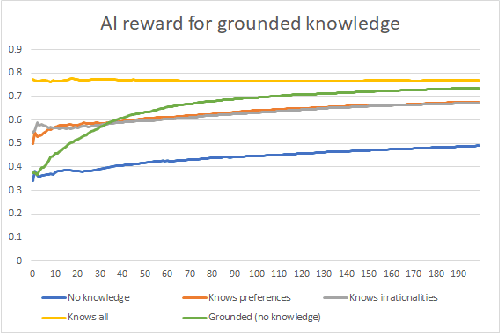
For an artificial intelligence (AI) to be aligned with human values (or human preferences), it must first learn those values. AI systems that are trained on human behavior, risk miscategorising human irrationalities as human values -- and then optimising for these irrationalities. Simply learning human values still carries risks: AI learning them will inevitably also gain information on human irrationalities and human behaviour/policy. Both of these can be dangerous: knowing human policy allows an AI to become generically more powerful (whether it is partially aligned or not aligned at all), while learning human irrationalities allows it to exploit humans without needing to provide value in return. This paper analyses the danger in developing artificial intelligence that learns about human irrationalities and human policy, and constructs a model recommendation system with various levels of information about human biases, human policy, and human values. It concludes that, whatever the power and knowledge of the AI, it is more dangerous for it to know human irrationalities than human values. Thus it is better for the AI to learn human values directly, rather than learning human biases and then deducing values from behaviour.
A Weibo Dataset for the 2022 Russo-Ukrainian Crisis
Mar 09, 2022
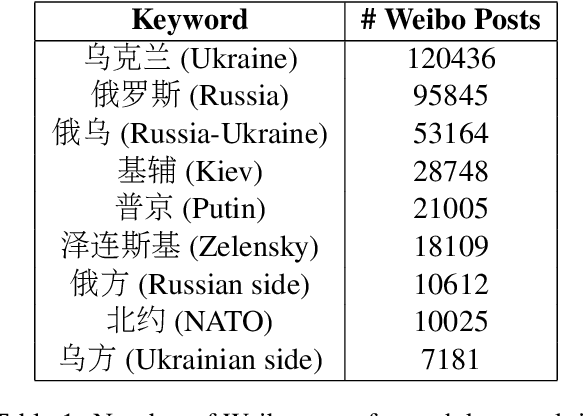
Online social networks such as Twitter and Weibo play an important role in how people stay informed and exchange reactions. Each crisis encompasses a new opportunity to study the portability of models for various tasks (e.g., information extraction, complex event understanding, misinformation detection, etc.), due to differences in domain, entities, and event types. We present the Russia-Ukraine Crisis Weibo (RUW) dataset, with over 3.5M user posts and comments in the first release. Our data is available at https://github.com/yrf1/RussiaUkraine_weibo_dataset.