 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evaluating BERT-based Pre-training Language Models for Detecting Misinformation
Mar 15, 2022
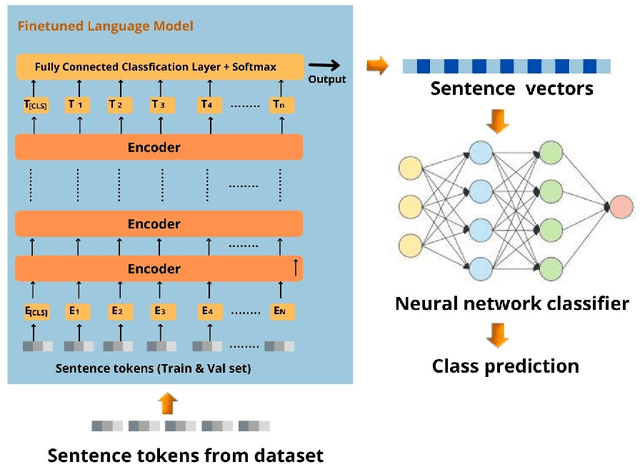
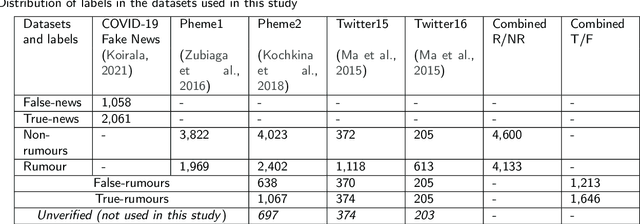
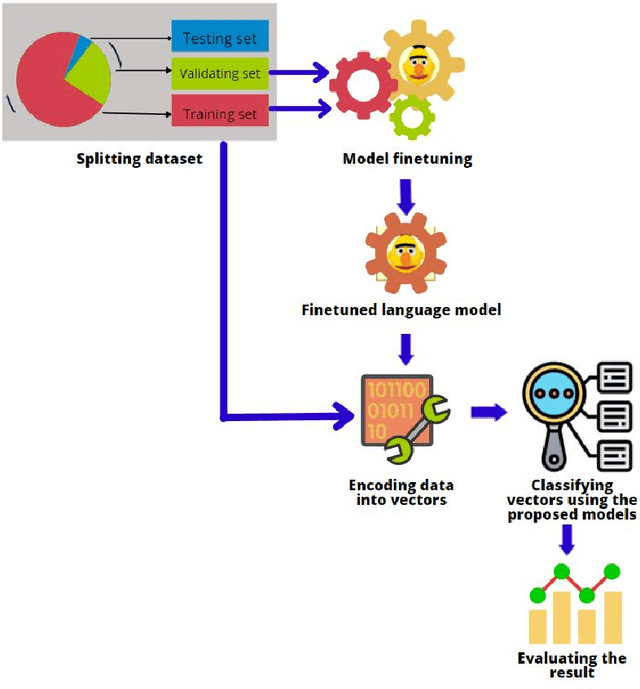
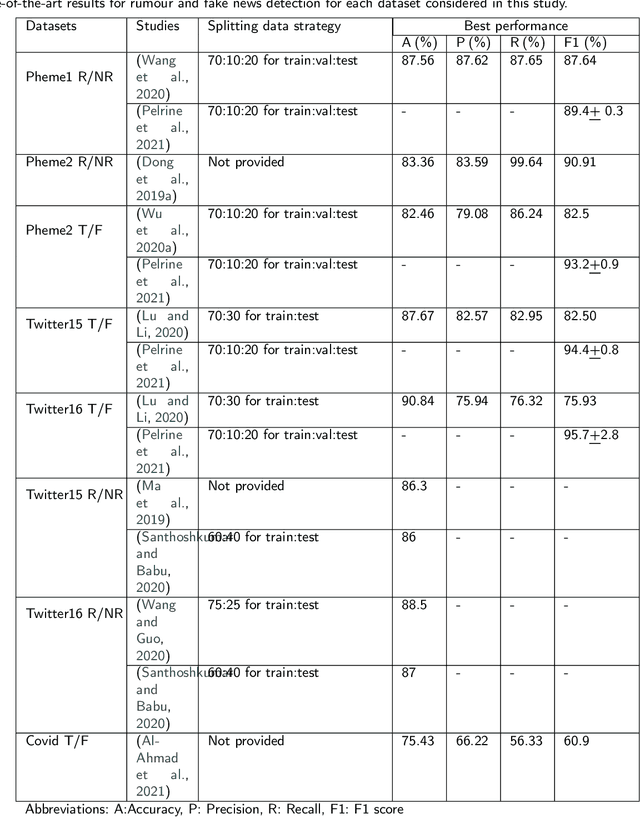
It is challenging to control the quality of online information due to the lack of supervision over all the information posted online. Manual checking is almost impossible given the vast number of posts made on online media and how quickly they spread. Therefore, there is a need for automated rumour detection techniques to limit the adverse effects of spreading misinformation. Previous studies mainly focused on finding and extracting the significant features of text data. However, extracting features is time-consuming and not a highly effective process. This study proposes the BERT- based pre-trained language models to encode text data into vectors and utilise neural network models to classify these vectors to detect misinformation. Furthermore, different language models (LM) ' performance with different trainable parameters was compared. The proposed technique is tested on different short and long text datasets. The result of the proposed technique has been compared with the state-of-the-art techniques on the same datasets. The results show that the proposed technique performs better than the state-of-the-art techniques. We also tested the proposed technique by combining the datasets. The results demonstrated that the large data training and testing size considerably improves the technique's performance.
Span-level Bidirectional Cross-attention Framework for Aspect Sentiment Triplet Extraction
Apr 27, 2022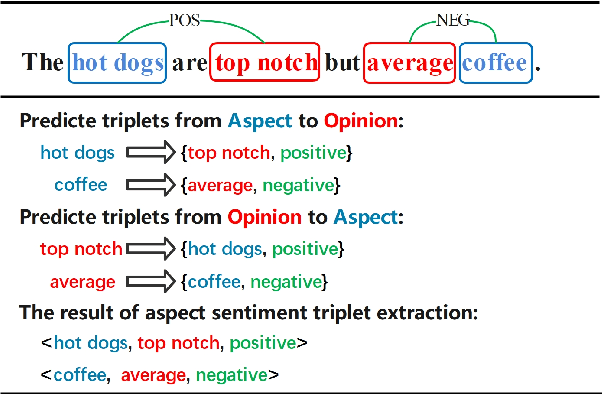
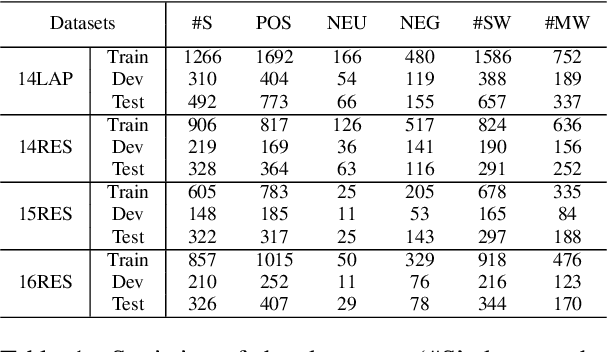
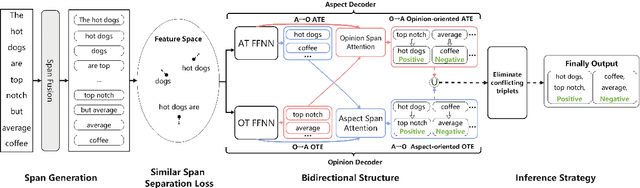
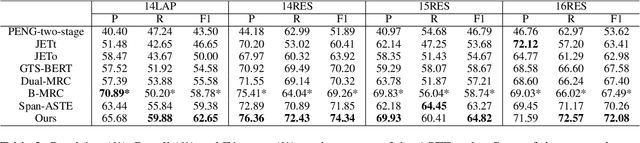
Aspect Sentiment Triplet Extraction (ASTE) is a new fine-grained sentiment analysis task that aims to extract triplets of aspect terms, sentiments, and opinion terms from review sentences. Recently, span-level models achieve gratifying results on ASTE task by taking advantage of whole span predictions. However, all the spans generated by these methods inevitably share at least one token with some others, and these method suffer from the similarity of these spans due to their similar distributions. Moreover, since either the aspect term or opinion term can trigger a sentiment triplet, it is challenging to make use of the information more comprehensively and adequately. To address these concerns, we propose a span-level bidirectional cross-attention framework. Specifically, we design a similar span separation loss to detach the spans with shared tokens and a bidirectional cross-attention structure that consists of aspect and opinion decoders to decode the span-level representations in both aspect-to-opinion and opinion-to-aspect directions. With differentiated span representations and bidirectional decoding structure, our model can extract sentiment triplets more precisely and efficiently. Experimental results show that our framework significantly outperforms state-of-the-art methods, achieving better performance in predicting triplets with multi-token entities and extracting triplets in sentences with multi-triplets.
Generalizing Aggregation Functions in GNNs:High-Capacity GNNs via Nonlinear Neighborhood Aggregators
Feb 18, 2022


Graph neural networks (GNNs) have achieved great success in many graph learning tasks. The main aspect powering existing GNNs is the multi-layer network architecture to learn the nonlinear graph representations for the specific learning tasks. The core operation in GNNs is message propagation in which each node updates its representation by aggregating its neighbors' representations. Existing GNNs mainly adopt either linear neighborhood aggregation (mean,sum) or max aggregator in their message propagation. (1) For linear aggregators, the whole nonlinearity and network's capacity of GNNs are generally limited due to deeper GNNs usually suffer from over-smoothing issue. (2) For max aggregator, it usually fails to be aware of the detailed information of node representations within neighborhood. To overcome these issues, we re-think the message propagation mechanism in GNNs and aim to develop the general nonlinear aggregators for neighborhood information aggregation in GNNs. One main aspect of our proposed nonlinear aggregators is that they provide the optimally balanced aggregators between max and mean/sum aggregations. Thus, our aggregators can inherit both (i) high nonlinearity that increases network's capacity and (ii) detail-sensitivity that preserves the detailed information of representations together in GNNs' message propagation. Promising experiments on several datasets show the effectiveness of the proposed nonlinear aggregators.
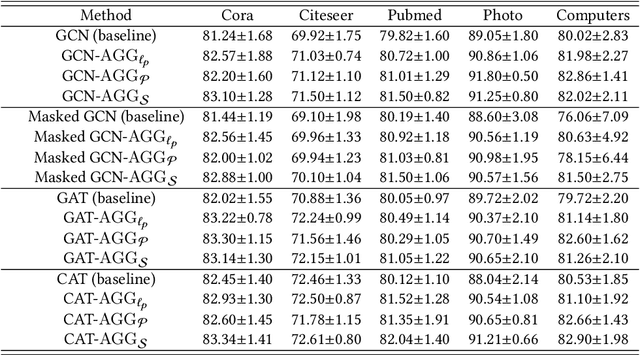
Principled inference of hyperedges and overlapping communities in hypergraphs
Apr 12, 2022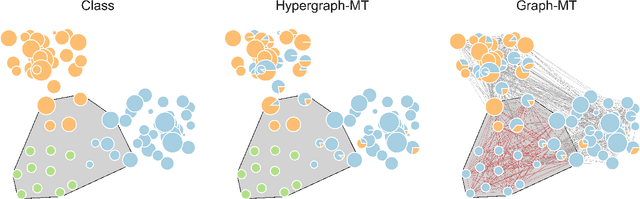
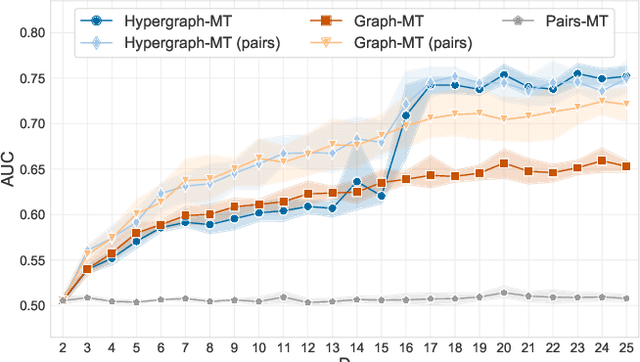
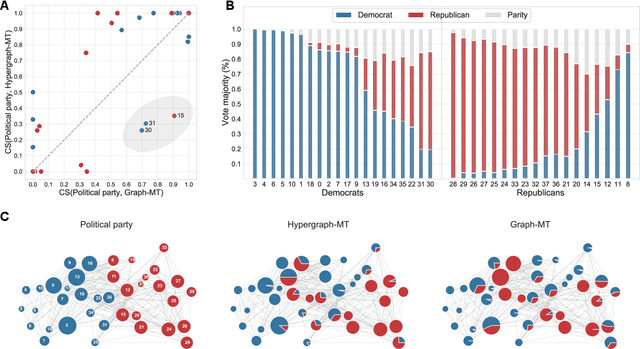
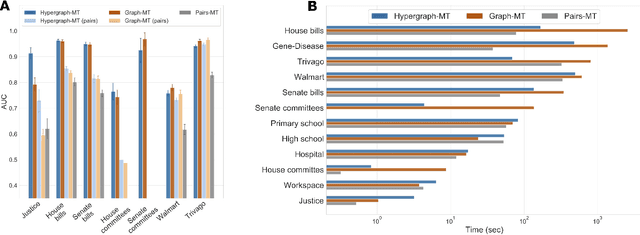
Hypergraphs, encoding structured interactions among any number of system units, have recently proven a successful tool to describe many real-world biological and social networks. Here we propose a framework based on statistical inference to characterize the structural organization of hypergraphs. The method allows to infer missing hyperedges of any size in a principled way, and to jointly detect overlapping communities in presence of higher-order interactions. Furthermore, our model has an efficient numerical implementation, and it runs faster than dyadic algorithms on pairwise records projected from higher-order data. We apply our method to a variety of real-world systems, showing strong performance in hyperedge prediction tasks, detecting communities well aligned with the information carried by interactions, and robustness against addition of noisy hyperedges. Our approach illustrates the fundamental advantages of a hypergraph probabilistic model when modeling relational systems with higher-order interactions.
Improving Visual Grounding with Visual-Linguistic Verification and Iterative Reasoning
Apr 30, 2022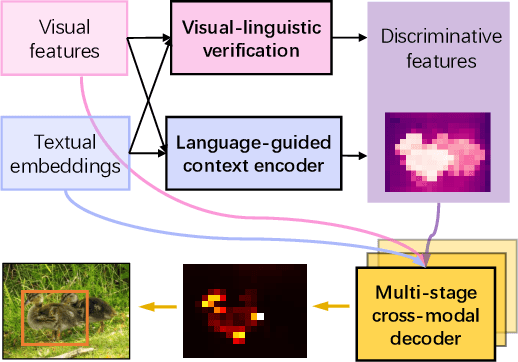
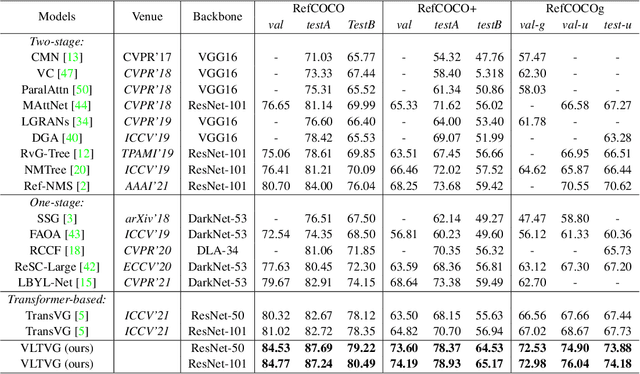
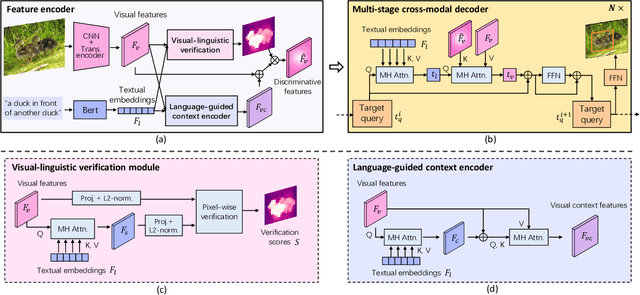
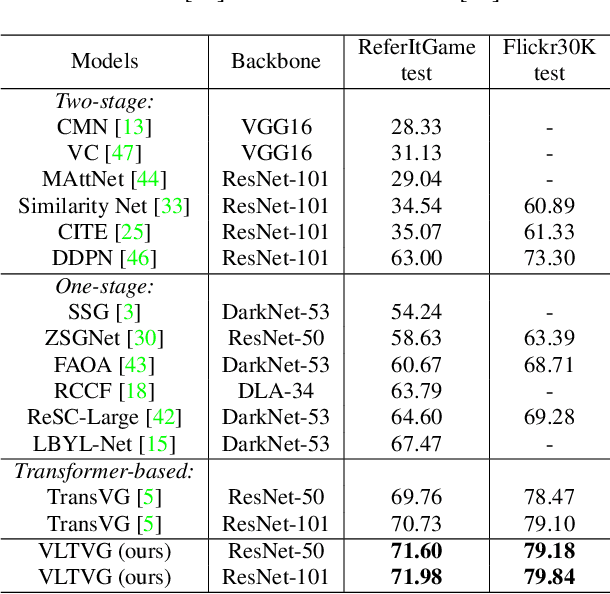
Visual grounding is a task to locate the target indicated by a natural language expression. Existing methods extend the generic object detection framework to this problem. They base the visual grounding on the features from pre-generated proposals or anchors, and fuse these features with the text embeddings to locate the target mentioned by the text. However, modeling the visual features from these predefined locations may fail to fully exploit the visual context and attribute information in the text query, which limits their performance. In this paper, we propose a transformer-based framework for accurate visual grounding by establishing text-conditioned discriminative features and performing multi-stage cross-modal reasoning. Specifically, we develop a visual-linguistic verification module to focus the visual features on regions relevant to the textual descriptions while suppressing the unrelated areas. A language-guided feature encoder is also devised to aggregate the visual contexts of the target object to improve the object's distinctiveness. To retrieve the target from the encoded visual features, we further propose a multi-stage cross-modal decoder to iteratively speculate on the correlations between the image and text for accurate target localization. Extensive experiments on five widely used datasets validate the efficacy of our proposed components and demonstrate state-of-the-art performance. Our code is public at https://github.com/yangli18/VLTVG.
Conditional Contrastive Learning with Kernel
Feb 14, 2022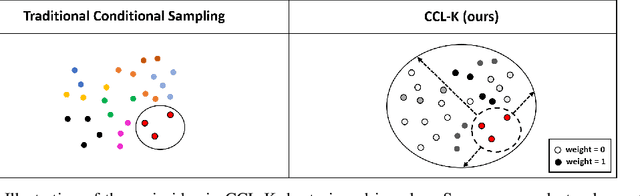



Conditional contrastive learning frameworks consider the conditional sampling procedure that constructs positive or negative data pairs conditioned on specific variables. Fair contrastive learning constructs negative pairs, for example, from the same gender (conditioning on sensitive information), which in turn reduces undesirable information from the learned representations; weakly supervised contrastive learning constructs positive pairs with similar annotative attributes (conditioning on auxiliary information), which in turn are incorporated into the representations. Although conditional contrastive learning enables many applications, the conditional sampling procedure can be challenging if we cannot obtain sufficient data pairs for some values of the conditioning variable. This paper presents Conditional Contrastive Learning with Kernel (CCL-K) that converts existing conditional contrastive objectives into alternative forms that mitigate the insufficient data problem. Instead of sampling data according to the value of the conditioning variable, CCL-K uses the Kernel Conditional Embedding Operator that samples data from all available data and assigns weights to each sampled data given the kernel similarity between the values of the conditioning variable. We conduct experiments using weakly supervised, fair, and hard negatives contrastive learning, showing CCL-K outperforms state-of-the-art baselines.
In Defense of Image Pre-Training for Spatiotemporal Recognition
May 03, 2022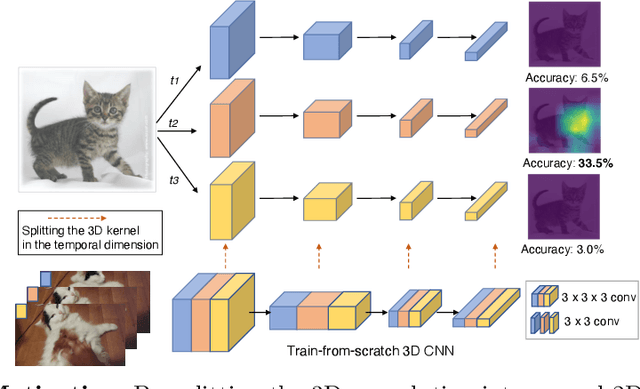
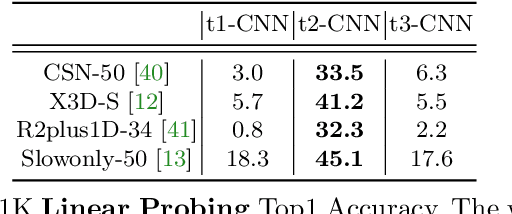
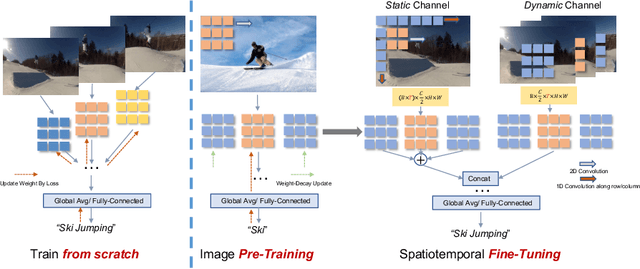

Image pre-training, the current de-facto paradigm for a wide range of visual tasks, is generally less favored in the field of video recognition. By contrast, a common strategy is to directly train with spatiotemporal convolutional neural networks (CNNs) from scratch. Nonetheless, interestingly, by taking a closer look at these from-scratch learned CNNs, we note there exist certain 3D kernels that exhibit much stronger appearance modeling ability than others, arguably suggesting appearance information is already well disentangled in learning. Inspired by this observation, we hypothesize that the key to effectively leveraging image pre-training lies in the decomposition of learning spatial and temporal features, and revisiting image pre-training as the appearance prior to initializing 3D kernels. In addition, we propose Spatial-Temporal Separable (STS) convolution, which explicitly splits the feature channels into spatial and temporal groups, to further enable a more thorough decomposition of spatiotemporal features for fine-tuning 3D CNNs. Our experiments show that simply replacing 3D convolution with STS notably improves a wide range of 3D CNNs without increasing parameters and computation on both Kinetics-400 and Something-Something V2. Moreover, this new training pipeline consistently achieves better results on video recognition with significant speedup. For instance, we achieve +0.6% top-1 of Slowfast on Kinetics-400 over the strong 256-epoch 128-GPU baseline while fine-tuning for only 50 epochs with 4 GPUs. The code and models are available at https://github.com/UCSC-VLAA/Image-Pretraining-for-Video.
Generating Self-Serendipity Preference in Recommender Systems for Addressing Cold Start Problems
Apr 27, 2022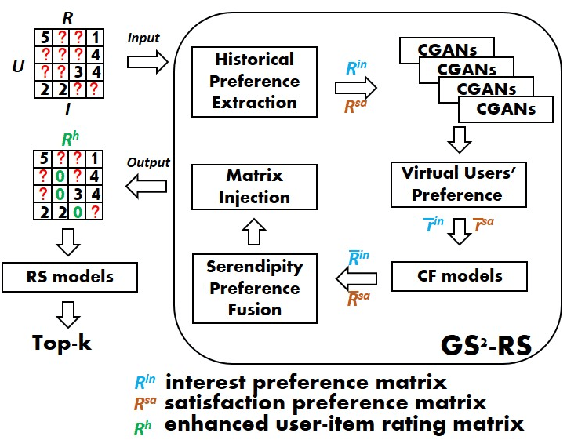

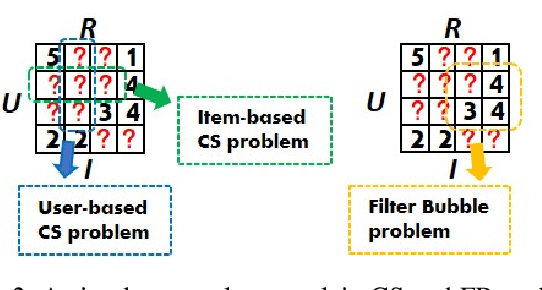
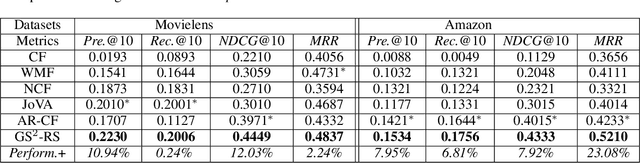
Classical accuracy-oriented Recommender Systems (RSs) typically face the cold-start problem and the filter-bubble problem when users suffer the familiar, repeated, and even predictable recommendations, making them boring and unsatisfied. To address the above issues, serendipity-oriented RSs are proposed to recommend appealing and valuable items significantly deviating from users' historical interactions and thus satisfying them by introducing unexplored but relevant candidate items to them. In this paper, we devise a novel serendipity-oriented recommender system (\textbf{G}enerative \textbf{S}elf-\textbf{S}erendipity \textbf{R}ecommender \textbf{S}ystem, \textbf{GS$^2$-RS}) that generates users' self-serendipity preferences to enhance the recommendation performance. Specifically, this model extracts users' interest and satisfaction preferences, generates virtual but convincible neighbors' preferences from themselves, and achieves their self-serendipity preference. Then these preferences are injected into the rating matrix as additional information for RS models. Note that GS$^2$-RS can not only tackle the cold-start problem but also provides diverse but relevant recommendations to relieve the filter-bubble problem. Extensive experiments on benchmark datasets illustrate that the proposed GS$^2$-RS model can significantly outperform the state-of-the-art baseline approaches in serendipity measures with a stable accuracy performance.
Fine-grained Information Status Classification Using Discourse Context-Aware BERT
Oct 26, 2020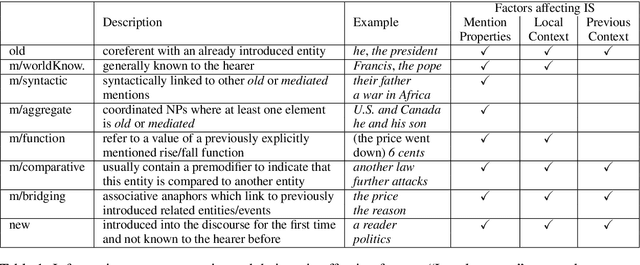
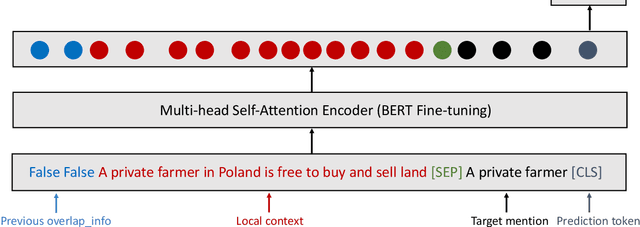
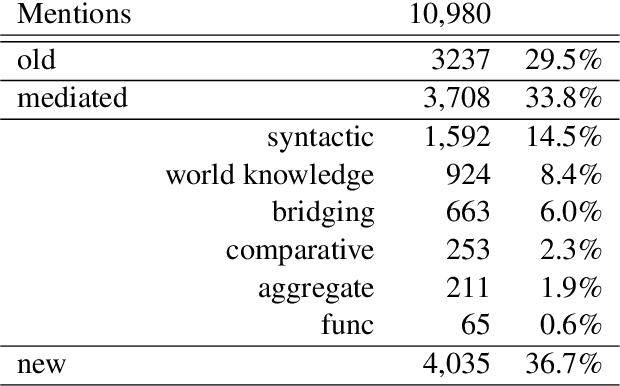
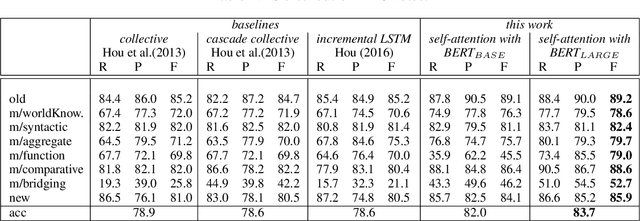
Previous work on bridging anaphora recognition (Hou et al., 2013a) casts the problem as a subtask of learning fine-grained information status (IS). However, these systems heavily depend on many hand-crafted linguistic features. In this paper, we propose a simple discourse context-aware BERT model for fine-grained IS classification. On the ISNotes corpus (Markert et al., 2012), our model achieves new state-of-the-art performance on fine-grained IS classification, obtaining a 4.8 absolute overall accuracy improvement compared to Hou et al. (2013a). More importantly, we also show an improvement of 10.5 F1 points for bridging anaphora recognition without using any complex hand-crafted semantic features designed for capturing the bridging phenomenon. We further analyze the trained model and find that the most attended signals for each IS category correspond well to linguistic notions of information status.
EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
May 06, 2022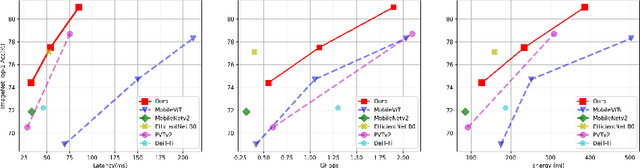
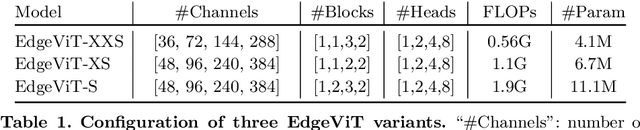
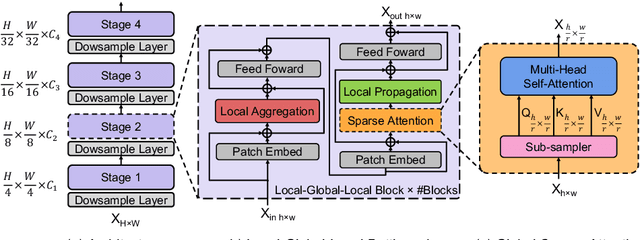
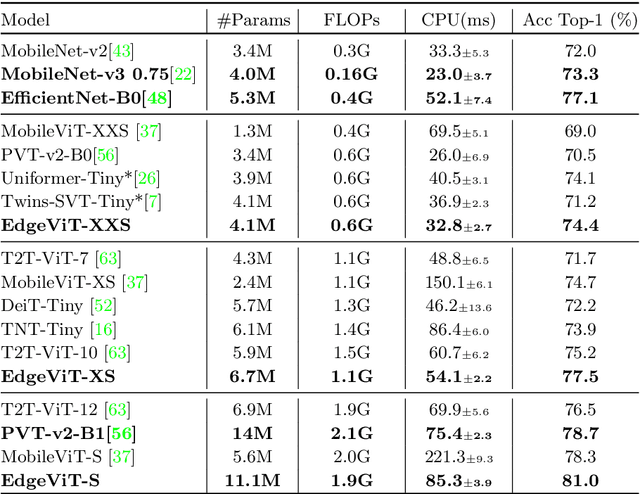
Self-attention based models such as vision transformers (ViTs) have emerged as a very competitive architecture alternative to convolutional neural networks (CNNs) in computer vision. Despite increasingly stronger variants with ever-higher recognition accuracies, due to the quadratic complexity of self-attention, existing ViTs are typically demanding in computation and model size. Although several successful design choices (e.g., the convolutions and hierarchical multi-stage structure) of prior CNNs have been reintroduced into recent ViTs, they are still not sufficient to meet the limited resource requirements of mobile devices. This motivates a very recent attempt to develop light ViTs based on the state-of-the-art MobileNet-v2, but still leaves a performance gap behind. In this work, pushing further along this under-studied direction we introduce EdgeViTs, a new family of light-weight ViTs that, for the first time, enable attention-based vision models to compete with the best light-weight CNNs in the tradeoff between accuracy and on-device efficiency. This is realized by introducing a highly cost-effective local-global-local (LGL) information exchange bottleneck based on optimal integration of self-attention and convolutions. For device-dedicated evaluation, rather than relying on inaccurate proxies like the number of FLOPs or parameters, we adopt a practical approach of focusing directly on on-device latency and, for the first time, energy efficiency. Specifically, we show that our models are Pareto-optimal when both accuracy-latency and accuracy-energy trade-offs are considered, achieving strict dominance over other ViTs in almost all cases and competing with the most efficient CNNs.