 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving the Faithfulness of Attention-based Explanations with Task-specific Information for Text Classification
May 07, 2021
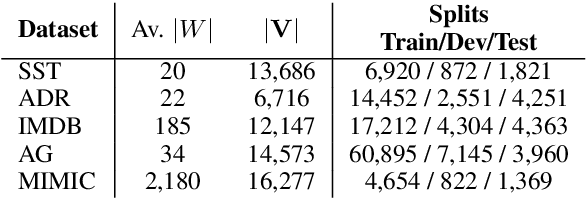
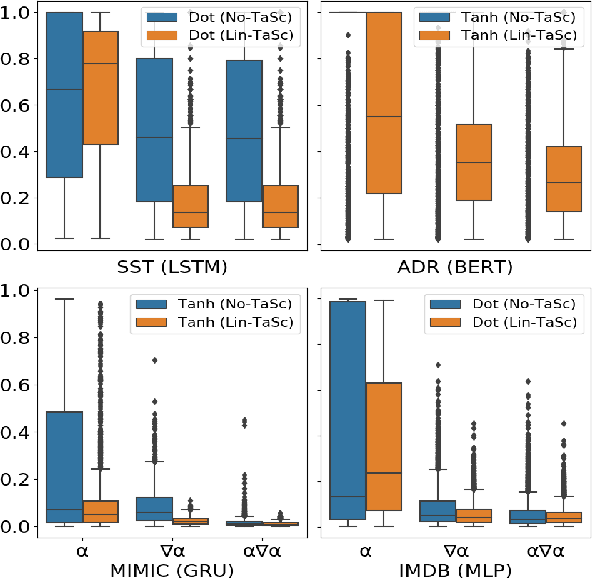
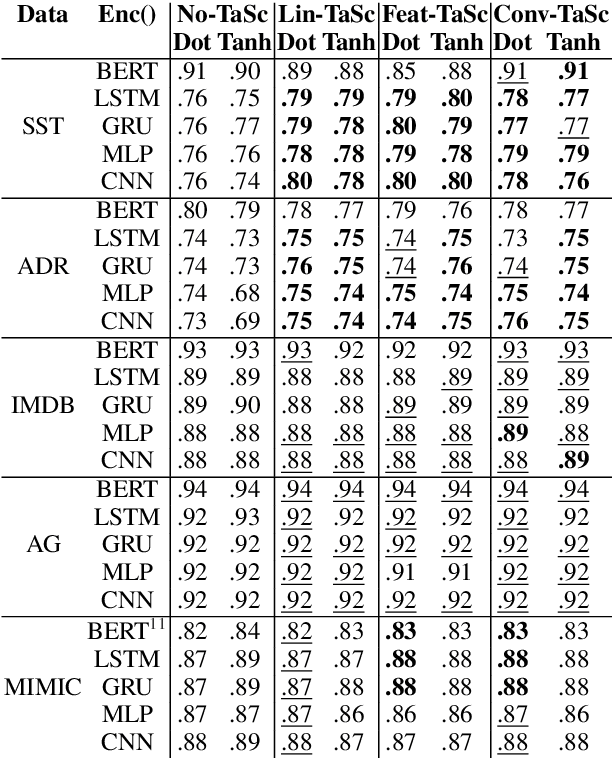
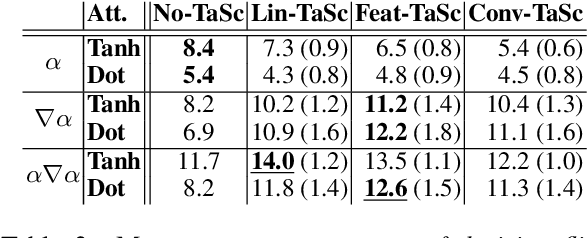
Neural network architectures in natural language processing often use attention mechanisms to produce probability distributions over input token representations. Attention has empirically been demonstrated to improve performance in various tasks, while its weights have been extensively used as explanations for model predictions. Recent studies (Jain and Wallace, 2019; Serrano and Smith, 2019; Wiegreffe and Pinter, 2019) have showed that it cannot generally be considered as a faithful explanation (Jacovi and Goldberg, 2020) across encoders and tasks. In this paper, we seek to improve the faithfulness of attention-based explanations for text classification. We achieve this by proposing a new family of Task-Scaling (TaSc) mechanisms that learn task-specific non-contextualised information to scale the original attention weights. Evaluation tests for explanation faithfulness, show that the three proposed variants of TaSc improve attention-based explanations across two attention mechanisms, five encoders and five text classification datasets without sacrificing predictive performance. Finally, we demonstrate that TaSc consistently provides more faithful attention-based explanations compared to three widely-used interpretability techniques.
A Novel Fast Exact Subproblem Solver for Stochastic Quasi-Newton Cubic Regularized Optimization
Apr 19, 2022
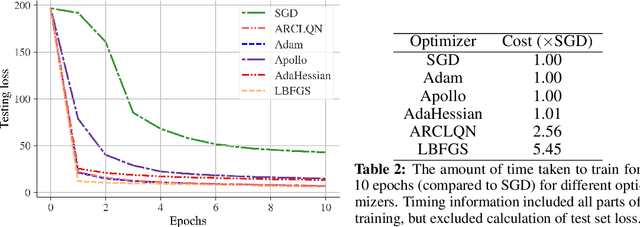

In this work we describe an Adaptive Regularization using Cubics (ARC) method for large-scale nonconvex unconstrained optimization using Limited-memory Quasi-Newton (LQN) matrices. ARC methods are a relatively new family of optimization strategies that utilize a cubic-regularization (CR) term in place of trust-regions and line-searches. LQN methods offer a large-scale alternative to using explicit second-order information by taking identical inputs to those used by popular first-order methods such as stochastic gradient descent (SGD). Solving the CR subproblem exactly requires Newton's method, yet using properties of the internal structure of LQN matrices, we are able to find exact solutions to the CR subproblem in a matrix-free manner, providing large speedups and scaling into modern size requirements. Additionally, we expand upon previous ARC work and explicitly incorporate first-order updates into our algorithm. We provide experimental results when the SR1 update is used, which show substantial speed-ups and competitive performance compared to Adam and other second order optimizers on deep neural networks (DNNs). We find that our new approach, ARCLQN, compares to modern optimizers with minimal tuning, a common pain-point for second order methods.
syslrn: Learning What to Monitor for Efficient Anomaly Detection
Mar 29, 2022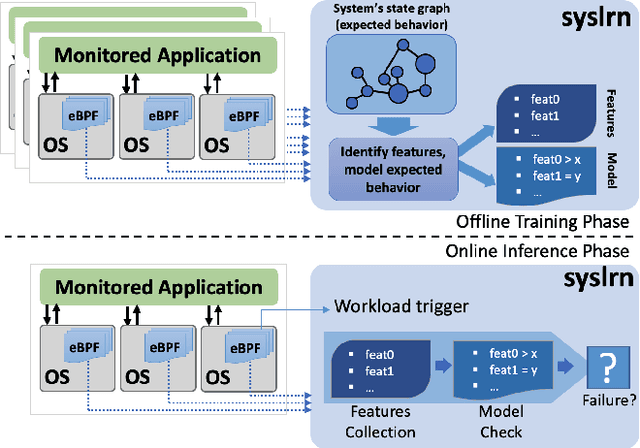
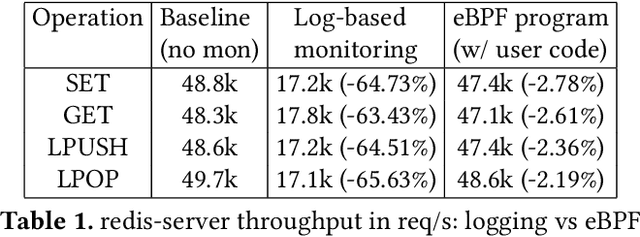
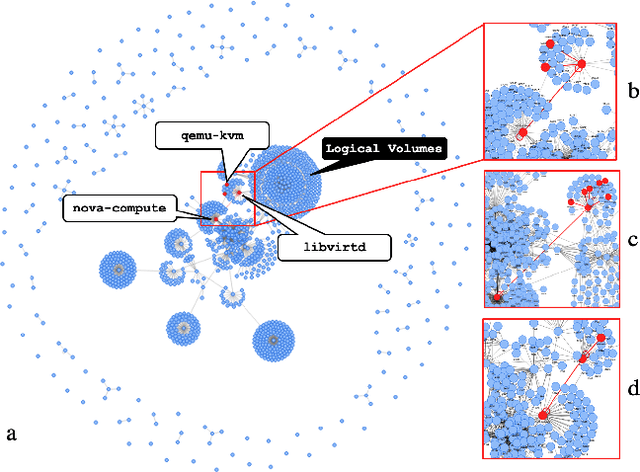
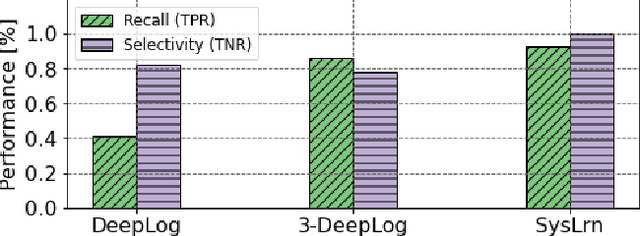
While monitoring system behavior to detect anomalies and failures is important, existing methods based on log-analysis can only be as good as the information contained in the logs, and other approaches that look at the OS-level software state introduce high overheads. We tackle the problem with syslrn, a system that first builds an understanding of a target system offline, and then tailors the online monitoring instrumentation based on the learned identifiers of normal behavior. While our syslrn prototype is still preliminary and lacks many features, we show in a case study for the monitoring of OpenStack failures that it can outperform state-of-the-art log-analysis systems with little overhead.
A Theory of Usable Information Under Computational Constraints
Feb 25, 2020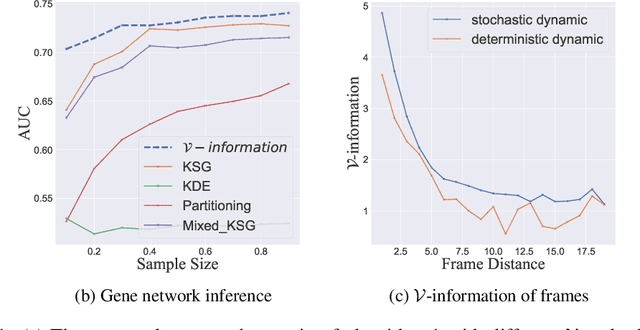
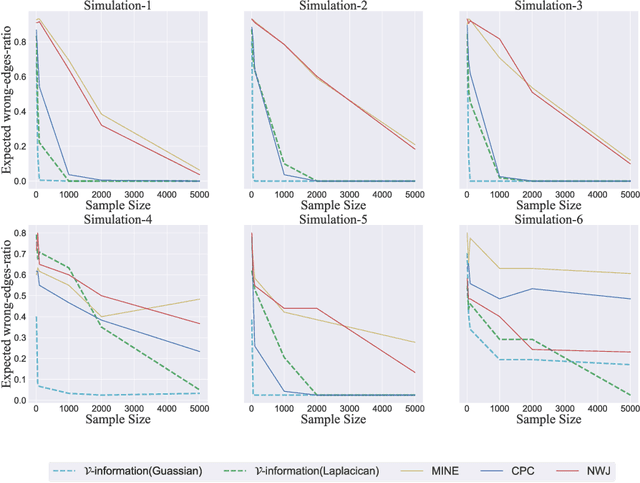

We propose a new framework for reasoning about information in complex systems. Our foundation is based on a variational extension of Shannon's information theory that takes into account the modeling power and computational constraints of the observer. The resulting \emph{predictive $\mathcal{V}$-information} encompasses mutual information and other notions of informativeness such as the coefficient of determination. Unlike Shannon's mutual information and in violation of the data processing inequality, $\mathcal{V}$-information can be created through computation. This is consistent with deep neural networks extracting hierarchies of progressively more informative features in representation learning. Additionally, we show that by incorporating computational constraints, $\mathcal{V}$-information can be reliably estimated from data even in high dimensions with PAC-style guarantees. Empirically, we demonstrate predictive $\mathcal{V}$-information is more effective than mutual information for structure learning and fair representation learning.
4D-MultispectralNet: Multispectral Stereoscopic Disparity Estimation using Human Masks
Apr 19, 2022
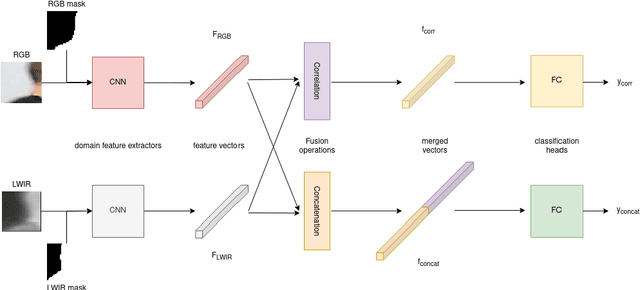
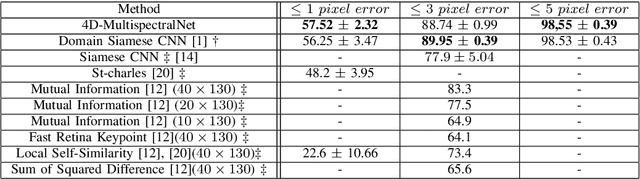
Multispectral stereoscopy is an emerging field. A lot of work has been done in classical stereoscopy, but multispectral stereoscopy is not studied as frequently. This type of stereoscopy can be used in autonomous vehicles to complete the information given by RGB cameras. It helps to identify objects in the surroundings when the conditions are more difficult, such as in night scenes. This paper focuses on the RGB-LWIR spectrum. RGB-LWIR stereoscopy has the same challenges as classical stereoscopy, that is occlusions, textureless surfaces and repetitive patterns, plus specific ones related to the different modalities. Finding matches between two spectrums adds another layer of complexity. Color, texture and shapes are more likely to vary from a spectrum to another. To address this additional challenge, this paper focuses on estimating the disparity of people present in a scene. Given the fact that people's shape is captured in both RGB and LWIR, we propose a novel method that uses segmentation masks of the human in both spectrum and than concatenate them to the original images before the first layer of a Siamese Network. This method helps to improve the accuracy, particularly within the one pixel error range.
A stochastic Stein Variational Newton method
Apr 19, 2022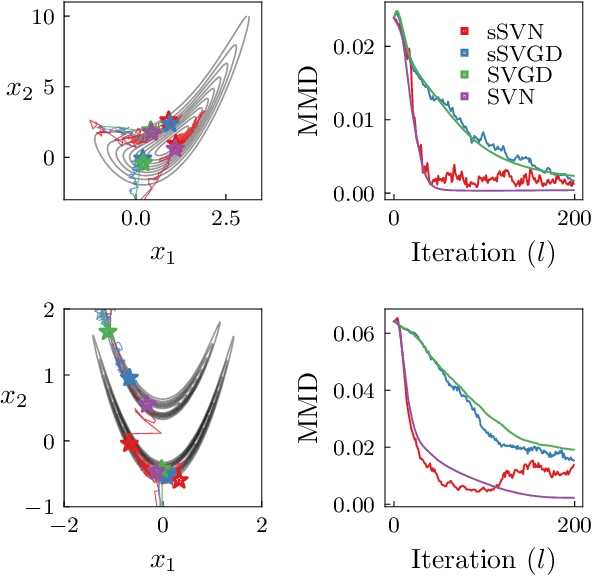
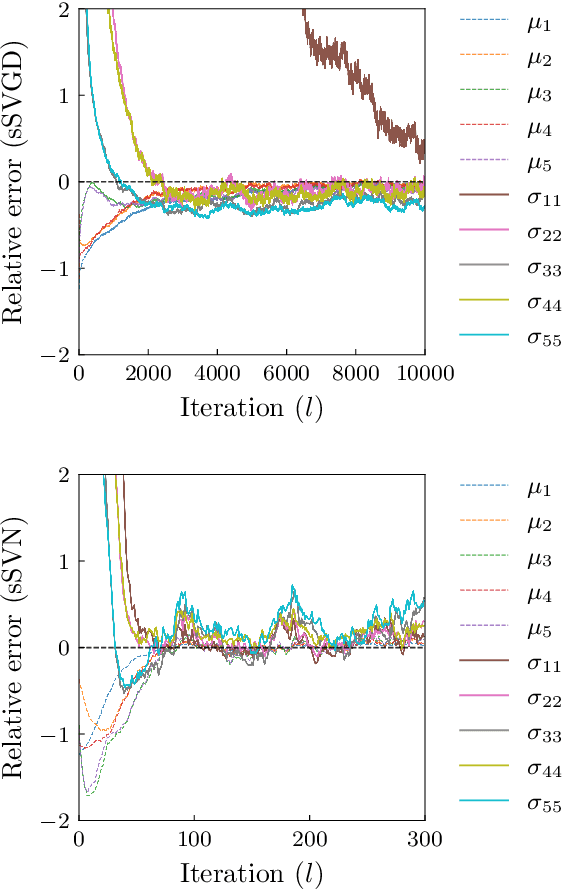
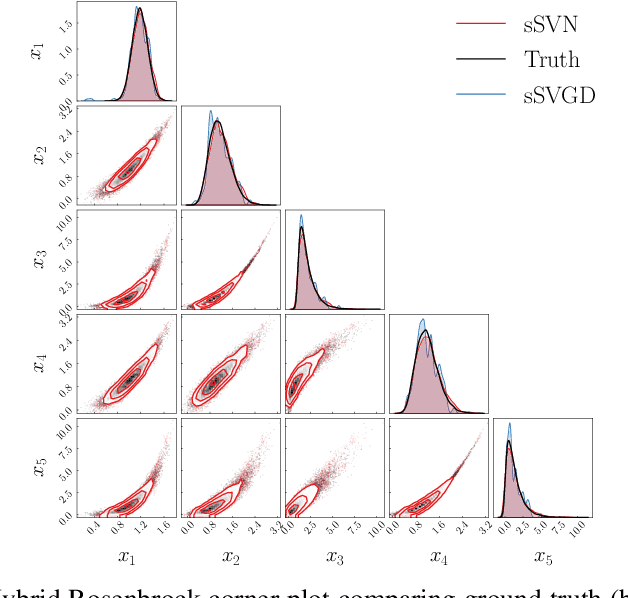
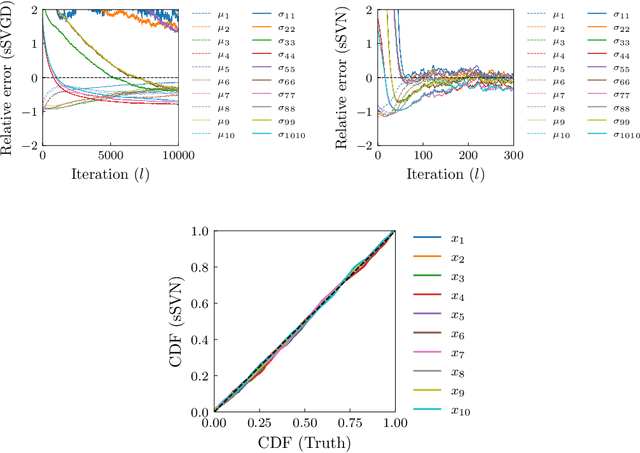
Stein variational gradient descent (SVGD) is a general-purpose optimization-based sampling algorithm that has recently exploded in popularity, but is limited by two issues: it is known to produce biased samples, and it can be slow to converge on complicated distributions. A recently proposed stochastic variant of SVGD (sSVGD) addresses the first issue, producing unbiased samples by incorporating a special noise into the SVGD dynamics such that asymptotic convergence is guaranteed. Meanwhile, Stein variational Newton (SVN), a Newton-like extension of SVGD, dramatically accelerates the convergence of SVGD by incorporating Hessian information into the dynamics, but also produces biased samples. In this paper we derive, and provide a practical implementation of, a stochastic variant of SVN (sSVN) which is both asymptotically correct and converges rapidly. We demonstrate the effectiveness of our algorithm on a difficult class of test problems -- the Hybrid Rosenbrock density -- and show that sSVN converges using three orders of magnitude fewer gradient evaluations of the log likelihood than its stochastic SVGD counterpart. Our results show that sSVN is a promising approach to accelerating high-precision Bayesian inference tasks with modest-dimension, $d\sim\mathcal{O}(10)$.
Generating 3D Molecules for Target Protein Binding
Apr 19, 2022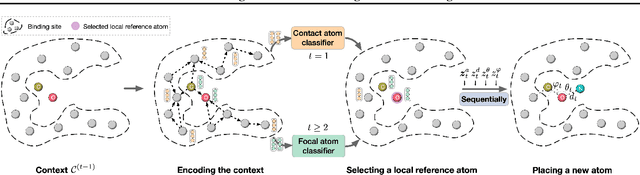
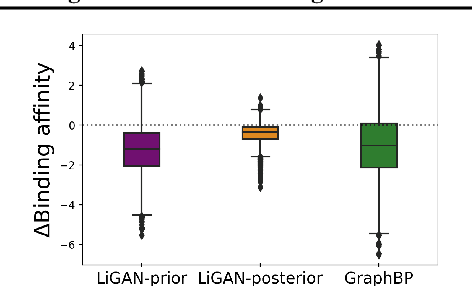
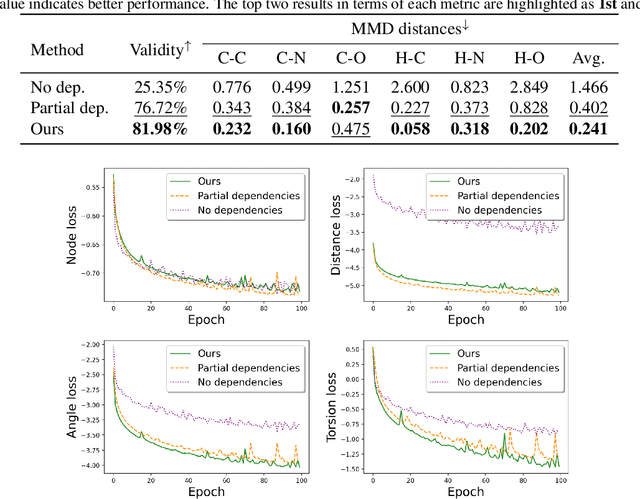
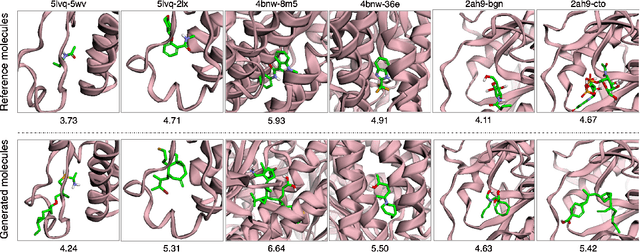
A fundamental problem in drug discovery is to design molecules that bind to specific proteins. To tackle this problem using machine learning methods, here we propose a novel and effective framework, known as GraphBP, to generate 3D molecules that bind to given proteins by placing atoms of specific types and locations to the given binding site one by one. In particular, at each step, we first employ a 3D graph neural network to obtain geometry-aware and chemically informative representations from the intermediate contextual information. Such context includes the given binding site and atoms placed in the previous steps. Second, to preserve the desirable equivariance property, we select a local reference atom according to the designed auxiliary classifiers and then construct a local spherical coordinate system. Finally, to place a new atom, we generate its atom type and relative location w.r.t. the constructed local coordinate system via a flow model. We also consider generating the variables of interest sequentially to capture the underlying dependencies among them. Experiments demonstrate that our GraphBP is effective to generate 3D molecules with binding ability to target protein binding sites. Our implementation is available at https://github.com/divelab/GraphBP.
How to Find Your Friendly Neighborhood: Graph Attention Design with Self-Supervision
Apr 11, 2022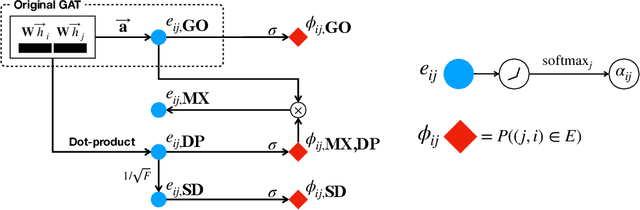
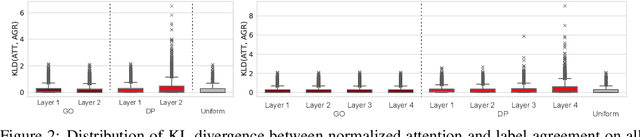
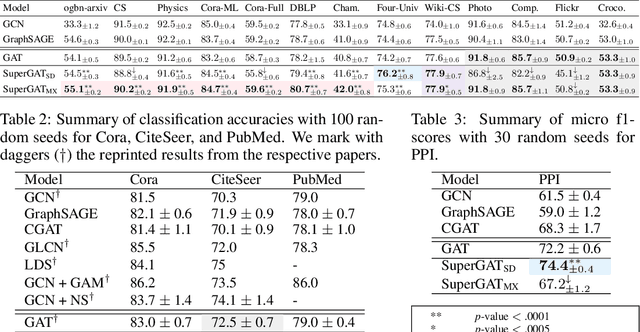
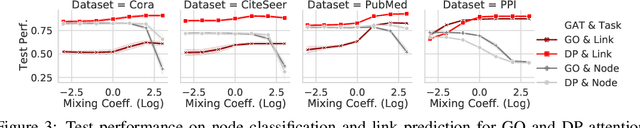
Attention mechanism in graph neural networks is designed to assign larger weights to important neighbor nodes for better representation. However, what graph attention learns is not understood well, particularly when graphs are noisy. In this paper, we propose a self-supervised graph attention network (SuperGAT), an improved graph attention model for noisy graphs. Specifically, we exploit two attention forms compatible with a self-supervised task to predict edges, whose presence and absence contain the inherent information about the importance of the relationships between nodes. By encoding edges, SuperGAT learns more expressive attention in distinguishing mislinked neighbors. We find two graph characteristics influence the effectiveness of attention forms and self-supervision: homophily and average degree. Thus, our recipe provides guidance on which attention design to use when those two graph characteristics are known. Our experiment on 17 real-world datasets demonstrates that our recipe generalizes across 15 datasets of them, and our models designed by recipe show improved performance over baselines.
Patch-wise Contrastive Style Learning for Instagram Filter Removal
Apr 15, 2022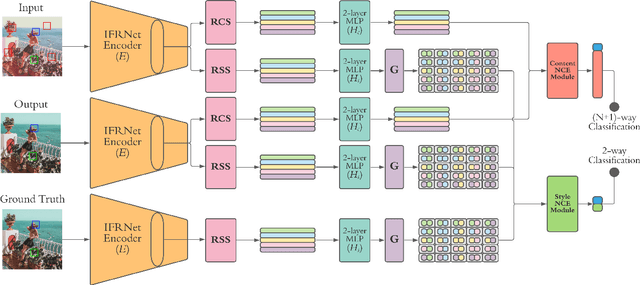
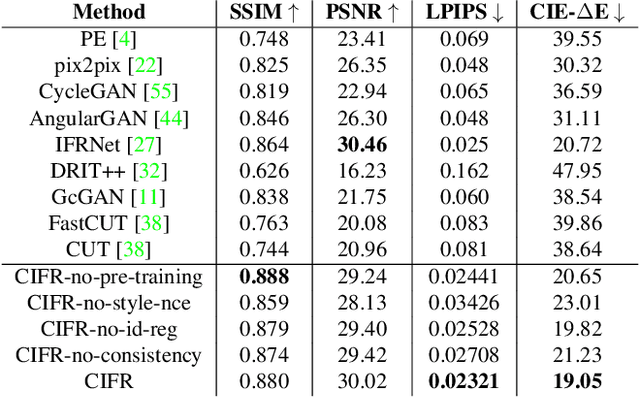
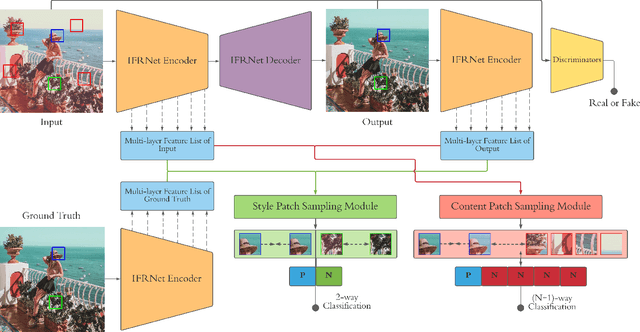
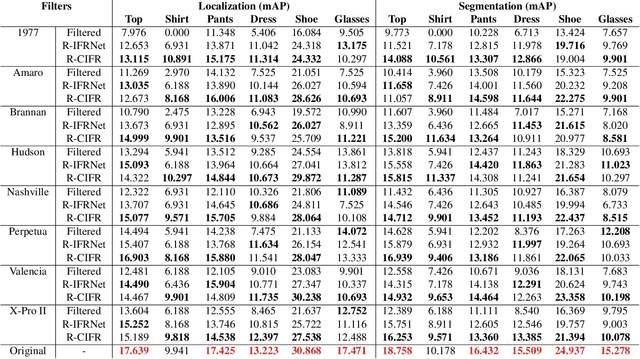
Image-level corruptions and perturbations degrade the performance of CNNs on different downstream vision tasks. Social media filters are one of the most common resources of various corruptions and perturbations for real-world visual analysis applications. The negative effects of these distractive factors can be alleviated by recovering the original images with their pure style for the inference of the downstream vision tasks. Assuming these filters substantially inject a piece of additional style information to the social media images, we can formulate the problem of recovering the original versions as a reverse style transfer problem. We introduce Contrastive Instagram Filter Removal Network (CIFR), which enhances this idea for Instagram filter removal by employing a novel multi-layer patch-wise contrastive style learning mechanism. Experiments show our proposed strategy produces better qualitative and quantitative results than the previous studies. Moreover, we present the results of our additional experiments for proposed architecture within different settings. Finally, we present the inference outputs and quantitative comparison of filtered and recovered images on localization and segmentation tasks to encourage the main motivation for this problem.
Conformalized Frequency Estimation from Sketched Data
Apr 08, 2022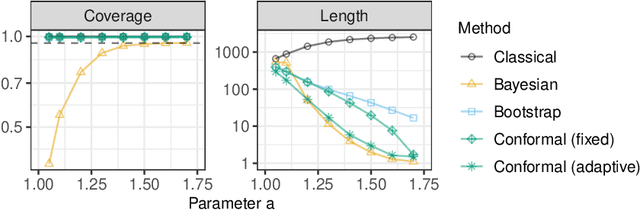
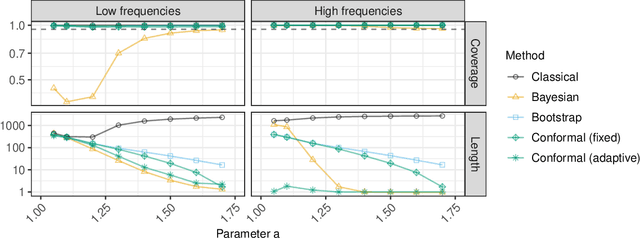
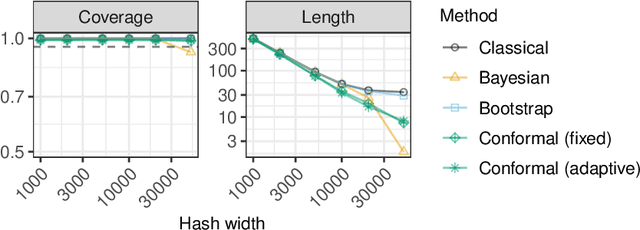
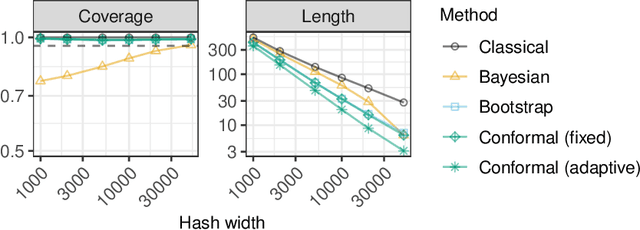
A flexible conformal inference method is developed to construct confidence intervals for the frequencies of queried objects in a very large data set, based on the information contained in a much smaller sketch of those data. The approach is completely data-adaptive and makes no use of any knowledge of the population distribution or of the inner workings of the sketching algorithm; instead, it constructs provably valid frequentist confidence intervals under the sole assumption of data exchangeability. Although the proposed solution is much more broadly applicable, this paper explicitly demonstrates its use in combination with the famous count-min sketch algorithm and a non-linear variation thereof to facilitate the exposition. The performance is compared to that of existing frequentist and Bayesian alternatives through several experiments with synthetic data as well as with real data sets consisting of SARS-CoV-2 DNA sequences and classic English literature.