 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DR-GAN: Distribution Regularization for Text-to-Image Generation
Apr 17, 2022
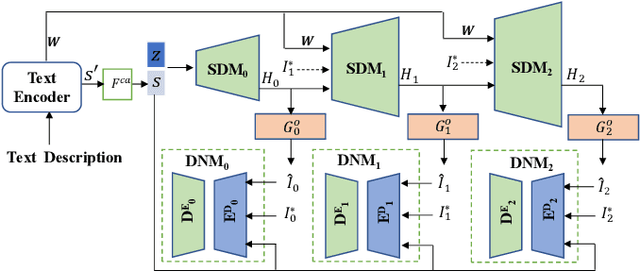
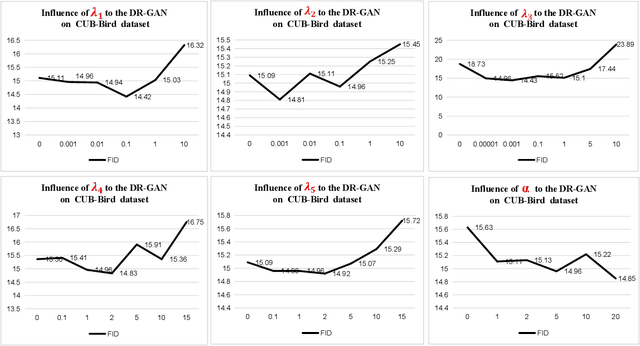

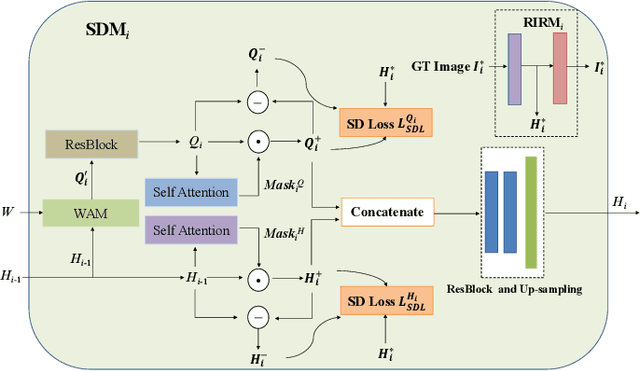
This paper presents a new Text-to-Image generation model, named Distribution Regularization Generative Adversarial Network (DR-GAN), to generate images from text descriptions from improved distribution learning. In DR-GAN, we introduce two novel modules: a Semantic Disentangling Module (SDM) and a Distribution Normalization Module (DNM). SDM combines the spatial self-attention mechanism and a new Semantic Disentangling Loss (SDL) to help the generator distill key semantic information for the image generation. DNM uses a Variational Auto-Encoder (VAE) to normalize and denoise the image latent distribution, which can help the discriminator better distinguish synthesized images from real images. DNM also adopts a Distribution Adversarial Loss (DAL) to guide the generator to align with normalized real image distributions in the latent space. Extensive experiments on two public datasets demonstrated that our DR-GAN achieved a competitive performance in the Text-to-Image task.
Classification of Hyperspectral Images Using SVM with Shape-adaptive Reconstruction and Smoothed Total Variation
Apr 06, 2022
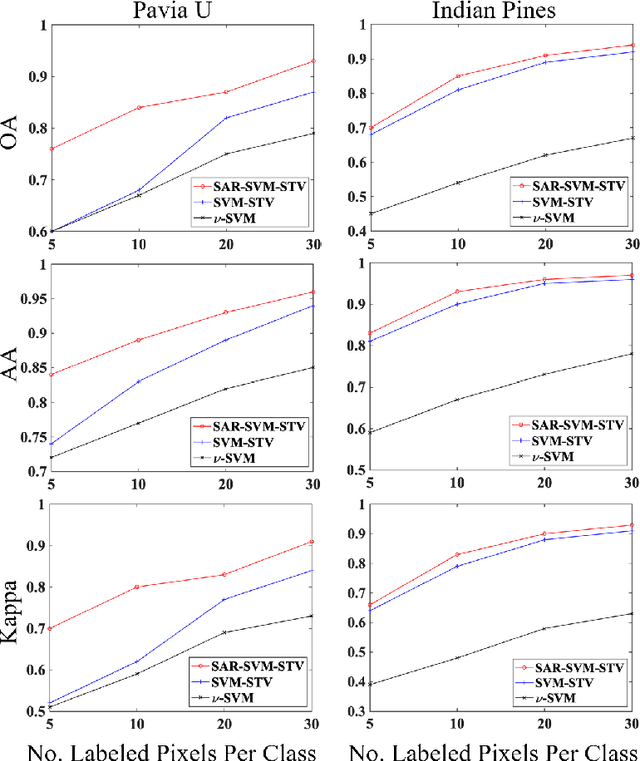
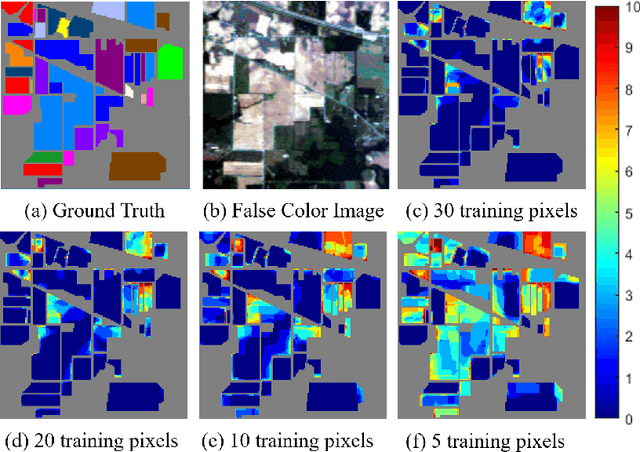

In this work, a novel algorithm called SVM with Shape-adaptive Reconstruction and Smoothed Total Variation (SaR-SVM-STV) is introduced to classify hyperspectral images, which makes full use of spatial and spectral information. The Shape-adaptive Reconstruction (SaR) is introduced to preprocess each pixel based on the Pearson Correlation between pixels in its shape-adaptive (SA) region. Support Vector Machines (SVMs) are trained to estimate the pixel-wise probability maps of each class. Then the Smoothed Total Variation (STV) model is applied to denoise and generate the final classification map. Experiments show that SaR-SVM-STV outperforms the SVM-STV method with a few training labels, demonstrating the significance of reconstructing hyperspectral images before classification.
Self-Calibrated Efficient Transformer for Lightweight Super-Resolution
Apr 19, 2022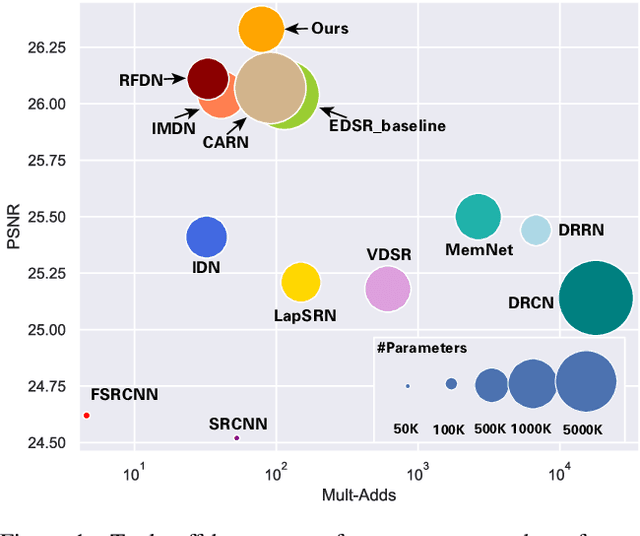
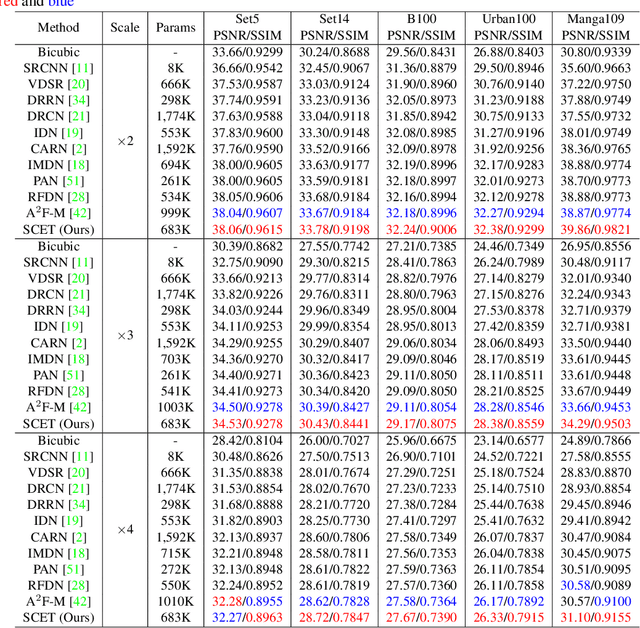
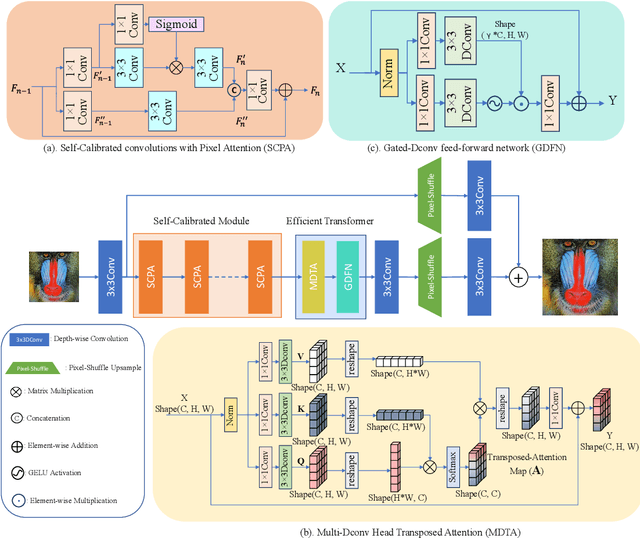
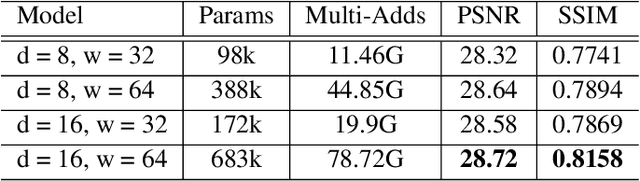
Recently, deep learning has been successfully applied to the single-image super-resolution (SISR) with remarkable performance. However, most existing methods focus on building a more complex network with a large number of layers, which can entail heavy computational costs and memory storage. To address this problem, we present a lightweight Self-Calibrated Efficient Transformer (SCET) network to solve this problem. The architecture of SCET mainly consists of the self-calibrated module and efficient transformer block, where the self-calibrated module adopts the pixel attention mechanism to extract image features effectively. To further exploit the contextual information from features, we employ an efficient transformer to help the network obtain similar features over long distances and thus recover sufficient texture details. We provide comprehensive results on different settings of the overall network. Our proposed method achieves more remarkable performance than baseline methods. The source code and pre-trained models are available at https://github.com/AlexZou14/SCET.
Bipartite Graph Embedding via Mutual Information Maximization
Dec 10, 2020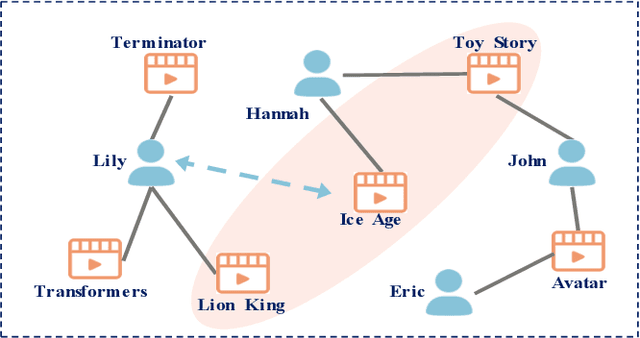
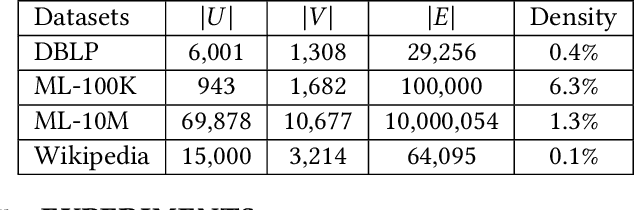
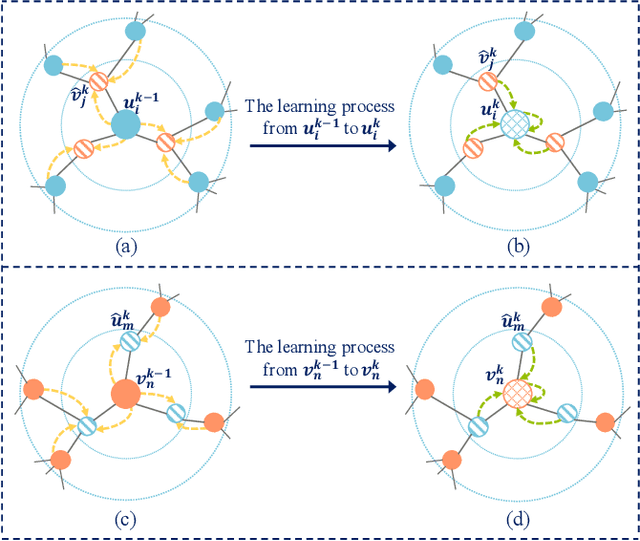
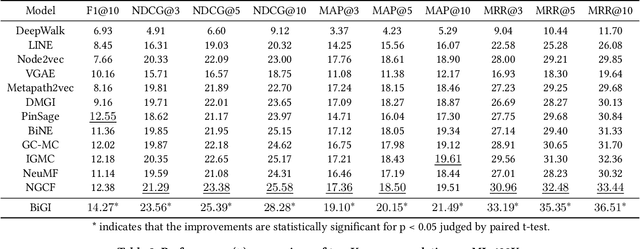
Bipartite graph embedding has recently attracted much attention due to the fact that bipartite graphs are widely used in various application domains. Most previous methods, which adopt random walk-based or reconstruction-based objectives, are typically effective to learn local graph structures. However, the global properties of bipartite graph, including community structures of homogeneous nodes and long-range dependencies of heterogeneous nodes, are not well preserved. In this paper, we propose a bipartite graph embedding called BiGI to capture such global properties by introducing a novel local-global infomax objective. Specifically, BiGI first generates a global representation which is composed of two prototype representations. BiGI then encodes sampled edges as local representations via the proposed subgraph-level attention mechanism. Through maximizing the mutual information between local and global representations, BiGI enables nodes in bipartite graph to be globally relevant. Our model is evaluated on various benchmark datasets for the tasks of top-K recommendation and link prediction. Extensive experiments demonstrate that BiGI achieves consistent and significant improvements over state-of-the-art baselines. Detailed analyses verify the high effectiveness of modeling the global properties of bipartite graph.
TIGRIS: An Informed Sampling-based Algorithm for Informative Path Planning
Mar 24, 2022
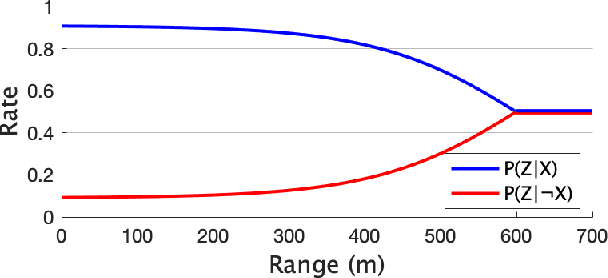
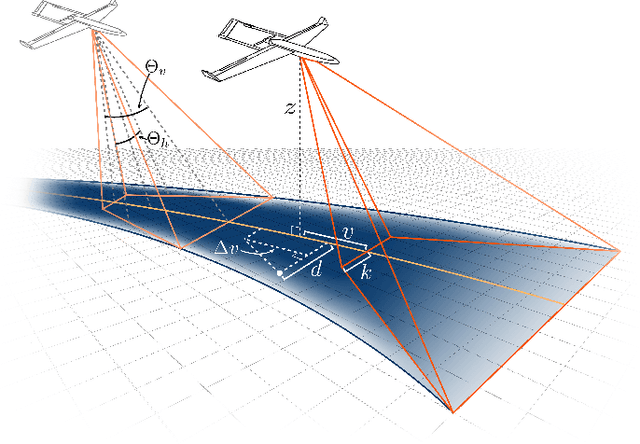
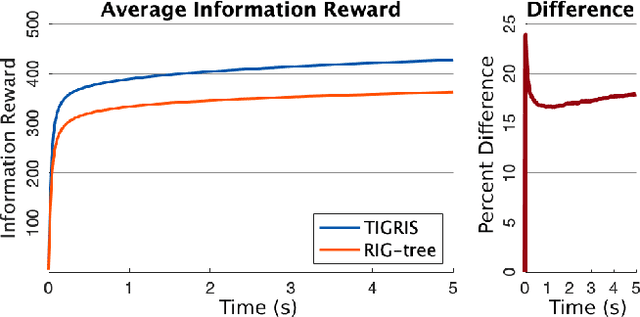
Informative path planning is an important and challenging problem in robotics that remains to be solved in a manner that allows for wide-spread implementation and real-world practical adoption. Among various reasons for this, one is the lack of approaches that allow for informative path planning in high-dimensional spaces and non-trivial sensor constraints. In this work we present a sampling-based approach that allows us to tackle the challenges of large and high-dimensional search spaces. This is done by performing informed sampling in the high-dimensional continuous space and incorporating potential information gain along edges in the reward estimation. This method rapidly generates a global path that maximizes information gain for the given path budget constraints. We discuss the details of our implementation for an example use case of searching for multiple objects of interest in a large search space using a fixed-wing UAV with a forward-facing camera. We compare our approach to a sampling-based planner baseline and demonstrate how our contributions allow our approach to consistently out-perform the baseline by $18.0\%$. With this we thus present a practical and generalizable informative path planning framework that can be used for very large environments, limited budgets, and high dimensional search spaces, such as robots with motion constraints or high-dimensional configuration spaces.
No Free Lunch Theorem for Security and Utility in Federated Learning
Mar 20, 2022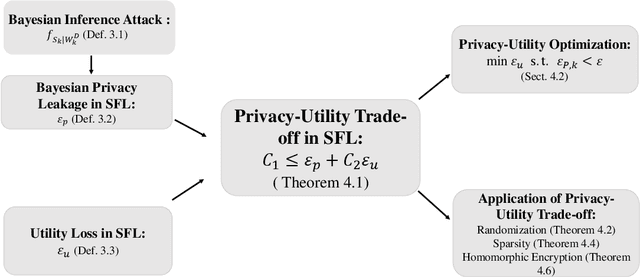

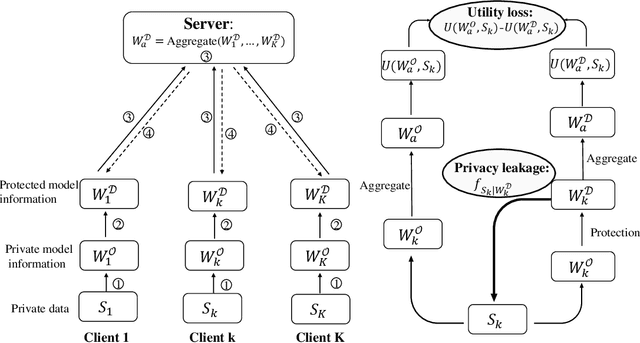
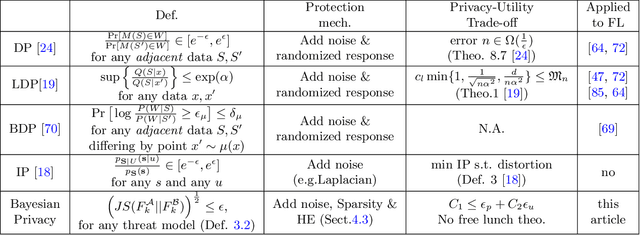
In a federated learning scenario where multiple parties jointly learn a model from their respective data, there exist two conflicting goals for the choice of appropriate algorithms. On one hand, private and sensitive training data must be kept secure as much as possible in the presence of \textit{semi-honest} partners, while on the other hand, a certain amount of information has to be exchanged among different parties for the sake of learning utility. Such a challenge calls for the privacy-preserving federated learning solution, which maximizes the utility of the learned model and maintains a provable privacy guarantee of participating parties' private data. This article illustrates a general framework that a) formulates the trade-off between privacy loss and utility loss from a unified information-theoretic point of view, and b) delineates quantitative bounds of privacy-utility trade-off when different protection mechanisms including Randomization, Sparsity, and Homomorphic Encryption are used. It was shown that in general \textit{there is no free lunch for the privacy-utility trade-off} and one had to trade the protection of privacy with a certain degree of degraded utility. The quantitative analysis illustrated in this article may serve as the guidance for the design of practical federated learning algorithms.
An information criterion for automatic gradient tree boosting
Aug 13, 2020
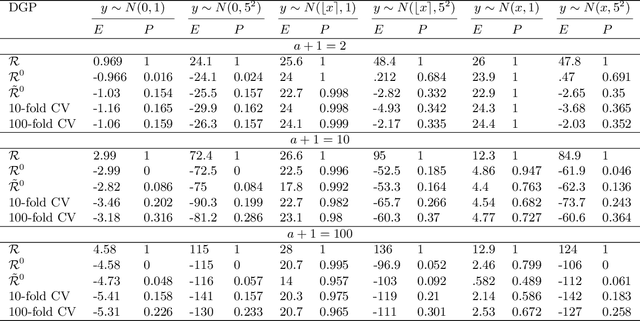
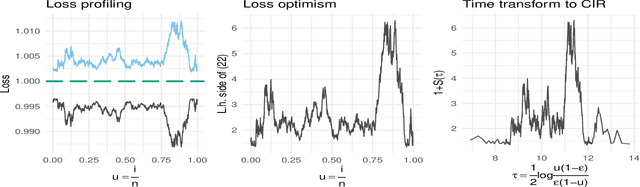
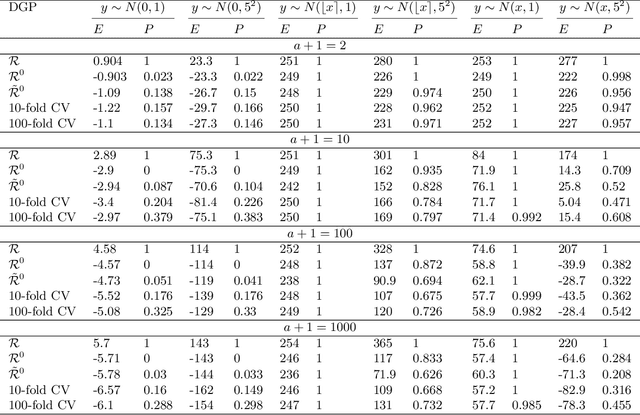
An information theoretic approach to learning the complexity of classification and regression trees and the number of trees in gradient tree boosting is proposed. The optimism (test loss minus training loss) of the greedy leaf splitting procedure is shown to be the maximum of a Cox-Ingersoll-Ross process, from which a generalization-error based information criterion is formed. The proposed procedure allows fast local model selection without cross validation based hyper parameter tuning, and hence efficient and automatic comparison among the large number of models performed during each boosting iteration. Relative to xgboost, speedups on numerical experiments ranges from around 10 to about 1400, at similar predictive-power measured in terms of test-loss.
M2TS: Multi-Scale Multi-Modal Approach Based on Transformer for Source Code Summarization
Mar 27, 2022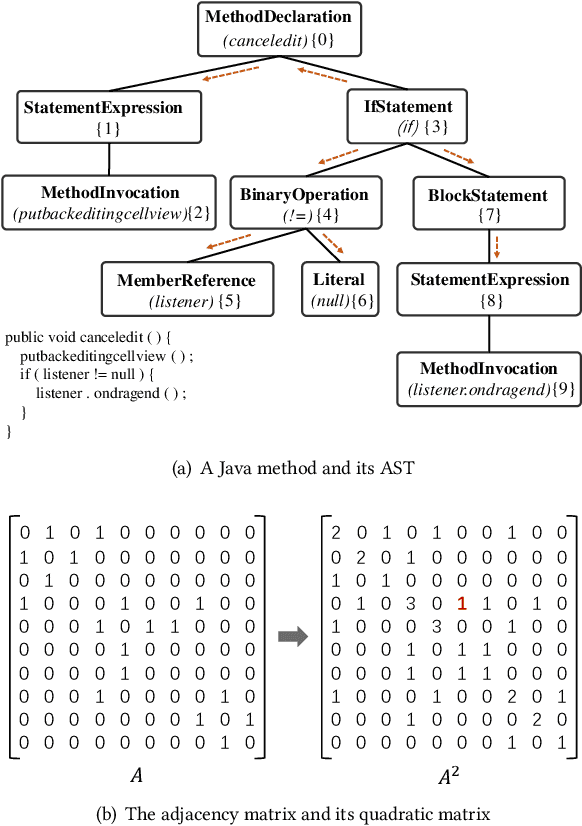
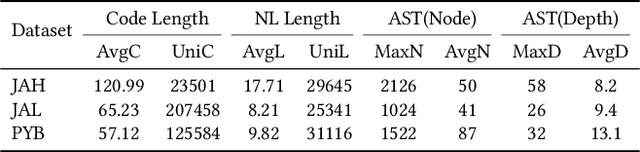
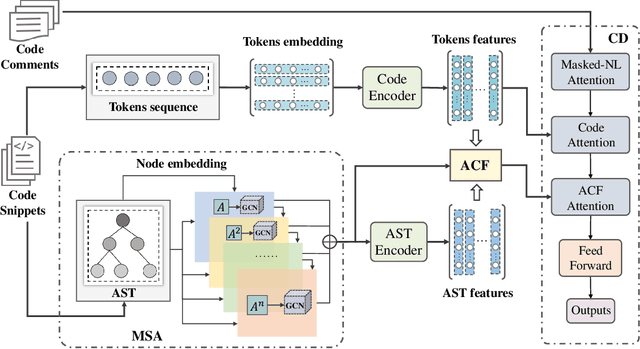
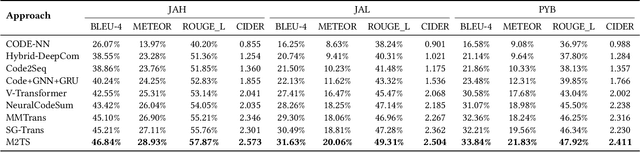
Source code summarization aims to generate natural language descriptions of code snippets. Many existing studies learn the syntactic and semantic knowledge of code snippets from their token sequences and Abstract Syntax Trees (ASTs). They use the learned code representations as input to code summarization models, which can accordingly generate summaries describing source code. Traditional models traverse ASTs as sequences or split ASTs into paths as input. However, the former loses the structural properties of ASTs, and the latter destroys the overall structure of ASTs. Therefore, comprehensively capturing the structural features of ASTs in learning code representations for source code summarization remains a challenging problem to be solved. In this paper, we propose M2TS, a Multi-scale Multi-modal approach based on Transformer for source code Summarization. M2TS uses a multi-scale AST feature extraction method, which can extract the structures of ASTs more completely and accurately at multiple local and global levels. To complement missing semantic information in ASTs, we also obtain code token features, and further combine them with the extracted AST features using a cross modality fusion method that not only fuses the syntactic and contextual semantic information of source code, but also highlights the key features of each modality. We conduct experiments on two Java and one Python datasets, and the experimental results demonstrate that M2TS outperforms current state-of-the-art methods. We release our code at https://github.com/TranSMS/M2TS.
On the Use of Fine-grained Vulnerable Code Statements for Software Vulnerability Assessment Models
Mar 16, 2022

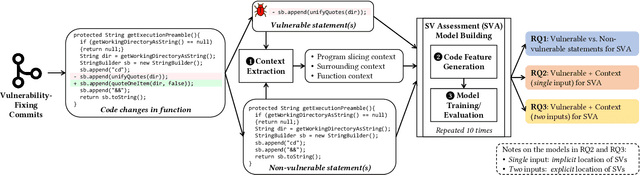
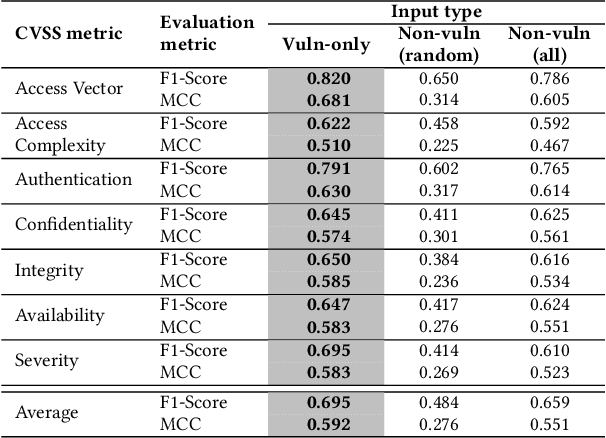
Many studies have developed Machine Learning (ML) approaches to detect Software Vulnerabilities (SVs) in functions and fine-grained code statements that cause such SVs. However, there is little work on leveraging such detection outputs for data-driven SV assessment to give information about exploitability, impact, and severity of SVs. The information is important to understand SVs and prioritize their fixing. Using large-scale data from 1,782 functions of 429 SVs in 200 real-world projects, we investigate ML models for automating function-level SV assessment tasks, i.e., predicting seven Common Vulnerability Scoring System (CVSS) metrics. We particularly study the value and use of vulnerable statements as inputs for developing the assessment models because SVs in functions are originated in these statements. We show that vulnerable statements are 5.8 times smaller in size, yet exhibit 7.5-114.5% stronger assessment performance (Matthews Correlation Coefficient (MCC)) than non-vulnerable statements. Incorporating context of vulnerable statements further increases the performance by up to 8.9% (0.64 MCC and 0.75 F1-Score). Overall, we provide the initial yet promising ML-based baselines for function-level SV assessment, paving the way for further research in this direction.
Cross-Image Relational Knowledge Distillation for Semantic Segmentation
Apr 14, 2022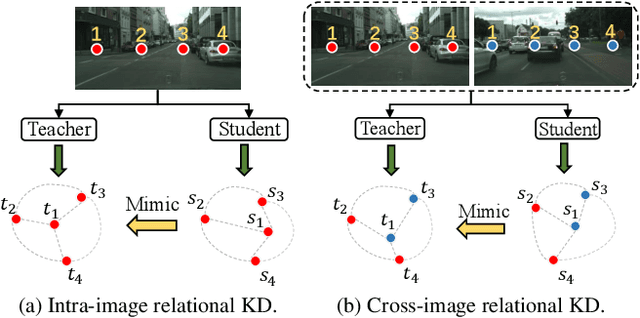
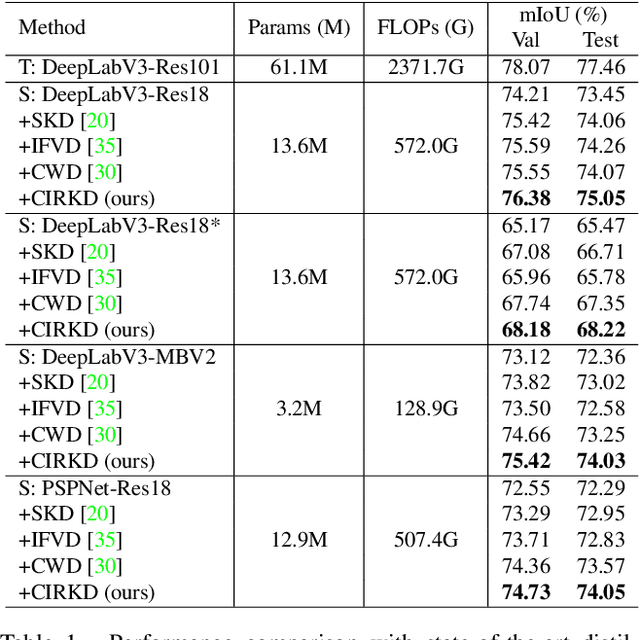
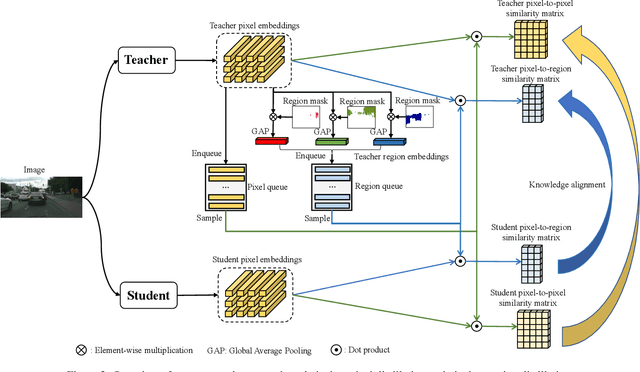
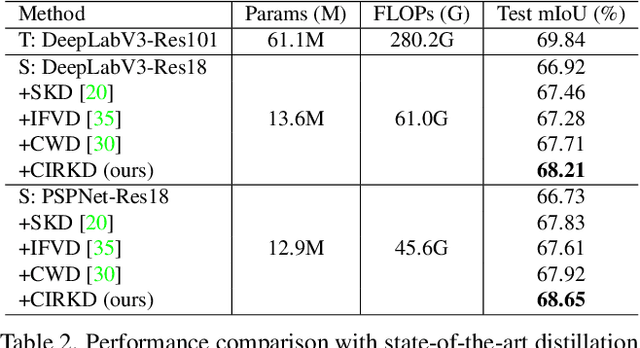
Current Knowledge Distillation (KD) methods for semantic segmentation often guide the student to mimic the teacher's structured information generated from individual data samples. However, they ignore the global semantic relations among pixels across various images that are valuable for KD. This paper proposes a novel Cross-Image Relational KD (CIRKD), which focuses on transferring structured pixel-to-pixel and pixel-to-region relations among the whole images. The motivation is that a good teacher network could construct a well-structured feature space in terms of global pixel dependencies. CIRKD makes the student mimic better structured semantic relations from the teacher, thus improving the segmentation performance. Experimental results over Cityscapes, CamVid and Pascal VOC datasets demonstrate the effectiveness of our proposed approach against state-of-the-art distillation methods. The code is available at https://github.com/winycg/CIRKD.