 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Band-Attention Modulated RetNet for Face Forgery Detection
Apr 09, 2024
The transformer networks are extensively utilized in face forgery detection due to their scalability across large datasets.Despite their success, transformers face challenges in balancing the capture of global context, which is crucial for unveiling forgery clues, with computational complexity.To mitigate this issue, we introduce Band-Attention modulated RetNet (BAR-Net), a lightweight network designed to efficiently process extensive visual contexts while avoiding catastrophic forgetting.Our approach empowers the target token to perceive global information by assigning differential attention levels to tokens at varying distances. We implement self-attention along both spatial axes, thereby maintaining spatial priors and easing the computational burden.Moreover, we present the adaptive frequency Band-Attention Modulation mechanism, which treats the entire Discrete Cosine Transform spectrogram as a series of frequency bands with learnable weights.Together, BAR-Net achieves favorable performance on several face forgery datasets, outperforming current state-of-the-art methods.
Adapting LLaMA Decoder to Vision Transformer
Apr 10, 2024This work examines whether decoder-only Transformers such as LLaMA, which were originally designed for large language models (LLMs), can be adapted to the computer vision field. We first "LLaMAfy" a standard ViT step-by-step to align with LLaMA's architecture, and find that directly applying a casual mask to the self-attention brings an attention collapse issue, resulting in the failure to the network training. We suggest to reposition the class token behind the image tokens with a post-sequence class token technique to overcome this challenge, enabling causal self-attention to efficiently capture the entire image's information. Additionally, we develop a soft mask strategy that gradually introduces a casual mask to the self-attention at the onset of training to facilitate the optimization behavior. The tailored model, dubbed as image LLaMA (iLLaMA), is akin to LLaMA in architecture and enables direct supervised learning. Its causal self-attention boosts computational efficiency and learns complex representation by elevating attention map ranks. iLLaMA rivals the performance with its encoder-only counterparts, achieving 75.1% ImageNet top-1 accuracy with only 5.7M parameters. Scaling the model to ~310M and pre-training on ImageNet-21K further enhances the accuracy to 86.0%. Extensive experiments demonstrate iLLaMA's reliable properties: calibration, shape-texture bias, quantization compatibility, ADE20K segmentation and CIFAR transfer learning. We hope our study can kindle fresh views to visual model design in the wave of LLMs. Pre-trained models and codes are available here.
Scaling Multi-Camera 3D Object Detection through Weak-to-Strong Eliciting
Apr 10, 2024The emergence of Multi-Camera 3D Object Detection (MC3D-Det), facilitated by bird's-eye view (BEV) representation, signifies a notable progression in 3D object detection. Scaling MC3D-Det training effectively accommodates varied camera parameters and urban landscapes, paving the way for the MC3D-Det foundation model. However, the multi-view fusion stage of the MC3D-Det method relies on the ill-posed monocular perception during training rather than surround refinement ability, leading to what we term "surround refinement degradation". To this end, our study presents a weak-to-strong eliciting framework aimed at enhancing surround refinement while maintaining robust monocular perception. Specifically, our framework employs weakly tuned experts trained on distinct subsets, and each is inherently biased toward specific camera configurations and scenarios. These biased experts can learn the perception of monocular degeneration, which can help the multi-view fusion stage to enhance surround refinement abilities. Moreover, a composite distillation strategy is proposed to integrate the universal knowledge of 2D foundation models and task-specific information. Finally, for MC3D-Det joint training, the elaborate dataset merge strategy is designed to solve the problem of inconsistent camera numbers and camera parameters. We set up a multiple dataset joint training benchmark for MC3D-Det and adequately evaluated existing methods. Further, we demonstrate the proposed framework brings a generalized and significant boost over multiple baselines. Our code is at \url{https://github.com/EnVision-Research/Scale-BEV}.
Vision-Language Model-based Physical Reasoning for Robot Liquid Perception
Apr 10, 2024There is a growing interest in applying large language models (LLMs) in robotic tasks, due to their remarkable reasoning ability and extensive knowledge learned from vast training corpora. Grounding LLMs in the physical world remains an open challenge as they can only process textual input. Recent advancements in large vision-language models (LVLMs) have enabled a more comprehensive understanding of the physical world by incorporating visual input, which provides richer contextual information than language alone. In this work, we proposed a novel paradigm that leveraged GPT-4V(ision), the state-of-the-art LVLM by OpenAI, to enable embodied agents to perceive liquid objects via image-based environmental feedback. Specifically, we exploited the physical understanding of GPT-4V to interpret the visual representation (e.g., time-series plot) of non-visual feedback (e.g., F/T sensor data), indirectly enabling multimodal perception beyond vision and language using images as proxies. We evaluated our method using 10 common household liquids with containers of various geometry and material. Without any training or fine-tuning, we demonstrated that our method can enable the robot to indirectly perceive the physical response of liquids and estimate their viscosity. We also showed that by jointly reasoning over the visual and physical attributes learned through interactions, our method could recognize liquid objects in the absence of strong visual cues (e.g., container labels with legible text or symbols), increasing the accuracy from 69.0% -- achieved by the best-performing vision-only variant -- to 86.0%.
An inclusive review on deep learning techniques and their scope in handwriting recognition
Apr 10, 2024Deep learning expresses a category of machine learning algorithms that have the capability to combine raw inputs into intermediate features layers. These deep learning algorithms have demonstrated great results in different fields. Deep learning has particularly witnessed for a great achievement of human level performance across a number of domains in computer vision and pattern recognition. For the achievement of state-of-the-art performances in diverse domains, the deep learning used different architectures and these architectures used activation functions to perform various computations between hidden and output layers of any architecture. This paper presents a survey on the existing studies of deep learning in handwriting recognition field. Even though the recent progress indicates that the deep learning methods has provided valuable means for speeding up or proving accurate results in handwriting recognition, but following from the extensive literature survey, the present study finds that the deep learning has yet to revolutionize more and has to resolve many of the most pressing challenges in this field, but promising advances have been made on the prior state of the art. Additionally, an inadequate availability of labelled data to train presents problems in this domain. Nevertheless, the present handwriting recognition survey foresees deep learning enabling changes at both bench and bedside with the potential to transform several domains as image processing, speech recognition, computer vision, machine translation, robotics and control, medical imaging, medical information processing, bio-informatics, natural language processing, cyber security, and many others.
LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding
Apr 08, 2024Recently, leveraging large language models (LLMs) or multimodal large language models (MLLMs) for document understanding has been proven very promising. However, previous works that employ LLMs/MLLMs for document understanding have not fully explored and utilized the document layout information, which is vital for precise document understanding. In this paper, we propose LayoutLLM, an LLM/MLLM based method for document understanding. The core of LayoutLLM is a layout instruction tuning strategy, which is specially designed to enhance the comprehension and utilization of document layouts. The proposed layout instruction tuning strategy consists of two components: Layout-aware Pre-training and Layout-aware Supervised Fine-tuning. To capture the characteristics of document layout in Layout-aware Pre-training, three groups of pre-training tasks, corresponding to document-level, region-level and segment-level information, are introduced. Furthermore, a novel module called layout chain-of-thought (LayoutCoT) is devised to enable LayoutLLM to focus on regions relevant to the question and generate accurate answers. LayoutCoT is effective for boosting the performance of document understanding. Meanwhile, it brings a certain degree of interpretability, which could facilitate manual inspection and correction. Experiments on standard benchmarks show that the proposed LayoutLLM significantly outperforms existing methods that adopt open-source 7B LLMs/MLLMs for document understanding. The training data of the LayoutLLM is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LayoutLLM
Product Description and QA Assisted Self-Supervised Opinion Summarization
Apr 08, 2024In e-commerce, opinion summarization is the process of summarizing the consensus opinions found in product reviews. However, the potential of additional sources such as product description and question-answers (QA) has been considered less often. Moreover, the absence of any supervised training data makes this task challenging. To address this, we propose a novel synthetic dataset creation (SDC) strategy that leverages information from reviews as well as additional sources for selecting one of the reviews as a pseudo-summary to enable supervised training. Our Multi-Encoder Decoder framework for Opinion Summarization (MEDOS) employs a separate encoder for each source, enabling effective selection of information while generating the summary. For evaluation, due to the unavailability of test sets with additional sources, we extend the Amazon, Oposum+, and Flipkart test sets and leverage ChatGPT to annotate summaries. Experiments across nine test sets demonstrate that the combination of our SDC approach and MEDOS model achieves on average a 14.5% improvement in ROUGE-1 F1 over the SOTA. Moreover, comparative analysis underlines the significance of incorporating additional sources for generating more informative summaries. Human evaluations further indicate that MEDOS scores relatively higher in coherence and fluency with 0.41 and 0.5 (-1 to 1) respectively, compared to existing models. To the best of our knowledge, we are the first to generate opinion summaries leveraging additional sources in a self-supervised setting.
Semantic Flow: Learning Semantic Field of Dynamic Scenes from Monocular Videos
Apr 08, 2024In this work, we pioneer Semantic Flow, a neural semantic representation of dynamic scenes from monocular videos. In contrast to previous NeRF methods that reconstruct dynamic scenes from the colors and volume densities of individual points, Semantic Flow learns semantics from continuous flows that contain rich 3D motion information. As there is 2D-to-3D ambiguity problem in the viewing direction when extracting 3D flow features from 2D video frames, we consider the volume densities as opacity priors that describe the contributions of flow features to the semantics on the frames. More specifically, we first learn a flow network to predict flows in the dynamic scene, and propose a flow feature aggregation module to extract flow features from video frames. Then, we propose a flow attention module to extract motion information from flow features, which is followed by a semantic network to output semantic logits of flows. We integrate the logits with volume densities in the viewing direction to supervise the flow features with semantic labels on video frames. Experimental results show that our model is able to learn from multiple dynamic scenes and supports a series of new tasks such as instance-level scene editing, semantic completions, dynamic scene tracking and semantic adaption on novel scenes. Codes are available at https://github.com/tianfr/Semantic-Flow/.
Language Models Can Reduce Asymmetry in Information Markets
Mar 21, 2024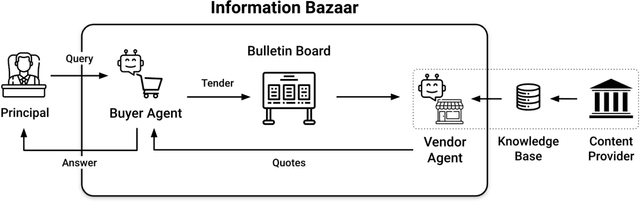

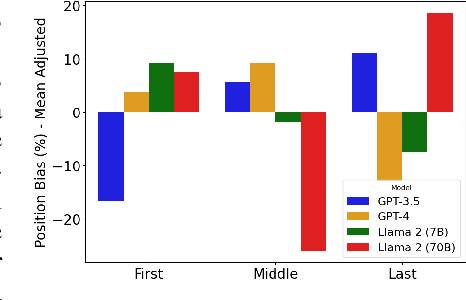
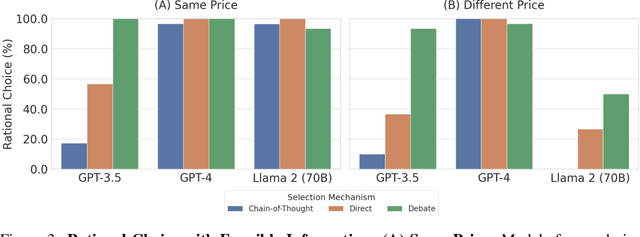
This work addresses the buyer's inspection paradox for information markets. The paradox is that buyers need to access information to determine its value, while sellers need to limit access to prevent theft. To study this, we introduce an open-source simulated digital marketplace where intelligent agents, powered by language models, buy and sell information on behalf of external participants. The central mechanism enabling this marketplace is the agents' dual capabilities: they not only have the capacity to assess the quality of privileged information but also come equipped with the ability to forget. This ability to induce amnesia allows vendors to grant temporary access to proprietary information, significantly reducing the risk of unauthorized retention while enabling agents to accurately gauge the information's relevance to specific queries or tasks. To perform well, agents must make rational decisions, strategically explore the marketplace through generated sub-queries, and synthesize answers from purchased information. Concretely, our experiments (a) uncover biases in language models leading to irrational behavior and evaluate techniques to mitigate these biases, (b) investigate how price affects demand in the context of informational goods, and (c) show that inspection and higher budgets both lead to higher quality outcomes.
Hierarchical Insights: Exploiting Structural Similarities for Reliable 3D Semantic Segmentation
Apr 09, 2024Safety-critical applications like autonomous driving call for robust 3D environment perception algorithms which can withstand highly diverse and ambiguous surroundings. The predictive performance of any classification model strongly depends on the underlying dataset and the prior knowledge conveyed by the annotated labels. While the labels provide a basis for the learning process, they usually fail to represent inherent relations between the classes - representations, which are a natural element of the human perception system. We propose a training strategy which enables a 3D LiDAR semantic segmentation model to learn structural relationships between the different classes through abstraction. We achieve this by implicitly modeling those relationships through a learning rule for hierarchical multi-label classification (HMC). With a detailed analysis we show, how this training strategy not only improves the model's confidence calibration, but also preserves additional information for downstream tasks like fusion, prediction and planning.