 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Active Visual Information Gathering for Vision-Language Navigation
Jul 15, 2020
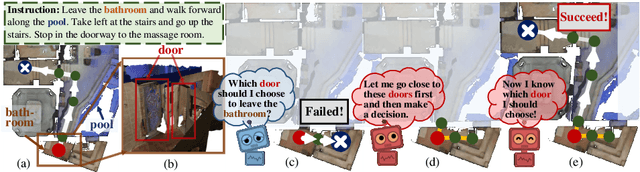
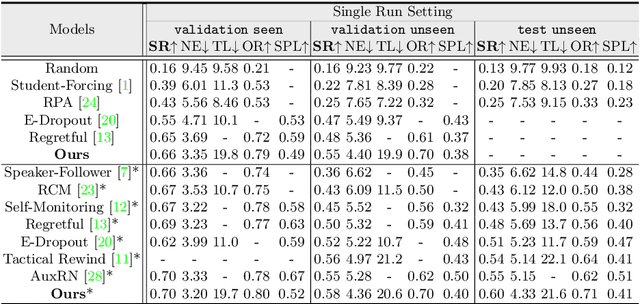
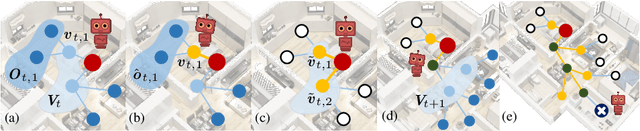
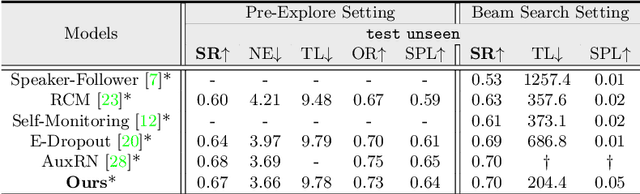
Vision-language navigation (VLN) is the task of entailing an agent to carry out navigational instructions inside photo-realistic environments. One of the key challenges in VLN is how to conduct a robust navigation by mitigating the uncertainty caused by ambiguous instructions and insufficient observation of the environment. Agents trained by current approaches typically suffer from this and would consequently struggle to avoid random and inefficient actions at every step. In contrast, when humans face such a challenge, they can still maintain robust navigation by actively exploring the surroundings to gather more information and thus make more confident navigation decisions. This work draws inspiration from human navigation behavior and endows an agent with an active information gathering ability for a more intelligent vision-language navigation policy. To achieve this, we propose an end-to-end framework for learning an exploration policy that decides i) when and where to explore, ii) what information is worth gathering during exploration, and iii) how to adjust the navigation decision after the exploration. The experimental results show promising exploration strategies emerged from training, which leads to significant boost in navigation performance. On the R2R challenge leaderboard, our agent gets promising results all three VLN settings, i.e., single run, pre-exploration, and beam search.
Deep Embeddings for Robust User-Based Amateur Vocal Percussion Classification
Apr 10, 2022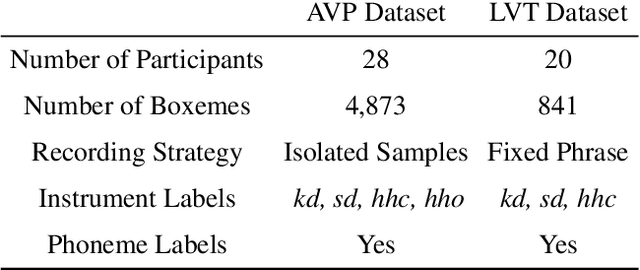
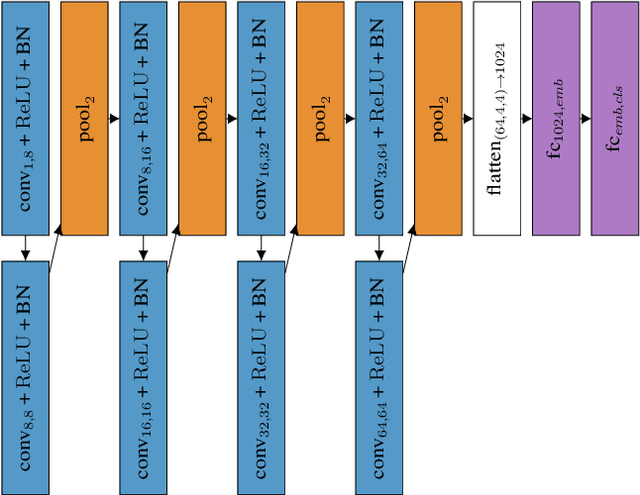

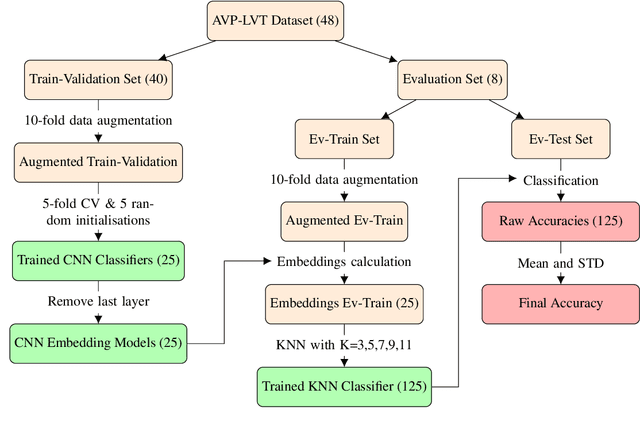
Vocal Percussion Transcription (VPT) is concerned with the automatic detection and classification of vocal percussion sound events, allowing music creators and producers to sketch drum lines on the fly. Classifier algorithms in VPT systems learn best from small user-specific datasets, which usually restrict modelling to small input feature sets to avoid data overfitting. This study explores several deep supervised learning strategies to obtain informative feature sets for amateur vocal percussion classification. We evaluated the performance of these sets on regular vocal percussion classification tasks and compared them with several baseline approaches including feature selection methods and a speech recognition engine. These proposed learning models were supervised with several label sets containing information from four different levels of abstraction: instrument-level, syllable-level, phoneme-level, and boxeme-level. Results suggest that convolutional neural networks supervised with syllable-level annotations produced the most informative embeddings for classification, which can be used as input representations to fit classifiers with. Finally, we used back-propagation-based saliency maps to investigate the importance of different spectrogram regions for feature learning.
Simultaneous Communication and Tracking in Arbitrary Trajectories via Beam-Space Processing
Mar 29, 2022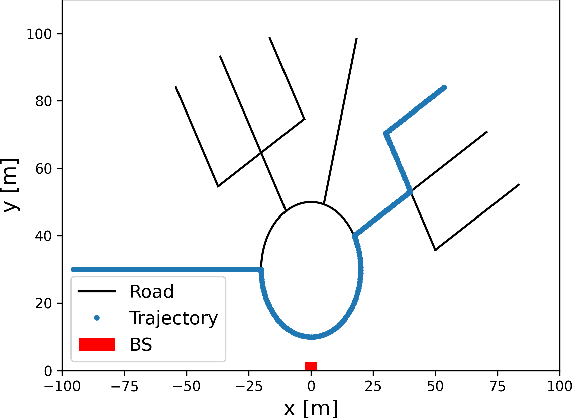
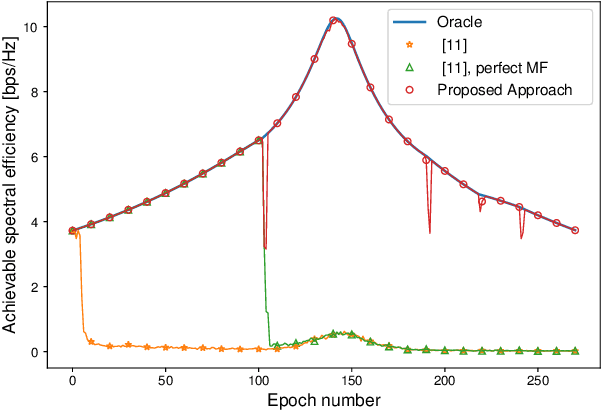
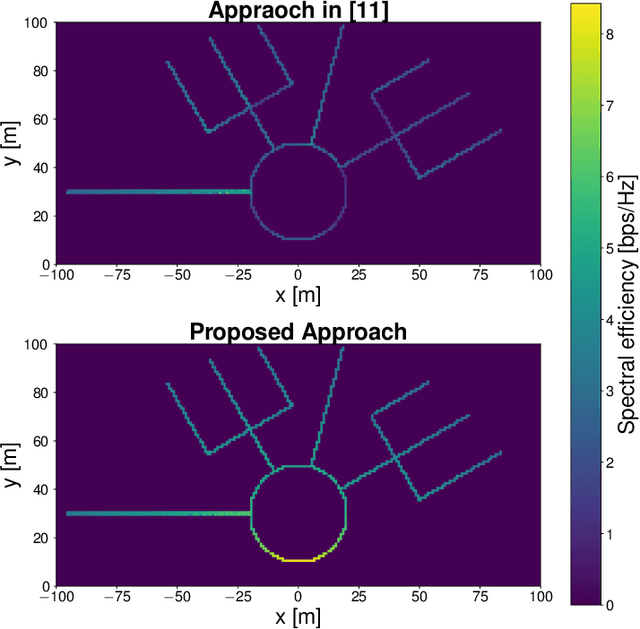
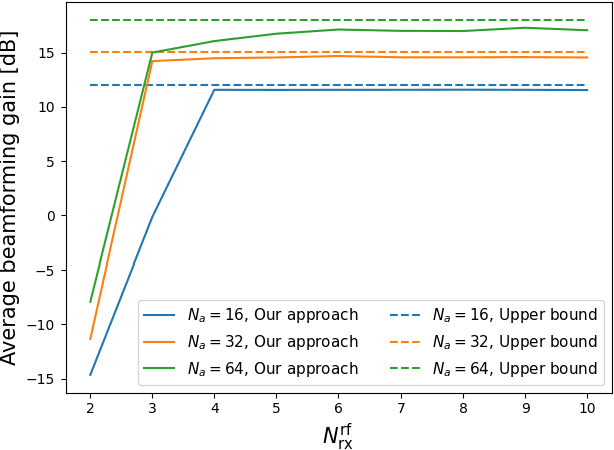
In this paper, we develop a beam tracking scheme for an orthogonal frequency division multiplexing (OFDM) Integrated Sensing and Communication (ISAC) system with a hybrid digital analog (HDA) architecture operating in the millimeter wave (mmWave) band. Our tracking method consists of an estimation step inspired by radar signal processing techniques, and a prediction step based on simple kinematic equations. The hybrid architecture exploits the predicted state information to focus only on the directions of interest, trading off beamforming gain, hardware complexity and multistream processing capabilities. Our extensive simulations in arbitrary trajectories show that the proposed method can outperform state of the art beam tracking methods in terms of prediction accuracy and consequently achievable communication rate, and is fully capable of dealing with highly non-linear dynamic motion patterns.
Measurement-based Admission Control in Sliced Networks: A Best Arm Identification Approach
Apr 14, 2022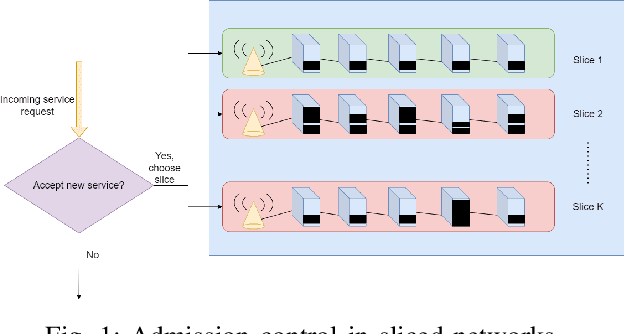
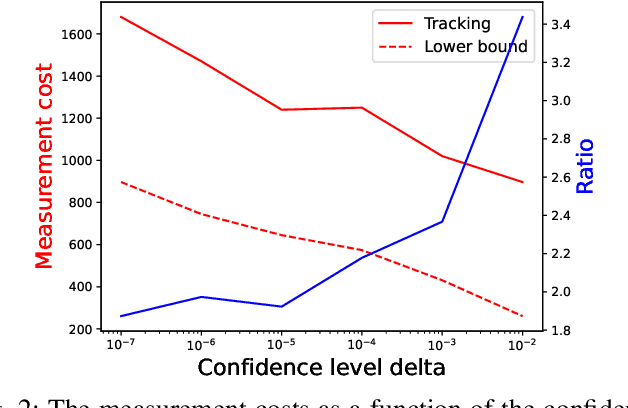
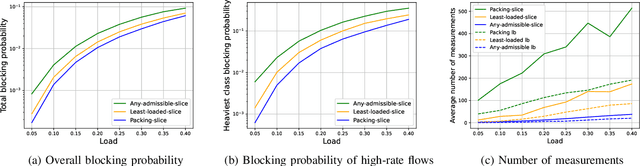

In sliced networks, the shared tenancy of slices requires adaptive admission control of data flows, based on measurements of network resources. In this paper, we investigate the design of measurement-based admission control schemes, deciding whether a new data flow can be admitted and in this case, on which slice. The objective is to devise a joint measurement and decision strategy that returns a correct decision (e.g., the least loaded slice) with a certain level of confidence while minimizing the measurement cost (the number of measurements made before committing to the decision). We study the design of such strategies for several natural admission criteria specifying what a correct decision is. For each of these criteria, using tools from best arm identification in bandits, we first derive an explicit information-theoretical lower bound on the cost of any algorithm returning the correct decision with fixed confidence. We then devise a joint measurement and decision strategy achieving this theoretical limit. We compare empirically the measurement costs of these strategies, and compare them both to the lower bounds as well as a naive measurement scheme. We find that our algorithm significantly outperforms the naive scheme (by a factor $2-8$).
Cross-Task Instance Representation Interactions and Label Dependencies for Joint Information Extraction with Graph Convolutional Networks
Mar 18, 2021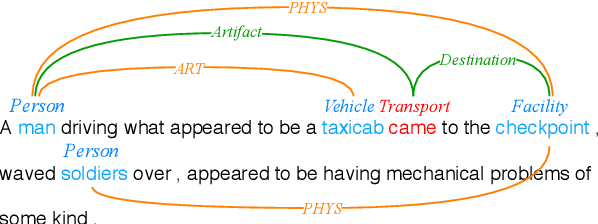
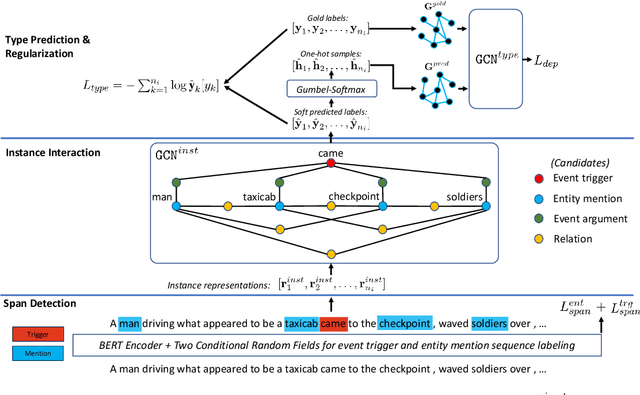
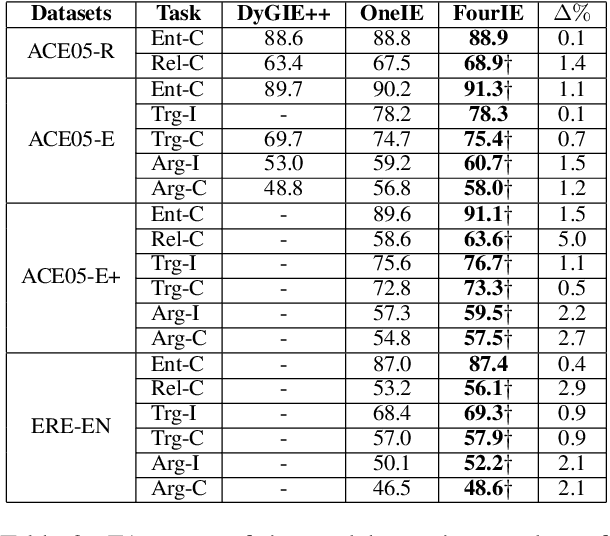
Existing works on information extraction (IE) have mainly solved the four main tasks separately (entity mention recognition, relation extraction, event trigger detection, and argument extraction), thus failing to benefit from inter-dependencies between tasks. This paper presents a novel deep learning model to simultaneously solve the four tasks of IE in a single model (called FourIE). Compared to few prior work on jointly performing four IE tasks, FourIE features two novel contributions to capture inter-dependencies between tasks. First, at the representation level, we introduce an interaction graph between instances of the four tasks that is used to enrich the prediction representation for one instance with those from related instances of other tasks. Second, at the label level, we propose a dependency graph for the information types in the four IE tasks that captures the connections between the types expressed in an input sentence. A new regularization mechanism is introduced to enforce the consistency between the golden and predicted type dependency graphs to improve representation learning. We show that the proposed model achieves the state-of-the-art performance for joint IE on both monolingual and multilingual learning settings with three different languages.
Sequence-Based Target Coin Prediction for Cryptocurrency Pump-and-Dump
Apr 21, 2022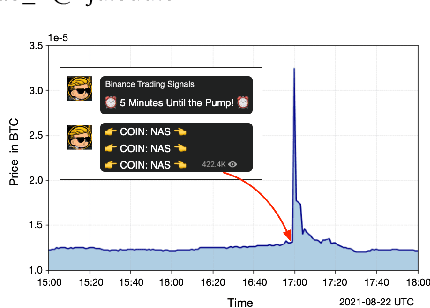
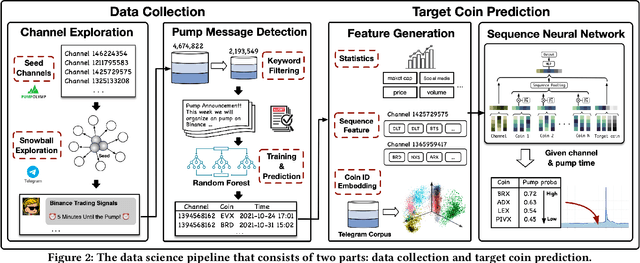
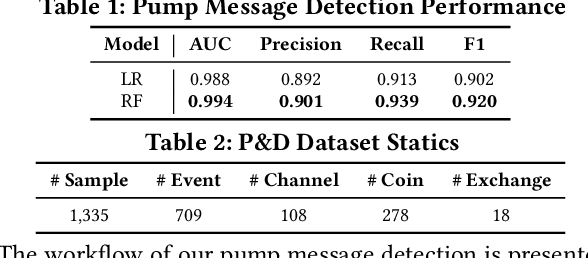
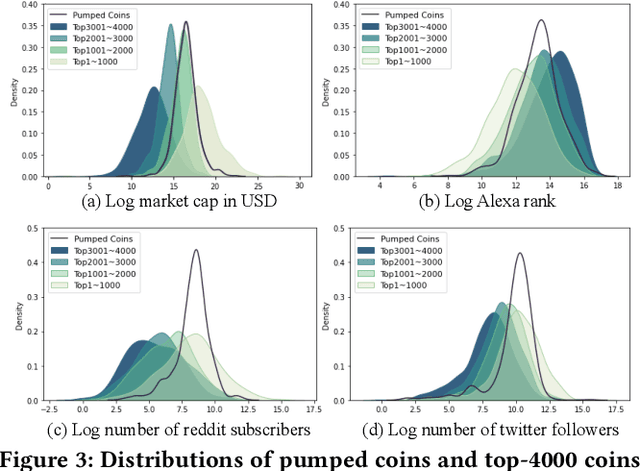
As the pump-and-dump schemes (P&Ds) proliferate in the cryptocurrency market, it becomes imperative to detect such fraudulent activities in advance, to inform potentially susceptible investors before they become victims. In this paper, we focus on the target coin prediction task, i.e., to predict the pump probability of all coins listed in the target exchange before a pump. We conduct a comprehensive study of the latest P&Ds, investigate 709 events organized in Telegram channels from Jan. 2019 to Jan. 2022, and unearth some abnormal yet interesting patterns of P&Ds. Empirical analysis demonstrates that pumped coins exhibit intra-channel homogeneity and inter-channel heterogeneity, which inspires us to develop a novel sequence-based neural network named SNN. Specifically, SNN encodes each channel's pump history as a sequence representation via a positional attention mechanism, which filters useful information and alleviates the noise introduced when the sequence length is long. We also identify and address the coin-side cold-start problem in a practical setting. Extensive experiments show a lift of 1.6% AUC and 41.0% Hit Ratio@3 brought by our method, making it well-suited for real-world application. As a side contribution, we release the source code of our entire data science pipeline on GitHub, along with the dataset tailored for studying the latest P&Ds.
Deep Vehicle Detection in Satellite Video
Apr 14, 2022



This work presents a deep learning approach for vehicle detection in satellite video. Vehicle detection is perhaps impossible in single EO satellite images due to the tininess of vehicles (4-10 pixel) and their similarity to the background. Instead, we consider satellite video which overcomes the lack of spatial information by temporal consistency of vehicle movement. A new spatiotemporal model of a compact $3 \times 3$ convolutional, neural network is proposed which neglects pooling layers and uses leaky ReLUs. Then we use a reformulation of the output heatmap including Non-Maximum-Suppression (NMS) for the final segmentation. Empirical results on two new annotated satellite videos reconfirm the applicability of this approach for vehicle detection. They more importantly indicate that pre-training on WAMI data and then fine-tuning on few annotated video frames for a new video is sufficient. In our experiment only five annotated images yield a $F_1$ score of 0.81 on a new video showing more complex traffic patterns than the Las Vegas video. Our best result on Las Vegas is a $F_1$ score of 0.87 which makes the proposed approach a leading method for this benchmark.
Revisiting Consistency Regularization for Semi-supervised Change Detection in Remote Sensing Images
Apr 21, 2022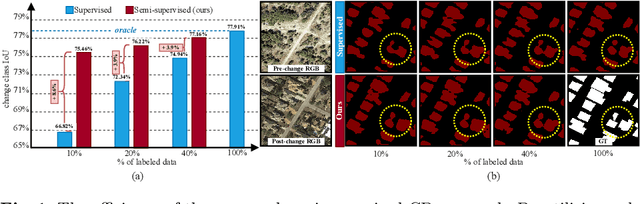
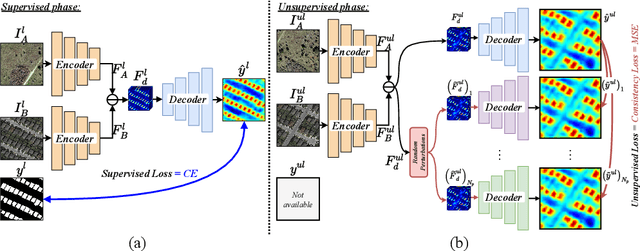
Remote-sensing (RS) Change Detection (CD) aims to detect "changes of interest" from co-registered bi-temporal images. The performance of existing deep supervised CD methods is attributed to the large amounts of annotated data used to train the networks. However, annotating large amounts of remote sensing images is labor-intensive and expensive, particularly with bi-temporal images, as it requires pixel-wise comparisons by a human expert. On the other hand, we often have access to unlimited unlabeled multi-temporal RS imagery thanks to ever-increasing earth observation programs. In this paper, we propose a simple yet effective way to leverage the information from unlabeled bi-temporal images to improve the performance of CD approaches. More specifically, we propose a semi-supervised CD model in which we formulate an unsupervised CD loss in addition to the supervised Cross-Entropy (CE) loss by constraining the output change probability map of a given unlabeled bi-temporal image pair to be consistent under the small random perturbations applied on the deep feature difference map that is obtained by subtracting their latent feature representations. Experiments conducted on two publicly available CD datasets show that the proposed semi-supervised CD method can reach closer to the performance of supervised CD even with access to as little as 10% of the annotated training data. Code available at https://github.com/wgcban/SemiCD
Online Distributed Evolutionary Optimization of Time Division Multiple Access Protocols
Apr 27, 2022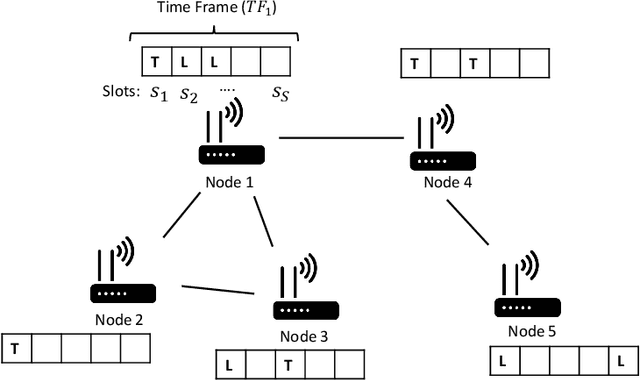
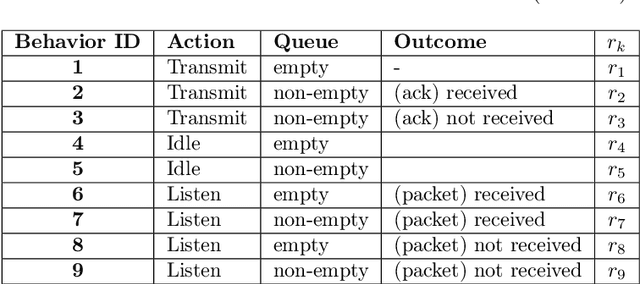
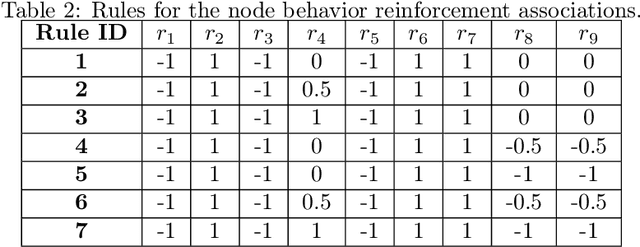
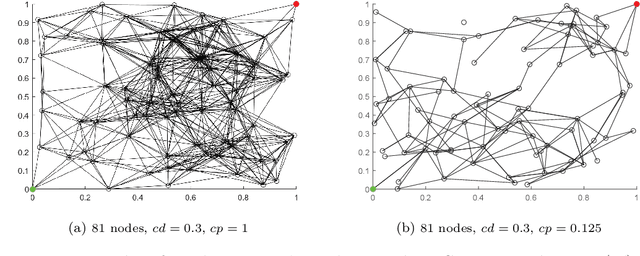
With the advent of cheap, miniaturized electronics, ubiquitous networking has reached an unprecedented level of complexity, scale and heterogeneity, becoming the core of several modern applications such as smart industry, smart buildings and smart cities. A crucial element for network performance is the protocol stack, namely the sets of rules and data formats that determine how the nodes in the network exchange information. A great effort has been put to devise formal techniques to synthesize (offline) network protocols, starting from system specifications and strict assumptions on the network environment. However, offline design can be hard to apply in the most modern network applications, either due to numerical complexity, or to the fact that the environment might be unknown and the specifications might not available. In these cases, online protocol design and adaptation has the potential to offer a much more scalable and robust solution. Nevertheless, so far only a few attempts have been done towards online automatic protocol design. Here, we envision a protocol as an emergent property of a network, obtained by an environment-driven Distributed Hill Climbing algorithm that uses node-local reinforcement signals to evolve, at runtime and without any central coordination, a network protocol from scratch. We test this approach with a 3-state Time Division Multiple Access (TDMA) Medium Access Control (MAC) protocol and we observe its emergence in networks of various scales and with various settings. We also show how Distributed Hill Climbing can reach different trade-offs in terms of energy consumption and protocol performance.
Explaining black-box text classifiers for disease-treatment information extraction
Oct 21, 2020
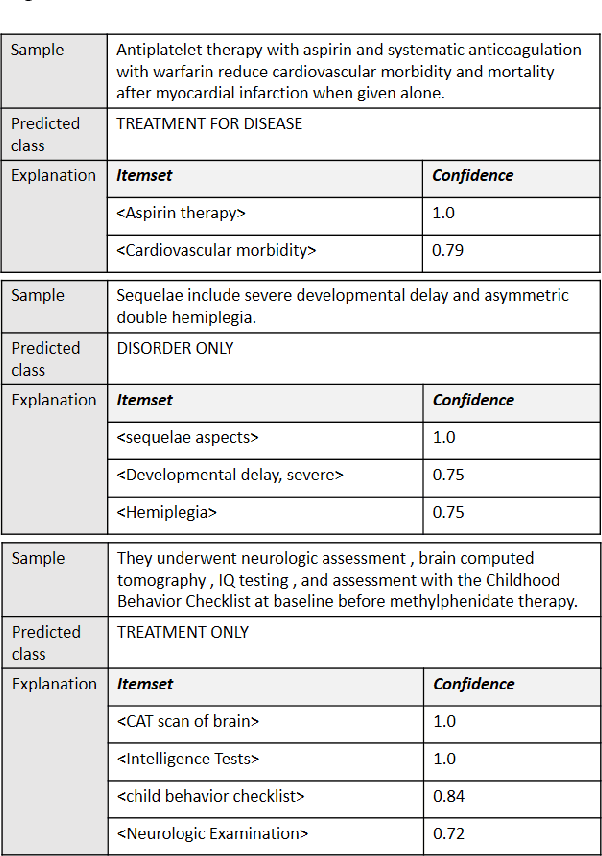
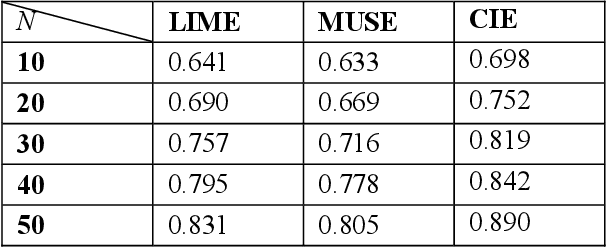
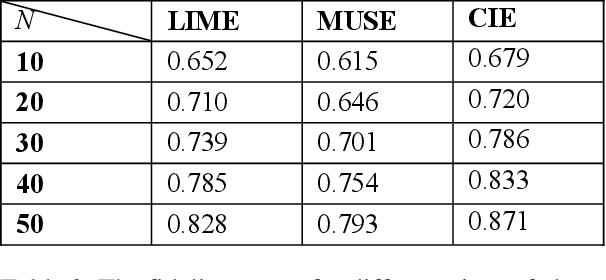
Deep neural networks and other intricate Artificial Intelligence (AI) models have reached high levels of accuracy on many biomedical natural language processing tasks. However, their applicability in real-world use cases may be limited due to their vague inner working and decision logic. A post-hoc explanation method can approximate the behavior of a black-box AI model by extracting relationships between feature values and outcomes. In this paper, we introduce a post-hoc explanation method that utilizes confident itemsets to approximate the behavior of black-box classifiers for medical information extraction. Incorporating medical concepts and semantics into the explanation process, our explanator finds semantic relations between inputs and outputs in different parts of the decision space of a black-box classifier. The experimental results show that our explanation method can outperform perturbation and decision set based explanators in terms of fidelity and interpretability of explanations produced for predictions on a disease-treatment information extraction task.