 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mechanisms for Hiding Sensitive Genotypes with Information-Theoretic Privacy
Jul 10, 2020
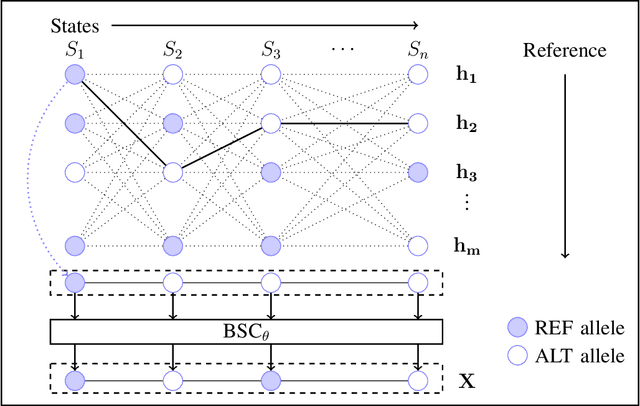
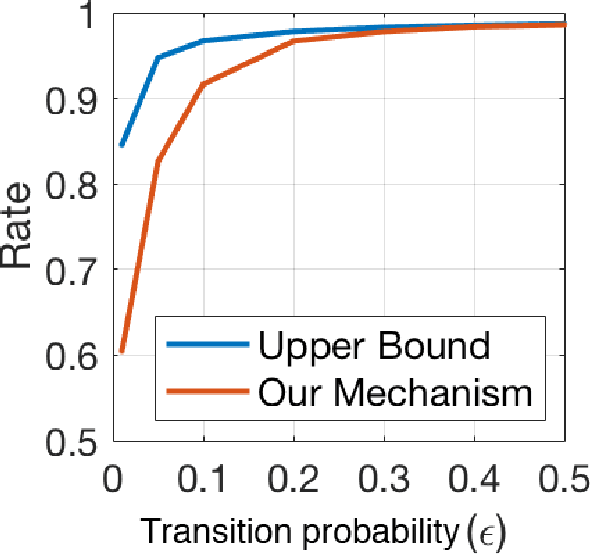
The growing availability of personal genomics services comes with increasing concerns for genomic privacy. Individuals may wish to withhold sensitive genotypes that contain critical health-related information when sharing their data with such services. A straightforward solution that masks only the sensitive genotypes does not ensure privacy due to the correlation structure within the genome. Here, we develop an information-theoretic mechanism for masking sensitive genotypes, which ensures no information about the sensitive genotypes is leaked. We also propose an efficient algorithmic implementation of our mechanism for genomic data governed by hidden Markov models. Our work is a step towards more rigorous control of privacy in genomic data sharing.
Tracking Urbanization in Developing Regions with Remote Sensing Spatial-Temporal Super-Resolution
Apr 04, 2022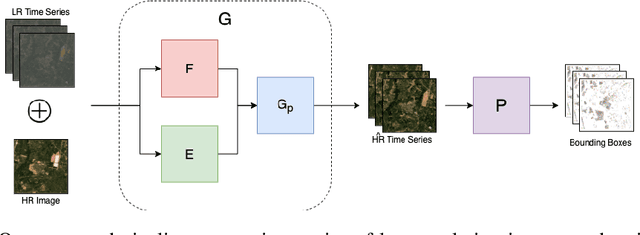
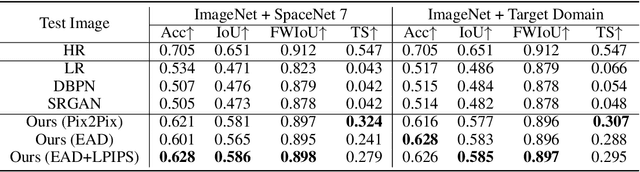

Automated tracking of urban development in areas where construction information is not available became possible with recent advancements in machine learning and remote sensing. Unfortunately, these solutions perform best on high-resolution imagery, which is expensive to acquire and infrequently available, making it difficult to scale over long time spans and across large geographies. In this work, we propose a pipeline that leverages a single high-resolution image and a time series of publicly available low-resolution images to generate accurate high-resolution time series for object tracking in urban construction. Our method achieves significant improvement in comparison to baselines using single image super-resolution, and can assist in extending the accessibility and scalability of building construction tracking across the developing world.
SUGAR: Subgraph Neural Network with Reinforcement Pooling and Self-Supervised Mutual Information Mechanism
Jan 20, 2021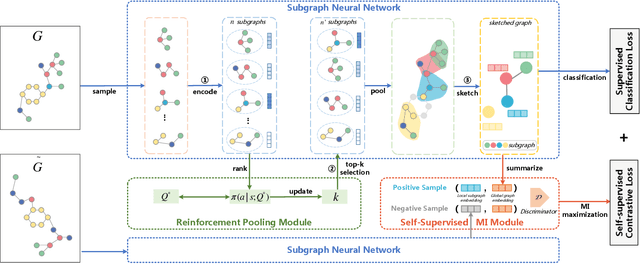
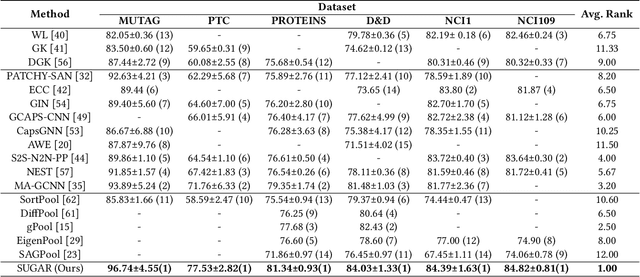
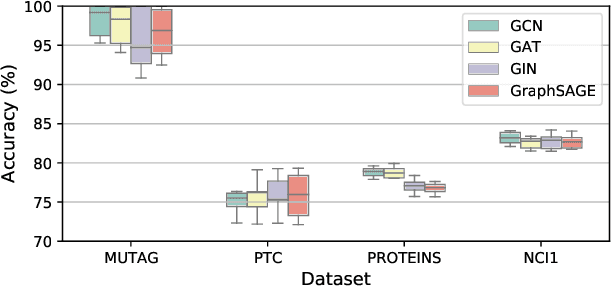
Graph representation learning has attracted increasing research attention. However, most existing studies fuse all structural features and node attributes to provide an overarching view of graphs, neglecting finer substructures' semantics, and suffering from interpretation enigmas. This paper presents a novel hierarchical subgraph-level selection and embedding based graph neural network for graph classification, namely SUGAR, to learn more discriminative subgraph representations and respond in an explanatory way. SUGAR reconstructs a sketched graph by extracting striking subgraphs as the representative part of the original graph to reveal subgraph-level patterns. To adaptively select striking subgraphs without prior knowledge, we develop a reinforcement pooling mechanism, which improves the generalization ability of the model. To differentiate subgraph representations among graphs, we present a self-supervised mutual information mechanism to encourage subgraph embedding to be mindful of the global graph structural properties by maximizing their mutual information. Extensive experiments on six typical bioinformatics datasets demonstrate a significant and consistent improvement in model quality with competitive performance and interpretability.
Refining Self-Supervised Learning in Imaging: Beyond Linear Metric
Feb 25, 2022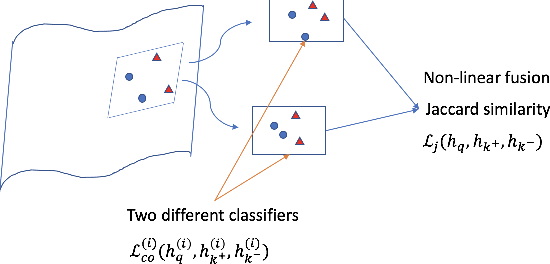
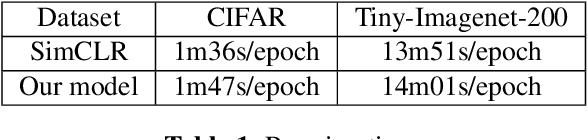
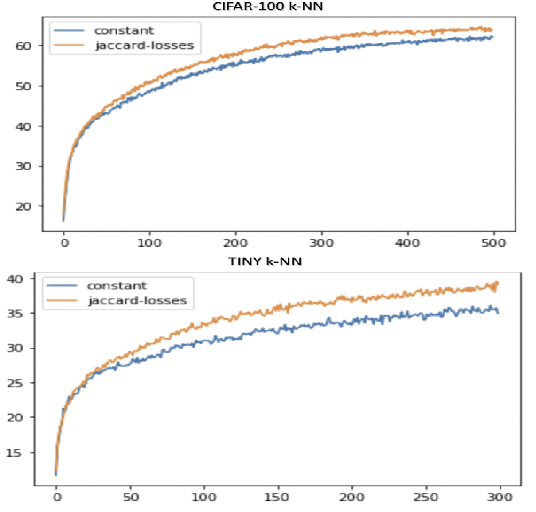
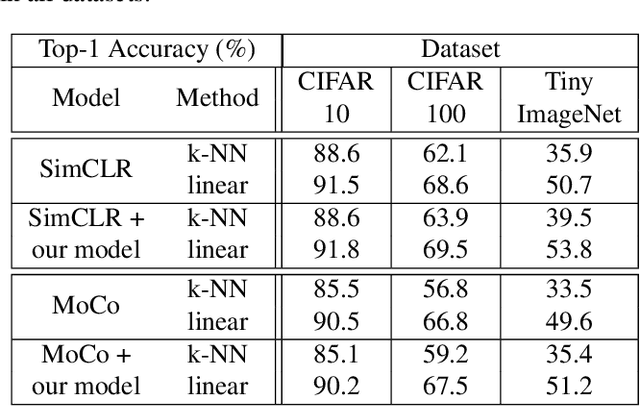
We introduce in this paper a new statistical perspective, exploiting the Jaccard similarity metric, as a measure-based metric to effectively invoke non-linear features in the loss of self-supervised contrastive learning. Specifically, our proposed metric may be interpreted as a dependence measure between two adapted projections learned from the so-called latent representations. This is in contrast to the cosine similarity measure in the conventional contrastive learning model, which accounts for correlation information. To the best of our knowledge, this effectively non-linearly fused information embedded in the Jaccard similarity, is novel to self-supervision learning with promising results. The proposed approach is compared to two state-of-the-art self-supervised contrastive learning methods on three image datasets. We not only demonstrate its amenable applicability in current ML problems, but also its improved performance and training efficiency.
Towards Analyzing the Bias of News Recommender Systems Using Sentiment and Stance Detection
Mar 11, 2022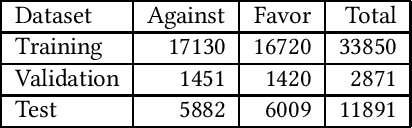

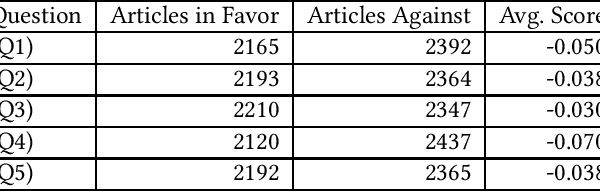
News recommender systems are used by online news providers to alleviate information overload and to provide personalized content to users. However, algorithmic news curation has been hypothesized to create filter bubbles and to intensify users' selective exposure, potentially increasing their vulnerability to polarized opinions and fake news. In this paper, we show how information on news items' stance and sentiment can be utilized to analyze and quantify the extent to which recommender systems suffer from biases. To that end, we have annotated a German news corpus on the topic of migration using stance detection and sentiment analysis. In an experimental evaluation with four different recommender systems, our results show a slight tendency of all four models for recommending articles with negative sentiments and stances against the topic of refugees and migration. Moreover, we observed a positive correlation between the sentiment and stance bias of the text-based recommenders and the preexisting user bias, which indicates that these systems amplify users' opinions and decrease the diversity of recommended news. The knowledge-aware model appears to be the least prone to such biases, at the cost of predictive accuracy.
Autoregressive Co-Training for Learning Discrete Speech Representations
Mar 29, 2022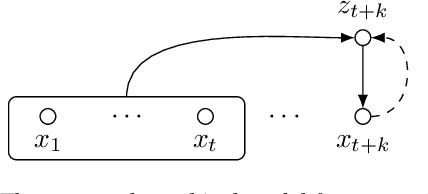
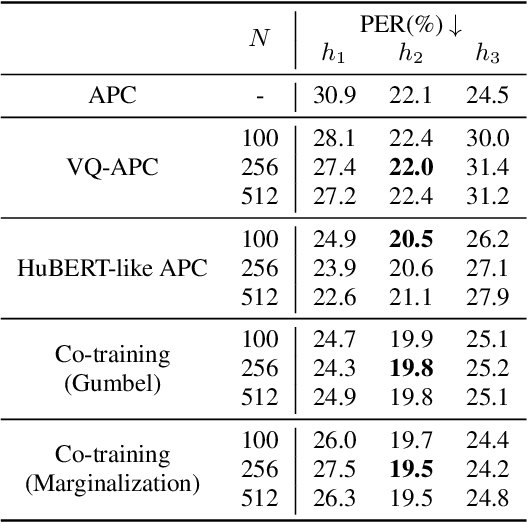
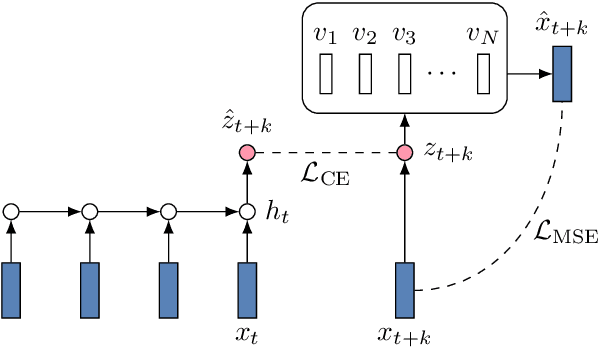
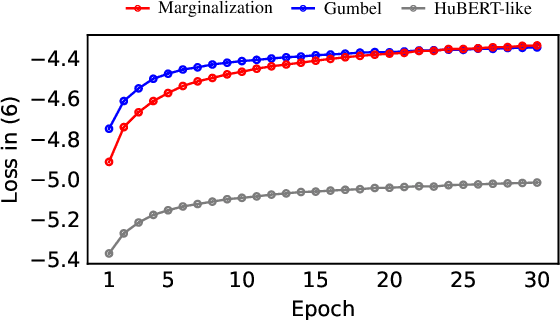
While several self-supervised approaches for learning discrete speech representation have been proposed, it is unclear how these seemingly similar approaches relate to each other. In this paper, we consider a generative model with discrete latent variables that learns a discrete representation for speech. The objective of learning the generative model is formulated as information-theoretic co-training. Besides the wide generality, the objective can be optimized with several approaches, subsuming HuBERT-like training and vector quantization for learning discrete representation. Empirically, we find that the proposed approach learns discrete representation that is highly correlated with phonetic units, more correlated than HuBERT-like training and vector quantization.
Improving Lidar-Based Semantic Segmentation of Top-View Grid Maps by Learning Features in Complementary Representations
Mar 02, 2022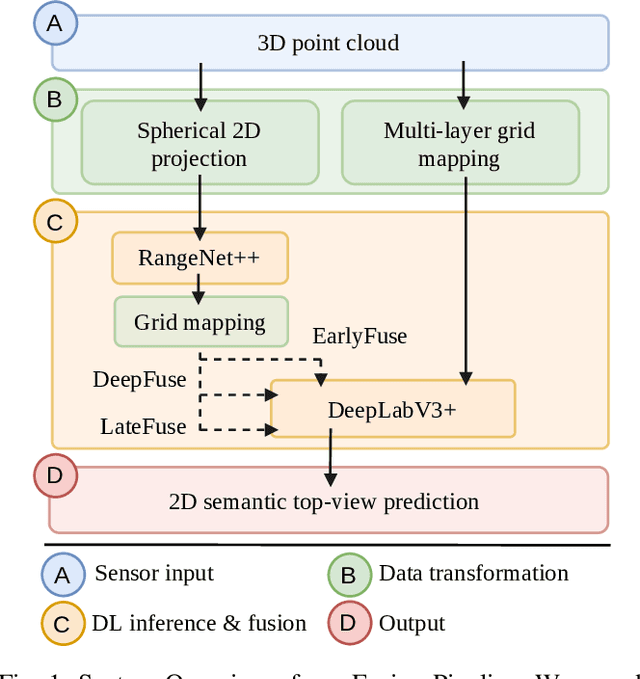
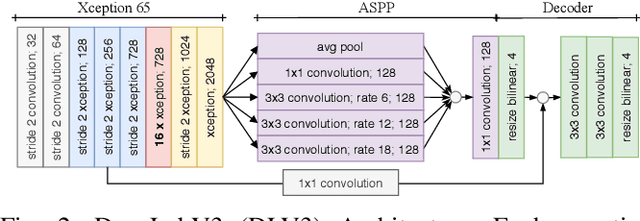
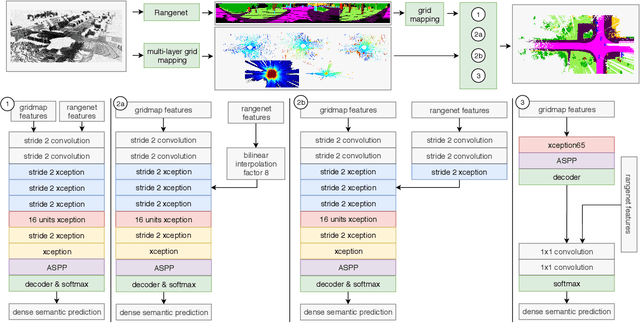

In this paper we introduce a novel way to predict semantic information from sparse, single-shot LiDAR measurements in the context of autonomous driving. In particular, we fuse learned features from complementary representations. The approach is aimed specifically at improving the semantic segmentation of top-view grid maps. Towards this goal the 3D LiDAR point cloud is projected onto two orthogonal 2D representations. For each representation a tailored deep learning architecture is developed to effectively extract semantic information which are fused by a superordinate deep neural network. The contribution of this work is threefold: (1) We examine different stages within the segmentation network for fusion. (2) We quantify the impact of embedding different features. (3) We use the findings of this survey to design a tailored deep neural network architecture leveraging respective advantages of different representations. Our method is evaluated using the SemanticKITTI dataset which provides a point-wise semantic annotation of more than 23.000 LiDAR measurements.
$π$BO: Augmenting Acquisition Functions with User Beliefs for Bayesian Optimization
Apr 23, 2022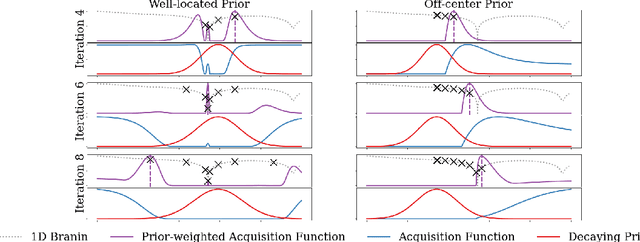
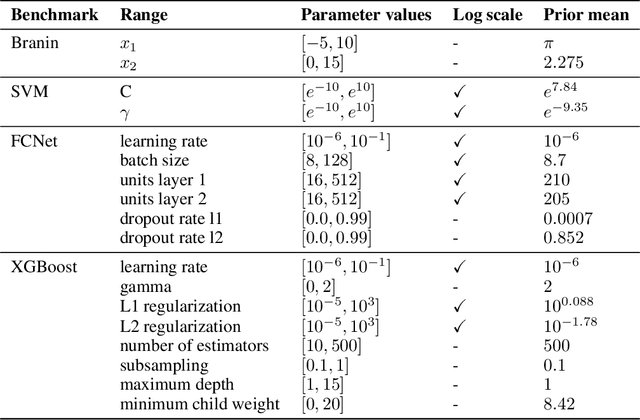
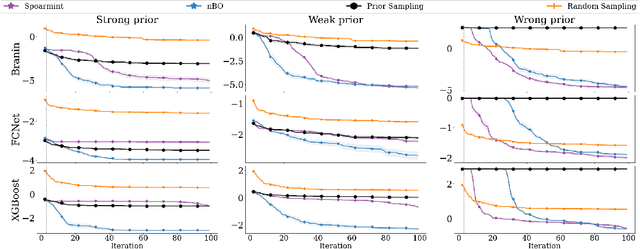

Bayesian optimization (BO) has become an established framework and popular tool for hyperparameter optimization (HPO) of machine learning (ML) algorithms. While known for its sample-efficiency, vanilla BO can not utilize readily available prior beliefs the practitioner has on the potential location of the optimum. Thus, BO disregards a valuable source of information, reducing its appeal to ML practitioners. To address this issue, we propose $\pi$BO, an acquisition function generalization which incorporates prior beliefs about the location of the optimum in the form of a probability distribution, provided by the user. In contrast to previous approaches, $\pi$BO is conceptually simple and can easily be integrated with existing libraries and many acquisition functions. We provide regret bounds when $\pi$BO is applied to the common Expected Improvement acquisition function and prove convergence at regular rates independently of the prior. Further, our experiments show that $\pi$BO outperforms competing approaches across a wide suite of benchmarks and prior characteristics. We also demonstrate that $\pi$BO improves on the state-of-the-art performance for a popular deep learning task, with a 12.5 $\times$ time-to-accuracy speedup over prominent BO approaches.
PLGAN: Generative Adversarial Networks for Power-Line Segmentation in Aerial Images
Apr 14, 2022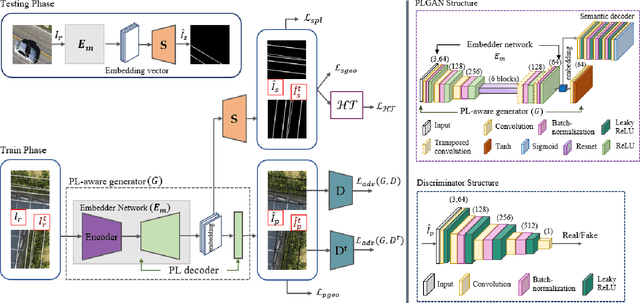

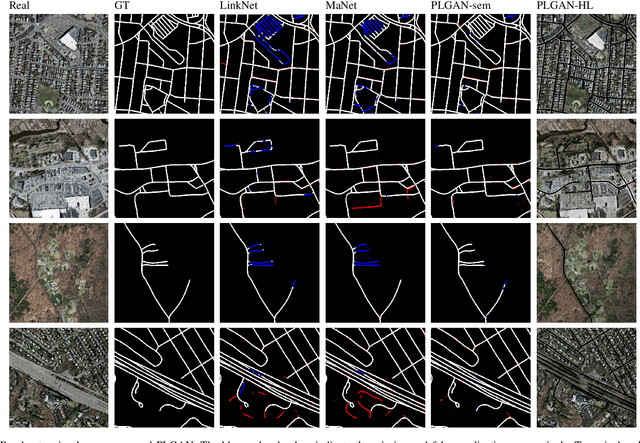
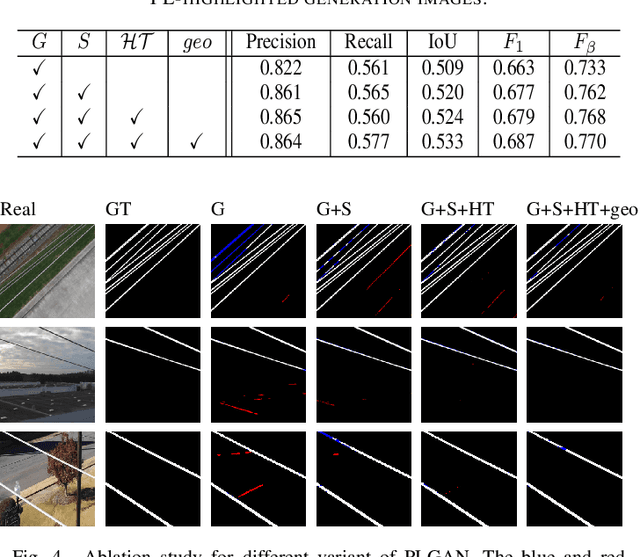
Accurate segmentation of power lines in various aerial images is very important for UAV flight safety. The complex background and very thin structures of power lines, however, make it an inherently difficult task in computer vision. This paper presents PLGAN, a simple yet effective method based on generative adversarial networks, to segment power lines from aerial images with different backgrounds. Instead of directly using the adversarial networks to generate the segmentation, we take their certain decoding features and embed them into another semantic segmentation network by considering more context, geometry, and appearance information of power lines. We further exploit the appropriate form of the generated images for high-quality feature embedding and define a new loss function in the Hough-transform parameter space to enhance the segmentation of very thin power lines. Extensive experiments and comprehensive analysis demonstrate that our proposed PLGAN outperforms the prior state-of-the-art methods for semantic segmentation and line detection.
Diverse Preference Augmentation with Multiple Domains for Cold-start Recommendations
Apr 01, 2022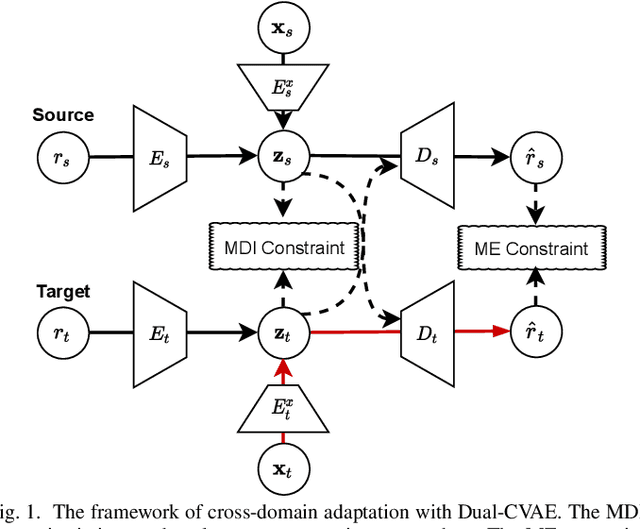
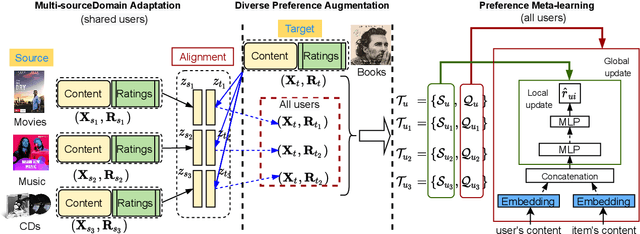
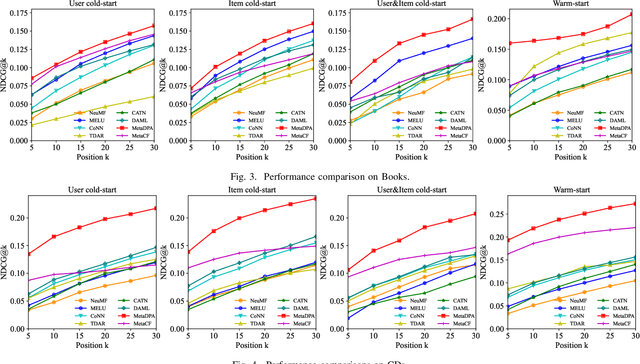
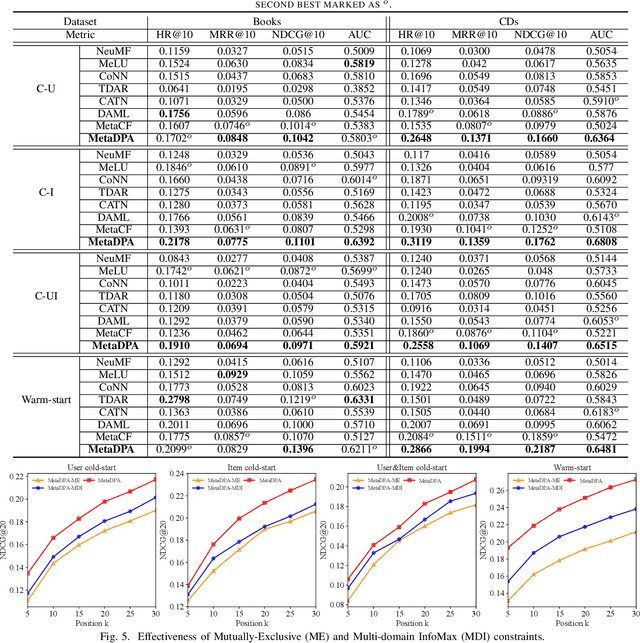
Cold-start issues have been more and more challenging for providing accurate recommendations with the fast increase of users and items. Most existing approaches attempt to solve the intractable problems via content-aware recommendations based on auxiliary information and/or cross-domain recommendations with transfer learning. Their performances are often constrained by the extremely sparse user-item interactions, unavailable side information, or very limited domain-shared users. Recently, meta-learners with meta-augmentation by adding noises to labels have been proven to be effective to avoid overfitting and shown good performance on new tasks. Motivated by the idea of meta-augmentation, in this paper, by treating a user's preference over items as a task, we propose a so-called Diverse Preference Augmentation framework with multiple source domains based on meta-learning (referred to as MetaDPA) to i) generate diverse ratings in a new domain of interest (known as target domain) to handle overfitting on the case of sparse interactions, and to ii) learn a preference model in the target domain via a meta-learning scheme to alleviate cold-start issues. Specifically, we first conduct multi-source domain adaptation by dual conditional variational autoencoders and impose a Multi-domain InfoMax (MDI) constraint on the latent representations to learn domain-shared and domain-specific preference properties. To avoid overfitting, we add a Mutually-Exclusive (ME) constraint on the output of decoders to generate diverse ratings given content data. Finally, these generated diverse ratings and the original ratings are introduced into the meta-training procedure to learn a preference meta-learner, which produces good generalization ability on cold-start recommendation tasks. Experiments on real-world datasets show our proposed MetaDPA clearly outperforms the current state-of-the-art baselines.