 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robustness of Machine Learning Models Beyond Adversarial Attacks
Apr 21, 2022
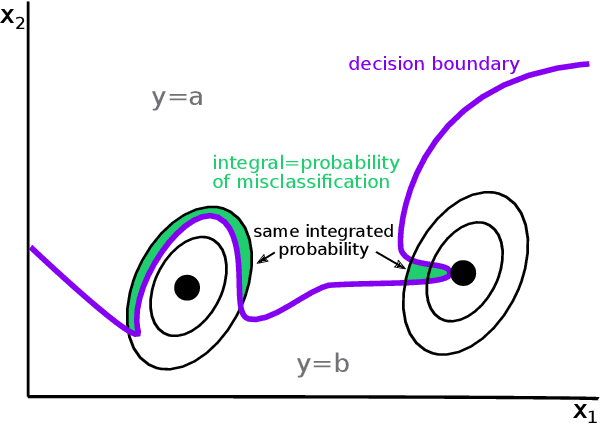
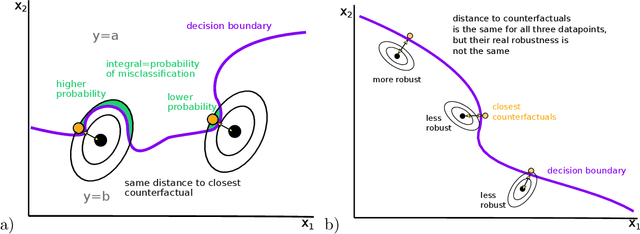
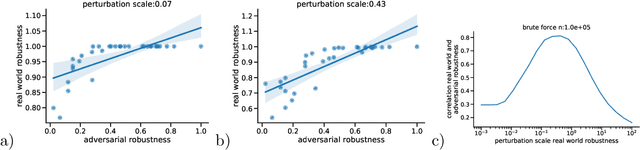
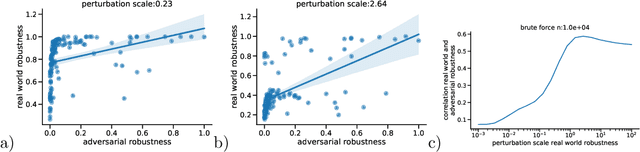
Correctly quantifying the robustness of machine learning models is a central aspect in judging their suitability for specific tasks, and thus, ultimately, for generating trust in the models. We show that the widely used concept of adversarial robustness and closely related metrics based on counterfactuals are not necessarily valid metrics for determining the robustness of ML models against perturbations that occur "naturally", outside specific adversarial attack scenarios. Additionally, we argue that generic robustness metrics in principle are insufficient for determining real-world-robustness. Instead we propose a flexible approach that models possible perturbations in input data individually for each application. This is then combined with a probabilistic approach that computes the likelihood that a real-world perturbation will change a prediction, thus giving quantitative information of the robustness of the trained machine learning model. The method does not require access to the internals of the classifier and thus in principle works for any black-box model. It is, however, based on Monte-Carlo sampling and thus only suited for input spaces with small dimensions. We illustrate our approach on two dataset, as well as on analytically solvable cases. Finally, we discuss ideas on how real-world robustness could be computed or estimated in high-dimensional input spaces.
A New Dataset and Transformer for Stereoscopic Video Super-Resolution
Apr 21, 2022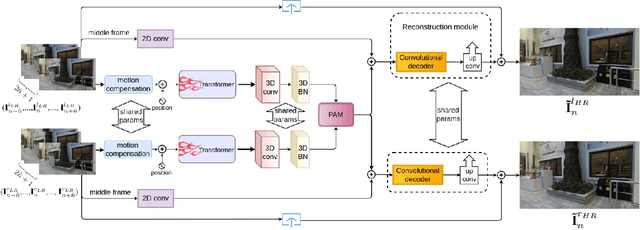
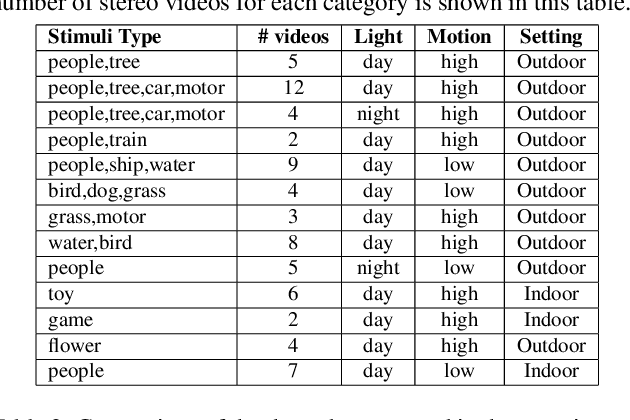

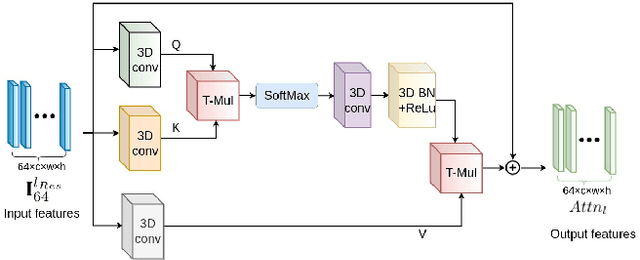
Stereo video super-resolution (SVSR) aims to enhance the spatial resolution of the low-resolution video by reconstructing the high-resolution video. The key challenges in SVSR are preserving the stereo-consistency and temporal-consistency, without which viewers may experience 3D fatigue. There are several notable works on stereoscopic image super-resolution, but there is little research on stereo video super-resolution. In this paper, we propose a novel Transformer-based model for SVSR, namely Trans-SVSR. Trans-SVSR comprises two key novel components: a spatio-temporal convolutional self-attention layer and an optical flow-based feed-forward layer that discovers the correlation across different video frames and aligns the features. The parallax attention mechanism (PAM) that uses the cross-view information to consider the significant disparities is used to fuse the stereo views. Due to the lack of a benchmark dataset suitable for the SVSR task, we collected a new stereoscopic video dataset, SVSR-Set, containing 71 full high-definition (HD) stereo videos captured using a professional stereo camera. Extensive experiments on the collected dataset, along with two other datasets, demonstrate that the Trans-SVSR can achieve competitive performance compared to the state-of-the-art methods. Project code and additional results are available at https://github.com/H-deep/Trans-SVSR/
WikiDiverse: A Multimodal Entity Linking Dataset with Diversified Contextual Topics and Entity Types
Apr 13, 2022
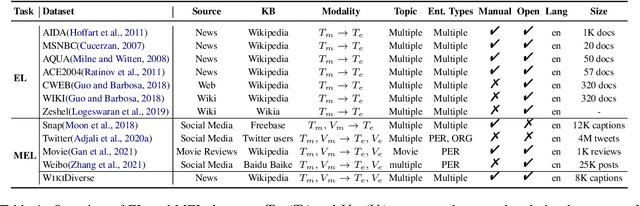
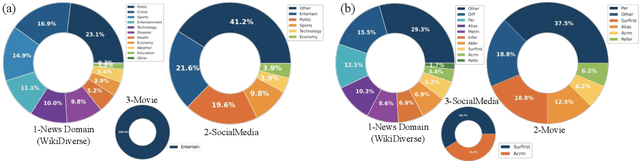

Multimodal Entity Linking (MEL) which aims at linking mentions with multimodal contexts to the referent entities from a knowledge base (e.g., Wikipedia), is an essential task for many multimodal applications. Although much attention has been paid to MEL, the shortcomings of existing MEL datasets including limited contextual topics and entity types, simplified mention ambiguity, and restricted availability, have caused great obstacles to the research and application of MEL. In this paper, we present WikiDiverse, a high-quality human-annotated MEL dataset with diversified contextual topics and entity types from Wikinews, which uses Wikipedia as the corresponding knowledge base. A well-tailored annotation procedure is adopted to ensure the quality of the dataset. Based on WikiDiverse, a sequence of well-designed MEL models with intra-modality and inter-modality attentions are implemented, which utilize the visual information of images more adequately than existing MEL models do. Extensive experimental analyses are conducted to investigate the contributions of different modalities in terms of MEL, facilitating the future research on this task. The dataset and baseline models are available at https://github.com/wangxw5/wikiDiverse.
Probability Link Models with Symmetric Information Divergence
Aug 10, 2020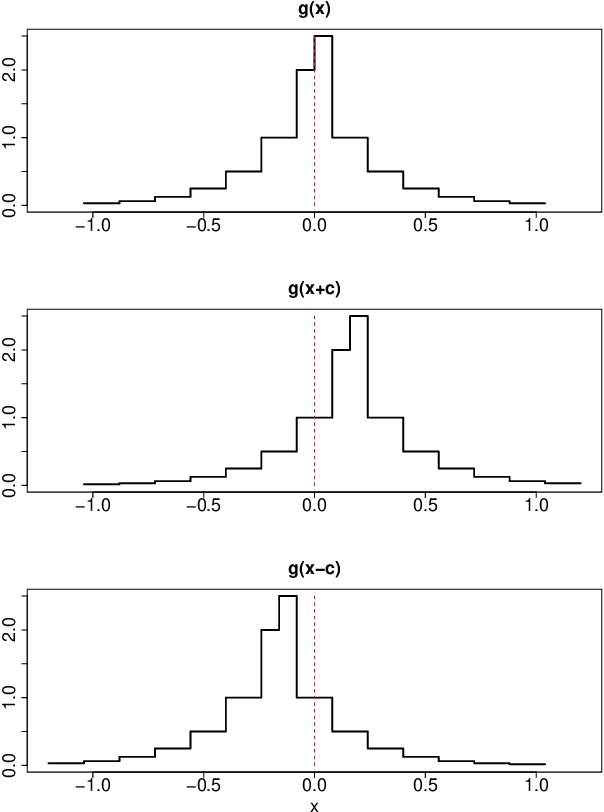
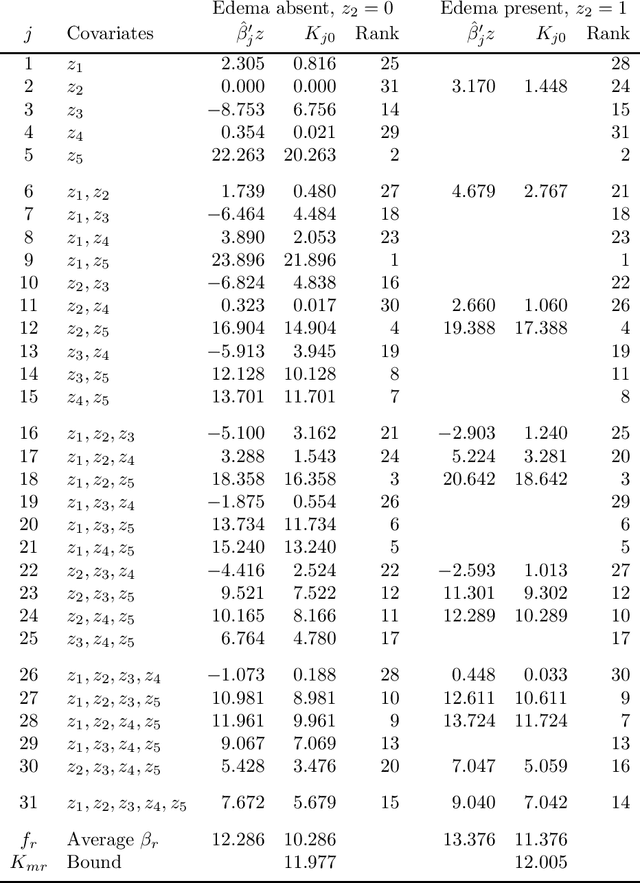
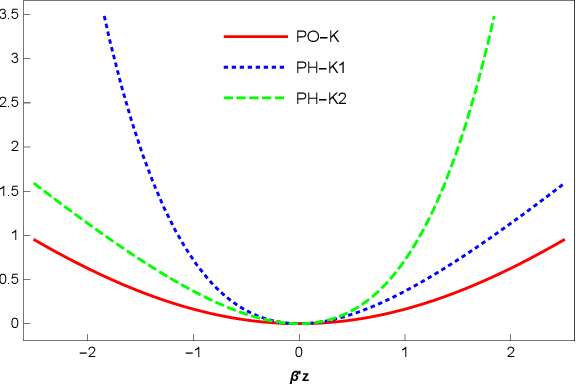
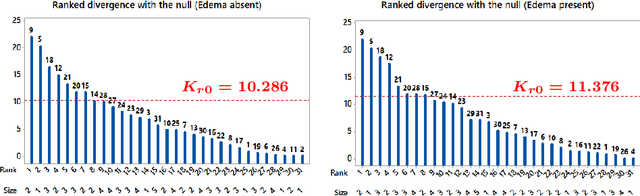
This paper introduces link functions for transforming one probability distribution to another such that the Kullback-Leibler and R\'enyi divergences between the two distributions are symmetric. Two general classes of link models are proposed. The first model links two survival functions and is applicable to models such as the proportional odds and change point, which are used in survival analysis and reliability modeling. A prototype application involving the proportional odds model demonstrates advantages of symmetric divergence measures over asymmetric measures for assessing the efficacy of features and for model averaging purposes. The advantages include providing unique ranks for models and unique information weights for model averaging with one-half as much computation requirement of asymmetric divergences. The second model links two cumulative probability distribution functions. This model produces a generalized location model which are continuous counterparts of the binary probability models such as probit and logit models. Examples include the generalized probit and logit models which have appeared in the survival analysis literature, and a generalized Laplace model and a generalized Student-$t$ model, which are survival time models corresponding to the respective binary probability models. Lastly, extensions to symmetric divergence between survival functions and conditions for copula dependence information are presented.
A data filling methodology for time series based on CNN and (Bi)LSTM neural networks
Apr 21, 2022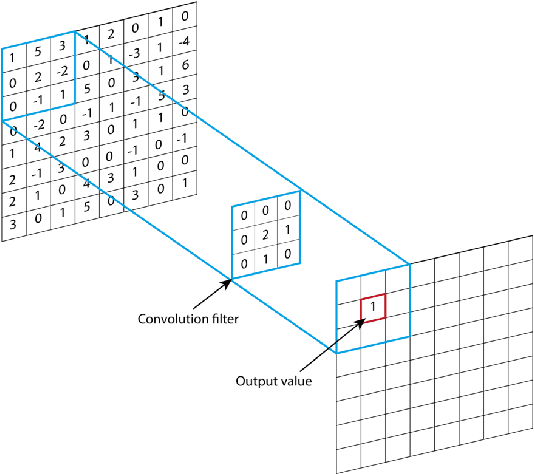
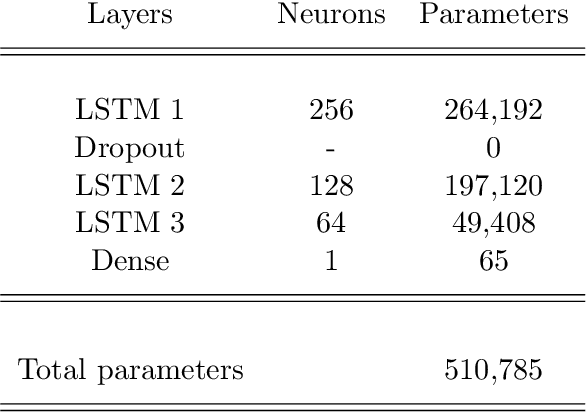
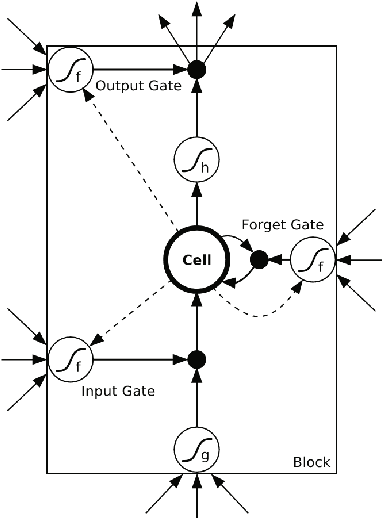
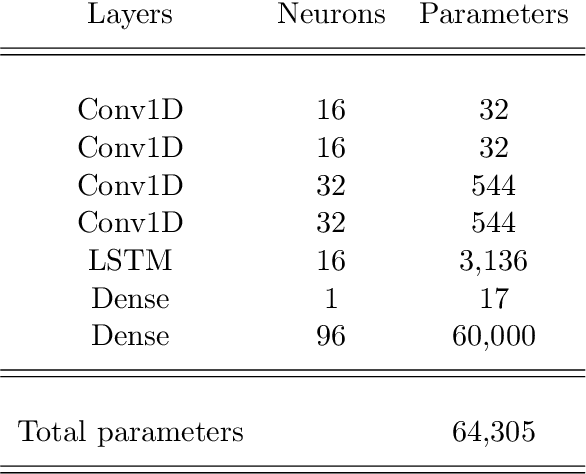
In the process of collecting data from sensors, several circumstances can affect their continuity and validity, resulting in alterations of the data or loss of information. Although classical methods of statistics, such as interpolation-like techniques, can be used to approximate the missing data in a time series, the recent developments in Deep Learning (DL) have given impetus to innovative and much more accurate forecasting techniques. In the present paper, we develop two DL models aimed at filling data gaps, for the specific case of internal temperature time series obtained from monitored apartments located in Bolzano, Italy. The DL models developed in the present work are based on the combination of Convolutional Neural Networks (CNNs), Long Short-Term Memory Neural Networks (LSTMs), and Bidirectional LSTMs (BiLSTMs). Two key features of our models are the use of both pre- and post-gap data, and the exploitation of a correlated time series (the external temperature) in order to predict the target one (the internal temperature). Our approach manages to capture the fluctuating nature of the data and shows good accuracy in reconstructing the target time series. In addition, our models significantly improve the already good results from another DL architecture that is used as a baseline for the present work.
FocalClick: Towards Practical Interactive Image Segmentation
Apr 17, 2022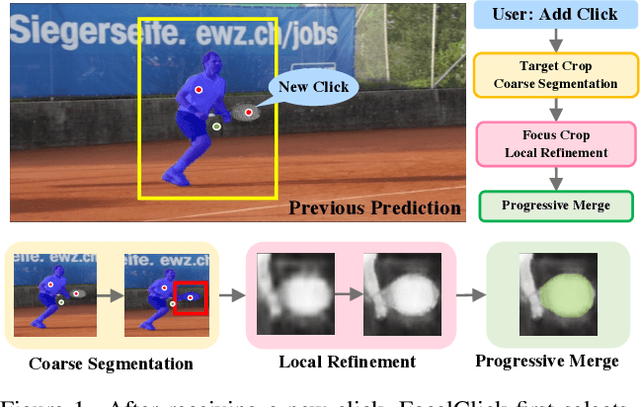


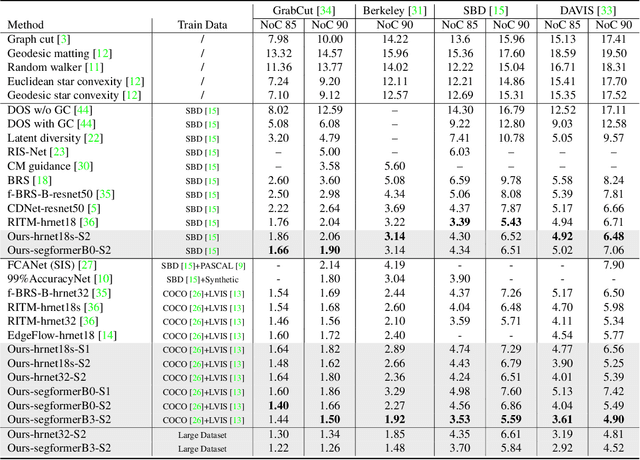
Interactive segmentation allows users to extract target masks by making positive/negative clicks. Although explored by many previous works, there is still a gap between academic approaches and industrial needs: first, existing models are not efficient enough to work on low power devices; second, they perform poorly when used to refine preexisting masks as they could not avoid destroying the correct part. FocalClick solves both issues at once by predicting and updating the mask in localized areas. For higher efficiency, we decompose the slow prediction on the entire image into two fast inferences on small crops: a coarse segmentation on the Target Crop, and a local refinement on the Focus Crop. To make the model work with preexisting masks, we formulate a sub-task termed Interactive Mask Correction, and propose Progressive Merge as the solution. Progressive Merge exploits morphological information to decide where to preserve and where to update, enabling users to refine any preexisting mask effectively. FocalClick achieves competitive results against SOTA methods with significantly smaller FLOPs. It also shows significant superiority when making corrections on preexisting masks. Code and data will be released at github.com/XavierCHEN34/ClickSEG
One-step Method for Material Quantitation using In-line Tomography with Single Scanning
Apr 17, 2022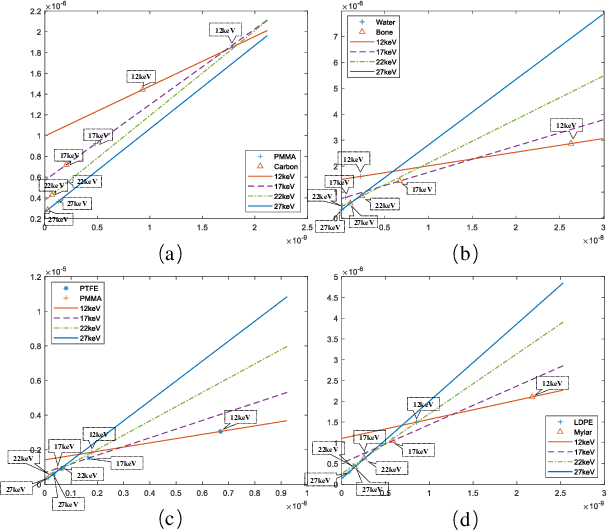

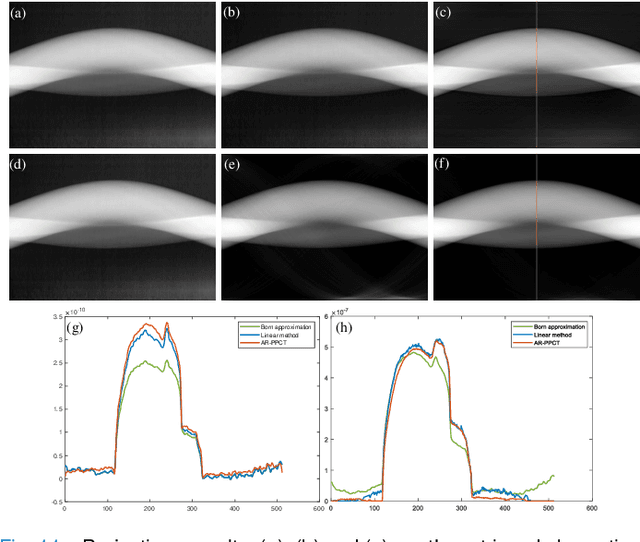
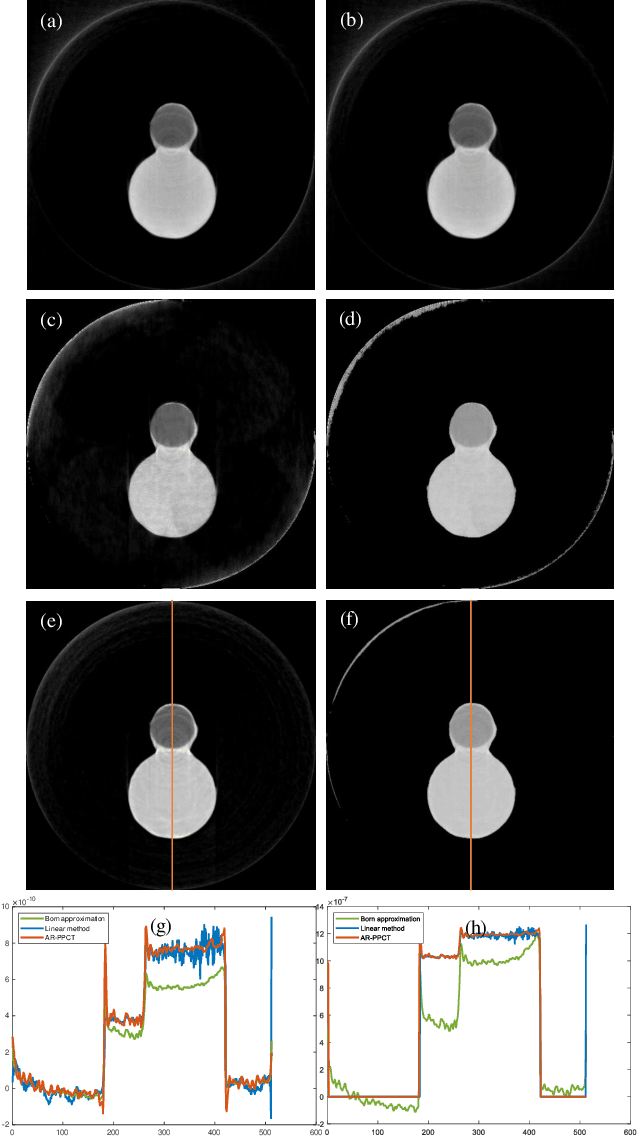
Objective: Quantitative technique based on In-line phase-contrast computed tomography with single scanning attracts more attention in application due to the flexibility of the implementation. However, the quantitative results usually suffer from artifacts and noise, since the phase retrieval and reconstruction are independent ("two-steps") without feedback from the original data. Our goal is to develop a method for material quantitative imaging based on a priori information specifically for the single-scanning data. Method: An iterative method that directly reconstructs the refractive index decrement delta and imaginary beta of the object from observed data ("one-step") within single object-to-detector distance (ODD) scanning. Simultaneously, high-quality quantitative reconstruction results are obtained by using a linear approximation that achieves material decomposition in the iterative process. Results: By comparing the equivalent atomic number of the material decomposition results in experiments, the accuracy of the proposed method is greater than 97.2%. Conclusion: The quantitative reconstruction and decomposition results are effectively improved, and there are feedback and corrections during the iteration, which effectively reduce the impact of noise and errors. Significance: This algorithm has the potential for quantitative imaging research, especially for imaging live samples and human breast preclinical studies.
Do End-to-end Stereo Algorithms Under-utilize Information?
Oct 14, 2020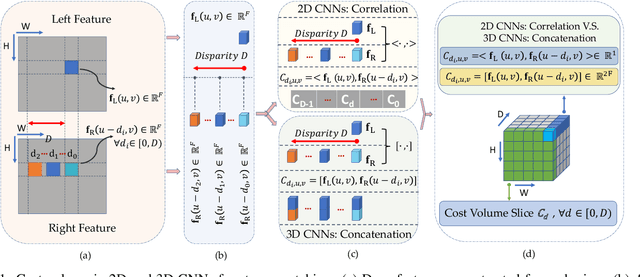
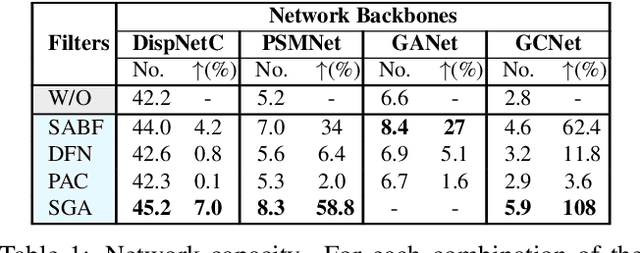
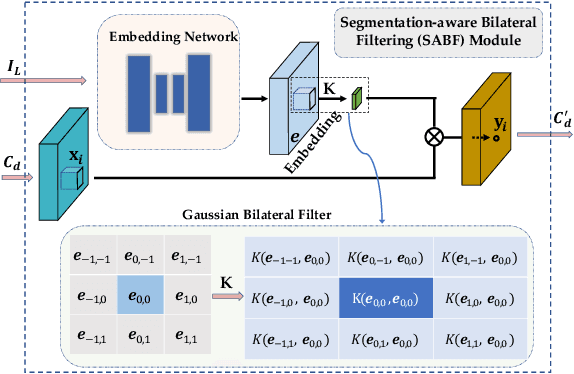
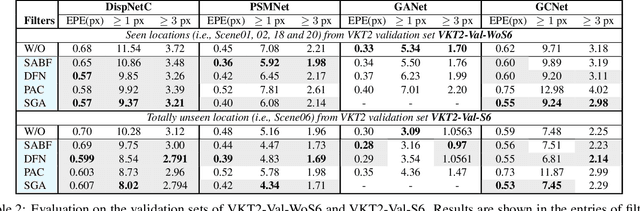
Deep networks for stereo matching typically leverage 2D or 3D convolutional encoder-decoder architectures to aggregate cost and regularize the cost volume for accurate disparity estimation. Due to content-insensitive convolutions and down-sampling and up-sampling operations, these cost aggregation mechanisms do not take full advantage of the information available in the images. Disparity maps suffer from over-smoothing near occlusion boundaries, and erroneous predictions in thin structures. In this paper, we show how deep adaptive filtering and differentiable semi-global aggregation can be integrated in existing 2D and 3D convolutional networks for end-to-end stereo matching, leading to improved accuracy. The improvements are due to utilizing RGB information from the images as a signal to dynamically guide the matching process, in addition to being the signal we attempt to match across the images. We show extensive experimental results on the KITTI 2015 and Virtual KITTI 2 datasets comparing four stereo networks (DispNetC, GCNet, PSMNet and GANet) after integrating four adaptive filters (segmentation-aware bilateral filtering, dynamic filtering networks, pixel adaptive convolution and semi-global aggregation) into their architectures. Our code is available at https://github.com/ccj5351/DAFStereoNets.
A World-Self Model Towards Understanding Intelligence
Apr 13, 2022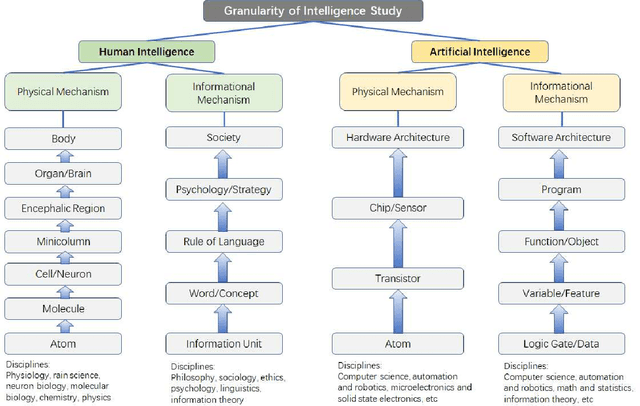
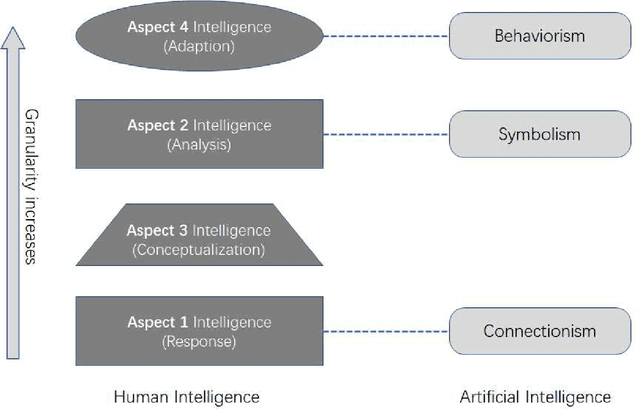
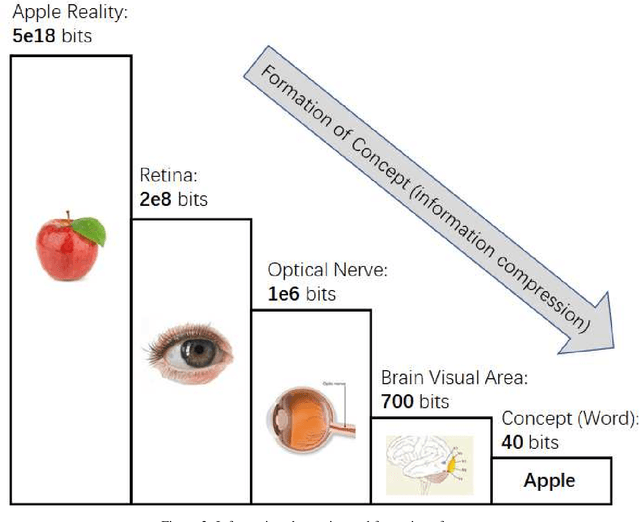
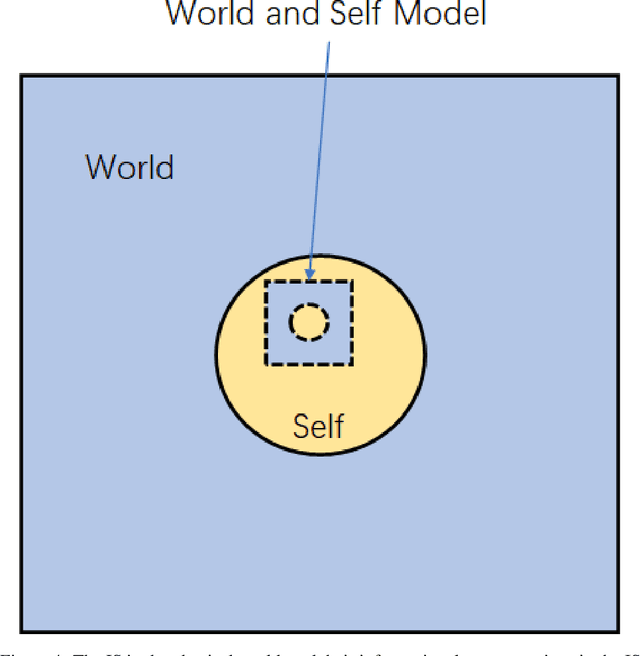
Artificial intelligence has achieved tremendous successes in various tasks, while it is still out of question that there are big gaps between artificial and human intelligence, and the nature of intelligence is still in darkness. In this work we will first stress the importance of defining the scope of discussion and choosing the right physical and informational granularity of investigation. We will carefully compare human and artificial intelligence, and propose that the information abstraction mechanism of human intelligence is the key to connect perception and cognition, and the lack of a new model is preventing the understanding and next-level implementation of intelligence. We will present the broader idea of "concept", the principles and mathematical frameworks of the new model World-Self Model (WSM) of intelligence, and finally an unified general framework of intelligence based on WSM. Rather than focusing on solving a specific problem or discussing a certain kind of intelligence, our work is instead towards a better understanding of the nature of the general phenomenon of intelligence, independent of the task or system of investigation.
Perception Visualization: Seeing Through the Eyes of a DNN
Apr 21, 2022
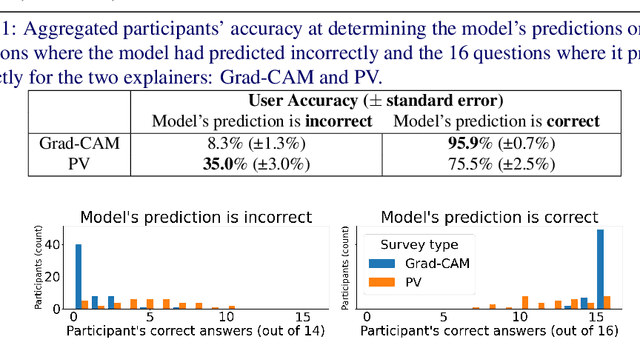

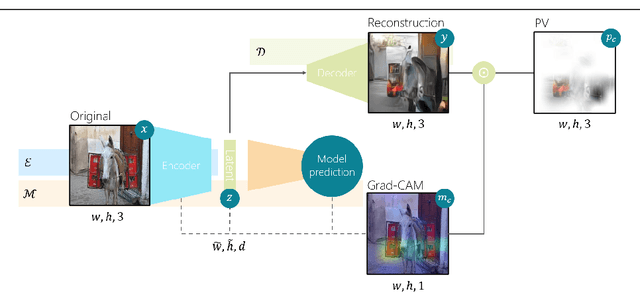
Artificial intelligence (AI) systems power the world we live in. Deep neural networks (DNNs) are able to solve tasks in an ever-expanding landscape of scenarios, but our eagerness to apply these powerful models leads us to focus on their performance and deprioritises our ability to understand them. Current research in the field of explainable AI tries to bridge this gap by developing various perturbation or gradient-based explanation techniques. For images, these techniques fail to fully capture and convey the semantic information needed to elucidate why the model makes the predictions it does. In this work, we develop a new form of explanation that is radically different in nature from current explanation methods, such as Grad-CAM. Perception visualization provides a visual representation of what the DNN perceives in the input image by depicting what visual patterns the latent representation corresponds to. Visualizations are obtained through a reconstruction model that inverts the encoded features, such that the parameters and predictions of the original models are not modified. Results of our user study demonstrate that humans can better understand and predict the system's decisions when perception visualizations are available, thus easing the debugging and deployment of deep models as trusted systems.