 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Graph-based approach to derive the geodesic distance on Statistical manifolds: Application to Multimedia Information Retrieval
Jun 26, 2021


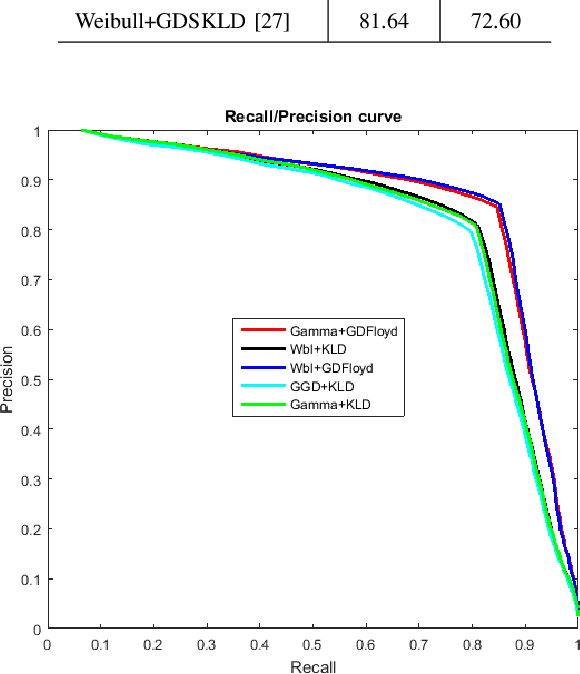
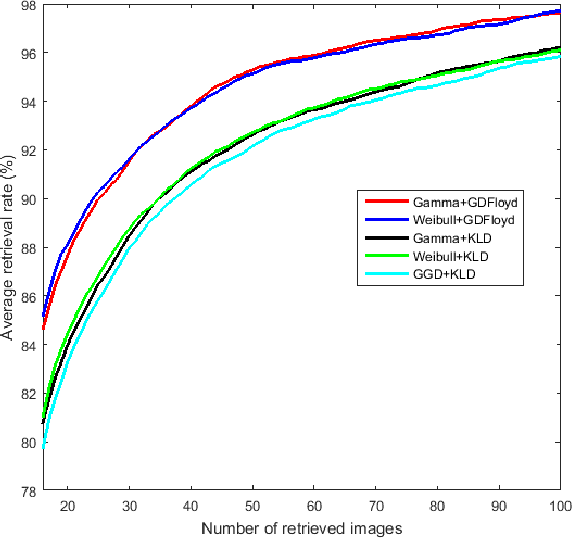
In this paper, we leverage the properties of non-Euclidean Geometry to define the Geodesic distance (GD) on the space of statistical manifolds. The Geodesic distance is a real and intuitive similarity measure that is a good alternative to the purely statistical and extensively used Kullback-Leibler divergence (KLD). Despite the effectiveness of the GD, a closed-form does not exist for many manifolds, since the geodesic equations are hard to solve. This explains that the major studies have been content to use numerical approximations. Nevertheless, most of those do not take account of the manifold properties, which leads to a loss of information and thus to low performances. We propose an approximation of the Geodesic distance through a graph-based method. This latter permits to well represent the structure of the statistical manifold, and respects its geometrical properties. Our main aim is to compare the graph-based approximation to the state of the art approximations. Thus, the proposed approach is evaluated for two statistical manifolds, namely the Weibull manifold and the Gamma manifold, considering the Content-Based Texture Retrieval application on different databases.
A Theory of Usable Information Under Computational Constraints
Feb 25, 2020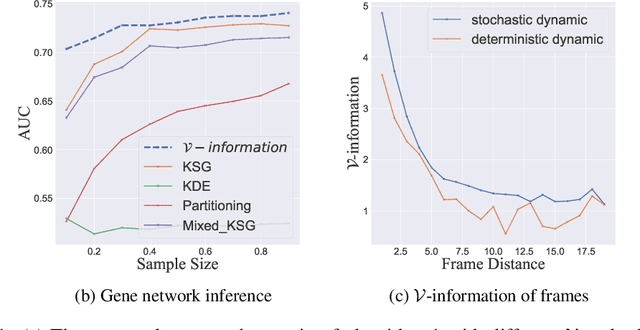
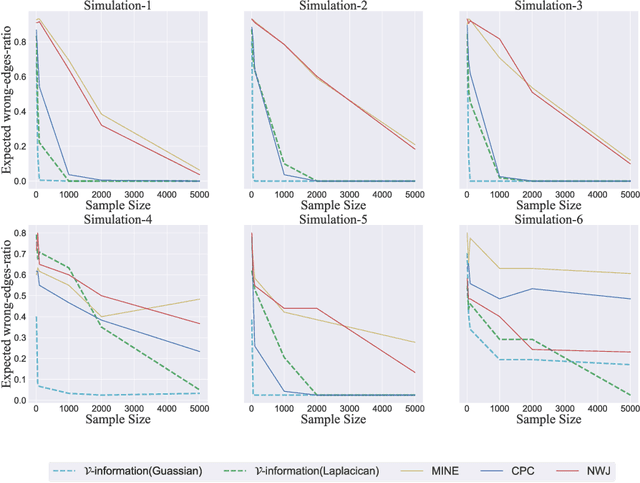

We propose a new framework for reasoning about information in complex systems. Our foundation is based on a variational extension of Shannon's information theory that takes into account the modeling power and computational constraints of the observer. The resulting \emph{predictive $\mathcal{V}$-information} encompasses mutual information and other notions of informativeness such as the coefficient of determination. Unlike Shannon's mutual information and in violation of the data processing inequality, $\mathcal{V}$-information can be created through computation. This is consistent with deep neural networks extracting hierarchies of progressively more informative features in representation learning. Additionally, we show that by incorporating computational constraints, $\mathcal{V}$-information can be reliably estimated from data even in high dimensions with PAC-style guarantees. Empirically, we demonstrate predictive $\mathcal{V}$-information is more effective than mutual information for structure learning and fair representation learning.
Epistemic AI platform accelerates innovation by connecting biomedical knowledge
Jan 30, 2022

Epistemic AI accelerates biomedical discovery by finding hidden connections in the network of biomedical knowledge. The Epistemic AI web-based software platform embodies the concept of knowledge mapping, an interactive process that relies on a knowledge graph in combination with natural language processing (NLP), information retrieval, relevance feedback, and network analysis. Knowledge mapping reduces information overload, prevents costly mistakes, and minimizes missed opportunities in the research process. The platform combines state-of-the-art methods for information extraction with machine learning, artificial intelligence and network analysis. Starting from a single biological entity, such as a gene or disease, users may: a) construct a map of connections to that entity, b) map an entire domain of interest, and c) gain insight into large biological networks of knowledge. Knowledge maps provide clarity and organization, simplifying the day-to-day research processes.
Hierarchical and Multi-Scale Variational Autoencoder for Diverse and Natural Non-Autoregressive Text-to-Speech
Apr 08, 2022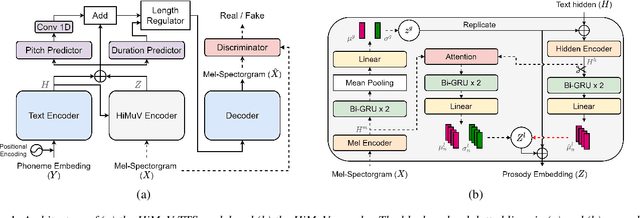
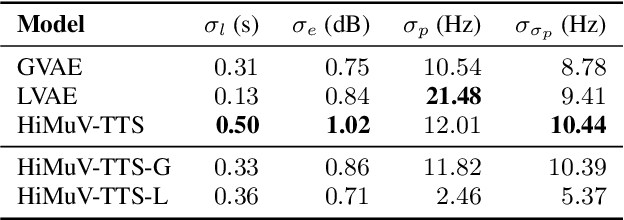
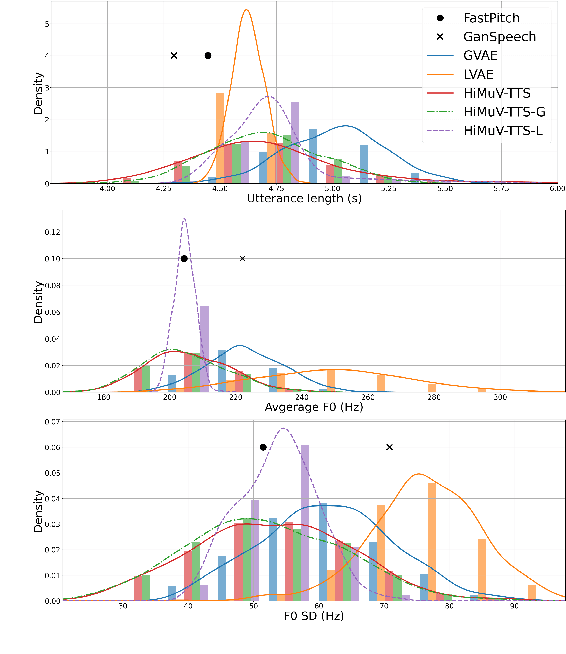
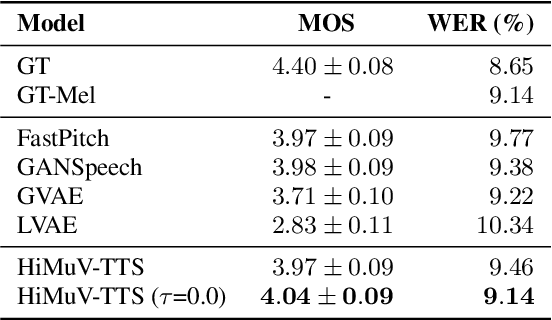
This paper proposes a hierarchical and multi-scale variational autoencoder-based non-autoregressive text-to-speech model (HiMuV-TTS) to generate natural speech with diverse speaking styles. Recent advances in non-autoregressive TTS (NAR-TTS) models have significantly improved the inference speed and robustness of synthesized speech. However, the diversity of speaking styles and naturalness are needed to be improved. To solve this problem, we propose the HiMuV-TTS model that first determines the global-scale prosody and then determines the local-scale prosody via conditioning on the global-scale prosody and the learned text representation. In addition, we improve the quality of speech by adopting the adversarial training technique. Experimental results verify that the proposed HiMuV-TTS model can generate more diverse and natural speech as compared to TTS models with single-scale variational autoencoders, and can represent different prosody information in each scale.
Learning Cooperative Dynamic Manipulation Skills from Human Demonstration Videos
Apr 08, 2022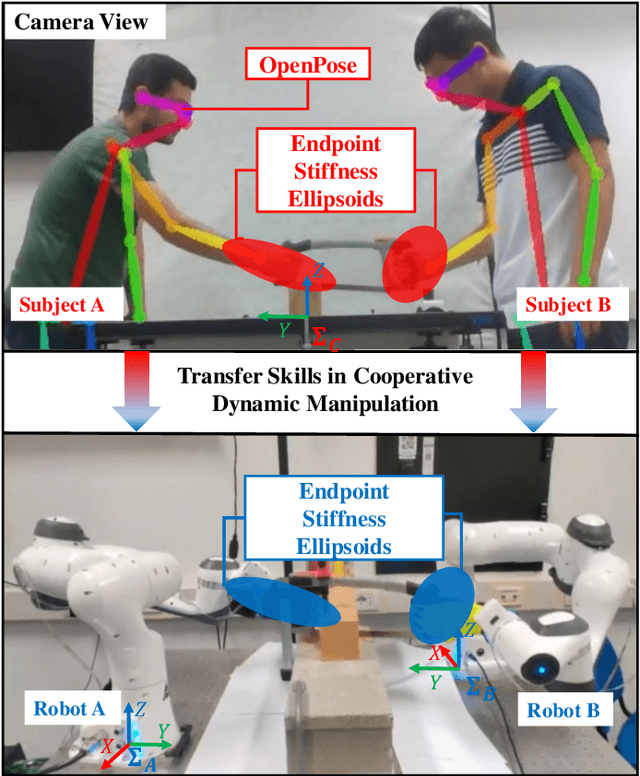
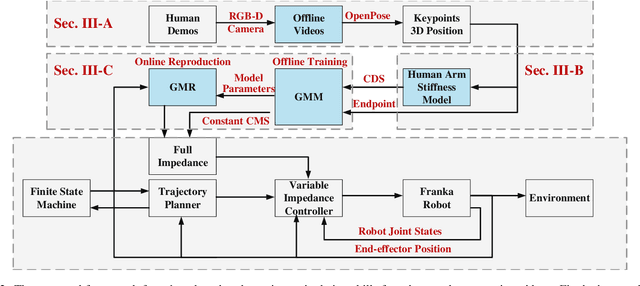
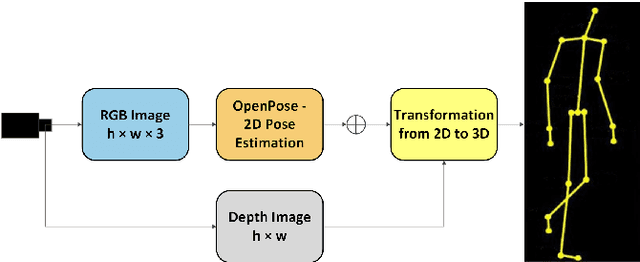
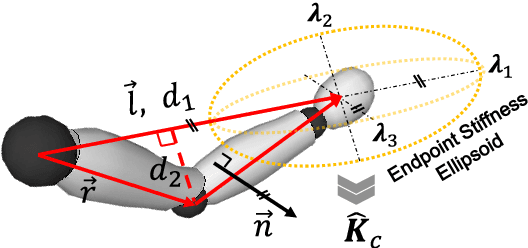
This article proposes a method for learning and robotic replication of dynamic collaborative tasks from offline videos. The objective is to extend the concept of learning from demonstration (LfD) to dynamic scenarios, benefiting from widely available or easily producible offline videos. To achieve this goal, we decode important dynamic information, such as the Configuration Dependent Stiffness (CDS), which reveals the contribution of arm pose to the arm endpoint stiffness, from a three-dimensional human skeleton model. Next, through encoding of the CDS via Gaussian Mixture Model (GMM) and decoding via Gaussian Mixture Regression (GMR), the robot's Cartesian impedance profile is estimated and replicated. We demonstrate the proposed method in a collaborative sawing task with leader-follower structure, considering environmental constraints and dynamic uncertainties. The experimental setup includes two Panda robots, which replicate the leader-follower roles and the impedance profiles extracted from a two-persons sawing video.
ISETAuto: Detecting vehicles with depth and radiance information
Jan 06, 2021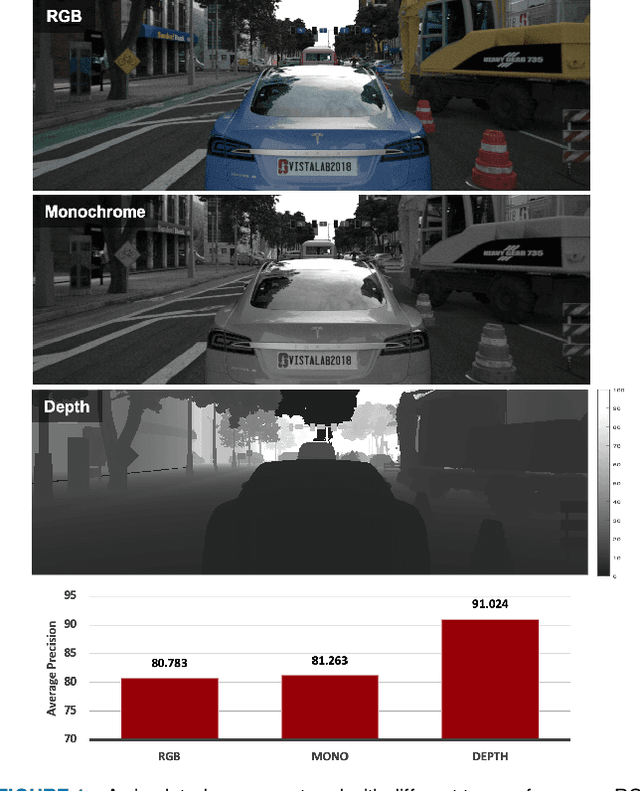

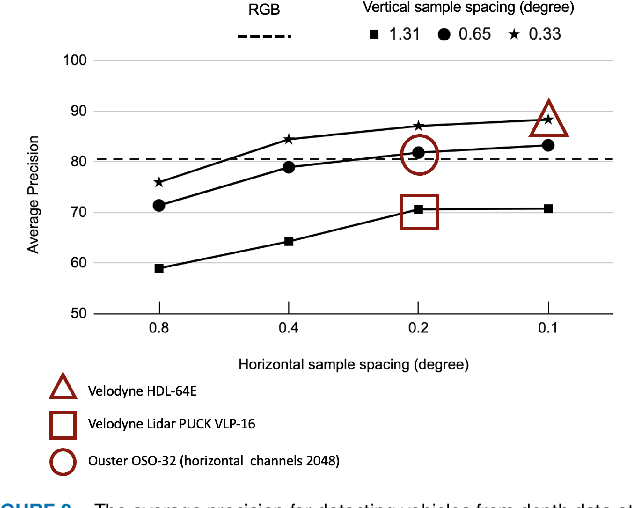
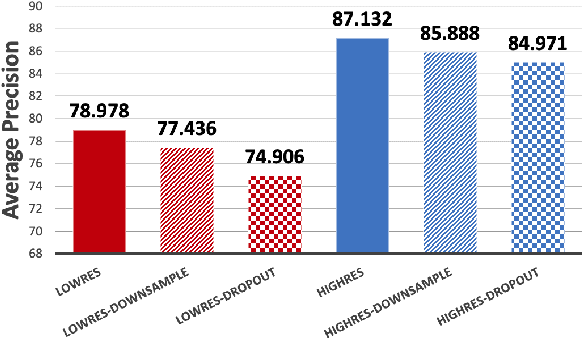
Autonomous driving applications use two types of sensor systems to identify vehicles - depth sensing LiDAR and radiance sensing cameras. We compare the performance (average precision) of a ResNet for vehicle detection in complex, daytime, driving scenes when the input is a depth map (D = d(x,y)), a radiance image (L = r(x,y)), or both [D,L]. (1) When the spatial sampling resolution of the depth map and radiance image are equal to typical camera resolutions, a ResNet detects vehicles at higher average precision from depth than radiance. (2) As the spatial sampling of the depth map declines to the range of current LiDAR devices, the ResNet average precision is higher for radiance than depth. (3) For a hybrid system that combines a depth map and radiance image, the average precision is higher than using depth or radiance alone. We established these observations in simulation and then confirmed them using realworld data. The advantage of combining depth and radiance can be explained by noting that the two type of information have complementary weaknesses. The radiance data are limited by dynamic range and motion blur. The LiDAR data have relatively low spatial resolution. The ResNet combines the two data sources effectively to improve overall vehicle detection.
Supervised Contrastive Learning with Structure Inference for Graph Classification
Mar 15, 2022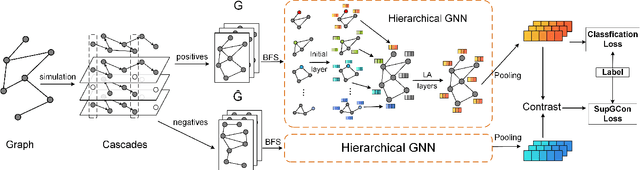
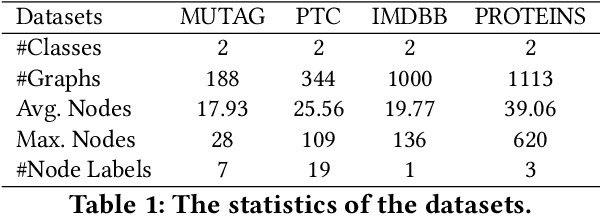
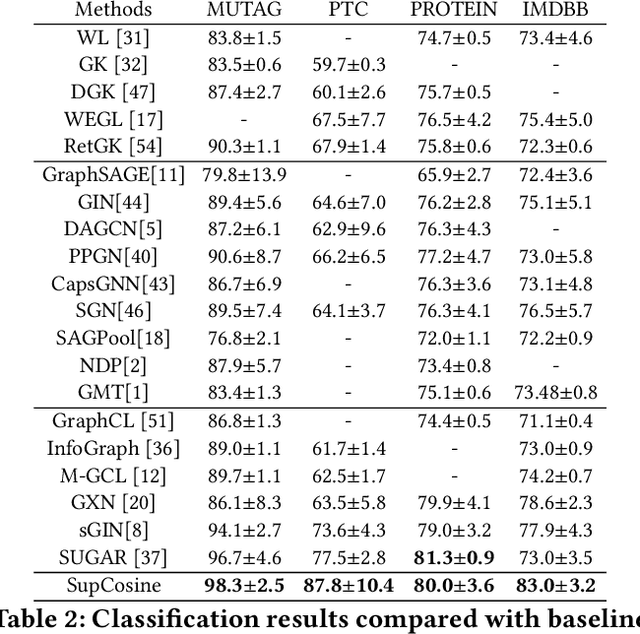
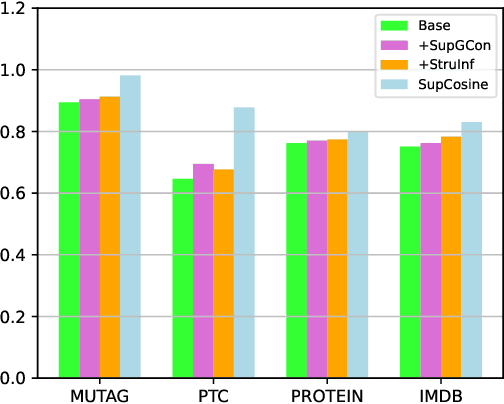
Advanced graph neural networks have shown great potentials in graph classification tasks recently. Different from node classification where node embeddings aggregated from local neighbors can be directly used to learn node labels, graph classification requires a hierarchical accumulation of different levels of topological information to generate discriminative graph embeddings. Still, how to fully explore graph structures and formulate an effective graph classification pipeline remains rudimentary. In this paper, we propose a novel graph neural network based on supervised contrastive learning with structure inference for graph classification. First, we propose a data-driven graph augmentation strategy that can discover additional connections to enhance the existing edge set. Concretely, we resort to a structure inference stage based on diffusion cascades to recover possible connections with high node similarities. Second, to improve the contrastive power of graph neural networks, we propose to use a supervised contrastive loss for graph classification. With the integration of label information, the one-vs-many contrastive learning can be extended to a many-vs-many setting, so that the graph-level embeddings with higher topological similarities will be pulled closer. The supervised contrastive loss and structure inference can be naturally incorporated within the hierarchical graph neural networks where the topological patterns can be fully explored to produce discriminative graph embeddings. Experiment results show the effectiveness of the proposed method compared with recent state-of-the-art methods.
Quality Metric Guided Portrait Line Drawing Generation from Unpaired Training Data
Feb 08, 2022
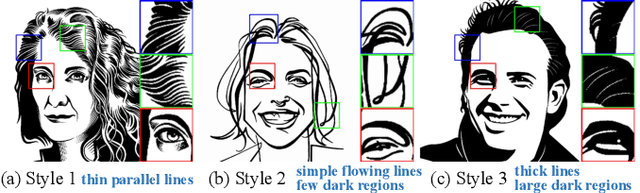
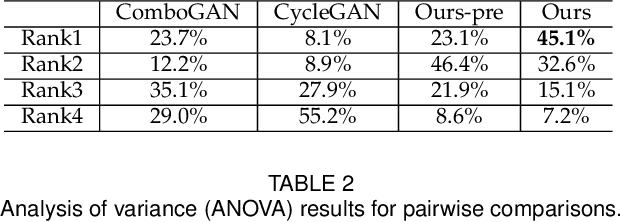

Face portrait line drawing is a unique style of art which is highly abstract and expressive. However, due to its high semantic constraints, many existing methods learn to generate portrait drawings using paired training data, which is costly and time-consuming to obtain. In this paper, we propose a novel method to automatically transform face photos to portrait drawings using unpaired training data with two new features; i.e., our method can (1) learn to generate high quality portrait drawings in multiple styles using a single network and (2) generate portrait drawings in a "new style" unseen in the training data. To achieve these benefits, we (1) propose a novel quality metric for portrait drawings which is learned from human perception, and (2) introduce a quality loss to guide the network toward generating better looking portrait drawings. We observe that existing unpaired translation methods such as CycleGAN tend to embed invisible reconstruction information indiscriminately in the whole drawings due to significant information imbalance between the photo and portrait drawing domains, which leads to important facial features missing. To address this problem, we propose a novel asymmetric cycle mapping that enforces the reconstruction information to be visible and only embedded in the selected facial regions. Along with localized discriminators for important facial regions, our method well preserves all important facial features in the generated drawings. Generator dissection further explains that our model learns to incorporate face semantic information during drawing generation. Extensive experiments including a user study show that our model outperforms state-of-the-art methods.
A Sharp Memory-Regret Trade-Off for Multi-Pass Streaming Bandits
May 02, 2022The stochastic $K$-armed bandit problem has been studied extensively due to its applications in various domains ranging from online advertising to clinical trials. In practice however, the number of arms can be very large resulting in large memory requirements for simultaneously processing them. In this paper we consider a streaming setting where the arms are presented in a stream and the algorithm uses limited memory to process these arms. Here, the goal is not only to minimize regret, but also to do so in minimal memory. Previous algorithms for this problem operate in one of the two settings: they either use $\Omega(\log \log T)$ passes over the stream (Rathod, 2021; Chaudhuri and Kalyanakrishnan, 2020; Liau et al., 2018), or just a single pass (Maiti et al., 2021). In this paper we study the trade-off between memory and regret when $B$ passes over the stream are allowed, for any $B \geq 1$, and establish tight regret upper and lower bounds for any $B$-pass algorithm. Our results uncover a surprising *sharp transition phenomenon*: $O(1)$ memory is sufficient to achieve $\widetilde\Theta\Big(T^{\frac{1}{2} + \frac{1}{2^{B+2}-2}}\Big)$ regret in $B$ passes, and increasing the memory to any quantity that is $o(K)$ has almost no impact on further reducing this regret, unless we use $\Omega(K)$ memory. Our main technical contribution is our lower bound which requires the use of information-theoretic techniques as well as ideas from round elimination to show that the *residual problem* remains challenging over subsequent passes.
Joint Policy Search for Multi-agent Collaboration with Imperfect Information
Aug 14, 2020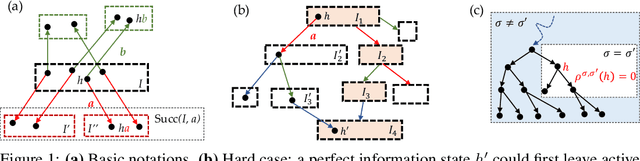

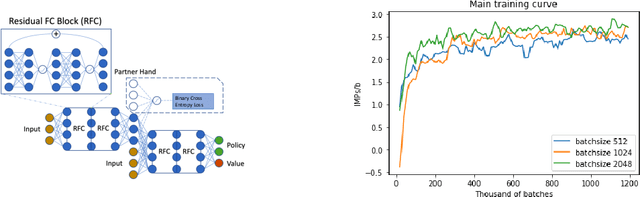

To learn good joint policies for multi-agent collaboration with imperfect information remains a fundamental challenge. While for two-player zero-sum games, coordinate-ascent approaches (optimizing one agent's policy at a time, e.g., self-play) work with guarantees, in multi-agent cooperative setting they often converge to sub-optimal Nash equilibrium. On the other hand, directly modeling joint policy changes in imperfect information game is nontrivial due to complicated interplay of policies (e.g., upstream updates affect downstream state reachability). In this paper, we show global changes of game values can be decomposed to policy changes localized at each information set, with a novel term named policy-change density. Based on this, we propose Joint Policy Search(JPS) that iteratively improves joint policies of collaborative agents in imperfect information games, without re-evaluating the entire game. On multi-agent collaborative tabular games, JPS is proven to never worsen performance and can improve solutions provided by unilateral approaches (e.g, CFR), outperforming algorithms designed for collaborative policy learning (e.g. BAD). Furthermore, for real-world games, JPS has an online form that naturally links with gradient updates. We test it to Contract Bridge, a 4-player imperfect-information game where a team of $2$ collaborates to compete against the other. In its bidding phase, players bid in turn to find a good contract through a limited information channel. Based on a strong baseline agent that bids competitive bridge purely through domain-agnostic self-play, JPS improves collaboration of team players and outperforms WBridge5, a championship-winning software, by $+0.63$ IMPs (International Matching Points) per board over 1k games, substantially better than previous SoTA ($+0.41$ IMPs/b). Note that $+0.1$ IMPs/b is regarded as a nontrivial improvement in Computer Bridge.