 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Assimilation of Satellite Active Fires Data
Apr 01, 2022
Wildland fires pose an increasingly serious problem in our society. The number and severity of these fires has been rising for many years. Wildfires pose direct threats to life and property as well as threats through ancillary effects like reduced air quality. The aim of this thesis is to develop techniques to help combat the impacts of wildfires by improving wildfire modeling capabilities by using satellite fire observations. Already much work has been done in this direction by other researchers. Our work seeks to expand the body of knowledge using mathematically sound methods to utilize information about wildfires that considers the uncertainties inherent in the satellite data. In this thesis we explore methods for using satellite data to help initialize and steer wildfire simulations. In particular, we develop a method for constructing the history of a fire, a new technique for assimilating wildfire data, and a method for modifying the behavior of a modeled fire by inferring information about the fuels in the fire domain. These goals rely on being able to estimate the time a fire first arrived at every location in a geographic region of interest. Because detailed knowledge of real wildfires is typically unavailable, the basic procedure for developing and testing the methods in this thesis will be to first work with simulated data so that the estimates produced can be compared with known solutions. The methods thus developed are then applied to real-world scenarios. Analysis of these scenarios shows that the work with constructing the history of fires and data assimilation improves improves fire modeling capabilities. The research is significant because it gives us a better understanding of the capabilities and limitations of using satellite data to inform wildfire models and it points the way towards new avenues for modeling fire behavior.
Episodic Memory Question Answering
May 03, 2022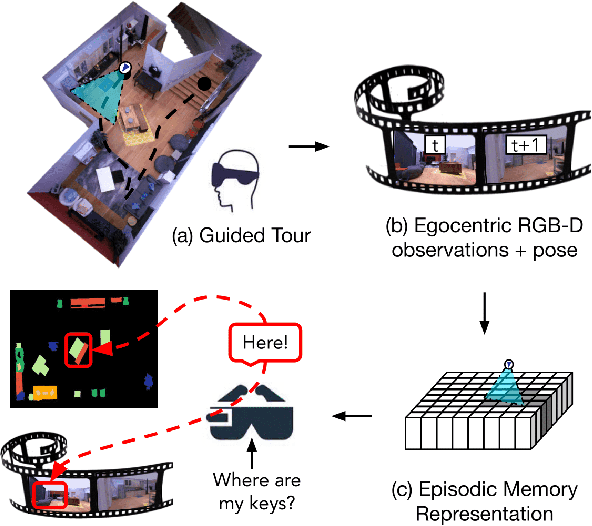
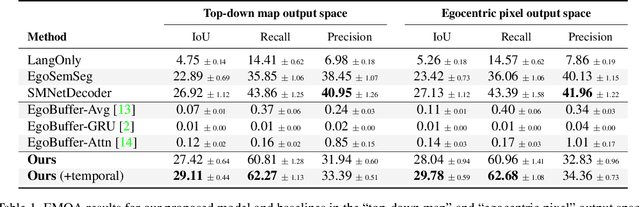
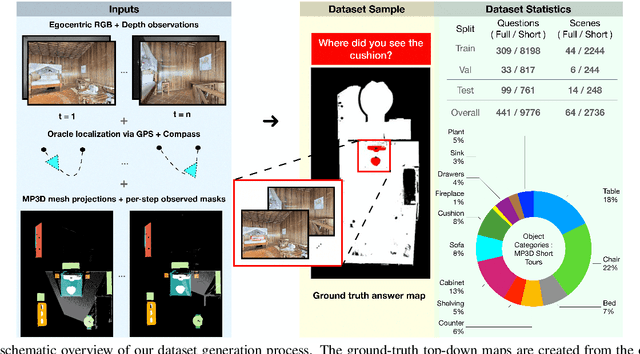
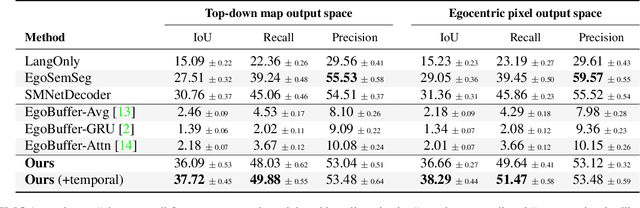
Egocentric augmented reality devices such as wearable glasses passively capture visual data as a human wearer tours a home environment. We envision a scenario wherein the human communicates with an AI agent powering such a device by asking questions (e.g., where did you last see my keys?). In order to succeed at this task, the egocentric AI assistant must (1) construct semantically rich and efficient scene memories that encode spatio-temporal information about objects seen during the tour and (2) possess the ability to understand the question and ground its answer into the semantic memory representation. Towards that end, we introduce (1) a new task - Episodic Memory Question Answering (EMQA) wherein an egocentric AI assistant is provided with a video sequence (the tour) and a question as an input and is asked to localize its answer to the question within the tour, (2) a dataset of grounded questions designed to probe the agent's spatio-temporal understanding of the tour, and (3) a model for the task that encodes the scene as an allocentric, top-down semantic feature map and grounds the question into the map to localize the answer. We show that our choice of episodic scene memory outperforms naive, off-the-shelf solutions for the task as well as a host of very competitive baselines and is robust to noise in depth, pose as well as camera jitter. The project page can be found at: https://samyak-268.github.io/emqa .
A Tech Hybrid-Recommendation Engine and Personalized Notification: An integrated tool to assist users through Recommendations (Project ATHENA)
Feb 13, 2022
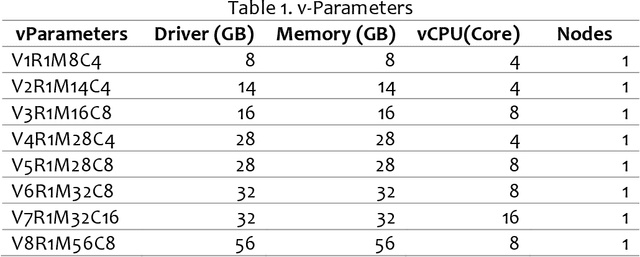
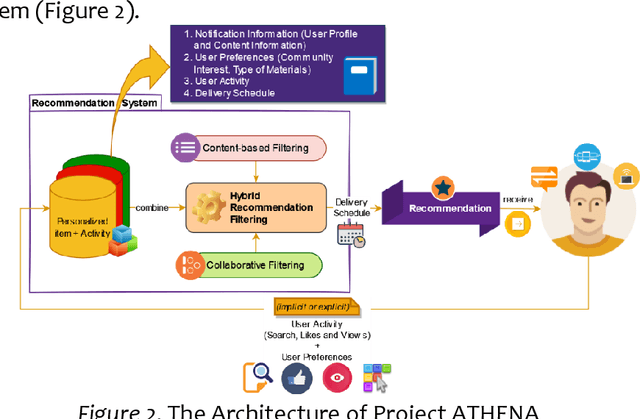
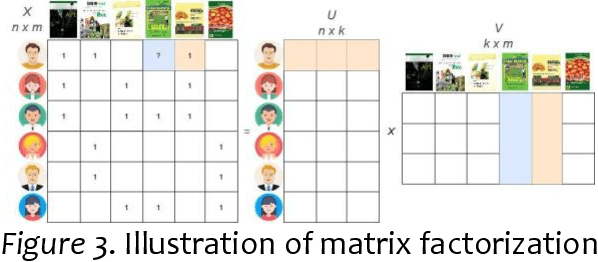
Project ATHENA aims to develop an application to address information overload, primarily focused on Recommendation Systems (RSs) with the personalization and user experience design of a modern system. Two machine learning (ML) algorithms were used: (1) TF-IDF for Content-based filtering (CBF); (2) Classification with Matrix Factorization- Singular Value Decomposition(SVD) applied with Collaborative filtering (CF) and mean (normalization) for prediction accuracy of the CF. Data sampling in academic Research and Development of Philippine Council for Agriculture, Aquatic, and Natural Resources Research and Development (PCAARRD) e-Library and Project SARAI publications plus simulated data used as training sets to generate a recommendation of items that uses the three RS filtering (CF, CBF, and personalized version of item recommendations). Series of Testing and TAM performed and discussed. Findings allow users to engage in online information and quickly evaluate retrieved items produced by the application. Compatibility-testing (CoT) shows the application is compatible with all major browsers and mobile-friendly. Performance-testing (PT) recommended v-parameter specs and TAM evaluations results indicate strongly associated with overall positive feedback, thoroughly enough to address the information-overload problem as the core of the paper. A modular architecture presented addressing the information overload, primarily focused on RSs with the personalization and design of modern systems. Developers utilized Two ML algorithms and prototyped a simplified version of the architecture. Series of testing (CoT and PT) and evaluations with TAM were performed and discussed. Project ATHENA added a UX feature design of a modern system.
On Learning Contrastive Representations for Learning with Noisy Labels
Mar 03, 2022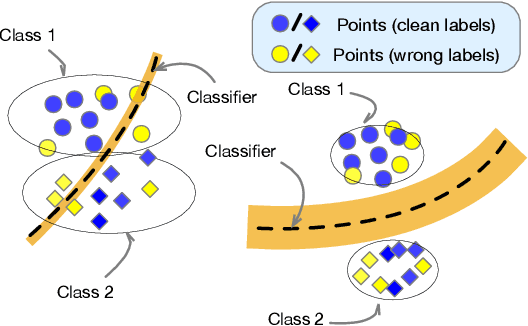
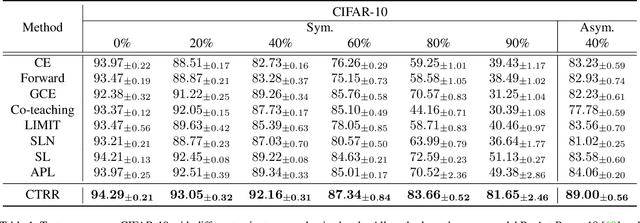
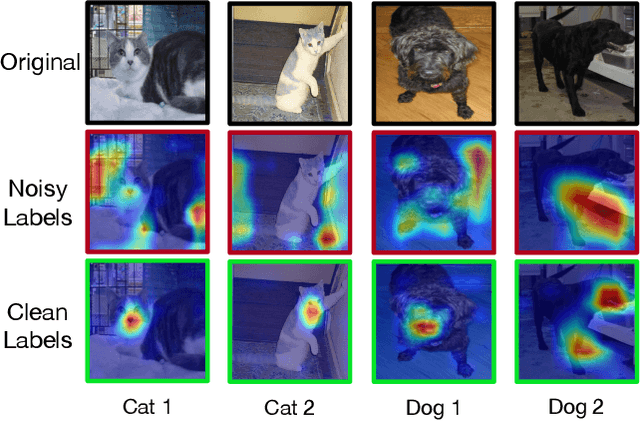
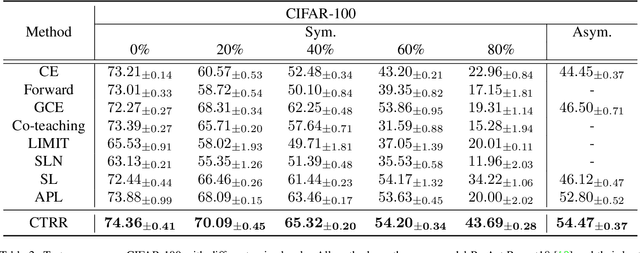
Deep neural networks are able to memorize noisy labels easily with a softmax cross-entropy (CE) loss. Previous studies attempted to address this issue focus on incorporating a noise-robust loss function to the CE loss. However, the memorization issue is alleviated but still remains due to the non-robust CE loss. To address this issue, we focus on learning robust contrastive representations of data on which the classifier is hard to memorize the label noise under the CE loss. We propose a novel contrastive regularization function to learn such representations over noisy data where label noise does not dominate the representation learning. By theoretically investigating the representations induced by the proposed regularization function, we reveal that the learned representations keep information related to true labels and discard information related to corrupted labels. Moreover, our theoretical results also indicate that the learned representations are robust to the label noise. The effectiveness of this method is demonstrated with experiments on benchmark datasets.
Span-level Bidirectional Cross-attention Framework for Aspect Sentiment Triplet Extraction
Apr 27, 2022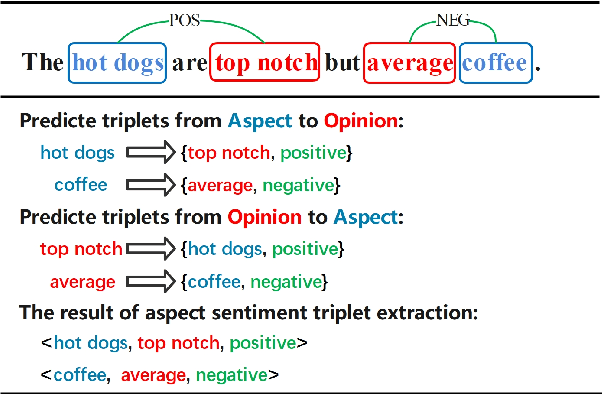
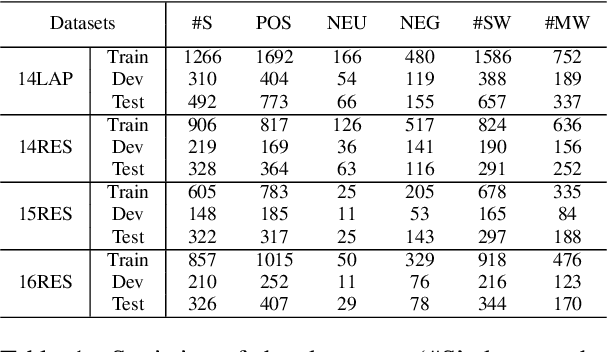
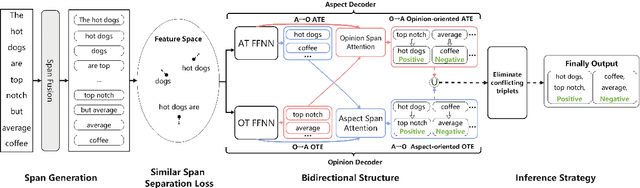
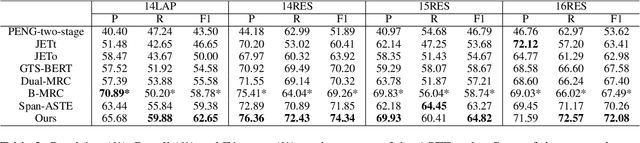
Aspect Sentiment Triplet Extraction (ASTE) is a new fine-grained sentiment analysis task that aims to extract triplets of aspect terms, sentiments, and opinion terms from review sentences. Recently, span-level models achieve gratifying results on ASTE task by taking advantage of whole span predictions. However, all the spans generated by these methods inevitably share at least one token with some others, and these method suffer from the similarity of these spans due to their similar distributions. Moreover, since either the aspect term or opinion term can trigger a sentiment triplet, it is challenging to make use of the information more comprehensively and adequately. To address these concerns, we propose a span-level bidirectional cross-attention framework. Specifically, we design a similar span separation loss to detach the spans with shared tokens and a bidirectional cross-attention structure that consists of aspect and opinion decoders to decode the span-level representations in both aspect-to-opinion and opinion-to-aspect directions. With differentiated span representations and bidirectional decoding structure, our model can extract sentiment triplets more precisely and efficiently. Experimental results show that our framework significantly outperforms state-of-the-art methods, achieving better performance in predicting triplets with multi-token entities and extracting triplets in sentences with multi-triplets.
VICTR: Visual Information Captured Text Representation for Text-to-Image Multimodal Tasks
Oct 25, 2020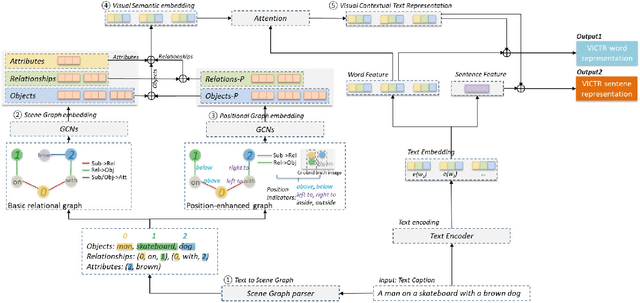
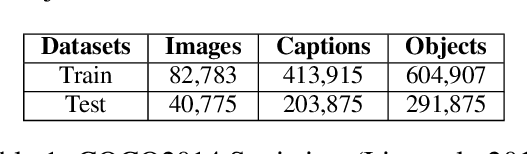
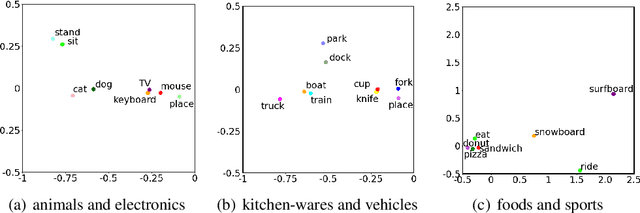
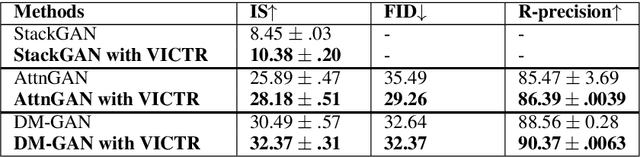
Text-to-image multimodal tasks, generating/retrieving an image from a given text description, are extremely challenging tasks since raw text descriptions cover quite limited information in order to fully describe visually realistic images. We propose a new visual contextual text representation for text-to-image multimodal tasks, VICTR, which captures rich visual semantic information of objects from the text input. First, we use the text description as initial input and conduct dependency parsing to extract the syntactic structure and analyse the semantic aspect, including object quantities, to extract the scene graph. Then, we train the extracted objects, attributes, and relations in the scene graph and the corresponding geometric relation information using Graph Convolutional Networks, and it generates text representation which integrates textual and visual semantic information. The text representation is aggregated with word-level and sentence-level embedding to generate both visual contextual word and sentence representation. For the evaluation, we attached VICTR to the state-of-the-art models in text-to-image generation.VICTR is easily added to existing models and improves across both quantitative and qualitative aspects.
A Generative Model for Relation Extraction and Classification
Feb 26, 2022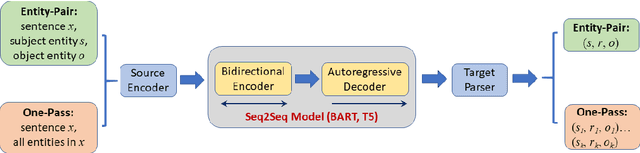
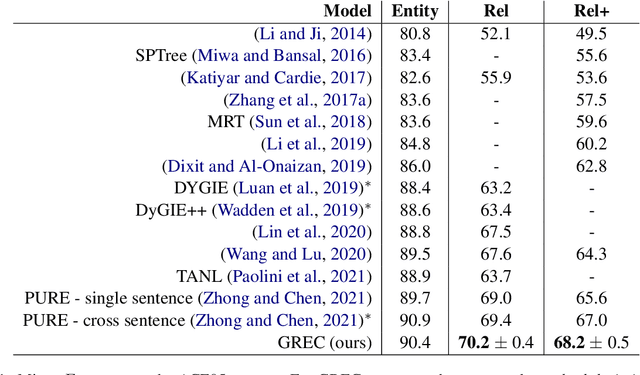
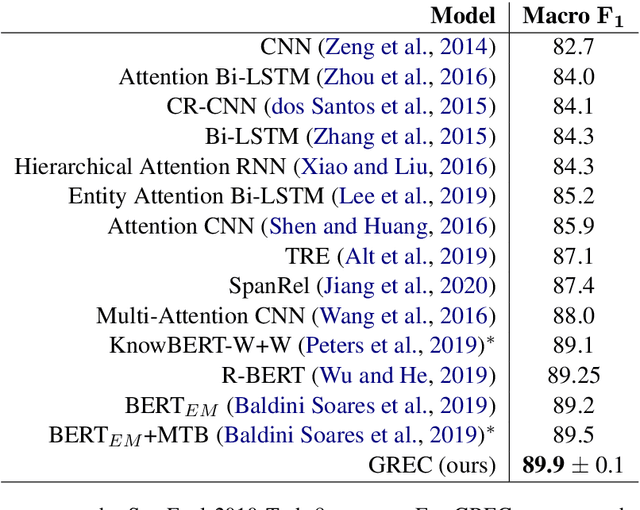
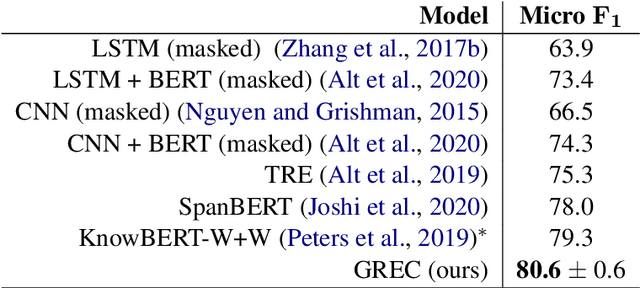
Relation extraction (RE) is an important information extraction task which provides essential information to many NLP applications such as knowledge base population and question answering. In this paper, we present a novel generative model for relation extraction and classification (which we call GREC), where RE is modeled as a sequence-to-sequence generation task. We explore various encoding representations for the source and target sequences, and design effective schemes that enable GREC to achieve state-of-the-art performance on three benchmark RE datasets. In addition, we introduce negative sampling and decoding scaling techniques which provide a flexible tool to tune the precision and recall performance of the model. Our approach can be extended to extract all relation triples from a sentence in one pass. Although the one-pass approach incurs certain performance loss, it is much more computationally efficient.
Estimation of Consistent Time Delays in Subsample via Auxiliary-Function-Based Iterative Updates
Mar 23, 2022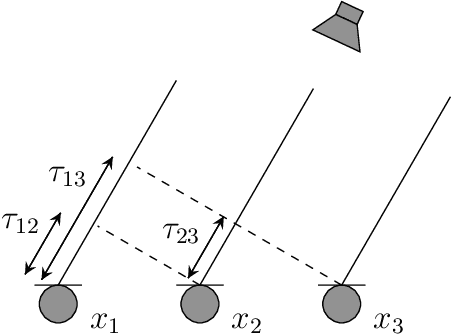
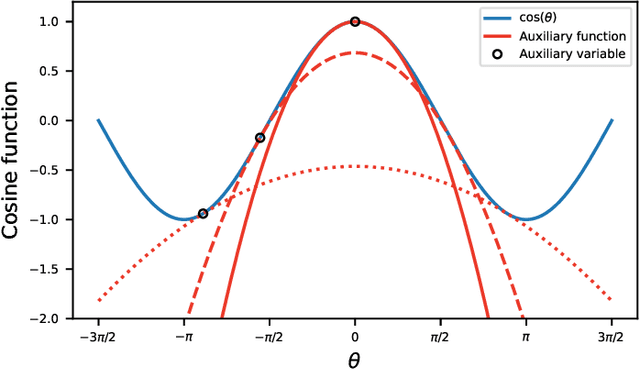
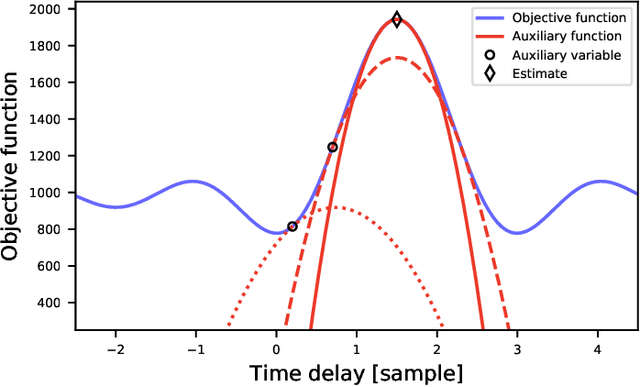
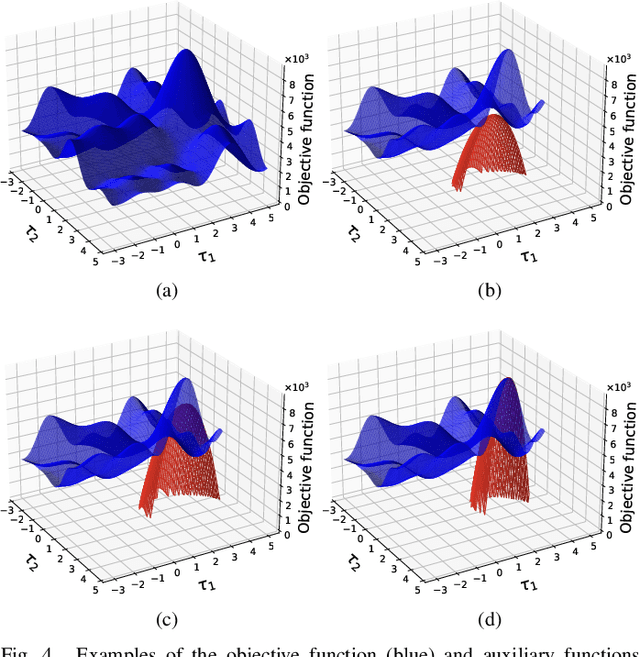
In this paper, we propose a new algorithm for the estimation of multiple time delays (TDs). Since a TD is a fundamental spatial cue for sensor array signal processing techniques, many methods for estimating it have been studied. Most of them, including generalized cross correlation (CC)-based methods, focus on how to estimate a TD between two sensors. These methods can then be easily adapted for multiple TDs by applying them to every pair of a reference sensor and another one. However, these pairwise methods can use only the partial information obtained by the selected sensors, resulting in inconsistent TD estimates and limited estimation accuracy. In contrast, we propose joint optimization of entire TD parameters, where spatial information obtained from all sensors is taken into account. We also introduce a consistent constraint regarding TD parameters to the observation model. We then consider a multidimensional CC (MCC) as the objective function, which is derived on the basis of maximum likelihood estimation. To maximize the MCC, which is a nonconvex function, we derive the auxiliary function for the MCC and design efficient update rules. We additionally estimate the amplitudes of the transfer functions for supporting the TD estimation, where we maximize the Rayleigh quotient under the non-negative constraint. We experimentally analyze essential features of the proposed method and evaluate its effectiveness in TD estimation. Code will be available at https://github.com/onolab-tmu/AuxTDE.
Generating Self-Serendipity Preference in Recommender Systems for Addressing Cold Start Problems
Apr 27, 2022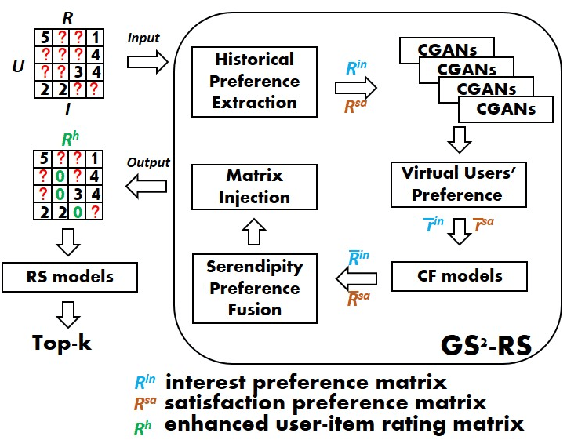

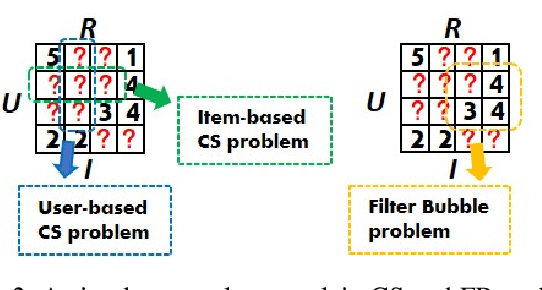
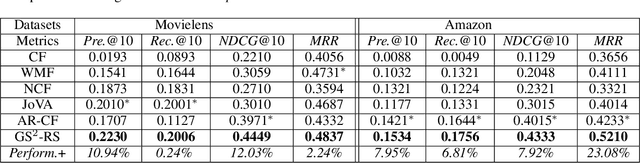
Classical accuracy-oriented Recommender Systems (RSs) typically face the cold-start problem and the filter-bubble problem when users suffer the familiar, repeated, and even predictable recommendations, making them boring and unsatisfied. To address the above issues, serendipity-oriented RSs are proposed to recommend appealing and valuable items significantly deviating from users' historical interactions and thus satisfying them by introducing unexplored but relevant candidate items to them. In this paper, we devise a novel serendipity-oriented recommender system (\textbf{G}enerative \textbf{S}elf-\textbf{S}erendipity \textbf{R}ecommender \textbf{S}ystem, \textbf{GS$^2$-RS}) that generates users' self-serendipity preferences to enhance the recommendation performance. Specifically, this model extracts users' interest and satisfaction preferences, generates virtual but convincible neighbors' preferences from themselves, and achieves their self-serendipity preference. Then these preferences are injected into the rating matrix as additional information for RS models. Note that GS$^2$-RS can not only tackle the cold-start problem but also provides diverse but relevant recommendations to relieve the filter-bubble problem. Extensive experiments on benchmark datasets illustrate that the proposed GS$^2$-RS model can significantly outperform the state-of-the-art baseline approaches in serendipity measures with a stable accuracy performance.
PLGAN: Generative Adversarial Networks for Power-Line Segmentation in Aerial Images
Apr 14, 2022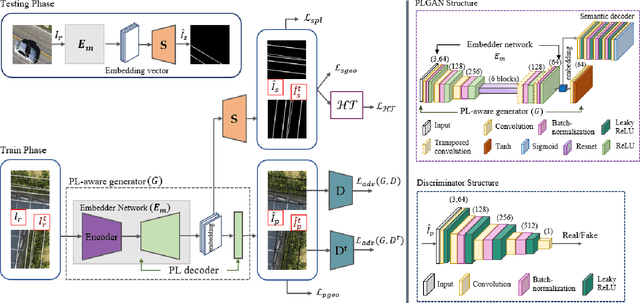

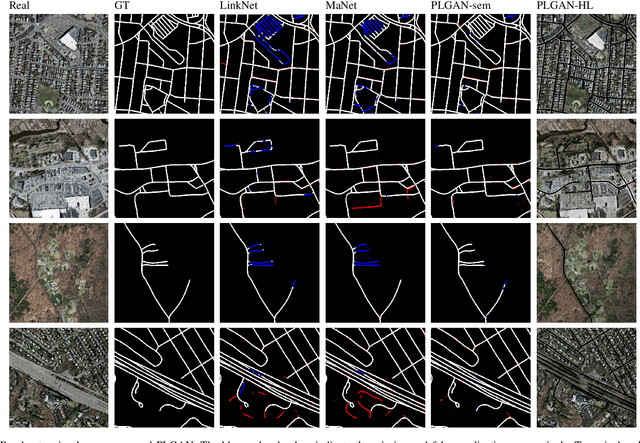
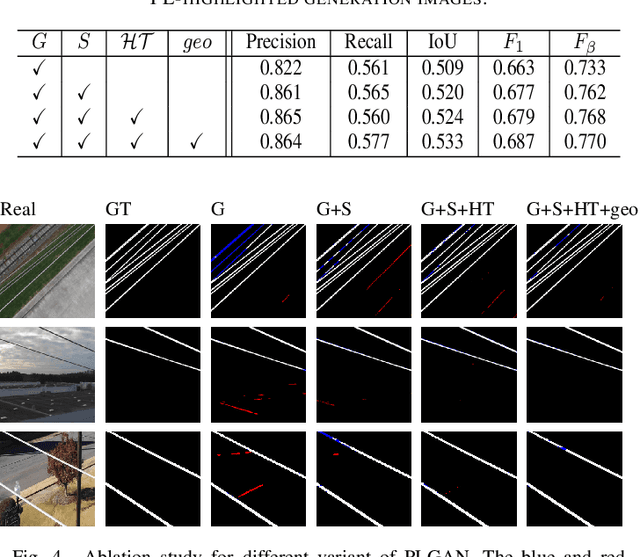
Accurate segmentation of power lines in various aerial images is very important for UAV flight safety. The complex background and very thin structures of power lines, however, make it an inherently difficult task in computer vision. This paper presents PLGAN, a simple yet effective method based on generative adversarial networks, to segment power lines from aerial images with different backgrounds. Instead of directly using the adversarial networks to generate the segmentation, we take their certain decoding features and embed them into another semantic segmentation network by considering more context, geometry, and appearance information of power lines. We further exploit the appropriate form of the generated images for high-quality feature embedding and define a new loss function in the Hough-transform parameter space to enhance the segmentation of very thin power lines. Extensive experiments and comprehensive analysis demonstrate that our proposed PLGAN outperforms the prior state-of-the-art methods for semantic segmentation and line detection.