 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gender classification by means of online uppercase handwriting: A text-dependent allographic approach
Mar 18, 2022

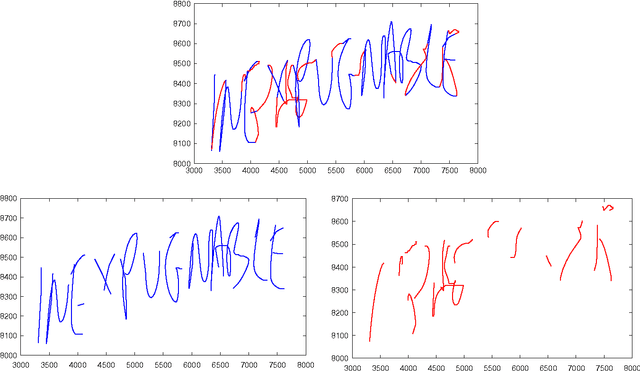
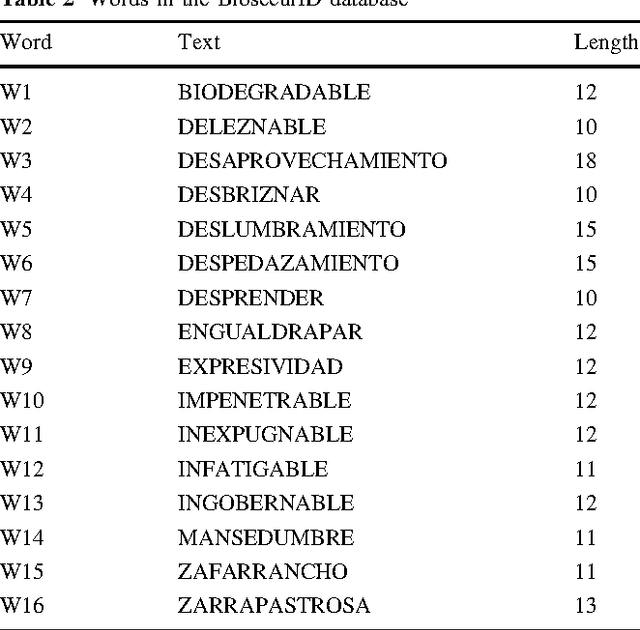
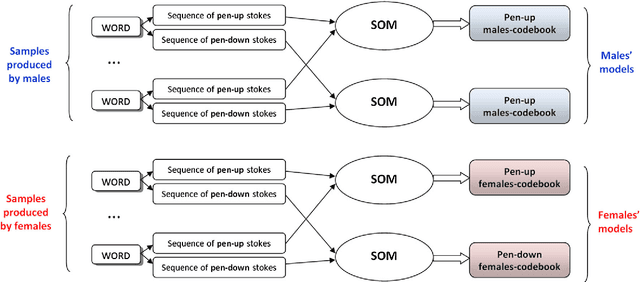
This paper presents a gender classification schema based on online handwriting. Using samples acquired with a digital tablet that captures the dynamics of the writing, it classifies the writer as a male or a female. The method proposed is allographic, regarding strokes as the structural units of handwriting. Strokes performed while the writing device is not exerting any pressure on the writing surface, pen-up (in-air) strokes, are also taken into account. The method is also text-dependent meaning that training and testing is done with exactly the same text. Text-dependency allows classification be performed with very small amounts of text. Experimentation, performed with samples from the BiosecurID database, yields results that fall in the range of the classification averages expected from human judges. With only four repetitions of a single uppercase word, the average rate of well classified writers is 68%; with sixteen words, the rate rises to an average 72.6%. Statistical analysis reveals that the aforementioned rates are highly significant. In order to explore the classification potential of the pen-up strokes, these are also considered. Although in this case results are not conclusive, an outstanding average of 74% of well classified writers is obtained when information from pen-up strokes is combined with information from pen-down ones.
* 25 pages, published in Cogn Comput 8, pages 15 to 29, year 2016
Modeling Lost Information in Lossy Image Compression
Jul 08, 2020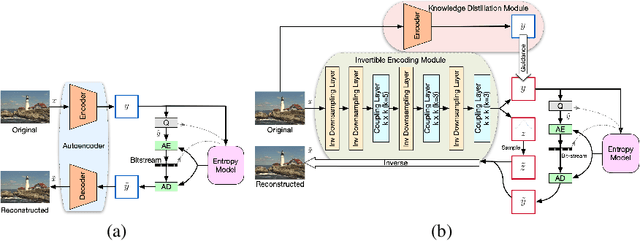

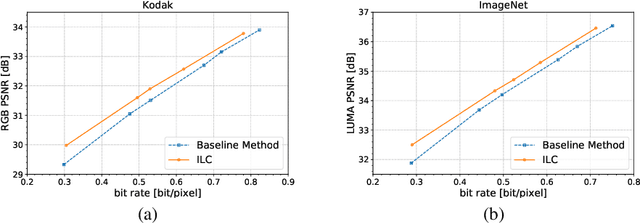
Lossy image compression is one of the most commonly used operators for digital images. Most recently proposed deep-learning-based image compression methods leverage the auto-encoder structure, and reach a series of promising results in this field. The images are encoded into low dimensional latent features first, and entropy coded subsequently by exploiting the statistical redundancy. However, the information lost during encoding is unfortunately inevitable, which poses a significant challenge to the decoder to reconstruct the original images. In this work, we propose a novel invertible framework called Invertible Lossy Compression (ILC) to largely mitigate the information loss problem. Specifically, ILC introduces an invertible encoding module to replace the encoder-decoder structure to produce the low dimensional informative latent representation, meanwhile, transform the lost information into an auxiliary latent variable that won't be further coded or stored. The latent representation is quantized and encoded into bit-stream, and the latent variable is forced to follow a specified distribution, i.e. isotropic Gaussian distribution. In this way, recovering the original image is made tractable by easily drawing a surrogate latent variable and applying the inverse pass of the module with the sampled variable and decoded latent features. Experimental results demonstrate that with a new component replacing the auto-encoder in image compression methods, ILC can significantly outperform the baseline method on extensive benchmark datasets by combining with the existing compression algorithms.
High-Rate Quantum Private Information Retrieval with Weakly Self-Dual Star Product Codes
Feb 04, 2021
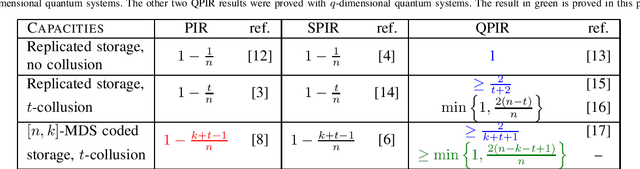
In the classical private information retrieval (PIR) setup, a user wants to retrieve a file from a database or a distributed storage system (DSS) without revealing the file identity to the servers holding the data. In the quantum PIR (QPIR) setting, a user privately retrieves a classical file by receiving quantum information from the servers. The QPIR problem has been treated by Song et al. in the case of replicated servers, both with and without collusion. QPIR over $[n,k]$ maximum distance separable (MDS) coded servers was recently considered by Allaix et al., but the collusion was essentially restricted to $t=n-k$ servers. In this paper, the QPIR setting is extended to account for more flexible collusion of servers satisfying $t < n-k+1$. Similarly to the previous cases, the rates achieved are better than those known or conjectured in the classical counterparts, as well as those of the previously proposed coded and colluding QPIR schemes. This is enabled by considering the stabilizer formalism and weakly self-dual generalized Reed--Solomon (GRS) star product codes.
Transferring Chemical and Energetic Knowledge Between Molecular Systems with Machine Learning
May 06, 2022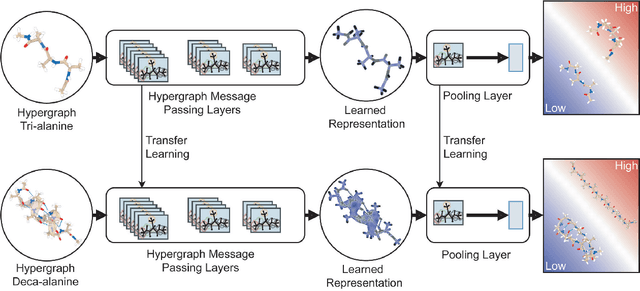
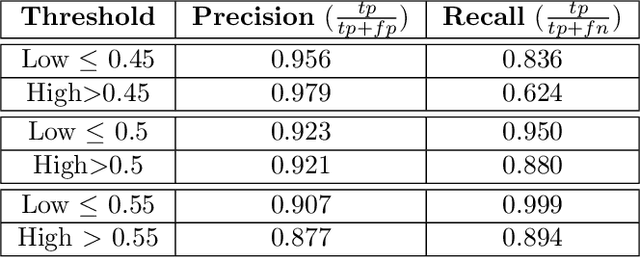
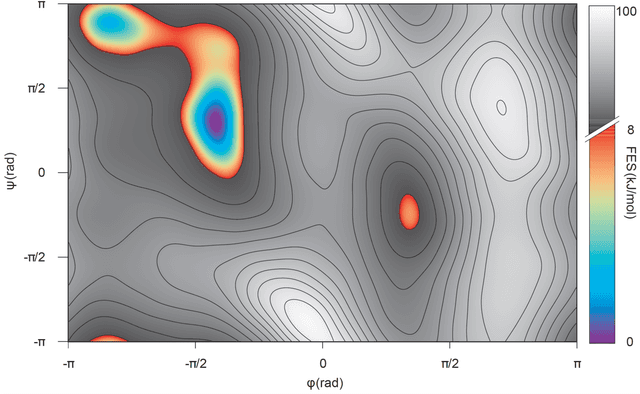
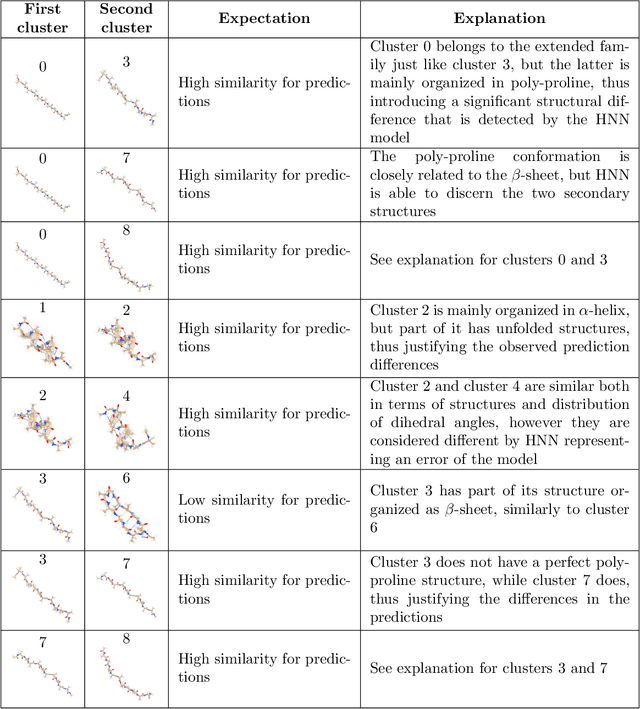
Predicting structural and energetic properties of a molecular system is one of the fundamental tasks in molecular simulations, and it has use cases in chemistry, biology, and medicine. In the past decade, the advent of machine learning algorithms has impacted on molecular simulations for various tasks, including property prediction of atomistic systems. In this paper, we propose a novel methodology for transferring knowledge obtained from simple molecular systems to a more complex one, possessing a significantly larger number of atoms and degrees of freedom. In particular, we focus on the classification of high and low free-energy states. Our approach relies on utilizing (i) a novel hypergraph representation of molecules, encoding all relevant information for characterizing the potential energy of a conformation, and (ii) novel message passing and pooling layers for processing and making predictions on such hypergraph-structured data. Despite the complexity of the problem, our results show a remarkable AUC of 0.92 for transfer learning from tri-alanine to the deca-alanine system. Moreover, we show that the very same transfer learning approach can be used to group, in an unsupervised way, various secondary structures of deca-alanine in clusters having similar free-energy values. Our study represents a proof of concept that reliable transfer learning models for molecular systems can be designed paving the way to unexplored routes in prediction of structural and energetic properties of biologically relevant systems.
ResT V2: Simpler, Faster and Stronger
Apr 15, 2022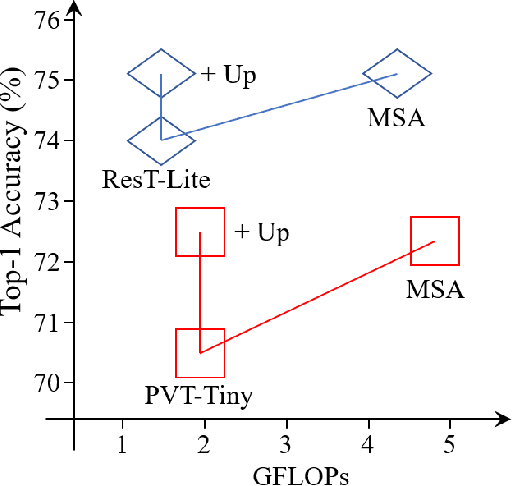
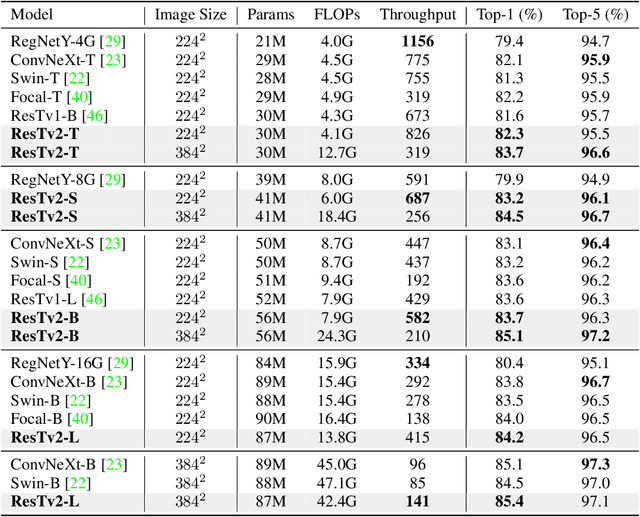
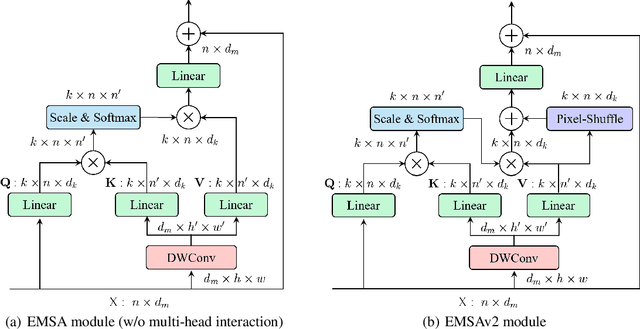

This paper proposes ResTv2, a simpler, faster, and stronger multi-scale vision Transformer for visual recognition. ResTv2 simplifies the EMSA structure in ResTv1 (i.e., eliminating the multi-head interaction part) and employs an upsample operation to reconstruct the lost medium- and high-frequency information caused by the downsampling operation. In addition, we explore different techniques for better apply ResTv2 backbones to downstream tasks. We found that although combining EMSAv2 and window attention can greatly reduce the theoretical matrix multiply FLOPs, it may significantly decrease the computation density, thus causing lower actual speed. We comprehensively validate ResTv2 on ImageNet classification, COCO detection, and ADE20K semantic segmentation. Experimental results show that the proposed ResTv2 can outperform the recently state-of-the-art backbones by a large margin, demonstrating the potential of ResTv2 as solid backbones. The code and models will be made publicly available at \url{https://github.com/wofmanaf/ResT}
Spatio-Temporal-Frequency Graph Attention Convolutional Network for Aircraft Recognition Based on Heterogeneous Radar Network
Apr 15, 2022
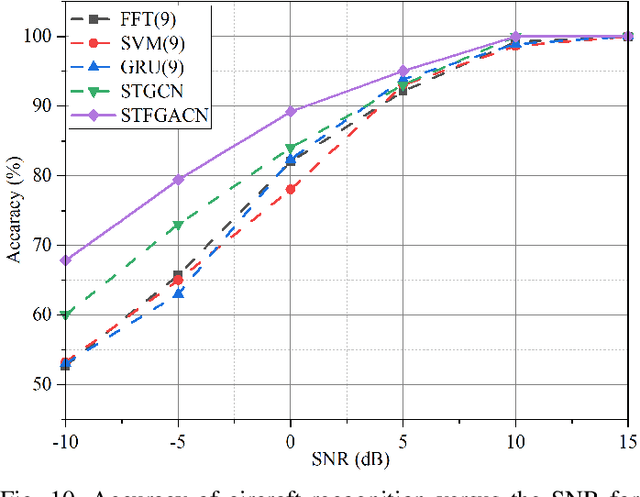
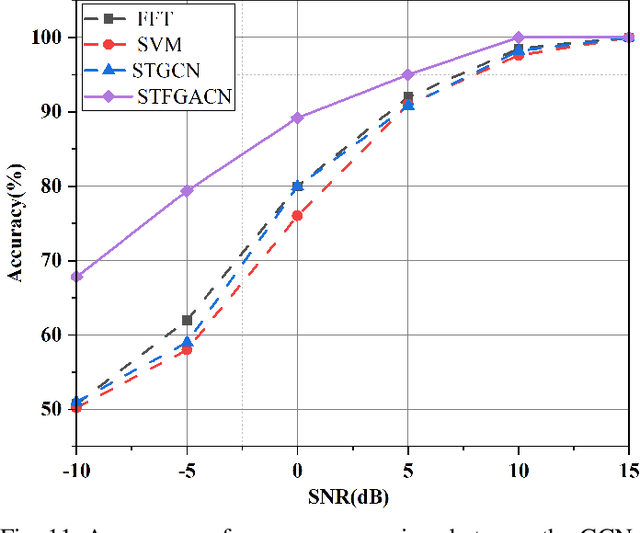
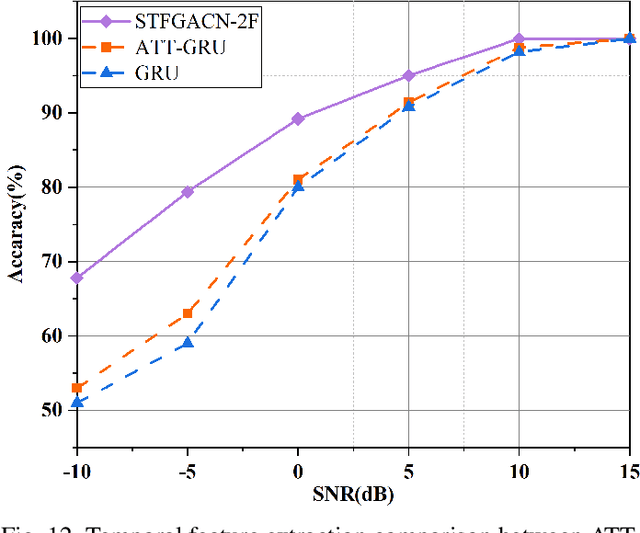
This paper proposes a knowledge-and-data-driven graph neural network-based collaboration learning model for reliable aircraft recognition in a heterogeneous radar network. The aircraft recognizability analysis shows that: (1) the semantic feature of an aircraft is motion patterns driven by the kinetic characteristics, and (2) the grammatical features contained in the radar cross-section (RCS) signals present spatial-temporal-frequency (STF) diversity decided by both the electromagnetic radiation shape and motion pattern of the aircraft. Then a STF graph attention convolutional network (STFGACN) is developed to distill semantic features from the RCS signals received by the heterogeneous radar network. Extensive experiment results verify that the STFGACN outperforms the baseline methods in terms of detection accuracy, and ablation experiments are carried out to further show that the expansion of the information dimension can gain considerable benefits to perform robustly in the low signal-to-noise ratio region.
Improving Neural ODEs via Knowledge Distillation
Mar 10, 2022
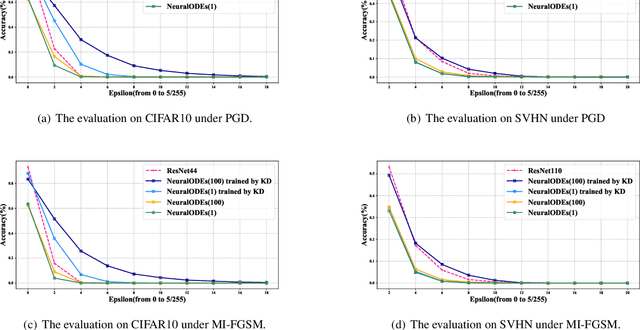
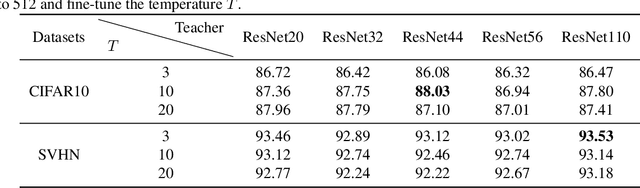

Neural Ordinary Differential Equations (Neural ODEs) construct the continuous dynamics of hidden units using ordinary differential equations specified by a neural network, demonstrating promising results on many tasks. However, Neural ODEs still do not perform well on image recognition tasks. The possible reason is that the one-hot encoding vector commonly used in Neural ODEs can not provide enough supervised information. We propose a new training based on knowledge distillation to construct more powerful and robust Neural ODEs fitting image recognition tasks. Specially, we model the training of Neural ODEs into a teacher-student learning process, in which we propose ResNets as the teacher model to provide richer supervised information. The experimental results show that the new training manner can improve the classification accuracy of Neural ODEs by 24% on CIFAR10 and 5% on SVHN. In addition, we also quantitatively discuss the effect of both knowledge distillation and time horizon in Neural ODEs on robustness against adversarial examples. The experimental analysis concludes that introducing the knowledge distillation and increasing the time horizon can improve the robustness of Neural ODEs against adversarial examples.
Adjacent Context Coordination Network for Salient Object Detection in Optical Remote Sensing Images
Mar 25, 2022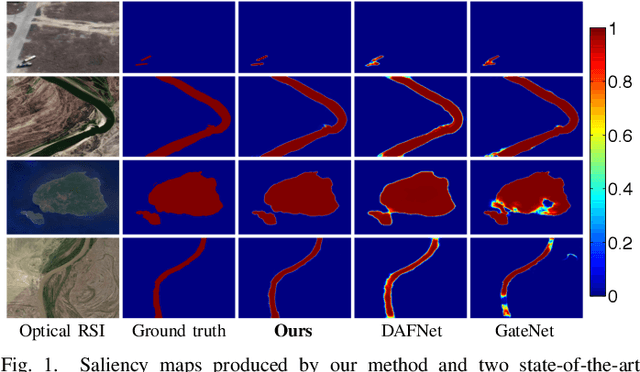
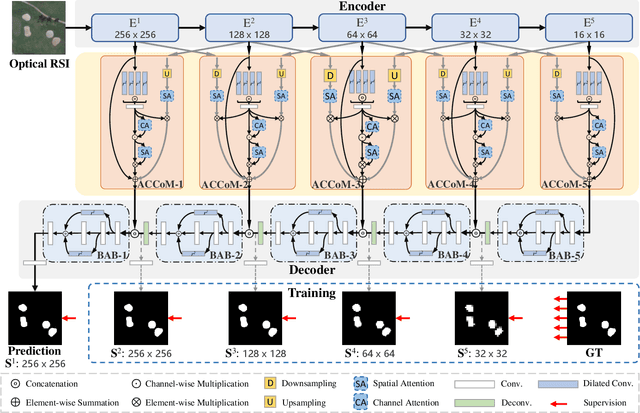

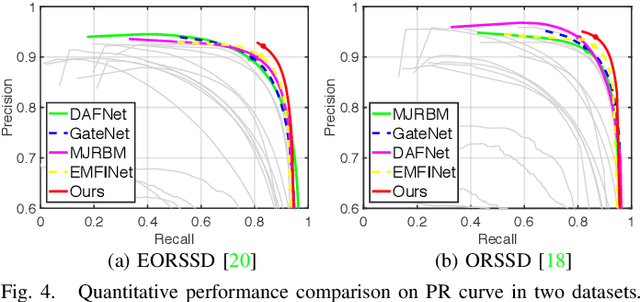
Salient object detection (SOD) in optical remote sensing images (RSIs), or RSI-SOD, is an emerging topic in understanding optical RSIs. However, due to the difference between optical RSIs and natural scene images (NSIs), directly applying NSI-SOD methods to optical RSIs fails to achieve satisfactory results. In this paper, we propose a novel Adjacent Context Coordination Network (ACCoNet) to explore the coordination of adjacent features in an encoder-decoder architecture for RSI-SOD. Specifically, ACCoNet consists of three parts: an encoder, Adjacent Context Coordination Modules (ACCoMs), and a decoder. As the key component of ACCoNet, ACCoM activates the salient regions of output features of the encoder and transmits them to the decoder. ACCoM contains a local branch and two adjacent branches to coordinate the multi-level features simultaneously. The local branch highlights the salient regions in an adaptive way, while the adjacent branches introduce global information of adjacent levels to enhance salient regions. Additionally, to extend the capabilities of the classic decoder block (i.e., several cascaded convolutional layers), we extend it with two bifurcations and propose a Bifurcation-Aggregation Block to capture the contextual information in the decoder. Extensive experiments on two benchmark datasets demonstrate that the proposed ACCoNet outperforms 22 state-of-the-art methods under nine evaluation metrics, and runs up to 81 fps on a single NVIDIA Titan X GPU. The code and results of our method are available at https://github.com/MathLee/ACCoNet.
A Temporal Kernel Approach for Deep Learning with Continuous-time Information
Mar 28, 2021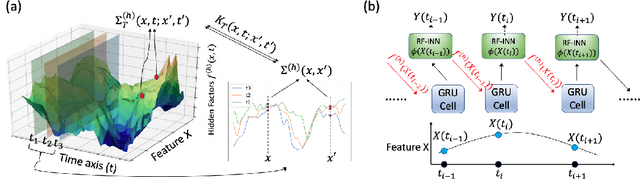
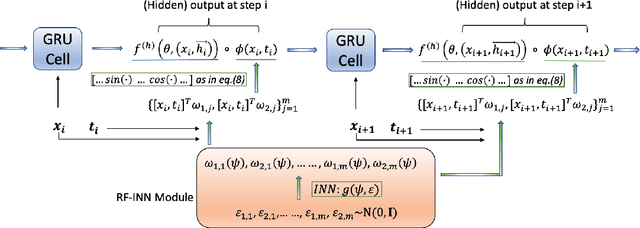
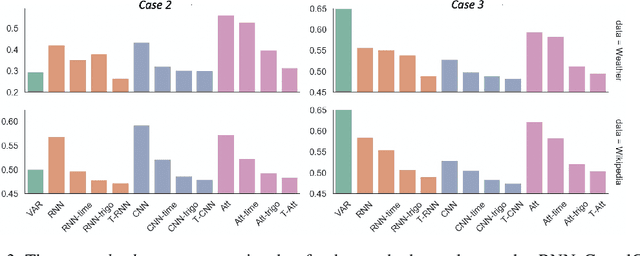
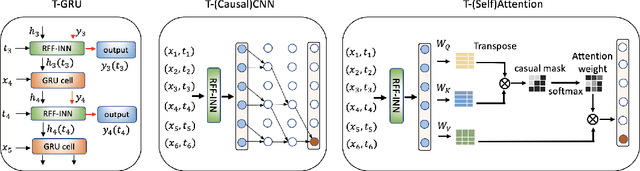
Sequential deep learning models such as RNN, causal CNN and attention mechanism do not readily consume continuous-time information. Discretizing the temporal data, as we show, causes inconsistency even for simple continuous-time processes. Current approaches often handle time in a heuristic manner to be consistent with the existing deep learning architectures and implementations. In this paper, we provide a principled way to characterize continuous-time systems using deep learning tools. Notably, the proposed approach applies to all the major deep learning architectures and requires little modifications to the implementation. The critical insight is to represent the continuous-time system by composing neural networks with a temporal kernel, where we gain our intuition from the recent advancements in understanding deep learning with Gaussian process and neural tangent kernel. To represent the temporal kernel, we introduce the random feature approach and convert the kernel learning problem to spectral density estimation under reparameterization. We further prove the convergence and consistency results even when the temporal kernel is non-stationary, and the spectral density is misspecified. The simulations and real-data experiments demonstrate the empirical effectiveness of our temporal kernel approach in a broad range of settings.
DiRA: Discriminative, Restorative, and Adversarial Learning for Self-supervised Medical Image Analysis
Apr 21, 2022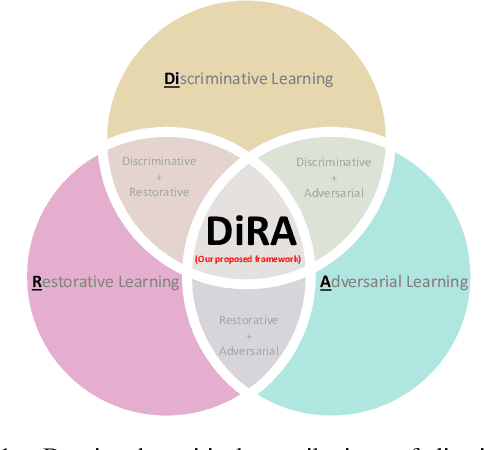

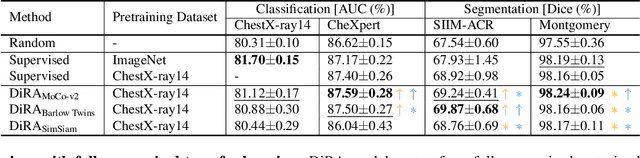
Discriminative learning, restorative learning, and adversarial learning have proven beneficial for self-supervised learning schemes in computer vision and medical imaging. Existing efforts, however, omit their synergistic effects on each other in a ternary setup, which, we envision, can significantly benefit deep semantic representation learning. To realize this vision, we have developed DiRA, the first framework that unites discriminative, restorative, and adversarial learning in a unified manner to collaboratively glean complementary visual information from unlabeled medical images for fine-grained semantic representation learning. Our extensive experiments demonstrate that DiRA (1) encourages collaborative learning among three learning ingredients, resulting in more generalizable representation across organs, diseases, and modalities; (2) outperforms fully supervised ImageNet models and increases robustness in small data regimes, reducing annotation cost across multiple medical imaging applications; (3) learns fine-grained semantic representation, facilitating accurate lesion localization with only image-level annotation; and (4) enhances state-of-the-art restorative approaches, revealing that DiRA is a general mechanism for united representation learning. All code and pre-trained models are available at https: //github.com/JLiangLab/DiRA.