 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning to Bid Long-Term: Multi-Agent Reinforcement Learning with Long-Term and Sparse Reward in Repeated Auction Games
Apr 05, 2022
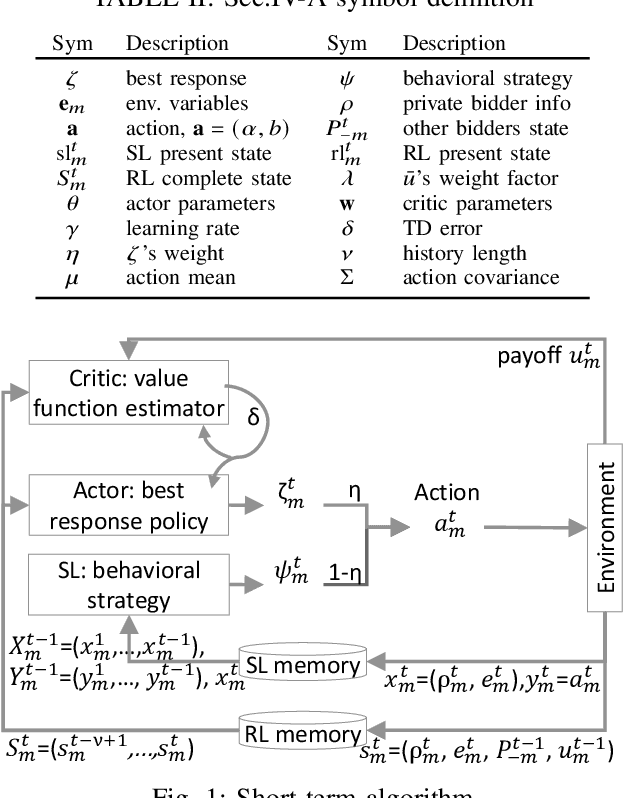
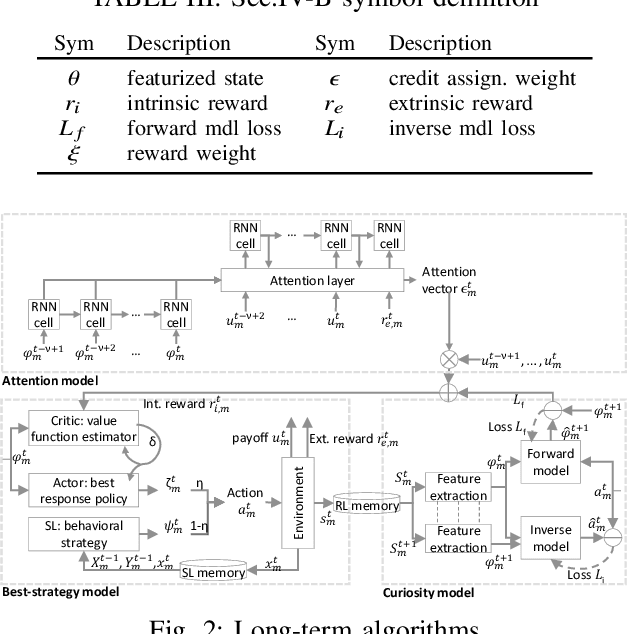
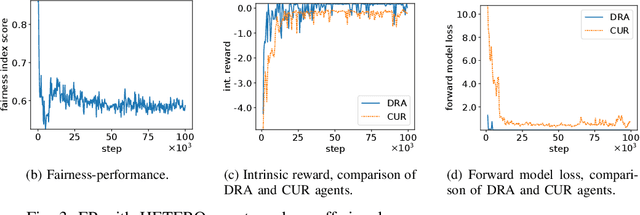
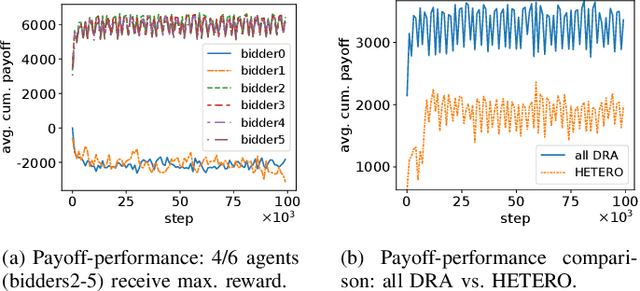
We propose a multi-agent distributed reinforcement learning algorithm that balances between potentially conflicting short-term reward and sparse, delayed long-term reward, and learns with partial information in a dynamic environment. We compare different long-term rewards to incentivize the algorithm to maximize individual payoff and overall social welfare. We test the algorithm in two simulated auction games, and demonstrate that 1) our algorithm outperforms two benchmark algorithms in a direct competition, with cost to social welfare, and 2) our algorithm's aggressive competitive behavior can be guided with the long-term reward signal to maximize both individual payoff and overall social welfare.
LAMBDA: Covering the Solution Set of Black-Box Inequality by Search Space Quantization
Mar 25, 2022Black-box functions are broadly used to model complex problems that provide no explicit information but the input and output. Despite existing studies of black-box function optimization, the solution set satisfying an inequality with a black-box function plays a more significant role than only one optimum in many practical situations. Covering as much as possible of the solution set through limited evaluations to the black-box objective function is defined as the Black-Box Coverage (BBC) problem in this paper. We formalized this problem in a sample-based search paradigm and constructed a coverage criterion with Confusion Matrix Analysis. Further, we propose LAMBDA (Latent-Action Monte-Carlo Beam Search with Density Adaption) to solve BBC problems. LAMBDA can focus around the solution set quickly by recursively partitioning the search space into accepted and rejected sub-spaces. Compared with La-MCTS, LAMBDA introduces density information to overcome the sampling bias of optimization and obtain more exploration. Benchmarking shows, LAMBDA achieved state-of-the-art performance among all baselines and was at most 33x faster to get 95% coverage than Random Search. Experiments also demonstrate that LAMBDA has a promising future in the verification of autonomous systems in virtual tests.
A Credible and Robust approach to Ego-Motion Estimation using an Automotive Radar
Apr 19, 2022
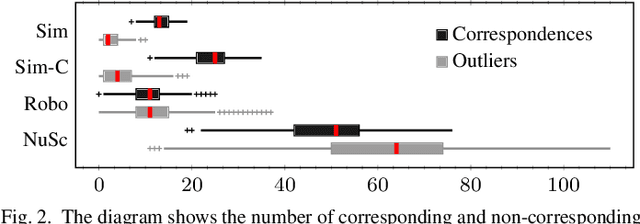

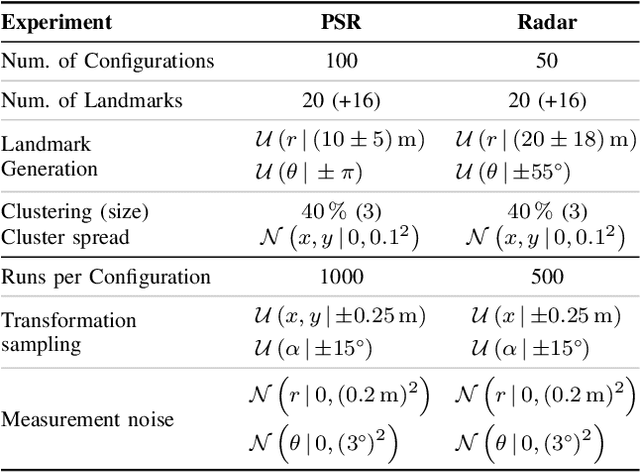
Consistent motion estimation is fundamental for all mobile autonomous systems. While this sounds like an easy task, often, it is not the case because of changing environmental conditions affecting odometry obtained from vision, Lidar, or the wheels themselves. Unsusceptible to challenging lighting and weather conditions, radar sensors are an obvious alternative. Usually, automotive radars return a sparse point cloud, representing the surroundings. Utilizing this information to motion estimation is challenging due to unstable and phantom measurements, which result in a high rate of outliers. We introduce a credible and robust probabilistic approach to estimate the ego-motion based on these challenging radar measurements; intended to be used within a loosely-coupled sensor fusion framework. Compared to existing solutions, evaluated on the popular nuScenes dataset and others, we show that our proposed algorithm is more credible while not depending on explicit correspondence calculation.
Restoring Negative Information in Few-Shot Object Detection
Oct 26, 2020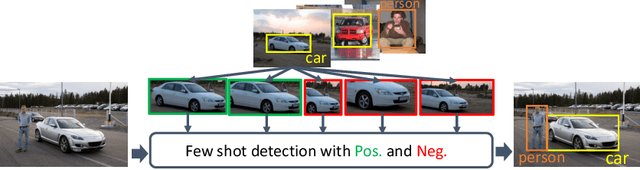
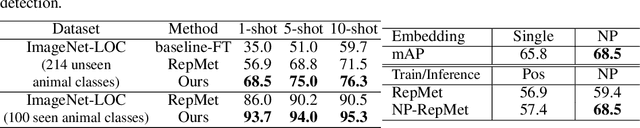
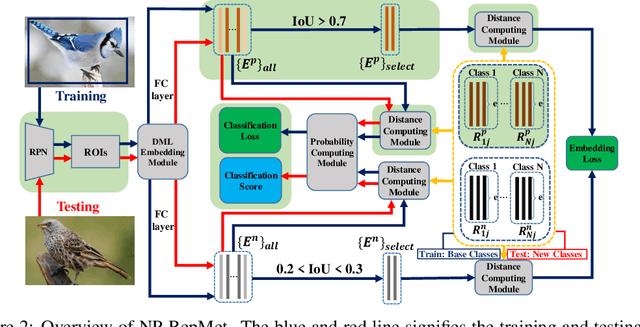

Few-shot learning has recently emerged as a new challenge in the deep learning field: unlike conventional methods that train the deep neural networks (DNNs) with a large number of labeled data, it asks for the generalization of DNNs on new classes with few annotated samples. Recent advances in few-shot learning mainly focus on image classification while in this paper we focus on object detection. The initial explorations in few-shot object detection tend to simulate a classification scenario by using the positive proposals in images with respect to certain object class while discarding the negative proposals of that class. Negatives, especially hard negatives, however, are essential to the embedding space learning in few-shot object detection. In this paper, we restore the negative information in few-shot object detection by introducing a new negative- and positive-representative based metric learning framework and a new inference scheme with negative and positive representatives. We build our work on a recent few-shot pipeline RepMet with several new modules to encode negative information for both training and testing. Extensive experiments on ImageNet-LOC and PASCAL VOC show our method substantially improves the state-of-the-art few-shot object detection solutions. Our code is available at https://github.com/yang-yk/NP-RepMet.
POCD: Probabilistic Object-Level Change Detection and Volumetric Mapping in Semi-Static Scenes
May 02, 2022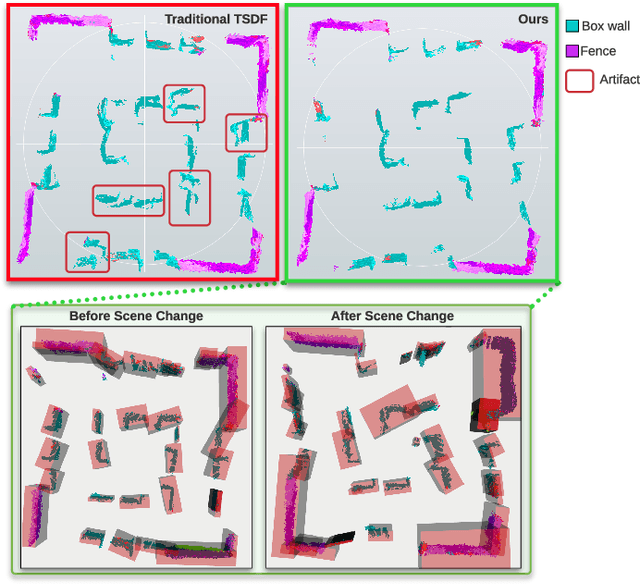
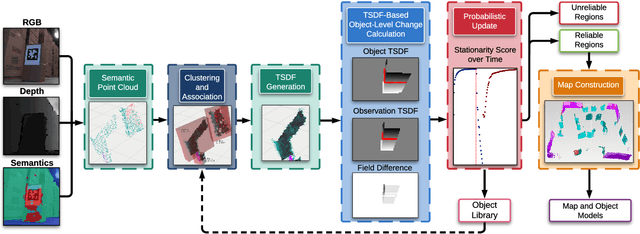

Maintaining an up-to-date map to reflect recent changes in the scene is very important, particularly in situations involving repeated traversals by a robot operating in an environment over an extended period. Undetected changes may cause a deterioration in map quality, leading to poor localization, inefficient operations, and lost robots. Volumetric methods, such as truncated signed distance functions (TSDFs), have quickly gained traction due to their real-time production of a dense and detailed map, though map updating in scenes that change over time remains a challenge. We propose a framework that introduces a novel probabilistic object state representation to track object pose changes in semi-static scenes. The representation jointly models a stationarity score and a TSDF change measure for each object. A Bayesian update rule that incorporates both geometric and semantic information is derived to achieve consistent online map maintenance. To extensively evaluate our approach alongside the state-of-the-art, we release a novel real-world dataset in a warehouse environment. We also evaluate on the public ToyCar dataset. Our method outperforms state-of-the-art methods on the reconstruction quality of semi-static environments.
Learning Causal Overhypotheses through Exploration in Children and Computational Models
Feb 21, 2022

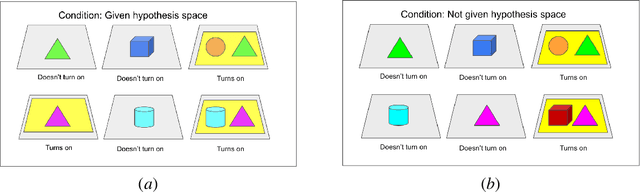

Despite recent progress in reinforcement learning (RL), RL algorithms for exploration still remain an active area of research. Existing methods often focus on state-based metrics, which do not consider the underlying causal structures of the environment, and while recent research has begun to explore RL environments for causal learning, these environments primarily leverage causal information through causal inference or induction rather than exploration. In contrast, human children - some of the most proficient explorers - have been shown to use causal information to great benefit. In this work, we introduce a novel RL environment designed with a controllable causal structure, which allows us to evaluate exploration strategies used by both agents and children in a unified environment. In addition, through experimentation on both computation models and children, we demonstrate that there are significant differences between information-gain optimal RL exploration in causal environments and the exploration of children in the same environments. We conclude with a discussion of how these findings may inspire new directions of research into efficient exploration and disambiguation of causal structures for RL algorithms.
Depth Completion using Geometry-Aware Embedding
Mar 21, 2022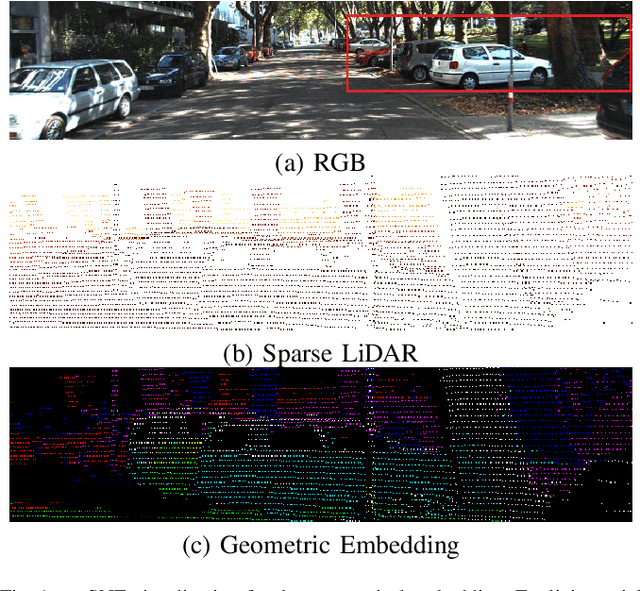

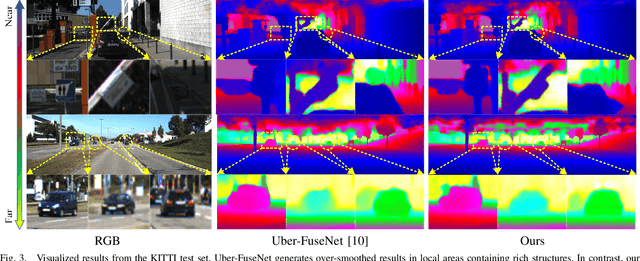
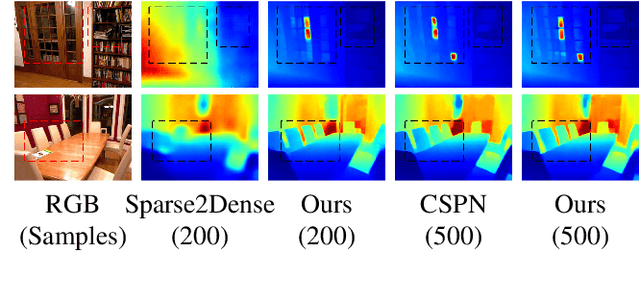
Exploiting internal spatial geometric constraints of sparse LiDARs is beneficial to depth completion, however, has been not explored well. This paper proposes an efficient method to learn geometry-aware embedding, which encodes the local and global geometric structure information from 3D points, e.g., scene layout, object's sizes and shapes, to guide dense depth estimation. Specifically, we utilize the dynamic graph representation to model generalized geometric relationship from irregular point clouds in a flexible and efficient manner. Further, we joint this embedding and corresponded RGB appearance information to infer missing depths of the scene with well structure-preserved details. The key to our method is to integrate implicit 3D geometric representation into a 2D learning architecture, which leads to a better trade-off between the performance and efficiency. Extensive experiments demonstrate that the proposed method outperforms previous works and could reconstruct fine depths with crisp boundaries in regions that are over-smoothed by them. The ablation study gives more insights into our method that could achieve significant gains with a simple design, while having better generalization capability and stability. The code is available at https://github.com/Wenchao-Du/GAENet.
Unsupervised Speech Decomposition via Triple Information Bottleneck
Apr 29, 2020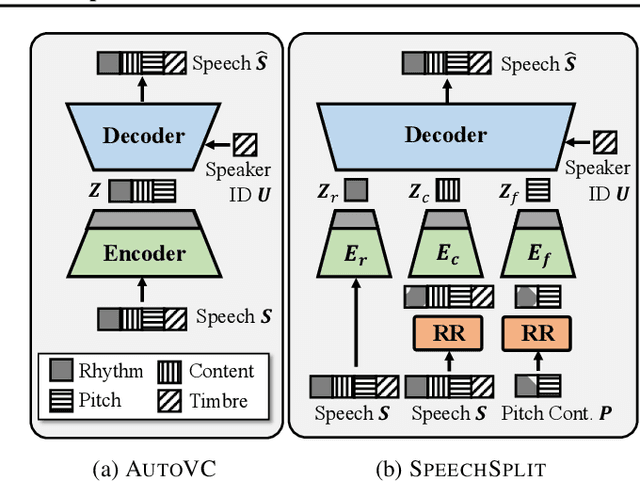
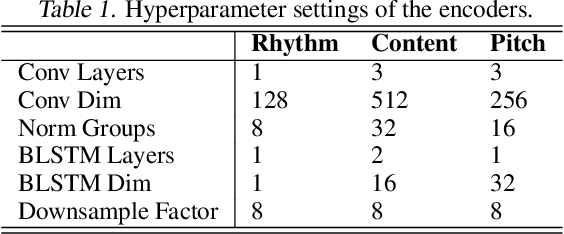
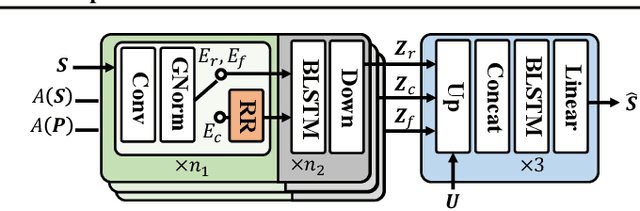

Speech information can be roughly decomposed into four components: language content, timbre, pitch, and rhythm. Obtaining disentangled representations of these components is useful in many speech analysis and generation applications. Recently, state-of-the-art voice conversion systems have led to speech representations that can disentangle speaker-dependent and independent information. However, these systems can only disentangle timbre, while information about pitch, rhythm and content is still mixed together. Further disentangling the remaining speech components is an under-determined problem in the absence of explicit annotations for each component, which are difficult and expensive to obtain. In this paper, we propose SpeechSplit, which can blindly decompose speech into its four components by introducing three carefully designed information bottlenecks. SpeechSplit is among the first algorithms that can separately perform style transfer on timbre, pitch and rhythm without text labels.
Seeing the advantage: visually grounding word embeddings to better capture human semantic knowledge
Feb 21, 2022
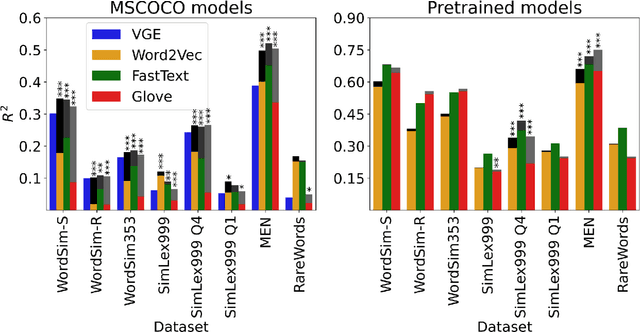
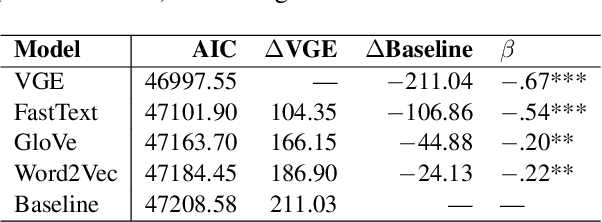

Distributional semantic models capture word-level meaning that is useful in many natural language processing tasks and have even been shown to capture cognitive aspects of word meaning. The majority of these models are purely text based, even though the human sensory experience is much richer. In this paper we create visually grounded word embeddings by combining English text and images and compare them to popular text-based methods, to see if visual information allows our model to better capture cognitive aspects of word meaning. Our analysis shows that visually grounded embedding similarities are more predictive of the human reaction times in a large priming experiment than the purely text-based embeddings. The visually grounded embeddings also correlate well with human word similarity ratings. Importantly, in both experiments we show that the grounded embeddings account for a unique portion of explained variance, even when we include text-based embeddings trained on huge corpora. This shows that visual grounding allows our model to capture information that cannot be extracted using text as the only source of information.
Lean Evolutionary Reinforcement Learning by Multitasking with Importance Sampling
Mar 21, 2022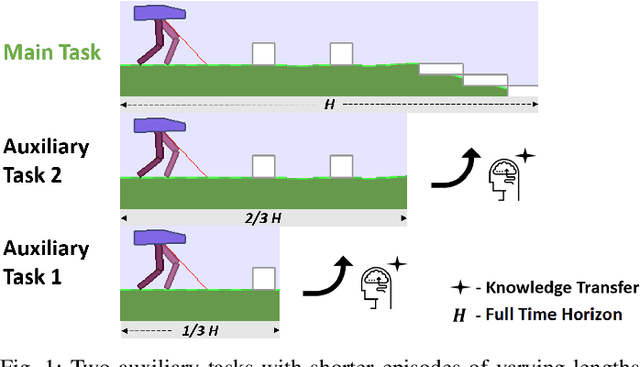


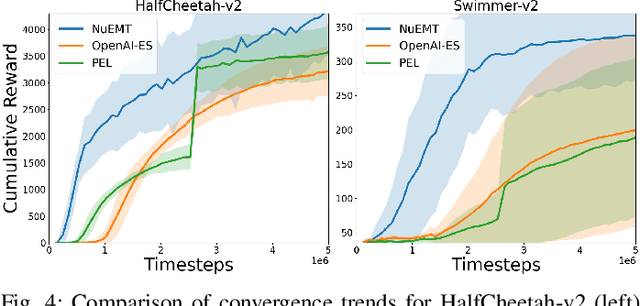
Studies have shown evolution strategies (ES) to be a promising approach for reinforcement learning (RL) with deep neural networks. However, the issue of high sample complexity persists in applications of ES to deep RL. In this paper, we address the shortcoming of today's methods via a novel neuroevolutionary multitasking (NuEMT) algorithm, designed to transfer information from a set of auxiliary tasks (of short episode length) to the target (full length) RL task at hand. The artificially generated auxiliary tasks allow an agent to update and quickly evaluate policies on shorter time horizons. The evolved skills are then transferred to guide the longer and harder task towards an optimal policy. We demonstrate that the NuEMT algorithm achieves data-lean evolutionary RL, reducing expensive agent-environment interaction data requirements. Our key algorithmic contribution in this setting is to introduce, for the first time, a multitask information transfer mechanism based on the statistical importance sampling technique. In addition, an adaptive resource allocation strategy is utilized to assign computational resources to auxiliary tasks based on their gleaned usefulness. Experiments on a range of continuous control tasks from the OpenAI Gym confirm that our proposed algorithm is efficient compared to recent ES baselines.