 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pre-train a Discriminative Text Encoder for Dense Retrieval via Contrastive Span Prediction
Apr 22, 2022
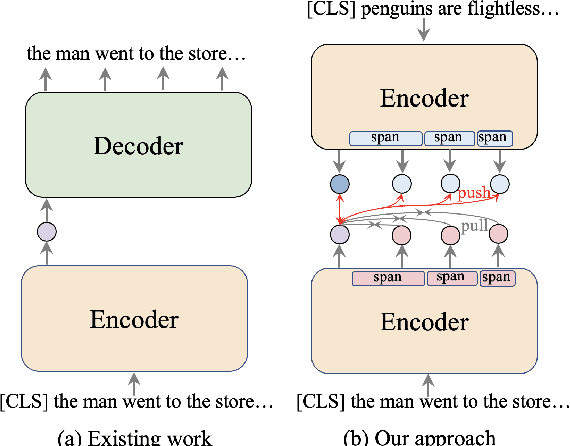
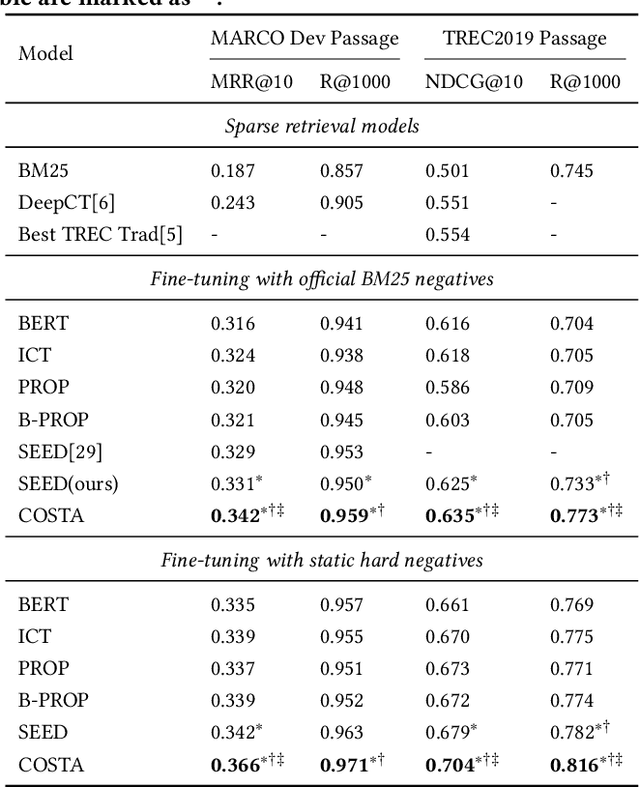
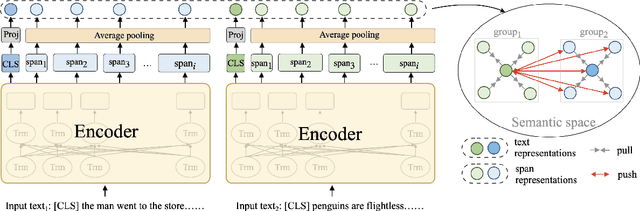
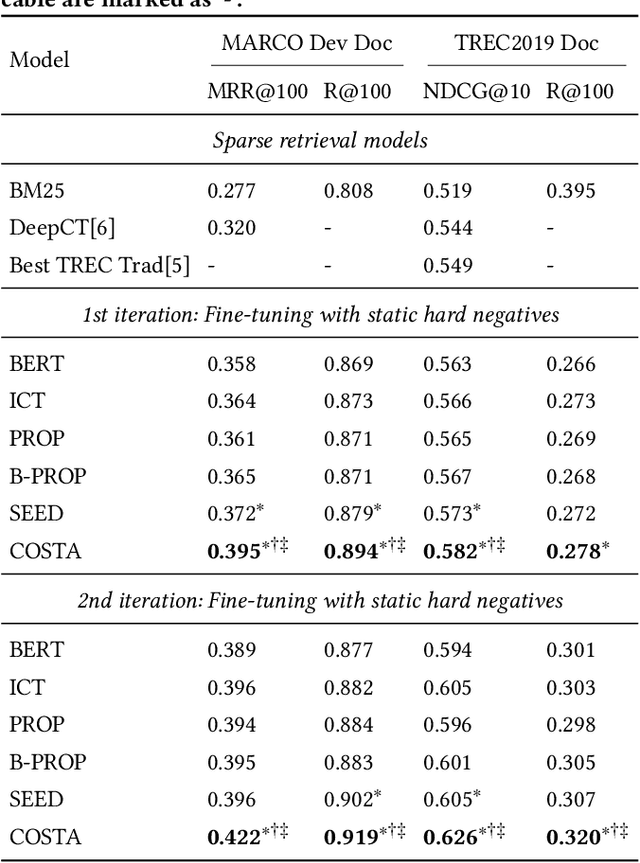
Dense retrieval has shown promising results in many information retrieval (IR) related tasks, whose foundation is high-quality text representation learning for effective search. Some recent studies have shown that autoencoder-based language models are able to boost the dense retrieval performance using a weak decoder. However, we argue that 1) it is not discriminative to decode all the input texts and, 2) even a weak decoder has the bypass effect on the encoder. Therefore, in this work, we introduce a novel contrastive span prediction task to pre-train the encoder alone, but still retain the bottleneck ability of the autoencoder. % Therefore, in this work, we propose to drop out the decoder and introduce a novel contrastive span prediction task to pre-train the encoder alone. The key idea is to force the encoder to generate the text representation close to its own random spans while far away from others using a group-wise contrastive loss. In this way, we can 1) learn discriminative text representations efficiently with the group-wise contrastive learning over spans and, 2) avoid the bypass effect of the decoder thoroughly. Comprehensive experiments over publicly available retrieval benchmark datasets show that our approach can outperform existing pre-training methods for dense retrieval significantly.
DFC: Anatomically Informed Fiber Clustering with Self-supervised Deep Learning for Fast and Effective Tractography Parcellation
May 02, 2022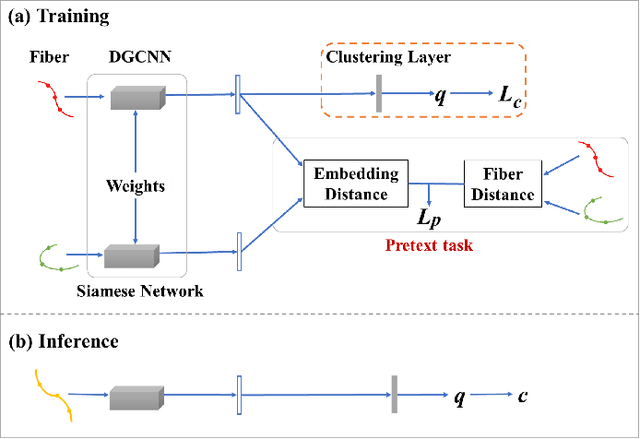
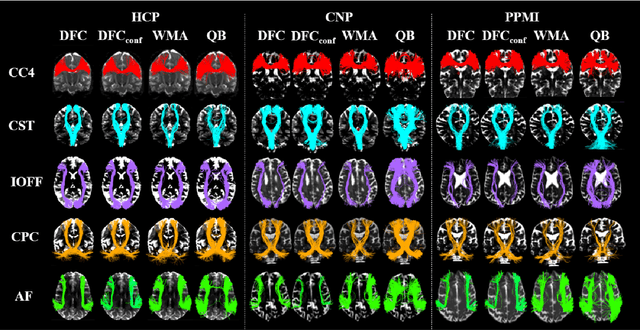
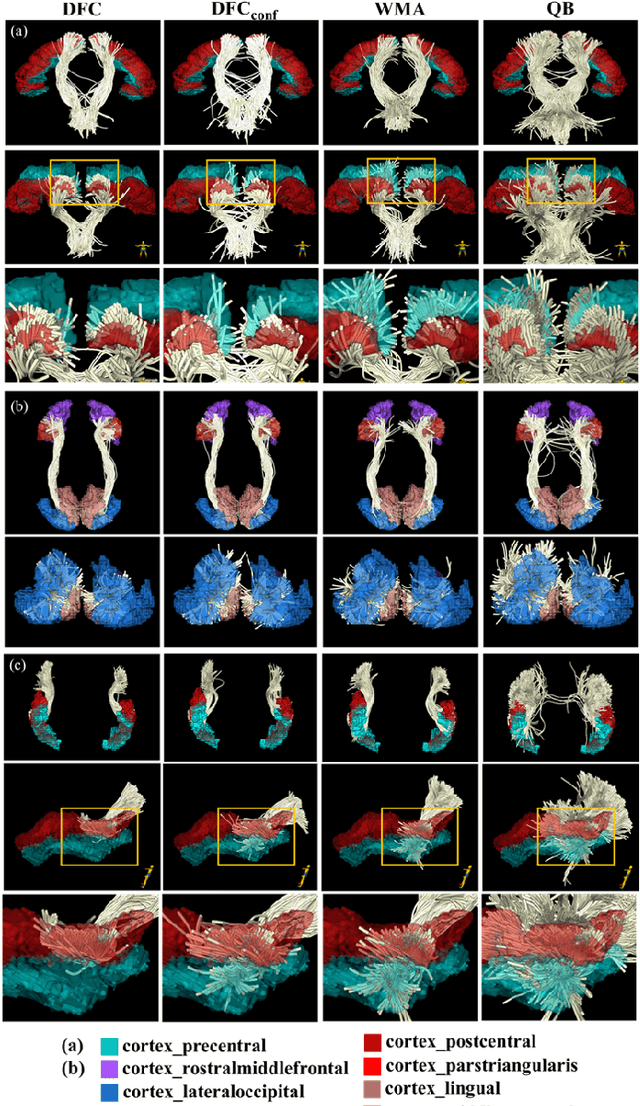
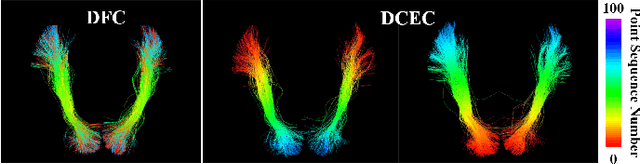
White matter fiber clustering (WMFC) parcellates tractography data into anatomically meaningful fiber bundles, usually in an unsupervised manner without the need of labeled ground truth data. While widely used WMFC approaches have shown good performance using classical machine learning techniques, recent advances in deep learning reveal a promising direction towards fast and effective WMFC. In this work, we propose a novel deep learning framework for WMFC, Deep Fiber Clustering (DFC), which solves the unsupervised clustering problem as a self-supervised learning task with a domain-specific pretext task to predict pairwise fiber distances. This accelerates the fiber representation learning to handle a known challenge in WMFC, i.e., the sensitivity of clustering results to the point ordering along fibers. We design a novel network architecture that represents input fibers as point clouds and allows the incorporation of additional sources of input information from gray matter parcellation. Thus DFC makes use of the combined white matter fiber geometry and gray matter anatomical parcellation to improve anatomical coherence of fiber clusters. In addition, DFC conducts outlier removal in a natural way by rejecting fibers with low cluster assignment probabilities. We evaluate DFC on three independently acquired cohorts (including data from 220 subjects) and compare it to several state-of-the-art WMFC algorithms. Experimental results demonstrate superior performance of DFC in terms of cluster compactness, generalization ability, anatomical coherence, and computational efficiency. In addition, DFC parcellates whole brain tractography with 50k fibers in about 1.5 minutes, providing a fast and efficient tool for large data analysis.
Situational Perception Guided Image Matting
Apr 22, 2022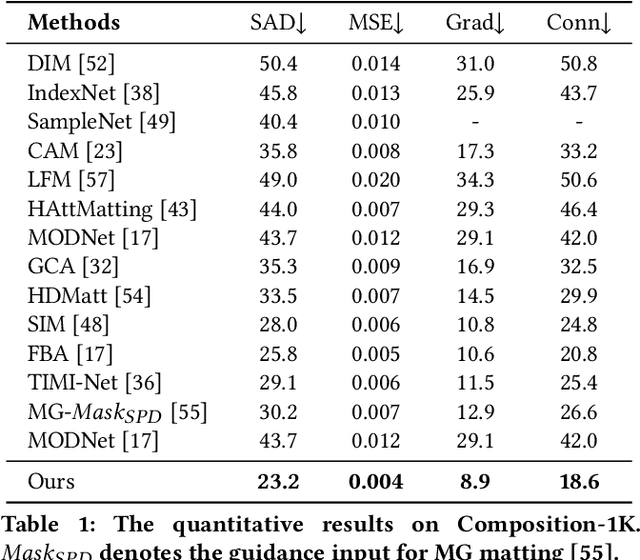
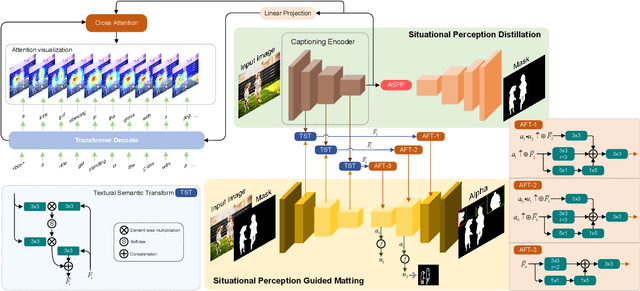
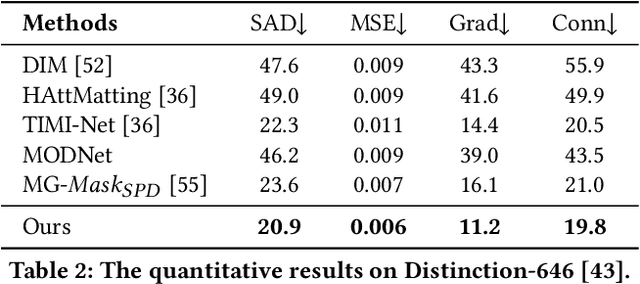
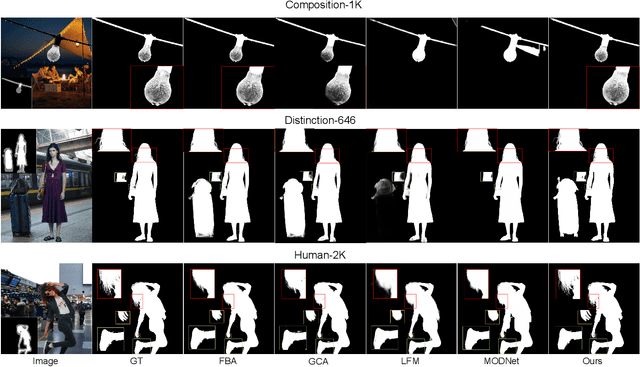
Most automatic matting methods try to separate the salient foreground from the background. However, the insufficient quantity and subjective bias of the current existing matting datasets make it difficult to fully explore the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a Situational Perception Guided Image Matting (SPG-IM) method that mitigates subjective bias of matting annotations and captures sufficient situational perception information for better global saliency distilled from the visual-to-textual task. SPG-IM can better associate inter-objects and object-to-environment saliency, and compensate the subjective nature of image matting and its expensive annotation. We also introduce a textual Semantic Transformation (TST) module that can effectively transform and integrate the semantic feature stream to guide the visual representations. In addition, an Adaptive Focal Transformation (AFT) Refinement Network is proposed to adaptively switch multi-scale receptive fields and focal points to enhance both global and local details. Extensive experiments demonstrate the effectiveness of situational perception guidance from the visual-to-textual tasks on image matting, and our model outperforms the state-of-the-art methods. We also analyze the significance of different components in our model. The code will be released soon.
Spherical Convolution empowered FoV Prediction in 360-degree Video Multicast with Limited FoV Feedback
Jan 29, 2022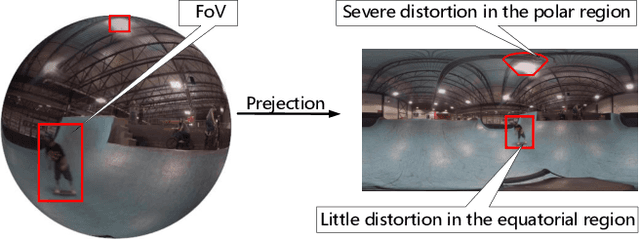

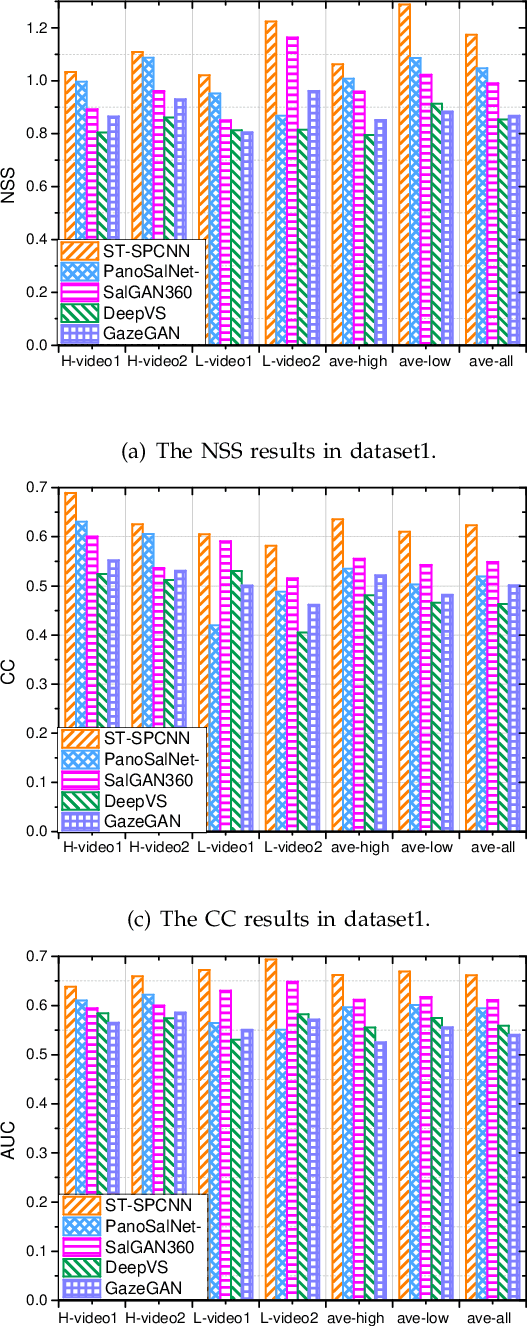
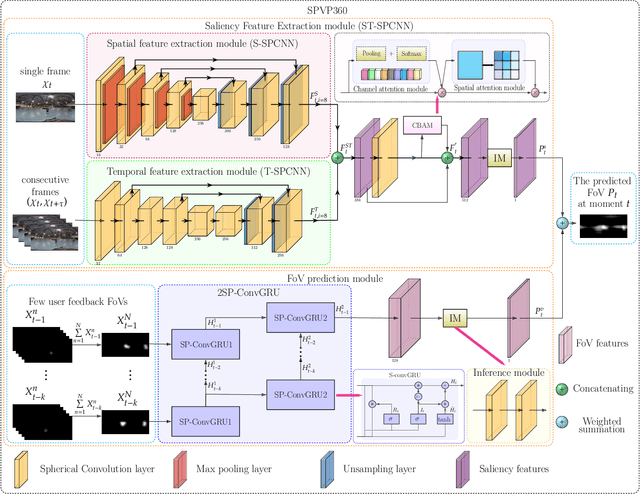
Field of view (FoV) prediction is critical in 360-degree video multicast, which is a key component of the emerging Virtual Reality (VR) and Augmented Reality (AR) applications. Most of the current prediction methods combining saliency detection and FoV information neither take into account that the distortion of projected 360-degree videos can invalidate the weight sharing of traditional convolutional networks, nor do they adequately consider the difficulty of obtaining complete multi-user FoV information, which degrades the prediction performance. This paper proposes a spherical convolution-empowered FoV prediction method, which is a multi-source prediction framework combining salient features extracted from 360-degree video with limited FoV feedback information. A spherical convolution neural network (CNN) is used instead of a traditional two-dimensional CNN to eliminate the problem of weight sharing failure caused by video projection distortion. Specifically, salient spatial-temporal features are extracted through a spherical convolution-based saliency detection model, after which the limited feedback FoV information is represented as a time-series model based on a spherical convolution-empowered gated recurrent unit network. Finally, the extracted salient video features are combined to predict future user FoVs. The experimental results show that the performance of the proposed method is better than other prediction methods.
Mixture Components Inference for Sparse Regression: Introduction and Application for Estimation of Neuronal Signal from fMRI BOLD
Mar 14, 2022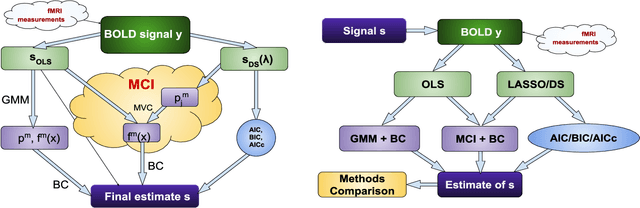
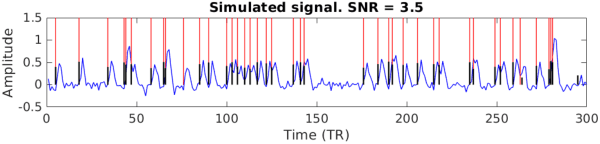
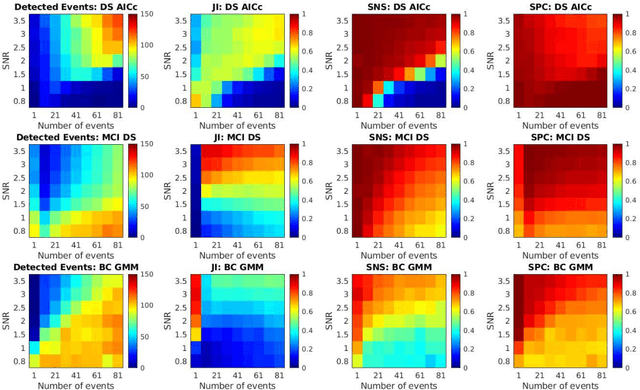
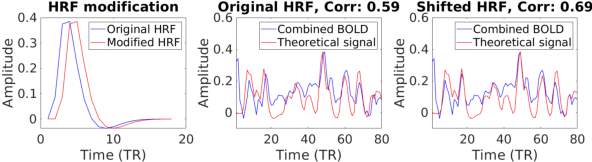
Sparse linear regression methods including the well-known LASSO and the Dantzig selector have become ubiquitous in the engineering practice, including in medical imaging. Among other tasks, they have been successfully applied for the estimation of neuronal activity from functional magnetic resonance data without prior knowledge of the stimulus or activation timing, utilizing an approximate knowledge of the hemodynamic response to local neuronal activity. These methods work by generating a parametric family of solutions with different sparsity, among which an ultimate choice is made using an information criteria. We propose a novel approach, that instead of selecting a single option from the family of regularized solutions, utilizes the whole family of such sparse regression solutions. Namely, their ensemble provides a first approximation of probability of activation at each time-point, and together with the conditional neuronal activity distributions estimated with the theory of mixtures with varying concentrations, they serve as the inputs to a Bayes classifier eventually deciding on the verity of activation at each time-point. We show in extensive numerical simulations that this new method performs favourably in comparison with standard approaches in a range of realistic scenarios. This is mainly due to the avoidance of overfitting and underfitting that commonly plague the solutions based on sparse regression combined with model selection methods, including the corrected Akaike Information Criterion. This advantage is finally documented in selected fMRI task datasets.
Zero Day Threat Detection Using Graph and Flow Based Security Telemetry
May 04, 2022
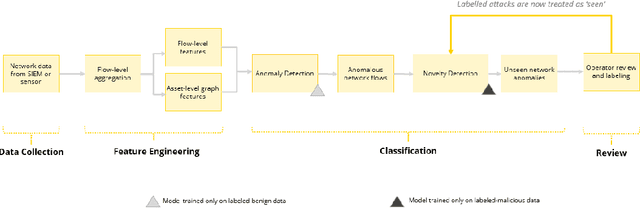
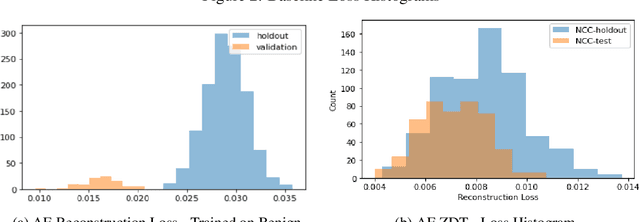

Zero Day Threats (ZDT) are novel methods used by malicious actors to attack and exploit information technology (IT) networks or infrastructure. In the past few years, the number of these threats has been increasing at an alarming rate and have been costing organizations millions of dollars to remediate. The increasing expansion of network attack surfaces and the exponentially growing number of assets on these networks necessitate the need for a robust AI-based Zero Day Threat detection model that can quickly analyze petabyte-scale data for potentially malicious and novel activity. In this paper, the authors introduce a deep learning based approach to Zero Day Threat detection that can generalize, scale, and effectively identify threats in near real-time. The methodology utilizes network flow telemetry augmented with asset-level graph features, which are passed through a dual-autoencoder structure for anomaly and novelty detection respectively. The models have been trained and tested on four large scale datasets that are representative of real-world organizational networks and they produce strong results with high precision and recall values. The models provide a novel methodology to detect complex threats with low false-positive rates that allow security operators to avoid alert fatigue while drastically reducing their mean time to response with near-real-time detection. Furthermore, the authors also provide a novel, labelled, cyber attack dataset generated from adversarial activity that can be used for validation or training of other models. With this paper, the authors' overarching goal is to provide a novel architecture and training methodology for cyber anomaly detectors that can generalize to multiple IT networks with minimal to no retraining while still maintaining strong performance.
Learning in Sparse Rewards settings through Quality-Diversity algorithms
Mar 02, 2022
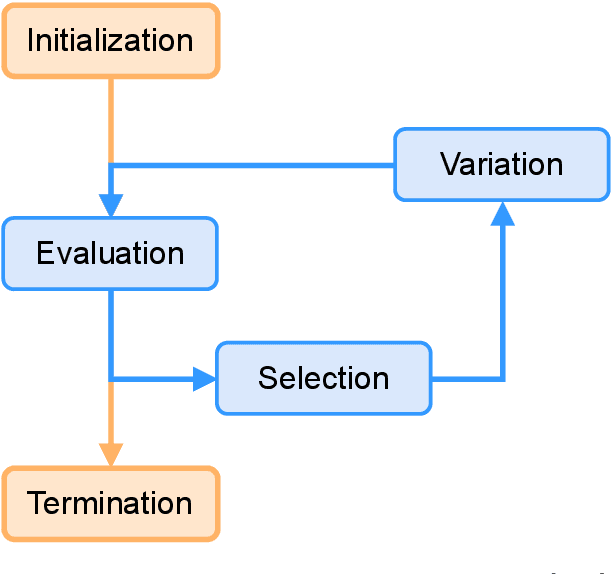
In the Reinforcement Learning (RL) framework, the learning is guided through a reward signal. This means that in situations of sparse rewards the agent has to focus on exploration, in order to discover which action, or set of actions leads to the reward. RL agents usually struggle with this. Exploration is the focus of Quality-Diversity (QD) methods. In this thesis, we approach the problem of sparse rewards with these algorithms, and in particular with Novelty Search (NS). This is a method that only focuses on the diversity of the possible policies behaviors. The first part of the thesis focuses on learning a representation of the space in which the diversity of the policies is evaluated. In this regard, we propose the TAXONS algorithm, a method that learns a low-dimensional representation of the search space through an AutoEncoder. While effective, TAXONS still requires information on when to capture the observation used to learn said space. For this, we study multiple ways, and in particular the signature transform, to encode information about the whole trajectory of observations. The thesis continues with the introduction of the SERENE algorithm, a method that can efficiently focus on the interesting parts of the search space. This method separates the exploration of the search space from the exploitation of the reward through a two-alternating-steps approach. The exploration is performed through NS. Any discovered reward is then locally exploited through emitters. The third and final contribution combines TAXONS and SERENE into a single approach: STAX. Throughout this thesis, we introduce methods that lower the amount of prior information needed in sparse rewards settings. These contributions are a promising step towards the development of methods that can autonomously explore and find high-performance policies in a variety of sparse rewards settings.
Extracting Targeted Training Data from ASR Models, and How to Mitigate It
Apr 18, 2022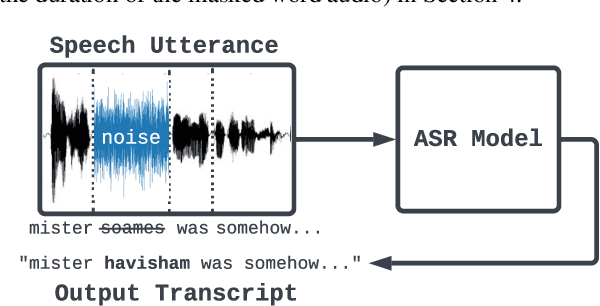
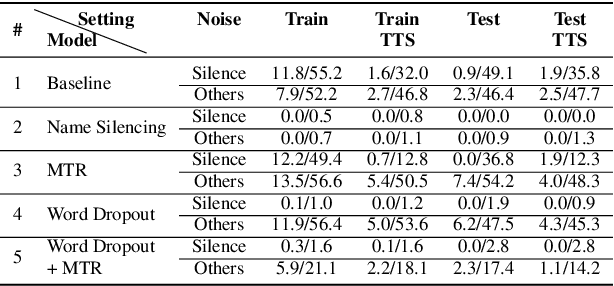
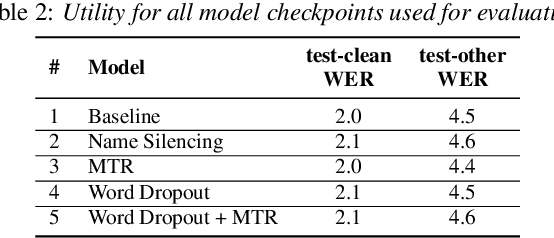
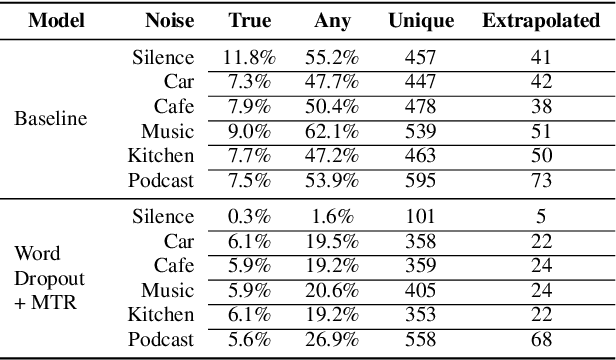
Recent work has designed methods to demonstrate that model updates in ASR training can leak potentially sensitive attributes of the utterances used in computing the updates. In this work, we design the first method to demonstrate information leakage about training data from trained ASR models. We design Noise Masking, a fill-in-the-blank style method for extracting targeted parts of training data from trained ASR models. We demonstrate the success of Noise Masking by using it in four settings for extracting names from the LibriSpeech dataset used for training a SOTA Conformer model. In particular, we show that we are able to extract the correct names from masked training utterances with 11.8% accuracy, while the model outputs some name from the train set 55.2% of the time. Further, we show that even in a setting that uses synthetic audio and partial transcripts from the test set, our method achieves 2.5% correct name accuracy (47.7% any name success rate). Lastly, we design Word Dropout, a data augmentation method that we show when used in training along with MTR, provides comparable utility as the baseline, along with significantly mitigating extraction via Noise Masking across the four evaluated settings.
Concentration of Random Feature Matrices in High-Dimensions
Apr 14, 2022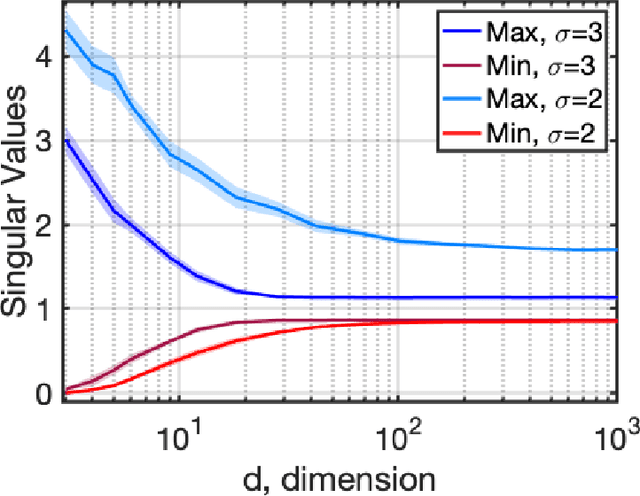
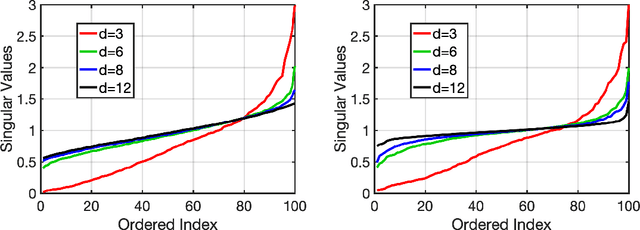
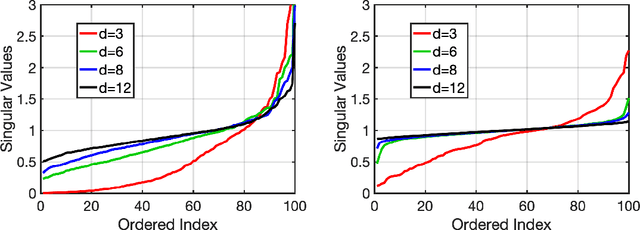
The spectra of random feature matrices provide essential information on the conditioning of the linear system used in random feature regression problems and are thus connected to the consistency and generalization of random feature models. Random feature matrices are asymmetric rectangular nonlinear matrices depending on two input variables, the data and the weights, which can make their characterization challenging. We consider two settings for the two input variables, either both are random variables or one is a random variable and the other is well-separated, i.e. there is a minimum distance between points. With conditions on the dimension, the complexity ratio, and the sampling variance, we show that the singular values of these matrices concentrate near their full expectation and near one with high-probability. In particular, since the dimension depends only on the logarithm of the number of random weights or the number of data points, our complexity bounds can be achieved even in moderate dimensions for many practical setting. The theoretical results are verified with numerical experiments.
SoccerNet-Tracking: Multiple Object Tracking Dataset and Benchmark in Soccer Videos
Apr 14, 2022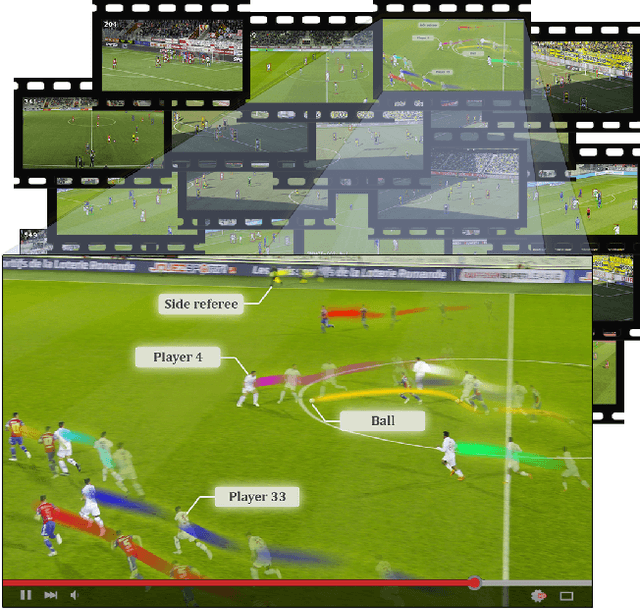
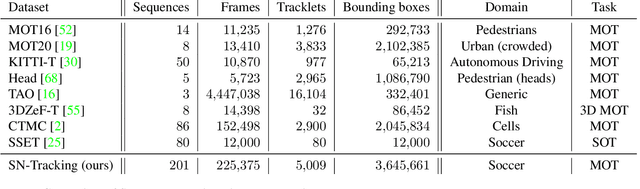
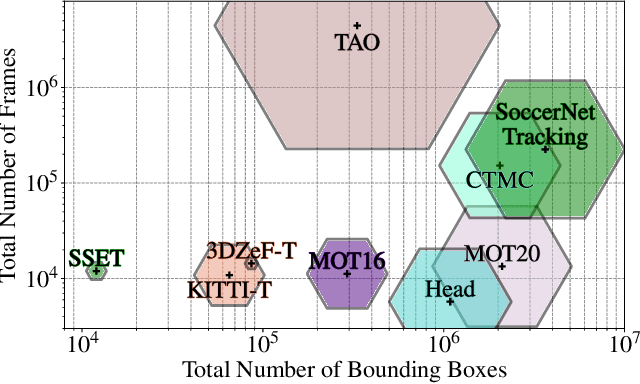
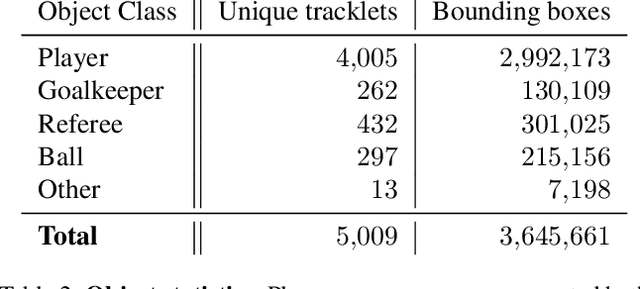
Tracking objects in soccer videos is extremely important to gather both player and team statistics, whether it is to estimate the total distance run, the ball possession or the team formation. Video processing can help automating the extraction of those information, without the need of any invasive sensor, hence applicable to any team on any stadium. Yet, the availability of datasets to train learnable models and benchmarks to evaluate methods on a common testbed is very limited. In this work, we propose a novel dataset for multiple object tracking composed of 200 sequences of 30s each, representative of challenging soccer scenarios, and a complete 45-minutes half-time for long-term tracking. The dataset is fully annotated with bounding boxes and tracklet IDs, enabling the training of MOT baselines in the soccer domain and a full benchmarking of those methods on our segregated challenge sets. Our analysis shows that multiple player, referee and ball tracking in soccer videos is far from being solved, with several improvement required in case of fast motion or in scenarios of severe occlusion.