 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ACVNet: Attention Concatenation Volume for Accurate and Efficient Stereo Matching
Mar 04, 2022
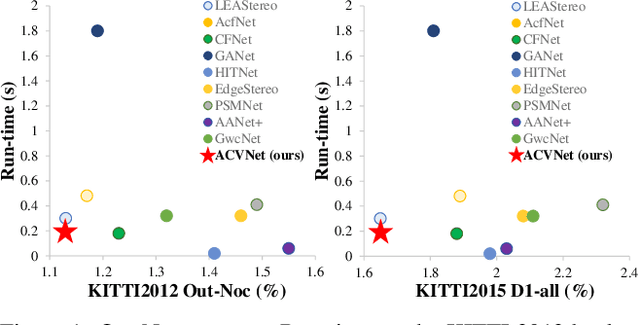
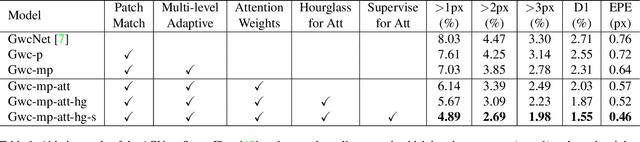
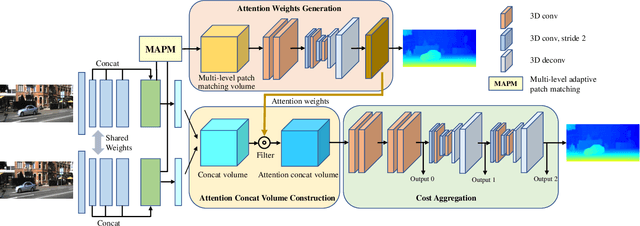
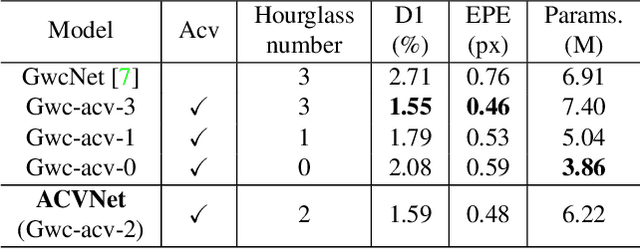
Stereo matching is a fundamental building block for many vision and robotics applications. An informative and concise cost volume representation is vital for stereo matching of high accuracy and efficiency. In this paper, we present a novel cost volume construction method which generates attention weights from correlation clues to suppress redundant information and enhance matching-related information in the concatenation volume. To generate reliable attention weights, we propose multi-level adaptive patch matching to improve the distinctiveness of the matching cost at different disparities even for textureless regions. The proposed cost volume is named attention concatenation volume (ACV) which can be seamlessly embedded into most stereo matching networks, the resulting networks can use a more lightweight aggregation network and meanwhile achieve higher accuracy, e.g. using only 1/25 parameters of the aggregation network can achieve higher accuracy for GwcNet. Furthermore, we design a highly accurate network (ACVNet) based on our ACV, which achieves state-of-the-art performance on several benchmarks.
Framework for inferring empirical causal graphs from binary data to support multidimensional poverty analysis
May 12, 2022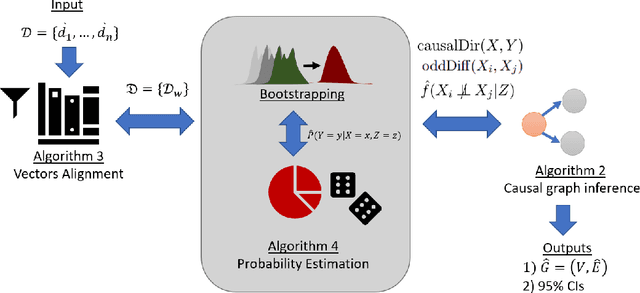
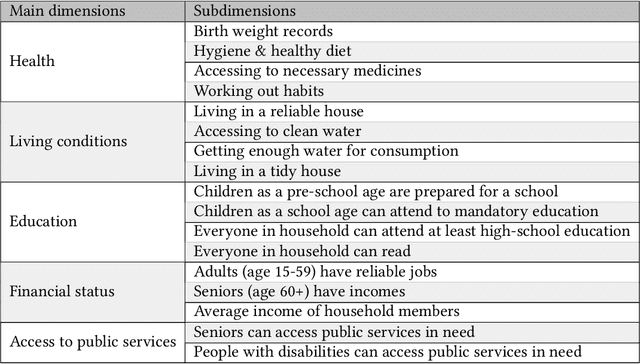
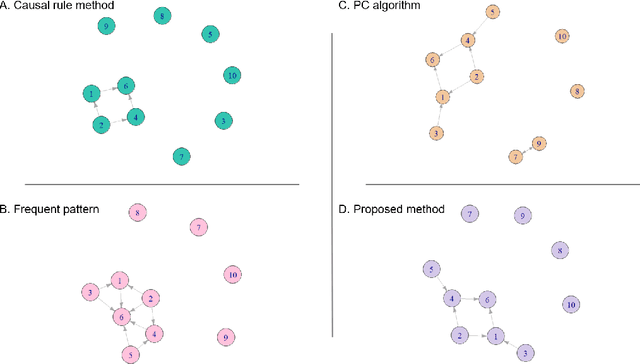

Poverty is one of the fundamental issues that mankind faces. Multidimensional Poverty Index (MPI) is deployed for measuring poverty issues in a population beyond monetary. However, MPI cannot provide information regarding associations and causal relations among poverty factors. Does education cause income inequality in a specific region? Is lacking education a cause of health issues? By not knowing causal relations, policy maker cannot pinpoint root causes of poverty issues of a specific population, which might not be the same across different population. Additionally, MPI requires binary data, which cannot be analyzed by most of causal inference frameworks. In this work, we proposed an exploratory-data-analysis framework for finding possible causal relations with confidence intervals among binary data. The proposed framework provides not only how severe the issue of poverty is, but it also provides the causal relations among poverty factors. Moreover, knowing a confidence interval of degree of causal direction lets us know how strong a causal relation is. We evaluated the proposed framework with several baseline approaches in simulation datasets as well as using two real-world datasets as case studies 1) Twin births of the United States: the relation between birth weight and mortality of twin, and 2) Thailand population surveys from 378k households of Chiang Mai and 353k households of Khon Kaen provinces. Our framework performed better than baselines in most cases. The first case study reveals almost all mortality cases in twins have issues of low birth weights but not all low-birth-weight twins were died. The second case study reveals that smoking associates with drinking alcohol in both provinces and there is a causal relation of smoking causes drinking alcohol in only Chiang Mai province. The framework can be applied beyond the poverty context.
HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
Apr 27, 2022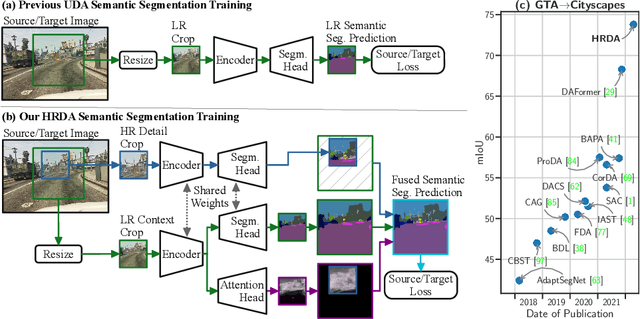
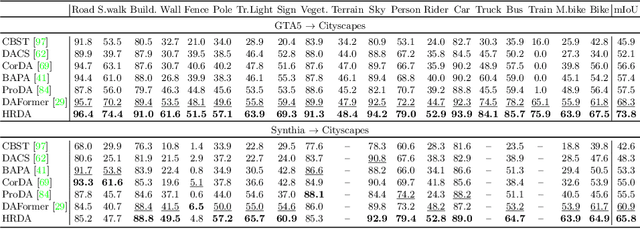
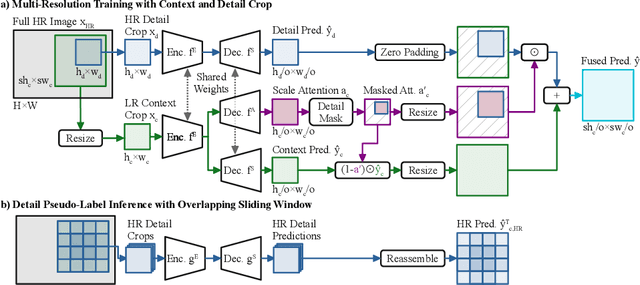
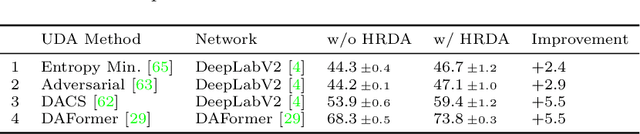
Unsupervised domain adaptation (UDA) aims to adapt a model trained on the source domain (e.g. synthetic data) to the target domain (e.g. real-world data) without requiring further annotations on the target domain. This work focuses on UDA for semantic segmentation as real-world pixel-wise annotations are particularly expensive to acquire. As UDA methods for semantic segmentation are usually GPU memory intensive, most previous methods operate only on downscaled images. We question this design as low-resolution predictions often fail to preserve fine details. The alternative of training with random crops of high-resolution images alleviates this problem but falls short in capturing long-range, domain-robust context information. Therefore, we propose HRDA, a multi-resolution training approach for UDA, that combines the strengths of small high-resolution crops to preserve fine segmentation details and large low-resolution crops to capture long-range context dependencies with a learned scale attention, while maintaining a manageable GPU memory footprint. HRDA enables adapting small objects and preserving fine segmentation details. It significantly improves the state-of-the-art performance by 5.5 mIoU for GTA-to-Cityscapes and 4.9 mIoU for Synthia-to-Cityscapes, resulting in unprecedented 73.8 and 65.8 mIoU, respectively. The implementation is available at https://github.com/lhoyer/HRDA.
Self-Supervised Learning of Object Parts for Semantic Segmentation
Apr 27, 2022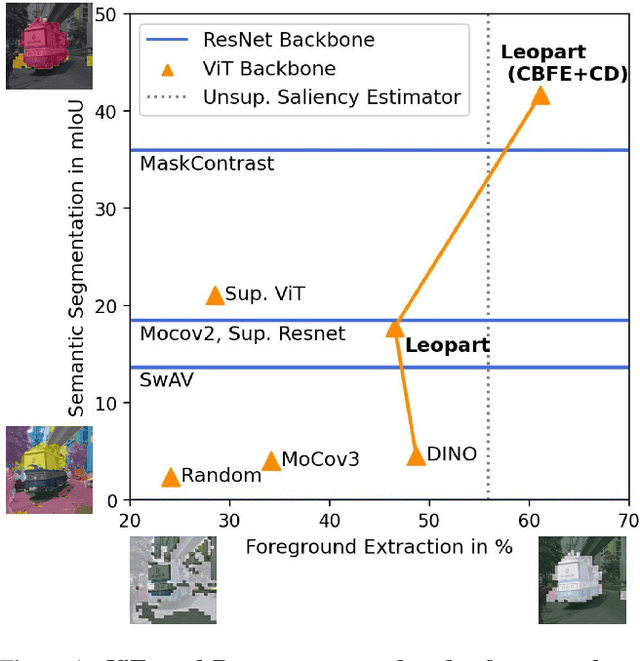
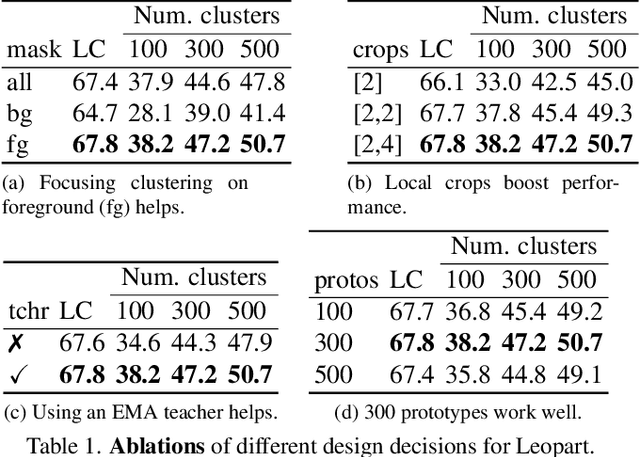
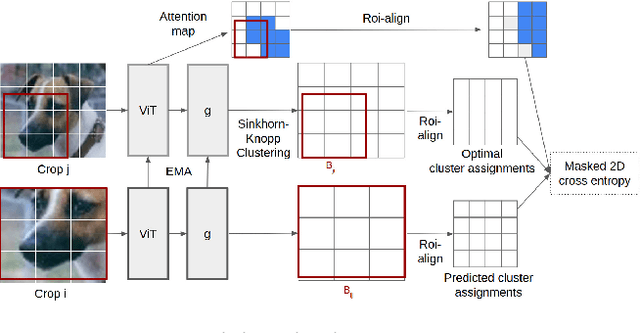
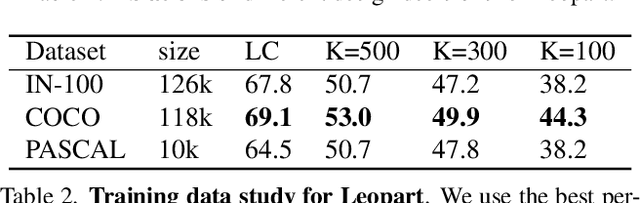
Progress in self-supervised learning has brought strong general image representation learning methods. Yet so far, it has mostly focused on image-level learning. In turn, tasks such as unsupervised image segmentation have not benefited from this trend as they require spatially-diverse representations. However, learning dense representations is challenging, as in the unsupervised context it is not clear how to guide the model to learn representations that correspond to various potential object categories. In this paper, we argue that self-supervised learning of object parts is a solution to this issue. Object parts are generalizable: they are a priori independent of an object definition, but can be grouped to form objects a posteriori. To this end, we leverage the recently proposed Vision Transformer's capability of attending to objects and combine it with a spatially dense clustering task for fine-tuning the spatial tokens. Our method surpasses the state-of-the-art on three semantic segmentation benchmarks by 17%-3%, showing that our representations are versatile under various object definitions. Finally, we extend this to fully unsupervised segmentation - which refrains completely from using label information even at test-time - and demonstrate that a simple method for automatically merging discovered object parts based on community detection yields substantial gains.
More to Less (M2L): Enhanced Health Recognition in the Wild with Reduced Modality of Wearable Sensors
Feb 16, 2022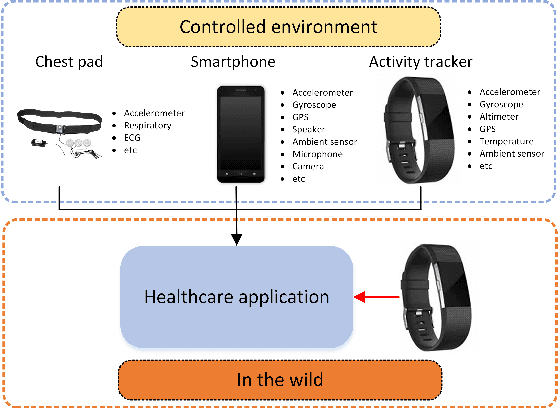
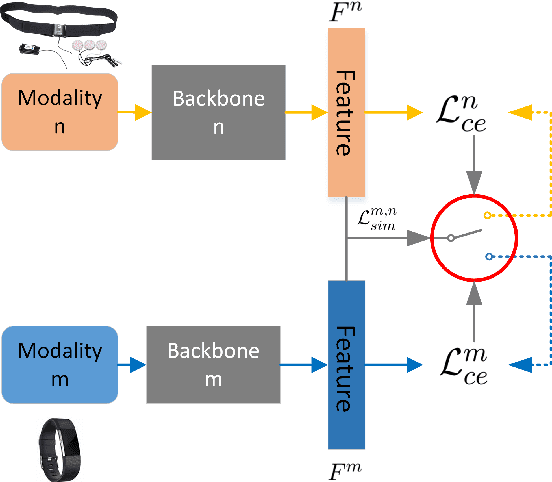
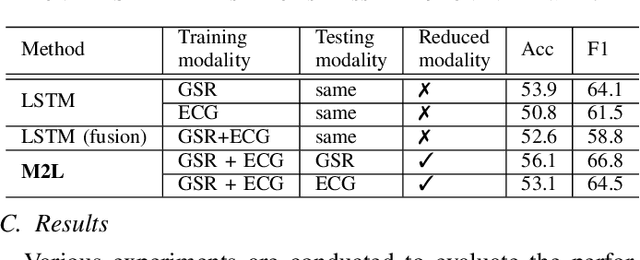
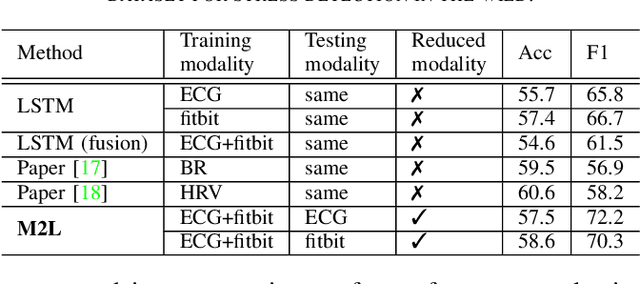
Accurately recognizing health-related conditions from wearable data is crucial for improved healthcare outcomes. To improve the recognition accuracy, various approaches have focused on how to effectively fuse information from multiple sensors. Fusing multiple sensors is a common scenario in many applications, but may not always be feasible in real-world scenarios. For example, although combining bio-signals from multiple sensors (i.e., a chest pad sensor and a wrist wearable sensor) has been proved effective for improved performance, wearing multiple devices might be impractical in the free-living context. To solve the challenges, we propose an effective more to less (M2L) learning framework to improve testing performance with reduced sensors through leveraging the complementary information of multiple modalities during training. More specifically, different sensors may carry different but complementary information, and our model is designed to enforce collaborations among different modalities, where positive knowledge transfer is encouraged and negative knowledge transfer is suppressed, so that better representation is learned for individual modalities. Our experimental results show that our framework achieves comparable performance when compared with the full modalities. Our code and results will be available at https://github.com/compwell-org/More2Less.git.
EntSUM: A Data Set for Entity-Centric Summarization
Apr 05, 2022
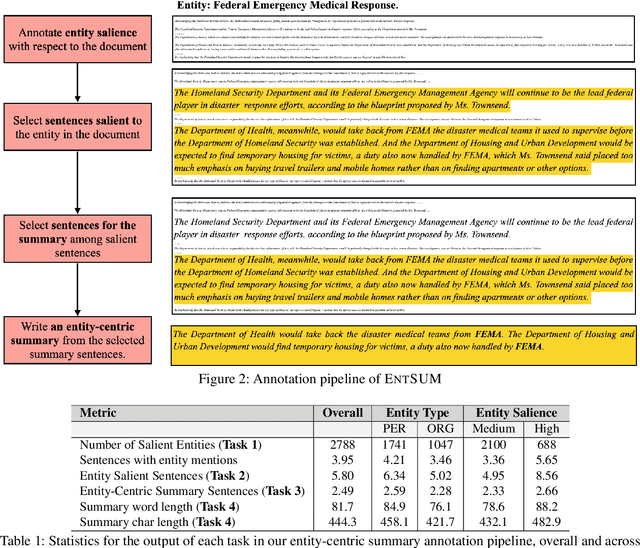

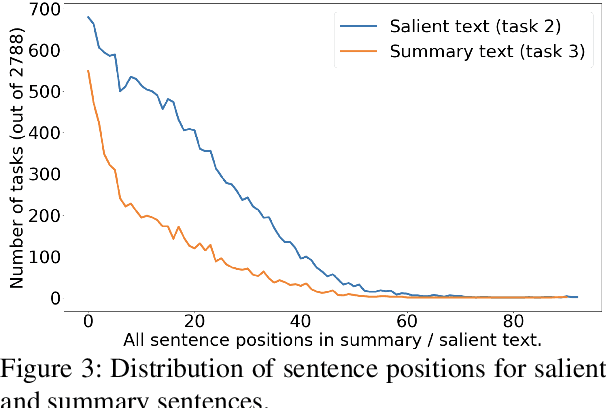
Controllable summarization aims to provide summaries that take into account user-specified aspects and preferences to better assist them with their information need, as opposed to the standard summarization setup which build a single generic summary of a document. We introduce a human-annotated data set EntSUM for controllable summarization with a focus on named entities as the aspects to control. We conduct an extensive quantitative analysis to motivate the task of entity-centric summarization and show that existing methods for controllable summarization fail to generate entity-centric summaries. We propose extensions to state-of-the-art summarization approaches that achieve substantially better results on our data set. Our analysis and results show the challenging nature of this task and of the proposed data set.
Beam Management with Orientation and RSRP using Deep Learning for Beyond 5G Systems
Feb 04, 2022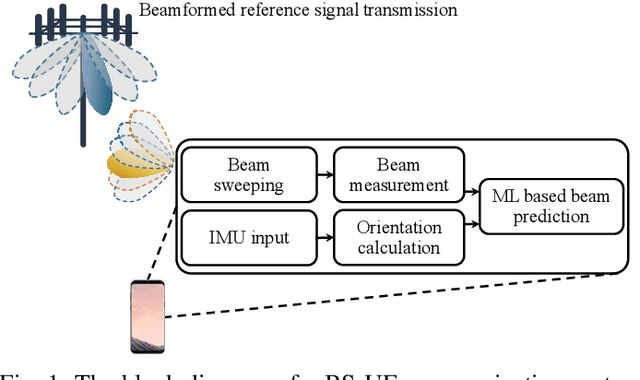
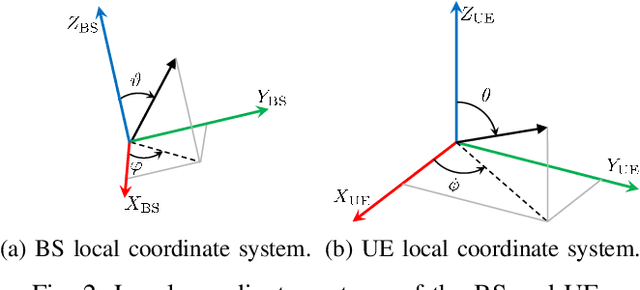

Beam management (BM), i.e., the process of finding and maintaining a suitable transmit and receive beam pair, can be challenging, particularly in highly dynamic scenarios. Side-information, e.g., orientation, from on-board sensors can assist the user equipment (UE) BM. In this work, we use the orientation information coming from the inertial measurement unit (IMU) for effective BM. We use a data-driven strategy that fuses the reference signal received power (RSRP) with orientation information using a recurrent neural network (RNN). Simulation results show that the proposed strategy performs much better than the conventional BM and an orientation-assisted BM strategy that utilizes particle filter in another study. Specifically, the proposed data-driven strategy improves the beam-prediction accuracy up to 34% and increases mean RSRP by up to 4.2 dB when the UE orientation changes quickly.
Guiding Attention using Partial-Order Relationships for Image Captioning
Apr 15, 2022
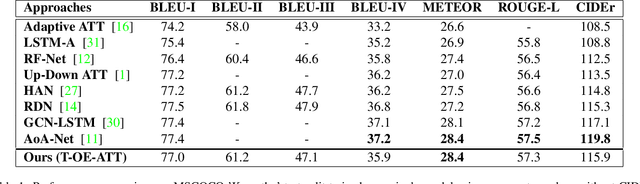
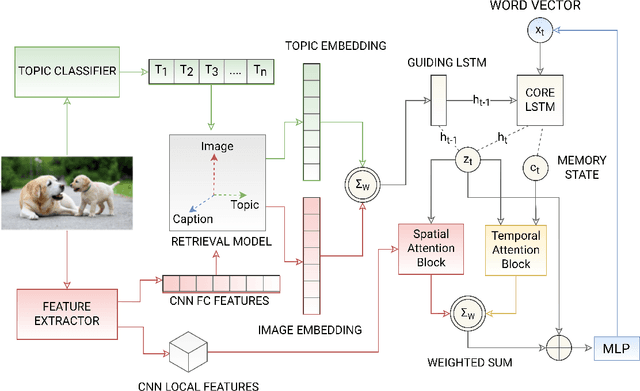
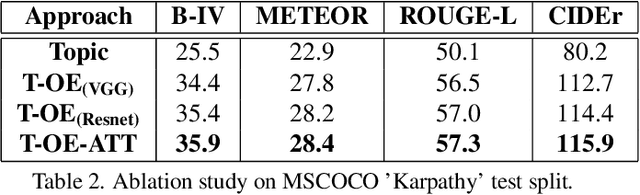
The use of attention models for automated image captioning has enabled many systems to produce accurate and meaningful descriptions for images. Over the years, many novel approaches have been proposed to enhance the attention process using different feature representations. In this paper, we extend this approach by creating a guided attention network mechanism, that exploits the relationship between the visual scene and text-descriptions using spatial features from the image, high-level information from the topics, and temporal context from caption generation, which are embedded together in an ordered embedding space. A pairwise ranking objective is used for training this embedding space which allows similar images, topics and captions in the shared semantic space to maintain a partial order in the visual-semantic hierarchy and hence, helps the model to produce more visually accurate captions. The experimental results based on MSCOCO dataset shows the competitiveness of our approach, with many state-of-the-art models on various evaluation metrics.
Blind Source Separation for Mixture of Sinusoids with Near-Linear Computational Complexity
Mar 27, 2022We propose a multi-tone decomposition algorithm that can find the frequencies, amplitudes and phases of the fundamental sinusoids in a noisy observation sequence. Under independent identically distributed Gaussian noise, our method utilizes a maximum likelihood approach to estimate the relevant tone parameters from the contaminated observations. When estimating $M$ number of sinusoidal sources, our algorithm successively estimates their frequencies and jointly optimizes their amplitudes and phases. Our method can also be implemented as a blind source separator in the absence of the information about $M$. The computational complexity of our algorithm is near-linear, i.e., $\tilde{O}(N)$.
High-Rate Quantum Private Information Retrieval with Weakly Self-Dual Star Product Codes
Feb 04, 2021
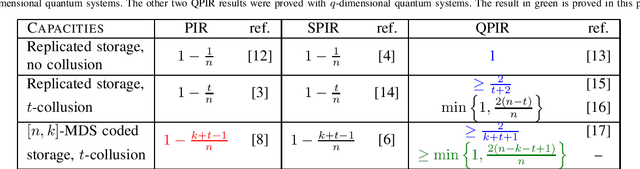
In the classical private information retrieval (PIR) setup, a user wants to retrieve a file from a database or a distributed storage system (DSS) without revealing the file identity to the servers holding the data. In the quantum PIR (QPIR) setting, a user privately retrieves a classical file by receiving quantum information from the servers. The QPIR problem has been treated by Song et al. in the case of replicated servers, both with and without collusion. QPIR over $[n,k]$ maximum distance separable (MDS) coded servers was recently considered by Allaix et al., but the collusion was essentially restricted to $t=n-k$ servers. In this paper, the QPIR setting is extended to account for more flexible collusion of servers satisfying $t < n-k+1$. Similarly to the previous cases, the rates achieved are better than those known or conjectured in the classical counterparts, as well as those of the previously proposed coded and colluding QPIR schemes. This is enabled by considering the stabilizer formalism and weakly self-dual generalized Reed--Solomon (GRS) star product codes.