 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hyperbolic Image Segmentation
Mar 11, 2022
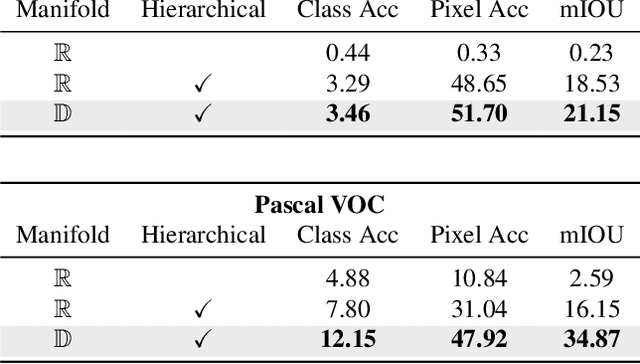

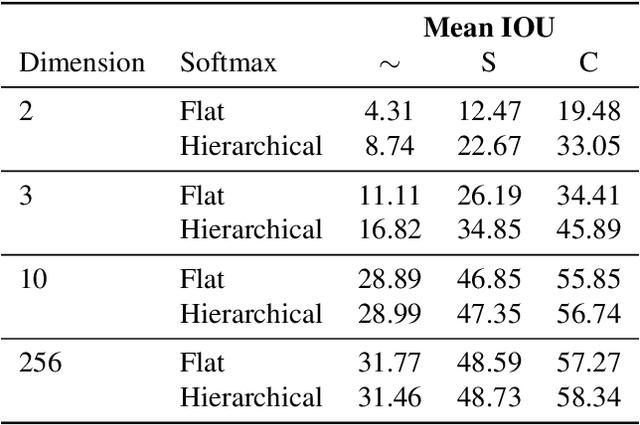
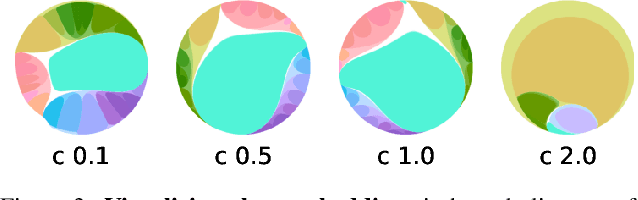
For image segmentation, the current standard is to perform pixel-level optimization and inference in Euclidean output embedding spaces through linear hyperplanes. In this work, we show that hyperbolic manifolds provide a valuable alternative for image segmentation and propose a tractable formulation of hierarchical pixel-level classification in hyperbolic space. Hyperbolic Image Segmentation opens up new possibilities and practical benefits for segmentation, such as uncertainty estimation and boundary information for free, zero-label generalization, and increased performance in low-dimensional output embeddings.
A Multi-stage deep architecture for summary generation of soccer videos
May 02, 2022
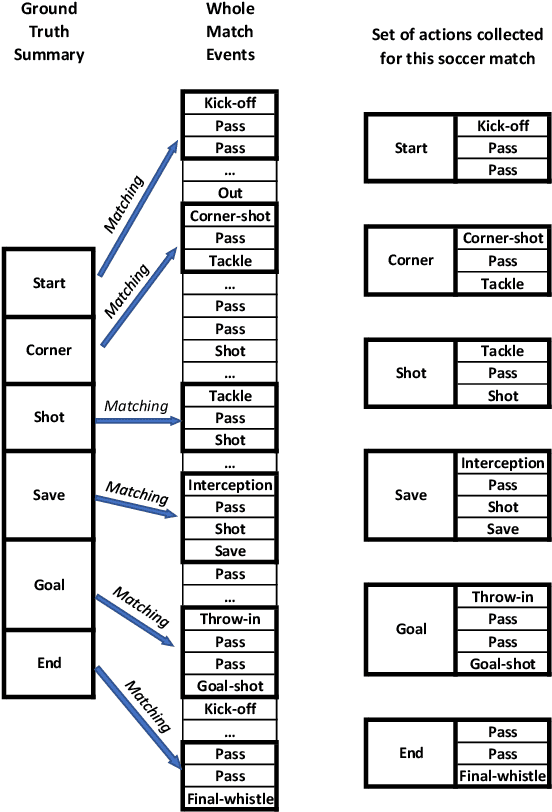
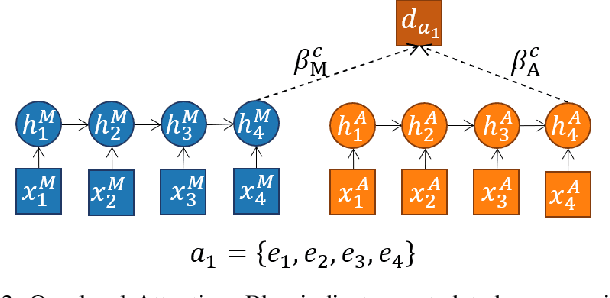
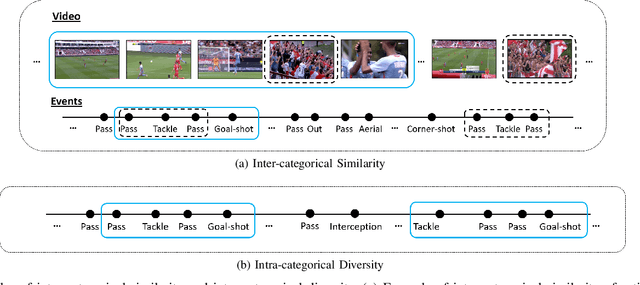
Video content is present in an ever-increasing number of fields, both scientific and commercial. Sports, particularly soccer, is one of the industries that has invested the most in the field of video analytics, due to the massive popularity of the game and the emergence of new markets. Previous state-of-the-art methods on soccer matches video summarization rely on handcrafted heuristics to generate summaries which are poorly generalizable, but these works have yet proven that multiple modalities help detect the best actions of the game. On the other hand, machine learning models with higher generalization potential have entered the field of summarization of general-purpose videos, offering several deep learning approaches. However, most of them exploit content specificities that are not appropriate for sport whole-match videos. Although video content has been for many years the main source for automatizing knowledge extraction in soccer, the data that records all the events happening on the field has become lately very important in sports analytics, since this event data provides richer context information and requires less processing. We propose a method to generate the summary of a soccer match exploiting both the audio and the event metadata. The results show that our method can detect the actions of the match, identify which of these actions should belong to the summary and then propose multiple candidate summaries which are similar enough but with relevant variability to provide different options to the final editor. Furthermore, we show the generalization capability of our work since it can transfer knowledge between datasets from different broadcasting companies, different competitions, acquired in different conditions, and corresponding to summaries of different lengths
Federated Learning with Lossy Distributed Source Coding: Analysis and Optimization
Apr 23, 2022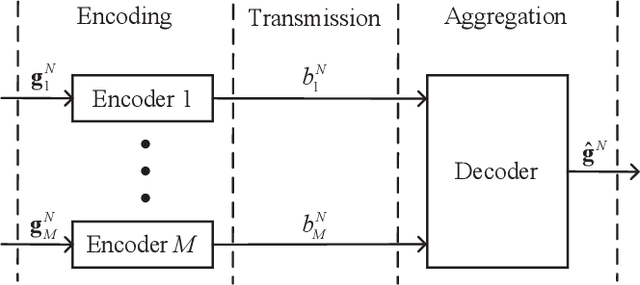
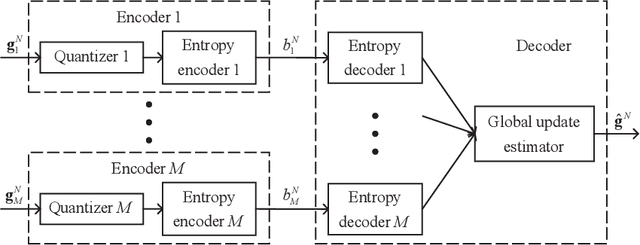
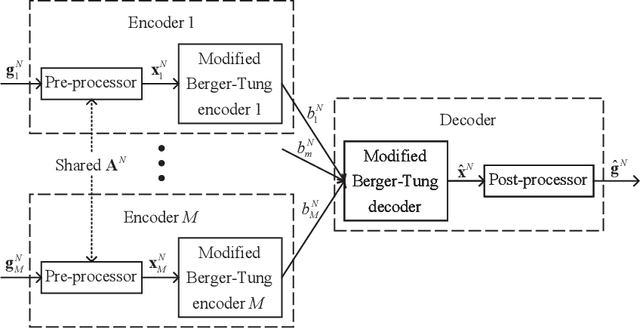
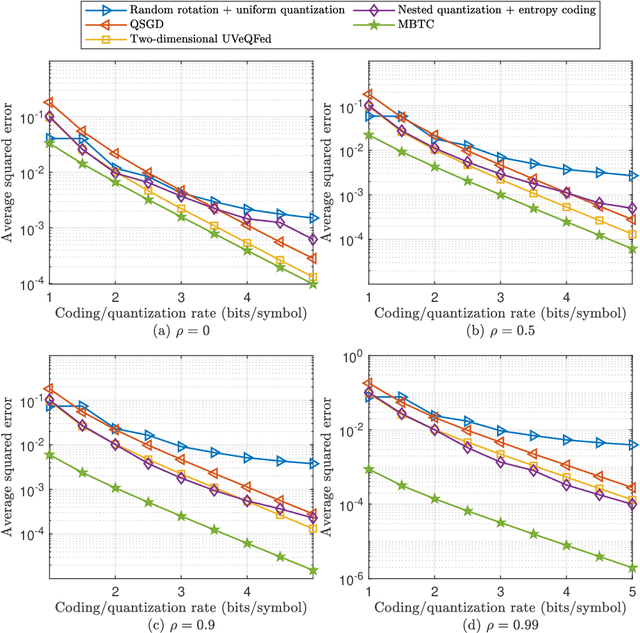
Recently, federated learning (FL), which replaces data sharing with model sharing, has emerged as an efficient and privacy-friendly paradigm for machine learning (ML). A main challenge of FL is its huge uplink communication cost. In this paper, we tackle this challenge from an information-theoretic perspective. Specifically, we put forth a distributed source coding (DSC) framework for FL uplink, which unifies the encoding, transmission, and aggregation of the local updates as a lossy DSC problem, thus providing a systematic way to exploit the correlation between local updates to improve the uplink efficiency. Under this DSC-FL framework, we propose an FL uplink scheme based on the modified Berger-Tung coding (MBTC), which supports separate encoding and joint decoding by modifying the achievability scheme of the Berger-Tung inner bound. The achievable region of the MBTC-based uplink scheme is also derived. To unleash the potential of the MBTC-based FL scheme, we carry out a convergence analysis and then formulate a convergence rate maximization problem to optimize the parameters of MBTC. To solve this problem, we develop two algorithms, respectively for small- and large-scale FL systems, based on the majorization-minimization (MM) technique. Numerical results demonstrate the superiority of the MBTC-based FL scheme in terms of aggregation distortion, convergence performance, and communication cost, revealing the great potential of the DSC-FL framework.
Explaining black-box text classifiers for disease-treatment information extraction
Oct 21, 2020
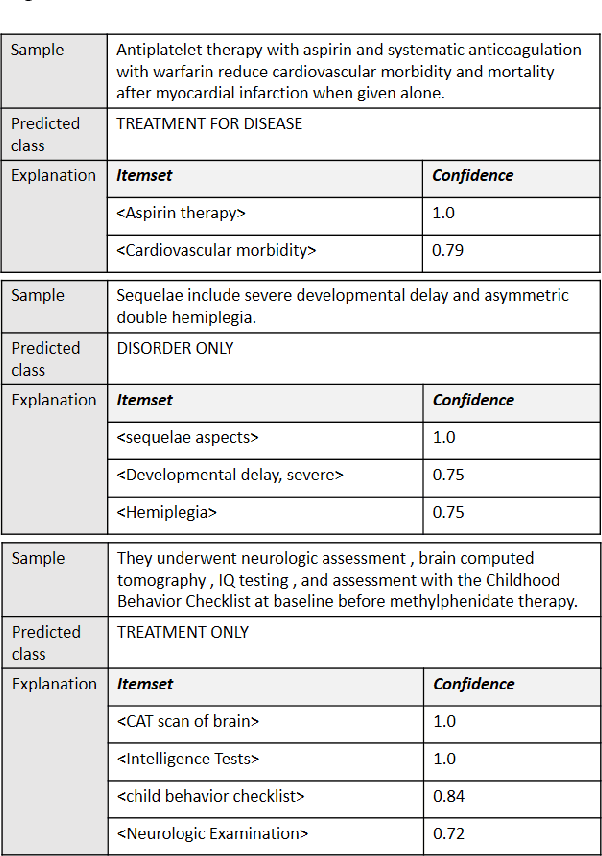
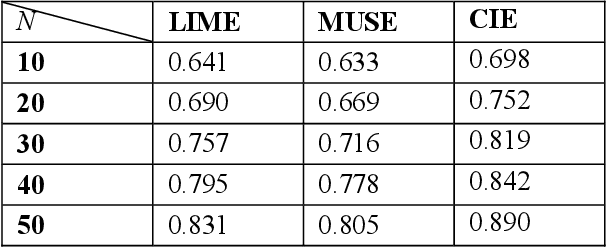
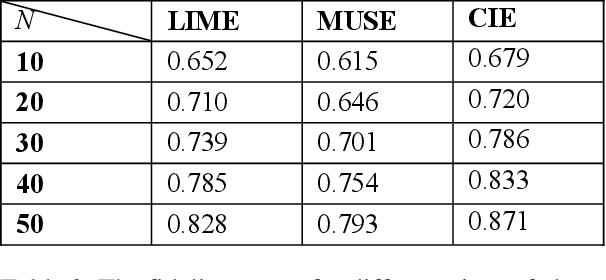
Deep neural networks and other intricate Artificial Intelligence (AI) models have reached high levels of accuracy on many biomedical natural language processing tasks. However, their applicability in real-world use cases may be limited due to their vague inner working and decision logic. A post-hoc explanation method can approximate the behavior of a black-box AI model by extracting relationships between feature values and outcomes. In this paper, we introduce a post-hoc explanation method that utilizes confident itemsets to approximate the behavior of black-box classifiers for medical information extraction. Incorporating medical concepts and semantics into the explanation process, our explanator finds semantic relations between inputs and outputs in different parts of the decision space of a black-box classifier. The experimental results show that our explanation method can outperform perturbation and decision set based explanators in terms of fidelity and interpretability of explanations produced for predictions on a disease-treatment information extraction task.
Dynamics Generalization via Information Bottleneck in Deep Reinforcement Learning
Aug 03, 2020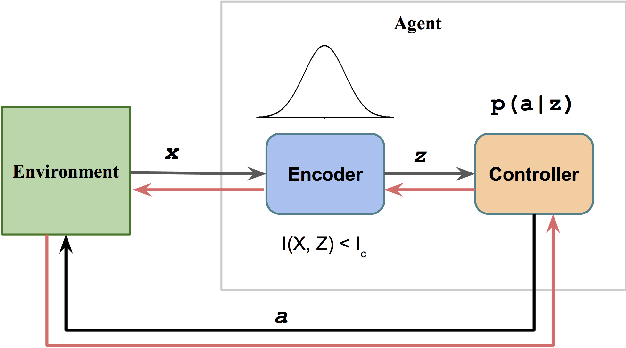
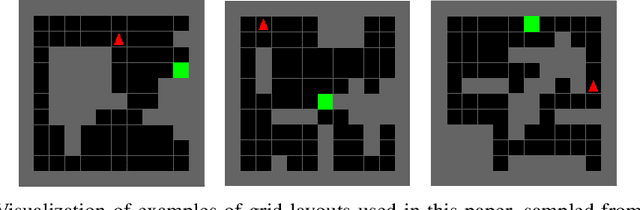
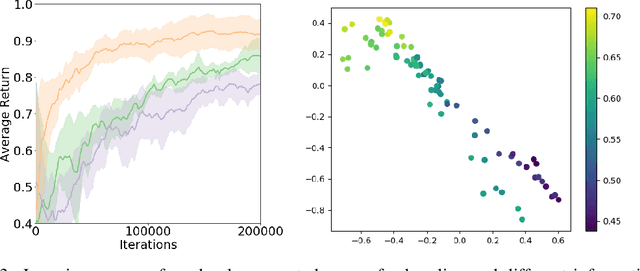
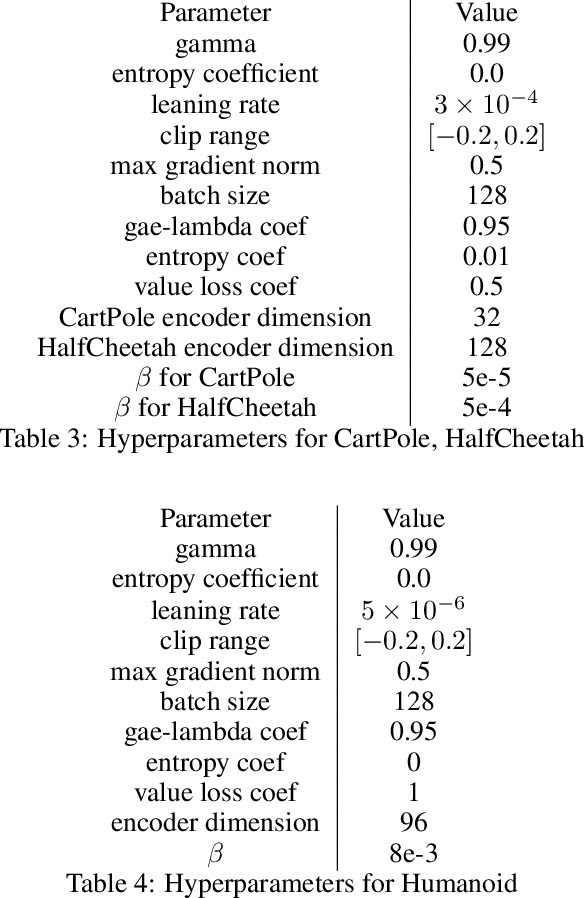
Despite the significant progress of deep reinforcement learning (RL) in solving sequential decision making problems, RL agents often overfit to training environments and struggle to adapt to new, unseen environments. This prevents robust applications of RL in real world situations, where system dynamics may deviate wildly from the training settings. In this work, our primary contribution is to propose an information theoretic regularization objective and an annealing-based optimization method to achieve better generalization ability in RL agents. We demonstrate the extreme generalization benefits of our approach in different domains ranging from maze navigation to robotic tasks; for the first time, we show that agents can generalize to test parameters more than 10 standard deviations away from the training parameter distribution. This work provides a principled way to improve generalization in RL by gradually removing information that is redundant for task-solving; it opens doors for the systematic study of generalization from training to extremely different testing settings, focusing on the established connections between information theory and machine learning.
Upsampling Autoencoder for Self-Supervised Point Cloud Learning
Mar 21, 2022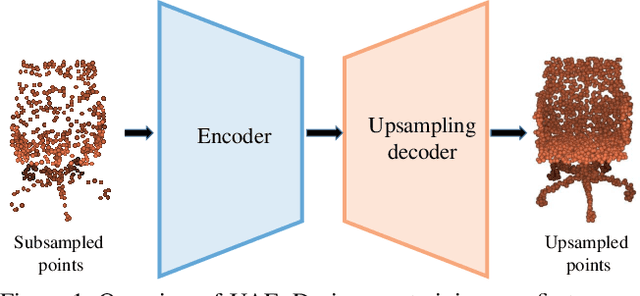
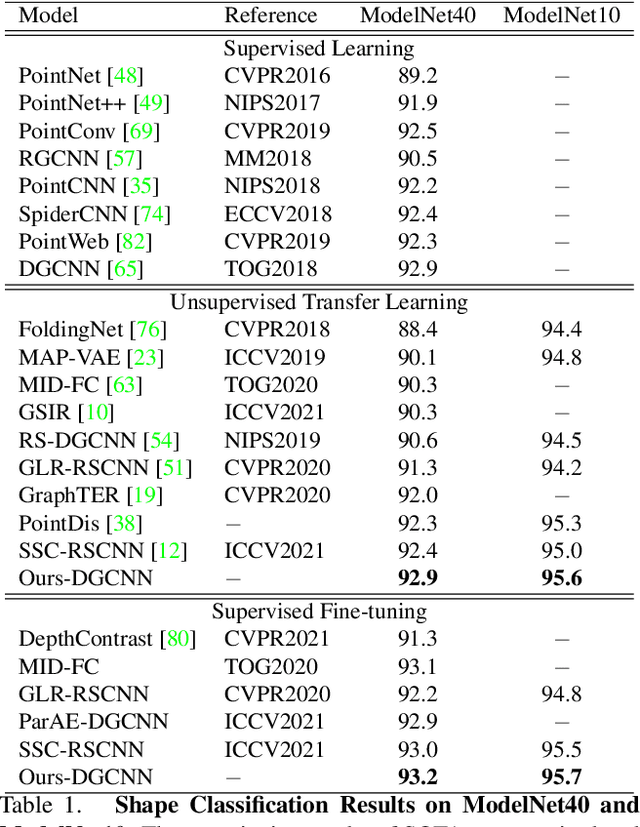
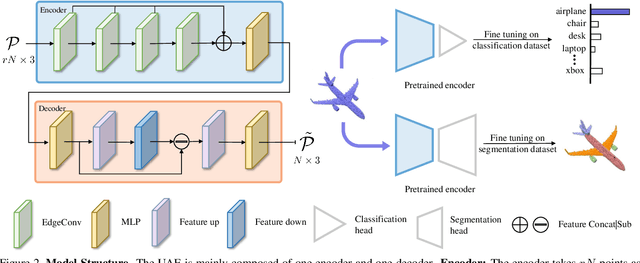
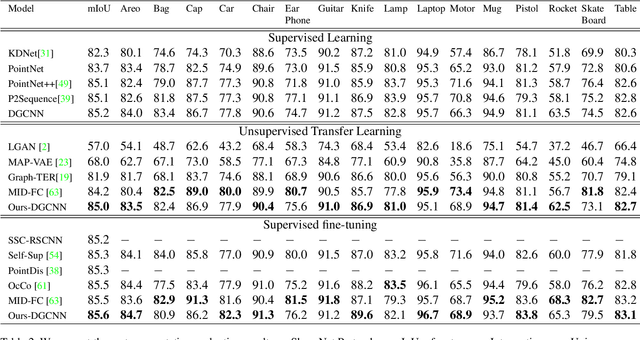
In computer-aided design (CAD) community, the point cloud data is pervasively applied in reverse engineering, where the point cloud analysis plays an important role. While a large number of supervised learning methods have been proposed to handle the unordered point clouds and demonstrated their remarkable success, their performance and applicability are limited to the costly data annotation. In this work, we propose a novel self-supervised pretraining model for point cloud learning without human annotations, which relies solely on upsampling operation to perform feature learning of point cloud in an effective manner. The key premise of our approach is that upsampling operation encourages the network to capture both high-level semantic information and low-level geometric information of the point cloud, thus the downstream tasks such as classification and segmentation will benefit from the pre-trained model. Specifically, our method first conducts the random subsampling from the input point cloud at a low proportion e.g., 12.5%. Then, we feed them into an encoder-decoder architecture, where an encoder is devised to operate only on the subsampled points, along with a upsampling decoder is adopted to reconstruct the original point cloud based on the learned features. Finally, we design a novel joint loss function which enforces the upsampled points to be similar with the original point cloud and uniformly distributed on the underlying shape surface. By adopting the pre-trained encoder weights as initialisation of models for downstream tasks, we find that our UAE outperforms previous state-of-the-art methods in shape classification, part segmentation and point cloud upsampling tasks. Code will be made publicly available upon acceptance.
An Efficient Approach for Optimizing the Cost-effective Individualized Treatment Rule Using Conditional Random Forest
Apr 23, 2022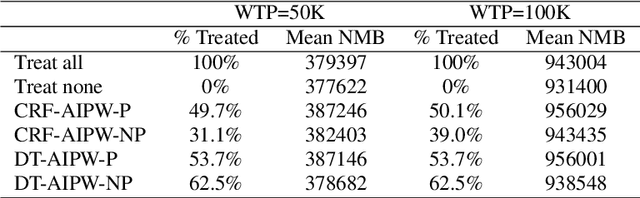
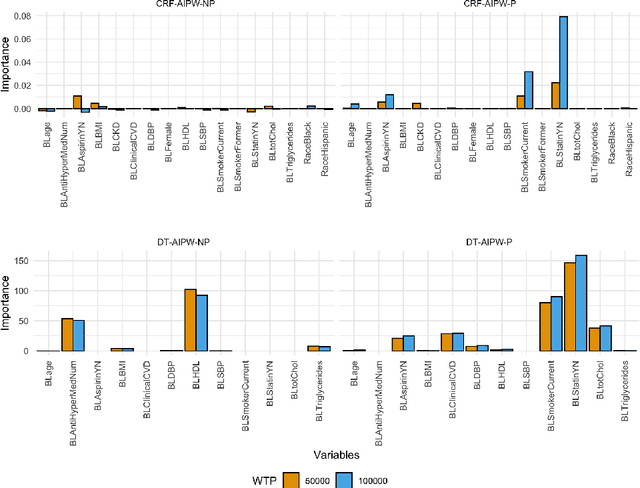
Evidence from observational studies has become increasingly important for supporting healthcare policy making via cost-effectiveness (CE) analyses. Similar as in comparative effectiveness studies, health economic evaluations that consider subject-level heterogeneity produce individualized treatment rules (ITRs) that are often more cost-effective than one-size-fits-all treatment. Thus, it is of great interest to develop statistical tools for learning such a cost-effective ITR (CE-ITR) under the causal inference framework that allows proper handling of potential confounding and can be applied to both trials and observational studies. In this paper, we use the concept of net-monetary-benefit (NMB) to assess the trade-off between health benefits and related costs. We estimate CE-ITR as a function of patients' characteristics that, when implemented, optimizes the allocation of limited healthcare resources by maximizing health gains while minimizing treatment-related costs. We employ the conditional random forest approach and identify the optimal CE-ITR using NMB-based classification algorithms, where two partitioned estimators are proposed for the subject-specific weights to effectively incorporate information from censored individuals. We conduct simulation studies to evaluate the performance of our proposals. We apply our top-performing algorithm to the NIH-funded Systolic Blood Pressure Intervention Trial (SPRINT) to illustrate the CE gains of assigning customized intensive blood pressure therapy.
Equivariant Graph Hierarchy-Based Neural Networks
Feb 22, 2022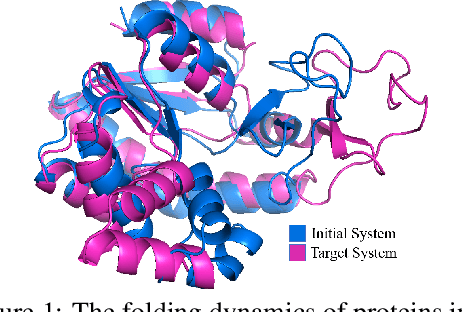

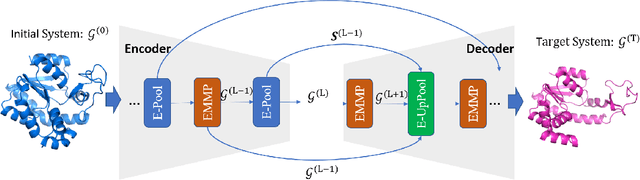
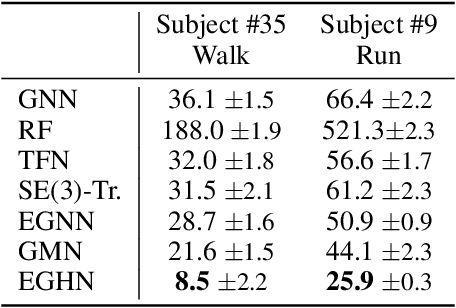
Equivariant Graph neural Networks (EGNs) are powerful in characterizing the dynamics of multi-body physical systems. Existing EGNs conduct flat message passing, which, yet, is unable to capture the spatial/dynamical hierarchy for complex systems particularly, limiting substructure discovery and global information fusion. In this paper, we propose Equivariant Hierarchy-based Graph Networks (EGHNs) which consist of the three key components: generalized Equivariant Matrix Message Passing (EMMP) , E-Pool and E-UpPool. In particular, EMMP is able to improve the expressivity of conventional equivariant message passing, E-Pool assigns the quantities of the low-level nodes into high-level clusters, while E-UpPool leverages the high-level information to update the dynamics of the low-level nodes. As their names imply, both E-Pool and E-UpPool are guaranteed to be equivariant to meet physic symmetry. Considerable experimental evaluations verify the effectiveness of our EGHN on several applications including multi-object dynamics simulation, motion capture, and protein dynamics modeling.
Detect-and-describe: Joint learning framework for detection and description of objects
Apr 19, 2022

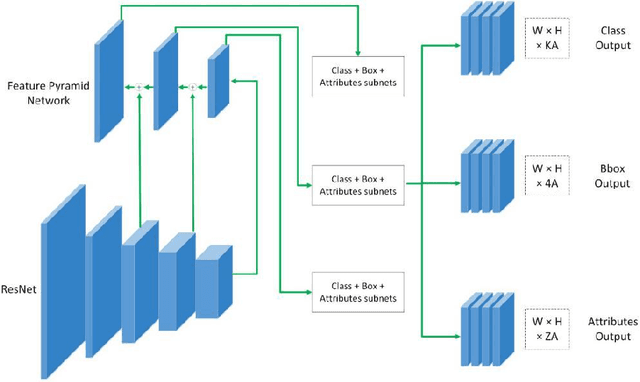
Traditional object detection answers two questions; "what" (what the object is?) and "where" (where the object is?). "what" part of the object detection can be fine-grained further i.e. "what type", "what shape" and "what material" etc. This results in the shifting of the object detection tasks to the object description paradigm. Describing an object provides additional detail that enables us to understand the characteristics and attributes of the object ("plastic boat" not just boat, "glass bottle" not just bottle). This additional information can implicitly be used to gain insight into unseen objects (e.g. unknown object is "metallic", "has wheels"), which is not possible in traditional object detection. In this paper, we present a new approach to simultaneously detect objects and infer their attributes, we call it Detect and Describe (DaD) framework. DaD is a deep learning-based approach that extends object detection to object attribute prediction as well. We train our model on aPascal train set and evaluate our approach on aPascal test set. We achieve 97.0% in Area Under the Receiver Operating Characteristic Curve (AUC) for object attributes prediction on aPascal test set. We also show qualitative results for object attribute prediction on unseen objects, which demonstrate the effectiveness of our approach for describing unknown objects.
Resolving the Disparate Impact of Uncertainty: Affirmative Action vs. Affirmative Information
Feb 19, 2021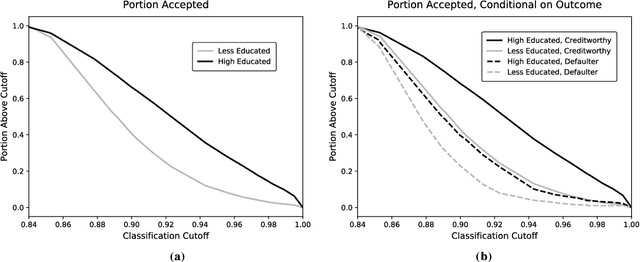
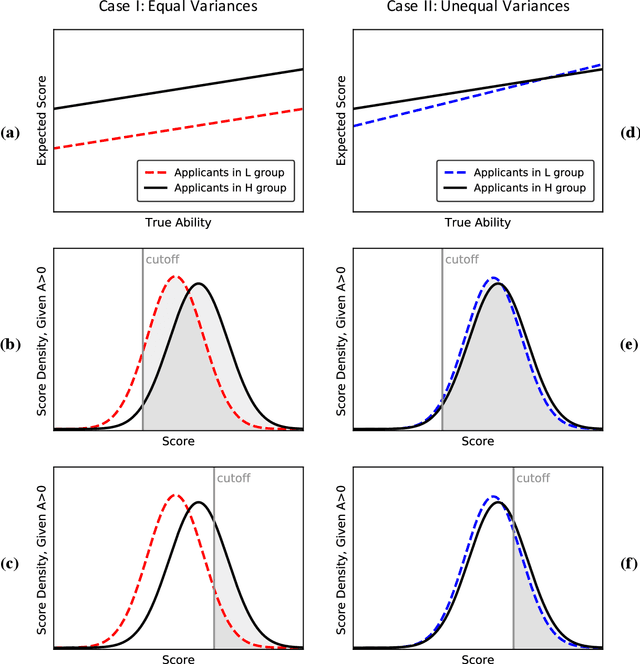
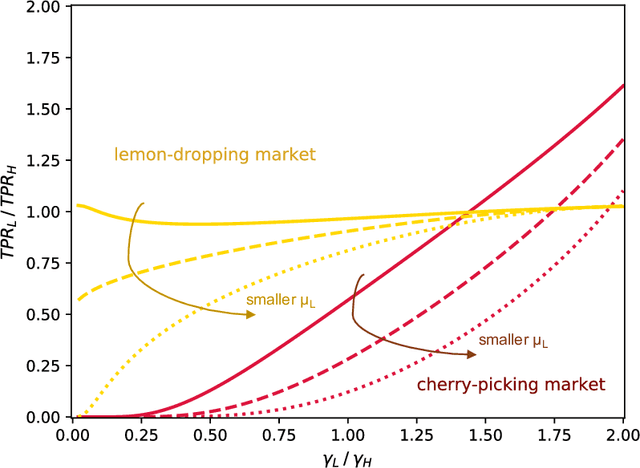
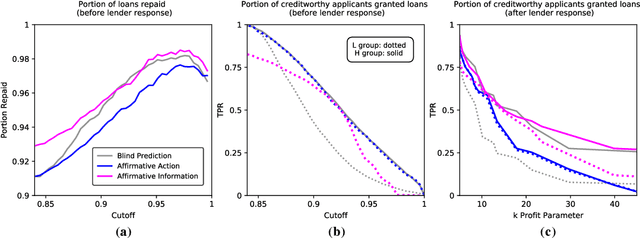
Algorithmic risk assessments hold the promise of greatly advancing accurate decision-making, but in practice, multiple real-world examples have been shown to distribute errors disproportionately across demographic groups. In this paper, we characterize why error disparities arise in the first place. We show that predictive uncertainty often leads classifiers to systematically disadvantage groups with lower-mean outcomes, assigning them smaller true and false positive rates than their higher-mean counterparts. This can occur even when prediction is group-blind. We prove that to avoid these error imbalances, individuals in lower-mean groups must either be over-represented among positive classifications or be assigned more accurate predictions than those in higher-mean groups. We focus on the latter condition as a solution to bridge error rate divides and show that data acquisition for low-mean groups can increase access to opportunity. We call the strategy "affirmative information" and compare it to traditional affirmative action in the classification task of identifying creditworthy borrowers.