 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generalizing Aggregation Functions in GNNs:High-Capacity GNNs via Nonlinear Neighborhood Aggregators
Feb 18, 2022


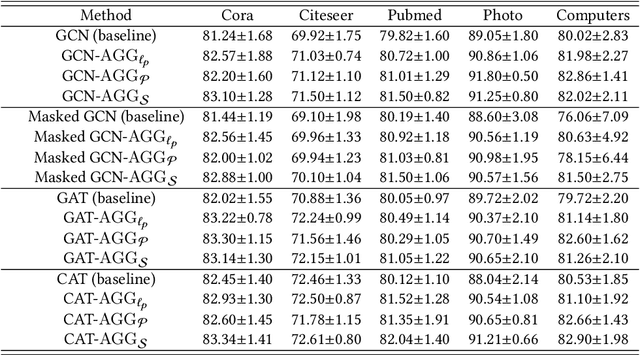

Graph neural networks (GNNs) have achieved great success in many graph learning tasks. The main aspect powering existing GNNs is the multi-layer network architecture to learn the nonlinear graph representations for the specific learning tasks. The core operation in GNNs is message propagation in which each node updates its representation by aggregating its neighbors' representations. Existing GNNs mainly adopt either linear neighborhood aggregation (mean,sum) or max aggregator in their message propagation. (1) For linear aggregators, the whole nonlinearity and network's capacity of GNNs are generally limited due to deeper GNNs usually suffer from over-smoothing issue. (2) For max aggregator, it usually fails to be aware of the detailed information of node representations within neighborhood. To overcome these issues, we re-think the message propagation mechanism in GNNs and aim to develop the general nonlinear aggregators for neighborhood information aggregation in GNNs. One main aspect of our proposed nonlinear aggregators is that they provide the optimally balanced aggregators between max and mean/sum aggregations. Thus, our aggregators can inherit both (i) high nonlinearity that increases network's capacity and (ii) detail-sensitivity that preserves the detailed information of representations together in GNNs' message propagation. Promising experiments on several datasets show the effectiveness of the proposed nonlinear aggregators.
A dataset of ant colonies motion trajectories in indoor and outdoor scenes for social cluster behavior study
Apr 09, 2022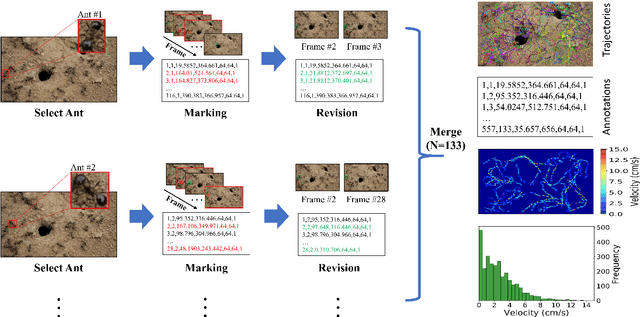
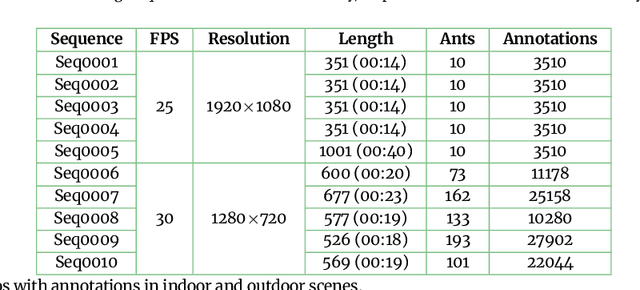
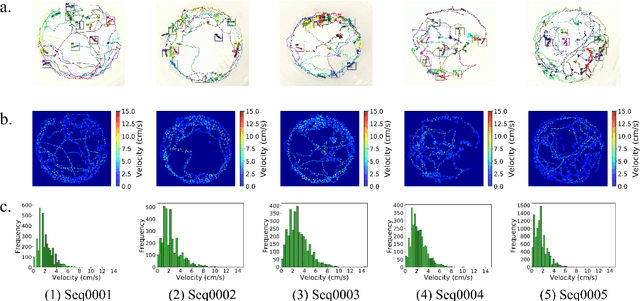
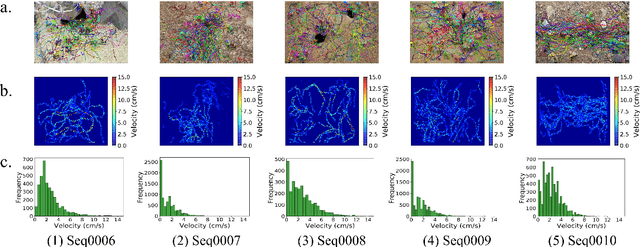
Motion and interaction of social insects (such as ants) have been studied by many researchers to understand the clustering mechanism. Most studies in the field of ant behavior have only focused on indoor environments, while outdoor environments are still underexplored. In this paper, we collect 10 videos of ant colonies from different indoor and outdoor scenes. And we develop an image sequence marking software named VisualMarkData, which enables us to provide annotations of ants in the video. In all 5354 frames, the location information and the identification number of each ant are recorded for a total of 712 ants and 114112 annotations. Moreover, we provide visual analysis tools to assess and validate the technical quality and reproducibility of our data. It is hoped that this dataset will contribute to a deeper exploration on the behavior of the ant colony.
Learning Weighting Map for Bit-Depth Expansion within a Rational Range
Apr 26, 2022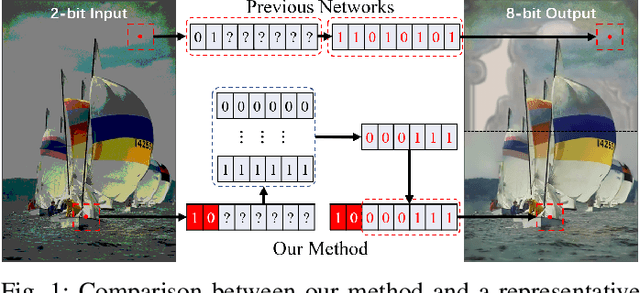


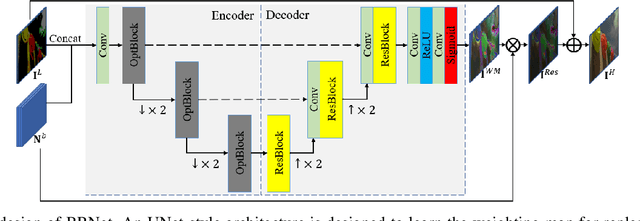
Bit-depth expansion (BDE) is one of the emerging technologies to display high bit-depth (HBD) image from low bit-depth (LBD) source. Existing BDE methods have no unified solution for various BDE situations, and directly learn a mapping for each pixel from LBD image to the desired value in HBD image, which may change the given high-order bits and lead to a huge deviation from the ground truth. In this paper, we design a bit restoration network (BRNet) to learn a weight for each pixel, which indicates the ratio of the replenished value within a rational range, invoking an accurate solution without modifying the given high-order bit information. To make the network adaptive for any bit-depth degradation, we investigate the issue in an optimization perspective and train the network under progressive training strategy for better performance. Moreover, we employ Wasserstein distance as a visual quality indicator to evaluate the difference of color distribution between restored image and the ground truth. Experimental results show our method can restore colorful images with fewer artifacts and false contours, and outperforms state-of-the-art methods with higher PSNR/SSIM results and lower Wasserstein distance. The source code will be made available at https://github.com/yuqing-liu-dut/bit-depth-expansion
I-AID: Identifying Actionable Information from Disaster-related Tweets
Aug 04, 2020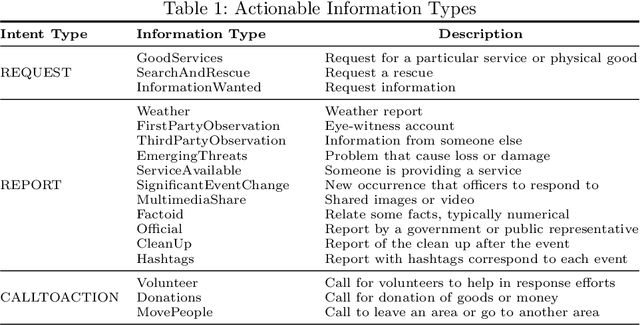
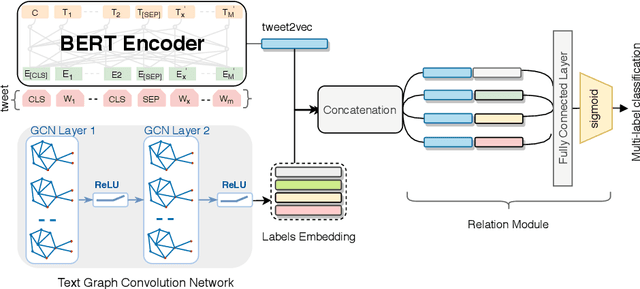
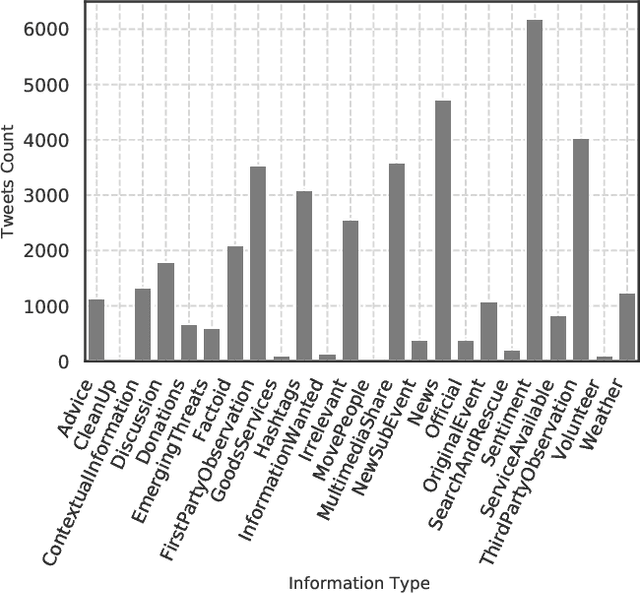
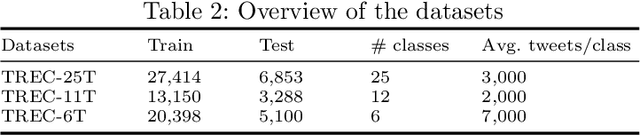
Social media data plays a significant role in modern disaster management by providing valuable data about affected people, donations, help requests, and advice. Recent studies highlight the need to filter information on social media into fine-grained content categories. However, identifying useful information from massive amounts of social media posts during a crisis is a challenging task. Automatically categorizing the information (e.g., reports on affected individuals, donations, and volunteers) contained in these posts is vital for their efficient handling and consumption by the communities affected and organizations concerned. In this paper, we propose a system, dubbed I-AID, to automatically filter tweets with critical or actionable information from the enormous volume of social media data. Our system combines state-of-the-art approaches to process and represents textual data in order to capture its underlying semantics. In particular, we use 1) Bidirectional Encoder Representations from Transformers (commonly known as, BERT) to learn a contextualized vector representation of a tweet, and 2) a graph-based architecture to compute semantic correlations between the entities and hashtags in tweets and their corresponding labels. We conducted our experiments on a real-world dataset of disaster-related tweets. Our experimental results indicate that our model outperforms state-of-the-art approaches baselines in terms of F1-score by +11%.
Self-Supervised Arbitrary-Scale Point Clouds Upsampling via Implicit Neural Representation
Apr 18, 2022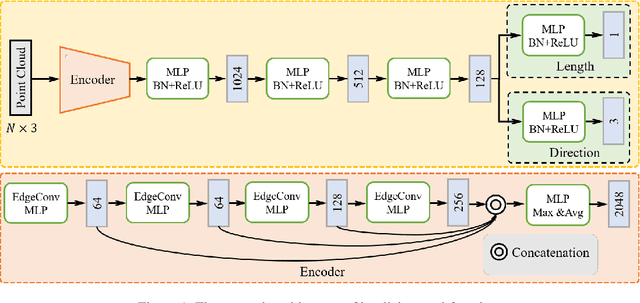
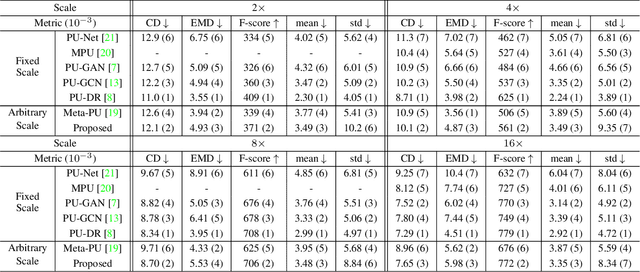
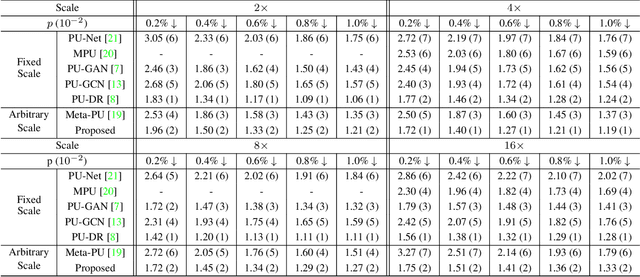
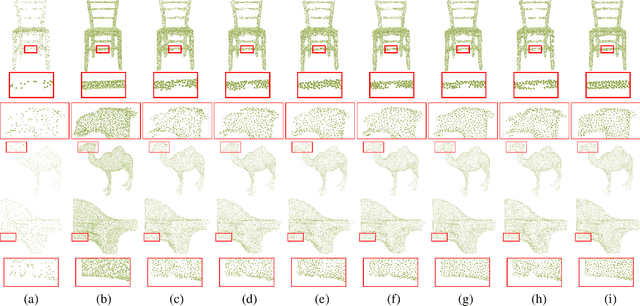
Point clouds upsampling is a challenging issue to generate dense and uniform point clouds from the given sparse input. Most existing methods either take the end-to-end supervised learning based manner, where large amounts of pairs of sparse input and dense ground-truth are exploited as supervision information; or treat up-scaling of different scale factors as independent tasks, and have to build multiple networks to handle upsampling with varying factors. In this paper, we propose a novel approach that achieves self-supervised and magnification-flexible point clouds upsampling simultaneously. We formulate point clouds upsampling as the task of seeking nearest projection points on the implicit surface for seed points. To this end, we define two implicit neural functions to estimate projection direction and distance respectively, which can be trained by two pretext learning tasks. Experimental results demonstrate that our self-supervised learning based scheme achieves competitive or even better performance than supervised learning based state-of-the-art methods. The source code is publicly available at https://github.com/xnowbzhao/sapcu.
Conditional Contrastive Learning with Kernel
Feb 14, 2022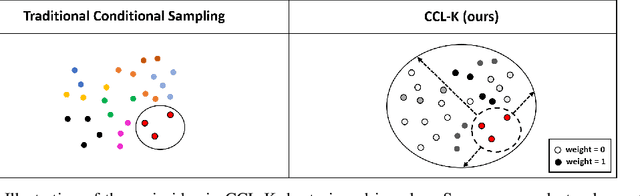



Conditional contrastive learning frameworks consider the conditional sampling procedure that constructs positive or negative data pairs conditioned on specific variables. Fair contrastive learning constructs negative pairs, for example, from the same gender (conditioning on sensitive information), which in turn reduces undesirable information from the learned representations; weakly supervised contrastive learning constructs positive pairs with similar annotative attributes (conditioning on auxiliary information), which in turn are incorporated into the representations. Although conditional contrastive learning enables many applications, the conditional sampling procedure can be challenging if we cannot obtain sufficient data pairs for some values of the conditioning variable. This paper presents Conditional Contrastive Learning with Kernel (CCL-K) that converts existing conditional contrastive objectives into alternative forms that mitigate the insufficient data problem. Instead of sampling data according to the value of the conditioning variable, CCL-K uses the Kernel Conditional Embedding Operator that samples data from all available data and assigns weights to each sampled data given the kernel similarity between the values of the conditioning variable. We conduct experiments using weakly supervised, fair, and hard negatives contrastive learning, showing CCL-K outperforms state-of-the-art baselines.
Distributed Neural Precoding for Hybrid mmWave MIMO Communications with Limited Feedback
Apr 18, 2022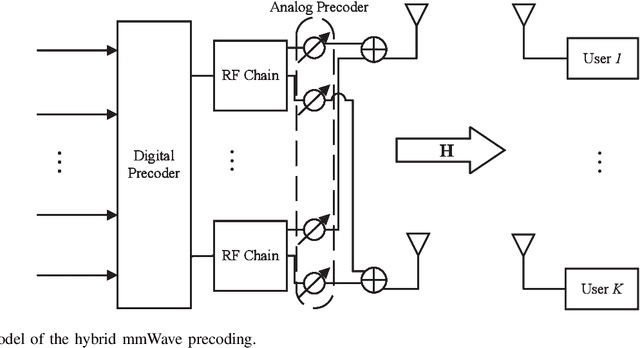
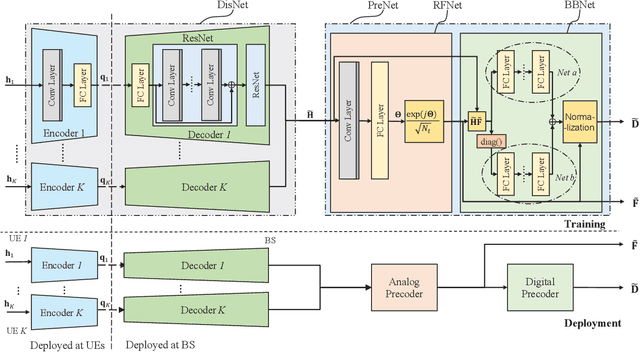
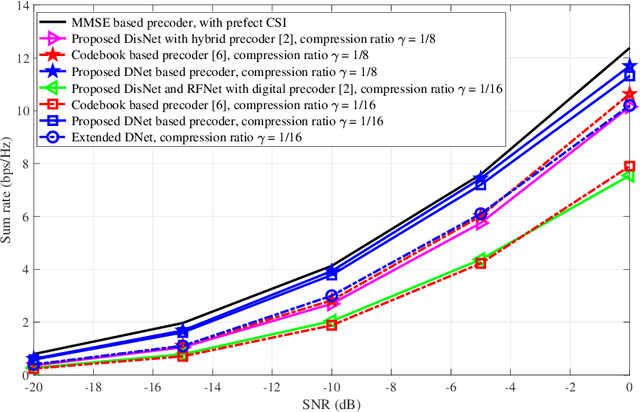
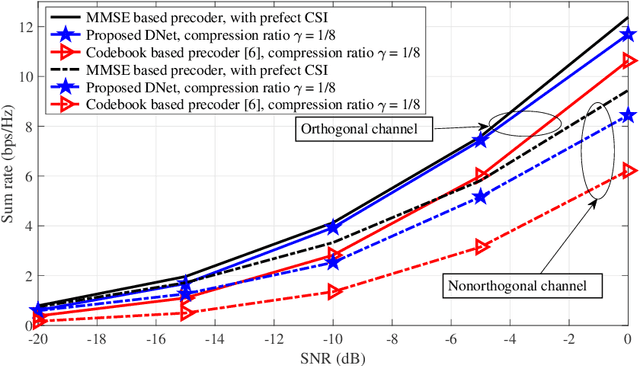
Hybrid precoding is a cost-efficient technique for millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) communications. This paper proposes a deep learning approach by using a distributed neural network for hybrid analog-and-digital precoding design with limited feedback. The proposed distributed neural precoding network, called DNet, is committed to achieving two objectives. First, the DNet realizes channel state information (CSI) compression with a distributed architecture of neural networks, which enables practical deployment on multiple users. Specifically, this neural network is composed of multiple independent sub-networks with the same structure and parameters, which reduces both the number of training parameters and network complexity. Secondly, DNet learns the calculation of hybrid precoding from reconstructed CSI from limited feedback. Different from existing black-box neural network design, the DNet is specifically designed according to the data form of the matrix calculation of hybrid precoding. Simulation results show that the proposed DNet significantly improves the performance up to nearly 50% compared to traditional limited feedback precoding methods under the tests with various CSI compression ratios.
Distributed Riemannian Optimization with Lazy Communication for Collaborative Geometric Estimation
Mar 02, 2022
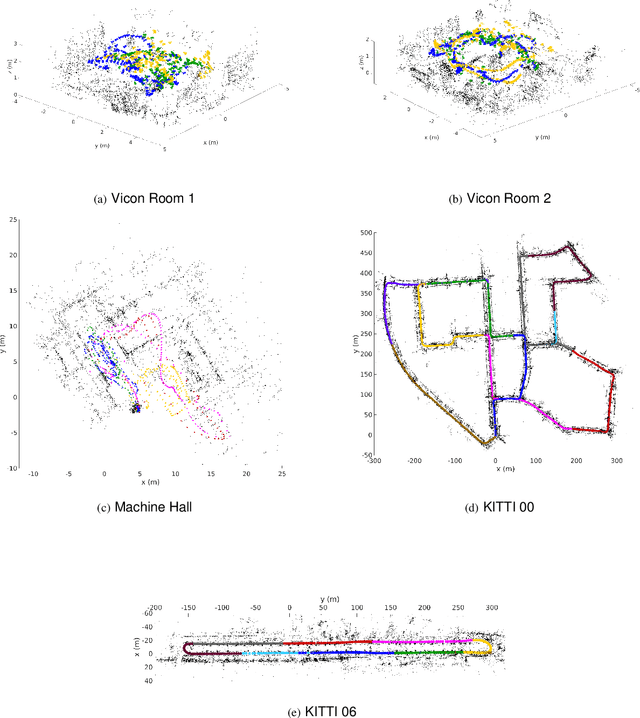


We present the first distributed optimization algorithm with lazy communication for collaborative geometric estimation, the backbone of modern collaborative simultaneous localization and mapping (SLAM) and structure-from-motion (SfM) applications. Our method allows agents to cooperatively reconstruct a shared geometric model on a central server by fusing individual observations, but without the need to transmit potentially sensitive information about the agents themselves (such as their locations). Furthermore, to alleviate the burden of communication during iterative optimization, we design a set of communication triggering conditions that enable agents to selectively upload local information that are useful to global optimization. Our approach thus achieves significant communication reduction with minimal impact on optimization performance. As our main theoretical contribution, we prove that our method converges to first-order critical points with a sublinear convergence rate. Numerical evaluations on bundle adjustment problems from collaborative SLAM and SfM datasets show that our method performs competitively against existing distributed techniques, while achieving up to 78% total communication reduction.
An Empirical Investigation of 3D Anomaly Detection and Segmentation
Mar 10, 2022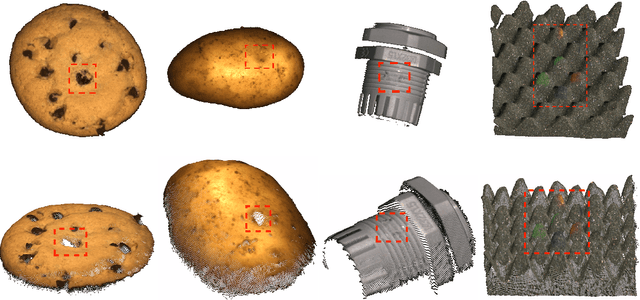

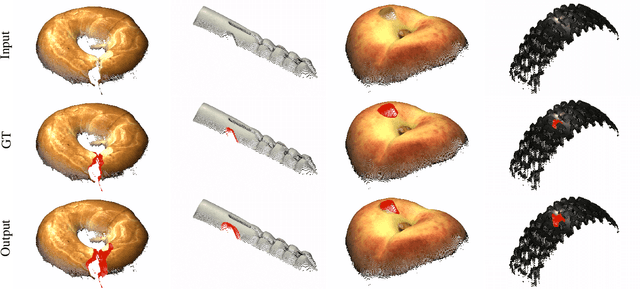
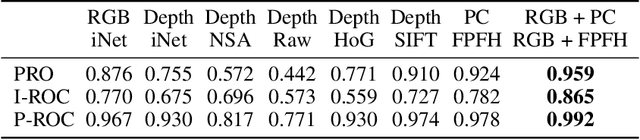
Anomaly detection and segmentation in images has made tremendous progress in recent years while 3D information has often been ignored. The objective of this paper is to further understand the benefit and role of 3D as opposed to color in image anomaly detection. Our study begins by presenting a surprising finding: standard color-only anomaly segmentation methods, when applied to 3D datasets, significantly outperform all current methods. On the other hand, we observe that color-only methods are insufficient for images containing geometric anomalies where shape cannot be unambiguously inferred from 2D. This suggests that better 3D methods are needed. We investigate different representations for 3D anomaly detection and discover that handcrafted orientation-invariant representations are unreasonably effective on this task. We uncover a simple 3D-only method that outperforms all recent approaches while not using deep learning, external pretraining datasets, or color information. As the 3D-only method cannot detect color and texture anomalies, we combine it with 2D color features, granting us the best current results by a large margin (Pixel-wise ROCAUC: 99.2%, PRO: 95.9% on MVTec 3D-AD). We conclude by discussing future challenges for 3D anomaly detection and segmentation.
GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors
Mar 14, 2022
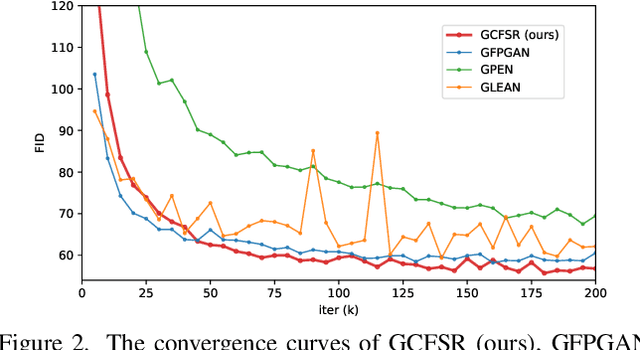

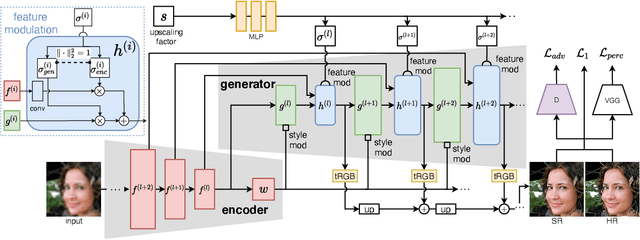
Face image super resolution (face hallucination) usually relies on facial priors to restore realistic details and preserve identity information. Recent advances can achieve impressive results with the help of GAN prior. They either design complicated modules to modify the fixed GAN prior or adopt complex training strategies to finetune the generator. In this work, we propose a generative and controllable face SR framework, called GCFSR, which can reconstruct images with faithful identity information without any additional priors. Generally, GCFSR has an encoder-generator architecture. Two modules called style modulation and feature modulation are designed for the multi-factor SR task. The style modulation aims to generate realistic face details and the feature modulation dynamically fuses the multi-level encoded features and the generated ones conditioned on the upscaling factor. The simple and elegant architecture can be trained from scratch in an end-to-end manner. For small upscaling factors (<=8), GCFSR can produce surprisingly good results with only adversarial loss. After adding L1 and perceptual losses, GCFSR can outperform state-of-the-art methods for large upscaling factors (16, 32, 64). During the test phase, we can modulate the generative strength via feature modulation by changing the conditional upscaling factor continuously to achieve various generative effects.