 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mutual Information for Explainable Deep Learning of Multiscale Systems
Sep 07, 2020
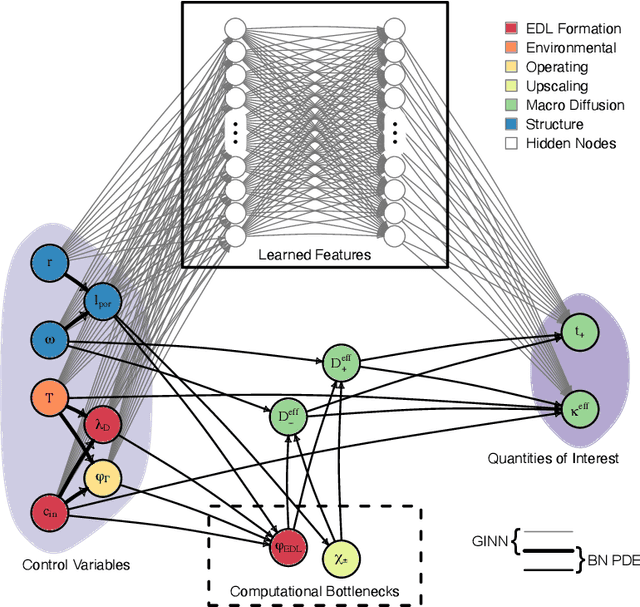
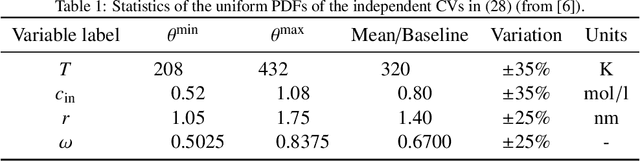
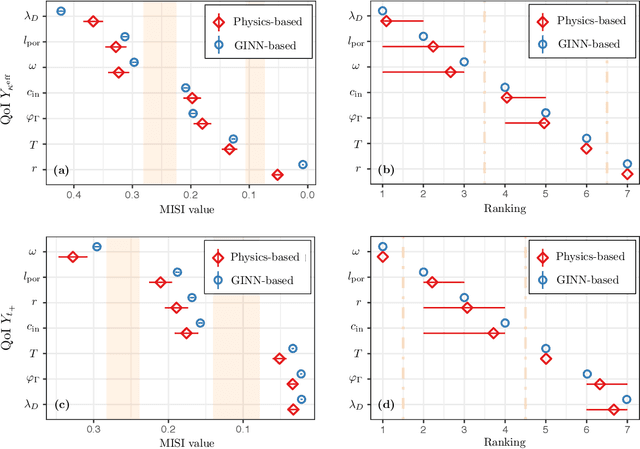
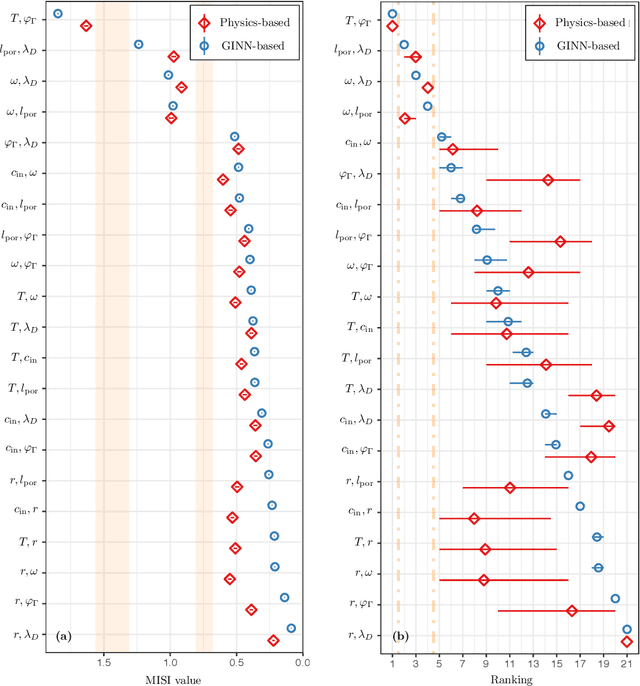
Timely completion of design cycles for multiscale and multiphysics systems ranging from consumer electronics to hypersonic vehicles relies on rapid simulation-based prototyping. The latter typically involves high-dimensional spaces of possibly correlated control variables (CVs) and quantities of interest (QoIs) with non-Gaussian and/or multimodal distributions. We develop a model-agnostic, moment-independent global sensitivity analysis (GSA) that relies on differential mutual information to rank the effects of CVs on QoIs. Large amounts of data, which are necessary to rank CVs with confidence, are cheaply generated by a deep neural network (DNN) surrogate model of the underlying process. The DNN predictions are made explainable by the GSA so that the DNN can be deployed to close design loops. Our information-theoretic framework is compatible with a wide variety of black-box models. Its application to multiscale supercapacitor design demonstrates that the CV rankings facilitated by a domain-aware Graph-Informed Neural Network are better resolved than their counterparts obtained with a physics-based model for a fixed computational budget. Consequently, our information-theoretic GSA provides an "outer loop" for accelerated product design by identifying the most and least sensitive input directions and performing subsequent optimization over appropriately reduced parameter subspaces.
Discriminative Supervised Subspace Learning for Cross-modal Retrieval
Jan 26, 2022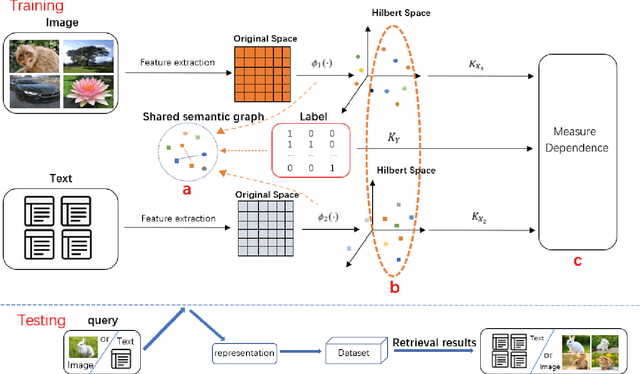
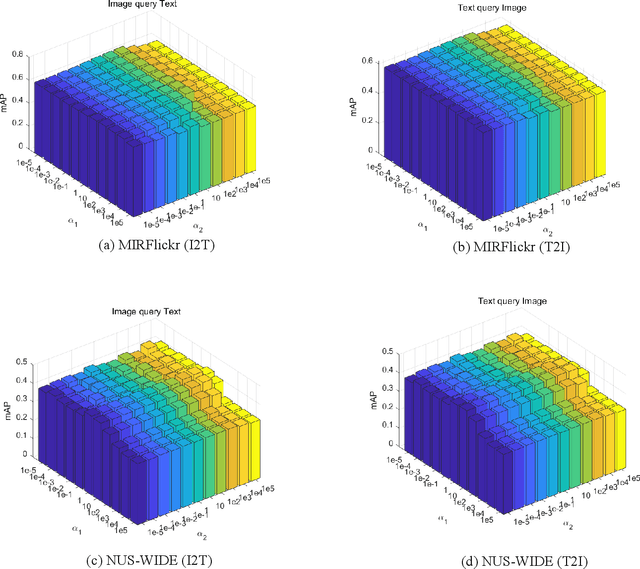
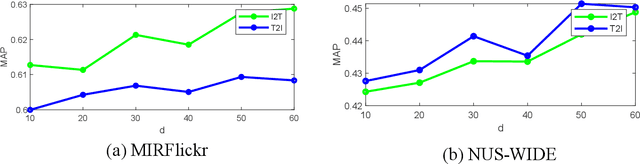
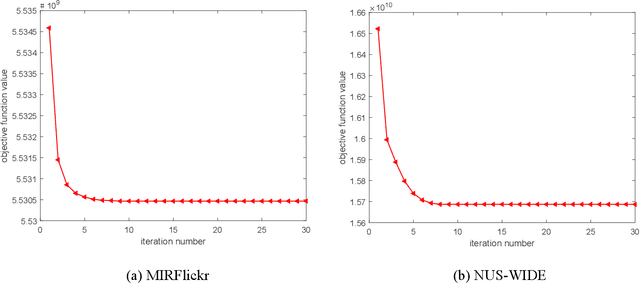
Nowadays the measure between heterogeneous data is still an open problem for cross-modal retrieval. The core of cross-modal retrieval is how to measure the similarity between different types of data. Many approaches have been developed to solve the problem. As one of the mainstream, approaches based on subspace learning pay attention to learning a common subspace where the similarity among multi-modal data can be measured directly. However, many of the existing approaches only focus on learning a latent subspace. They ignore the full use of discriminative information so that the semantically structural information is not well preserved. Therefore satisfactory results can not be achieved as expected. We in this paper propose a discriminative supervised subspace learning for cross-modal retrieval(DS2L), to make full use of discriminative information and better preserve the semantically structural information. Specifically, we first construct a shared semantic graph to preserve the semantic structure within each modality. Subsequently, the Hilbert-Schmidt Independence Criterion(HSIC) is introduced to preserve the consistence between feature-similarity and semantic-similarity of samples. Thirdly, we introduce a similarity preservation term, thus our model can compensate for the shortcomings of insufficient use of discriminative data and better preserve the semantically structural information within each modality. The experimental results obtained on three well-known benchmark datasets demonstrate the effectiveness and competitiveness of the proposed method against the compared classic subspace learning approaches.
Semi-supervised Learning on Large Graphs: is Poisson Learning a Game-Changer?
Feb 28, 2022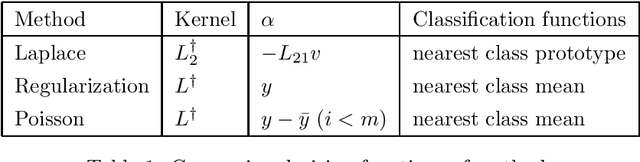
We explain Poisson learning on graph-based semi-supervised learning to see if it could avoid the problem of global information loss problem as Laplace-based learning methods on large graphs. From our analysis, Poisson learning is simply Laplace regularization with thresholding, cannot overcome the problem.
Pixel2Mesh++: 3D Mesh Generation and Refinement from Multi-View Images
Apr 21, 2022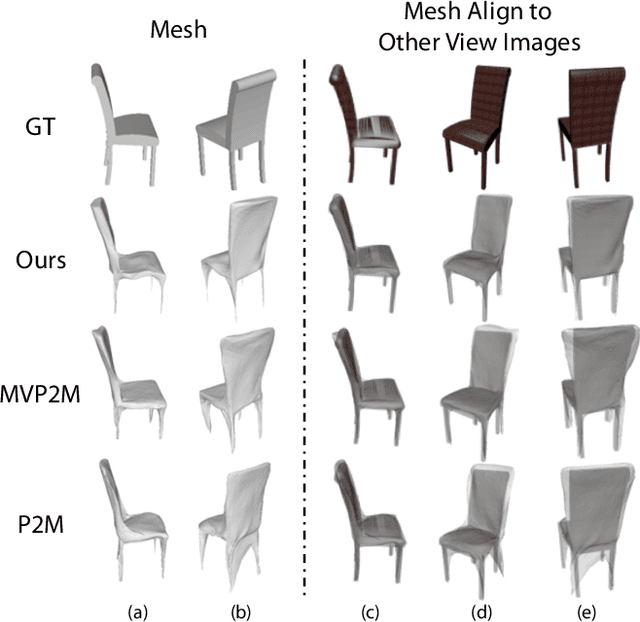
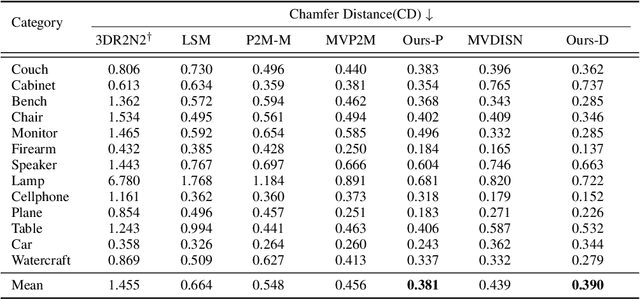
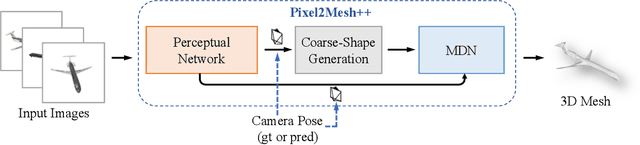
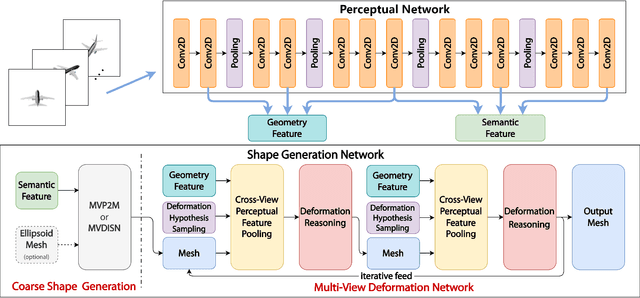
We study the problem of shape generation in 3D mesh representation from a small number of color images with or without camera poses. While many previous works learn to hallucinate the shape directly from priors, we adopt to further improve the shape quality by leveraging cross-view information with a graph convolution network. Instead of building a direct mapping function from images to 3D shape, our model learns to predict series of deformations to improve a coarse shape iteratively. Inspired by traditional multiple view geometry methods, our network samples nearby area around the initial mesh's vertex locations and reasons an optimal deformation using perceptual feature statistics built from multiple input images. Extensive experiments show that our model produces accurate 3D shapes that are not only visually plausible from the input perspectives, but also well aligned to arbitrary viewpoints. With the help of physically driven architecture, our model also exhibits generalization capability across different semantic categories, and the number of input images. Model analysis experiments show that our model is robust to the quality of the initial mesh and the error of camera pose, and can be combined with a differentiable renderer for test-time optimization.
A Masked Image Reconstruction Network for Document-level Relation Extraction
Apr 21, 2022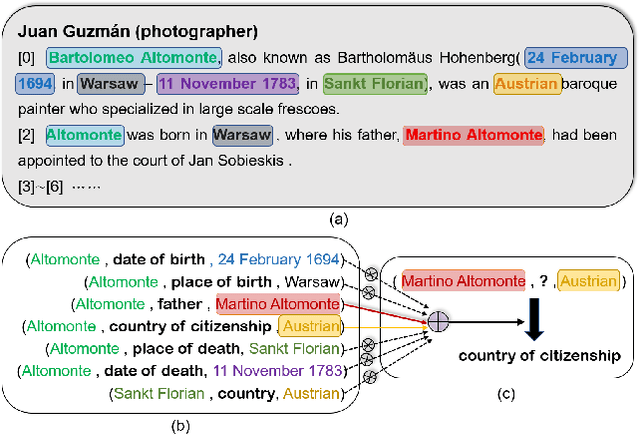
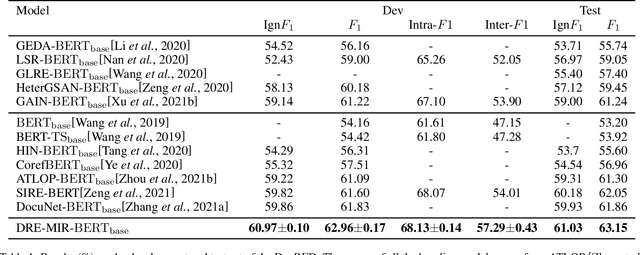
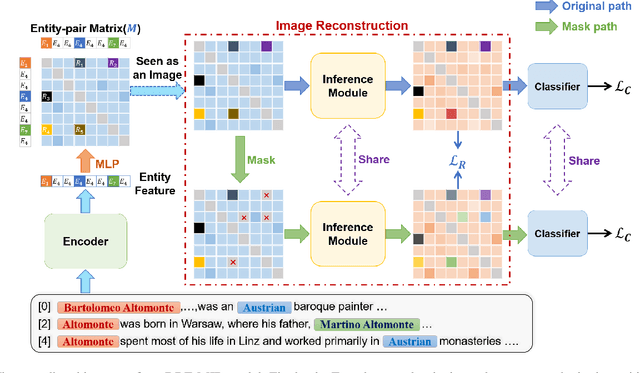
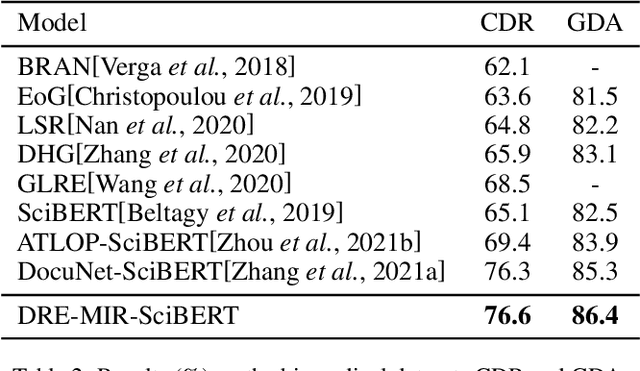
Document-level relation extraction aims to extract relations among entities within a document. Compared with its sentence-level counterpart, Document-level relation extraction requires inference over multiple sentences to extract complex relational triples. Previous research normally complete reasoning through information propagation on the mention-level or entity-level document-graphs, regardless of the correlations between the relationships. In this paper, we propose a novel Document-level Relation Extraction model based on a Masked Image Reconstruction network (DRE-MIR), which models inference as a masked image reconstruction problem to capture the correlations between relationships. Specifically, we first leverage an encoder module to get the features of entities and construct the entity-pair matrix based on the features. After that, we look on the entity-pair matrix as an image and then randomly mask it and restore it through an inference module to capture the correlations between the relationships. We evaluate our model on three public document-level relation extraction datasets, i.e. DocRED, CDR, and GDA. Experimental results demonstrate that our model achieves state-of-the-art performance on these three datasets and has excellent robustness against the noises during the inference process.
pysamoo: Surrogate-Assisted Multi-Objective Optimization in Python
Apr 12, 2022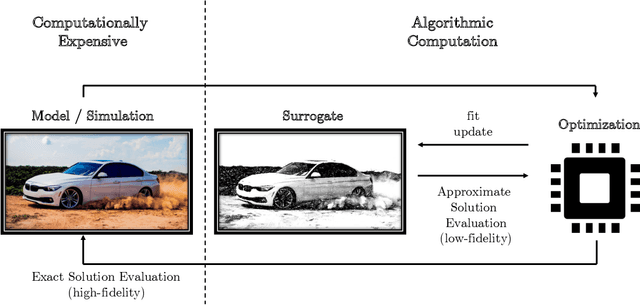
Significant effort has been made to solve computationally expensive optimization problems in the past two decades, and various optimization methods incorporating surrogates into optimization have been proposed. However, most optimization toolboxes do not consist of ready-to-run algorithms for computationally expensive problems, especially in combination with other key requirements, such as handling multiple conflicting objectives or constraints. Thus, the lack of appropriate software packages has become a bottleneck for solving real-world applications. The proposed framework, pysamoo, addresses these shortcomings of existing optimization frameworks and provides multiple optimization methods for handling problems involving time-consuming evaluation functions. The framework extends the functionalities of pymoo, a popular and comprehensive toolbox for multi-objective optimization, and incorporates surrogates to support expensive function evaluations. The framework is available under the GNU Affero General Public License (AGPL) and is primarily designed for research purposes. For more information about pysamoo, readers are encouraged to visit: anyoptimization.com/projects/pysamoo.
Masked Autoencoders for Point Cloud Self-supervised Learning
Mar 13, 2022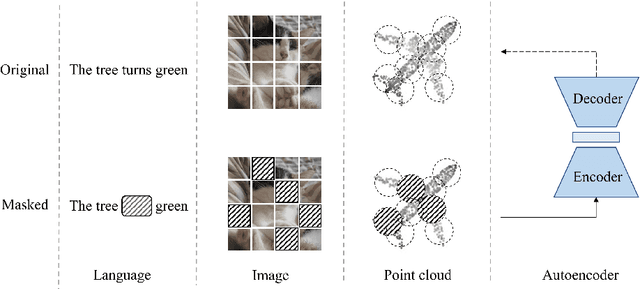
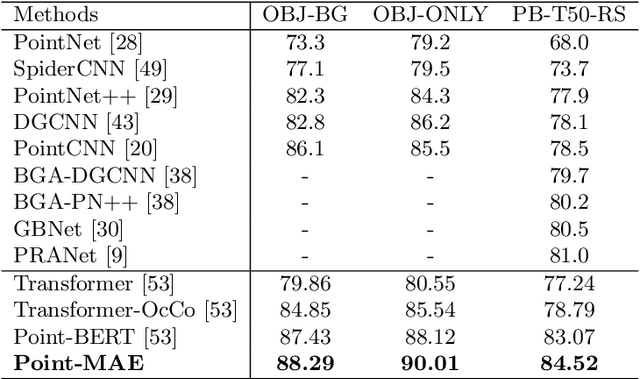
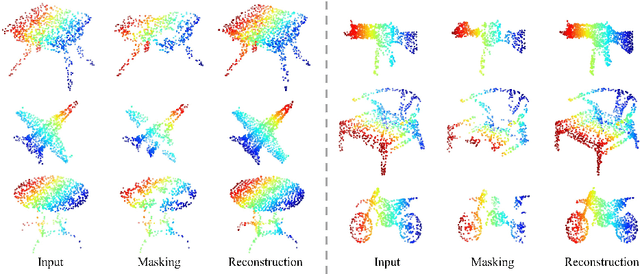
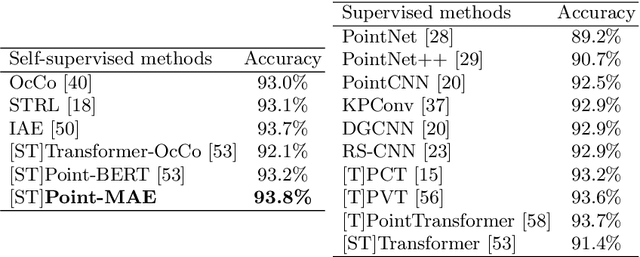
As a promising scheme of self-supervised learning, masked autoencoding has significantly advanced natural language processing and computer vision. Inspired by this, we propose a neat scheme of masked autoencoders for point cloud self-supervised learning, addressing the challenges posed by point cloud's properties, including leakage of location information and uneven information density. Concretely, we divide the input point cloud into irregular point patches and randomly mask them at a high ratio. Then, a standard Transformer based autoencoder, with an asymmetric design and a shifting mask tokens operation, learns high-level latent features from unmasked point patches, aiming to reconstruct the masked point patches. Extensive experiments show that our approach is efficient during pre-training and generalizes well on various downstream tasks. Specifically, our pre-trained models achieve 84.52\% accuracy on ScanObjectNN and 94.04% accuracy on ModelNet40, outperforming all the other self-supervised learning methods. We show with our scheme, a simple architecture entirely based on standard Transformers can surpass dedicated Transformer models from supervised learning. Our approach also advances state-of-the-art accuracies by 1.5%-2.3% in the few-shot object classification. Furthermore, our work inspires the feasibility of applying unified architectures from languages and images to the point cloud.
A Survey of Super-Resolution in Iris Biometrics with Evaluation of Dictionary-Learning
Mar 27, 2022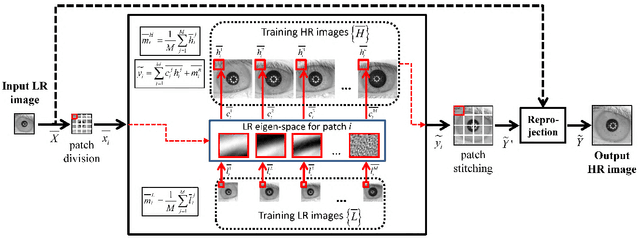
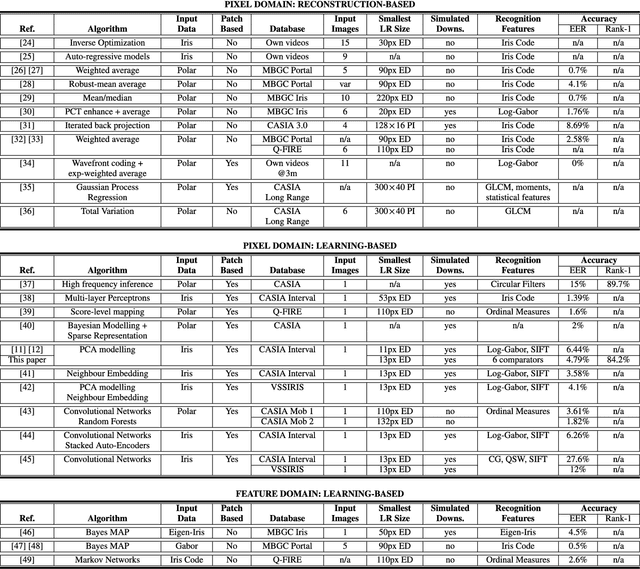
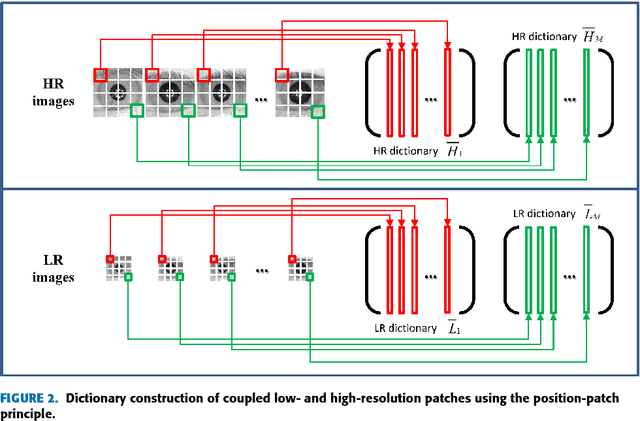

The lack of resolution has a negative impact on the performance of image-based biometrics. While many generic super-resolution methods have been proposed to restore low-resolution images, they usually aim to enhance their visual appearance. However, a visual enhancement of biometric images does not necessarily correlate with a better recognition performance. Reconstruction approaches need thus to incorporate specific information from the target biometric modality to effectively improve recognition. This paper presents a comprehensive survey of iris super-resolution approaches proposed in the literature. We have also adapted an Eigen-patches reconstruction method based on PCA Eigen-transformation of local image patches. The structure of the iris is exploited by building a patch-position dependent dictionary. In addition, image patches are restored separately, having their own reconstruction weights. This allows the solution to be locally optimized, helping to preserve local information. To evaluate the algorithm, we degraded high-resolution images from the CASIA Interval V3 database. Different restorations were considered, with 15x15 pixels being the smallest resolution. To the best of our knowledge, this is among the smallest resolutions employed in the literature. The framework is complemented with six public iris comparators, which were used to carry out biometric verification and identification experiments. Experimental results show that the proposed method significantly outperforms both bilinear and bicubic interpolation at very low-resolution. The performance of a number of comparators attains an impressive Equal Error Rate as low as 5%, and a Top-1 accuracy of 77-84% when considering iris images of only 15x15 pixels. These results clearly demonstrate the benefit of using trained super-resolution techniques to improve the quality of iris images prior to matching.
CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery
Feb 01, 2022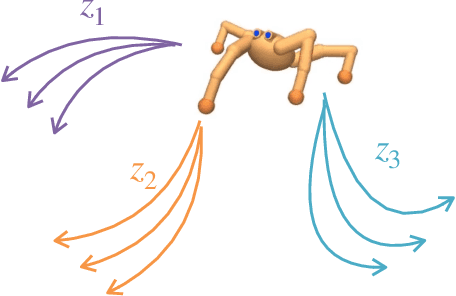
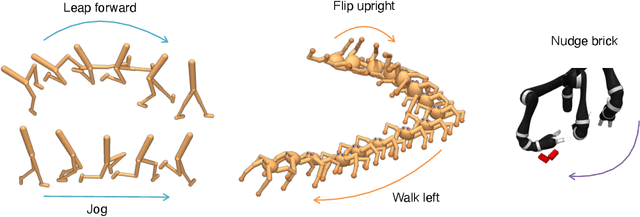

We introduce Contrastive Intrinsic Control (CIC), an algorithm for unsupervised skill discovery that maximizes the mutual information between skills and state transitions. In contrast to most prior approaches, CIC uses a decomposition of the mutual information that explicitly incentivizes diverse behaviors by maximizing state entropy. We derive a novel lower bound estimate for the mutual information which combines a particle estimator for state entropy to generate diverse behaviors and contrastive learning to distill these behaviors into distinct skills. We evaluate our algorithm on the Unsupervised Reinforcement Learning Benchmark, which consists of a long reward-free pre-training phase followed by a short adaptation phase to downstream tasks with extrinsic rewards. We find that CIC substantially improves over prior unsupervised skill discovery methods and outperforms the next leading overall exploration algorithm in terms of downstream task performance.
KeepAugment: A Simple Information-Preserving Data Augmentation Approach
Nov 23, 2020
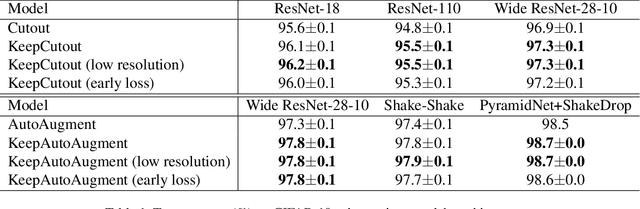
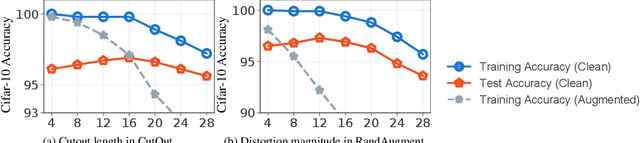
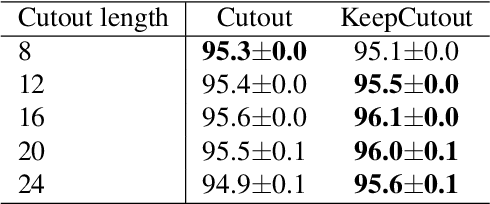
Data augmentation (DA) is an essential technique for training state-of-the-art deep learning systems. In this paper, we empirically show data augmentation might introduce noisy augmented examples and consequently hurt the performance on unaugmented data during inference. To alleviate this issue, we propose a simple yet highly effective approach, dubbed \emph{KeepAugment}, to increase augmented images fidelity. The idea is first to use the saliency map to detect important regions on the original images and then preserve these informative regions during augmentation. This information-preserving strategy allows us to generate more faithful training examples. Empirically, we demonstrate our method significantly improves on a number of prior art data augmentation schemes, e.g. AutoAugment, Cutout, random erasing, achieving promising results on image classification, semi-supervised image classification, multi-view multi-camera tracking and object detection.