 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Model-based Deep Learning Receiver Design for Rate-Splitting Multiple Access
May 02, 2022
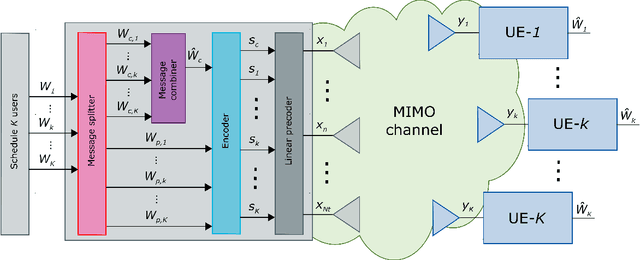
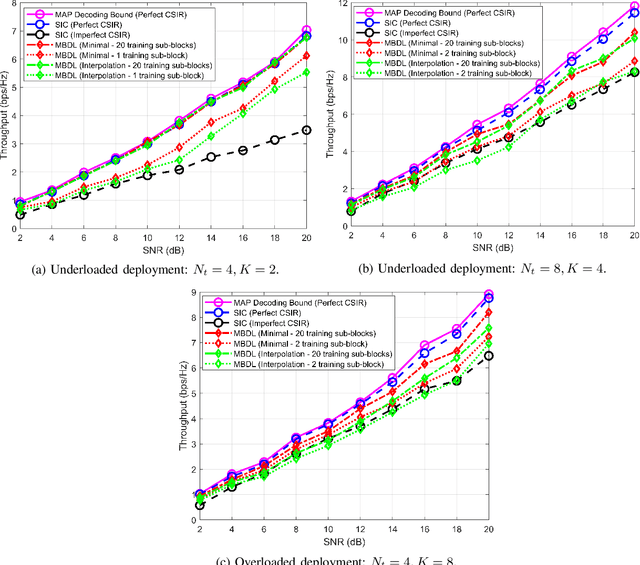
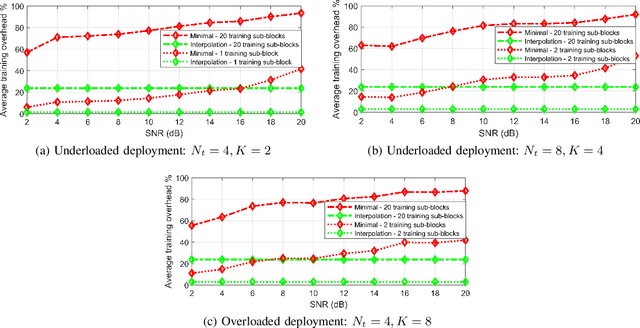
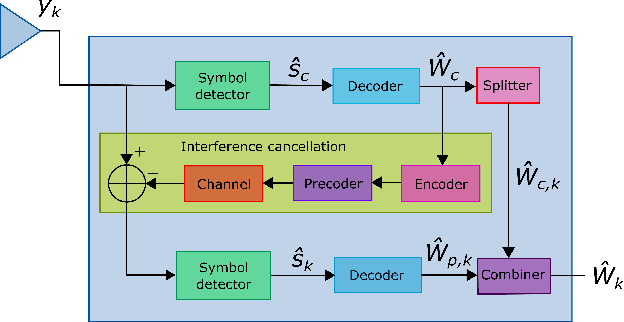
Effective and adaptive interference management is required in next generation wireless communication systems. To address this challenge, Rate-Splitting Multiple Access (RSMA), relying on multi-antenna rate-splitting (RS) at the transmitter and successive interference cancellation (SIC) at the receivers, has been intensively studied in recent years, albeit mostly under the assumption of perfect Channel State Information at the Receiver (CSIR) and ideal capacity-achieving modulation and coding schemes. To assess its practical performance, benefits, and limits under more realistic conditions, this work proposes a novel design for a practical RSMA receiver based on model-based deep learning (MBDL) methods, which aims to unite the simple structure of the conventional SIC receiver and the robustness and model agnosticism of deep learning techniques. The MBDL receiver is evaluated in terms of uncoded Symbol Error Rate (SER), throughput performance through Link-Level Simulations (LLS), and average training overhead. Also, a comparison with the SIC receiver, with perfect and imperfect CSIR, is given. Results reveal that the MBDL outperforms by a significant margin the SIC receiver with imperfect CSIR, due to its ability to generate on demand non-linear symbol detection boundaries in a pure data-driven manner.
A Novel Approach to Fairness in Automated Decision-Making using Affective Normalization
May 02, 2022
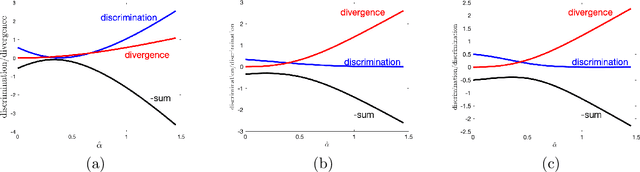
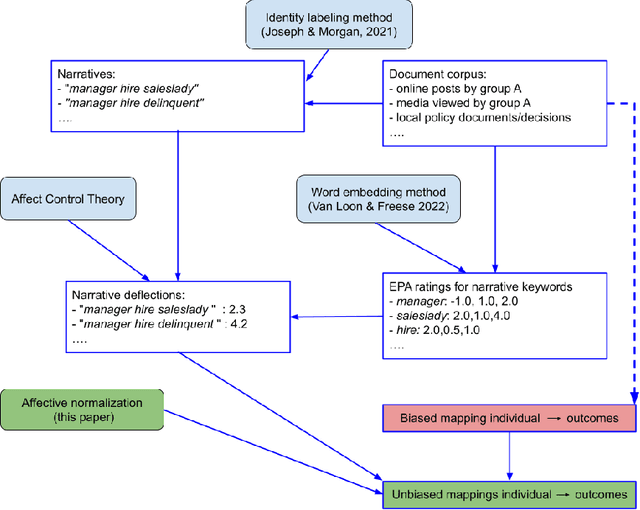
Any decision, such as one about who to hire, involves two components. First, a rational component, i.e., they have a good education, they speak clearly. Second, an affective component, based on observables such as visual features of race and gender, and possibly biased by stereotypes. Here we propose a method for measuring the affective, socially biased, component, thus enabling its removal. That is, given a decision-making process, these affective measurements remove the affective bias in the decision, rendering it fair across a set of categories defined by the method itself. We thus propose that this may solve three key problems in intersectional fairness: (1) the definition of categories over which fairness is a consideration; (2) an infinite regress into smaller and smaller groups; and (3) ensuring a fair distribution based on basic human rights or other prior information. The primary idea in this paper is that fairness biases can be measured using affective coherence, and that this can be used to normalize outcome mappings. We aim for this conceptual work to expose a novel method for handling fairness problems that uses emotional coherence as an independent measure of bias that goes beyond statistical parity.
Learning Future Object Prediction with a Spatiotemporal Detection Transformer
Apr 21, 2022
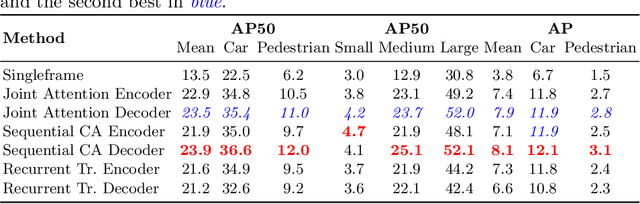
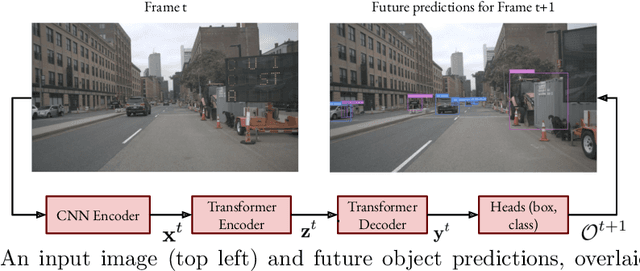
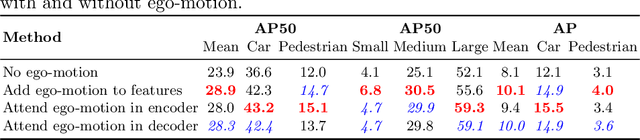
We explore future object prediction -- a challenging problem where all objects visible in a future video frame are to be predicted. We propose to tackle this problem end-to-end by training a detection transformer to directly output future objects. In order to make accurate predictions about the future, it is necessary to capture the dynamics in the scene, both of other objects and of the ego-camera. We extend existing detection transformers in two ways to capture the scene dynamics. First, we experiment with three different mechanisms that enable the model to spatiotemporally process multiple frames. Second, we feed ego-motion information to the model via cross-attention. We show that both of these cues substantially improve future object prediction performance. Our final approach learns to capture the dynamics and make predictions on par with an oracle for 100 ms prediction horizons, and outperform baselines for longer prediction horizons.
Anatomy-aware Self-supervised Learning for Anomaly Detection in Chest Radiographs
May 09, 2022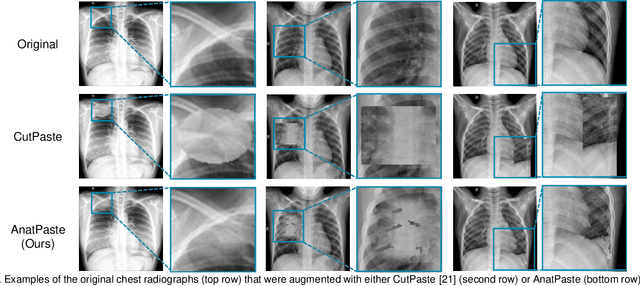
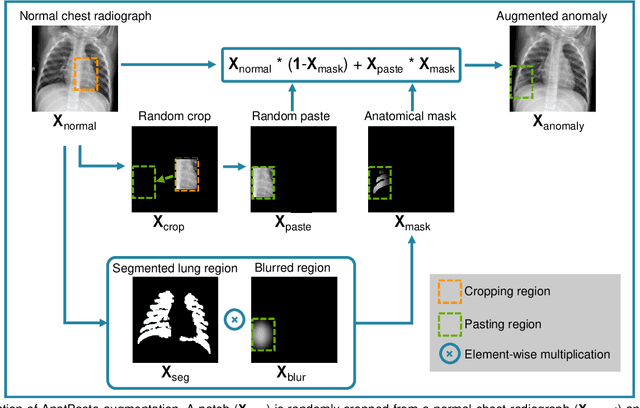
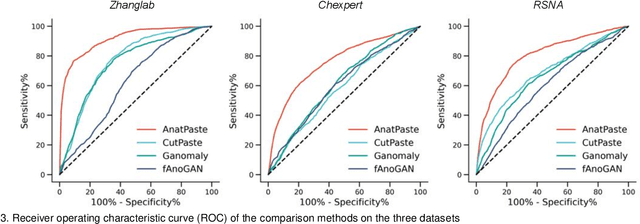
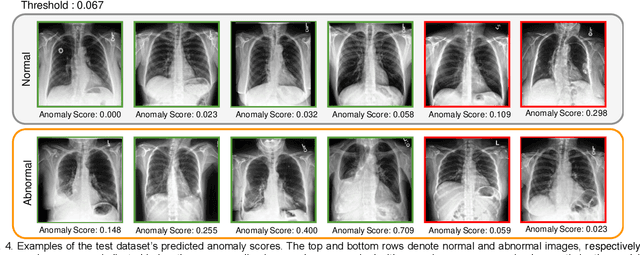
Large numbers of labeled medical images are essential for the accurate detection of anomalies, but manual annotation is labor-intensive and time-consuming. Self-supervised learning (SSL) is a training method to learn data-specific features without manual annotation. Several SSL-based models have been employed in medical image anomaly detection. These SSL methods effectively learn representations in several field-specific images, such as natural and industrial product images. However, owing to the requirement of medical expertise, typical SSL-based models are inefficient in medical image anomaly detection. We present an SSL-based model that enables anatomical structure-based unsupervised anomaly detection (UAD). The model employs the anatomy-aware pasting (AnatPaste) augmentation tool. AnatPaste employs a threshold-based lung segmentation pretext task to create anomalies in normal chest radiographs, which are used for model pretraining. These anomalies are similar to real anomalies and help the model recognize them. We evaluate our model on three opensource chest radiograph datasets. Our model exhibit area under curves (AUC) of 92.1%, 78.7%, and 81.9%, which are the highest among existing UAD models. This is the first SSL model to employ anatomical information as a pretext task. AnatPaste can be applied in various deep learning models and downstream tasks. It can be employed for other modalities by fixing appropriate segmentation. Our code is publicly available at: https://github.com/jun-sato/AnatPaste.
Robust PCA Unrolling Network for Super-resolution Vessel Extraction in X-ray Coronary Angiography
Apr 24, 2022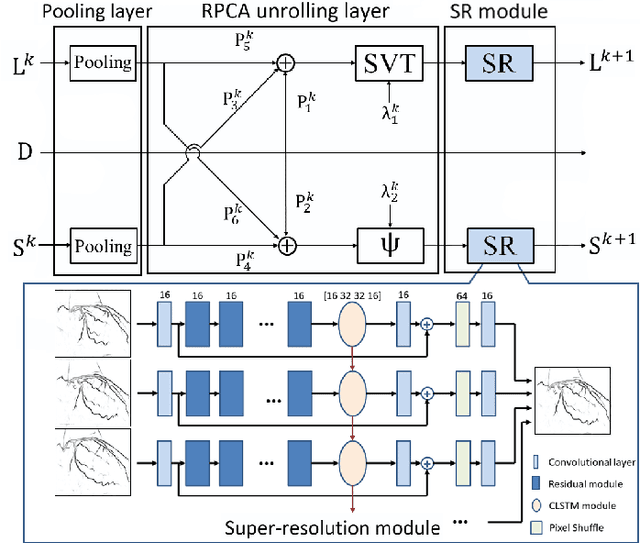
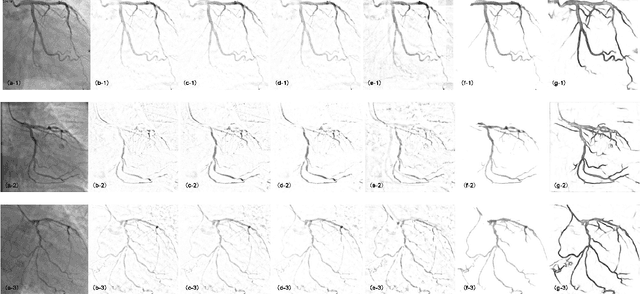

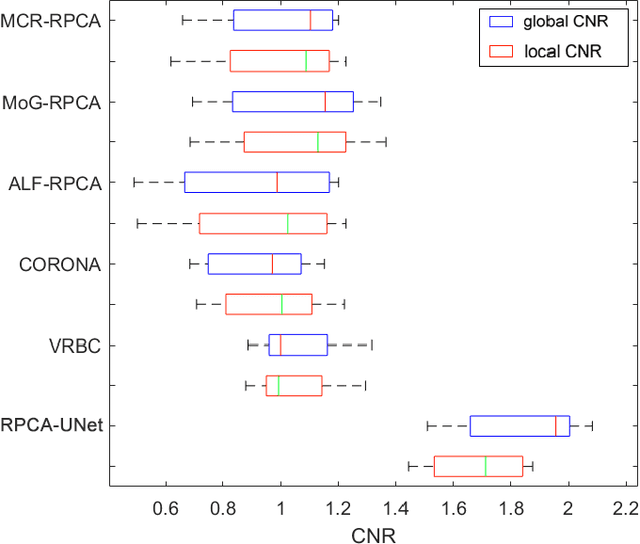
Although robust PCA has been increasingly adopted to extract vessels from X-ray coronary angiography (XCA) images, challenging problems such as inefficient vessel-sparsity modelling, noisy and dynamic background artefacts, and high computational cost still remain unsolved. Therefore, we propose a novel robust PCA unrolling network with sparse feature selection for super-resolution XCA vessel imaging. Being embedded within a patch-wise spatiotemporal super-resolution framework that is built upon a pooling layer and a convolutional long short-term memory network, the proposed network can not only gradually prune complex vessel-like artefacts and noisy backgrounds in XCA during network training but also iteratively learn and select the high-level spatiotemporal semantic information of moving contrast agents flowing in the XCA-imaged vessels. The experimental results show that the proposed method significantly outperforms state-of-the-art methods, especially in the imaging of the vessel network and its distal vessels, by restoring the intensity and geometry profiles of heterogeneous vessels against complex and dynamic backgrounds.
Using segment-based features of jaw movements to recognize foraging activities in grazing cattle
Apr 01, 2022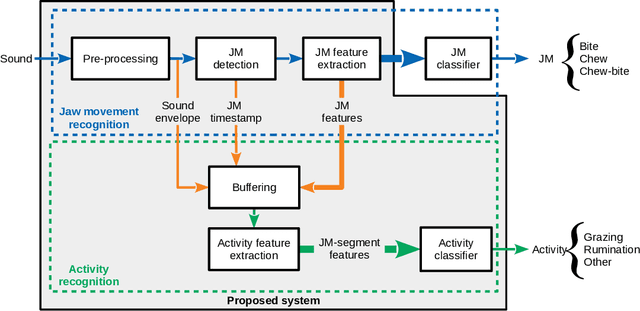

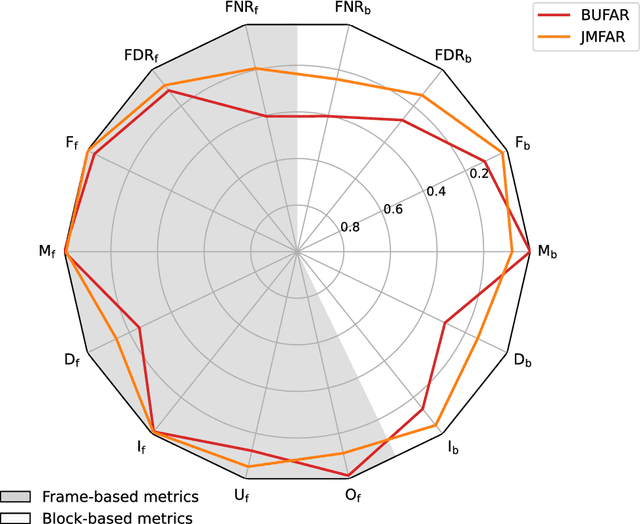
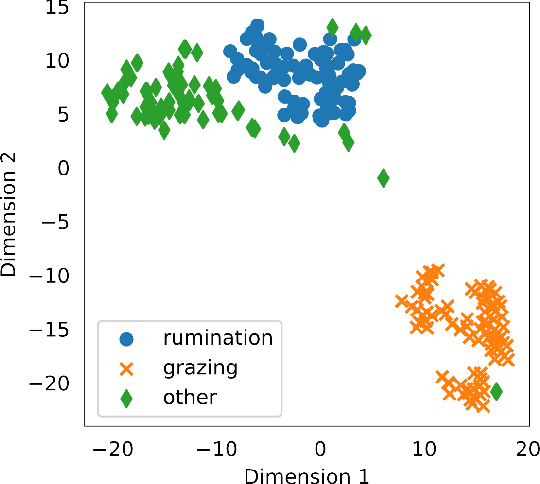
Precision livestock farming optimizes livestock production through the use of sensor information and communication technologies to support decision making, proactively and near real-time. Among available technologies to monitor foraging behavior, the acoustic method has been highly reliable and repeatable, but can be subject to further computational improvements to increase precision and specificity of recognition of foraging activities. In this study, an algorithm called Jaw Movement segment-based Foraging Activity Recognizer (JMFAR) is proposed. The method is based on the computation and analysis of temporal, statistical and spectral features of jaw movement sounds for detection of rumination and grazing bouts. They are called JM-segment features because they are extracted from a sound segment and expect to capture JM information of the whole segment rather than individual JMs. Two variants of the method are proposed and tested: (i) the temporal and statistical features only JMFAR-ns; and (ii) a feature selection process (JMFAR-sel). The JMFAR was tested on signals registered in a free grazing environment, achieving an average weighted F1-score greater than 95%. Then, it was compared with a state-of-the-art algorithm, showing improved performance for estimation of grazing bouts (+19%). The JMFAR-ns variant reduced the computational cost by 25.4%, but achieved a slightly lower performance than the JMFAR. The good performance and low computational cost of JMFAR-ns supports the feasibility of using this algorithm variant for real-time implementation in low-cost embedded systems.
Federated Learning on Heterogeneous and Long-Tailed Data via Classifier Re-Training with Federated Features
Apr 28, 2022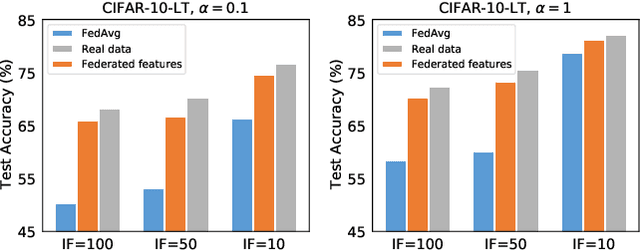
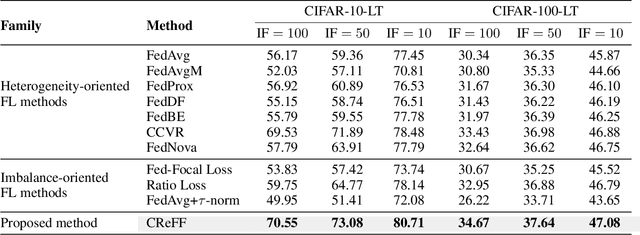
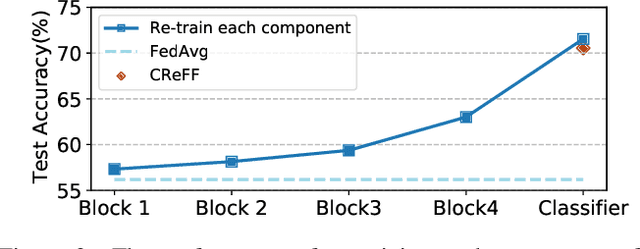
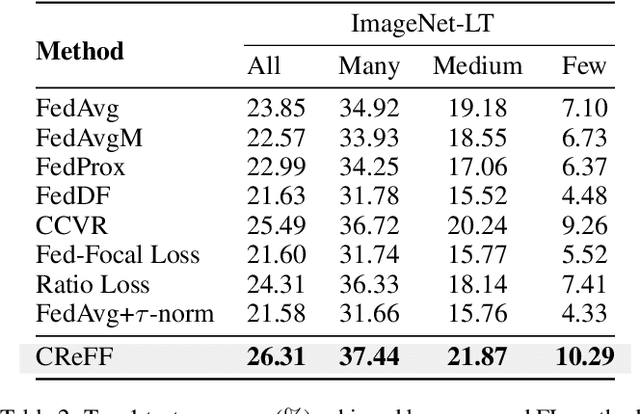
Federated learning (FL) provides a privacy-preserving solution for distributed machine learning tasks. One challenging problem that severely damages the performance of FL models is the co-occurrence of data heterogeneity and long-tail distribution, which frequently appears in real FL applications. In this paper, we reveal an intriguing fact that the biased classifier is the primary factor leading to the poor performance of the global model. Motivated by the above finding, we propose a novel and privacy-preserving FL method for heterogeneous and long-tailed data via Classifier Re-training with Federated Features (CReFF). The classifier re-trained on federated features can produce comparable performance as the one re-trained on real data in a privacy-preserving manner without information leakage of local data or class distribution. Experiments on several benchmark datasets show that the proposed CReFF is an effective solution to obtain a promising FL model under heterogeneous and long-tailed data. Comparative results with the state-of-the-art FL methods also validate the superiority of CReFF. Our code is available at https://github.com/shangxinyi/CReFF-FL.
Multi-view Point Cloud Registration based on Evolutionary Multitasking with Bi-Channel Knowledge Sharing Mechanism
May 06, 2022
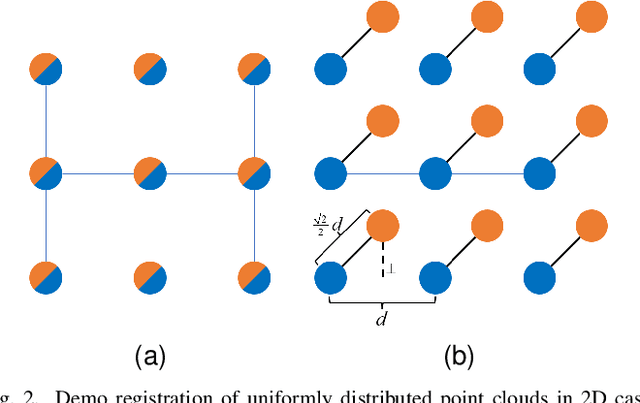
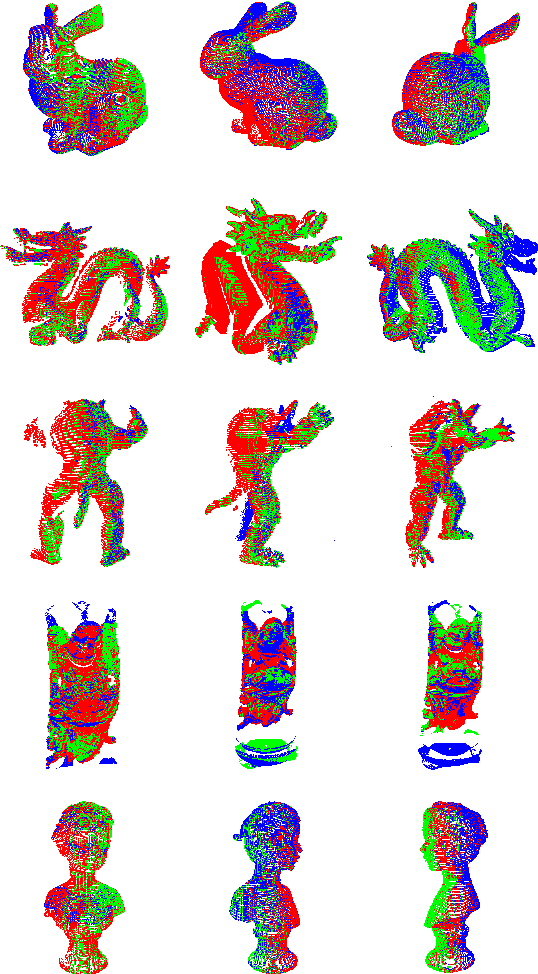

Registration of multi-view point clouds is fundamental in 3D reconstruction. Since there are close connections between point clouds captured from different viewpoints, registration performance can be enhanced if these connections be harnessed properly. Therefore, this paper models the registration problem as multi-task optimization, and proposes a novel bi-channel knowledge sharing mechanism for effective and efficient problem solving. The modeling of multi-view point cloud registration as multi-task optimization are twofold. By simultaneously considering the local accuracy of two point clouds as well as the global consistency posed by all the point clouds involved, a fitness function with an adaptive threshold is derived. Also a framework of the co-evolutionary search process is defined for the concurrent optimization of multiple fitness functions belonging to related tasks. To enhance solution quality and convergence speed, the proposed bi-channel knowledge sharing mechanism plays its role. The intra-task knowledge sharing introduces aiding tasks that are much simpler to solve, and useful information is shared within tasks, accelerating the search process. The inter-task knowledge sharing explores commonalities buried among tasks, aiming to prevent tasks from getting stuck to local optima. Comprehensive experiments conducted on model object as well as scene point clouds show the efficacy of the proposed method.
Property Unlearning: A Defense Strategy Against Property Inference Attacks
May 18, 2022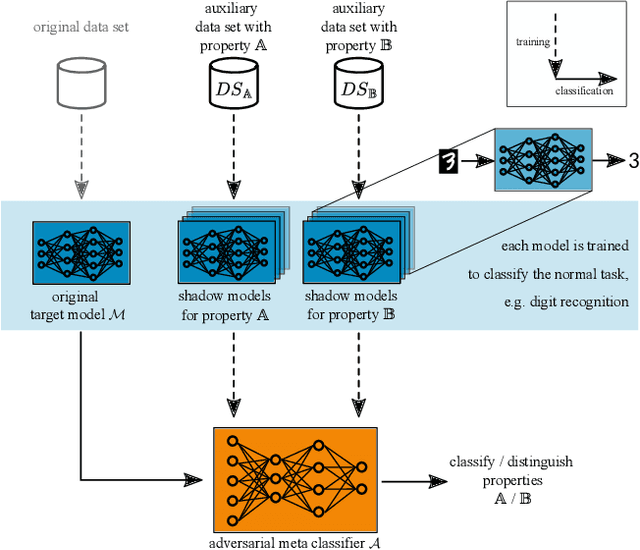
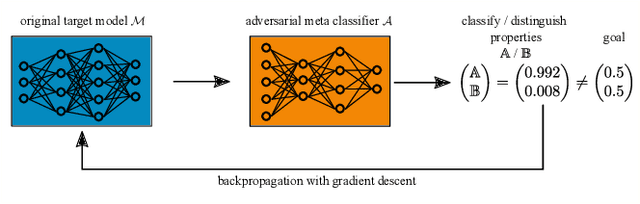
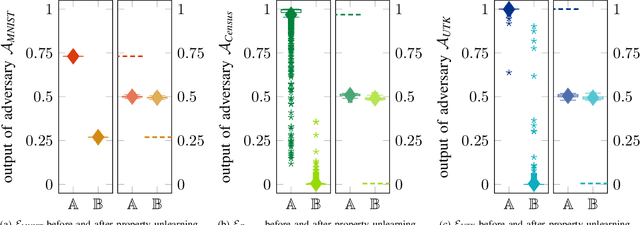
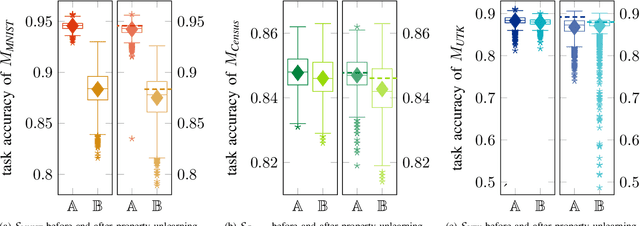
During the training of machine learning models, they may store or "learn" more information about the training data than what is actually needed for the prediction or classification task. This is exploited by property inference attacks which aim at extracting statistical properties from the training data of a given model without having access to the training data itself. These properties may include the quality of pictures to identify the camera model, the age distribution to reveal the target audience of a product, or the included host types to refine a malware attack in computer networks. This attack is especially accurate when the attacker has access to all model parameters, i.e., in a white-box scenario. By defending against such attacks, model owners are able to ensure that their training data, associated properties, and thus their intellectual property stays private, even if they deliberately share their models, e.g., to train collaboratively, or if models are leaked. In this paper, we introduce property unlearning, an effective defense mechanism against white-box property inference attacks, independent of the training data type, model task, or number of properties. Property unlearning mitigates property inference attacks by systematically changing the trained weights and biases of a target model such that an adversary cannot extract chosen properties. We empirically evaluate property unlearning on three different data sets, including tabular and image data, and two types of artificial neural networks. Our results show that property unlearning is both efficient and reliable to protect machine learning models against property inference attacks, with a good privacy-utility trade-off. Furthermore, our approach indicates that this mechanism is also effective to unlearn multiple properties.
A Thin Format Vision-Based Tactile Sensor with A Micro Lens Array (MLA)
Apr 19, 2022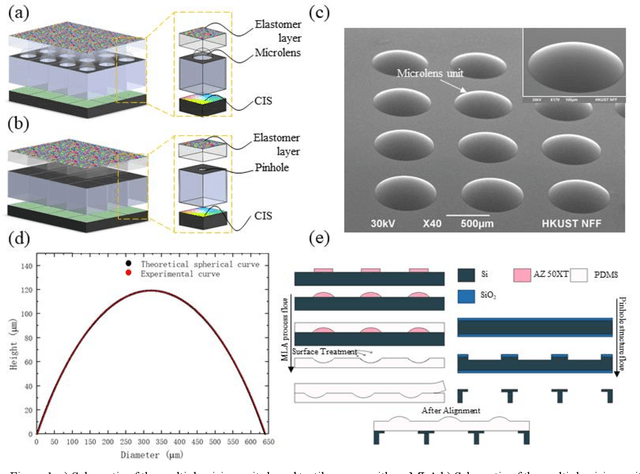
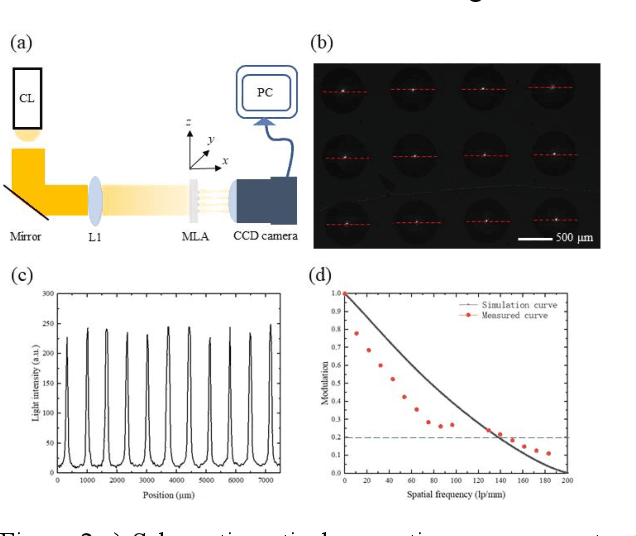
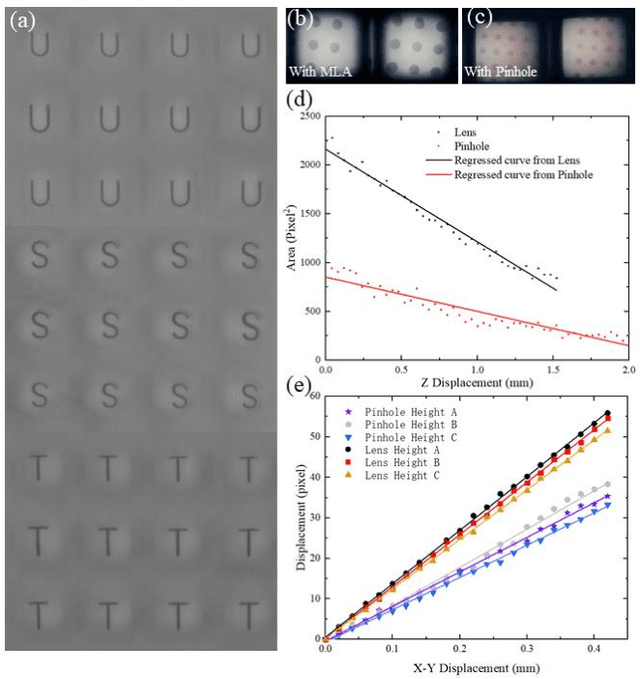
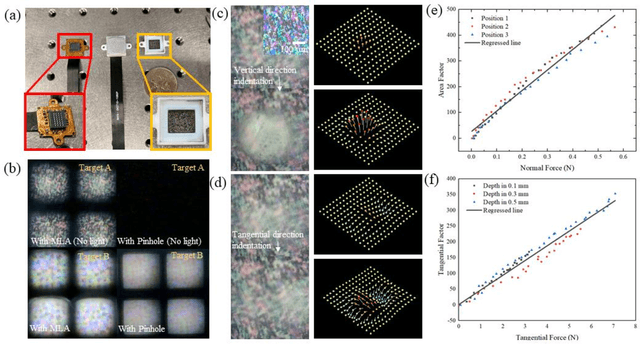
Vision-based tactile sensors have been widely studied in the robotics field for high spatial resolution and compatibility with machine learning algorithms. However, the currently employed sensor's imaging system is bulky limiting its further application. Here we present a micro lens array (MLA) based vison system to achieve a low thickness format of the sensor package with high tactile sensing performance. Multiple micromachined micro lens units cover the whole elastic touching layer and provide a stitched clear tactile image, enabling high spatial resolution with a thin thickness of 5 mm. The thermal reflow and soft lithography method ensure the uniform spherical profile and smooth surface of micro lens. Both optical and mechanical characterization demonstrated the sensor's stable imaging and excellent tactile sensing, enabling precise 3D tactile information, such as displacement mapping and force distribution with an ultra compact-thin structure.