 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Generalizable Dexterous Manipulation from Human Grasp Affordance
Apr 05, 2022
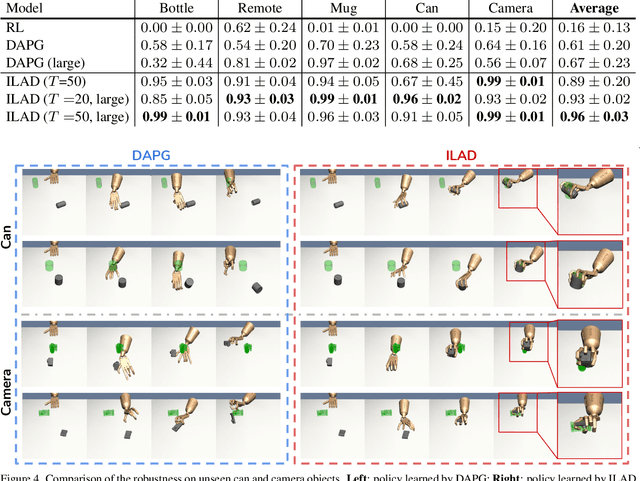
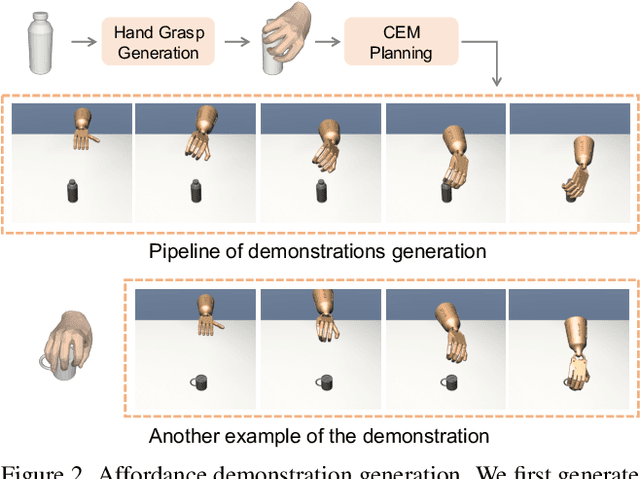

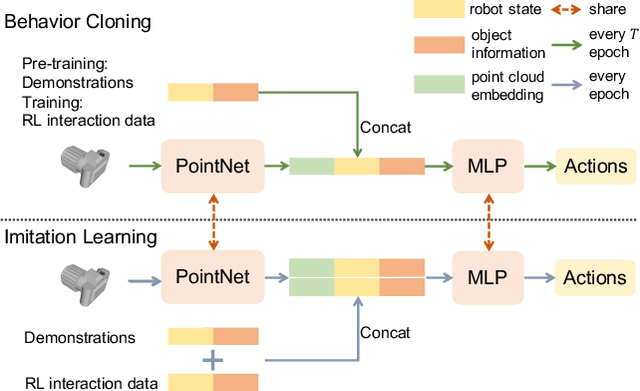
Dexterous manipulation with a multi-finger hand is one of the most challenging problems in robotics. While recent progress in imitation learning has largely improved the sample efficiency compared to Reinforcement Learning, the learned policy can hardly generalize to manipulate novel objects, given limited expert demonstrations. In this paper, we propose to learn dexterous manipulation using large-scale demonstrations with diverse 3D objects in a category, which are generated from a human grasp affordance model. This generalizes the policy to novel object instances within the same category. To train the policy, we propose a novel imitation learning objective jointly with a geometric representation learning objective using our demonstrations. By experimenting with relocating diverse objects in simulation, we show that our approach outperforms baselines with a large margin when manipulating novel objects. We also ablate the importance on 3D object representation learning for manipulation. We include videos, code, and additional information on the project website - https://kristery.github.io/ILAD/ .
Deep Vehicle Detection in Satellite Video
Apr 14, 2022



This work presents a deep learning approach for vehicle detection in satellite video. Vehicle detection is perhaps impossible in single EO satellite images due to the tininess of vehicles (4-10 pixel) and their similarity to the background. Instead, we consider satellite video which overcomes the lack of spatial information by temporal consistency of vehicle movement. A new spatiotemporal model of a compact $3 \times 3$ convolutional, neural network is proposed which neglects pooling layers and uses leaky ReLUs. Then we use a reformulation of the output heatmap including Non-Maximum-Suppression (NMS) for the final segmentation. Empirical results on two new annotated satellite videos reconfirm the applicability of this approach for vehicle detection. They more importantly indicate that pre-training on WAMI data and then fine-tuning on few annotated video frames for a new video is sufficient. In our experiment only five annotated images yield a $F_1$ score of 0.81 on a new video showing more complex traffic patterns than the Las Vegas video. Our best result on Las Vegas is a $F_1$ score of 0.87 which makes the proposed approach a leading method for this benchmark.
Sequence-Based Target Coin Prediction for Cryptocurrency Pump-and-Dump
Apr 21, 2022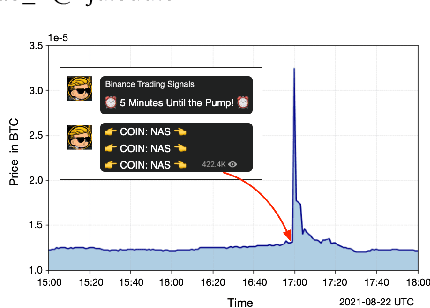
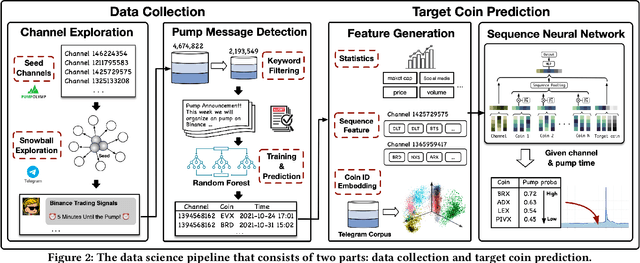
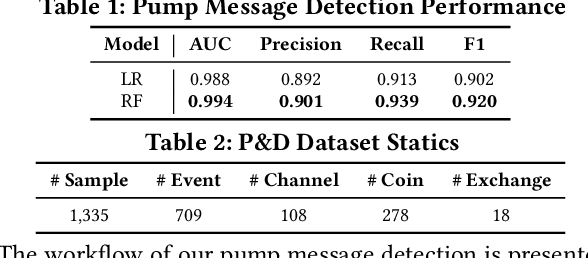
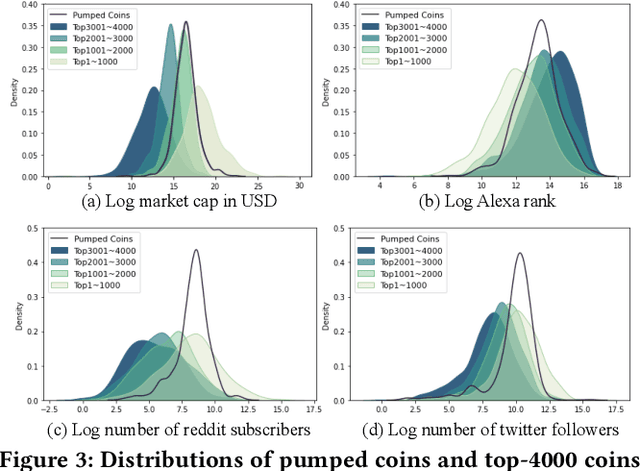
As the pump-and-dump schemes (P&Ds) proliferate in the cryptocurrency market, it becomes imperative to detect such fraudulent activities in advance, to inform potentially susceptible investors before they become victims. In this paper, we focus on the target coin prediction task, i.e., to predict the pump probability of all coins listed in the target exchange before a pump. We conduct a comprehensive study of the latest P&Ds, investigate 709 events organized in Telegram channels from Jan. 2019 to Jan. 2022, and unearth some abnormal yet interesting patterns of P&Ds. Empirical analysis demonstrates that pumped coins exhibit intra-channel homogeneity and inter-channel heterogeneity, which inspires us to develop a novel sequence-based neural network named SNN. Specifically, SNN encodes each channel's pump history as a sequence representation via a positional attention mechanism, which filters useful information and alleviates the noise introduced when the sequence length is long. We also identify and address the coin-side cold-start problem in a practical setting. Extensive experiments show a lift of 1.6% AUC and 41.0% Hit Ratio@3 brought by our method, making it well-suited for real-world application. As a side contribution, we release the source code of our entire data science pipeline on GitHub, along with the dataset tailored for studying the latest P&Ds.
Positioning Using Visible Light Communications: A Perspective Arcs Approach
Apr 18, 2022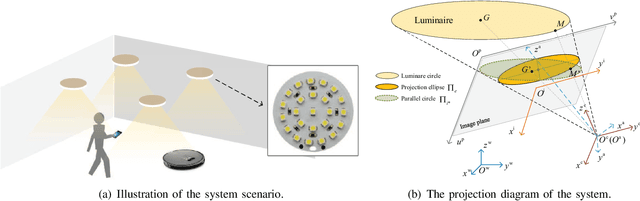
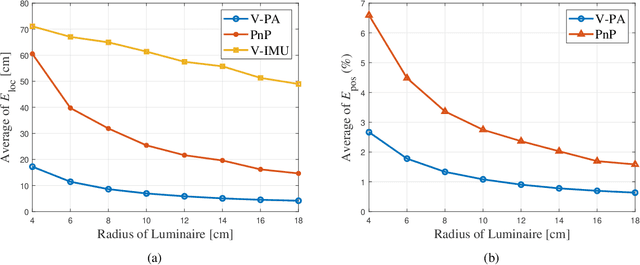
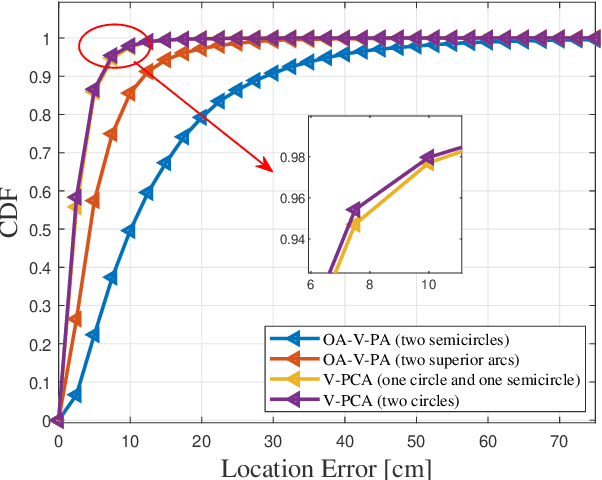
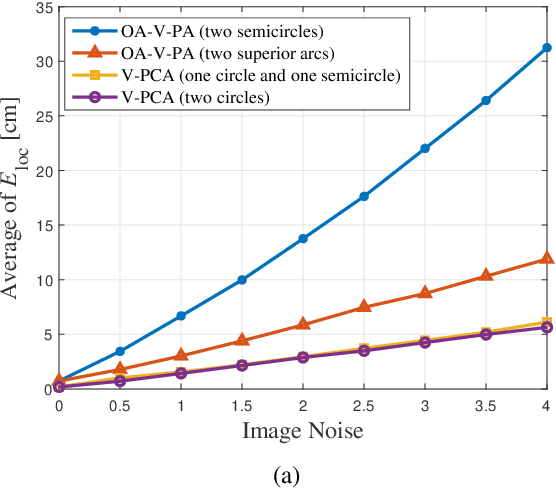
Visible light positioning (VLP) is an accurate indoor positioning technology that uses luminaires as transmitters. In particular, circular luminaires are a common source type for VLP, that are typically treated only as point sources for positioning, while ignoring their geometry characteristics. In this paper, the arc feature of the circular luminaire and the coordinate information obtained via visible light communication (VLC) are jointly used for VLC-enabled indoor positioning, and a novel perspective arcs approach is proposed. The proposed approach does not rely on any inertial measurement unit, and has no tilted angle limitations at the user. First, a VLC assisted perspective circle and arc algorithm (V-PCA) is proposed for a scenario in which a complete luminaire and an incomplete one can be captured by the user. Considering the cases in which parts of VLC links are blocked, an anti-occlusion VLC assisted perspective arcs algorithm (OA-V-PA) is proposed. Simulation results show that the proposed indoor positioning algorithm can achieve a 95th percentile positioning accuracy of around 10 cm. Moreover, an experimental prototype based on mobile phone is implemented, in which, a fused image processing method is proposed. Experimental results show that the average positioning accuracy is less than 5 cm.
The dangers in algorithms learning humans' values and irrationalities
Mar 01, 2022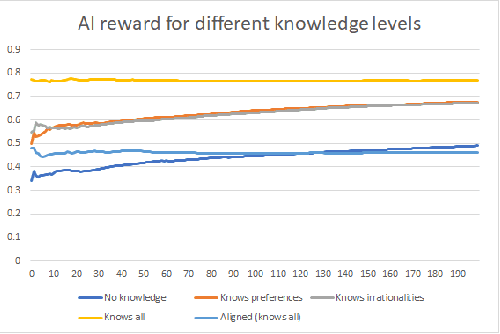
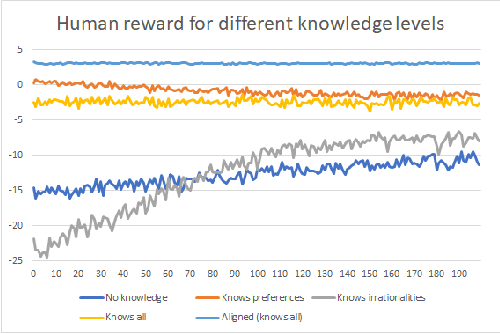
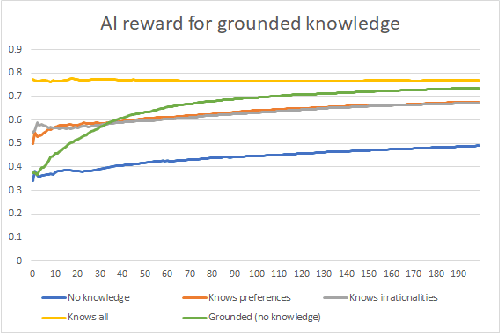
For an artificial intelligence (AI) to be aligned with human values (or human preferences), it must first learn those values. AI systems that are trained on human behavior, risk miscategorising human irrationalities as human values -- and then optimising for these irrationalities. Simply learning human values still carries risks: AI learning them will inevitably also gain information on human irrationalities and human behaviour/policy. Both of these can be dangerous: knowing human policy allows an AI to become generically more powerful (whether it is partially aligned or not aligned at all), while learning human irrationalities allows it to exploit humans without needing to provide value in return. This paper analyses the danger in developing artificial intelligence that learns about human irrationalities and human policy, and constructs a model recommendation system with various levels of information about human biases, human policy, and human values. It concludes that, whatever the power and knowledge of the AI, it is more dangerous for it to know human irrationalities than human values. Thus it is better for the AI to learn human values directly, rather than learning human biases and then deducing values from behaviour.
Revisiting Consistency Regularization for Semi-supervised Change Detection in Remote Sensing Images
Apr 21, 2022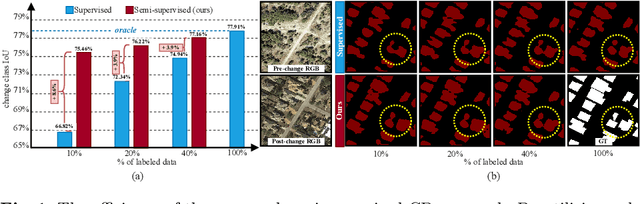
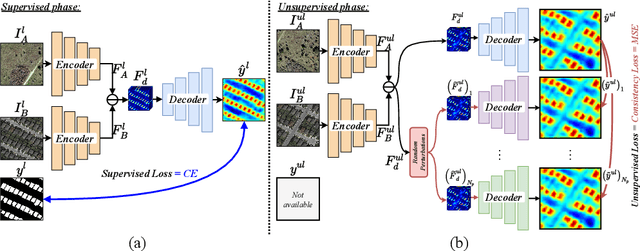
Remote-sensing (RS) Change Detection (CD) aims to detect "changes of interest" from co-registered bi-temporal images. The performance of existing deep supervised CD methods is attributed to the large amounts of annotated data used to train the networks. However, annotating large amounts of remote sensing images is labor-intensive and expensive, particularly with bi-temporal images, as it requires pixel-wise comparisons by a human expert. On the other hand, we often have access to unlimited unlabeled multi-temporal RS imagery thanks to ever-increasing earth observation programs. In this paper, we propose a simple yet effective way to leverage the information from unlabeled bi-temporal images to improve the performance of CD approaches. More specifically, we propose a semi-supervised CD model in which we formulate an unsupervised CD loss in addition to the supervised Cross-Entropy (CE) loss by constraining the output change probability map of a given unlabeled bi-temporal image pair to be consistent under the small random perturbations applied on the deep feature difference map that is obtained by subtracting their latent feature representations. Experiments conducted on two publicly available CD datasets show that the proposed semi-supervised CD method can reach closer to the performance of supervised CD even with access to as little as 10% of the annotated training data. Code available at https://github.com/wgcban/SemiCD
Vision Transformer Equipped with Neural Resizer on Facial Expression Recognition Task
Apr 05, 2022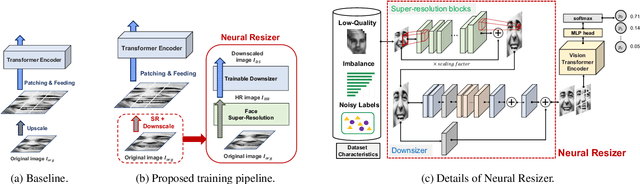
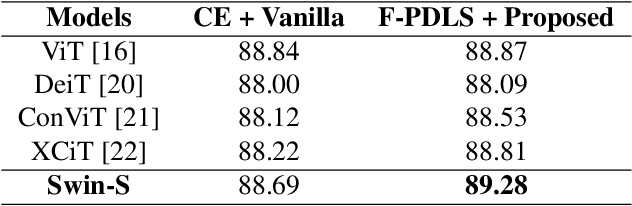
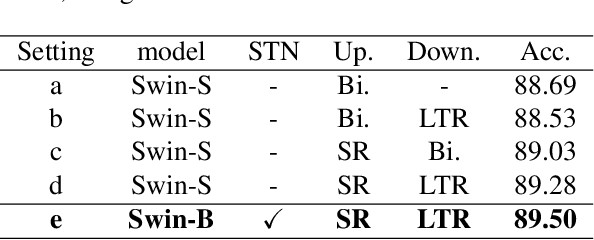

When it comes to wild conditions, Facial Expression Recognition is often challenged with low-quality data and imbalanced, ambiguous labels. This field has much benefited from CNN based approaches; however, CNN models have structural limitation to see the facial regions in distant. As a remedy, Transformer has been introduced to vision fields with global receptive field, but requires adjusting input spatial size to the pretrained models to enjoy their strong inductive bias at hands. We herein raise a question whether using the deterministic interpolation method is enough to feed low-resolution data to Transformer. In this work, we propose a novel training framework, Neural Resizer, to support Transformer by compensating information and downscaling in a data-driven manner trained with loss function balancing the noisiness and imbalance. Experiments show our Neural Resizer with F-PDLS loss function improves the performance with Transformer variants in general and nearly achieves the state-of-the-art performance.
A Weibo Dataset for the 2022 Russo-Ukrainian Crisis
Mar 09, 2022
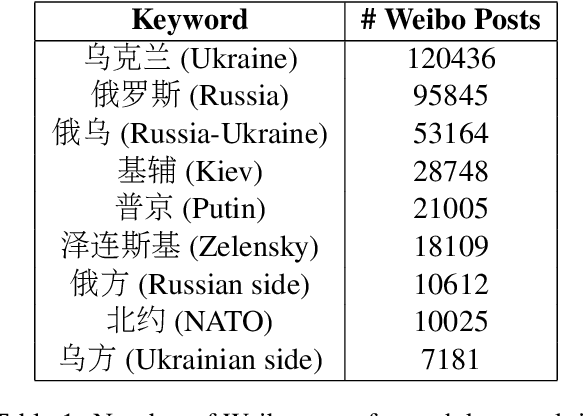
Online social networks such as Twitter and Weibo play an important role in how people stay informed and exchange reactions. Each crisis encompasses a new opportunity to study the portability of models for various tasks (e.g., information extraction, complex event understanding, misinformation detection, etc.), due to differences in domain, entities, and event types. We present the Russia-Ukraine Crisis Weibo (RUW) dataset, with over 3.5M user posts and comments in the first release. Our data is available at https://github.com/yrf1/RussiaUkraine_weibo_dataset.
A Novel Image Descriptor with Aggregated Semantic Skeleton Representation for Long-term Visual Place Recognition
Feb 08, 2022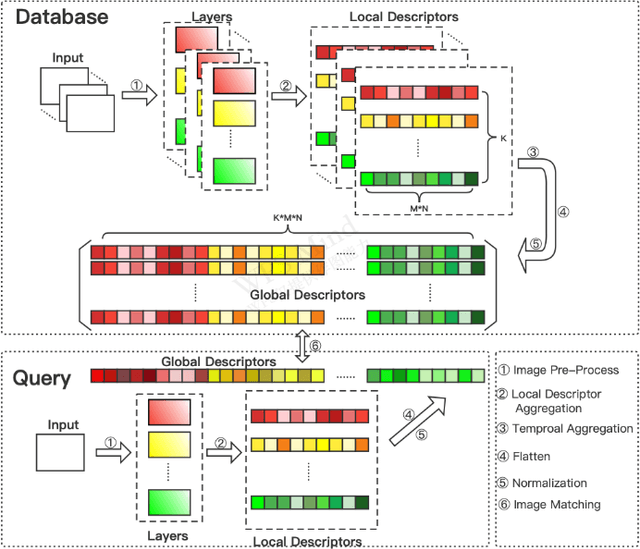
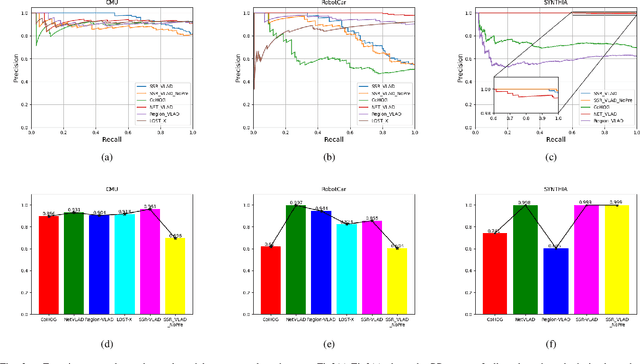
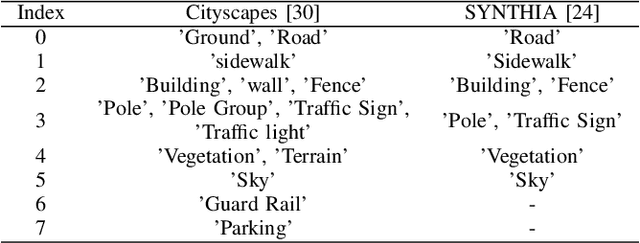
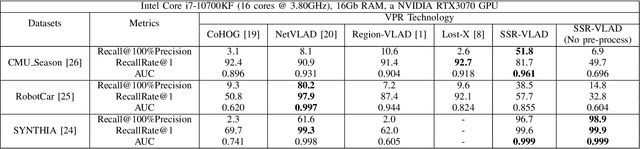
In a Simultaneous Localization and Mapping (SLAM) system, a loop-closure can eliminate accumulated errors, which is accomplished by Visual Place Recognition (VPR), a task that retrieves the current scene from a set of pre-stored sequential images through matching specific scene-descriptors. In urban scenes, the appearance variation caused by seasons and illumination has brought great challenges to the robustness of scene descriptors. Semantic segmentation images can not only deliver the shape information of objects but also their categories and spatial relations that will not be affected by the appearance variation of the scene. Innovated by the Vector of Locally Aggregated Descriptor (VLAD), in this paper, we propose a novel image descriptor with aggregated semantic skeleton representation (SSR), dubbed SSR-VLAD, for the VPR under drastic appearance-variation of environments. The SSR-VLAD of one image aggregates the semantic skeleton features of each category and encodes the spatial-temporal distribution information of the image semantic information. We conduct a series of experiments on three public datasets of challenging urban scenes. Compared with four state-of-the-art VPR methods- CoHOG, NetVLAD, LOST-X, and Region-VLAD, VPR by matching SSR-VLAD outperforms those methods and maintains competitive real-time performance at the same time.
Neural Enhanced Belief Propagation for Data Association in Multiobject Tracking
Mar 26, 2022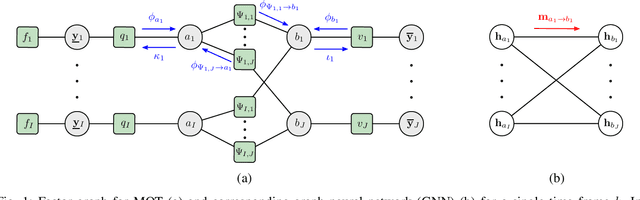
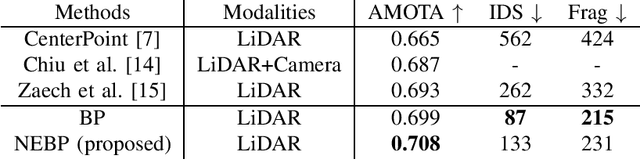
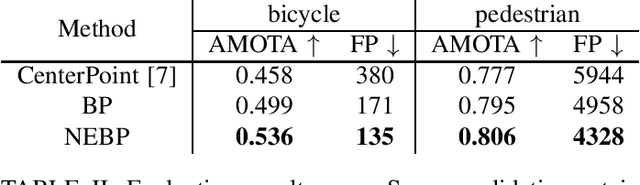
Situation-aware technologies enabled by multiobject tracking (MOT) methods will create new services and applications in fields such as autonomous navigation and applied ocean sciences. Belief propagation (BP) is a state-of-the-art method for Bayesian MOT but fully relies on a statistical model and preprocessed sensor measurements. In this paper, we establish a hybrid method for model-based and data-driven MOT. The proposed neural enhanced belief propagation (NEBP) approach complements BP by information learned from raw sensor data with the goal to improve data association and to reject false alarm measurements. We evaluate the performance of our NEBP approach for MOT on the nuScenes autonomous driving dataset and demonstrate that it can outperform state-of-the-art reference methods.