 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Web-Based File Clustering and Indexing for Mindoro State University
Feb 13, 2022
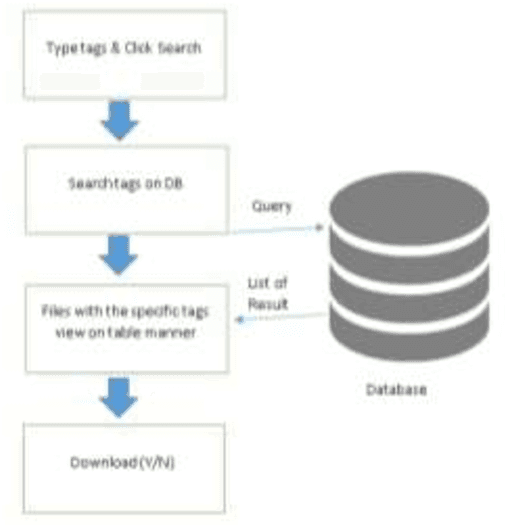

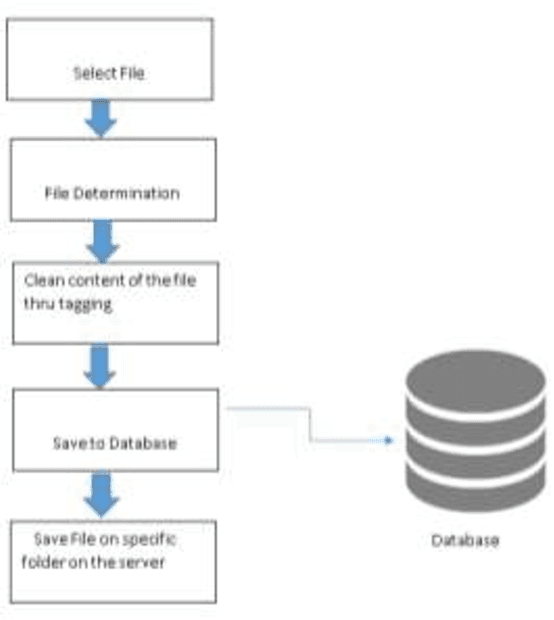
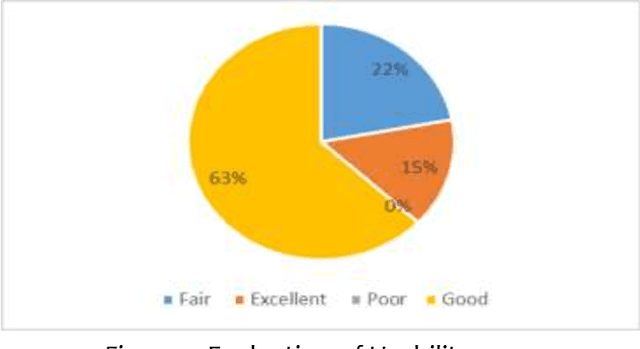
The Web Based File Clustering and Indexing for Mindoro State University aim to organize data circulated over the Web into groups or collections to facilitate data availability and access and at the same time meet user preferences. The main benefits include increasing Web information accessibility, understanding users navigation behavior, improving information retrieval and content delivery on the Web. Web based file clustering could help in reaching the required documents that the user is searching for. In this paper a novel approach has been introduced for search results clustering that is based on the semantics of the retrieved documents rather than the syntax of the terms in those documents. Data clustering was used to improve the information retrieval from the collection of documents. Data were processed and analyzed using SPSS where the instrument was evaluated to test the reliability and validity of the measures used. Evaluation was based on a Likert scale of Excellent, Good, Fair, and Poor as described for the selected quality characteristics.
* 11 pages, 9 figures, 1 table
Computing Nash Equilibria in Multiplayer DAG-Structured Stochastic Games with Persistent Imperfect Information
Oct 26, 2020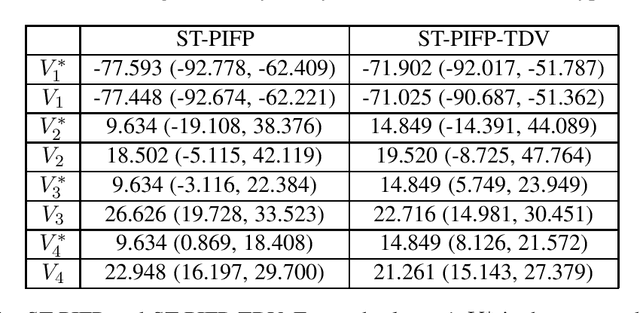
Many important real-world settings contain multiple players interacting over an unknown duration with probabilistic state transitions, and are naturally modeled as stochastic games. Prior research on algorithms for stochastic games has focused on two-player zero-sum games, games with perfect information, and games with imperfect-information that is local and does not extend between game states. We present an algorithm for approximating Nash equilibrium in multiplayer general-sum stochastic games with persistent imperfect information that extends throughout game play. We experiment on a 4-player imperfect-information naval strategic planning scenario. Using a new procedure, we are able to demonstrate that our algorithm computes a strategy that closely approximates Nash equilibrium in this game.
Quantum Accelerated Estimation of Algorithmic Information
Jun 01, 2020
In this research we present a quantum circuit for estimating algorithmic information metrics like the universal prior distribution. This accelerates inferring algorithmic structure in data for discovering causal generative models. The computation model is restricted in time and space resources to make it computable in approximating the target metrics. A classical exhaustive enumeration is shown for a few examples. The precise quantum circuit design that allows executing a superposition of automata is presented. As a use-case, an application framework for experimenting on DNA sequences for meta-biology is proposed. To our knowledge, this is the first time approximating algorithmic information is implemented for quantum computation. Our implementation on the OpenQL quantum programming language and the QX Simulator is copy-left and can be found on https://github.com/Advanced-Research-Centre/QuBio.
Emergent cooperation through mutual information maximization
Jun 21, 2020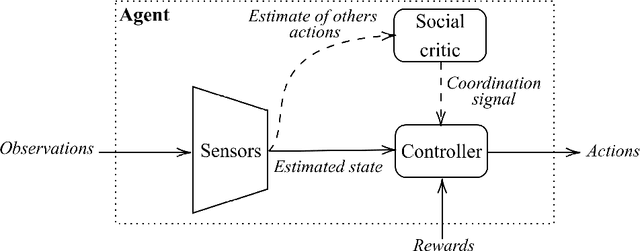
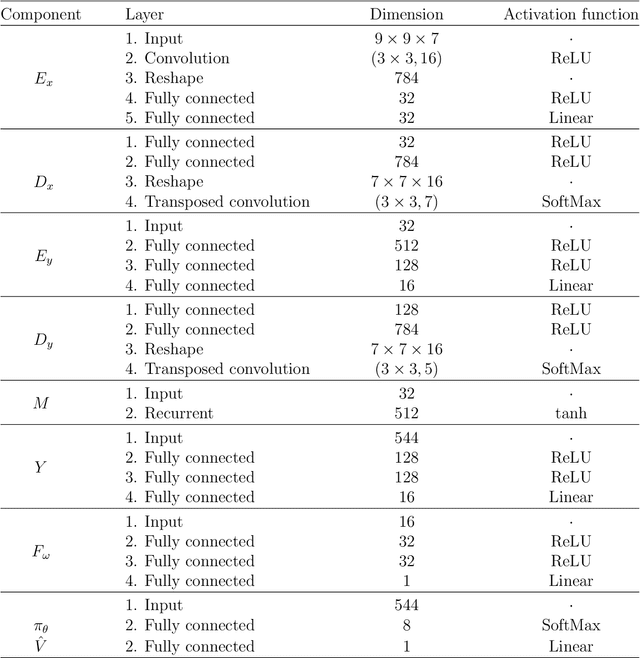

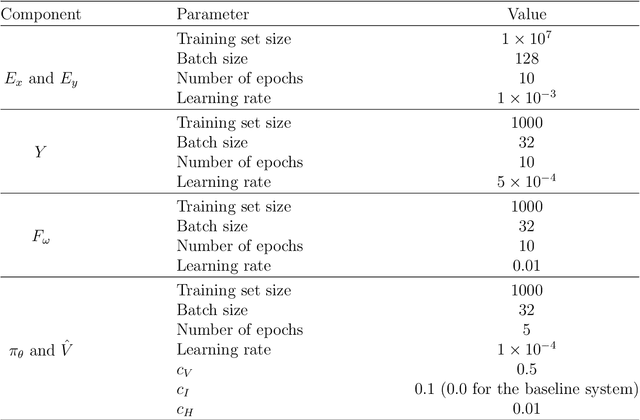
With artificial intelligence systems becoming ubiquitous in our society, its designers will soon have to start to consider its social dimension, as many of these systems will have to interact among them to work efficiently. With this in mind, we propose a decentralized deep reinforcement learning algorithm for the design of cooperative multi-agent systems. The algorithm is based on the hypothesis that highly correlated actions are a feature of cooperative systems, and hence, we propose the insertion of an auxiliary objective of maximization of the mutual information between the actions of agents in the learning problem. Our system is applied to a social dilemma, a problem whose optimal solution requires that agents cooperate to maximize a macroscopic performance function despite the divergent individual objectives of each agent. By comparing the performance of the proposed system to a system without the auxiliary objective, we conclude that the maximization of mutual information among agents promotes the emergence of cooperation in social dilemmas.
Faster Learned Sparse Retrieval with Guided Traversal
Apr 24, 2022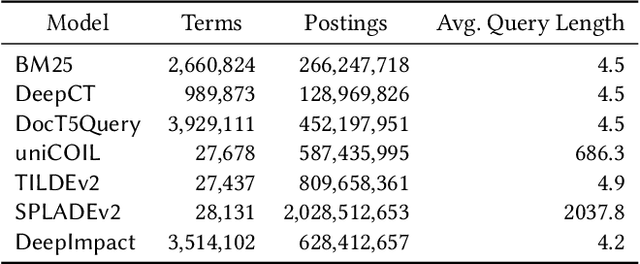
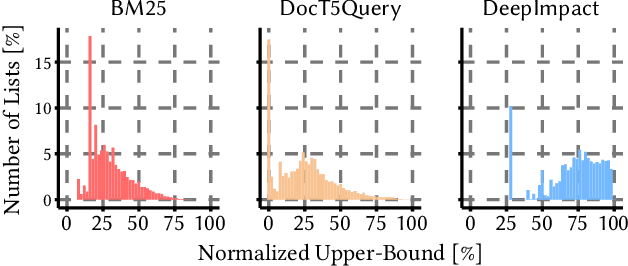
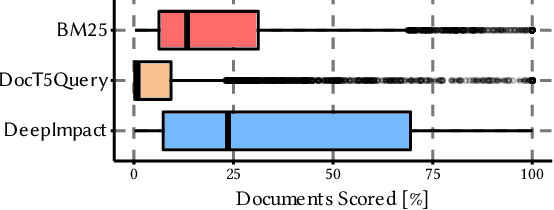
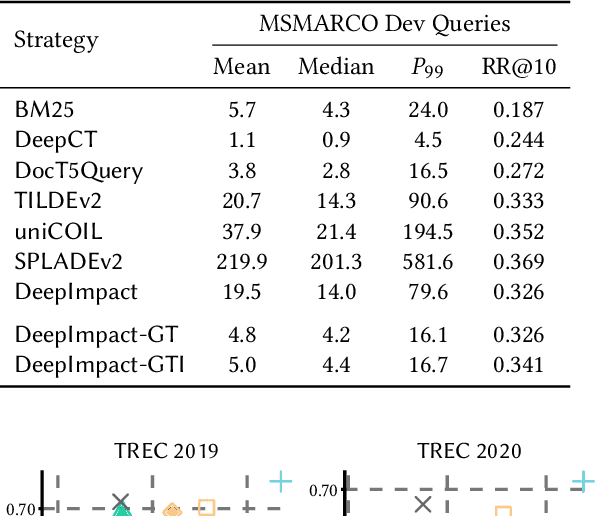
Neural information retrieval architectures based on transformers such as BERT are able to significantly improve system effectiveness over traditional sparse models such as BM25. Though highly effective, these neural approaches are very expensive to run, making them difficult to deploy under strict latency constraints. To address this limitation, recent studies have proposed new families of learned sparse models that try to match the effectiveness of learned dense models, while leveraging the traditional inverted index data structure for efficiency. Current learned sparse models learn the weights of terms in documents and, sometimes, queries; however, they exploit different vocabulary structures, document expansion techniques, and query expansion strategies, which can make them slower than traditional sparse models such as BM25. In this work, we propose a novel indexing and query processing technique that exploits a traditional sparse model's "guidance" to efficiently traverse the index, allowing the more effective learned model to execute fewer scoring operations. Our experiments show that our guided processing heuristic is able to boost the efficiency of the underlying learned sparse model by a factor of four without any measurable loss of effectiveness.
Rotationally Equivariant 3D Object Detection
Apr 28, 2022

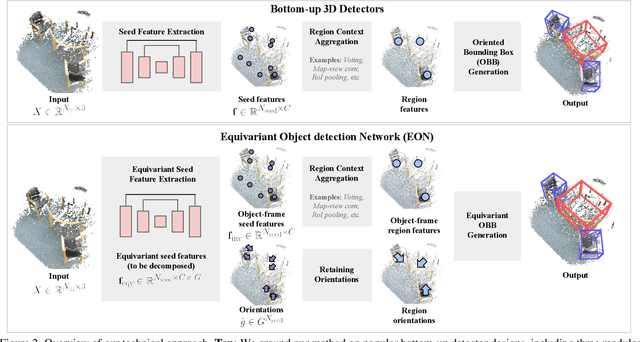
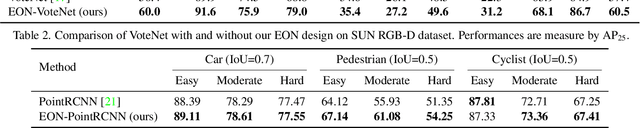
Rotation equivariance has recently become a strongly desired property in the 3D deep learning community. Yet most existing methods focus on equivariance regarding a global input rotation while ignoring the fact that rotation symmetry has its own spatial support. Specifically, we consider the object detection problem in 3D scenes, where an object bounding box should be equivariant regarding the object pose, independent of the scene motion. This suggests a new desired property we call object-level rotation equivariance. To incorporate object-level rotation equivariance into 3D object detectors, we need a mechanism to extract equivariant features with local object-level spatial support while being able to model cross-object context information. To this end, we propose Equivariant Object detection Network (EON) with a rotation equivariance suspension design to achieve object-level equivariance. EON can be applied to modern point cloud object detectors, such as VoteNet and PointRCNN, enabling them to exploit object rotation symmetry in scene-scale inputs. Our experiments on both indoor scene and autonomous driving datasets show that significant improvements are obtained by plugging our EON design into existing state-of-the-art 3D object detectors.
Computer Science Named Entity Recognition in the Open Research Knowledge Graph
Mar 28, 2022
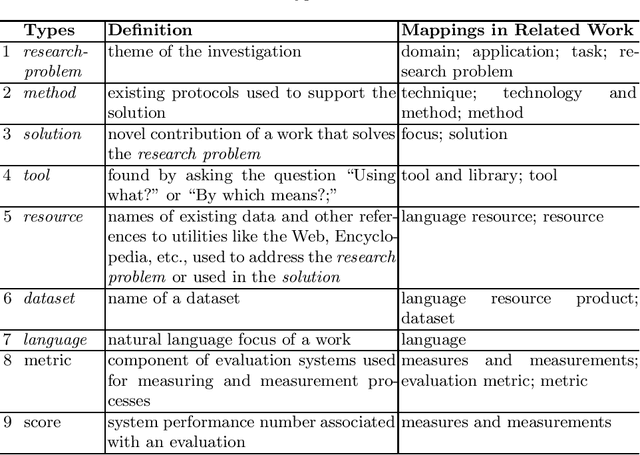
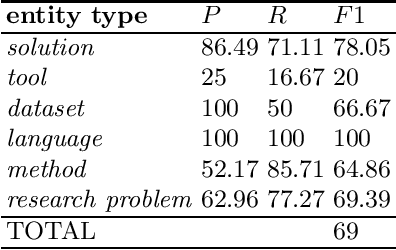
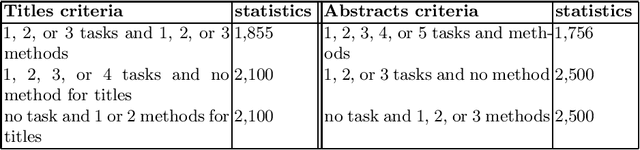
Domain-specific named entity recognition (NER) on Computer Science (CS) scholarly articles is an information extraction task that is arguably more challenging for the various annotation aims that can beset the task and has been less studied than NER in the general domain. Given that significant progress has been made on NER, we believe that scholarly domain-specific NER will receive increasing attention in the years to come. Currently, progress on CS NER -- the focus of this work -- is hampered in part by its recency and the lack of a standardized annotation aim for scientific entities/terms. This work proposes a standardized task by defining a set of seven contribution-centric scholarly entities for CS NER viz., research problem, solution, resource, language, tool, method, and dataset. Following which, its main contributions are: combines existing CS NER resources that maintain their annotation focus on the set or subset of contribution-centric scholarly entities we consider; further, noting the need for big data to train neural NER models, this work additionally supplies thousands of contribution-centric entity annotations from article titles and abstracts, thus releasing a cumulative large novel resource for CS NER; and, finally, trains a sequence labeling CS NER model inspired after state-of-the-art neural architectures from the general domain NER task. Throughout the work, several practical considerations are made which can be useful to information technology designers of the digital libraries.
Lagrangian PINNs: A causality-conforming solution to failure modes of physics-informed neural networks
May 05, 2022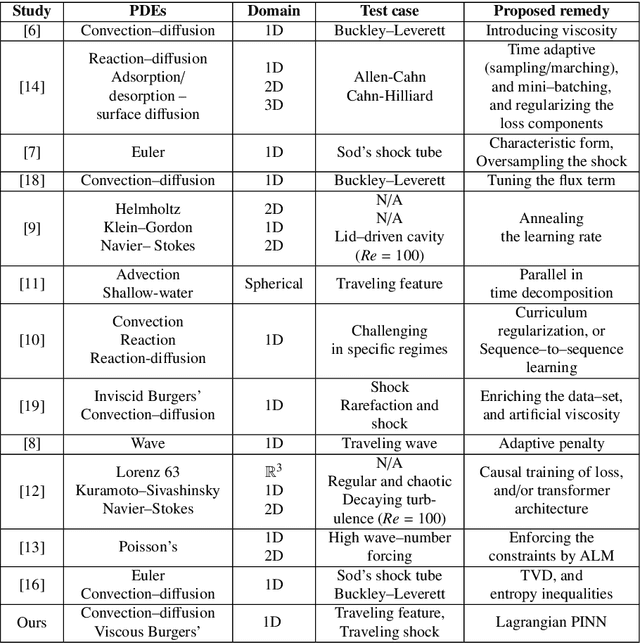
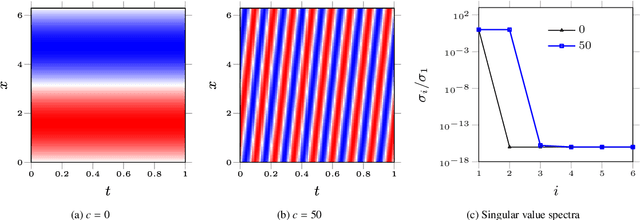
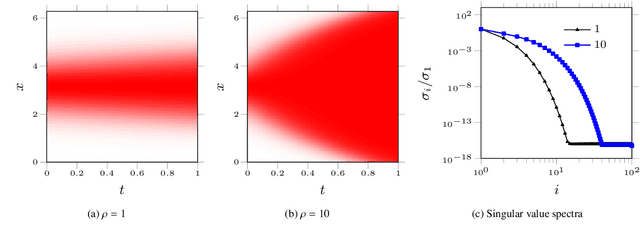
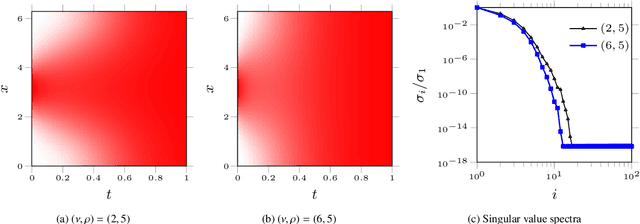
Physics-informed neural networks (PINNs) leverage neural-networks to find the solutions of partial differential equation (PDE)-constrained optimization problems with initial conditions and boundary conditions as soft constraints. These soft constraints are often considered to be the sources of the complexity in the training phase of PINNs. Here, we demonstrate that the challenge of training (i) persists even when the boundary conditions are strictly enforced, and (ii) is closely related to the Kolmogorov n-width associated with problems demonstrating transport, convection, traveling waves, or moving fronts. Given this realization, we describe the mechanism underlying the training schemes such as those used in eXtended PINNs (XPINN), curriculum regularization, and sequence-to-sequence learning. For an important category of PDEs, i.e., governed by non-linear convection-diffusion equation, we propose reformulating PINNs on a Lagrangian frame of reference, i.e., LPINNs, as a PDE-informed solution. A parallel architecture with two branches is proposed. One branch solves for the state variables on the characteristics, and the second branch solves for the low-dimensional characteristics curves. The proposed architecture conforms to the causality innate to the convection, and leverages the direction of travel of the information in the domain. Finally, we demonstrate that the loss landscapes of LPINNs are less sensitive to the so-called "complexity" of the problems, compared to those in the traditional PINNs in the Eulerian framework.
A Rich Recipe Representation as Plan to Support Expressive Multi Modal Queries on Recipe Content and Preparation Process
Mar 31, 2022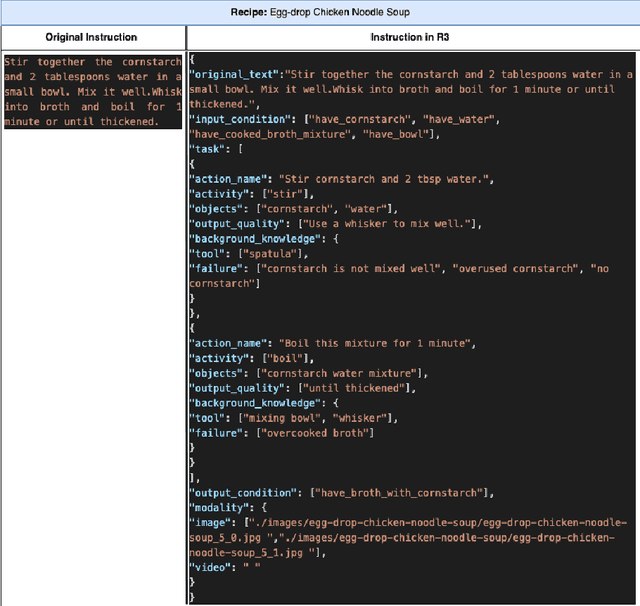
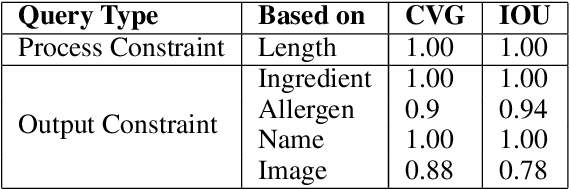
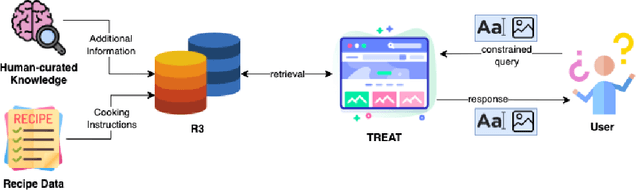
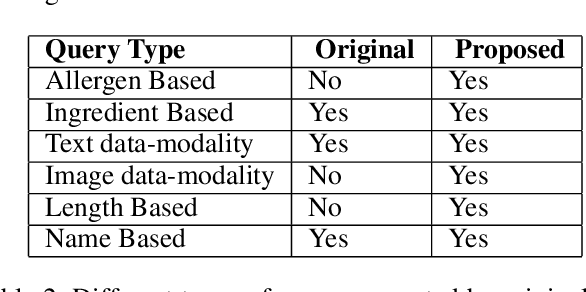
Food is not only a basic human necessity but also a key factor driving a society's health and economic well-being. As a result, the cooking domain is a popular use-case to demonstrate decision-support (AI) capabilities in service of benefits like precision health with tools ranging from information retrieval interfaces to task-oriented chatbots. An AI here should understand concepts in the food domain (e.g., recipes, ingredients), be tolerant to failures encountered while cooking (e.g., browning of butter), handle allergy-based substitutions, and work with multiple data modalities (e.g. text and images). However, the recipes today are handled as textual documents which makes it difficult for machines to read, reason and handle ambiguity. This demands a need for better representation of the recipes, overcoming the ambiguity and sparseness that exists in the current textual documents. In this paper, we discuss the construction of a machine-understandable rich recipe representation (R3), in the form of plans, from the recipes available in natural language. R3 is infused with additional knowledge such as information about allergens and images of ingredients, possible failures and tips for each atomic cooking step. To show the benefits of R3, we also present TREAT, a tool for recipe retrieval which uses R3 to perform multi-modal reasoning on the recipe's content (plan objects - ingredients and cooking tools), food preparation process (plan actions and time), and media type (image, text). R3 leads to improved retrieval efficiency and new capabilities that were hither-to not possible in textual representation.
Unsupervised Spatial-spectral Hyperspectral Image Reconstruction and Clustering with Diffusion Geometry
Apr 28, 2022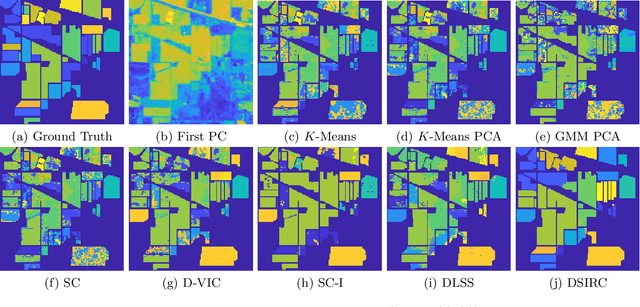
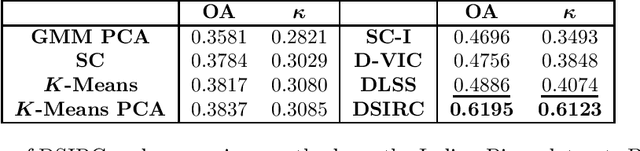
Hyperspectral images, which store a hundred or more spectral bands of reflectance, have become an important data source in natural and social sciences. Hyperspectral images are often generated in large quantities at a relatively coarse spatial resolution. As such, unsupervised machine learning algorithms incorporating known structure in hyperspectral imagery are needed to analyze these images automatically. This work introduces the Spatial-Spectral Image Reconstruction and Clustering with Diffusion Geometry (DSIRC) algorithm for partitioning highly mixed hyperspectral images. DSIRC reduces measurement noise through a shape-adaptive reconstruction procedure. In particular, for each pixel, DSIRC locates spectrally correlated pixels within a data-adaptive spatial neighborhood and reconstructs that pixel's spectral signature using those of its neighbors. DSIRC then locates high-density, high-purity pixels far in diffusion distance (a data-dependent distance metric) from other high-density, high-purity pixels and treats these as cluster exemplars, giving each a unique label. Non-modal pixels are assigned the label of their diffusion distance-nearest neighbor of higher density and purity that is already labeled. Strong numerical results indicate that incorporating spatial information through image reconstruction substantially improves the performance of pixel-wise clustering.