 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Meta-path Analysis on Spatio-Temporal Graphs for Pedestrian Trajectory Prediction
Feb 27, 2022
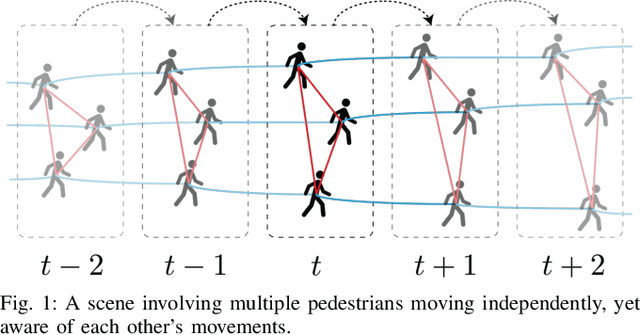
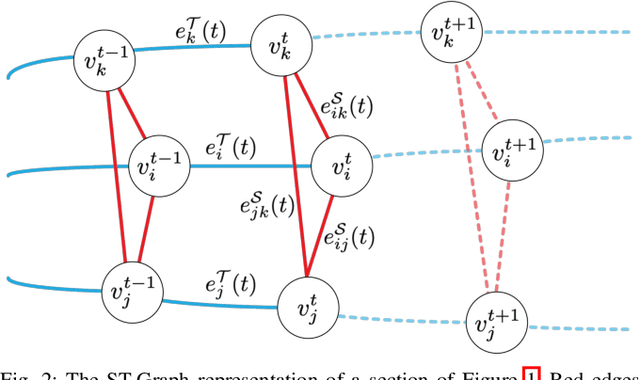
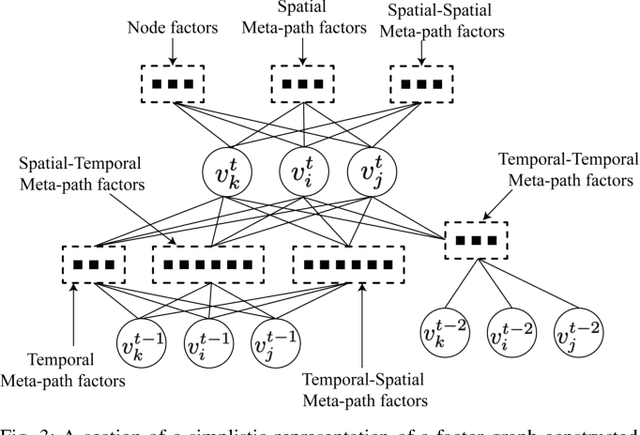
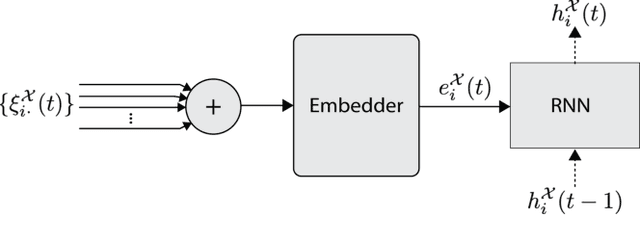
Spatio-temporal graphs (ST-graphs) have been used to model time series tasks such as traffic forecasting, human motion modeling, and action recognition. The high-level structure and corresponding features from ST-graphs have led to improved performance over traditional architectures. However, current methods tend to be limited by simple features, despite the rich information provided by the full graph structure, which leads to inefficiencies and suboptimal performance in downstream tasks. We propose the use of features derived from meta-paths, walks across different types of edges, in ST-graphs to improve the performance of Structural Recurrent Neural Network. In this paper, we present the Meta-path Enhanced Structural Recurrent Neural Network (MESRNN), a generic framework that can be applied to any spatio-temporal task in a simple and scalable manner. We employ MESRNN for pedestrian trajectory prediction, utilizing these meta-path based features to capture the relationships between the trajectories of pedestrians at different points in time and space. We compare our MESRNN against state-of-the-art ST-graph methods on standard datasets to show the performance boost provided by meta-path information. The proposed model consistently outperforms the baselines in trajectory prediction over long time horizons by over 32\%, and produces more socially compliant trajectories in dense crowds. For more information please refer to the project website at https://sites.google.com/illinois.edu/mesrnn/home.
Combining Deep Reinforcement Learning and Search for Imperfect-Information Games
Jul 27, 2020
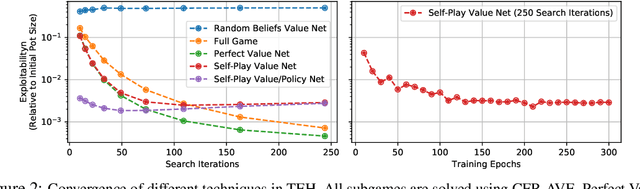
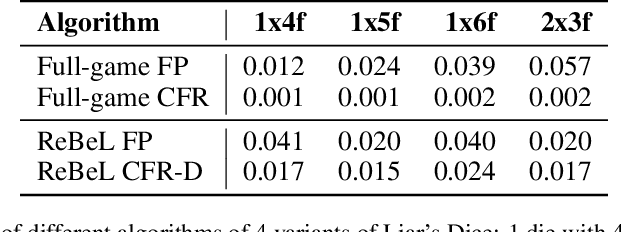
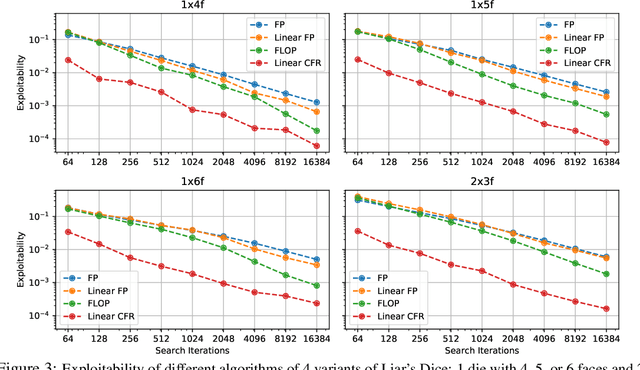
The combination of deep reinforcement learning and search at both training and test time is a powerful paradigm that has led to a number of a successes in single-agent settings and perfect-information games, best exemplified by the success of AlphaZero. However, algorithms of this form have been unable to cope with imperfect-information games. This paper presents ReBeL, a general framework for self-play reinforcement learning and search for imperfect-information games. In the simpler setting of perfect-information games, ReBeL reduces to an algorithm similar to AlphaZero. Results show ReBeL leads to low exploitability in benchmark imperfect-information games and achieves superhuman performance in heads-up no-limit Texas hold'em poker, while using far less domain knowledge than any prior poker AI. We also prove that ReBeL converges to a Nash equilibrium in two-player zero-sum games in tabular settings.
A Deep Reinforcement Learning Framework for Rapid Diagnosis of Whole Slide Pathological Images
May 05, 2022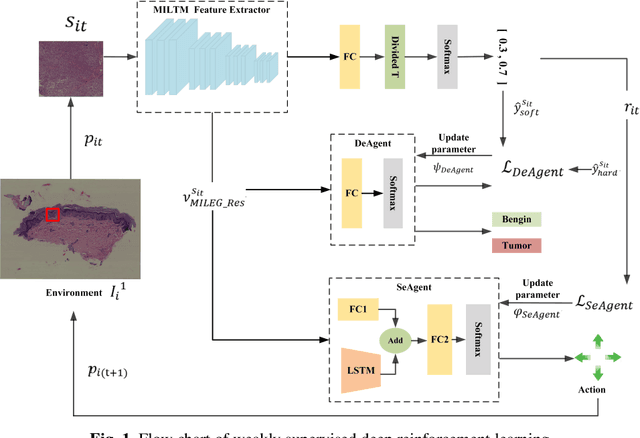
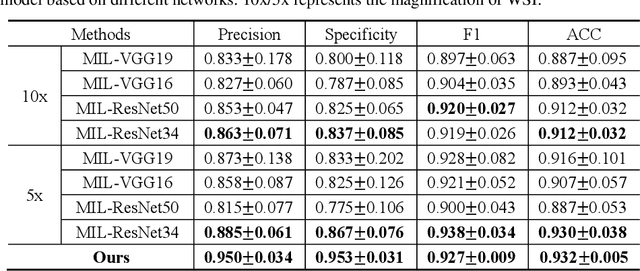
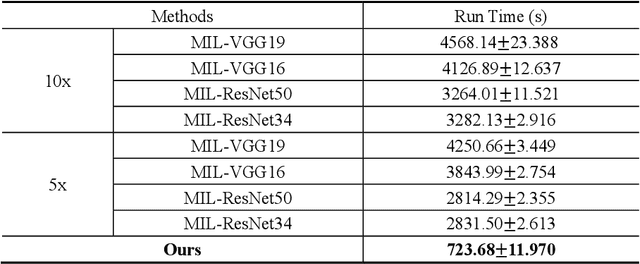
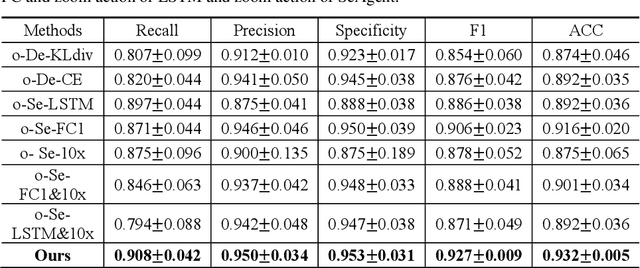
The deep neural network is a research hotspot for histopathological image analysis, which can improve the efficiency and accuracy of diagnosis for pathologists or be used for disease screening. The whole slide pathological image can reach one gigapixel and contains abundant tissue feature information, which needs to be divided into a lot of patches in the training and inference stages. This will lead to a long convergence time and large memory consumption. Furthermore, well-annotated data sets are also in short supply in the field of digital pathology. Inspired by the pathologist's clinical diagnosis process, we propose a weakly supervised deep reinforcement learning framework, which can greatly reduce the time required for network inference. We use neural network to construct the search model and decision model of reinforcement learning agent respectively. The search model predicts the next action through the image features of different magnifications in the current field of view, and the decision model is used to return the predicted probability of the current field of view image. In addition, an expert-guided model is constructed by multi-instance learning, which not only provides rewards for search model, but also guides decision model learning by the knowledge distillation method. Experimental results show that our proposed method can achieve fast inference and accurate prediction of whole slide images without any pixel-level annotations.
A Survey on Unsupervised Industrial Anomaly Detection Algorithms
Apr 28, 2022


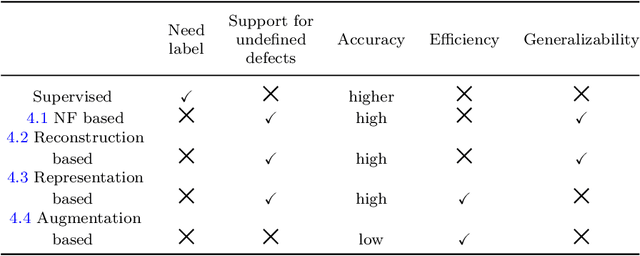
In line with the development of Industry 4.0, more and more attention is attracted to the field of surface defect detection. Improving efficiency as well as saving labor costs has steadily become a matter of great concern in industry field, where deep learning-based algorithms performs better than traditional vision inspection methods in recent years. While existing deep learning-based algorithms are biased towards supervised learning, which not only necessitates a huge amount of labeled data and a significant amount of labor, but it is also inefficient and has certain limitations. In contrast, recent research shows that unsupervised learning has great potential in tackling above disadvantages for visual anomaly detection. In this survey, we summarize current challenges and provide a thorough overview of recently proposed unsupervised algorithms for visual anomaly detection covering five categories, whose innovation points and frameworks are described in detail. Meanwhile, information on publicly available datasets containing surface image samples are provided. By comparing different classes of methods, the advantages and disadvantages of anomaly detection algorithms are summarized. It is expected to assist both the research community and industry in developing a broader and cross-domain perspective.
Anomaly Detection by Leveraging Incomplete Anomalous Knowledge with Anomaly-Aware Bidirectional GANs
Apr 28, 2022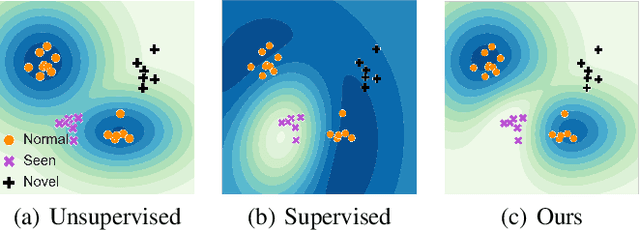
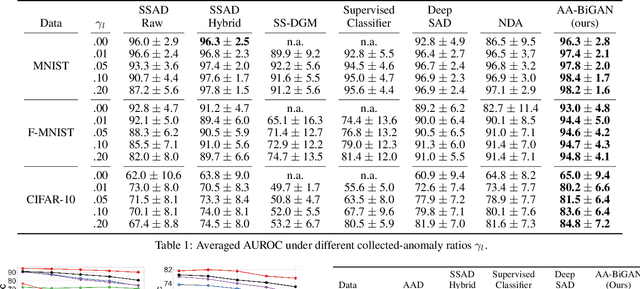
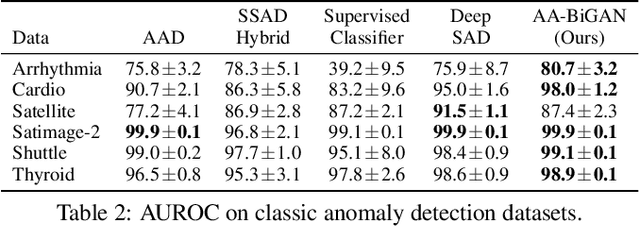
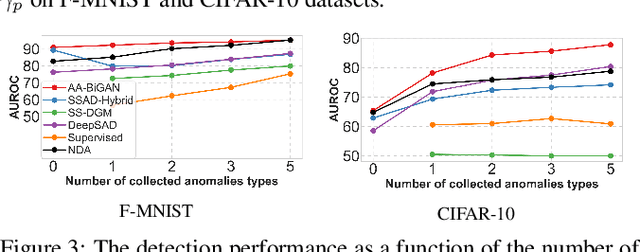
The goal of anomaly detection is to identify anomalous samples from normal ones. In this paper, a small number of anomalies are assumed to be available at the training stage, but they are assumed to be collected only from several anomaly types, leaving the majority of anomaly types not represented in the collected anomaly dataset at all. To effectively leverage this kind of incomplete anomalous knowledge represented by the collected anomalies, we propose to learn a probability distribution that can not only model the normal samples, but also guarantee to assign low density values for the collected anomalies. To this end, an anomaly-aware generative adversarial network (GAN) is developed, which, in addition to modeling the normal samples as most GANs do, is able to explicitly avoid assigning probabilities for collected anomalous samples. Moreover, to facilitate the computation of anomaly detection criteria like reconstruction error, the proposed anomaly-aware GAN is designed to be bidirectional, attaching an encoder for the generator. Extensive experimental results demonstrate that our proposed method is able to effectively make use of the incomplete anomalous information, leading to significant performance gains compared to existing methods.
GAM(e) changer or not? An evaluation of interpretable machine learning models based on additive model constraints
Apr 19, 2022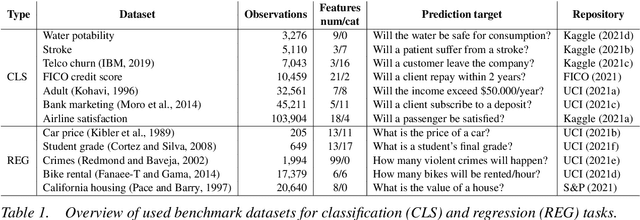
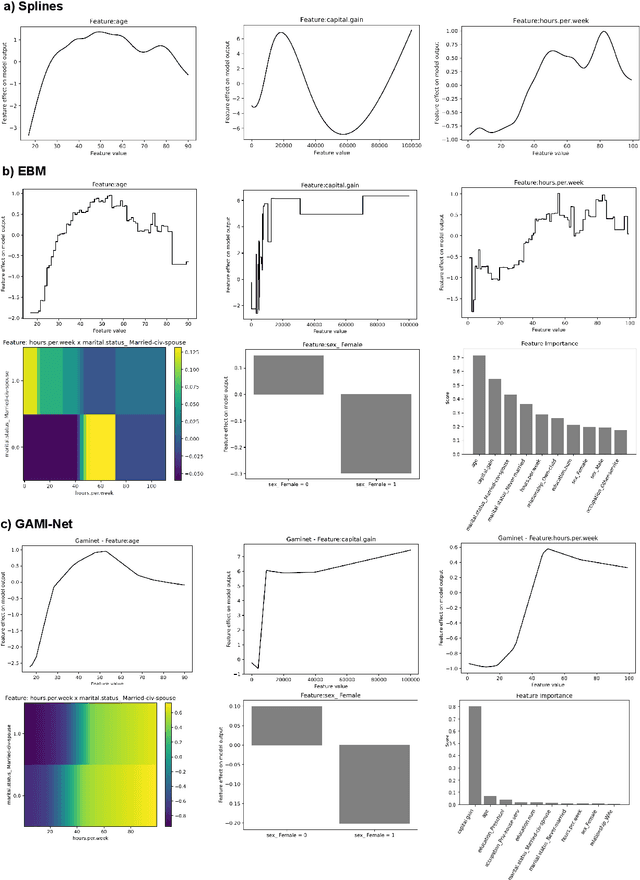
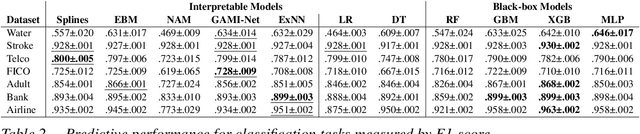
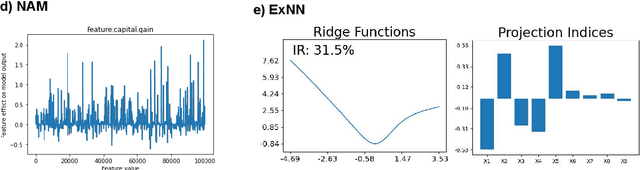
The number of information systems (IS) studies dealing with explainable artificial intelligence (XAI) is currently exploding as the field demands more transparency about the internal decision logic of machine learning (ML) models. However, most techniques subsumed under XAI provide post-hoc-analytical explanations, which have to be considered with caution as they only use approximations of the underlying ML model. Therefore, our paper investigates a series of intrinsically interpretable ML models and discusses their suitability for the IS community. More specifically, our focus is on advanced extensions of generalized additive models (GAM) in which predictors are modeled independently in a non-linear way to generate shape functions that can capture arbitrary patterns but remain fully interpretable. In our study, we evaluate the prediction qualities of five GAMs as compared to six traditional ML models and assess their visual outputs for model interpretability. On this basis, we investigate their merits and limitations and derive design implications for further improvements.
Ultrasound Shear Wave Elasticity Imaging with Spatio-Temporal Deep Learning
Apr 28, 2022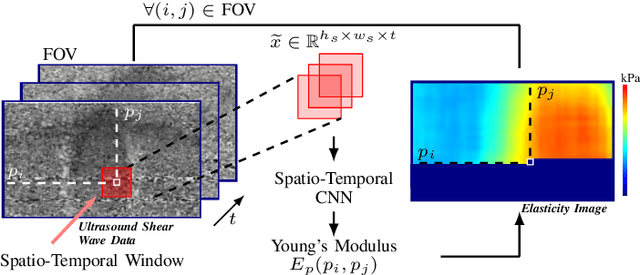
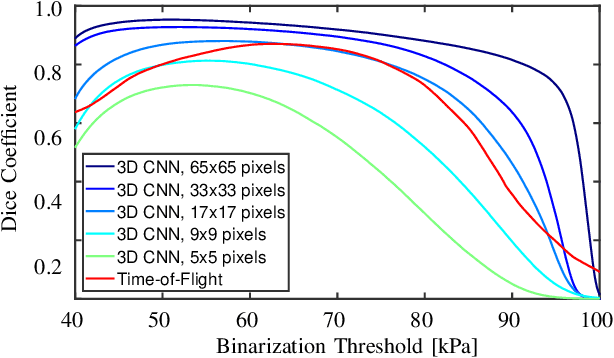
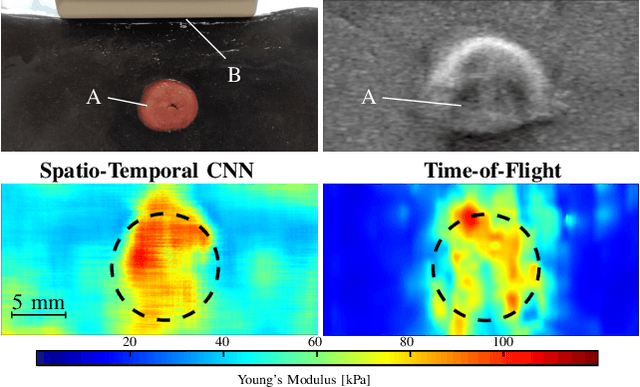

Ultrasound shear wave elasticity imaging is a valuable tool for quantifying the elastic properties of tissue. Typically, the shear wave velocity is derived and mapped to an elasticity value, which neglects information such as the shape of the propagating shear wave or push sequence characteristics. We present 3D spatio-temporal CNNs for fast local elasticity estimation from ultrasound data. This approach is based on retrieving elastic properties from shear wave propagation within small local regions. A large training data set is acquired with a robot from homogeneous gelatin phantoms ranging from 17.42 kPa to 126.05 kPa with various push locations. The results show that our approach can estimate elastic properties on a pixelwise basis with a mean absolute error of 5.01+-4.37 kPa. Furthermore, we estimate local elasticity independent of the push location and can even perform accurate estimates inside the push region. For phantoms with embedded inclusions, we report a 53.93% lower MAE (7.50 kPa) and on the background of 85.24% (1.64 kPa) compared to a conventional shear wave method. Overall, our method offers fast local estimations of elastic properties with small spatio-temporal window sizes.
Magnitude-aware Probabilistic Speaker Embeddings
Feb 28, 2022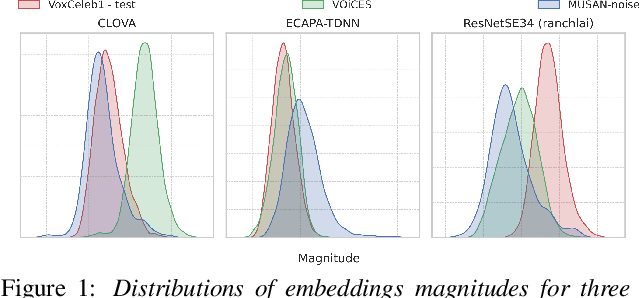


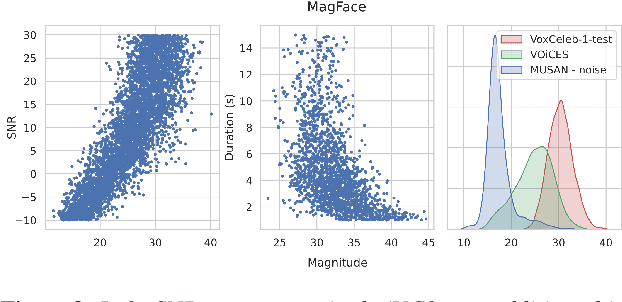
Recently, hyperspherical embeddings have established themselves as a dominant technique for face and voice recognition. Specifically, Euclidean space vector embeddings are learned to encode person-specific information in their direction while ignoring the magnitude. However, recent studies have shown that the magnitudes of the embeddings extracted by deep neural networks may indicate the quality of the corresponding inputs. This paper explores the properties of the magnitudes of the embeddings related to quality assessment and out-of-distribution detection. We propose a new probabilistic speaker embedding extractor using the information encoded in the embedding magnitude and leverage it in the speaker verification pipeline. We also propose several quality-aware diarization methods and incorporate the magnitudes in those. Our results indicate significant improvements over magnitude-agnostic baselines both in speaker verification and diarization tasks.
Contextual Attention Network: Transformer Meets U-Net
Mar 02, 2022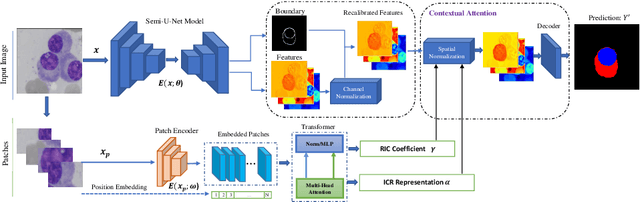
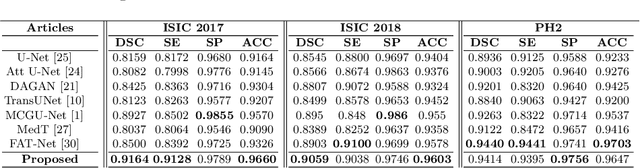


Currently, convolutional neural networks (CNN) (e.g., U-Net) have become the de facto standard and attained immense success in medical image segmentation. However, as a downside, CNN based methods are a double-edged sword as they fail to build long-range dependencies and global context connections due to the limited receptive field that stems from the intrinsic characteristics of the convolution operation. Hence, recent articles have exploited Transformer variants for medical image segmentation tasks which open up great opportunities due to their innate capability of capturing long-range correlations through the attention mechanism. Although being feasibly designed, most of the cohort studies incur prohibitive performance in capturing local information, thereby resulting in less lucidness of boundary areas. In this paper, we propose a contextual attention network to tackle the aforementioned limitations. The proposed method uses the strength of the Transformer module to model the long-range contextual dependency. Simultaneously, it utilizes the CNN encoder to capture local semantic information. In addition, an object-level representation is included to model the regional interaction map. The extracted hierarchical features are then fed to the contextual attention module to adaptively recalibrate the representation space using the local information. Then, they emphasize the informative regions while taking into account the long-range contextual dependency derived by the Transformer module. We validate our method on several large-scale public medical image segmentation datasets and achieve state-of-the-art performance. We have provided the implementation code in https://github.com/rezazad68/TMUnet.
Efficient and Accurate Conversion of Spiking Neural Network with Burst Spikes
Apr 28, 2022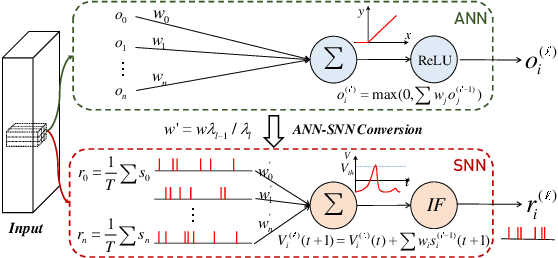
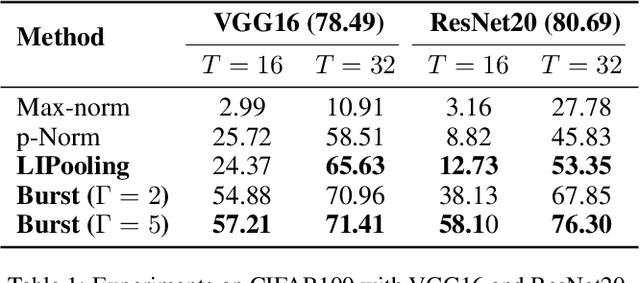
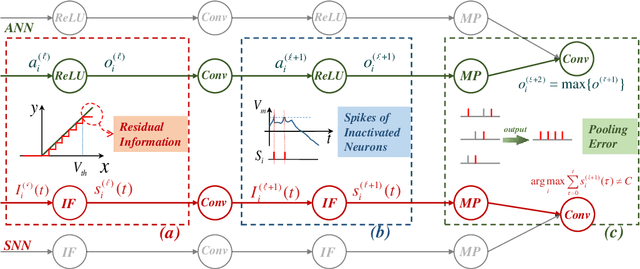
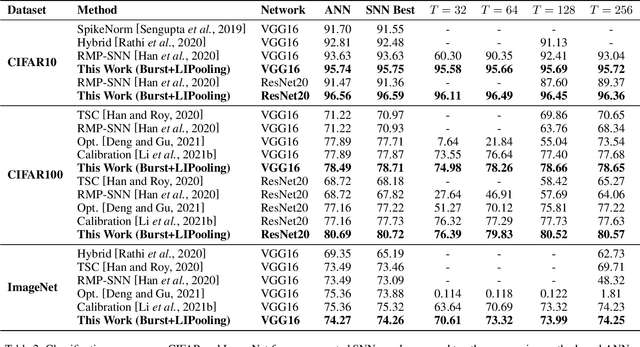
Spiking neural network (SNN), as a brain-inspired energy-efficient neural network, has attracted the interest of researchers. While the training of spiking neural networks is still an open problem. One effective way is to map the weight of trained ANN to SNN to achieve high reasoning ability. However, the converted spiking neural network often suffers from performance degradation and a considerable time delay. To speed up the inference process and obtain higher accuracy, we theoretically analyze the errors in the conversion process from three perspectives: the differences between IF and ReLU, time dimension, and pooling operation. We propose a neuron model for releasing burst spikes, a cheap but highly efficient method to solve residual information. In addition, Lateral Inhibition Pooling (LIPooling) is proposed to solve the inaccuracy problem caused by MaxPooling in the conversion process. Experimental results on CIFAR and ImageNet demonstrate that our algorithm is efficient and accurate. For example, our method can ensure nearly lossless conversion of SNN and only use about 1/10 (less than 100) simulation time under 0.693$\times$ energy consumption of the typical method. Our code is available at https://github.com/Brain-Inspired-Cognitive-Engine/Conversion_Burst.