 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automated Audio Captioning using Audio Event Clues
Apr 18, 2022
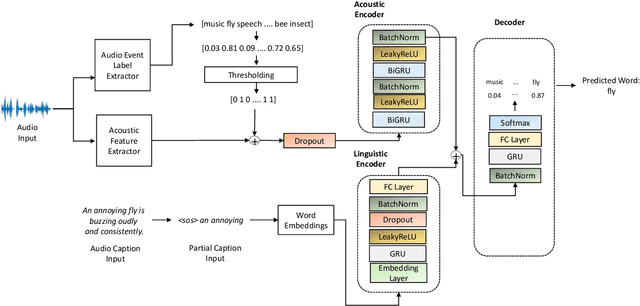
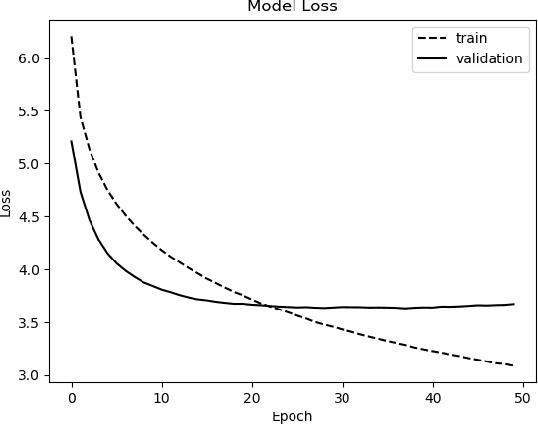
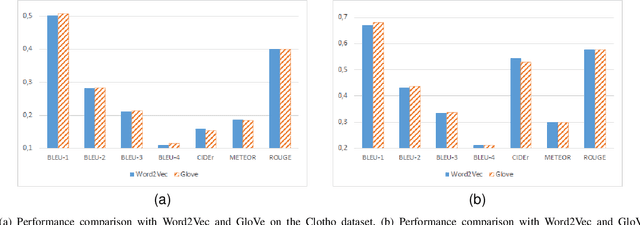

Audio captioning is an important research area that aims to generate meaningful descriptions for audio clips. Most of the existing research extracts acoustic features of audio clips as input to encoder-decoder and transformer architectures to produce the captions in a sequence-to-sequence manner. Due to data insufficiency and the architecture's inadequate learning capacity, additional information is needed to generate natural language sentences, as well as acoustic features. To address these problems, an encoder-decoder architecture is proposed that learns from both acoustic features and extracted audio event labels as inputs. The proposed model is based on pre-trained acoustic features and audio event detection. Various experiments used different acoustic features, word embedding models, audio event label extraction methods, and implementation configurations to show which combinations have better performance on the audio captioning task. Results of the extensive experiments on multiple datasets show that using audio event labels with the acoustic features improves the recognition performance and the proposed method either outperforms or achieves competitive results with the state-of-the-art models.
Multichannel Speech Separation with Narrow-band Conformer
Apr 09, 2022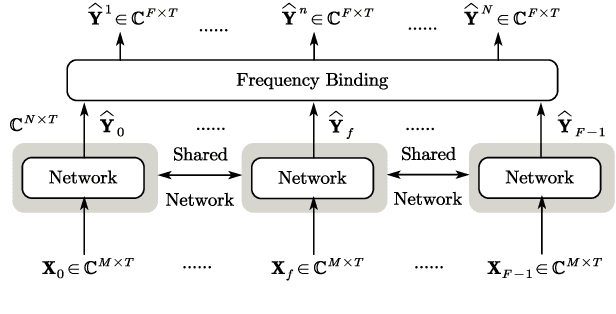
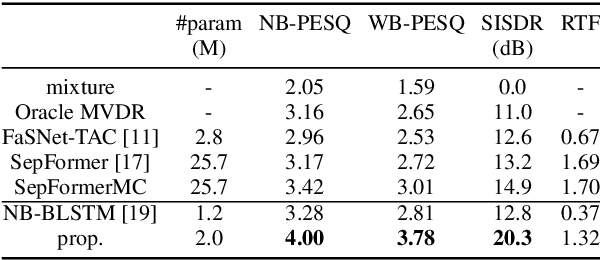
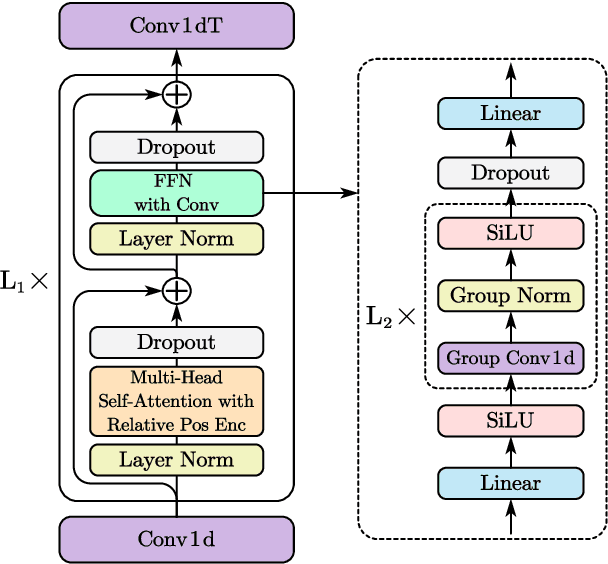
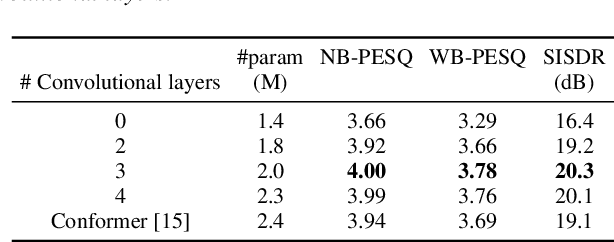
This work proposes a multichannel speech separation method with narrow-band Conformer (named NBC). The network is trained to learn to automatically exploit narrow-band speech separation information, such as spatial vector clustering of multiple speakers. Specifically, in the short-time Fourier transform (STFT) domain, the network processes each frequency independently, and is shared by all frequencies. For one frequency, the network inputs the STFT coefficients of multichannel mixture signals, and predicts the STFT coefficients of separated speech signals. Clustering of spatial vectors shares a similar principle with the self-attention mechanism in the sense of computing the similarity of vectors and then aggregating similar vectors. Therefore, Conformer would be especially suitable for the present problem. Experiments show that the proposed narrow-band Conformer achieves better speech separation performance than other state-of-the-art methods by a large margin.
Nonnegative-Constrained Joint Collaborative Representation with Union Dictionary for Hyperspectral Anomaly Detection
Mar 18, 2022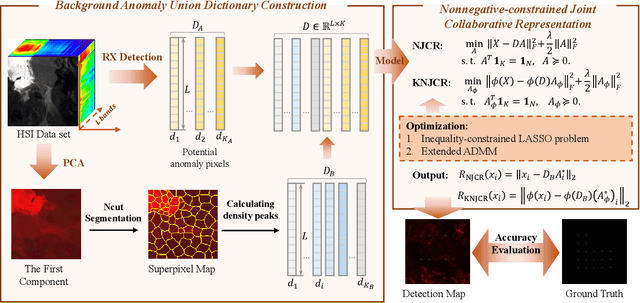
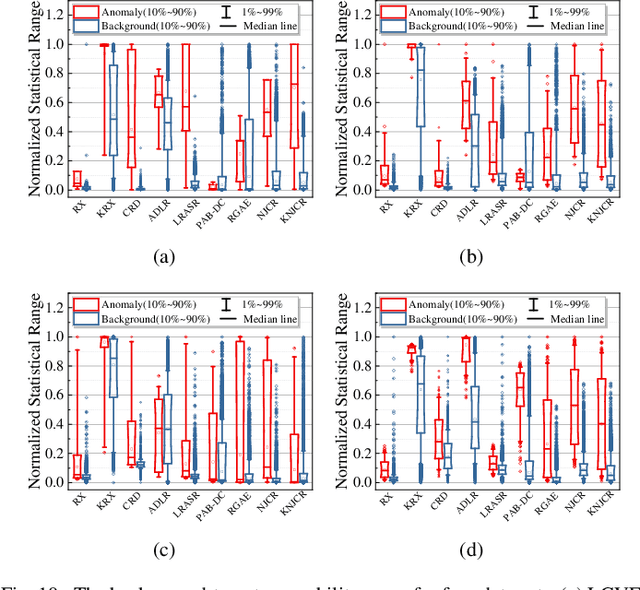
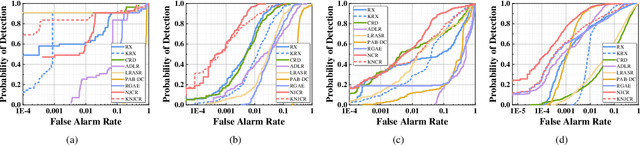
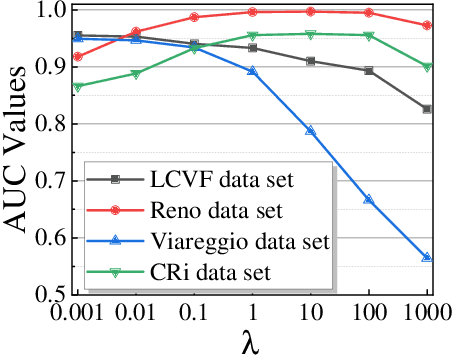
Recently, many collaborative representation-based (CR) algorithms have been proposed for hyperspectral anomaly detection. CR-based detectors approximate the image by a linear combination of background dictionaries and the coefficient matrix, and derive the detection map by utilizing recovery residuals. However, these CR-based detectors are often established on the premise of precise background features and strong image representation, which are very difficult to obtain. In addition, pursuing the coefficient matrix reinforced by the general $l_2$-min is very time consuming. To address these issues, a nonnegative-constrained joint collaborative representation model is proposed in this paper for the hyperspectral anomaly detection task. To extract reliable samples, a union dictionary consisting of background and anomaly sub-dictionaries is designed, where the background sub-dictionary is obtained at the superpixel level and the anomaly sub-dictionary is extracted by the pre-detection process. And the coefficient matrix is jointly optimized by the Frobenius norm regularization with a nonnegative constraint and a sum-to-one constraint. After the optimization process, the abnormal information is finally derived by calculating the residuals that exclude the assumed background information. To conduct comparable experiments, the proposed nonnegative-constrained joint collaborative representation (NJCR) model and its kernel version (KNJCR) are tested in four HSI data sets and achieve superior results compared with other state-of-the-art detectors.
Multi-task transfer learning for finding actionable information from crisis-related messages on social media
Feb 26, 2021
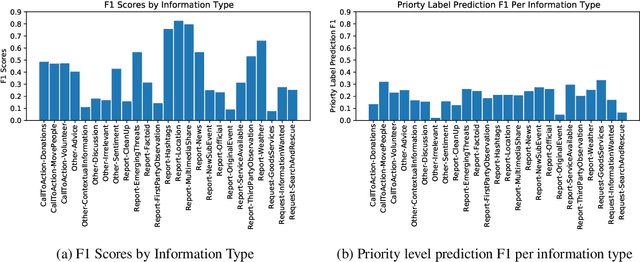
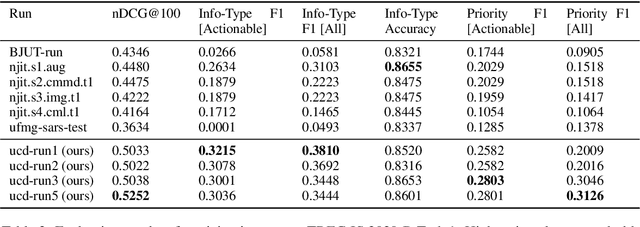
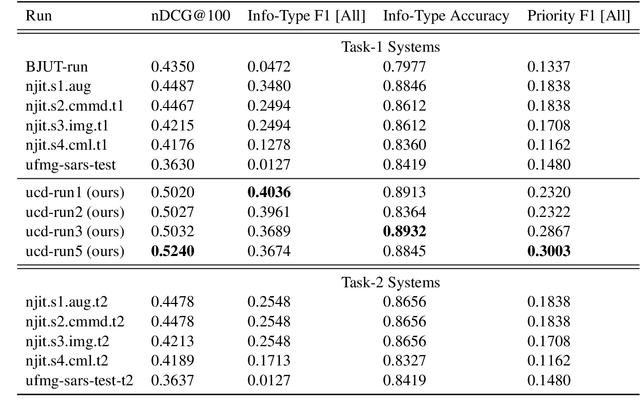
The Incident streams (IS) track is a research challenge aimed at finding important information from social media during crises for emergency response purposes. More specifically, given a stream of crisis-related tweets, the IS challenge asks a participating system to 1) classify what the types of users' concerns or needs are expressed in each tweet, known as the information type (IT) classification task and 2) estimate how critical each tweet is with regard to emergency response, known as the priority level prediction task. In this paper, we describe our multi-task transfer learning approach for this challenge. Our approach leverages state-of-the-art transformer models including both encoder-based models such as BERT and a sequence-to-sequence based T5 for joint transfer learning on the two tasks. Based on this approach, we submitted several runs to the track. The returned evaluation results show that our runs substantially outperform other participating runs in both IT classification and priority level prediction.
BBA-net: A bi-branch attention network for crowd counting
Jan 22, 2022
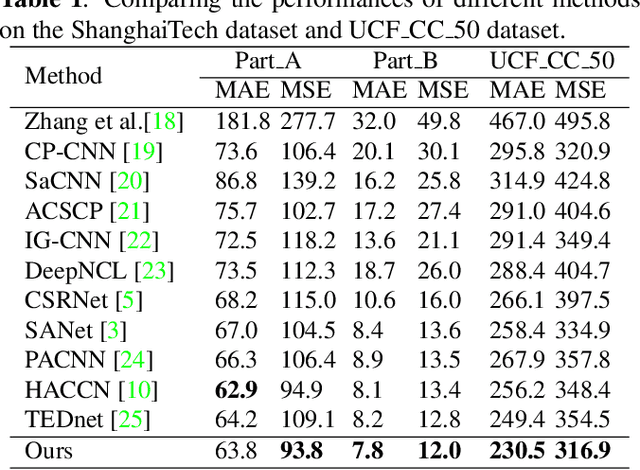
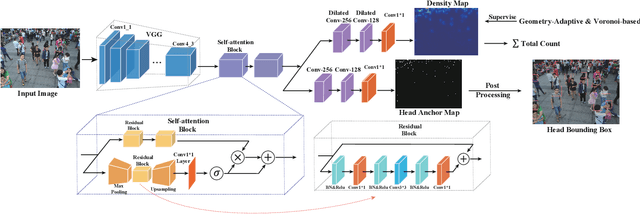

In the field of crowd counting, the current mainstream CNN-based regression methods simply extract the density information of pedestrians without finding the position of each person. This makes the output of the network often found to contain incorrect responses, which may erroneously estimate the total number and not conducive to the interpretation of the algorithm. To this end, we propose a Bi-Branch Attention Network (BBA-NET) for crowd counting, which has three innovation points. i) A two-branch architecture is used to estimate the density information and location information separately. ii) Attention mechanism is used to facilitate feature extraction, which can reduce false responses. iii) A new density map generation method combining geometric adaptation and Voronoi split is introduced. Our method can integrate the pedestrian's head and body information to enhance the feature expression ability of the density map. Extensive experiments performed on two public datasets show that our method achieves a lower crowd counting error compared to other state-of-the-art methods.
An Empirical Investigation of 3D Anomaly Detection and Segmentation
Mar 10, 2022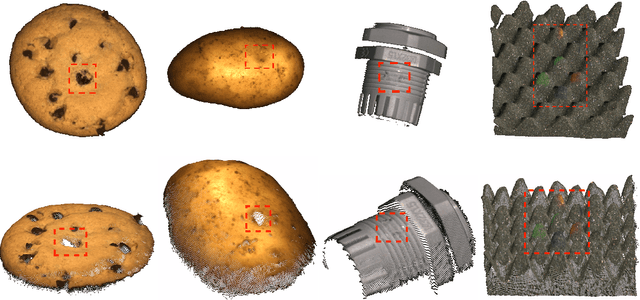

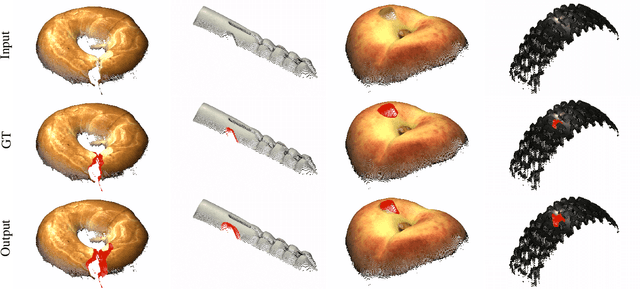
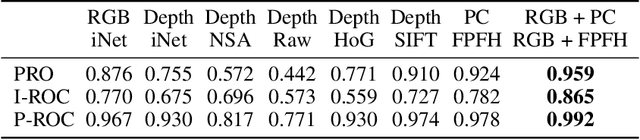
Anomaly detection and segmentation in images has made tremendous progress in recent years while 3D information has often been ignored. The objective of this paper is to further understand the benefit and role of 3D as opposed to color in image anomaly detection. Our study begins by presenting a surprising finding: standard color-only anomaly segmentation methods, when applied to 3D datasets, significantly outperform all current methods. On the other hand, we observe that color-only methods are insufficient for images containing geometric anomalies where shape cannot be unambiguously inferred from 2D. This suggests that better 3D methods are needed. We investigate different representations for 3D anomaly detection and discover that handcrafted orientation-invariant representations are unreasonably effective on this task. We uncover a simple 3D-only method that outperforms all recent approaches while not using deep learning, external pretraining datasets, or color information. As the 3D-only method cannot detect color and texture anomalies, we combine it with 2D color features, granting us the best current results by a large margin (Pixel-wise ROCAUC: 99.2%, PRO: 95.9% on MVTec 3D-AD). We conclude by discussing future challenges for 3D anomaly detection and segmentation.
Counterfactual Learning To Rank for Utility-Maximizing Query Autocompletion
Apr 22, 2022

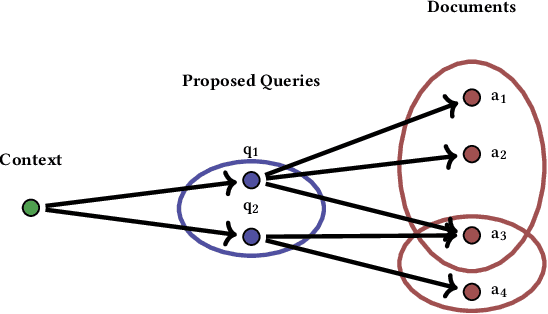
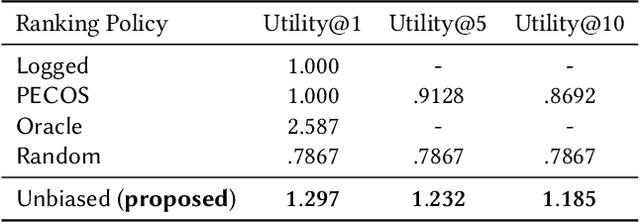
Conventional methods for query autocompletion aim to predict which completed query a user will select from a list. A shortcoming of this approach is that users often do not know which query will provide the best retrieval performance on the current information retrieval system, meaning that any query autocompletion methods trained to mimic user behavior can lead to suboptimal query suggestions. To overcome this limitation, we propose a new approach that explicitly optimizes the query suggestions for downstream retrieval performance. We formulate this as a problem of ranking a set of rankings, where each query suggestion is represented by the downstream item ranking it produces. We then present a learning method that ranks query suggestions by the quality of their item rankings. The algorithm is based on a counterfactual learning approach that is able to leverage feedback on the items (e.g., clicks, purchases) to evaluate query suggestions through an unbiased estimator, thus avoiding the assumption that users write or select optimal queries. We establish theoretical support for the proposed approach and provide learning-theoretic guarantees. We also present empirical results on publicly available datasets, and demonstrate real-world applicability using data from an online shopping store.
Learning 6-DoF Object Poses to Grasp Category-level Objects by Language Instructions
May 09, 2022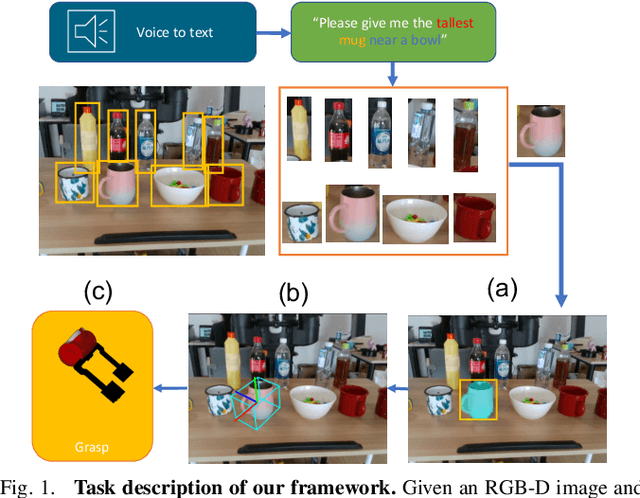

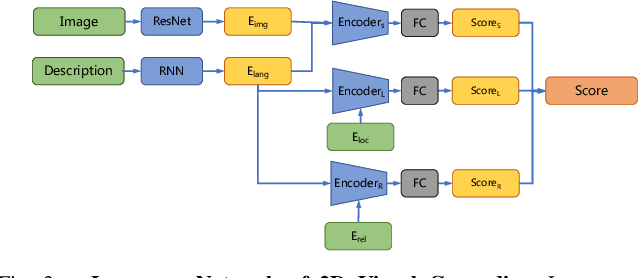

This paper studies the task of any objects grasping from the known categories by free-form language instructions. This task demands the technique in computer vision, natural language processing, and robotics. We bring these disciplines together on this open challenge, which is essential to human-robot interaction. Critically, the key challenge lies in inferring the category of objects from linguistic instructions and accurately estimating the 6-DoF information of unseen objects from the known classes. In contrast, previous works focus on inferring the pose of object candidates at the instance level. This significantly limits its applications in real-world scenarios.In this paper, we propose a language-guided 6-DoF category-level object localization model to achieve robotic grasping by comprehending human intention. To this end, we propose a novel two-stage method. Particularly, the first stage grounds the target in the RGB image through language description of names, attributes, and spatial relations of objects. The second stage extracts and segments point clouds from the cropped depth image and estimates the full 6-DoF object pose at category-level. Under such a manner, our approach can locate the specific object by following human instructions, and estimate the full 6-DoF pose of a category-known but unseen instance which is not utilized for training the model. Extensive experimental results show that our method is competitive with the state-of-the-art language-conditioned grasp method. Importantly, we deploy our approach on a physical robot to validate the usability of our framework in real-world applications. Please refer to the supplementary for the demo videos of our robot experiments.
Unsupervised Multimodal Word Discovery based on Double Articulation Analysis with Co-occurrence cues
Jan 18, 2022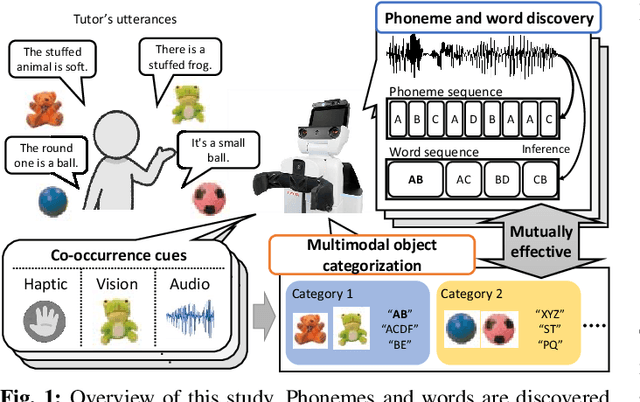
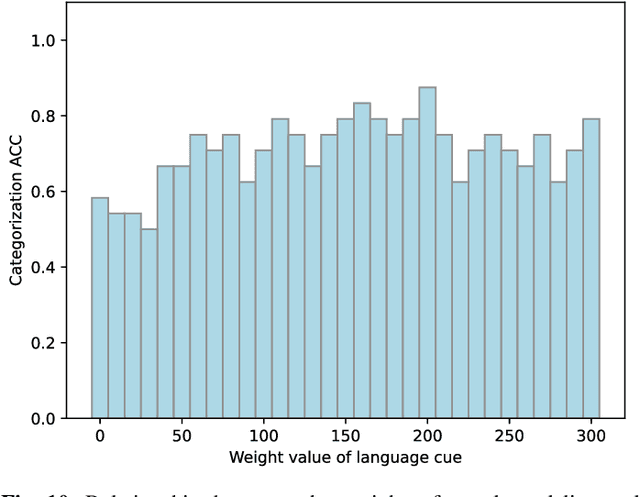
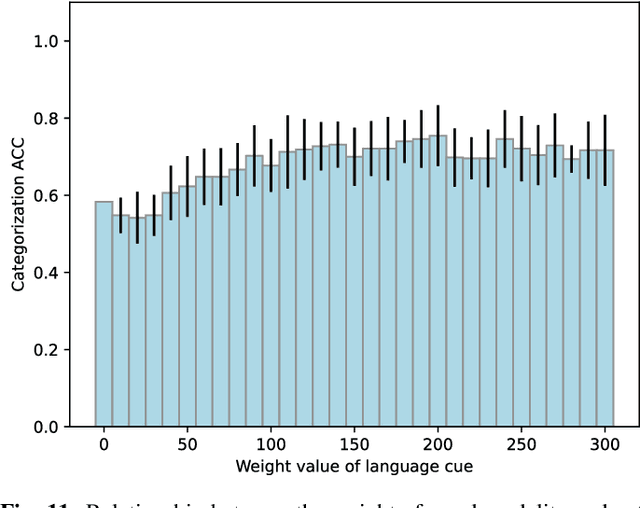
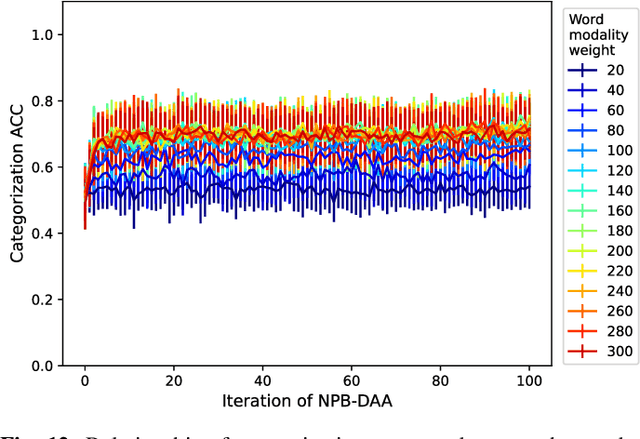
Human infants acquire their verbal lexicon from minimal prior knowledge of language based on the statistical properties of phonological distributions and the co-occurrence of other sensory stimuli. In this study, we propose a novel fully unsupervised learning method discovering speech units by utilizing phonological information as a distributional cue and object information as a co-occurrence cue. The proposed method can not only (1) acquire words and phonemes from speech signals using unsupervised learning, but can also (2) utilize object information based on multiple modalities (i.e., vision, tactile, and auditory) simultaneously. The proposed method is based on the Nonparametric Bayesian Double Articulation Analyzer (NPB-DAA) discovering phonemes and words from phonological features, and Multimodal Latent Dirichlet Allocation (MLDA) categorizing multimodal information obtained from objects. In the experiment, the proposed method showed higher word discovery performance than the baseline methods. In particular, words that expressed the characteristics of the object (i.e., words corresponding to nouns and adjectives) were segmented accurately. Furthermore, we examined how learning performance is affected by differences in the importance of linguistic information. When the weight of the word modality was increased, the performance was further improved compared to the fixed condition.
GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors
Mar 14, 2022
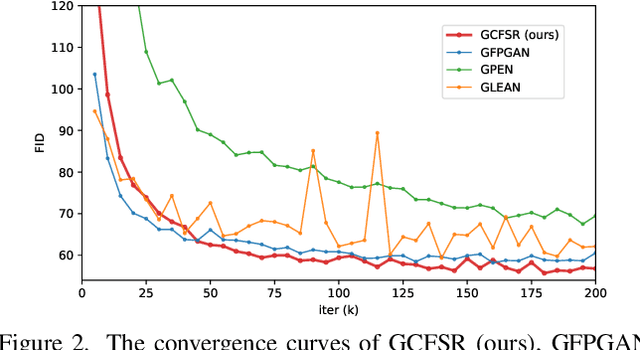

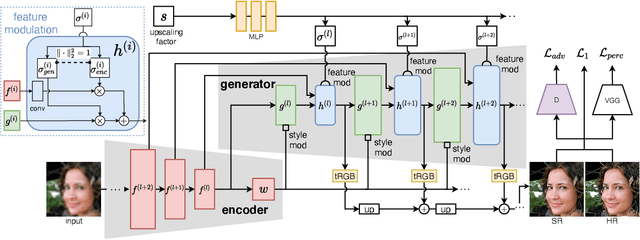
Face image super resolution (face hallucination) usually relies on facial priors to restore realistic details and preserve identity information. Recent advances can achieve impressive results with the help of GAN prior. They either design complicated modules to modify the fixed GAN prior or adopt complex training strategies to finetune the generator. In this work, we propose a generative and controllable face SR framework, called GCFSR, which can reconstruct images with faithful identity information without any additional priors. Generally, GCFSR has an encoder-generator architecture. Two modules called style modulation and feature modulation are designed for the multi-factor SR task. The style modulation aims to generate realistic face details and the feature modulation dynamically fuses the multi-level encoded features and the generated ones conditioned on the upscaling factor. The simple and elegant architecture can be trained from scratch in an end-to-end manner. For small upscaling factors (<=8), GCFSR can produce surprisingly good results with only adversarial loss. After adding L1 and perceptual losses, GCFSR can outperform state-of-the-art methods for large upscaling factors (16, 32, 64). During the test phase, we can modulate the generative strength via feature modulation by changing the conditional upscaling factor continuously to achieve various generative effects.