 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Selective Information Passing for MR/CT Image Segmentation
Oct 10, 2020
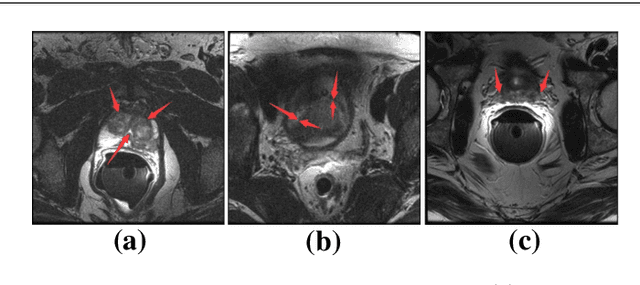
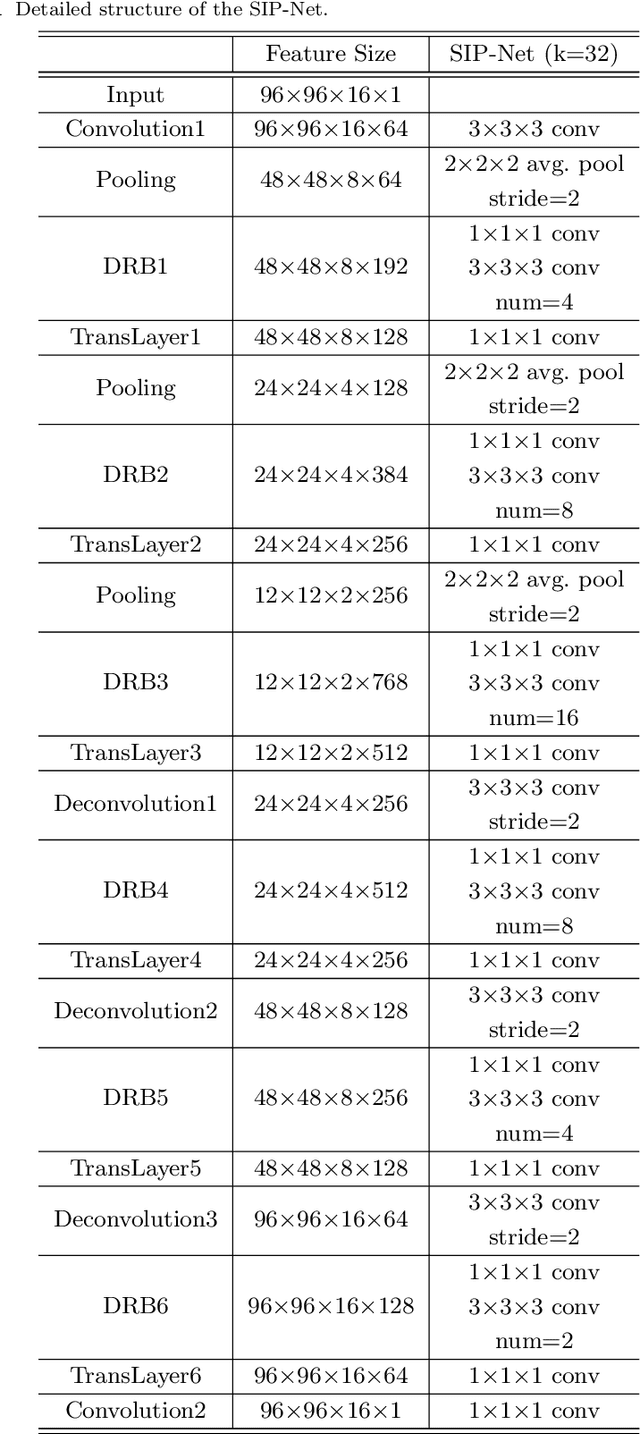
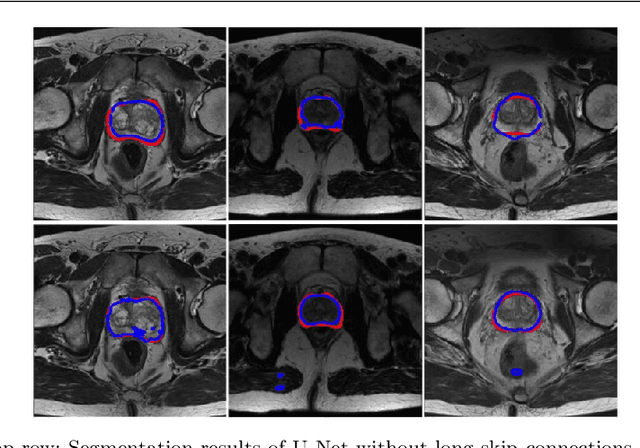
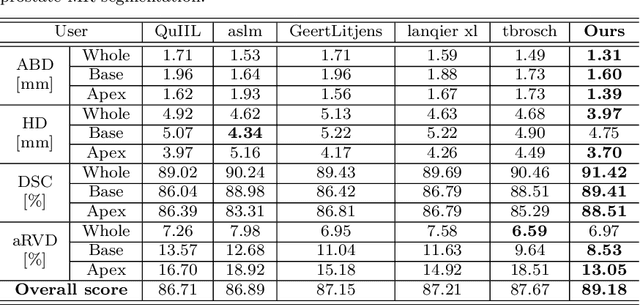
Automated medical image segmentation plays an important role in many clinical applications, which however is a very challenging task, due to complex background texture, lack of clear boundary and significant shape and texture variation between images. Many researchers proposed an encoder-decoder architecture with skip connections to combine low-level feature maps from the encoder path with high-level feature maps from the decoder path for automatically segmenting medical images. The skip connections have been shown to be effective in recovering fine-grained details of the target objects and may facilitate the gradient back-propagation. However, not all the feature maps transmitted by those connections contribute positively to the network performance. In this paper, to adaptively select useful information to pass through those skip connections, we propose a novel 3D network with self-supervised function, named selective information passing network (SIP-Net). We evaluate our proposed model on the MICCAI Prostate MR Image Segmentation 2012 Grant Challenge dataset, TCIA Pancreas CT-82 and MICCAI 2017 Liver Tumor Segmentation (LiTS) Challenge dataset. The experimental results across these data sets show that our model achieved improved segmentation results and outperformed other state-of-the-art methods. The source code of this work is available at https://github.com/ahukui/SIPNet.
Wind power predictions from nowcasts to 4-hour forecasts: a learning approach with variable selection
Apr 20, 2022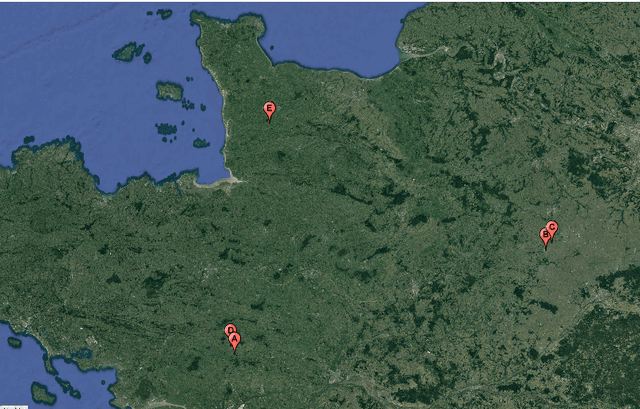

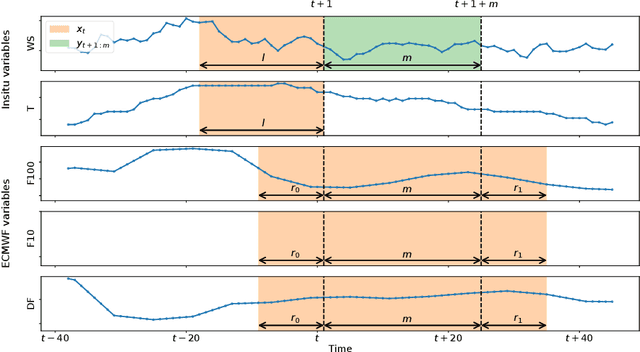
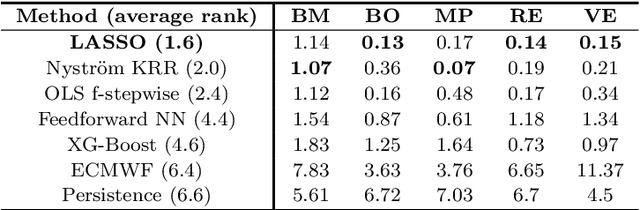
We study the prediction of short term wind speed and wind power (every 10 minutes up to 4 hours ahead). Accurate forecasts for those quantities are crucial to mitigate the negative effects of wind farms' intermittent production on energy systems and markets. For those time scales, outputs of numerical weather prediction models are usually overlooked even though they should provide valuable information on higher scales dynamics. In this work, we combine those outputs with local observations using machine learning. So as to make the results usable for practitioners, we focus on simple and well known methods which can handle a high volume of data. We study first variable selection through two simple techniques, a linear one and a nonlinear one. Then we exploit those results to forecast wind speed and wind power still with an emphasis on linear models versus nonlinear ones. For the wind power prediction, we also compare the indirect approach (wind speed predictions passed through a power curve) and the indirect one (directly predict wind power).
DL4SciVis: A State-of-the-Art Survey on Deep Learning for Scientific Visualization
Apr 13, 2022



Since 2016, we have witnessed the tremendous growth of artificial intelligence+visualization (AI+VIS) research. However, existing survey papers on AI+VIS focus on visual analytics and information visualization, not scientific visualization (SciVis). In this paper, we survey related deep learning (DL) works in SciVis, specifically in the direction of DL4SciVis: designing DL solutions for solving SciVis problems. To stay focused, we primarily consider works that handle scalar and vector field data but exclude mesh data. We classify and discuss these works along six dimensions: domain setting, research task, learning type, network architecture, loss function, and evaluation metric. The paper concludes with a discussion of the remaining gaps to fill along the discussed dimensions and the grand challenges we need to tackle as a community. This state-of-the-art survey guides SciVis researchers in gaining an overview of this emerging topic and points out future directions to grow this research.
Cross-modal Memory Networks for Radiology Report Generation
Apr 28, 2022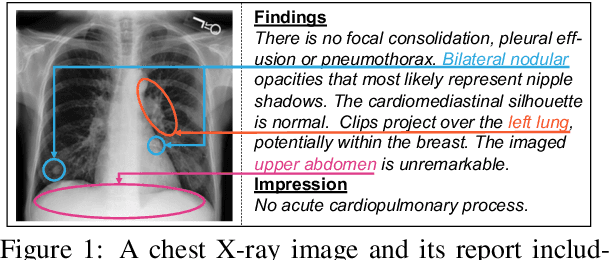
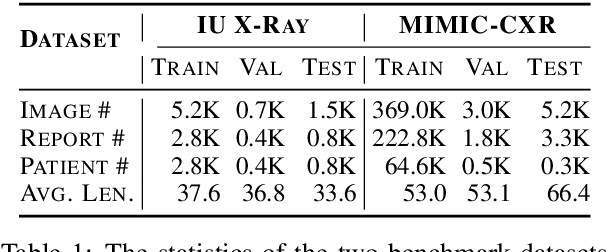
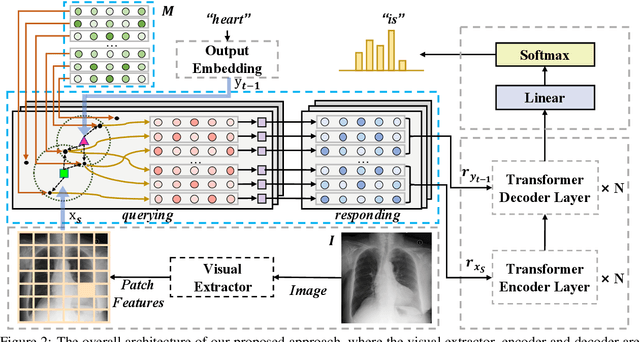
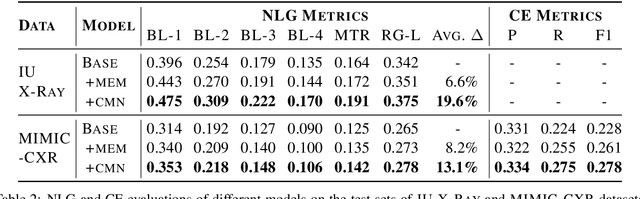
Medical imaging plays a significant role in clinical practice of medical diagnosis, where the text reports of the images are essential in understanding them and facilitating later treatments. By generating the reports automatically, it is beneficial to help lighten the burden of radiologists and significantly promote clinical automation, which already attracts much attention in applying artificial intelligence to medical domain. Previous studies mainly follow the encoder-decoder paradigm and focus on the aspect of text generation, with few studies considering the importance of cross-modal mappings and explicitly exploit such mappings to facilitate radiology report generation. In this paper, we propose a cross-modal memory networks (CMN) to enhance the encoder-decoder framework for radiology report generation, where a shared memory is designed to record the alignment between images and texts so as to facilitate the interaction and generation across modalities. Experimental results illustrate the effectiveness of our proposed model, where state-of-the-art performance is achieved on two widely used benchmark datasets, i.e., IU X-Ray and MIMIC-CXR. Further analyses also prove that our model is able to better align information from radiology images and texts so as to help generating more accurate reports in terms of clinical indicators.
Random Graph Embedding and Joint Sparse Regularization for Multi-label Feature Selection
Apr 13, 2022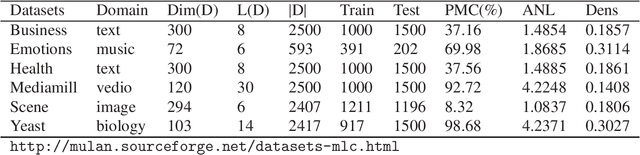
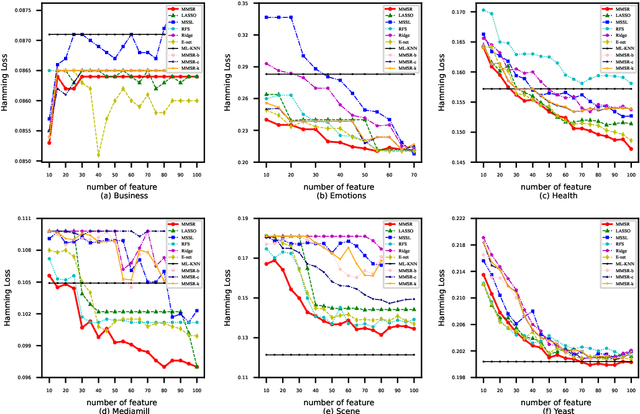

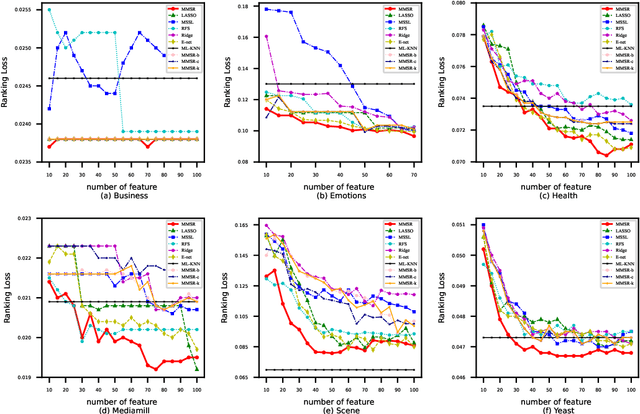
Multi-label learning is often used to mine the correlation between variables and multiple labels, and its research focuses on fully extracting the information between variables and labels. The $\ell_{2,1}$ regularization is often used to get a sparse coefficient matrix, but the problem of multicollinearity among variables cannot be effectively solved. In this paper, the proposed model can choose the most relevant variables by solving a joint constraint optimization problem using the $\ell_{2,1}$ regularization and Frobenius regularization. In manifold regularization, we carry out a random walk strategy based on the joint structure to construct a neighborhood graph, which is highly robust to outliers. In addition, we give an iterative algorithm of the proposed method and proved the convergence of this algorithm. The experiments on the real-world data sets also show that the comprehensive performance of our method is consistently better than the classical method.
Locality Sensitive Hashing for Structured Data: A Survey
Apr 24, 2022
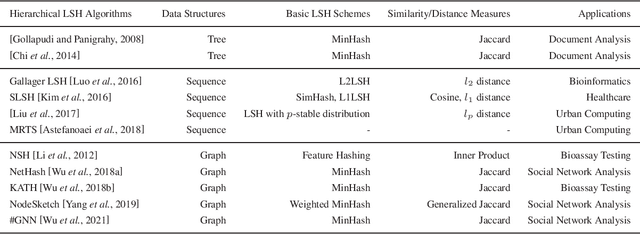

Data similarity (or distance) computation is a fundamental research topic which fosters a variety of similarity-based machine learning and data mining applications. In big data analytics, it is impractical to compute the exact similarity of data instances due to high computational cost. To this end, the Locality Sensitive Hashing (LSH) technique has been proposed to provide accurate estimators for various similarity measures between sets or vectors in an efficient manner without the learning process. Structured data (e.g., sequences, trees and graphs), which are composed of elements and relations between the elements, are commonly seen in the real world, but the traditional LSH algorithms cannot preserve the structure information represented as relations between elements. In order to conquer the issue, researchers have been devoted to the family of the hierarchical LSH algorithms. In this paper, we explore the present progress of the research into hierarchical LSH from the following perspectives: 1) Data structures, where we review various hierarchical LSH algorithms for three typical data structures and uncover their inherent connections; 2) Applications, where we review the hierarchical LSH algorithms in multiple application scenarios; 3) Challenges, where we discuss some potential challenges as future directions.
High-Rate Quantum Private Information Retrieval with Weakly Self-Dual Star Product Codes
Feb 04, 2021
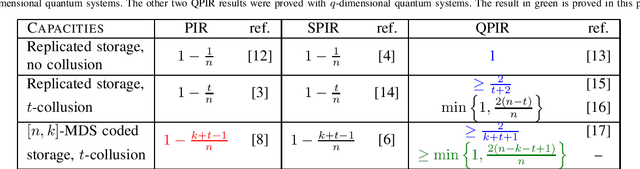
In the classical private information retrieval (PIR) setup, a user wants to retrieve a file from a database or a distributed storage system (DSS) without revealing the file identity to the servers holding the data. In the quantum PIR (QPIR) setting, a user privately retrieves a classical file by receiving quantum information from the servers. The QPIR problem has been treated by Song et al. in the case of replicated servers, both with and without collusion. QPIR over $[n,k]$ maximum distance separable (MDS) coded servers was recently considered by Allaix et al., but the collusion was essentially restricted to $t=n-k$ servers. In this paper, the QPIR setting is extended to account for more flexible collusion of servers satisfying $t < n-k+1$. Similarly to the previous cases, the rates achieved are better than those known or conjectured in the classical counterparts, as well as those of the previously proposed coded and colluding QPIR schemes. This is enabled by considering the stabilizer formalism and weakly self-dual generalized Reed--Solomon (GRS) star product codes.
Visual-based Positioning and Pose Estimation
Apr 20, 2022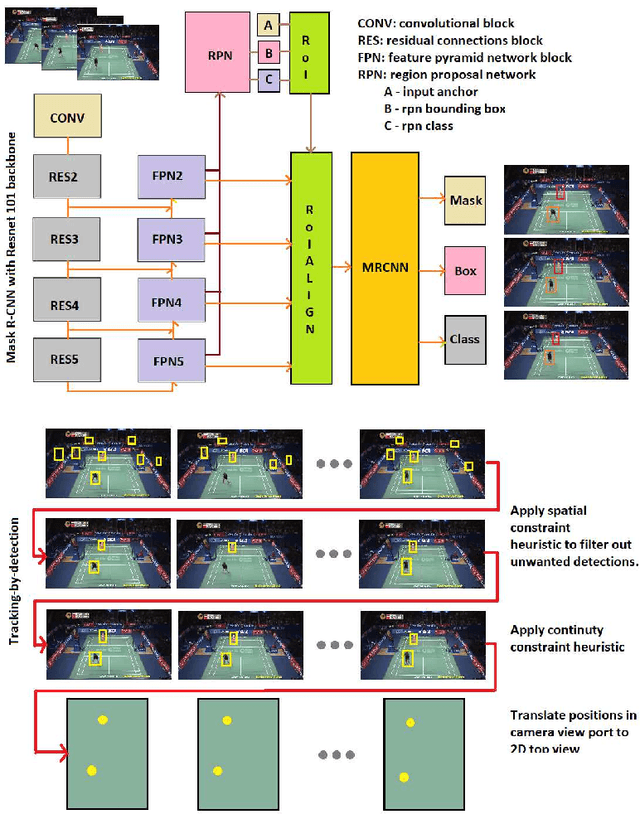
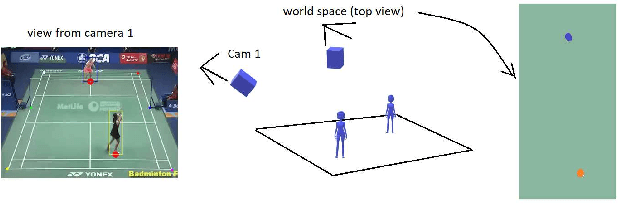
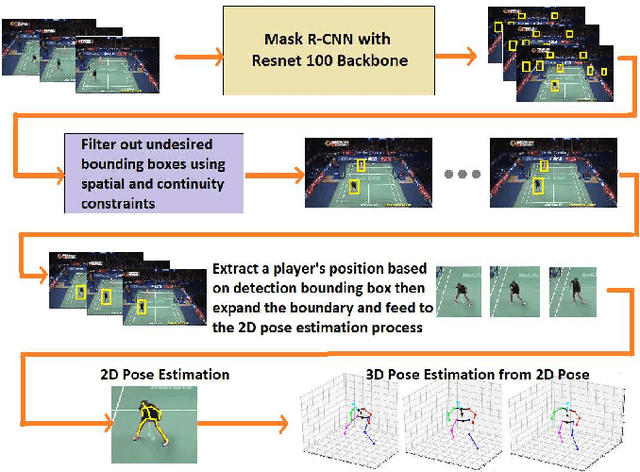
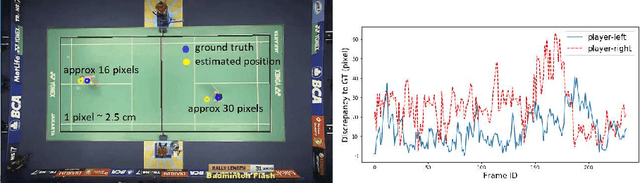
Recent advances in deep learning and computer vision offer an excellent opportunity to investigate high-level visual analysis tasks such as human localization and human pose estimation. Although the performance of human localization and human pose estimation has significantly improved in recent reports, they are not perfect and erroneous localization and pose estimation can be expected among video frames. Studies on the integration of these techniques into a generic pipeline that is robust to noise introduced from those errors are still lacking. This paper fills the missing study. We explored and developed two working pipelines that suited the visual-based positioning and pose estimation tasks. Analyses of the proposed pipelines were conducted on a badminton game. We showed that the concept of tracking by detection could work well, and errors in position and pose could be effectively handled by a linear interpolation technique using information from nearby frames. The results showed that the Visual-based Positioning and Pose Estimation could deliver position and pose estimations with good spatial and temporal resolutions.
KamNet: An Integrated Spatiotemporal Deep Neural Network for Rare Event Search in KamLAND-Zen
Mar 08, 2022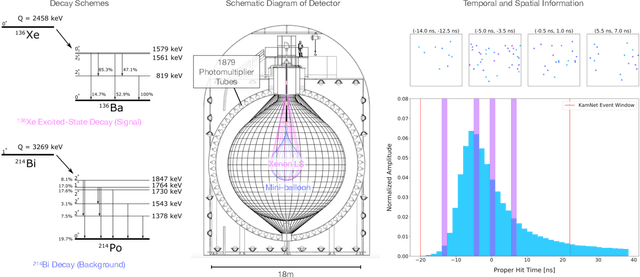
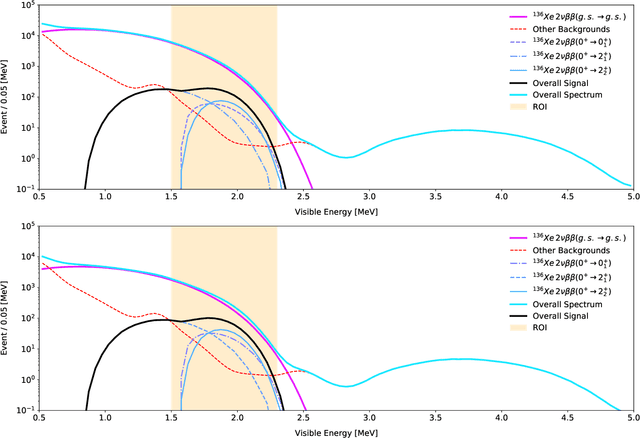
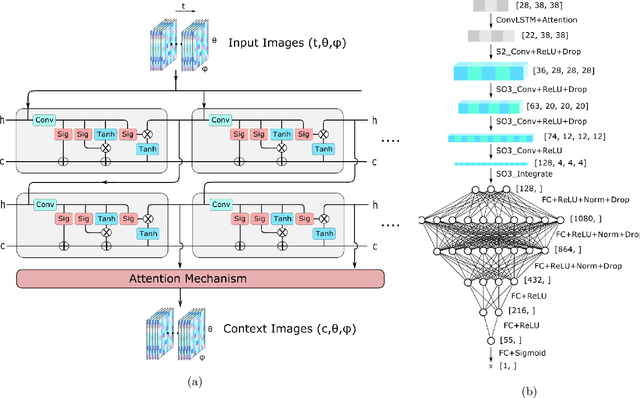
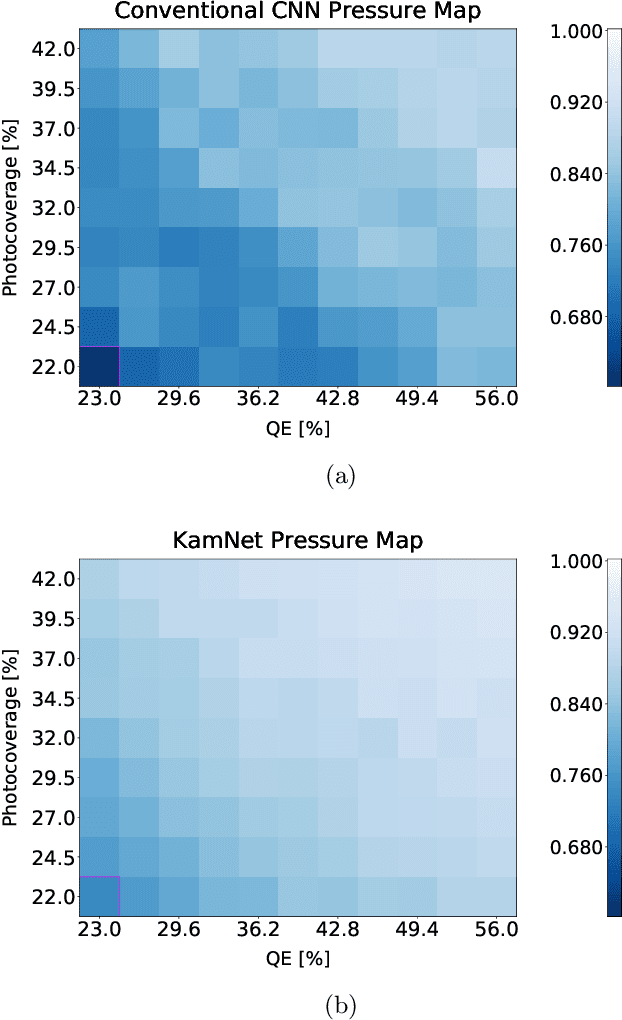
Rare event searches allow us to search for new physics at energy scales inaccessible with other means by leveraging specialized large-mass detectors. Machine learning provides a new tool to maximize the information provided by these detectors. The information is sparse, which forces these algorithms to start from the lowest level data and exploit all symmetries in the detector to produce results. In this work we present KamNet which harnesses breakthroughs in geometric deep learning and spatiotemporal data analysis to maximize the physics reach of KamLAND-Zen, a kiloton scale spherical liquid scintillator detector searching for neutrinoless double beta decay ($0\nu\beta\beta$). Using a simplified background model for KamLAND we show that KamNet outperforms a conventional CNN on benchmarking MC simulations with an increasing level of robustness. Using simulated data, we then demonstrate KamNet's ability to increase KamLAND-Zen's sensitivity to $0\nu\beta\beta$ and $0\nu\beta\beta$ to excited states. A key component of this work is the addition of an attention mechanism to elucidate the underlying physics KamNet is using for the background rejection.
ACVNet: Attention Concatenation Volume for Accurate and Efficient Stereo Matching
Mar 04, 2022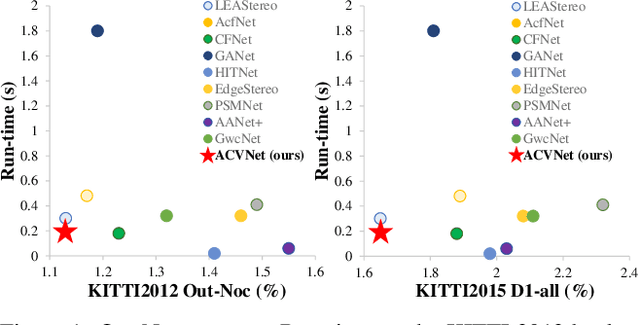
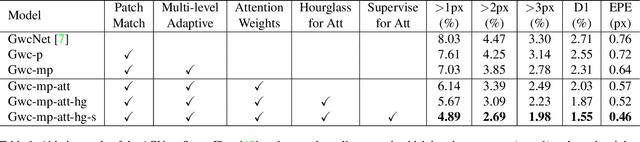
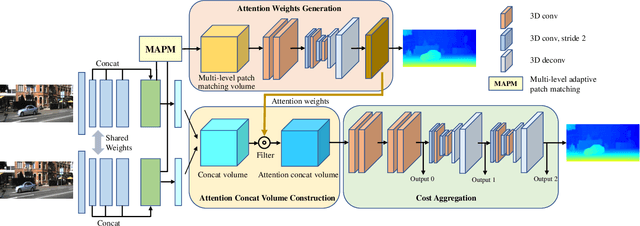
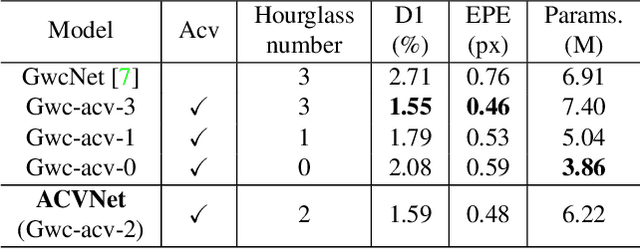
Stereo matching is a fundamental building block for many vision and robotics applications. An informative and concise cost volume representation is vital for stereo matching of high accuracy and efficiency. In this paper, we present a novel cost volume construction method which generates attention weights from correlation clues to suppress redundant information and enhance matching-related information in the concatenation volume. To generate reliable attention weights, we propose multi-level adaptive patch matching to improve the distinctiveness of the matching cost at different disparities even for textureless regions. The proposed cost volume is named attention concatenation volume (ACV) which can be seamlessly embedded into most stereo matching networks, the resulting networks can use a more lightweight aggregation network and meanwhile achieve higher accuracy, e.g. using only 1/25 parameters of the aggregation network can achieve higher accuracy for GwcNet. Furthermore, we design a highly accurate network (ACVNet) based on our ACV, which achieves state-of-the-art performance on several benchmarks.