 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
May 06, 2022
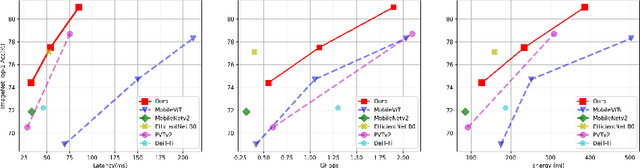
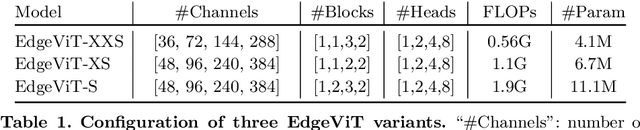
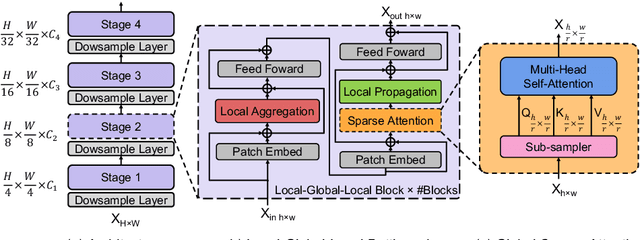
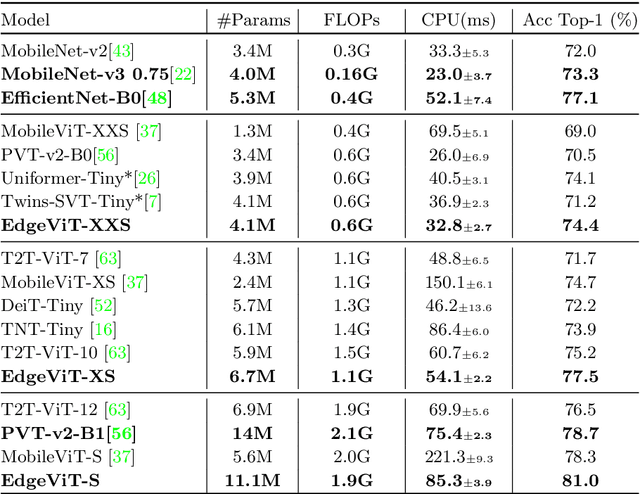
Self-attention based models such as vision transformers (ViTs) have emerged as a very competitive architecture alternative to convolutional neural networks (CNNs) in computer vision. Despite increasingly stronger variants with ever-higher recognition accuracies, due to the quadratic complexity of self-attention, existing ViTs are typically demanding in computation and model size. Although several successful design choices (e.g., the convolutions and hierarchical multi-stage structure) of prior CNNs have been reintroduced into recent ViTs, they are still not sufficient to meet the limited resource requirements of mobile devices. This motivates a very recent attempt to develop light ViTs based on the state-of-the-art MobileNet-v2, but still leaves a performance gap behind. In this work, pushing further along this under-studied direction we introduce EdgeViTs, a new family of light-weight ViTs that, for the first time, enable attention-based vision models to compete with the best light-weight CNNs in the tradeoff between accuracy and on-device efficiency. This is realized by introducing a highly cost-effective local-global-local (LGL) information exchange bottleneck based on optimal integration of self-attention and convolutions. For device-dedicated evaluation, rather than relying on inaccurate proxies like the number of FLOPs or parameters, we adopt a practical approach of focusing directly on on-device latency and, for the first time, energy efficiency. Specifically, we show that our models are Pareto-optimal when both accuracy-latency and accuracy-energy trade-offs are considered, achieving strict dominance over other ViTs in almost all cases and competing with the most efficient CNNs.
$π$BO: Augmenting Acquisition Functions with User Beliefs for Bayesian Optimization
Apr 23, 2022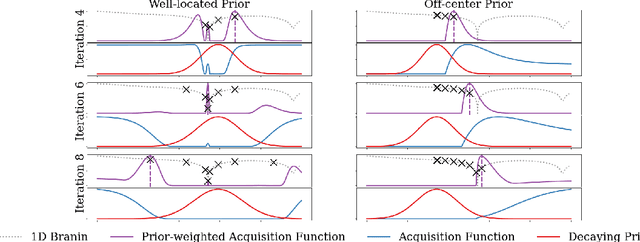
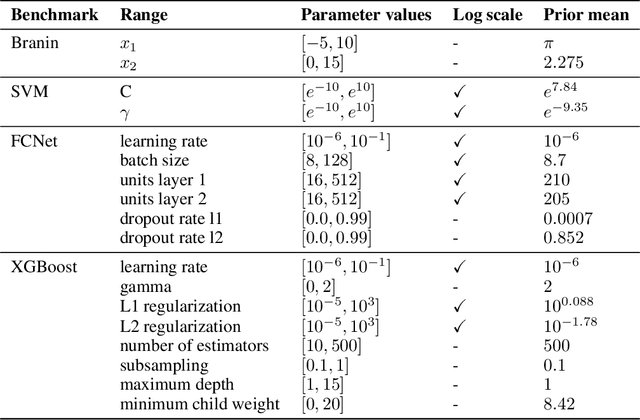
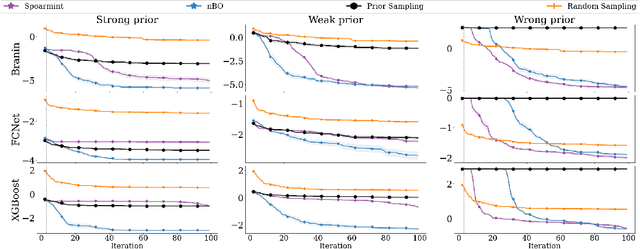

Bayesian optimization (BO) has become an established framework and popular tool for hyperparameter optimization (HPO) of machine learning (ML) algorithms. While known for its sample-efficiency, vanilla BO can not utilize readily available prior beliefs the practitioner has on the potential location of the optimum. Thus, BO disregards a valuable source of information, reducing its appeal to ML practitioners. To address this issue, we propose $\pi$BO, an acquisition function generalization which incorporates prior beliefs about the location of the optimum in the form of a probability distribution, provided by the user. In contrast to previous approaches, $\pi$BO is conceptually simple and can easily be integrated with existing libraries and many acquisition functions. We provide regret bounds when $\pi$BO is applied to the common Expected Improvement acquisition function and prove convergence at regular rates independently of the prior. Further, our experiments show that $\pi$BO outperforms competing approaches across a wide suite of benchmarks and prior characteristics. We also demonstrate that $\pi$BO improves on the state-of-the-art performance for a popular deep learning task, with a 12.5 $\times$ time-to-accuracy speedup over prominent BO approaches.
In Defense of Image Pre-Training for Spatiotemporal Recognition
May 03, 2022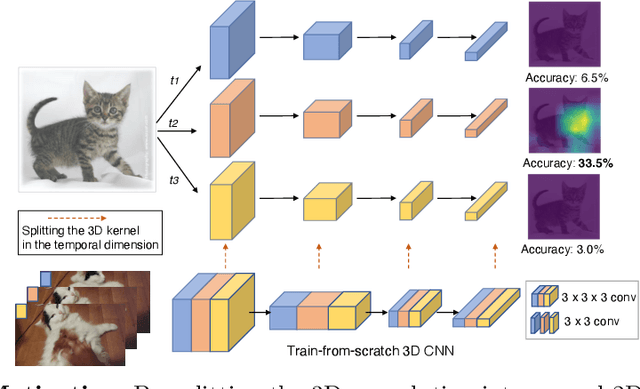
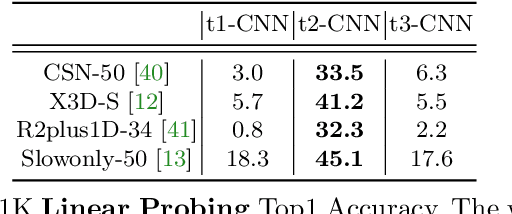
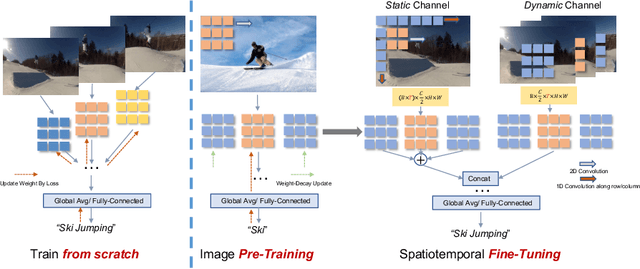

Image pre-training, the current de-facto paradigm for a wide range of visual tasks, is generally less favored in the field of video recognition. By contrast, a common strategy is to directly train with spatiotemporal convolutional neural networks (CNNs) from scratch. Nonetheless, interestingly, by taking a closer look at these from-scratch learned CNNs, we note there exist certain 3D kernels that exhibit much stronger appearance modeling ability than others, arguably suggesting appearance information is already well disentangled in learning. Inspired by this observation, we hypothesize that the key to effectively leveraging image pre-training lies in the decomposition of learning spatial and temporal features, and revisiting image pre-training as the appearance prior to initializing 3D kernels. In addition, we propose Spatial-Temporal Separable (STS) convolution, which explicitly splits the feature channels into spatial and temporal groups, to further enable a more thorough decomposition of spatiotemporal features for fine-tuning 3D CNNs. Our experiments show that simply replacing 3D convolution with STS notably improves a wide range of 3D CNNs without increasing parameters and computation on both Kinetics-400 and Something-Something V2. Moreover, this new training pipeline consistently achieves better results on video recognition with significant speedup. For instance, we achieve +0.6% top-1 of Slowfast on Kinetics-400 over the strong 256-epoch 128-GPU baseline while fine-tuning for only 50 epochs with 4 GPUs. The code and models are available at https://github.com/UCSC-VLAA/Image-Pretraining-for-Video.
Unified Simultaneous Wireless Information and Power Transfer for IoT: Signaling and Architecture with Deep Learning Adaptive Control
Jun 26, 2021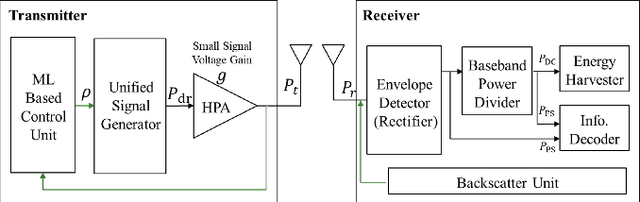
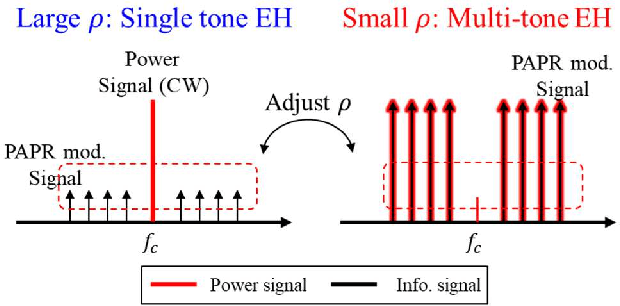
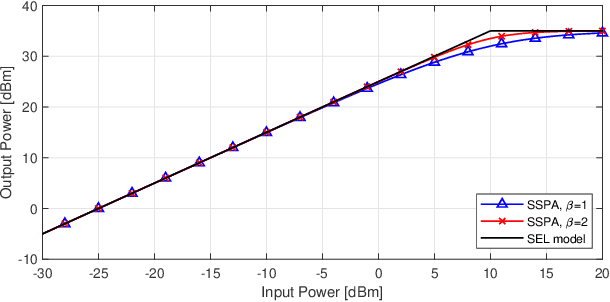
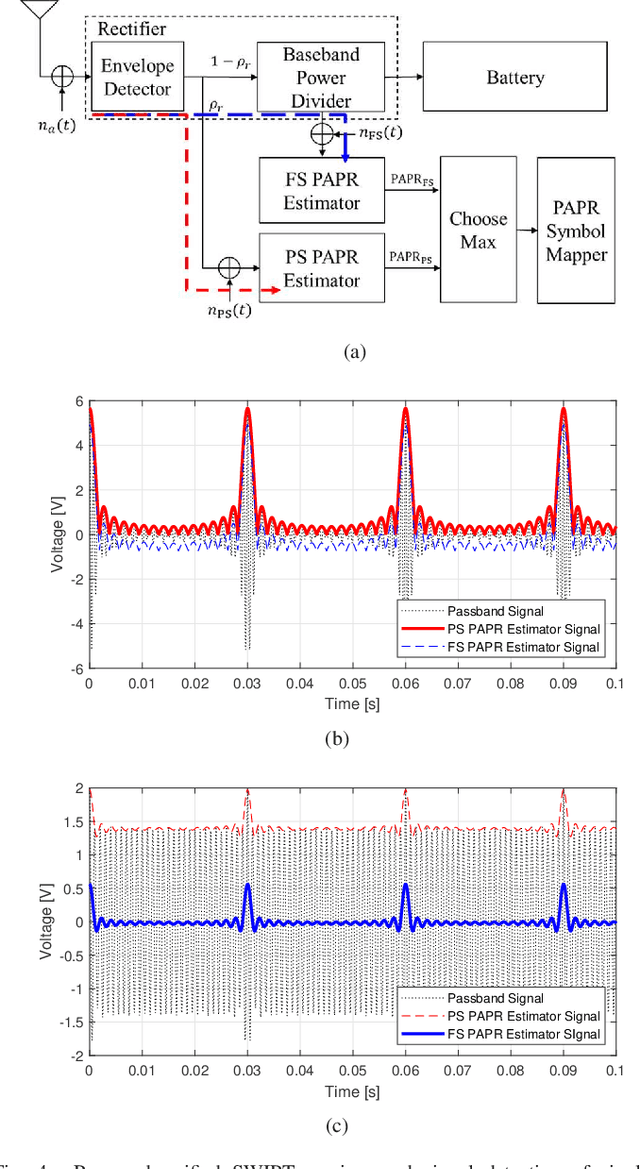
In this paper, we propose a unified SWIPT signal and its architecture design in order to take advantage of both single tone and multi-tone signaling by adjusting only the power allocation ratio of a unified signal. For this, we design a novel unified and integrated receiver architecture for the proposed unified SWIPT signaling, which consumes low power with an envelope detection. To relieve the computational complexity of the receiver, we propose an adaptive control algorithm by which the transmitter adjusts the communication mode through temporal convolutional network (TCN) based asymmetric processing. To this end, the transmitter optimizes the modulation index and power allocation ratio in short-term scale while updating the mode switching threshold in long-term scale. We demonstrate that the proposed unified SWIPT system improves the achievable rate under the self-powering condition of low-power IoT devices. Consequently it is foreseen to effectively deploy low-power IoT networks that concurrently supply both information and energy wirelessly to the devices by using the proposed unified SWIPT and adaptive control algorithm in place at the transmitter side.
Improving Visual Grounding with Visual-Linguistic Verification and Iterative Reasoning
Apr 30, 2022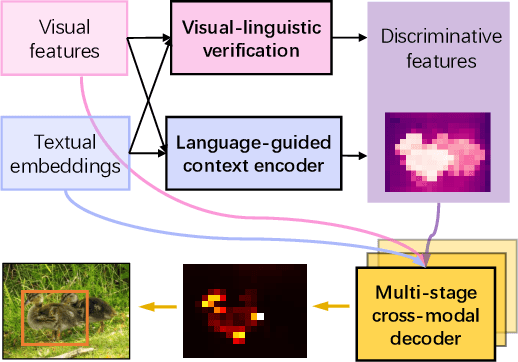
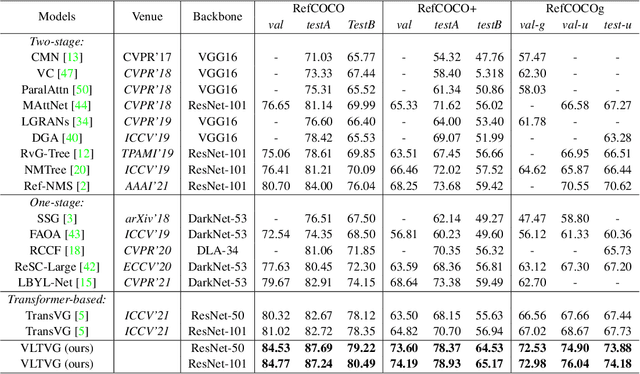
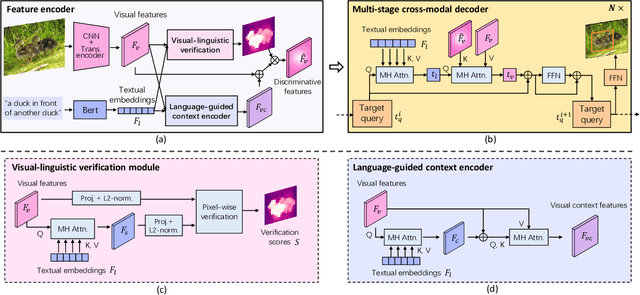
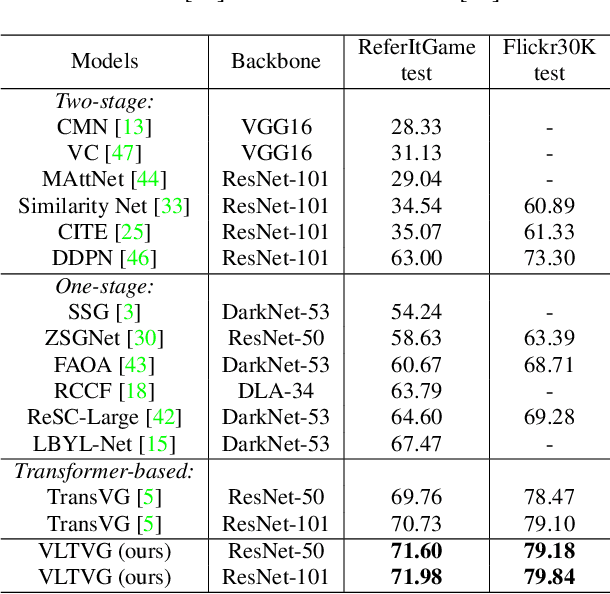
Visual grounding is a task to locate the target indicated by a natural language expression. Existing methods extend the generic object detection framework to this problem. They base the visual grounding on the features from pre-generated proposals or anchors, and fuse these features with the text embeddings to locate the target mentioned by the text. However, modeling the visual features from these predefined locations may fail to fully exploit the visual context and attribute information in the text query, which limits their performance. In this paper, we propose a transformer-based framework for accurate visual grounding by establishing text-conditioned discriminative features and performing multi-stage cross-modal reasoning. Specifically, we develop a visual-linguistic verification module to focus the visual features on regions relevant to the textual descriptions while suppressing the unrelated areas. A language-guided feature encoder is also devised to aggregate the visual contexts of the target object to improve the object's distinctiveness. To retrieve the target from the encoded visual features, we further propose a multi-stage cross-modal decoder to iteratively speculate on the correlations between the image and text for accurate target localization. Extensive experiments on five widely used datasets validate the efficacy of our proposed components and demonstrate state-of-the-art performance. Our code is public at https://github.com/yangli18/VLTVG.
Span-level Bidirectional Cross-attention Framework for Aspect Sentiment Triplet Extraction
Apr 27, 2022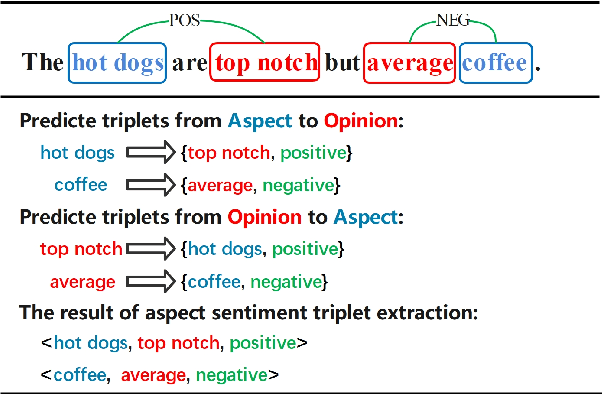
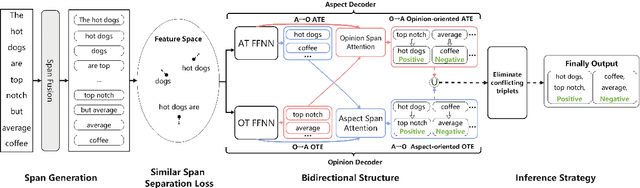
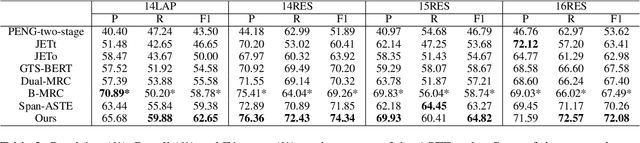
Aspect Sentiment Triplet Extraction (ASTE) is a new fine-grained sentiment analysis task that aims to extract triplets of aspect terms, sentiments, and opinion terms from review sentences. Recently, span-level models achieve gratifying results on ASTE task by taking advantage of whole span predictions. However, all the spans generated by these methods inevitably share at least one token with some others, and these method suffer from the similarity of these spans due to their similar distributions. Moreover, since either the aspect term or opinion term can trigger a sentiment triplet, it is challenging to make use of the information more comprehensively and adequately. To address these concerns, we propose a span-level bidirectional cross-attention framework. Specifically, we design a similar span separation loss to detach the spans with shared tokens and a bidirectional cross-attention structure that consists of aspect and opinion decoders to decode the span-level representations in both aspect-to-opinion and opinion-to-aspect directions. With differentiated span representations and bidirectional decoding structure, our model can extract sentiment triplets more precisely and efficiently. Experimental results show that our framework significantly outperforms state-of-the-art methods, achieving better performance in predicting triplets with multi-token entities and extracting triplets in sentences with multi-triplets.
Episodic Memory Question Answering
May 03, 2022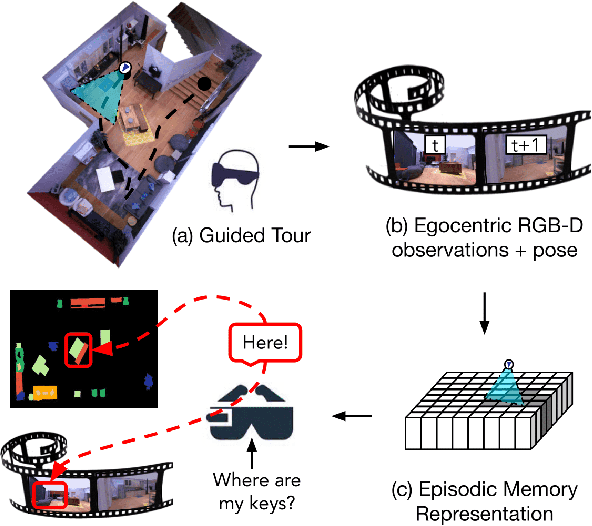
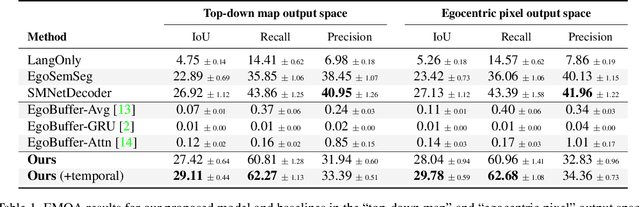
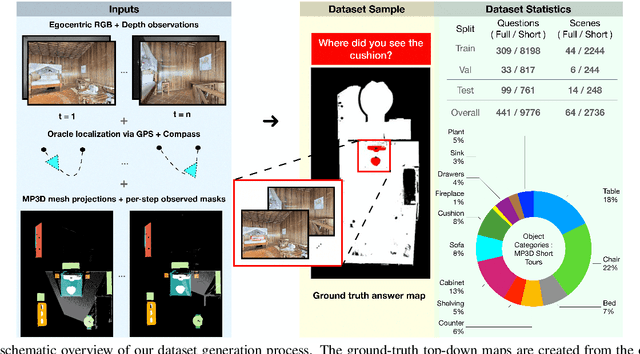
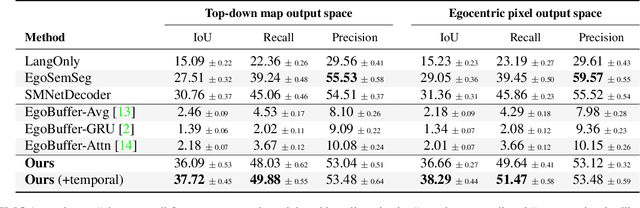
Egocentric augmented reality devices such as wearable glasses passively capture visual data as a human wearer tours a home environment. We envision a scenario wherein the human communicates with an AI agent powering such a device by asking questions (e.g., where did you last see my keys?). In order to succeed at this task, the egocentric AI assistant must (1) construct semantically rich and efficient scene memories that encode spatio-temporal information about objects seen during the tour and (2) possess the ability to understand the question and ground its answer into the semantic memory representation. Towards that end, we introduce (1) a new task - Episodic Memory Question Answering (EMQA) wherein an egocentric AI assistant is provided with a video sequence (the tour) and a question as an input and is asked to localize its answer to the question within the tour, (2) a dataset of grounded questions designed to probe the agent's spatio-temporal understanding of the tour, and (3) a model for the task that encodes the scene as an allocentric, top-down semantic feature map and grounds the question into the map to localize the answer. We show that our choice of episodic scene memory outperforms naive, off-the-shelf solutions for the task as well as a host of very competitive baselines and is robust to noise in depth, pose as well as camera jitter. The project page can be found at: https://samyak-268.github.io/emqa .
Generating Self-Serendipity Preference in Recommender Systems for Addressing Cold Start Problems
Apr 27, 2022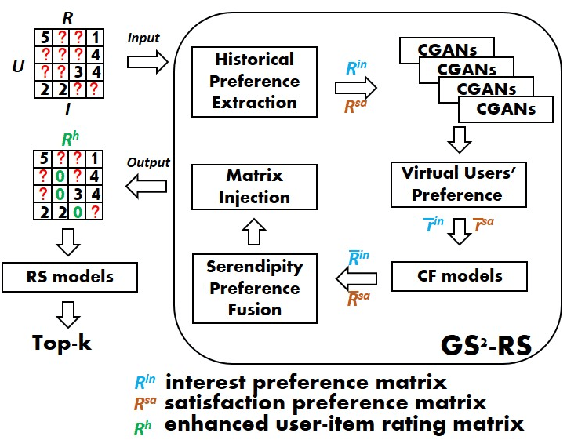

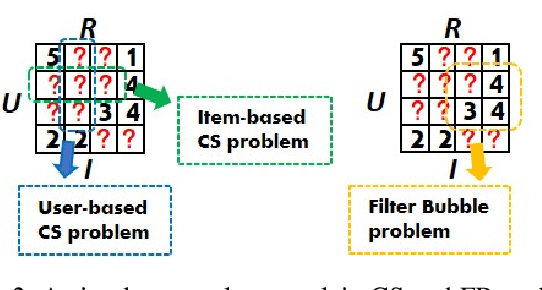
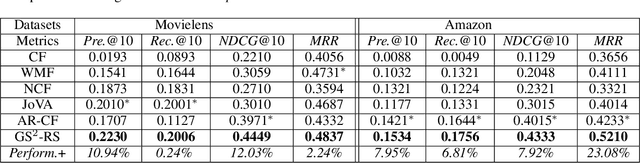
Classical accuracy-oriented Recommender Systems (RSs) typically face the cold-start problem and the filter-bubble problem when users suffer the familiar, repeated, and even predictable recommendations, making them boring and unsatisfied. To address the above issues, serendipity-oriented RSs are proposed to recommend appealing and valuable items significantly deviating from users' historical interactions and thus satisfying them by introducing unexplored but relevant candidate items to them. In this paper, we devise a novel serendipity-oriented recommender system (\textbf{G}enerative \textbf{S}elf-\textbf{S}erendipity \textbf{R}ecommender \textbf{S}ystem, \textbf{GS$^2$-RS}) that generates users' self-serendipity preferences to enhance the recommendation performance. Specifically, this model extracts users' interest and satisfaction preferences, generates virtual but convincible neighbors' preferences from themselves, and achieves their self-serendipity preference. Then these preferences are injected into the rating matrix as additional information for RS models. Note that GS$^2$-RS can not only tackle the cold-start problem but also provides diverse but relevant recommendations to relieve the filter-bubble problem. Extensive experiments on benchmark datasets illustrate that the proposed GS$^2$-RS model can significantly outperform the state-of-the-art baseline approaches in serendipity measures with a stable accuracy performance.
PLGAN: Generative Adversarial Networks for Power-Line Segmentation in Aerial Images
Apr 14, 2022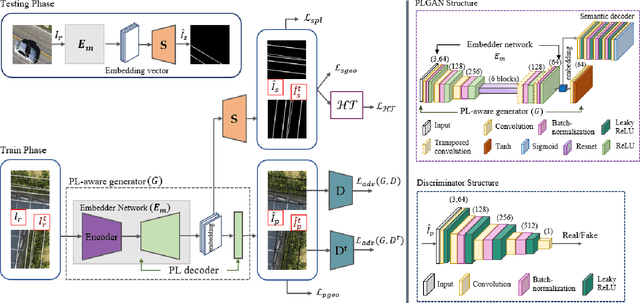

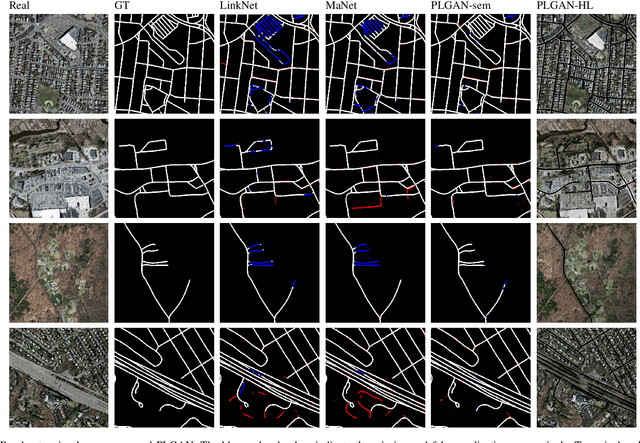
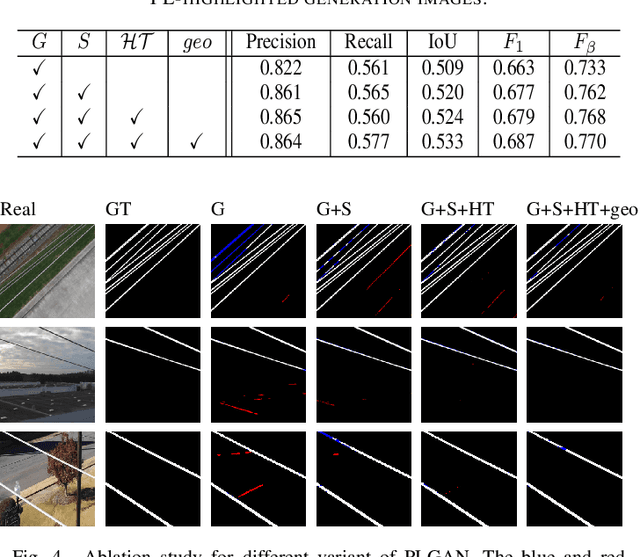
Accurate segmentation of power lines in various aerial images is very important for UAV flight safety. The complex background and very thin structures of power lines, however, make it an inherently difficult task in computer vision. This paper presents PLGAN, a simple yet effective method based on generative adversarial networks, to segment power lines from aerial images with different backgrounds. Instead of directly using the adversarial networks to generate the segmentation, we take their certain decoding features and embed them into another semantic segmentation network by considering more context, geometry, and appearance information of power lines. We further exploit the appropriate form of the generated images for high-quality feature embedding and define a new loss function in the Hough-transform parameter space to enhance the segmentation of very thin power lines. Extensive experiments and comprehensive analysis demonstrate that our proposed PLGAN outperforms the prior state-of-the-art methods for semantic segmentation and line detection.
SpeechSplit 2.0: Unsupervised speech disentanglement for voice conversion Without tuning autoencoder Bottlenecks
Mar 26, 2022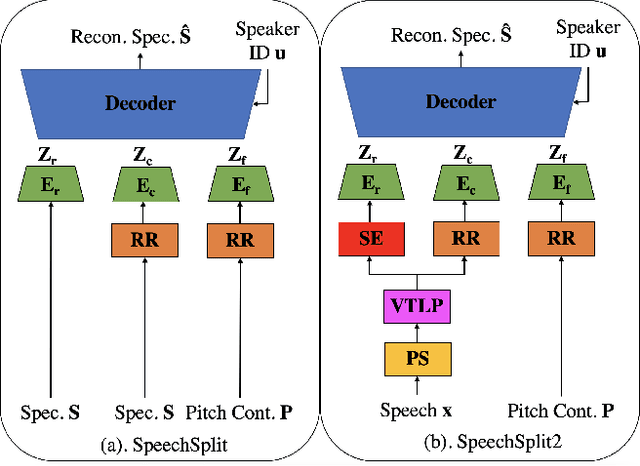
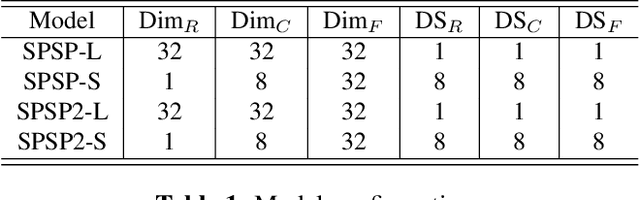
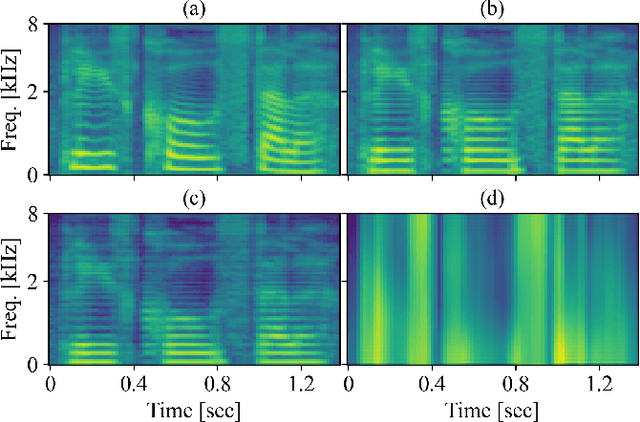
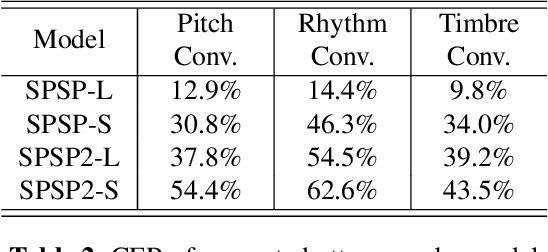
SpeechSplit can perform aspect-specific voice conversion by disentangling speech into content, rhythm, pitch, and timbre using multiple autoencoders in an unsupervised manner. However, SpeechSplit requires careful tuning of the autoencoder bottlenecks, which can be time-consuming and less robust. This paper proposes SpeechSplit 2.0, which constrains the information flow of the speech component to be disentangled on the autoencoder input using efficient signal processing methods instead of bottleneck tuning. Evaluation results show that SpeechSplit 2.0 achieves comparable performance to SpeechSplit in speech disentanglement and superior robustness to the bottleneck size variations. Our code is available at https://github.com/biggytruck/SpeechSplit2.